Den 29. januar er National Puzzle Day, og for at fejre det, har vi lavet en sjov blog, der beskriver, hvordan man løser Sudoku ved hjælp af kunstig intelligens (AI).
Introduktion
Før ordle, Sudoku puslespil var raseriet, og det er stadig meget populært. I de senere år er brugen af optimering metoder til at løse gåden har været et dominerende tema. Se “Løsning af Sudoku-puslespil ved hjælp af optimering i Arkieva".
I nuværende tid er brugen af AI fokuseret på maskinlæring, som omfatter en bred vifte af metoder fra lasso-regression til forstærkningslæring. Brugen af AI har dukkede op igen at tackle komplekse planlægning udfordringer. En metode, søgning med tilbagesporing, er almindeligt anvendt og er perfekt til Sudoku.
Denne blog vil give en detaljeret beskrivelse af, hvordan man bruger denne metode til at løse Sudoku. Som det viser sig, kan "backtracking" findes i optimerings- og maskinlæringsmotorer og er en hjørnesten i den avancerede heuristik, som Arkieva bruger til planlægning. Algoritmen er implementeret i et "Array Programming Language", et funktionsorienteret programmeringssprog, der håndterer en rigt sæt af matrixstrukturer.
Grundlæggende om Sudoku
Fra Wikipedia: Sudoku er et logikbaseret, kombinatorisk talplaceringspuslespil. Målet er at udfylde et 9×9-gitter med cifre, så hver kolonne, hver række og hver af de ni 3×3-undergitter, der udgør gitteret (også kaldet "kasser", "blokke", "regioner", eller "underkvadrater") indeholder alle cifrene fra 1 til 9. Puslespillet giver et delvist gennemført gitter, som typisk har en unik løsning. Fuldførte puslespil er altid en type latinsk firkant med en yderligere begrænsning på indholdet af individuelle regioner. For eksempel må det samme enkelt heltal ikke optræde to gange i den samme 9×9 spillebrætrække eller kolonne eller i nogen af de ni 3×3 underområder på 9×9 spillebrættet.
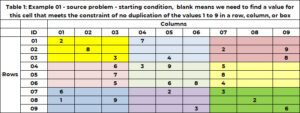
Tabel 1 har et eksempel på et problem. Der er 9 rækker og 9 kolonner til i alt 81 celler. Hver har tilladelse til at have et og kun et af ni heltal mellem 1 og 9. I startløsningen har en celle enten en enkelt værdi - som fikserer værdien i denne celle til den værdi, eller cellen er tom, hvilket indikerer, at vi har brug for for at finde en værdi for denne celle. Cellen (1,1) har værdien 2 og celle (6,5) har værdien 6. Celle (1,2) og celle (2,3) er tomme, og algoritmen vil finde en værdi for disse celler.
Komplikationen
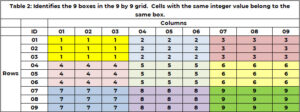
Ud over at tilhøre én og kun én række og kolonne, hører en celle til én og kun 1 boks. Der er 9 kasser, og de er angivet med farve i tabel 1. Tabel 2 bruger et unikt heltal mellem 1 og 9 til at identificere hver boks eller gitter. Cellerne med en rækkeværdi på (1, 2 eller 3) og kolonneværdi på (1, 2 eller 3) hører til boks 1. Boks 6 er rækkeværdier på (4, 5, 6) og kolonneværdier (7, 8) , 9). Boks-id'et bestemmes af formlen BOX_ID = {3x(floor((ROW_ID-1) /3)} + loft (COL_ID/3). For cellen (5,7), 6 = 3x(floor(5-1) ))/3) + loft (8/3)= 3×1 + 3 = 3+3.
Hjertet af puslespillet
At finde en heltalsværdi mellem 1 og 9 for hver ukendt celle, således at heltal 1 til 9 bruges én gang og kun én gang for hver kolonne, hver række og hver boks.
