Med Amazon EMR 6.15, søsatte vi AWS søformation baseret finkornet adgangskontrol (FGAC) på Open Table Formats (OTF'er), herunder Apache Hudi, Apache Iceberg og Delta lake. Dette giver dig mulighed for at forenkle sikkerhed og styring over transaktionelle datasøer ved at give adgangskontrol på tabel-, kolonne- og rækkeniveau-tilladelser med dine Apache Spark-job. Mange store virksomhedsvirksomheder søger at bruge deres transaktionsdatasø til at få indsigt og forbedre beslutningstagningen. Du kan bygge en søhusarkitektur ved hjælp af Amazon EMR integreret med Lake Formation til FGAC. Denne kombination af tjenester giver dig mulighed for at udføre dataanalyse på din transaktionsdatasø, mens du sikrer sikker og kontrolleret adgang.
Amazon EMR record server-komponenten understøtter datafiltreringsfunktionalitet på tabel-, kolonne-, række-, celle- og indlejret attributniveau. Det udvider understøttelse til Hive, Apache Hudi, Apache Iceberg og Delta lake-formater til både læsning (inklusive tidsrejser og trinvis forespørgsel) og skriveoperationer (på DML-sætninger såsom INSERT). Derudover introducerer Amazon EMR med version 6.15 adgangskontrolbeskyttelse til sin applikationswebgrænseflade, såsom on-cluster Spark History Server, Yarn Timeline Server og Yarn Resource Manager UI.
I dette indlæg demonstrerer vi, hvordan man implementerer FGAC på Apache Hudi tabeller ved hjælp af Amazon EMR integreret med Lake Formation.
Brugscase for transaktionsdatasø
Amazon EMR-kunder bruger ofte åbne tabelformater til at understøtte deres ACID-transaktions- og tidsrejsebehov i en datasø. Ved at bevare historiske versioner giver datasø-tidsrejser fordele såsom revision og overholdelse, datagendannelse og rollback, reproducerbar analyse og dataudforskning på forskellige tidspunkter.
En anden populær transaktionsdatasø er trinvis forespørgsel. Inkrementel forespørgsel refererer til en forespørgselsstrategi, der fokuserer på kun at behandle og analysere de nye eller opdaterede data i en datasø siden den sidste forespørgsel. Nøgleideen bag inkrementelle forespørgsler er at bruge metadata eller ændre sporingsmekanismer til at identificere de nye eller ændrede data siden den sidste forespørgsel. Ved at identificere disse ændringer kan forespørgselsmotoren optimere forespørgslen til kun at behandle de relevante data, hvilket væsentligt reducerer behandlingstiden og ressourcekravene.
Løsningsoversigt
I dette indlæg demonstrerer vi, hvordan man implementerer FGAC på Apache Hudi-tabeller ved hjælp af Amazon EMR på Amazon Elastic Compute Cloud (Amazon EC2) integreret med Lake Formation. Apache Hudi er en open source-transaktionel datasø-ramme, der i høj grad forenkler inkrementel databehandling og udvikling af datapipelines. Denne nye FGAC-funktion understøtter alle OTF. Udover at demonstrere med Hudi her, vil vi følge op med andre OTF-tabeller med andre blogs. Vi bruger notesbøger in Amazon SageMaker Studio at læse og skrive Hudi-data via forskellige brugeradgangstilladelser gennem en EMR-klynge. Dette afspejler scenarier for dataadgang i den virkelige verden – for eksempel hvis en ingeniørbruger har brug for fuld dataadgang for at fejlfinde på en dataplatform, hvorimod dataanalytikere muligvis kun har brug for at få adgang til en delmængde af disse data, der ikke indeholder personligt identificerbare oplysninger (PII ). Integrering med Lake Formation via Amazon EMR runtime rolle sætter dig yderligere i stand til at forbedre din datasikkerhedsstilling og forenkler datakontrolstyring for Amazon EMR-arbejdsbelastninger. Denne løsning sikrer et sikkert og kontrolleret miljø for dataadgang, der opfylder de forskellige behov og sikkerhedskrav fra forskellige brugere og roller i en organisation.
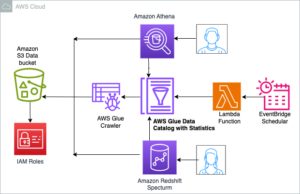
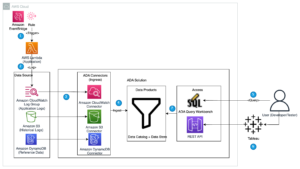
Følgende diagram illustrerer løsningsarkitekturen.
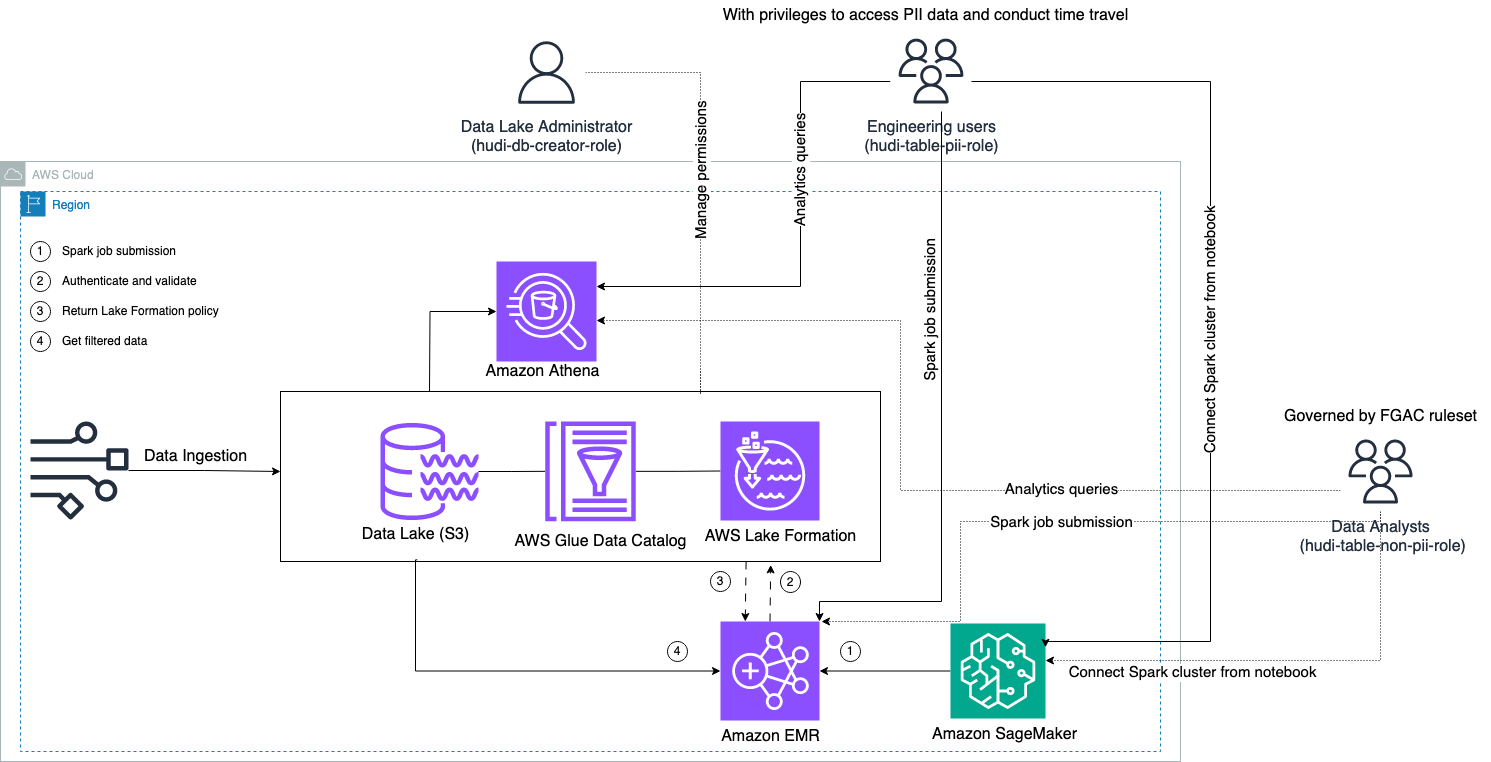
Vi udfører en dataindtagelsesproces for at opsætte (opdatere og indsætte) et Hudi-datasæt til en Amazon Simple Storage Service (Amazon S3) bucket, og fortsætter eller opdater tabelskemaet i AWS Lim Datakatalog. Med nul databevægelse kan vi forespørge Hudi-tabellen styret af Lake Formation via forskellige AWS-tjenester, som f.eks. Amazonas Athena, Amazon EMR og Amazon SageMaker.
Når brugere indsender et Spark-job gennem EMR-klyngeslutpunkter (EMR Steps, Livy, EMR Studio og SageMaker), validerer Lake Formation deres privilegier og instruerer EMR-klyngen i at bortfiltrere følsomme data såsom PII-data.
Denne løsning har tre forskellige typer brugere med forskellige niveauer af tilladelser til at få adgang til Hudi-dataene:
- hudi-db-skaber-rolle – Dette bruges af datasø-administratoren, som har privilegier til at udføre DDL-operationer, såsom oprettelse, ændring og sletning af databaseobjekter. De kan definere datafiltreringsregler på Lake Formation for dataadgangskontrol på række- og kolonneniveau. Disse FGAC-regler sikrer, at datasøen er sikret og opfylder de krævede databeskyttelsesforskrifter.
- hudi-table-pii-rolle – Dette bruges af tekniske brugere. Teknikbrugerne er i stand til at udføre tidsrejser og trinvise forespørgsler på både Copy-on-Write (CoW) og Merge-on-Read (MoR). De har også privilegium til at få adgang til PII-data baseret på eventuelle tidsstempler.
- hudi-bord-ikke-pii-rolle – Dette bruges af dataanalytikere. Dataanalytikeres dataadgangsrettigheder er underlagt FGAC-autoriserede regler, der kontrolleres af datasø-administratorer. De har ikke synlighed på kolonner, der indeholder PII-data som navne og adresser. Derudover kan de ikke få adgang til rækker af data, der ikke opfylder visse betingelser. For eksempel kan brugerne kun få adgang til datarækker, der tilhører deres land.
Forudsætninger
Du kan downloade de tre notesbøger, der bruges i dette indlæg fra GitHub repo.
Før du implementerer løsningen, skal du sikre dig, at du har følgende:
Udfør følgende trin for at konfigurere dine tilladelser:
- Log ind på din AWS-konto med din admin IAM-bruger.
Sørg for, at du er ius-east-1Område.
- Opret en S3-spand i
us-east-1Region (f.eks.emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Dernæst aktiverer vi Lake Formation ved ændring af standardtilladelsesmodellen.
