Fabs er begyndt at implementere maskinlæringsmodeller til at bore dybt ind i komplekse processer, der udnytter både stor computerkraft og betydelige fremskridt inden for ML. Alt dette er nødvendigt, efterhånden som dimensionerne krymper og kompleksiteten øges med nye materialer og strukturer, processer og emballagemuligheder, og efterhånden som efterspørgslen efter pålidelighed stiger.
Opbygning af robuste modeller kræver træning af algoritmerne, og vellykket implementering kræver overvågning af anvendelsen og effektiviteten af disse modeller. Men det er ikke så nemt som at trykke på en knap og gå. Det kræver træning/omskoling/krydstræning af forskellige ingeniørdiscipliner - fabriksingeniører, udstyrsingeniører og procesingeniører - at bruge disse modeller til opskriftsstifinding, procesramping, optimering af kritiske dimensioner, forbedring af waferudbytte og værktøj-til-værktøj og kammer-til-kammer-matching.
"Domæneekspertise er helt afgørende for produktiv brug af AI/ML-tilgange," sagde Regina Freed, vicepræsident for AIx-løsninger hos Applied Materials. "Faktisk vil hardware- og procesekspertise - sammen med hybridmodeller baseret på ML og fysik - være den eneste vej til en vellykket implementering af ML."
At arbejde sammen med ML-trænede modeller kræver en forståelse af, hvordan man bruger disse modeller, samt en evne til at evaluere deres effektivitet og robusthed.
"Ingeniører skal tro på, at det kommer til at fungere, og de skal forstå, hvad ML kan og ikke kan," sagde Jon Herlocker, CEO for Tignis. "Det bliver ikke til en maskine og beslutter sig for at overtage fab. Ingeniører kan indstille kontroller på disse modeller for at udvikle tillid. De bruger de samme robuste statistiske metoder til at kvalificere de ML-trænede modeller, som de ville bruge til at kvalificere et traditionelt proceskontrolsystem. De opretter specifikke prøveudtagningsplaner for at måle variabilitet inden for disse planer."
ML åbner også døren til at udforske mere komplekse relationer mellem data på tværs af produktionsflowet. Men der er nogle forbehold.
"Det, der virkelig er forbløffende ved maskinlæringsudviklingen (DL), er brugen af denne utrolige computerkraft, især i GPU'er," bemærkede Ajay Baranwal, direktør for Center for Deep Learning in Electronics Manufacturing (CDLe). "I DL-træning kan et utroligt antal parametre og parameterkombinationer udforskes ved at bruge denne enorme regnekraft. På nogle måder er det, der er sket, at brute force computing kan vinde dagen i disse dage, fordi så meget computerkraft nu er tilgængelig. Men der er en afvejning mellem at udforske store parametre for at udføre komplekse analyser og at begrænse det til enklere modeller. Overtilpasning, skævhed og fortolkning er et par ulemper ved at beholde flere parametre."
Når den er kvalificeret, skal en ML-model, der bruges til fab kontrol, overvåges for at tage højde for drift og andre procesændringer, der kan påvirke forholdet mellem input- og outputdata.
Effektiv anvendelse af en ML-baseret model til udstyr og processtyring kræver mere end blot modeltræning. Det kræver også validering, overvågning og vedligeholdelse.
Pålidelig data og domæneekspertise
Succesfulde ML-trænede modeller er bygget på et fundament af pålidelige data og domæneekspertise. Dernæst kræver reduktion af inputparametre fra de hundreder til tusinder, der er tilgængelige for dem, der virkelig betyder noget, en udforskning af forhold, ofte ved hjælp af fysikbaserede modeller. Sådanne modeller er særligt vigtige for udvikling af procesopskrifter. Kontrol af resultaterne i forhold til fysikbaserede modeller og ingeniørviden sikrer korrekt vejledning af ML-udvikling. Der er også afvejninger ved optimering af flere resultatspecifikationer.
