I dag stiller vi en ny kapacitet til rådighed AWS Lim Datakatalog der tillader generering af statistikker på kolonneniveau for AWS Glue-tabeller. Disse statistikker er nu integreret med de omkostningsbaserede optimeringsværktøjer (CBO). Amazonas Athena og Amazon Rødforskydningsspektrum, hvilket resulterer i forbedret forespørgselsydeevne og potentielle omkostningsbesparelser.
Datasøer er designet til at gemme enorme mængder af rå, ustrukturerede eller semistrukturerede data til en lav pris, og organisationer deler disse datasæt på tværs af flere afdelinger og teams. Forespørgslerne på disse store datasæt læser enorme mængder data og kan udføre komplekse joinoperationer på flere datasæt. Da vi talte med vores kunder, lærte vi, at et af de udfordrende aspekter ved datasøens ydeevne er, hvordan man kan optimere disse analyseforespørgsler til at udføre hurtigere.
Optimeringen af datasøens ydeevne er især vigtig for forespørgsler med flere joinforbindelser, og det er her, omkostningsbaserede optimeringsværktøjer hjælper mest. For at CBO kan fungere, skal kolonnestatistik indsamles og opdateres baseret på ændringer i dataene. Vi lancerer muligheden for at generere statistikker på kolonneniveau såsom antal distinkte, antal nuller, max og min på filer såsom Parquet, ORC, JSON, Amazon ION, CSV, XML på AWS Glue-tabeller. Med denne lancering har kunderne nu en integreret end-to-end oplevelse, hvor statistik om Glue-tabeller indsamles og gemmes i AWS Glue Catalog og gøres tilgængelig for analysetjenester for forbedret forespørgselsplanlægning og -udførelse.
Ved at bruge disse statistikker forbedrer omkostningsbaserede optimeringsprogrammer forespørgselskørselsplaner og øger ydeevnen af forespørgsler, der køres i Amazon Athena og Amazon Redshift Spectrum. For eksempel kan CBO bruge kolonnestatistikker såsom antal forskellige værdier og antal nuller til at forbedre rækkeforudsigelse. Rækkeforudsigelse er antallet af rækker fra en tabel, der vil blive returneret af et bestemt trin under forespørgselsplanlægningsfasen. Jo mere nøjagtige rækkeforudsigelserne er, desto mere effektive er trinene til udførelse af forespørgsler. Dette fører til hurtigere udførelse af forespørgsler og potentielt reducerede omkostninger. Nogle af de specifikke optimeringer, som CBO kan anvende, inkluderer sammenføjningsomlægning og push-down af aggregeringer baseret på den tilgængelige statistik for hver tabel og kolonne.
Til kunder, der bruger data mesh med AWS søformation tilladelser, er tabeller fra forskellige dataproducenter katalogiseret i de centraliserede styringskonti. Når de genererer statistik om tabeller på centraliseret katalog og deler disse tabeller med forbrugere, vil forespørgsler på disse tabeller i forbrugerkonti automatisk se forbedringer af forespørgselsydeevnen. I dette indlæg vil vi demonstrere evnen til AWS Glue Data Catalog til at generere kolonnestatistikker til vores eksempeltabeller.
Løsningsoversigt
For at demonstrere effektiviteten af denne kapacitet anvender vi industristandarden TPC-DS 3 TB datasæt gemt i en Amazon Simple Storage Service (Amazon S3) offentlig spand. Vi sammenligner forespørgselsydeevnen før og efter generering af kolonnestatistik for tabellerne ved at køre forespørgsler i Amazon Athena og Amazon Redshift Spectrum. Vi leverer forespørgsler, som vi brugte i dette indlæg, og vi opfordrer til at prøve dine egne forespørgsler efter arbejdsgangen som illustreret i de følgende detaljer.
Arbejdsgangen består af følgende trin på højt niveau:
- Katalogisering af Amazon S3 Bucket: Brug AWS Glue Crawler til at gennemgå den udpegede Amazon S3-spand, udtrække metadata og problemfrit gemme dem i AWS Glue-datakataloget. Vi forespørger disse tabeller ved hjælp af Amazon Athena og Amazon Redshift Spectrum.
- Generering af kolonnestatistik: Anvend de forbedrede funktioner i AWS Glue Data Catalog til at generere omfattende kolonnestatistik for de gennemgåede data og derved give værdifuld indsigt i datasættet.
- Forespørgsel med Amazon Athena og Amazon Redshift Spectrum: Evaluer virkningen af kolonnestatistikker på forespørgselsydeevne ved at bruge Amazon Athena og Amazon Redshift Spectrum til at udføre forespørgsler på datasættet.
Følgende diagram illustrerer løsningsarkitekturen.
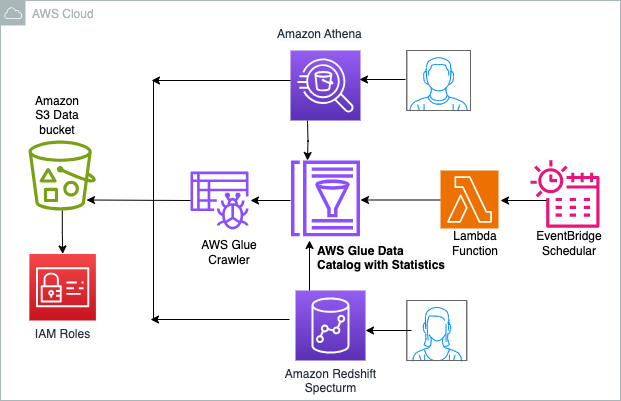
Går igennem
For at implementere løsningen gennemfører vi følgende trin:
- Opsæt ressourcer med AWS CloudFormation.