- Log ind på Lake Formation-konsollen som administratorbruger.
- Vælg Indstillinger for datakatalog under Administration i navigationsruden.
- Under Standardtilladelser for nyoprettede databaser og tabeller, fravælg Brug kun IAM-adgangskontrol til nye databaser , Brug kun IAM-adgangskontrol til nye tabeller i nye databaser.
- Vælg Gem.
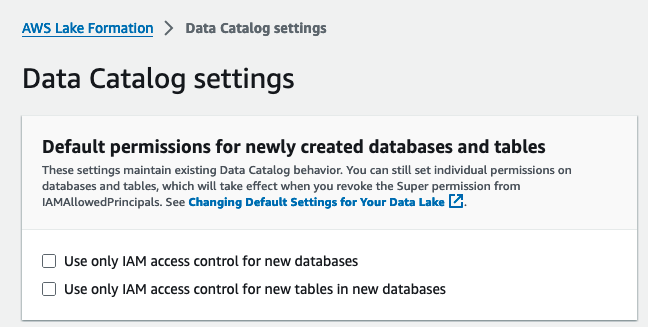
Alternativt skal du tilbagekalde IAMAllowedPrincipals på ressourcer (databaser og tabeller), der er oprettet, hvis du startede Lake Formation med standardindstillingen.
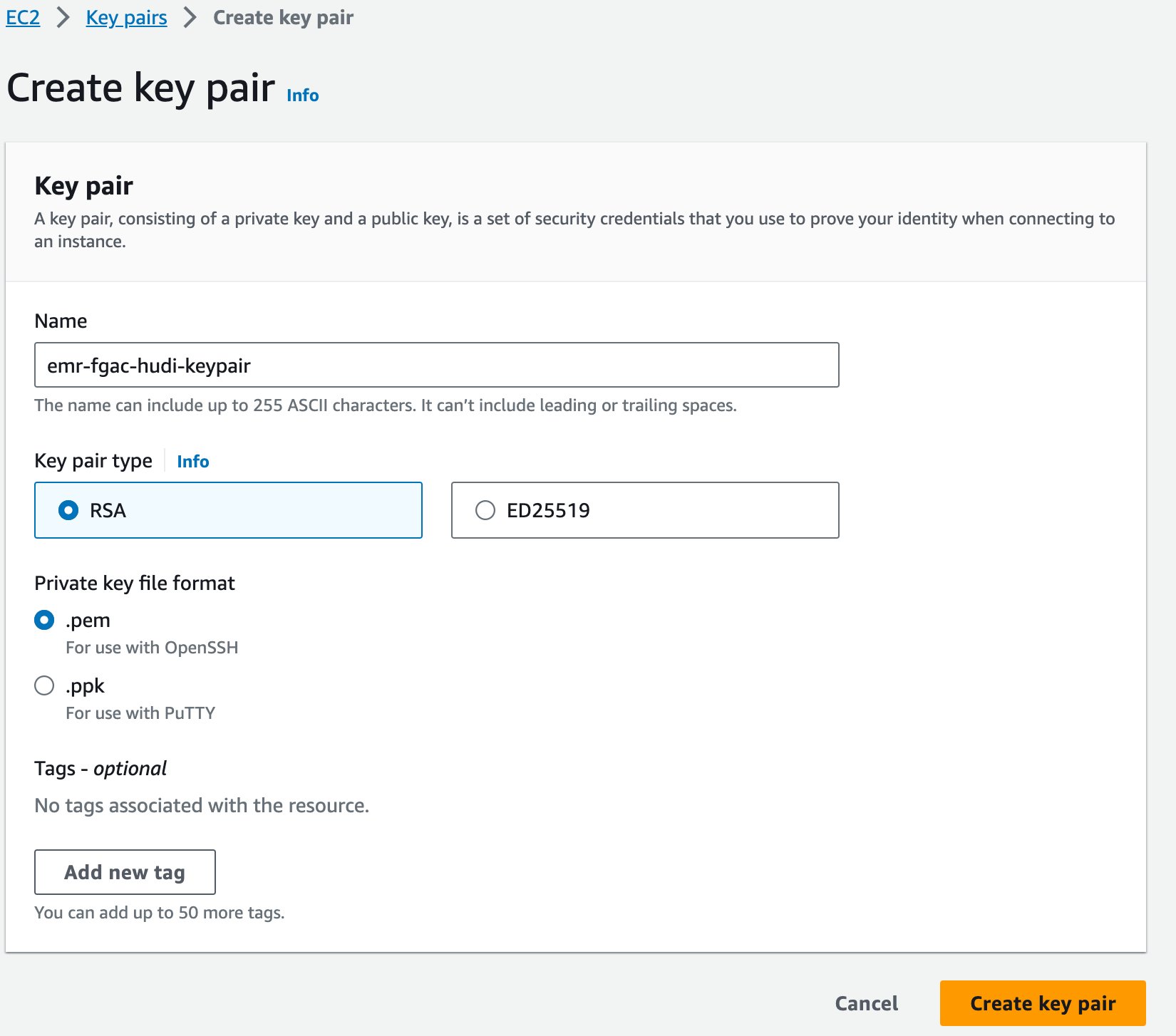
Til sidst opretter vi et nøglepar til Amazon EMR.
- På Amazon EC2-konsollen skal du vælge Nøglepar i navigationsruden.
- Vælg Opret nøglepar.
- Til Navn, indtast et navn (f.eks
emr-fgac-hudi-keypair). - Vælg Opret nøglepar.
Det genererede nøglepar (for dette indlæg, emr-fgac-hudi-keypair.pem) vil gemme på din lokale computer.
Dernæst opretter vi en AWS Cloud9 interaktivt udviklingsmiljø (IDE).
- På AWS Cloud9-konsollen skal du vælge miljøer i navigationsruden.
- Vælg Skab miljø.
- Til Navn¸ indtast et navn (f.eks.
emr-fgac-hudi-env). - Behold de andre indstillinger som standard.
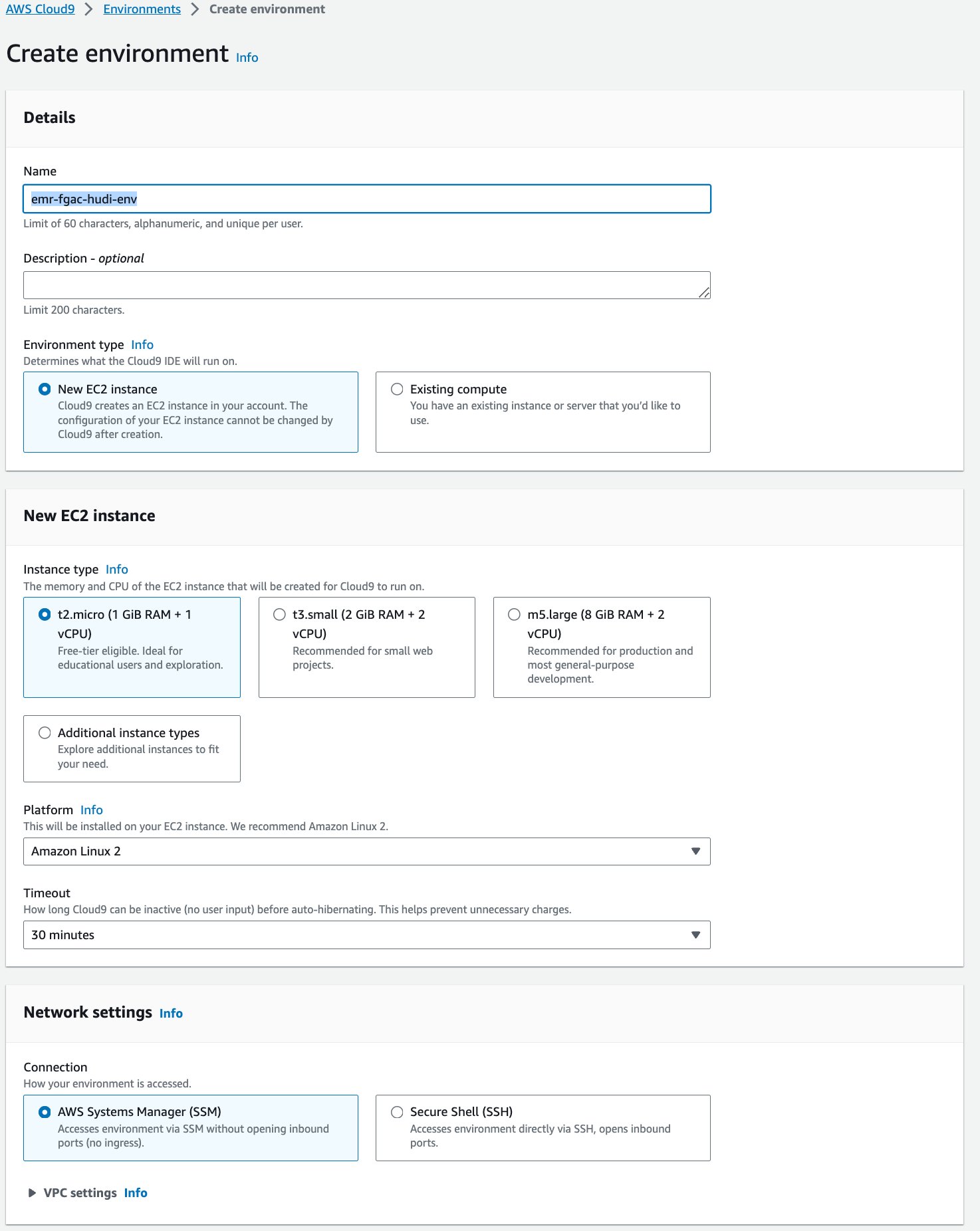
- Vælg Opret.
- Når IDE er klar, skal du vælge Åbne at åbne den.