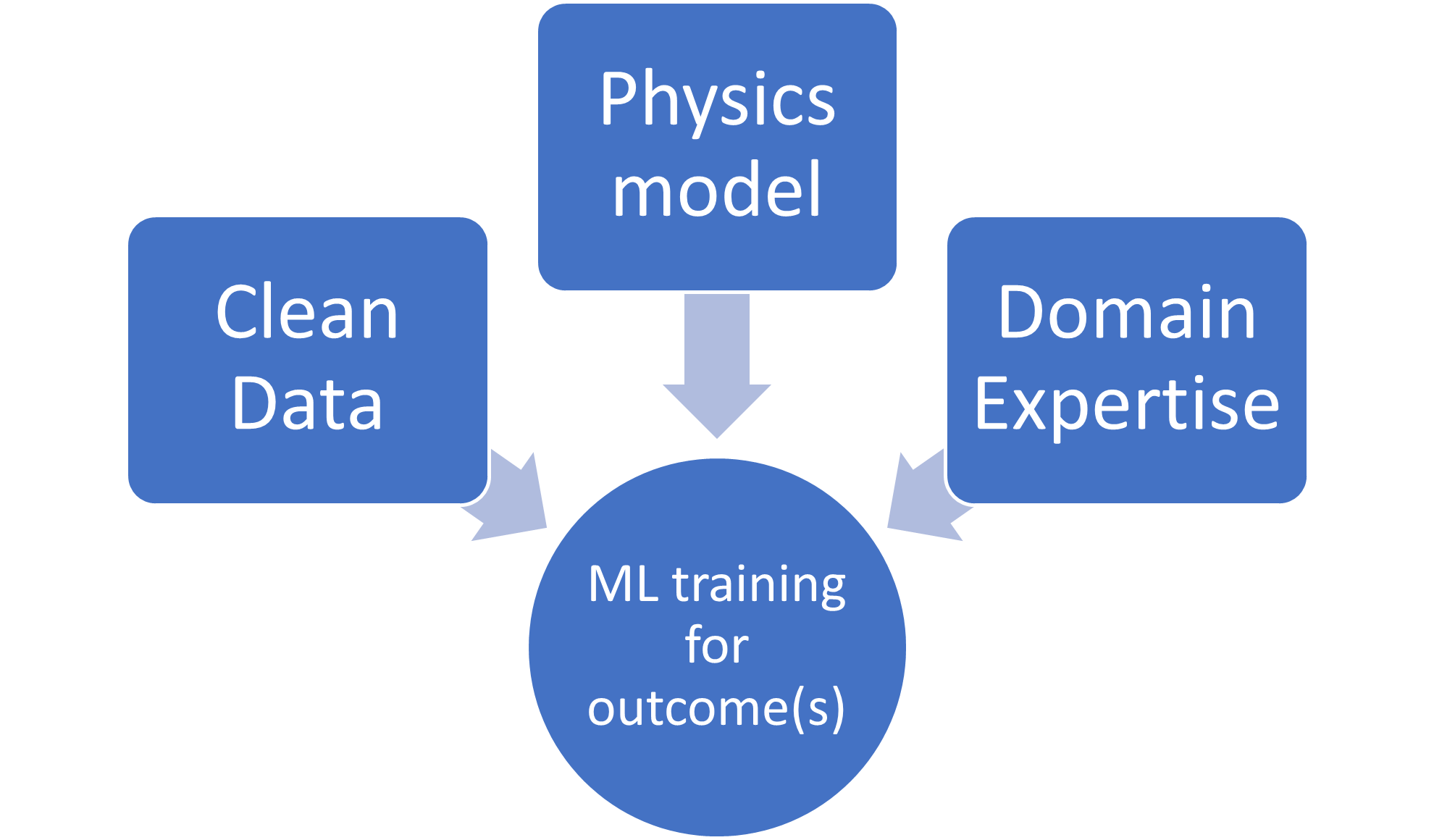
Fig. 1: Nødvendige komponenter til at træne en ML-model til fab-processer. Kilde: A. Meixner/Semiconductor Engineering
Uanset om ingeniører anvender computervision, statistiske modeller eller deep learning-modeller, begynder modelskabelse altid med data. Disse data skal være rene, hvilket betyder fejlfrie og fuldstændige. For optimering på tværs af flere fantastiske procestrin eller feed-forward-applikationer kræver fletning af data fra flere kilder sporbarhed på wafer og/eller die-niveau. Som adskillige brancheeksperter bemærkede, ligger de tunge løft i håndteringen af data. Dette gælder for den indledende modelbygning og for implementeringen i en fabriksindstilling.
Sammen med en konstant strøm af pålidelige data skal fab procesingeniører styre modellen i den rigtige retning. Dette behov er ikke anderledes end i noget andet felt, hvor ML-afledte modeller er skabt.