- Kør AWS Glue Crawler på den offentlige Amazon S3-bøtte for at vise 3TB TPC-DS-datasættet.
- Kør forespørgsler på Amazon Athena og Amazon Redshift, og noter forespørgselsvarigheden
- Generer statistik for AWS Glue Data Catalogue-tabeller
- Kør forespørgsler på Amazon Athena og Amazon Redshift, og sammenlign forespørgselsvarigheden med tidligere kørsel
- Valgfrit: Planlæg AWS Glue-søjlestatistikjob ved hjælp af AWS Lambda og Amazon EventBridge Scheduler
Konfigurer ressourcer med AWS CloudFormation
Dette indlæg indeholder en AWS CloudFormation skabelon til hurtig opsætning. Du kan gennemgå og tilpasse den, så den passer til dine behov. Skabelonen genererer følgende ressourcer:
- En Amazon Virtual Private Cloud (Amazon VPC), offentligt undernet, private undernet og rutetabeller.
- En Amazon Redshift-serverløs arbejdsgruppe og navneområde.
- En AWS Glue-crawler til at gennemgå den offentlige Amazon S3-spand og oprette en tabel til Glue Data Catalog for TPC-DS-datasættet
- AWS Glue katalogdatabaser og tabeller
- En Amazon S3-spand til at opbevare athena-resultater.
- AWS identitets- og adgangsstyring (AWS IAM) brugere og politikker.
- AWS Lambda og Amazon Event Bridge-planlægger for at planlægge AWS Glue Column-statistikker
For at starte AWS CloudFormation-stakken skal du udføre følgende trin:
Bemærk: AWS Glue-datakatalogtabellerne genereres ved hjælp af den offentlige bucket s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/, vært i us-east-1 område. Hvis du har til hensigt at implementere denne AWS CloudFormation-skabelon i en anden region, er det nødvendigt enten at kopiere dataene til den tilsvarende region eller dele dataene inden for din implementerede region, for at de er tilgængelige fra Amazon Redshift.