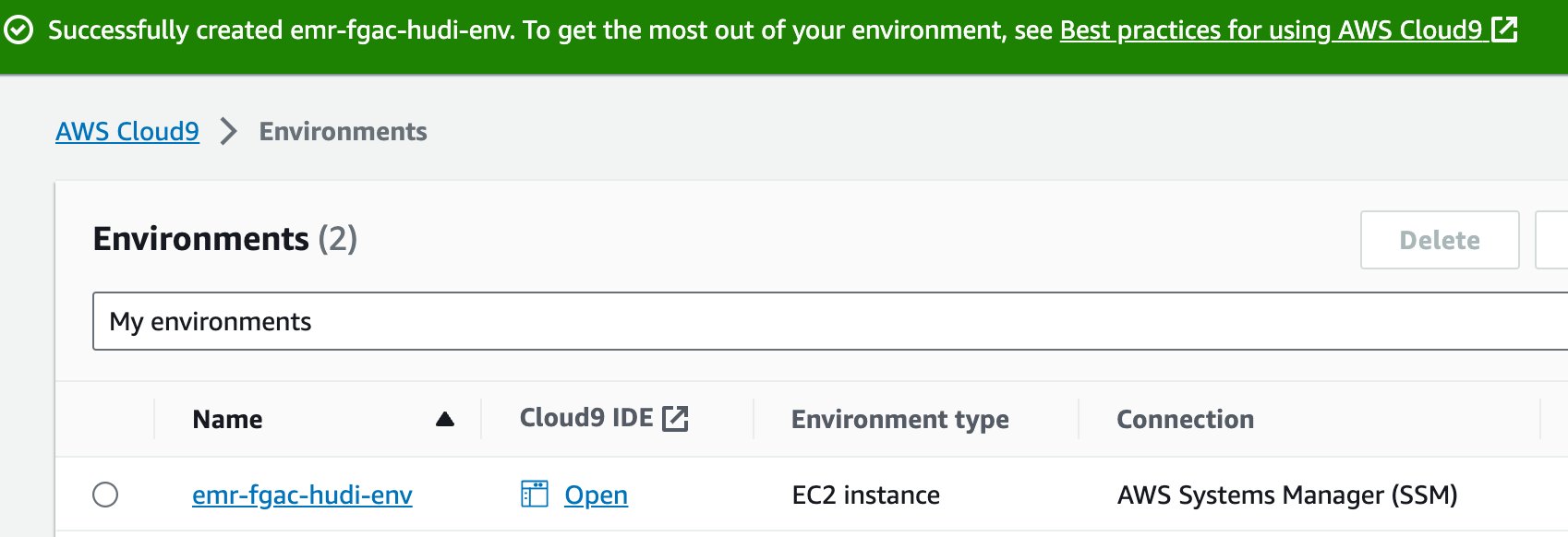
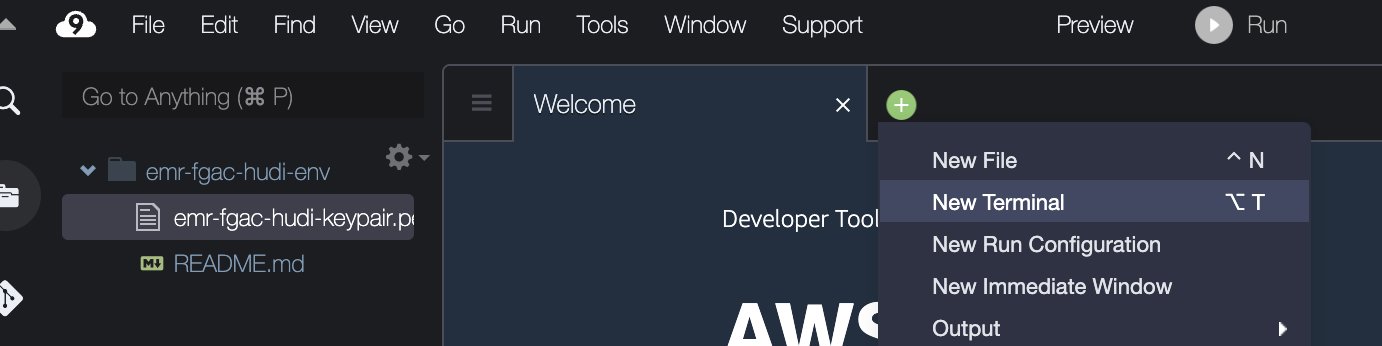
- I AWS Cloud9 IDE, på File (Felt) menu, vælg Upload lokale filer.

- Upload nøglepar-filen (
emr-fgac-hudi-keypair.pem). - Vælg plustegnet og vælg Ny terminal.
- Indtast følgende kommandolinjer i terminalen:
Bemærk, at eksempelkoden kun er et proof of concept til demonstrationsformål. For produktionssystemer skal du bruge en betroet certificeringsmyndighed (CA) til at udstede certifikater. Henvise til Levering af certifikater til kryptering af data under transport med Amazon EMR-kryptering for yderligere oplysninger.
Implementer løsningen via AWS CloudFormation
Vi leverer en AWS CloudFormation skabelon, der automatisk opsætter følgende tjenester og komponenter:
- En S3-spand til datasøen. Det indeholder eksempel TPC-DS datasættet.
- En EMR-klynge med sikkerhedskonfiguration og offentlig DNS aktiveret.
- EMR runtime IAM-roller med Lake Formation finmaskede tilladelser:
- -hudi-db-skaber-rolle – Denne rolle bruges til at oprette Apache Hudi-database og tabeller.
- -hudi-table-pii-rolle – Denne rolle giver tilladelse til at forespørge alle kolonner i Hudi-tabeller, inklusive kolonner med PII.
- -hudi-bord-ikke-pii-rolle – Denne rolle giver tilladelse til at forespørge i Hudi-tabeller, der har filtreret PII-kolonner fra Lake Formation.
- SageMaker Studio eksekveringsroller, der giver brugerne mulighed for at påtage sig deres tilsvarende EMR runtime roller.
- Netværksressourcer såsom VPC, undernet og sikkerhedsgrupper.
Udfør følgende trin for at implementere ressourcerne:
- Vælg Hurtig oprette stak for at starte CloudFormation-stakken.
- Til Staknavn, indtast et staknavn (f.eks.
rsv2-emr-hudi-blog). - Til Ec2KeyPair, indtast navnet på dit nøglepar.
- Til IdleTimeout, indtast en ledig timeout for EMR-klyngen for at undgå at betale for klyngen, når den ikke bliver brugt.
- Til InitS3Bucket, indtast S3-bøttenavnet, du oprettede for at gemme Amazon EMR-krypteringscertifikatet .zip-fil.
- Til S3CertsZip, skal du indtaste S3-URI'en for Amazon EMR-krypteringscertifikatets .zip-fil.
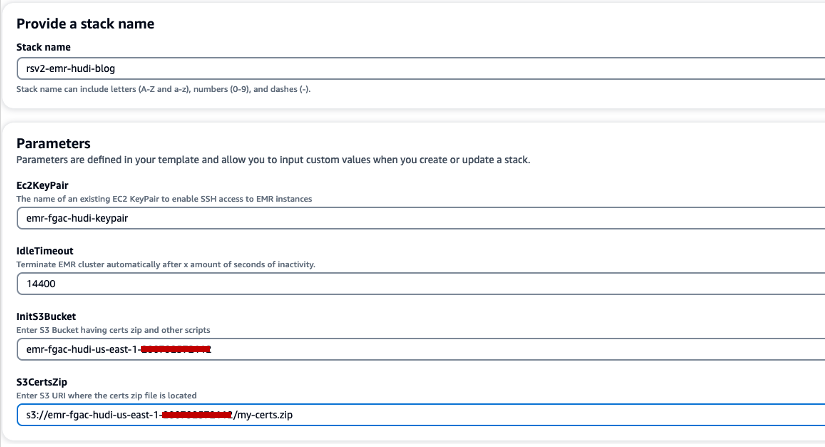
- Type Jeg anerkender, at AWS CloudFormation kan skabe IAM-ressourcer med brugerdefinerede navne.
- Vælg Opret stak.
CloudFormations stak-implementeringen tager omkring 10 minutter.
Konfigurer Lake Formation til Amazon EMR-integration
Udfør følgende trin for at konfigurere Lake Formation:
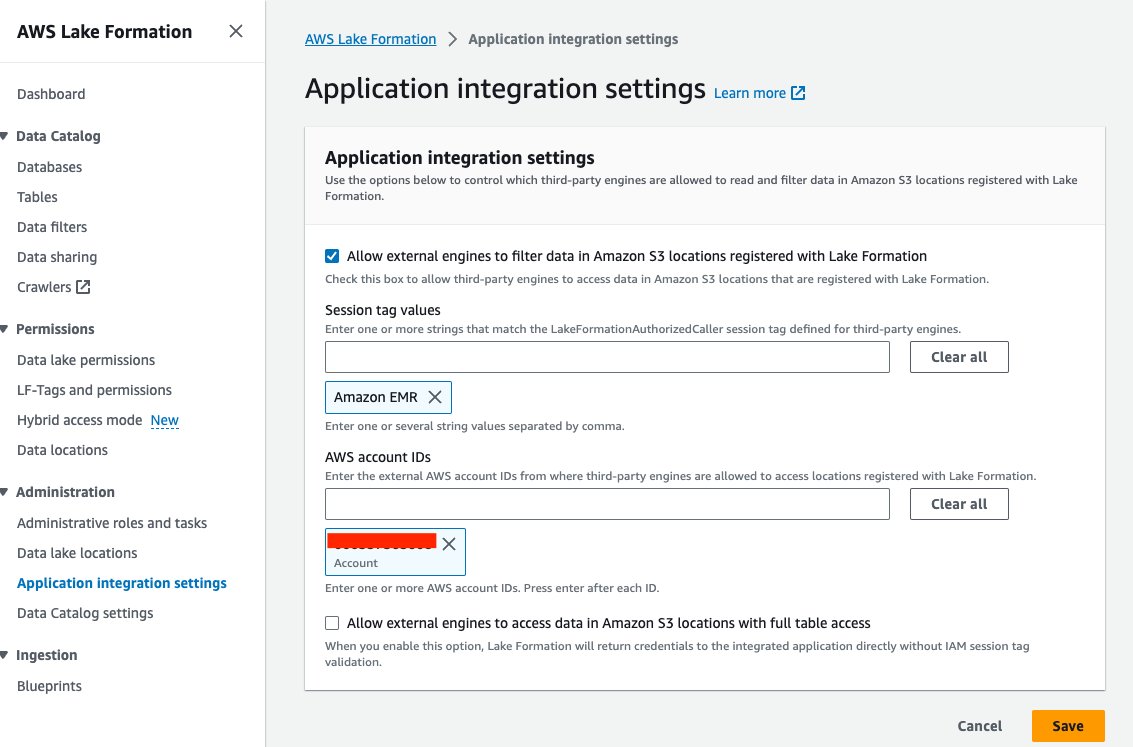
- Vælg på Lake Formation-konsollen Indstillinger for applikationsintegration under Administration i navigationsruden.
- Type Tillad eksterne motorer at filtrere data på Amazon S3-lokationer, der er registreret hos Lake Formation.
- Vælg Amazon EMR forum Session tag værdier.
- Indtast dit AWS-konto-id for AWS-konto-id'er.
- Vælg Gem.