"I de tidligste stadier er det meget nyttigt at have fageksperter til at øge ML i fabrikkerne, især i procesudviklingsapplikationer," sagde Anjaneya Thakar, seniordirektør for produktlinjeledelse hos Synopsys. "Da modellen bygges ved hjælp af en begrænset mængde data, kan du optimere omkring et forkert optimalt punkt, fordi de har set problemet, før en fagekspert hurtigt kan guide det tilbage. Når først din model er tunet, og du har fået kontrol over din variabilitet, er der mindre behov for emneeksperter til at køre den på daglig basis."
Bare det at lade en algoritme træne en model uden retning er som at have en ny ansættelse i fab.
"I nogle henseender er maskinlæring som menneskelig læring," sagde Tignis' Herlocker. "Hvis du har en junior procesingeniør, er der kun så meget, de kan gøre. Men som ingeniøren lærer, kan de løse mere komplekse problemer. Det samme gælder med ML. Jo mere træning ML-modellen har, jo bedre bliver den. ML model træning er domæneviden. Udfordringen fremad er, hvordan man tager al den domæneviden og transformerer den, så den kan forbruges af ML som 'træning'. I sidste ende er vi nødt til at parre menneskelig intuition og viden med ML for at få de bedste resultater."
Lam Research udforskede den optimale parring af ingeniørens intuition/viden med ML-resultater i et simuleringseksperiment. [1] "Der er et ordsprog blandt ingeniører, at datavidenskab uden domæneviden ikke er meget værd," sagde Keren Kanarik, teknisk administrerende direktør hos Lam Research. "På samme måde vil domæneviden uden datavidenskab ikke sætte dig i stand til at innovere hurtigt nok i den konkurrenceprægede halvlederverden. Lam testede for nylig denne idé ved at skabe et virtuelt spil, der sammenlignede mennesker med AI i udviklingen af en halvlederproces til den laveste pris-til-mål (dvs. det færreste antal eksperimenter). Resultaterne leverede en præskriptiv tilgang til, hvordan man kombinerer domæneekspertise med datavidenskab."
Reducer og prioriter
Den store attraktion ved ML-baserede modeller er deres evne til at forbinde flere inputparametre til ikke-lineære relationer med flere udfaldsparametre. Men for nutidens modeller er de fleste eksperter enige om, at antallet af signifikante inputparametre ofte er i størrelsesordenen 10. Der er flere grunde til denne grænse, herunder optimering for forkerte resultater, forklaring af den trænede model og se sammenhængene.