- Log ind på AWS Management Console som AWS Identity and Access Management (AWS IAM) administrator.
- Vælg Start stak for at implementere en AWS CloudFormation-skabelon.

- Vælg Næste.
- På den næste side skal du beholde alle muligheder som standard eller foretage passende ændringer baseret på dit valg Næste.
- Gennemgå detaljerne på den sidste side, og vælg Jeg anerkender, at AWS CloudFormation kan skabe IAM-ressourcer.
- Vælg Opret.
Denne stak kan tage omkring 10 minutter at fuldføre, hvorefter du kan se den installerede stak på AWS CloudFormation-konsollen.
Kør AWS Glue Crawlers oprettet af AWS CloudFormation-stakken
For at køre dine webcrawlere skal du udføre følgende trin:
- På AWS Lim-konsollen til AWS limkonsol, skal du vælge Crawlere under Datakatalog i navigationsruden.
- Find og kør to crawlere
tpcdsdb-without-stats,tpcdsdb-with-stats. Det kan tage et par minutter at fuldføre.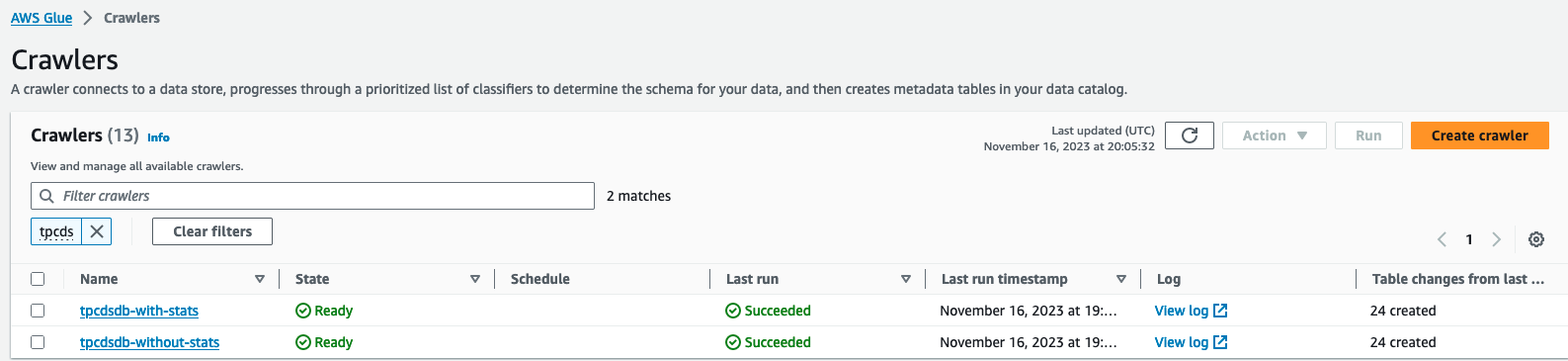
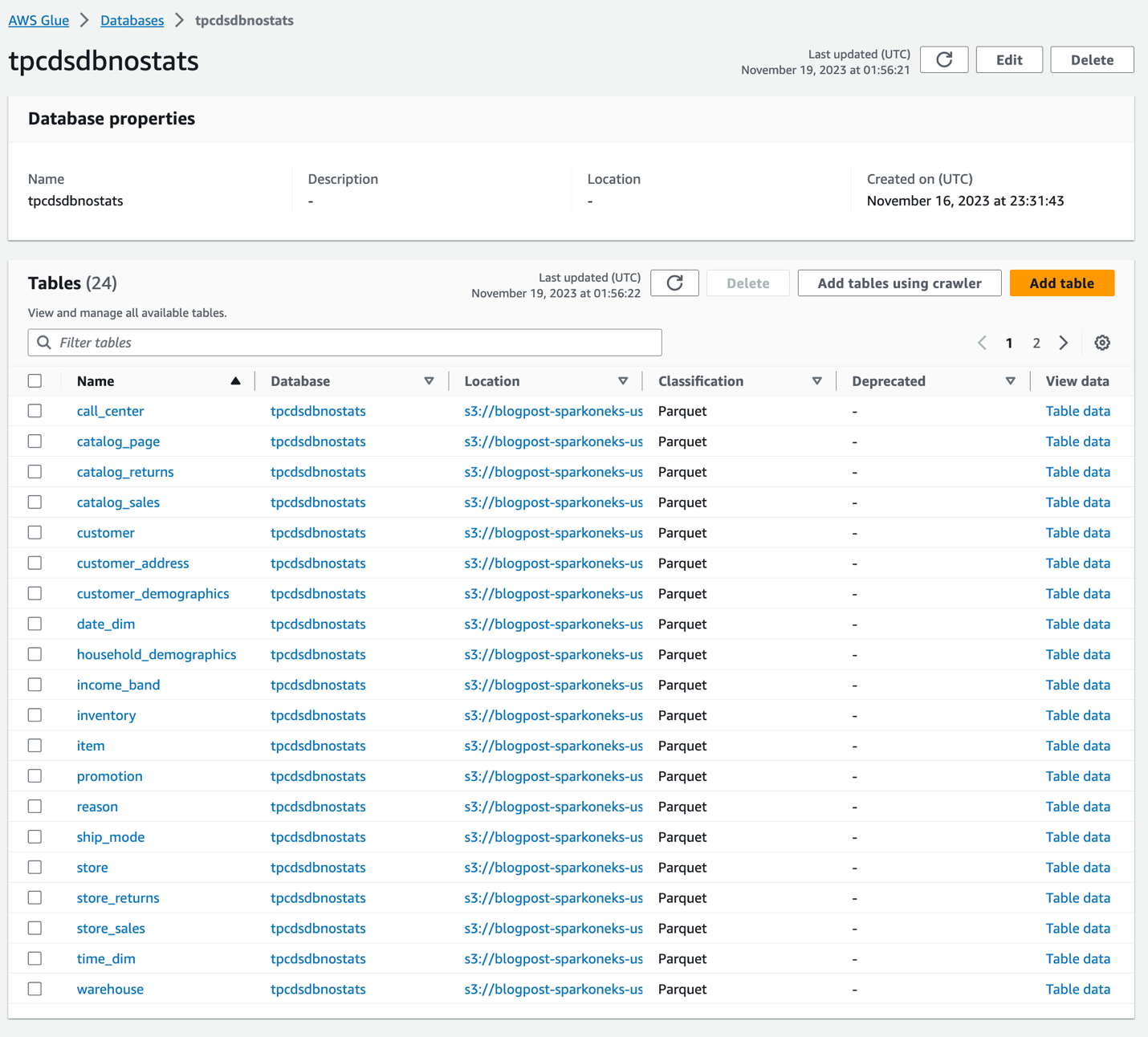
Når crawleren er fuldført, vil den skabe to identiske databaser tpcdsdbnostats , tpcdsdbwithstats. Bordene i tpcdsdbnostats har ingen statistikker, og vi bruger dem som reference. Vi genererer statistik på tabeller i tpcdsdbwithstats. Bekræft venligst, at du har disse to databaser og underliggende tabeller fra AWS Glue Console. tpcdsdbnostats-databasen vil se ud som nedenfor. På nuværende tidspunkt er der ingen statistik genereret på disse tabeller.
Kør den leverede forespørgsel ved hjælp af Amazon Athena på tabeller uden statistik
For at køre din forespørgsel i Amazon Athena på tabeller uden statistik skal du udføre følgende trin:
- Download athena-forespørgsler fra her.
- På Amazonas Athena konsol, vælg den angivne forespørgsel en ad gangen for tabeller i databasen
tpcdsdbnostats. - Kør forespørgslen og noter ned Kørselstid for hver forespørgsel.