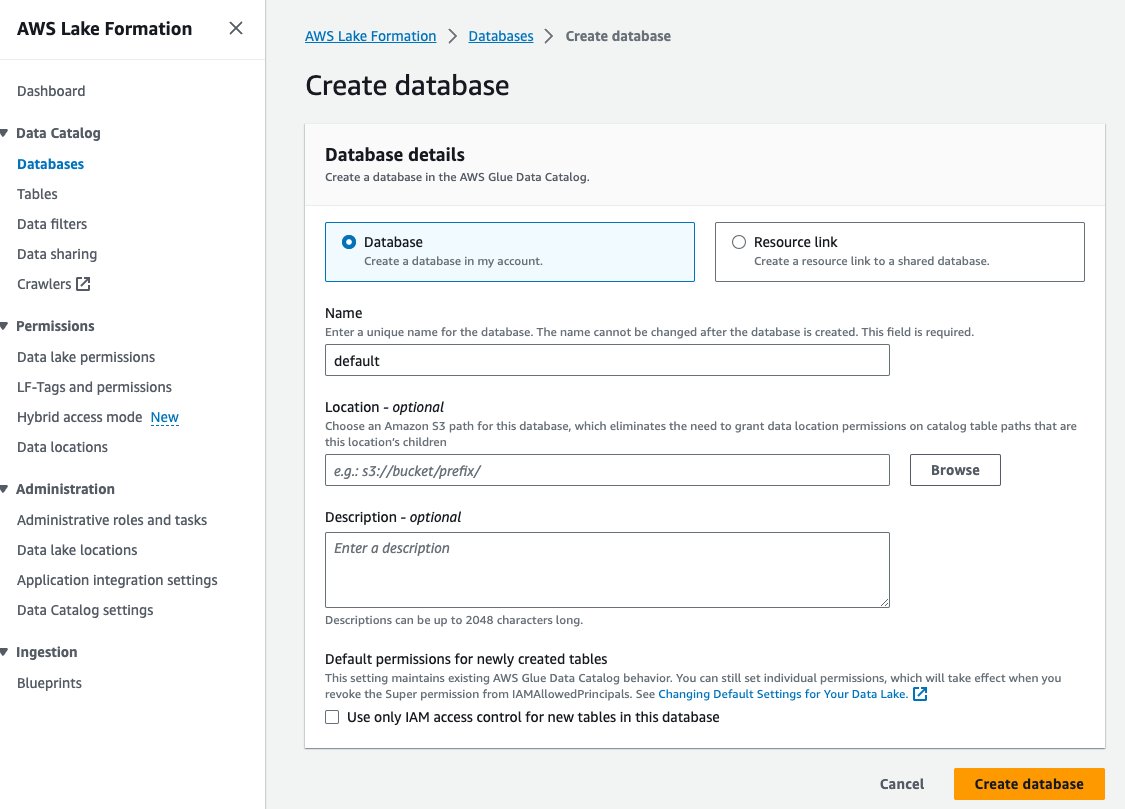
- Vælg Databaser under Datakatalog i navigationsruden.
- Vælg Opret database.
- Til Navn, indtast standard.
- Vælg Opret database.
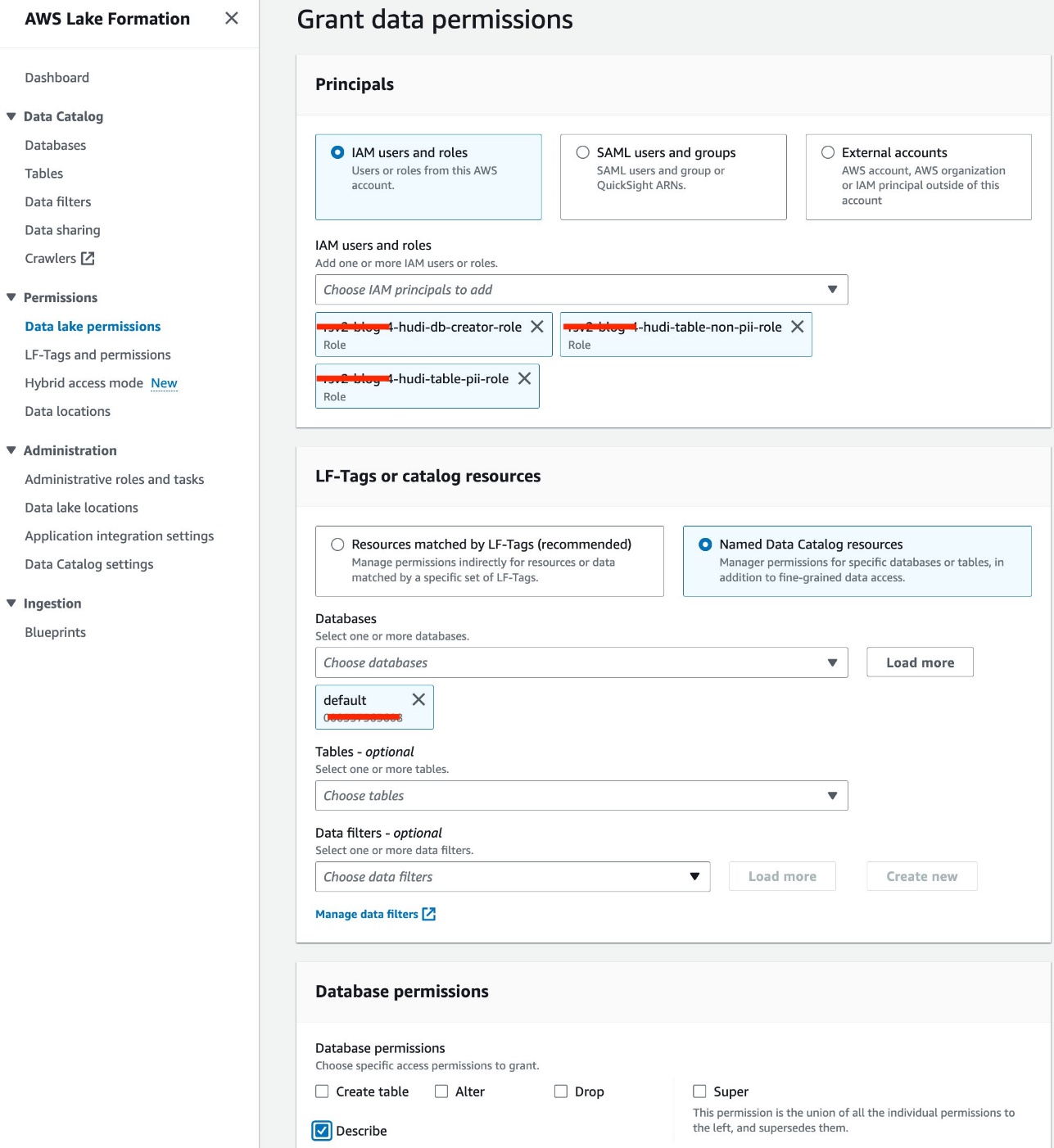
- Vælg Data sø-tilladelser under Tilladelser i navigationsruden.
- Vælg Grant.
- Type IAM brugere og roller.
- Vælg dine IAM-roller.
- Til Databaser, vælg standard.
- Til Databasetilladelser, Vælg Beskriv.
- Vælg Grant.
Kopier Hudi JAR-filen til Amazon EMR HDFS
Til brug Hudi med Jupyter notesbøger, skal du udføre følgende trin for EMR-klyngen, som inkluderer kopiering af en Hudi JAR-fil fra Amazon EMR-lokalbiblioteket til dets HDFS-lager, så du kan konfigurere en Spark-session til at bruge Hudi:
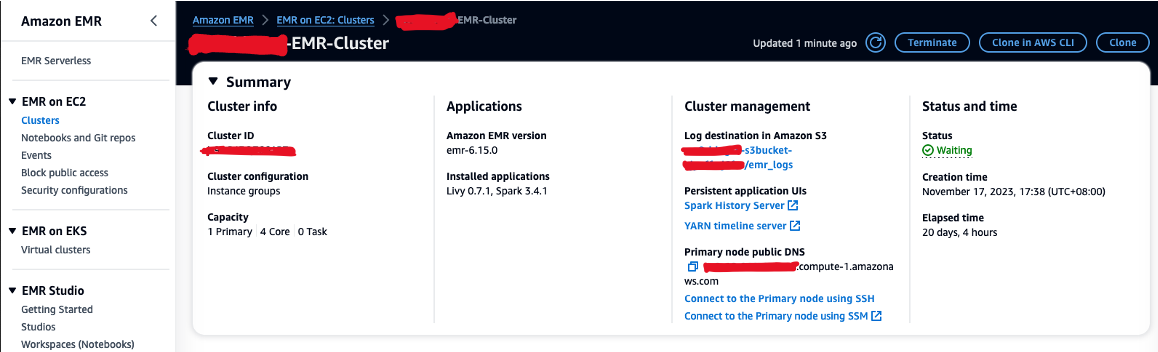
- Godkend indgående SSH-trafik (port 22).
- Kopier værdien for Primær node offentlig DNS (f.eks. ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) fra EMR-klyngen Resumé sektion.
- Gå tilbage til den forrige AWS Cloud9-terminal, du brugte til at oprette EC2-nøgleparret.
- Kør følgende kommando til SSH ind i den primære EMR-knude. Udskift pladsholderen med dit EMR DNS-værtsnavn:
- Kør følgende kommando for at kopiere Hudi JAR-filen til HDFS:
Opret Hudi-databasen og tabellerne i Lake Formation
Nu er vi klar til at oprette Hudi-databasen og tabellerne med FGAC aktiveret af EMR-runtime-rollen. Det EMR runtime rolle er en IAM-rolle, som du kan angive, når du sender et job eller en forespørgsel til en EMR-klynge.
Giv databaseopretter tilladelse
Lad os først give Lake Formation-databaseopretteren tilladelse til<STACK-NAME>-hudi-db-creator-role:
- Log ind på din AWS-konto som administrator.
- Vælg på Lake Formation-konsollen Administrative roller og opgaver under Administration i navigationsruden.
- Bekræft, at din AWS-loginbruger er blevet tilføjet som datasø-administrator.
- I Database skaber sektion, skal du vælge Grant.
- Til IAM brugere og roller, vælg
<STACK-NAME>-hudi-db-creator-role. - Til Katalogtilladelser, Vælg Opret database.
- Vælg Grant.