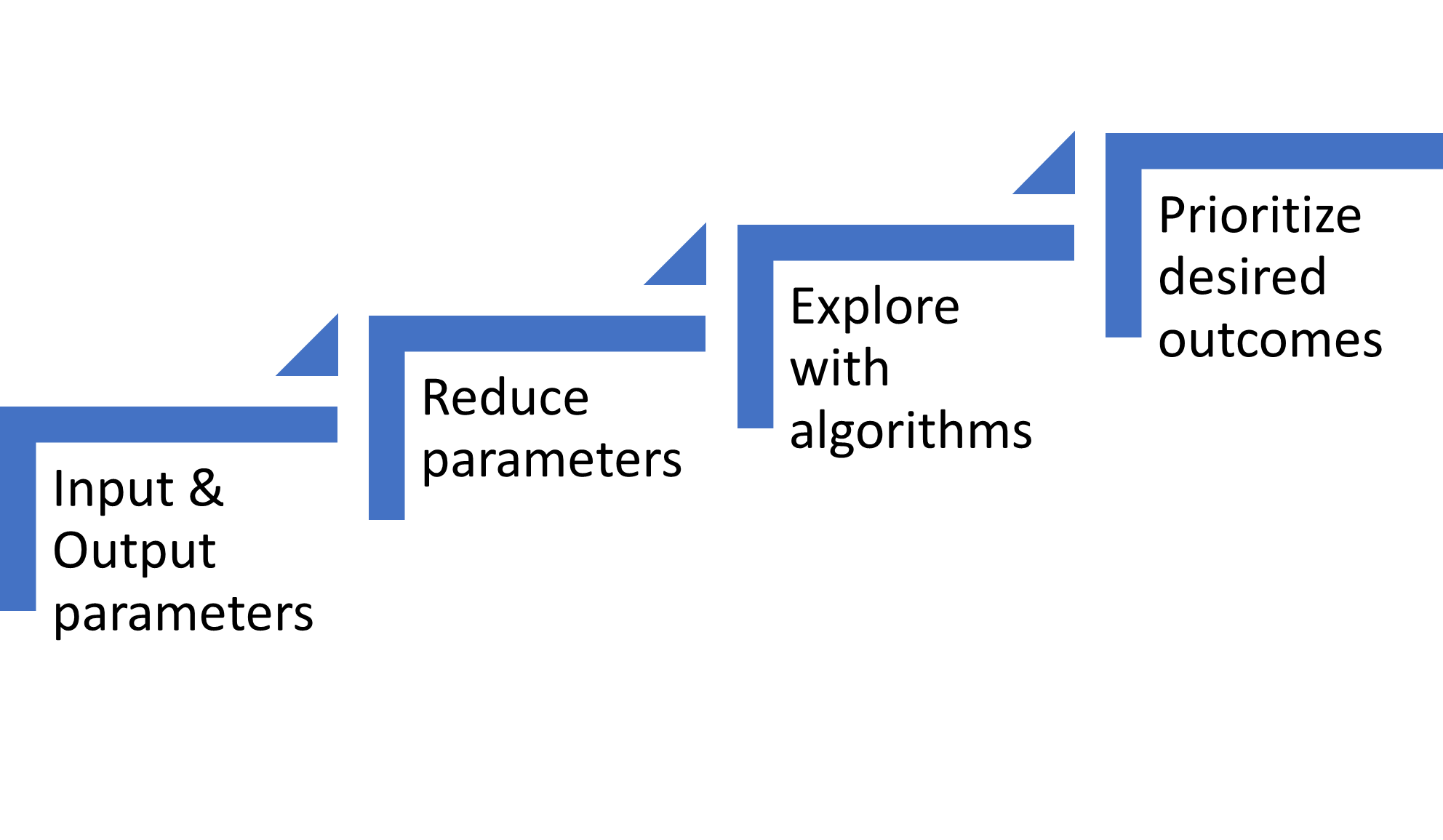
Fig. 2: Machine learning build pipeline til at skabe en model. Kilde: A. Meixner/Semiconductor Engineering
"Nøglen til en vellykket implementering af komplekse algoritmer er visualisering. Du skal levere en kraftfuld visuel repræsentation, der hjælper brugerne med det samme at fortolke og forstå resultaterne – og deres grænser – af algoritmerne. Når det visuelle billede rammer beskueren lige mellem øjnene, kan yield-ingeniører springe i gang,” udtalte Dieter Rathei, CEO for DR Udbytte.
ML træningsalgoritmer kan lettere udforske flere parametre; dog er parameterreduktion et vigtigt skridt i modeludviklingspipelinen.
"På grund af den sorte boks karakter af de fleste ML-modeller, er der nogle gange en frygt for, at brugerne vil finde sig i at korrelere procesydelsen med ugedagen," sagde Meghali Chopra, CEO for Sandbox Semiconductor. “ML er designet til at belyse nøgledatarelationer, men skrald ind er lig med skrald ud. En god ML-modeltilgang og pipeline er designet til at skelne signalet fra støjen. Vi bruger fysikaktiveret AI til at begrænse parameterrummet. Vi investerer også kraftigt i dataforbehandling og dimensionsreduktionsteknikker for at sikre, at de vigtigste parametre bliver belyst for vores brugere."
Belysning af de væsentlige parametre til ingeniører kan leveres på en trinvis måde, først én parameter, derefter to og muligvis tre.
"Vi har to niveauer i vores værktøj," sagde Jeff David, vicepræsident for AI-løsninger hos PDF-løsninger. "Den ene er den univariante forudsigelse. Vi starter med univariant, fordi det er nemt at forstå og visualisere. For eksempel, hvis parameter A er omkring 2.7, og jeg ser flere fejl, når den er under 2.7, så har vi i næste trin en interaktion mellem to parametre. Og så viser vi drill-downs i interaktionen for de to parametre. Men vi stopper ved to, for når man først går til tre og fire, bliver det meget svært at visualisere og udforske.”
Den anden advarsel om antallet af anvendte parametre er forkerte korrelationer.