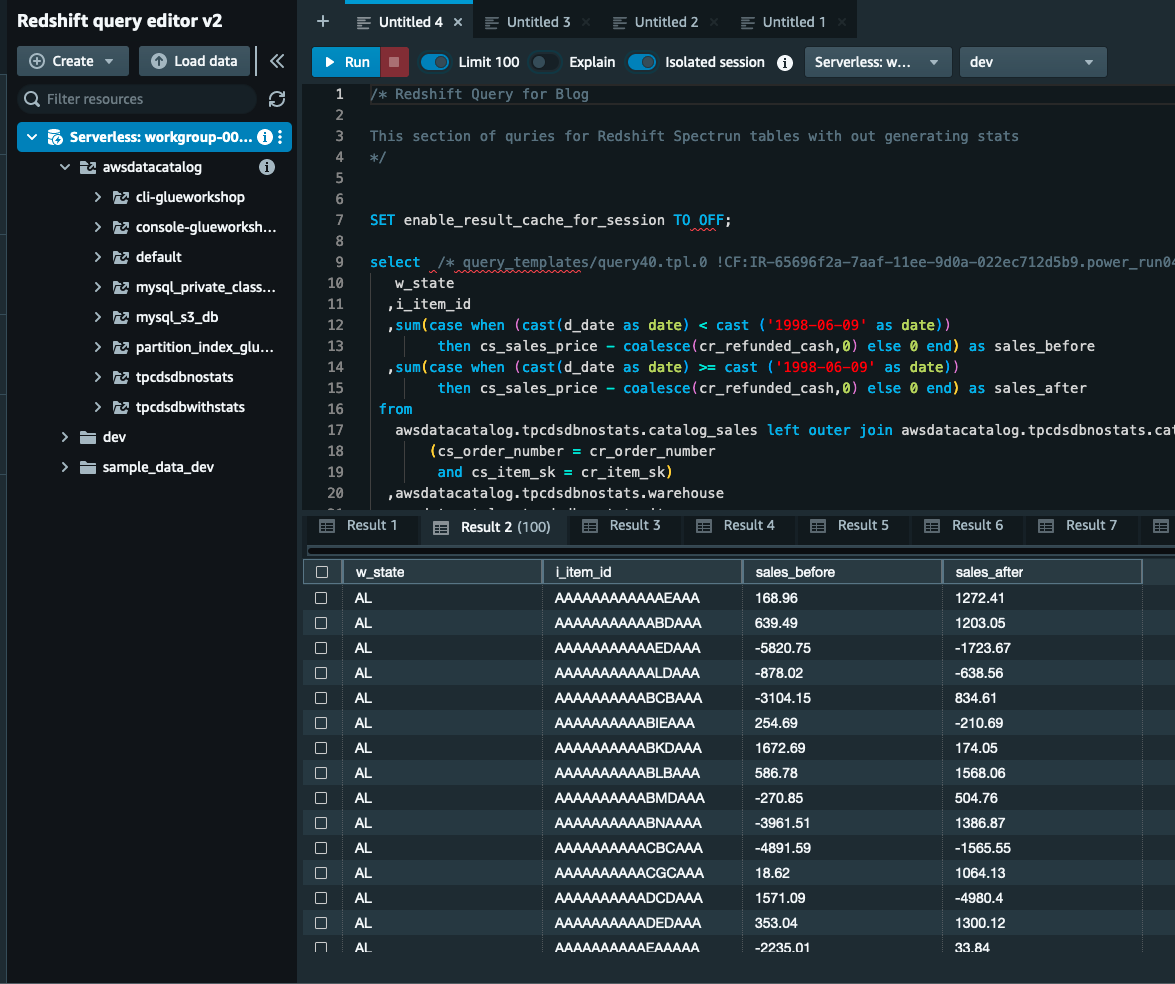
Kør den leverede forespørgsel ved hjælp af Amazon Redshift Spectrum på tabeller uden statistik
For at køre din forespørgsel i Amazon Redshift skal du udføre følgende trin:
- Download Amazon Redshift-forespørgsler fra link..
- På Redshift forespørgselseditor v2, udføre Redshift Query for tabeller uden statistik sektion fra den downloadede forespørgsel.
- Kør forespørgslen, og noter forespørgselsudførelsen af hver forespørgsel.
Generer statistik om AWS Glue Catalog-tabeller
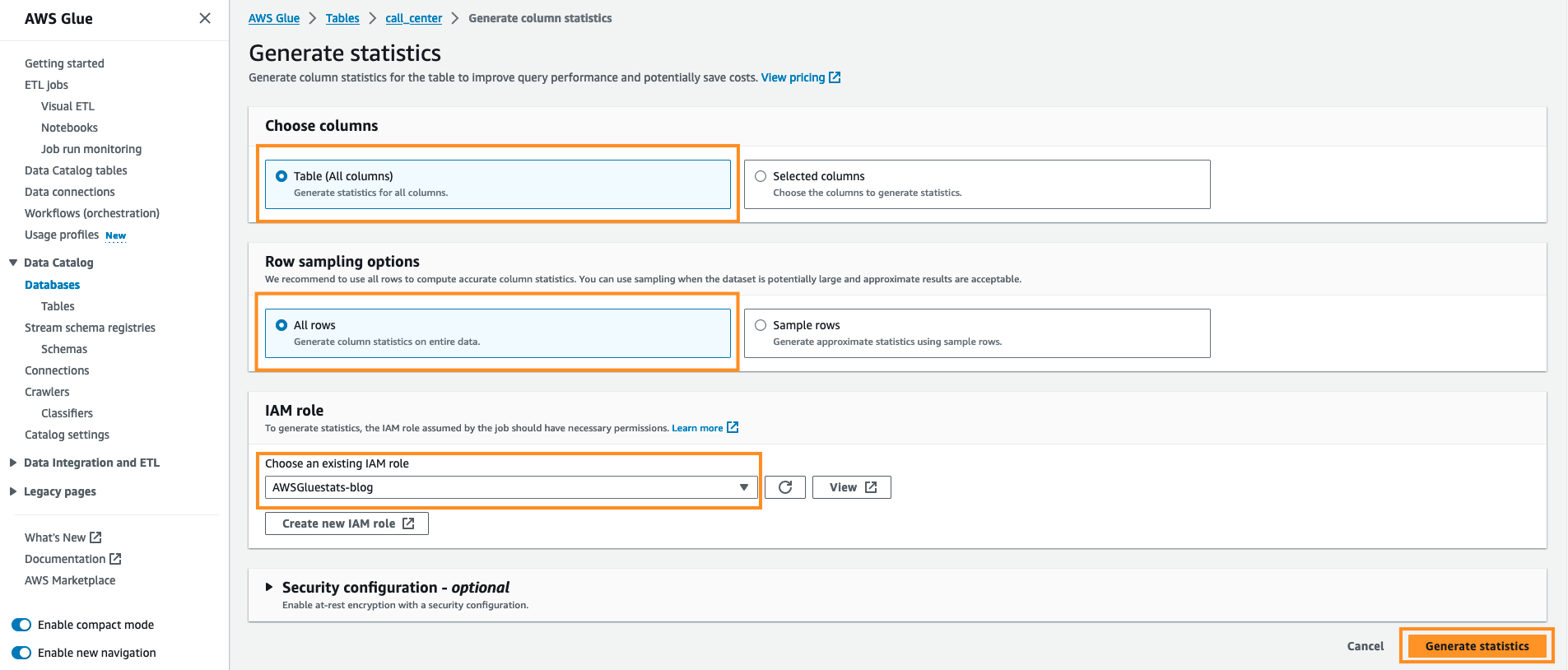
For at generere statistik om AWS Glue Catalog-tabeller skal du udføre følgende trin:
- Naviger til AWS limkonsol og vælg databaserne under Datakatalog.