Registrer datasøens placering
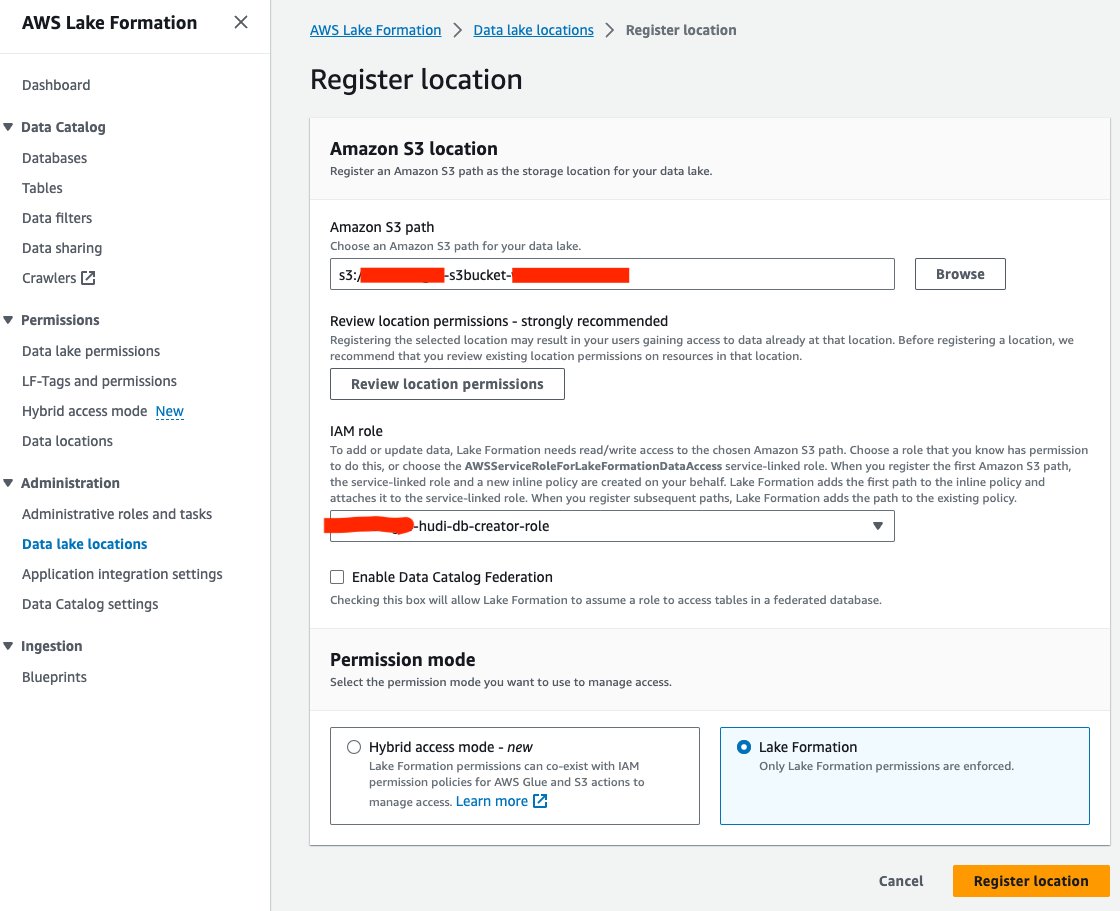
Lad os derefter registrere S3-datasøens placering i Lake Formation:
- Vælg på Lake Formation-konsollen Placering af datasøer under Administration i navigationsruden.
- Vælg Registrer placering.
- Til Amazon S3-sti, Vælg Gennemse og vælg data lake S3-spanden. (
<STACK_NAME>s3bucket-XXXXXXX) oprettet fra CloudFormation-stakken. - Til IAM rolle, vælg
<STACK-NAME>-hudi-db-creator-role. - Til Tilladelsestilstand, Vælg Søformation.
- Vælg Registrer placering.
Giv dataplaceringstilladelse
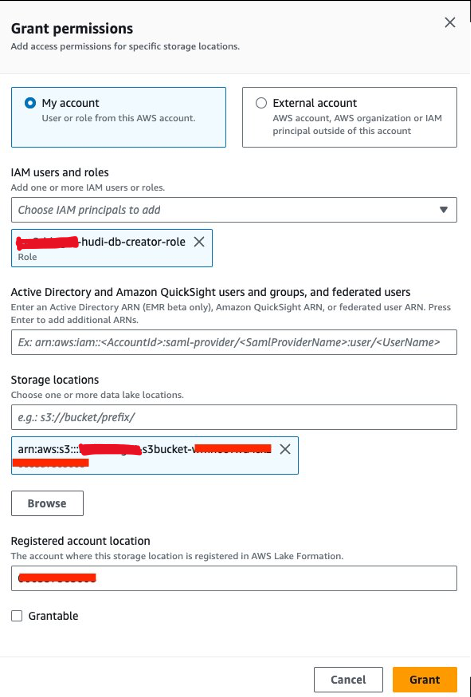
Dernæst skal vi bevilge<STACK-NAME>-hudi-db-creator-roledataplaceringstilladelsen:
- Vælg på Lake Formation-konsollen Dataplaceringer under Tilladelser i navigationsruden.
- Vælg Grant.
- Til IAM brugere og roller, vælg
<STACK-NAME>-hudi-db-creator-role. - Til Opbevaringssteder, indtast S3-spanden (
<STACK_NAME>-s3bucket-XXXXXXX). - Vælg Grant.
Tilslut til EMR-klyngen
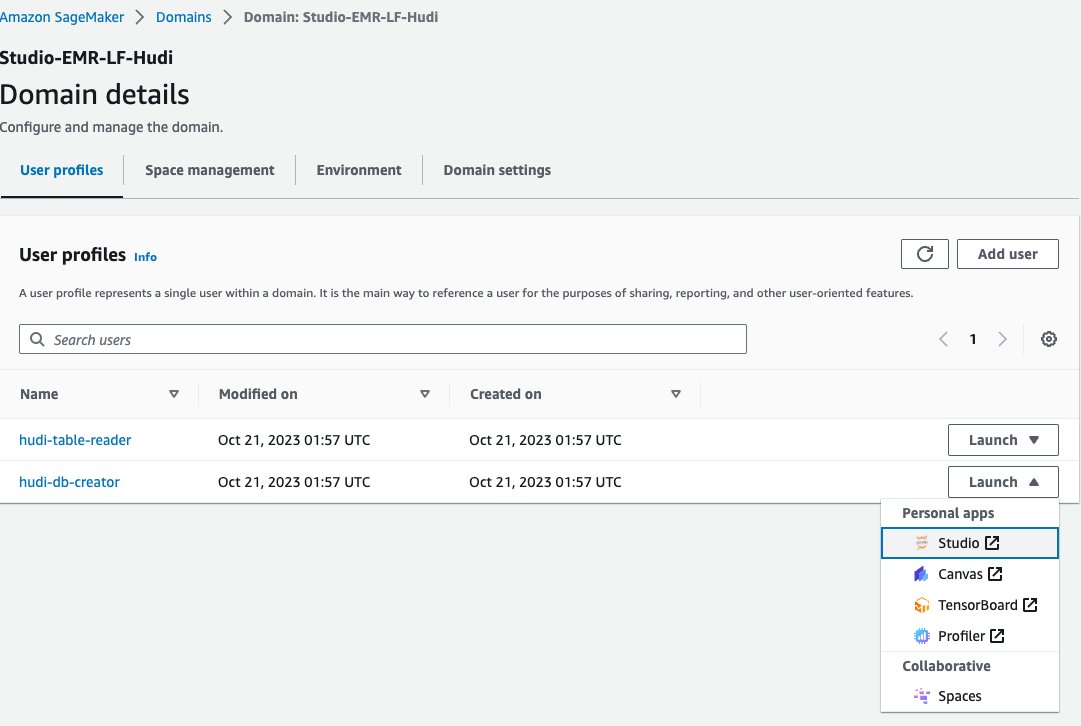
Lad os nu bruge en Jupyter-notesbog i SageMaker Studio til at oprette forbindelse til EMR-klyngen med databaseskaberen EMR-runtime-rollen:
- Vælg på SageMaker-konsollen domæner i navigationsruden.
- Vælg domænet
<STACK-NAME>-Studio-EMR-LF-Hudi. - På Launch menuen ud for brugerprofilen
<STACK-NAME>-hudi-db-creator, vælg studie.
- Download notesbogen rsv2-hudi-db-creator-notebook.
- Vælg upload-ikonet.
- Vælg den downloadede Jupyter notesbog og vælg Åbne.
- Åbn den uploadede notesbog.
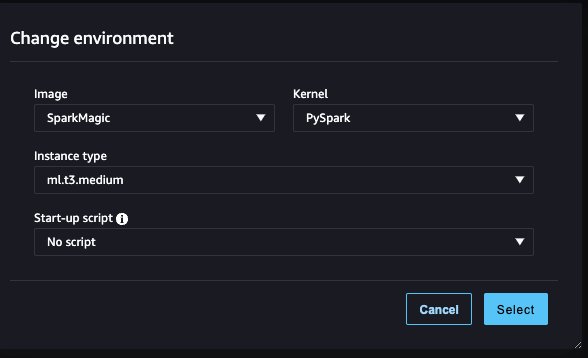
- Til Billede, vælg SparkMagic.
- Til kernel, vælg PySpark.
- Lad de andre konfigurationer være standard, og vælg Type.
- Vælg Cluster for at oprette forbindelse til EMR-klyngen.

- Vælg EMR på EC2-klyngen (
<STACK-NAME>-EMR-Cluster) oprettet med CloudFormation-stakken. - Vælg Tilslut.
- Til EMR-udførelsesrolle, vælg
<STACK-NAME>-hudi-db-creator-role. - Vælg Tilslut.
Opret database og tabeller
Nu kan du følge trinene i notesbogen for at oprette Hudi-databasen og tabellerne. De vigtigste trin er som følger:
- Når du starter den bærbare computer, skal du konfigurere
“spark.sql.catalog.spark_catalog.lf.managed":"true"at informere Spark om, at spark_catalog er beskyttet af Lake Formation. - Opret Hudi-tabeller ved hjælp af følgende Spark SQL.
- Indsæt data fra kildetabellen til Hudi-tabellerne.
- Indsæt data igen i Hudi-tabellerne.
Forespørg Hudi-tabellerne via Lake Formation med FGAC
Når du har oprettet Hudi-databasen og tabellerne, er du klar til at forespørge tabellerne ved hjælp af finmasket adgangskontrol med Lake Formation. Vi har lavet to typer Hudi-tabeller: Copy-On-Write (COW) og Merge-On-Read (MOR). COW-tabellen gemmer data i et søjleformat (Parquet), og hver opdatering opretter en ny version af filer under en skrivning. Det betyder, at Hudi for hver opdatering omskriver hele filen, hvilket kan være mere ressourcekrævende, men giver hurtigere læseydelse. MOR, på den anden side, er indført for tilfælde, hvor COW måske ikke er optimal, især for skrive- eller ændringstunge arbejdsbyrder. I en MOR-tabel, hver gang der er en opdatering, skriver Hudi kun rækken for den ændrede post, hvilket reducerer omkostningerne og muliggør skrivning med lav latens. Læseydelsen kan dog være langsommere sammenlignet med COW-tabeller.