"For denne type anvendelse (udvikling af ætsningsopskrifter) er processerne så komplekse, at rodårsagsanalyse kan vise, hvorfor modellering af denne kompleksitet virkelig er vigtig," sagde Sandbox Semiconductors Chopra. "Faren ved at modellere så mange parametre er, at du kan finde falske korrelationer, dvs. procesresultatet med ugedagen. Det er det, du vil undgå. Vi investerer massivt i dimensionsreduktion. Og så bruger vi vores forankringsfysikbaserede model, så vi er aldrig for bekymrede for at overkompleksisere problemet, fordi en god modelleringspipeline i det væsentlige vil finde alle de vigtige procesparametre for dig."
Andre er enige om behovet for en modelleringspipeline, der reducerer parametre og finder væsentlige sammenhænge.
"Der er bestemt en grænse i antallet af parametre," sagde PDFs David. "Men du ved ikke for en given use case, før du træner en model med de data, du har, og validerer den. Vores platform giver automatisk vores kunder mulighed for at gøre dette med vores træningspipeline. Vores træningspipeline skaleres for at give vores kunder mulighed for at se de målinger, de skal se på deres trænede modeller på få timer, fra dataindtagelse hele vejen til trænede modeller. Så, hvis de trænede modeller viser værdi, kan brugeren automatisk implementere modellerne med vores ModelOps-platform."
Der er også afvejninger i at afbalancere flere resultater.
"Grundlæggende er det sandt, at der ikke er nogen måde, du kan bygge disse controllere uden at en procesingeniør deltager, fordi der er beslutninger om afvejninger, der skal træffes," sagde Herlocker. "Du forsøger at optimere til mange ting på én gang. For eksempel forsøger du at optimere til CD, men du forsøger også at minimere mængden af energi, du bruger. Der er iboende menneskelige beslutninger, ingeniører træffer om, ’Hvor meget bekymrer jeg mig om proceskvalitet versus energiforbrug versus kemikalieforbrug versus kemiske emissioner?’ Men ML-uddannelse ved ikke, hvilken der er vigtigst. Det er kun ingeniørerne, der gør, så de skal være der.”
Implementer og vedligehold
Når først den er udviklet, skal ML valideres og implementeres i en produktionsindstilling, og den skal vedligeholdes. Dette udføres bedst med en systematisk og pålidelig proces i halvlederfabrikkerne, og det kræver en maskinlæringsoperation (ML Ops) proces/metodeplatform. Dette er blevet standard i ML-applikationer i andre industrier, og er netop nu ved at ske i halvlederindustrien.
Ingeniører udvikler ML-modeller isoleret. Overgangen fra udvikling til produktionsmiljø involverer et sæt praksisser svarende til DevOps for udrulning af softwaresystemer. Når modellen lanceres i produktion, muliggør en ML Ops-platform en forøgelse af automatiseringen af implementeringen og forbedring af modelkvaliteten. [2] Den gælder således for hele ML-modellens livscyklus.
"I det sidste årti eller deromkring har der været masser af spænding omkring, hvordan ML kan tilføre værdi til halvlederfremstilling på tværs af mange use cases," sagde PDFs David. "Men når det bliver tid til at implementere det i produktionen, kæmper folk. Hvordan overvåger du for eksempel, om din trænede model gør, hvad den skal? Hvis ikke, hvad er udvejen? Hvad hvis det er tid til at lave forudsigelser, og dine data ikke er der? Det sker oftere, end vi gerne vil. Hvordan opdager du en drift i de inputdata, som din trænede model stolede på? Hvilke handlinger tager du omkring det? Hvad laver du? ML Ops er dybest set implementeringen af at få alt det her til at køre i produktion, så du rent faktisk kan bruge det."
Derudover bør modellerne have mulighed for genoptræning. "Der har været masser af gennembrud i nye ML-algoritmer, hvoraf mange er deep learning-relaterede. Deep learning er et stort investeringsområde, og som branche er vi i stand til mange ting, der ikke var muligt før, især når det kommer til at arbejde med store modeller. Mange forbedringer inden for modelomdannelsesautomatisering har vist sig at være afgørende for den brede udbredelse af ML-modeller i højvolumenproduktionsmiljøer,” sagde Tignis’ Herlocker.
Et andet aspekt af ML Ops er hurtigere implementering af modeller til lignende forudsigelser, men på forskellige produkter. På grund af produktkarakteristika kan de samme inputparametre resultere i forskellige outputdata. Dette kan også betyde, at en anden træningstilgang er et bedre match til et datasæt. Og det er her, ML pipeline og ML Ops kommer i spil.