- Klik på
tpcdsdbwithstatsdatabasen, og den vil vise alle de tilgængelige tabeller. - Vælg en af disse tabeller (f.eks.
call_center). - Gå til Kolonnestatistik – ny fanebladet og vælg Generer statistik.
- Behold standardindstillingen. Under Vælg kolonner holde Tabel (alle kolonner) og Under Indstillinger for rækkeprøveudtagning Holde Alle rækker, under IAM rolle vælge AWSGluestats-blog og vælg Generer statistik.
Du vil være i stand til at se status for statistikgenereringen, som er vist i følgende illustration:

Efter at have genereret statistik om AWS Glue Catalog-tabeller, bør du være i stand til at se detaljerede kolonnestatistikker for denne tabel:
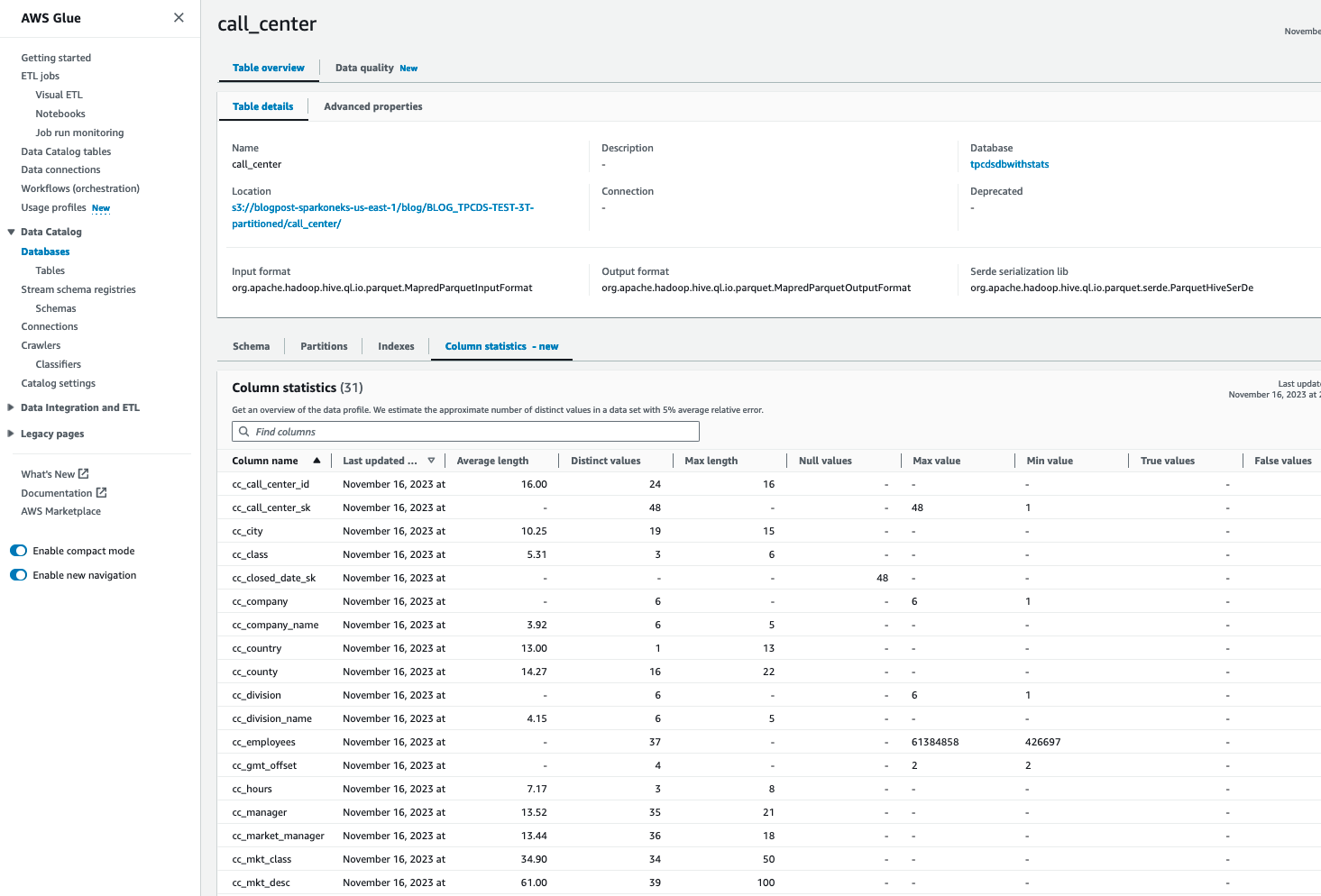
Gentag trin 2-5 for at generere statistik for alle nødvendige tabeller, som f.eks catalog_sales, catalog_returns, warehouse, item, date_dim, store_sales, customer, customer_address, web_sales, time_dim, ship_mode, web_site, web_returns. Alternativt kan du følge "Planlæg AWS Glue Statistics Runs” sektion nær slutningen af denne blog for at generere statistik for alle tabeller. Når det er gjort, skal du vurdere forespørgselsydeevne for hver forespørgsel.