Giv bordadgangstilladelse
Vi bruger IAM-rollen<STACK-NAME>-hudi-table-pii-roleat forespørge Hudi COW og MOR indeholdende PII-kolonner. Vi giver først bordet adgangstilladelse via Lake Formation:
- Vælg på Lake Formation-konsollen Data sø-tilladelser under Tilladelser i navigationsruden.
- Vælg Grant.
- Vælg
<STACK-NAME>-hudi-table-pii-roleforum IAM brugere og roller. - Vælg den
rsv2_blog_hudi_db_1database til Databaser. - Til tabeller, vælg de fire Hudi-tabeller, du oprettede i Jupyter-notesbogen.
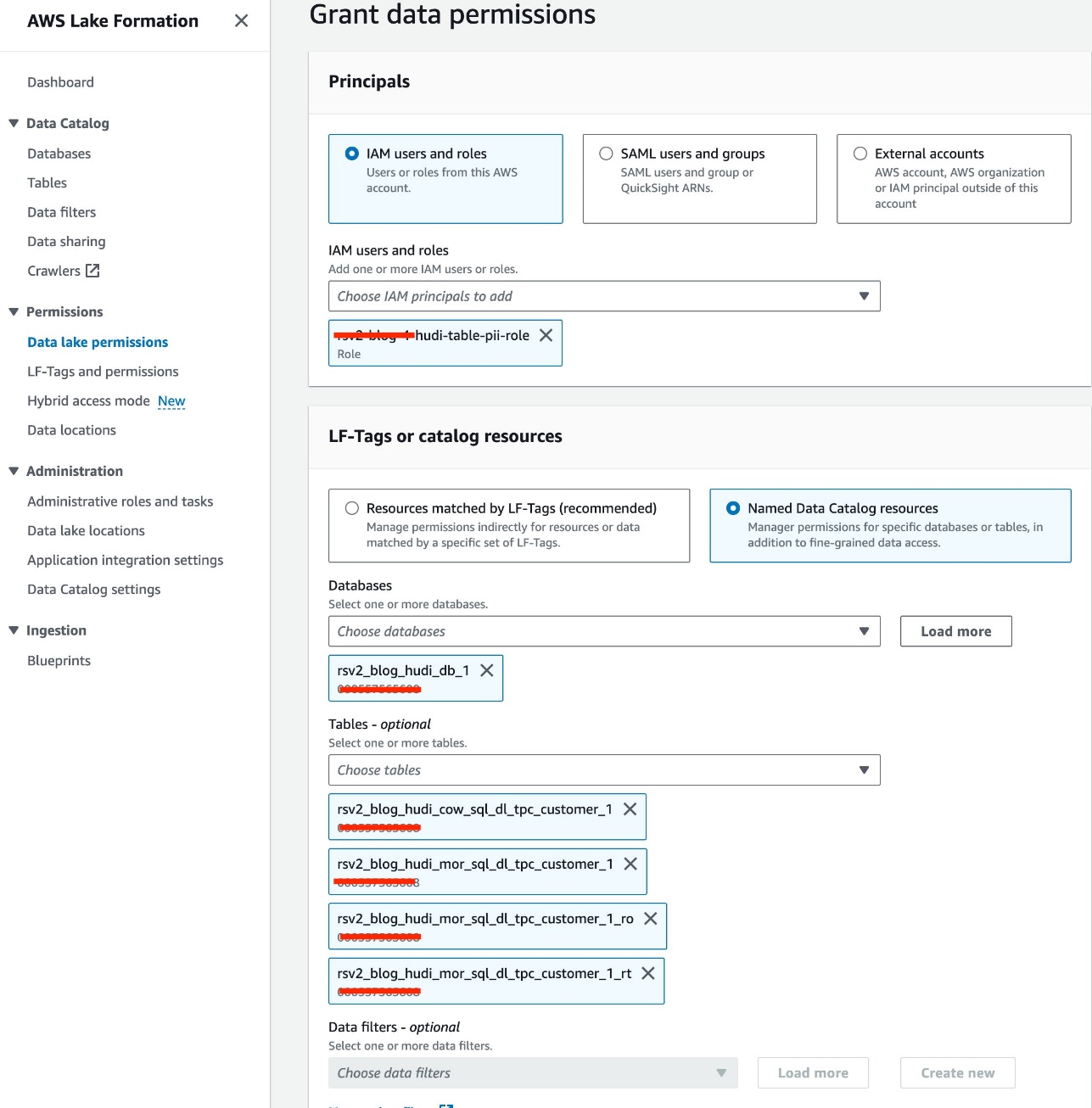
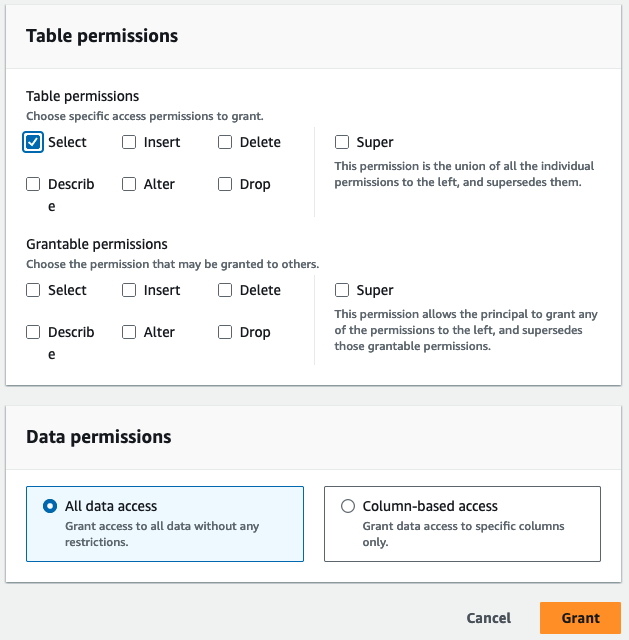
- Til Tabeltilladelser, Vælg Type.
- Vælg Grant.
Spørg PII-kolonner
Nu er du klar til at køre notesbogen for at forespørge Hudi-tabellerne. Lad os følge lignende trin til det forrige afsnit for at køre notesbogen i SageMaker Studio:
- På SageMaker-konsollen skal du navigere til
<STACK-NAME>-Studio-EMR-LF-Hudidomæne. - På Launch menuen ved siden af
<STACK-NAME>-hudi-table-readerbrugerprofil, vælg studie. - Upload den downloadede notesbog rsv2-hudi-table-pii-læser-notesbog.
- Åbn den uploadede notesbog.
- Gentag notebook-opsætningstrinnene og opret forbindelse til den samme EMR-klynge, men brug rollen
<STACK-NAME>-hudi-table-pii-role.
I den nuværende fase skal FGAC-aktiveret EMR-klynge forespørge Hudis forpligtelsestidskolonne for at udføre inkrementelle forespørgsler og tidsrejser. Det understøtter ikke Sparks "tidsstempel fra" syntaks og Spark.read(). Vi arbejder aktivt på at inkorporere støtte til begge handlinger i fremtidige Amazon EMR-udgivelser med FGAC aktiveret.
Du kan nu følge trinene i notesbogen. Følgende er nogle fremhævede trin:
- Kør en snapshot-forespørgsel.
- Kør en trinvis forespørgsel.
- Kør en tidsrejseforespørgsel.
- Kør MOR læseoptimerede og realtidstabelforespørgsler.
Forespørg Hudi-tabellerne med datafiltre på kolonneniveau og rækkeniveau
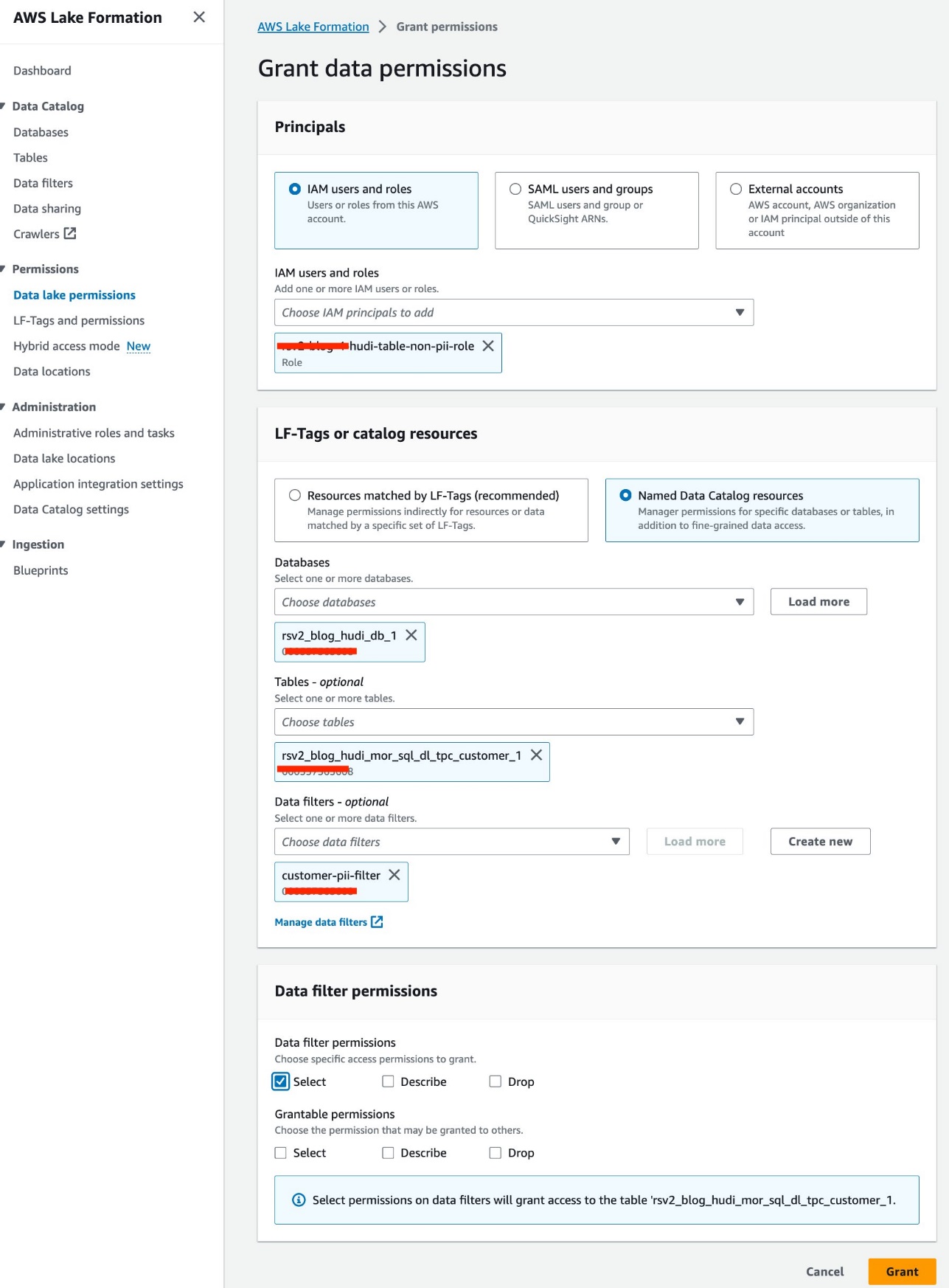
Vi bruger IAM-rollen<STACK-NAME>-hudi-table-non-pii-rolefor at forespørge Hudi-tabeller. Denne rolle har ikke tilladelse til at forespørge på kolonner, der indeholder PII. Vi bruger datafiltre på søjle- og rækkeniveau til at implementere finkornet adgangskontrol:
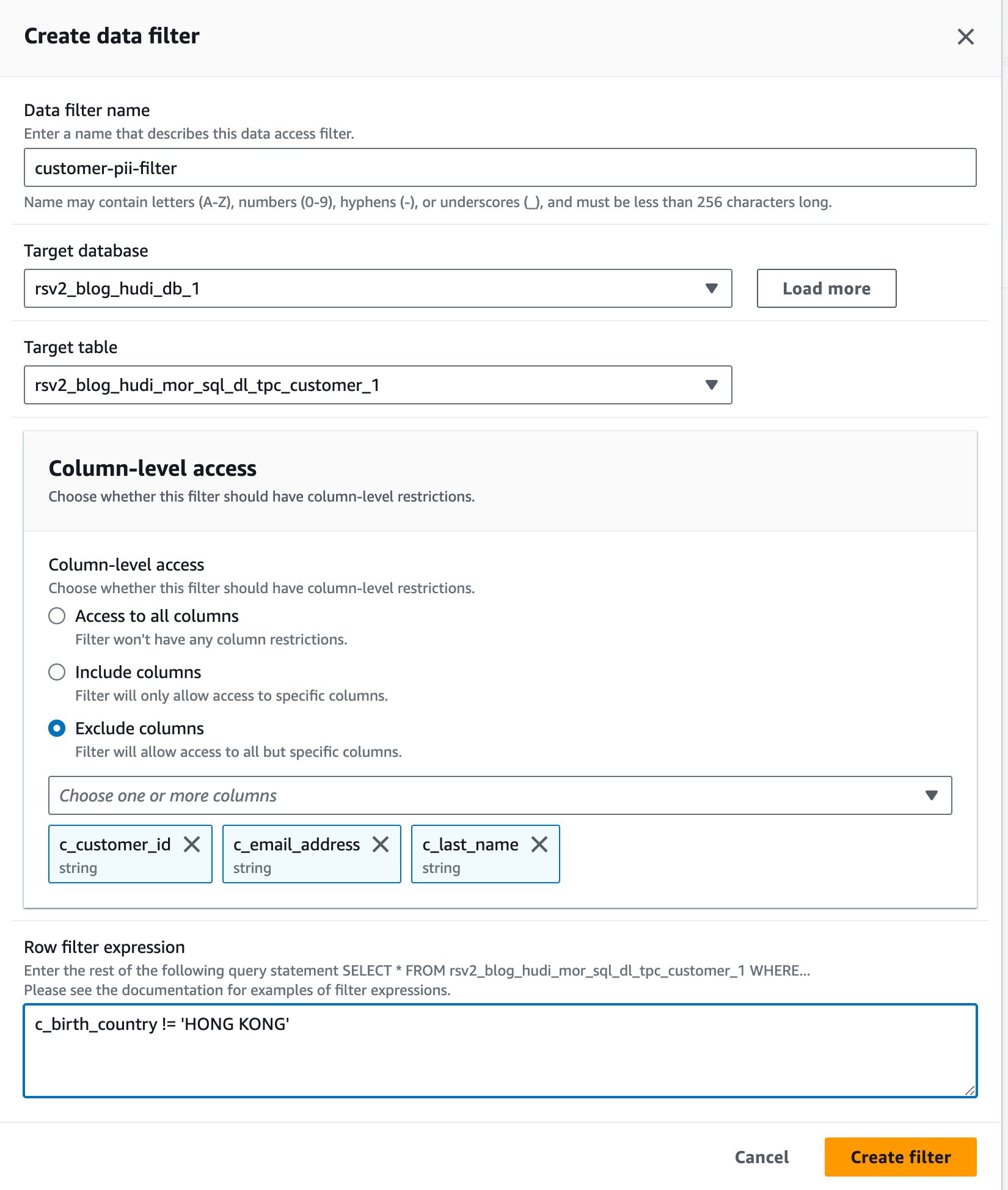
- Vælg på Lake Formation-konsollen Datafiltre under Datakatalog i navigationsruden.
- Vælg Opret nyt filter.
- Til Datafilternavn, gå ind
customer-pii-filter. - Vælg
rsv2_blog_hudi_db_1forum Måldatabase. - Vælg
rsv2_blog_hudi_mor_sql_dl_customer_1forum Måltabel. - Type Ekskluder kolonner og vælg
c_customer_id,c_email_addressogc_last_namekolonner. - Indtast
c_birth_country != 'HONG KONG'forum Rækkefilterudtryk. - Vælg Opret filter.
- Vælg Data sø-tilladelser under Tilladelser i navigationsruden.
- Vælg Grant.
- Vælg
<STACK-NAME>-hudi-table-non-pii-roleforum IAM brugere og roller. - Vælg