"Du vil træne en anden model pr. produkt A, B og C, og du vil gøre det på en automatiseret måde, samt hurtigt implementere hver enkelt af dem," sagde PDFs David. "Måske er tilfældig skov ikke den bedste til det datasæt. Med ML Ops tager du dit datasæt, du skærer det op i stykker, og du implementerer forskellige typer algoritmiske tilgange. De er hyperparametre til det datasæt, der kan valideres i det, der kaldes krydsvalidering. [3] Derefter bygger du modellen ud ved hjælp af din bedste algoritme-tilgang, som så bliver pakket ind i modellen, og derefter implementerer du den til produktion. Det kan være forskelligt fra chip til chip. ML Ops er hårdt tiltrængt i branchen, og jeg hører endda fra kunder, at de ønsker denne ML OPS platform mere end evnen til at træne en model med en algoritme. Årsagen er i sidste ende, at de rent faktisk ønsker at implementere ML i produktionen. Uden en platform til at gøre det, betyder intet andet noget.”
Konklusion
På grund af presset fra økonomi, effektivitet og effektivitet bliver halvlederfabrikanters ingeniørteam nødt til at bruge ML-modeller til at understøtte deres arbejde. ML er dukket op som et middel til at fremskynde opskriftsudvikling, øge gennemløbet og opnå et par procentpoint af udbytte. Med ML's evne til at adressere komplekse interaktioner, der afhænger af rumlige egenskaber og tidsmæssige tilstande, vil fremtidige ML-modeller samoptimere på tværs af procestrin, hvilket accelererer forståelsen af nye kemiske mekanismer og meget mere.
Men som med ethvert værktøj i deres værktøjskasse, skal ingeniører forstå ML's begrænsninger. For at gøre det effektivt har de brug for en robust ML-modelpipeline, der udvikler, validerer, implementerer og overvåger. Og procesingeniører skal stadig lede og lette ansøgningen.
"En af de ting, vi fandt, er, at nutidens ML-løsninger har brug for en procesingeniør, softwareingeniør, dataforskere og en it-person," sagde Herlocker. "Som en del af vores vision er den kritiske person procesingeniøren. Vi kan bygge et stykke software, der lader procesingeniøren gøre dette uden alle andre. Vi er tæt på at nå det mål og dermed give procesingeniøren mulighed for effektivt at bruge ML."
Referencer
- Kanarik, K., et al. "Menneske-maskine samarbejde til forbedring af halvlederprocesudvikling," Nature 616, 707-711 (2023). https://doi.org/10.1038/s41586-023-05773-7
- https://en.wikipedia.org/wiki/MLOps
- https://en.wikipedia.org/wiki/Hyperparameter_(machine_learning)
Relaterede historier
Hvornår og hvor skal AI/ML implementeres i Fabs
Smartere værktøjer kan forbedre proceskontrol, identificere årsagerne til udflugter og fremskynde udviklingen af opskrifter.
Brug af ML til forbedret Fab-planlægning
Forskere bruger neurale netværk til at øge effektiviteten af waferbehandling ved at identificere mønstre i store datasamlinger.
Anvendelse af ML i fejlanalyse
Hvornår og hvor maskinlæring bruges bedst, og hvordan man vælger den rigtige model.
Dataproblemer monteret i chipfremstilling
Masterdatapraksis gør det muligt for produktingeniører og fabriks-it-ingeniører at håndtere forskellige datatyper og kvalitet.
Balancering af AI og ingeniørekspertise i Fab
Resultater viser store forbedringer, når begge er implementeret til ny procesudvikling.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://semiengineering.com/fabs-begin-ramping-up-machine-learning/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 2023
- 7
- a
- evne
- I stand
- Om
- absolut
- fremskynde
- accelererende
- Konto
- opnå
- tværs
- Handling
- aktioner
- faktisk
- Desuden
- adresse
- fremskridt
- påvirke
- mod
- AI
- AI / ML
- AL
- algoritme
- algoritmisk
- algoritmer
- Alle
- tillade
- tillader
- også
- altid
- forbløffende
- blandt
- beløb
- an
- analyse
- ,
- enhver
- Anvendelse
- applikationer
- anvendt
- gælder
- Indløs
- Anvendelse
- tilgang
- tilgange
- ER
- OMRÅDE
- omkring
- AS
- udseende
- forsikrer
- At
- attraktion
- Automatiseret
- automatisk
- Automation
- til rådighed
- undgå
- b
- tilbage
- afbalancering
- baseret
- I bund og grund
- grundlag
- BE
- fordi
- bliver
- bliver
- været
- før
- begynde
- Begyndelse
- være
- Tro
- jf. nedenstående
- BEDSTE
- Bedre
- mellem
- skævhed
- Big
- Sort kasse
- boost
- både
- grænser
- gennembrud
- bringe
- bred
- brute force
- bygge
- Bygning
- bygget
- men
- .