Kør den leverede forespørgsel ved hjælp af Athena Console på statistiktabeller
- På Amazonas Athena konsol, udføre Athena-forespørgsel til tabeller med statistik sektion fra den downloadede forespørgsel.
- Kør og noter forespørgselsudførelsen af hver forespørgsel.
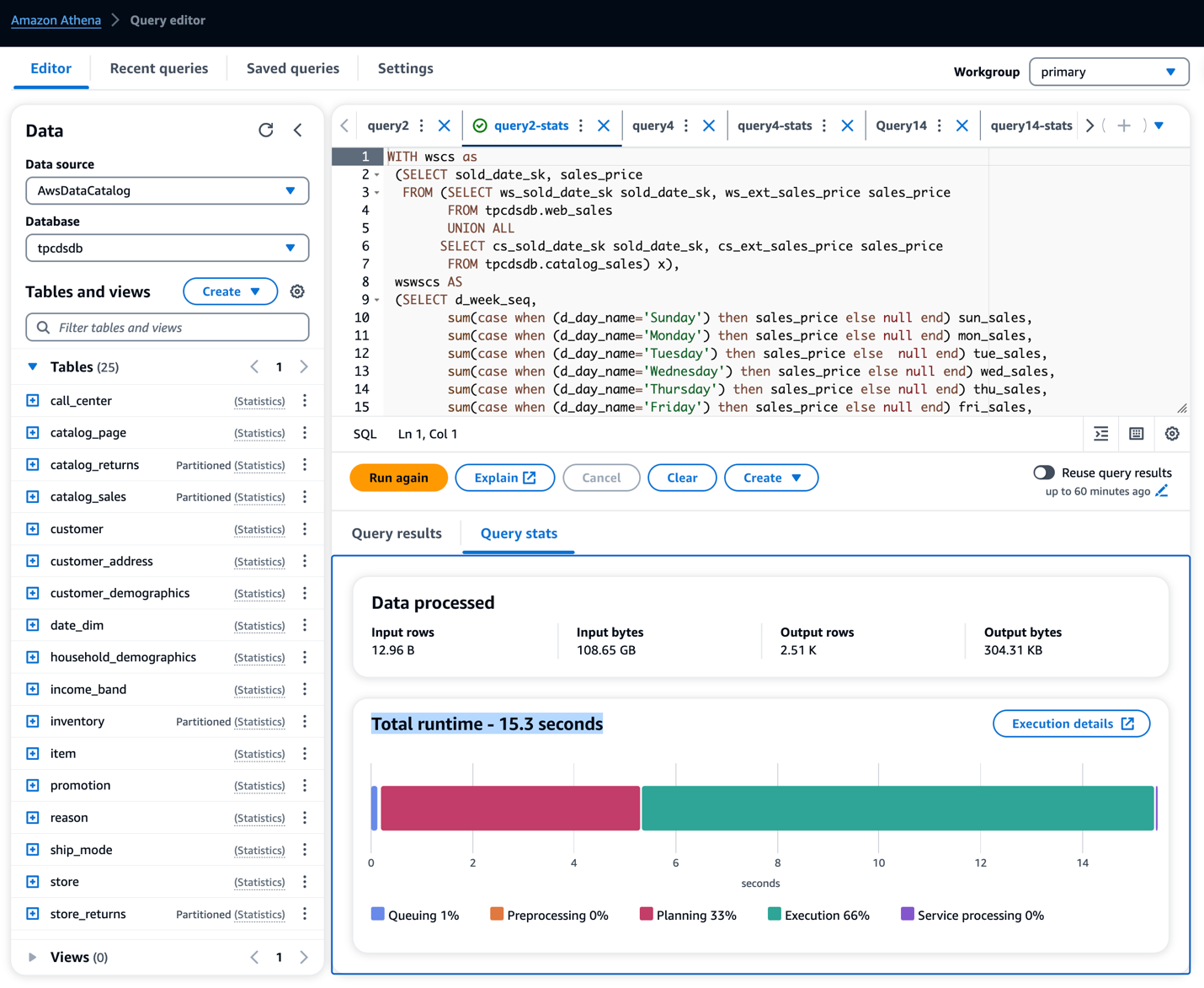
I vores prøvekørsel af forespørgslerne på tabellerne observerede vi forespørgselsudførelsestiden i henhold til nedenstående tabel. Vi så en klar forbedring i forespørgselsydeevnen, varierende fra 13 til 55 %.
Athena forespørgselstid forbedring
| TPC-DS 3T-forespørgsler | uden limstatistik (sek.) | med limstatistik (sek.) | præstationsforbedring (%) |
| Forespørgsel 2 | 33.62 | 15.17 | 55 % |
| Forespørgsel 4 | 132.11 | 72.94 | 45 % |
| Forespørgsel 14 | 134.77 | 91.48 | 32 % |
| Forespørgsel 28 | 55.99 | 39.36 | 30 % |
| Forespørgsel 38 | 29.32 | 25.58 | 13 % |
Kør den angivne forespørgsel ved hjælp af Amazon Redshift Spectrum på statistiktabeller
- På Amazonas Redshift forespørgselseditor v2, udføre Redshift Query for tabeller med statistik sektion fra den downloadede forespørgsel.