rsv2_blog_hudi_db_1forum Databaser. - Vælg
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1forum tabeller. - Vælg
customer-pii-filterforum Datafiltre. - Til Datafiltertilladelser, Vælg Type.
- Vælg Grant.
Lad os følge lignende trin for at køre notesbogen i SageMaker Studio:
- På SageMaker-konsollen skal du navigere til domænet
Studio-EMR-LF-Hudi. - På Launch menu til
hudi-table-readerbrugerprofil, vælg studie. - Upload den downloadede notesbog rsv2-hudi-table-ikke-pii-læser-notesbog Og vælg Åbne.
- Gentag notebook-opsætningstrinnene og opret forbindelse til den samme EMR-klynge, men vælg rollen
<STACK-NAME>-hudi-table-non-pii-role.
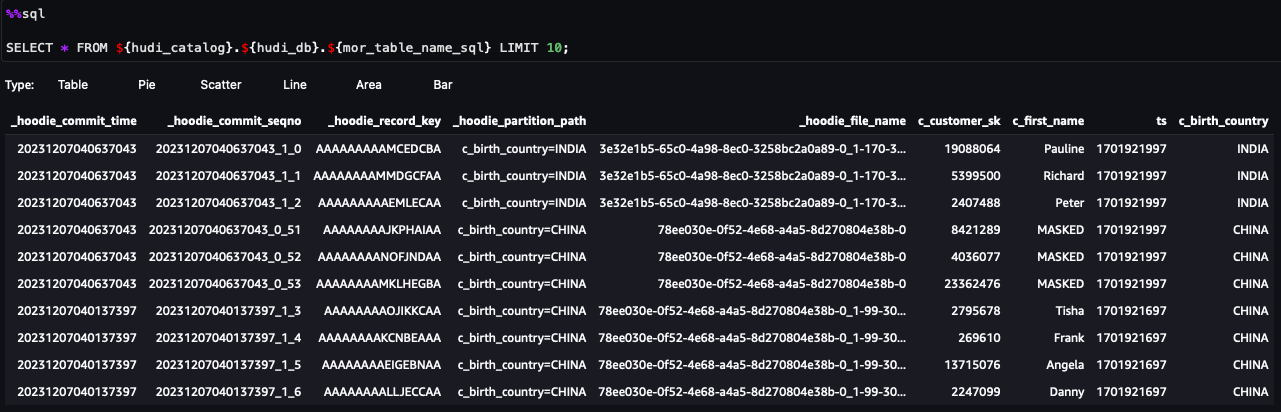
Du kan nu følge trinene i notesbogen. Fra forespørgselsresultaterne kan du se, at FGAC via søformationsdatafilteret er blevet anvendt. Rollen kan ikke se PII-kolonnernec_customer_id,c_last_nameogc_email_address. Også rækkerne fraHONG KONGer blevet filtreret.
Ryd op
Når du er færdig med at eksperimentere med løsningen, anbefaler vi at rydde op i ressourcer med følgende trin for at undgå uventede omkostninger:
- Luk SageMaker Studio-apps for brugerprofilerne.
EMR-klyngen slettes automatisk efter timeout-værdien for tomgang.
- Slette Amazon Elastic File System (Amazon EFS) volumen oprettet for domænet.
- Tøm S3-spandene oprettet af CloudFormation-stakken.
- Slet stakken på AWS CloudFormation-konsollen.
Konklusion
I dette indlæg brugte vi Apachi Hudi, en type OTF-tabeller, til at demonstrere denne nye funktion til at håndhæve finkornet adgangskontrol på Amazon EMR. Du kan definere granulære tilladelser i Lake Formation for OTF-tabeller og anvende dem via Spark SQL-forespørgsler på EMR-klynger. Du kan også bruge transaktionsdatasø-funktioner, såsom at køre snapshot-forespørgsler, inkrementelle forespørgsler, tidsrejser og DML-forespørgsler. Bemærk venligst, at denne nye funktion dækker alle OTF-borde.
Denne funktion lanceres i alt fra Amazon EMR release 6.15 Regioner hvor Amazon EMR er tilgængelig. Med Amazon EMR-integration med Lake Formation kan du trygt administrere og behandle big data, låse op for indsigt og lette informeret beslutningstagning, mens du opretholder datasikkerhed og styring.
For at lære mere, se Aktiver søformation med Amazon EMR og kontakt gerne dine AWS Solutions Architects, som kan være behjælpelige ved siden af din datarejse.
Om forfatteren
 Raymond Lai er en Senior Solutions Architect, der har specialiseret sig i at imødekomme behovene hos store virksomhedskunder. Hans ekspertise ligger i at hjælpe kunder med at migrere indviklede virksomhedssystemer og databaser til AWS, konstruere virksomhedsdata warehousing og data lake platforme. Raymond udmærker sig ved at identificere og designe løsninger til AI/ML use cases, og han har særligt fokus på AWS Serverless løsninger og Event Driven Architecture design.