- by
- kaldet
- CAN
- kapacitet
- hvilken
- tilfælde
- tilfælde
- årsager
- CD
- center
- Direktør
- udfordre
- Ændringer
- karakteristika
- kontrol
- kemikalie
- chip
- Vælg
- Chopra
- ren
- Luk
- samarbejde
- kollektioner
- kombinationer
- kombinerer
- kommer
- sammenlignet
- konkurrencedygtig
- fuldføre
- komplekse
- kompleksitet
- komponenter
- Compute
- computer
- Computer Vision
- computing
- computerkraft
- tillid
- Tilslut
- forbruges
- forbrug
- kontrol
- kontrol
- korrelere
- korrelationer
- kunne
- Par
- skabe
- oprettet
- Oprettelse af
- skabelse
- kritisk
- Kunder
- dagligt
- FARE
- data
- datalogi
- datasæt
- David
- dag
- Dage
- deal
- årti
- beslutte
- afgørelser
- dyb
- dyb læring
- definitivt
- leveret
- Efterspørgsel
- afhænge
- indsætte
- indsat
- implementering
- udruller
- Afledt
- konstrueret
- opdage
- udvikle
- udviklet
- udvikling
- Udvikling
- udvikler
- DevOps
- forskellige
- svært
- størrelse
- direkte
- retning
- Direktør
- discipliner
- skelne
- do
- Er ikke
- gør
- domæne
- Dont
- Ved
- ulemper
- grund
- e
- E&T
- hver
- tidligste
- nemt
- let
- økonomi
- effektivt
- effektivitet
- effektivitet
- Elektronik
- andet
- opstået
- Emissioner
- bemyndigelse
- muliggøre
- muliggør
- ende
- energi
- energiforbrug
- ingeniør
- Engineering
- Ingeniører
- nok
- sikre
- Hele
- Miljø
- miljøer
- Lig
- udstyr
- især
- væsentlig
- væsentlige
- evaluere
- Endog
- alle
- evolution
- eksempel
- Spænding
- henrettet
- eksperiment
- eksperimenter
- ekspert
- ekspertise
- eksperter
- forklarer
- udforskning
- udforske
- udforsket
- Udforskning
- Øjne
- lette
- Faktisk
- fabrikker
- fabrik
- Manglende
- fejl
- falsk
- FAST
- frygt
- få
- felt
- Fig
- Finde
- fund
- Fornavn
- flow
- Til
- Tving
- skov
- Videresend
- fundet
- Foundation
- fire
- fra
- fremtiden
- spil
- få
- få
- given
- Go
- mål
- gå
- godt
- GPU'er
- vejledning
- vejlede
- skete
- Happening
- sker
- Hardware
- Have
- have
- høre
- stærkt
- tunge
- tunge løft
- hjælper
- Høj
- leje
- Hits
- HOURS
- Hvordan
- How To
- Men
- HTTPS
- menneskelig
- Mennesker
- Hundreder
- Hybrid
- i
- idé
- identificere
- identificere
- if
- belyse
- billede
- gennemføre
- implementering
- vigtigt
- Forbedre
- forbedret
- forbedringer
- forbedring
- in
- I andre
- Herunder
- Forøg
- Stigninger
- utrolige
- industrier
- industrien
- industri eksperter
- iboende
- initial
- innovere
- indgang
- øjeblikkeligt
- interaktion
- interaktioner
- ind
- intuition
- Invest
- investering
- involverer
- isolation
- spørgsmål
- IT
- jon
- hoppe
- lige
- holde
- Nøgle
- Kend
- viden
- Lam
- stor
- Efternavn
- lanceret
- læring
- mindre
- Lets
- udlejning
- niveauer
- løftestang
- livscyklus
- løft
- ligesom
- GRÆNSE
- begrænsninger
- Limited
- Line (linje)
- masser
- laveste
- maskine
- machine learning
- lavet
- vedligeholdelse
- lave
- ledelse
- styring
- Managing Director
- måde
- Produktion
- mange
- Match
- matchende
- materialer
- Matter
- Matters
- max-bredde
- betyde
- betyder