- Kør forespørgslen, og noter forespørgselsudførelsen af hver forespørgsel.
I vores prøvekørsel af forespørgslerne på tabellerne observerede vi forespørgselsudførelsestiden i henhold til nedenstående tabel. Vi så en klar forbedring i forespørgselsydeevnen, varierende fra 13 til 89 %.
Amazon Redshift Spectrum forbedring af forespørgselstid
| TPC-DS 3T-forespørgsler | uden limstatistik (sek.) | med limstatistik (sek.) | præstationsforbedring (%) |
| Forespørgsel 40 | 124.156 | 13.12 | 89 % |
| Forespørgsel 60 | 29.52 | 16.97 | 42 % |
| Forespørgsel 66 | 18.914 | 16.39 | 13 % |
| Forespørgsel 95 | 308.806 | 200 | 35 % |
| Forespørgsel 99 | 20.064 | 16 | 20 % |
Planlæg AWS Lim statistik Kørsler
I dette segment af indlægget guider vi dig gennem trinene til planlægning af AWS Glue-søjlestatistikker ved hjælp af AWS Lambda og Amazon Eventbridge Planlægger. For at strømline denne proces blev der oprettet en AWS Lambda-funktion og en Amazon EventBridge-planlægger som en del af CloudFormations stak-implementeringen.
- AWS Lambda funktion opsætning:
Til at begynde med bruger vi en AWS Lambda-funktion til at udløse udførelsen af AWS Glue-søjlestatistikjobbet. AWS Lambda-funktionen påberåber sig start_column_statistics_task_run API gennem boto3 (AWS SDK for Python) biblioteket. Dette danner grundlaget for automatisering af kolonnestatistikopdateringen.
Lad os udforske AWS Lambda-funktionen:
-
- Gå til AWS Lim Lambda konsol.
- Type Funktioner og lokaliser
GlueTableStatisticsFunctionv1. - For en klarere forståelse af AWS Lambda-funktionen anbefaler vi at gennemgå koden i Kode afsnit og undersøgelse af miljøvariablerne under Konfiguration.
- Amazon EventBridge-planlægningskonfiguration
Det næste trin involverer planlægning af AWS Lambda-funktionsindkaldelse ved hjælp af Amazon EventBridge Scheduler. Planlæggeren er konfigureret til at udløse AWS Lambda-funktionen dagligt på et bestemt tidspunkt – i dette tilfælde 08:00. Dette sikrer, at AWS Glue-søjlestatistikjobbet kører på en regelmæssig og forudsigelig basis.
Lad os nu undersøge, hvordan du kan opdatere tidsplanen:
Gøre rent
For at undgå uønskede debiteringer på din AWS-konto skal du slette AWS-ressourcerne:
- Log ind på AWS CloudFormation-konsollen som den AWS IAM-administrator, der bruges til at oprette AWS CloudFormation-stakken.
- Slet den AWS CloudFormation-stak, du har oprettet.
Konklusion
I dette indlæg viste vi dig, hvordan du kan bruge AWS Glue Data Katalog at generere statistik på kolonneniveau for AWS Lim borde. Disse statistikker er nu integreret med omkostningsbaseret optimizer fra Amazonas Athena og Amazon Rødforskydningsspektrum, hvilket resulterer i forbedret forespørgselsydeevne og potentielle omkostningsbesparelser. Henvise til Docs for support til Glue Catalog Statistics på tværs af forskellige AWS-analysetjenester.
Hvis du har spørgsmål eller forslag, så send dem i kommentarfeltet.
Om forfatterne
 Sandeep Adwankar er Senior Technical Product Manager hos AWS. Baseret i California Bay-området arbejder han med kunder over hele kloden for at omsætte forretningsmæssige og tekniske krav til produkter, der sætter kunder i stand til at forbedre, hvordan de administrerer, sikrer og får adgang til data.
Sandeep Adwankar er Senior Technical Product Manager hos AWS. Baseret i California Bay-området arbejder han med kunder over hele kloden for at omsætte forretningsmæssige og tekniske krav til produkter, der sætter kunder i stand til at forbedre, hvordan de administrerer, sikrer og får adgang til data.
 Navnit Shukla fungerer som AWS Specialist Solution Architect med fokus på Analytics. Han besidder en stærk entusiasme for at hjælpe kunder med at opdage værdifuld indsigt fra deres data. Gennem sin ekspertise konstruerer han innovative løsninger, der sætter virksomheder i stand til at nå frem til informerede, datadrevne valg. Navnit Shukla er især den dygtige forfatter til bogen med titlen Data Wrangling on AWS. Han kan nås via LinkedIn.