Raymond Lai er en Senior Solutions Architect, der har specialiseret sig i at imødekomme behovene hos store virksomhedskunder. Hans ekspertise ligger i at hjælpe kunder med at migrere indviklede virksomhedssystemer og databaser til AWS, konstruere virksomhedsdata warehousing og data lake platforme. Raymond udmærker sig ved at identificere og designe løsninger til AI/ML use cases, og han har særligt fokus på AWS Serverless løsninger og Event Driven Architecture design.
 Bin Wang, PhD, er en Senior Analytic Specialist Solutions Architect hos AWS, der kan prale af over 12 års erfaring i ML-industrien med særligt fokus på annoncering. Han besidder ekspertise i naturlig sprogbehandling (NLP), anbefalingssystemer, forskellige ML-algoritmer og ML-operationer. Han er dybt passioneret omkring at anvende ML/DL og big data-teknikker til at løse problemer i den virkelige verden.
Bin Wang, PhD, er en Senior Analytic Specialist Solutions Architect hos AWS, der kan prale af over 12 års erfaring i ML-industrien med særligt fokus på annoncering. Han besidder ekspertise i naturlig sprogbehandling (NLP), anbefalingssystemer, forskellige ML-algoritmer og ML-operationer. Han er dybt passioneret omkring at anvende ML/DL og big data-teknikker til at løse problemer i den virkelige verden.
 Aditya Shah er softwareudviklingsingeniør hos AWS. Han er interesseret i databaser og datavarehusmotorer og har arbejdet med ydelsesoptimeringer, sikkerhedsoverholdelse og ACID-overholdelse for motorer som Apache Hive og Apache Spark.
Aditya Shah er softwareudviklingsingeniør hos AWS. Han er interesseret i databaser og datavarehusmotorer og har arbejdet med ydelsesoptimeringer, sikkerhedsoverholdelse og ACID-overholdelse for motorer som Apache Hive og Apache Spark.
 Melodi Yang er Senior Big Data Solution Architect for Amazon EMR hos AWS. Hun er en erfaren analyseleder, der arbejder med AWS-kunder for at give bedste praksis-vejledning og teknisk rådgivning for at hjælpe deres succes med datatransformation. Hendes interesseområder er open source frameworks og automatisering, data engineering og DataOps.
Melodi Yang er Senior Big Data Solution Architect for Amazon EMR hos AWS. Hun er en erfaren analyseleder, der arbejder med AWS-kunder for at give bedste praksis-vejledning og teknisk rådgivning for at hjælpe deres succes med datatransformation. Hendes interesseområder er open source frameworks og automatisering, data engineering og DataOps.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 100
- 11
- 12
- 130
- 15 %
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- Om
- adgang
- Konto
- anerkende
- aktioner
- aktivt
- tilføjet
- Derudover
- adresser
- admin
- administratorer
- Reklame
- rådgivning
- Efter
- igen
- AI / ML
- algoritmer
- Alle
- tillade
- tilladt
- tillader
- langs med
- også
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- analyse
- Analytikere
- Analytisk
- analytics
- analysere
- ,
- enhver
- Apache
- Apache Spark
- Anvendelse
- anvendt
- Indløs
- Anvendelse
- arkitekter
- arkitektur
- ER
- områder
- omkring
- AS
- hjælpe
- Assistance
- bistår
- antage
- At
- revision
- myndighed
- autoriseret
- automatisk
- Automation
- til rådighed
- undgå
- AWS
- AWS Cloud9
- AWS CloudFormation
- AWS søformation
- tilbage
- baseret
- BE
- været
- bag
- være
- fordele
- udover
- BEDSTE
- Big
- Big data
- blogs
- pral
- både
- bygge
- men
- by
- CA
- CAN
- stand
- bære
- regnskabsmæssige
- tilfælde
- tilfælde
- katalog
- catering
- vis
- certifikat
- certifikater
- Certificering
- lave om
- ændret
- Ændringer
- Kina
- Vælg
- Rengøring
- Cloud9
- Cluster
- kode
- Kolonne
- Kolonner
- KOM
- kombination
- begå
- Virksomheder
- sammenlignet
- fuldføre
- Compliance
- komponent
- komponenter
- Compute
- computer
- Konceptet
- betingelser
- Adfærd
- trygt
- Konfiguration
- Tilslut
- Konsol
- konstruere
- kontakt
- indeholder
- indeholder
- kontrol
- kontrolleret
- kontrol
- kopiering
- Tilsvarende
- Koste
- Omkostninger
- land
- dækker
- skabe
- oprettet
- skaber
- Oprettelse af
- skaberen
- Nuværende
- skik
- Kunder
- data
- dataadgang
- dataanalyse
- Data Lake
- Dataplatform
- databeskyttelse
- databehandling
- datasikkerhed
- datalager
- Database
- databaser
- Beslutningstagning
- dybt
- Standard
- definere
- Delta
- demonstrere
- demonstrerer
- indsætte
- implementering
- Design
- designe
- detaljer
- Udvikling
- forskellige
- distinkt
- forskelligartede
- dns
- do
- gør
- Er ikke
- domæne
- færdig
- Dont
- ned
- downloade
- drevet
- i løbet af
- hver
- andet
- muliggøre
- aktiveret
- muliggør
- kryptering
- ende
- endpoints
- håndhæve
- Engine (Motor)
- ingeniør
- Engineering
- Motorer
- sikre
- sikrer
- sikring
- Indtast
- Enterprise
- virksomhedskunder
- Hele
- Miljø
- Ether (ETH)
- begivenhed
- Hver
- eksempel
- udførelse
- eksisterer
- erfaring
- erfarne
- ekspertise
- udforskning
- udvider
- ekstern
- faciliterende
- hurtigere
- Feature
- Funktionalitet
- føler sig
- File (Felt)
- Filer
- filtrere
- filtrering
- Filtre
- Fornavn
- Fokus
- fokuserer
- følger
- efter
- følger
- Til
- format
- formation
- fire
- Framework
- rammer
- Gratis
- fra
- Opfylde
- fuld
- funktionalitet
- yderligere
- fremtiden
- Gevinst
- genereret
- regeringsførelse
- reguleret
- indrømme
- stærkt
- gruppe
- Gruppens
- vejledning
- hånd
- Have
- he
- hende
- link.
- Fremhævet
- hans
- historisk
- historie
- Hive
- Hong
- Hong Kong
- hus
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- idé
- identificere
- identificere
- tomgang
- if
- illustrerer
- gennemføre
- Forbedre
- in
- omfatter
- Herunder
- inkorporering
- inkremental
- Indien
- industrien
- informere
- oplysninger
- informeret
- indgang
- indsigt
- integreret
- Integration
- integration
- interaktiv
- interesseret
- interesser
- grænseflade
- interne
- ind
- indviklet
- introduceret
- Introducerer
- spørgsmål
- IT
- ITS
- Job
- Karriere
- rejse
- jpg
- Jupyter Notebook
- Nøgle
- Kong
- sø
- Sprog
- stor
- Efternavn
- lancere
- lanceret
- leder
- LÆR
- niveauer
- ligger
- ligesom
- GRÆNSE
- linjer
- lokale
- placering
- placeringer
- Logge på
- større
- lave
- administrere
- lykkedes
- ledelse
- leder
- mange
- Kan..
- midler
- mekanismer
- møde
- Menu
- Metadata
- måske
- migrere
- minutter
- ML
- ML algoritmer
- modificeret
- mere
- bevægelse
- navn
- navne
- Natural
- Naturligt sprog
- Natural Language Processing
- Naviger
- Navigation
- Behov
- behov
- Ny
- ny funktion
- nyligt
- næste
- NLP
- node
- Bemærk
- notesbog
- notesbøger
- nu
- objekter
- of
- tit
- on
- ONE
- kun
- åbent
- open source
- openssl
- Produktion
- optimal
- Optimer
- Option
- Indstillinger
- or
- ordrer
- organisation
- Andet
- ud
- i løbet af
- par
- brød
- særlig
- især
- lidenskabelige
- betale
- ydeevne
- udfører
- tilladelse
- Tilladelser
- Personligt
- phd
- PIO
- pladsholder
- perron
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- plus
- punkter
- Populær
- besidder
- Indlæg
- praksis
- bevare
- tidligere
- primære
- Beskyttelse af personlige oplysninger
- privilegium
- privilegier
- problemer
- behandle
- forarbejdning
- produktion
- Profil
- Profiler
- bevis
- Bevis for koncept
- beskyttet
- beskyttelse
- give
- giver
- leverer
- offentlige
- formål
- forespørgsler
- Læs
- Læsning
- klar
- virkelige verden
- realtid
- anbefaler
- optage
- opsving
- reducerer
- reducere
- henvise
- refererer
- afspejler
- region
- register
- registreret
- regler
- frigive
- Udgivelser
- relevant
- erstatte
- påkrævet
- Krav
- ressource
- ressourceintensive
- Ressourcer
- resultere
- Resultater
- rettigheder
- roller
- roller
- RÆKKE
- rsa
- regler
- Kør
- kører
- sagemaker
- samme
- Gem
- Sektion
- sikker
- Sikret
- sikkerhed
- se
- Søg
- Vælg
- senior
- følsom
- server
- Serverless
- Tjenester
- Session
- sæt
- sæt
- indstillinger
- setup
- hun
- underskrive
- betydeligt
- lignende
- Simpelt
- forenkler
- forenkle
- siden
- Snapshot
- So
- Software
- softwareudvikling
- løsninger
- Løsninger
- SOLVE
- nogle
- Kilde
- Spark
- specialist
- specialiseret
- SQL
- stable
- Stage
- starte
- påbegyndt
- Starter
- udsagn
- Steps
- opbevaring
- forhandler
- Strategi
- String
- Studio
- indsende
- undernet
- succes
- sådan
- RESUMÉ
- support
- Understøtter
- sikker
- syntaks
- Systemer
- bord
- TAG
- tager
- Teknisk
- teknikker
- skabelon
- terminal
- at
- The Source
- deres
- Them
- derefter
- Der.
- Disse
- de
- denne
- tre
- Gennem
- tid
- tidsrejser
- tidslinje
- til
- Sporing
- transaktion
- transaktionsbeslutning
- Transformation
- transit
- rejse
- sand
- betroet
- Ts
- to
- typen
- typer
- ui
- under
- Uventet
- ukendt
- oplåsning
- Opdatering
- opdateret
- opretholdelsen
- uploadet
- URI
- brug
- brug tilfælde
- anvendte
- Bruger
- brugere
- ved brug af
- validerer
- værdi
- forskellige
- udgave
- via
- synlighed
- bind
- Warehouse
- Warehousing
- we
- web
- webservices
- hvornår
- ud fra følgende betragtninger
- som
- mens
- WHO
- vilje
- med
- inden for
- arbejdede
- arbejder
- skriver
- år
- dig
- Din
- zephyrnet
- nul
- Zip