- midler
- måle
- mekanismer
- sammenlægning
- metoder
- Metrics
- minimere
- ML
- ML algoritmer
- model
- modellering
- modeller
- Overvåg
- overvåges
- overvågning
- skærme
- mere
- mest
- MONTERING
- flytning
- meget
- flere
- skal
- Natur
- nødvendig
- Behov
- behov
- behov
- net
- Neural
- neurale netværk
- aldrig
- Ny
- næste
- ingen
- Støj
- bemærkede
- intet
- nu
- nummer
- observeret
- of
- tit
- on
- engang
- ONE
- kun
- åbner
- Produktion
- optimal
- optimering
- Optimer
- optimering
- Indstillinger
- or
- ordrer
- Andet
- vores
- ud
- Resultat
- udfald
- output
- i løbet af
- emballage
- par
- parring
- parameter
- parametre
- del
- deltager
- især
- sti
- mønstre
- Mennesker
- per
- procentdel
- udføre
- ydeevne
- person,
- Fysik
- stykke
- stykker
- pipeline
- planer
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Leg
- Punkt
- punkter
- mulig
- eventuelt
- magt
- vigtigste
- praksis
- forudsigelse
- Forudsigelser
- præsident
- trykke
- Problem
- behandle
- Processer
- forarbejdning
- Produkt
- produktion
- produktiv
- Produkter
- passende
- egenskaber
- give
- bevise
- kvalificeret
- kvalificere
- kvalitet
- hurtigere
- hurtigt
- rampe
- tilfældig
- virkelig
- årsager
- for nylig
- opskrift
- reducerer
- reducere
- reduktion
- Relationer
- pålidelighed
- pålidelig
- repræsentation
- repræsenterer
- påkrævet
- Kræver
- forskning
- henseender
- resultere
- Resultater
- omskoling
- højre
- robust
- robusthed
- Kør
- kører
- Said
- samme
- sandkasse
- skalaer
- Videnskab
- forskere
- se
- se
- set
- halvleder
- senior
- sæt
- indstilling
- flere
- bør
- Vis
- Signal
- signifikant
- lignende
- Simpelt
- enklere
- simulation
- So
- Software
- Software Engineer
- Løsninger
- SOLVE
- nogle
- sommetider
- Kilde
- Kilder
- Space
- rumlige
- specifikke
- specifikationer
- etaper
- standard
- starte
- erklærede
- Stater
- statistiske
- steady
- styre
- Trin
- Steps
- Stadig
- Stands
- strukturer
- Kamp
- emne
- vellykket
- sådan
- tilført
- support
- formodes
- systemet
- Systemer
- Tag
- Tandem
- hold
- Teknisk
- teknikker
- afprøvet
- end
- at
- Området
- deres
- selv
- derefter
- Der.
- Disse
- de
- ting
- ting
- denne
- dem
- tusinder
- tre
- kapacitet
- Dermed
- tid
- til
- nutidens
- også
- værktøj
- Værktøjskasse
- værktøjer
- Sporbarhed
- traditionelle
- Tog
- uddannet
- Kurser
- Transform
- overgang
- sand
- forsøger
- TUR
- to
- typen
- typer
- Ultimativt
- forstå
- forståelse
- indtil
- på
- brug
- brug tilfælde
- anvendte
- Bruger
- brugere
- ved brug af
- udnytte
- VALIDATE
- valideret
- validerer
- validering
- værdi
- række
- Vast
- versus
- meget
- vice
- Vice President
- Virtual
- vision
- visuel
- visualisering
- Visualiser
- afgørende
- ønsker
- Vej..
- måder
- we
- uge
- GODT
- var
- Hvad
- Hvad er
- hvornår
- hvorvidt
- som
- hvorfor
- Wikipedia
- vilje
- vinde
- med
- inden for
- uden
- Arbejde
- arbejder
- world
- bekymret
- værd
- ville
- Indpakket
- Forkert
- endnu
- Udbytte
- dig
- Din
- zephyrnet