Navnit Shukla fungerer som AWS Specialist Solution Architect med fokus på Analytics. Han besidder en stærk entusiasme for at hjælpe kunder med at opdage værdifuld indsigt fra deres data. Gennem sin ekspertise konstruerer han innovative løsninger, der sætter virksomheder i stand til at nå frem til informerede, datadrevne valg. Navnit Shukla er især den dygtige forfatter til bogen med titlen Data Wrangling on AWS. Han kan nås via LinkedIn.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/enhance-query-performance-using-aws-glue-data-catalog-column-level-statistics/
- :er
- :hvor
- $OP
- 08
- 1
- 10
- 100
- 13
- 264
- 30
- a
- I stand
- adgang
- adgangsstyring
- tilgængelig
- gennemført
- Konto
- Konti
- præcis
- anerkende
- tværs
- Efter
- Alle
- tillader
- Amazon
- Amazonas Athena
- Amazon Web Services
- beløb
- an
- Analytisk
- analytics
- ,
- enhver
- api
- passende
- arkitektur
- ER
- OMRÅDE
- omkring
- AS
- udseende
- vurdere
- bistår
- At
- forfatter
- automatisk
- Automatisering
- til rådighed
- undgå
- AWS
- AWS CloudFormation
- AWS Lim
- AWS Lambda
- baseret
- grundlag
- Bugt
- BE
- før
- begynde
- jf. nedenstående
- Blog
- bog
- boosts
- BRIDGE
- virksomhed
- virksomheder
- by
- california
- CAN
- kapaciteter
- kapacitet
- tilfælde
- katalog
- centraliseret
- vis
- udfordrende
- Ændringer
- afgifter
- valg
- Vælg
- klar
- klarere
- kunder
- Cloud
- kode
- Kolonne
- Kolonner
- kommentarer
- sammenligne
- fuldføre
- Fuldender
- komplekse
- omfattende
- konfigureret
- består
- Konsol
- forbruger
- Forbrugere
- Tilsvarende
- Koste
- omkostningsbesparelser
- Omkostninger
- crawler
- skabe
- oprettet
- Oprettelse af
- Kunder
- tilpasse
- dagligt
- data
- Data Lake
- datastyret
- Database
- databaser
- datasæt
- Standard
- demonstrere
- afdelinger
- indsætte
- indsat
- implementering
- udpeget
- konstrueret
- detaljeret
- detaljer
- forskellige
- opdage
- distinkt
- færdig
- ned
- varighed
- i løbet af
- e
- hver
- editor
- effektivitet
- effektiv
- enten
- bemyndige
- muliggøre
- tilskynde
- ende
- ende til ende
- forbedre
- forbedret
- sikrer
- entusiasme
- Miljø
- især
- Ether (ETH)
- evaluere
- begivenhed
- Undersøgelse
- eksempel
- udføre
- udførelse
- erfaring
- ekspertise
- udforske
- hurtigere
- få
- Filer
- endelige
- Fokus
- følger
- efter
- Til
- fra
- funktion
- generere
- genereret
- genererer
- generere
- generation
- kloden
- regeringsførelse
- fundament
- vejlede
- Have
- he
- hjælper
- Høj
- hans
- hostede
- Hvordan
- How To
- HTML
- http
- HTTPS
- IAM
- identisk
- Identity
- identitets- og adgangsstyring
- if
- illustrerer
- KIMOs Succeshistorier
- gennemføre
- vigtigt
- Forbedre
- forbedret
- forbedringer
- forbedrer
- in
- omfatter
- omfatter
- informeret
- innovativ
- indsigt
- integreret
- hensigt
- ind
- påberåber sig
- involverer
- IT
- Job
- Karriere
- deltage
- Sammenføjninger
- jpg
- json
- Holde
- sø
- søer
- stor
- lancere
- lancering
- Leads
- lærte
- Niveau
- Bibliotek
- ligesom
- Liste
- Se
- ligner
- Lav
- lavet
- lave
- Making
- administrere
- ledelse
- leder
- max
- Kan..
- Metadata
- måske
- minut
- minutter
- mere
- mere effektiv
- mest
- flere
- Navigation
- I nærheden af
- nødvendig
- Behov
- behov
- Ny
- næste
- ingen
- især
- Bemærk
- nu
- nummer
- observeret
- of
- on
- engang
- ONE
- Produktion
- optimering
- Optimer
- Option
- or
- ordrer
- organisationer
- vores
- ud
- egen
- side
- brød
- del
- per
- udføre
- ydeevne
- Tilladelser
- planlægning
- planer
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- pm
- politikker
- besidder
- Indlæg
- potentiale
- potentielt
- Forudsigelig
- forudsigelse
- Forudsigelser
- tidligere
- private
- behandle
- Producenter
- Produkt
- produktchef
- Produkter
- forudsat
- leverer
- offentlige
- Python
- forespørgsler
- Spørgsmål
- Hurtig
- spænder
- Raw
- nået
- Læs
- anbefaler
- Reduceret
- henvise
- henvisningen
- region
- fast
- krav
- Krav
- Ressourcer
- resultere
- resulterer
- gennemgå
- gennemgå
- roller
- R
- RÆKKE
- Kør
- kører
- løber
- Besparelser
- så
- planlægge
- planlægning
- SDK
- problemfrit
- SEK
- Sektion
- sikker
- se
- segment
- Vælg
- senior
- Serverless
- tjener
- tjeneste
- Tjenester
- sæt
- setup
- Del
- bør
- viste
- vist
- Simpelt
- løsninger
- Løsninger
- nogle
- specialist
- specifikke
- Spectrum
- SQL
- stable
- Stage
- statistik
- statistik
- Status
- Trin
- Steps
- opbevaring
- butik
- opbevaret
- strømline
- stærk
- indsende
- subnet
- undernet
- Succesfuld
- sådan
- Dragt
- support
- bord
- Tag
- taler
- hold
- Teknisk
- skabelon
- at
- deres
- Them
- Der.
- derved
- Disse
- de
- denne
- dem
- Gennem
- tid
- titlen
- til
- Oversætte
- udløse
- prøv
- to
- under
- underliggende
- forståelse
- uønsket
- Opdatering
- opdateret
- brug
- anvendte
- brugere
- ved brug af
- udnytte
- Ved hjælp af
- Værdifuld
- Værdier
- forskellige
- Vast
- verificere
- Specifikation
- Virtual
- we
- web
- webservices
- var
- hvornår
- som
- vilje
- med
- inden for
- uden
- Arbejde
- workflow
- arbejdsgruppe
- virker
- ville
- XML
- yaml
- dig
- Din
- zephyrnet