Lad os se på celle (1,3), som er tom. Række 1 har allerede værdierne 2 og 7. Disse er ikke tilladt i denne celle. Kolonne 3 har allerede værdierne 3, 5,6, 7,9. Disse er ikke tilladt. Boks 1 (gul) har værdierne 2, 3 og 8. Disse er ikke tilladt. Følgende værdier er ikke tilladt (2,7); (3, 5, 6, 7, 9); (2, 3, 8). De unikke værdier, der ikke er tilladt, er (2, 3, 5, 6, 7, 8, 9). De eneste kandidatværdier er (1,4).
En løsningstilgang ville være midlertidigt at tildele 1 til celle (1,3) og derefter prøve at finde kandidatværdier for en anden celle.
En backtracking-løsning: Start af komponenter
Array struktur
Udgangsstedet er at beslutte en matrixstruktur til at gemme kildeproblemet og understøtte søgningen. Tabel 3 har denne array-struktur. Kolonne 1 er et unikt heltals-id for hver celle. Værdierne går fra 1 til 81. Kolonne 2 er række-id'et for cellen. Kolonne 3 er cellens kolonne-id. Kolonne 4 er boks-id'et. Kolonne 5 er værdien i cellen. Observer en celle uden en værdi får værdien nul i stedet for tom eller null. Dette holder dette som et "heltals-array" - langt overlegent med hensyn til ydeevne.

I APL vil dette array blive lagret i et 2-dimensionelt array, hvor formen er 81 gange 5. Antag, at elementerne i tabel 3 er lagret i variablen MAT. Eksempler på funktioner er:
Kommandoen MAT[1 2 3;]griber de første 3 rækker af MAT
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
MAT[1 2 3; 4 5] sikrer række 1, 2, 3 og kun kolonne 4 og 5
1
1
1
(MAT[;5]=0)/MAT[;1] finder alle celler, der har brug for en værdi.
INDSÆT TABEL 3
Sundhedstjek: Dubletter
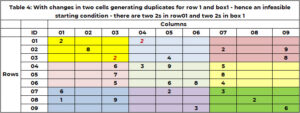
Inden søgningen påbegyndes, er det vigtigt at tjekke sin fornuft! Det er den mulige startløsning. Mulig for Sudoku, er der nu dubletter i enhver række, kolonne eller boks. Den nuværende startløsning, for eksempel 1, er mulig. Tabel 4 har et eksempel, hvor startløsningen har dubletter. Række 1 har to værdier 2. Område 1 har to værdier 2. Funktionen "SANITY_DUPE" håndterer denne logik.
Sanity Check: Indstillinger for celler uden værdier
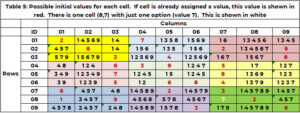
En meget nyttig information ville være alle de mulige værdier for en celle uden en værdi. Hvis der ikke er nogen kandidater, er dette puslespil ikke løseligt. En celle kan ikke påtage sig en værdi, som dens nabo allerede har gjort krav på. Ved at bruge tabel 1 for celle (1,3,'1' – denne sidste 1 er boxiden), er dens naboer række 1, kolonne 3 og boks 1. Række 1 har værdierne (2,7); kolonne 3 har værdierne (3,5,6,7,9); boks 1 har værdierne (2,3,8). Celle (1,3.1) kan ikke tage følgende værdier (2,3,5,6,7,8,9). De eneste muligheder for celle (1,3,1) er (1,4). For celle (4,1,2) er værdierne 1, 2, 3, 5, 6, 7, 9 allerede brugt i række 4, kolonne 1 og/eller boks 4. De eneste kandidatværdier er (4,8) . Unction "SANITY_CAND" håndterer denne logik.
Tabel 5 viser kandidaterne, for eksempel 1 ved starten af søgeprocessen. Hvis en celle allerede er blevet tildelt en værdi i startbetingelserne (tabel 1), så gentages denne værdi og vises med rødt. Hvis en celle, der har brug for en værdi, kun har én mulighed, vises denne med hvidt. Celle (8,7,9) har den enkelte værdi 7 i hvid. (2,5,8,4,3) er påberåbt af nabokolonne 7. (1, 2, 9) af række 8. (3,2,6) af boks 9. Kun værdien 7 er uopkrævet.
Sundhedstjek: Leder efter konflikter
Oplysningerne, der identificerer alle muligheder for celler, der har brug for en værdi (opslået i tabel 4), gør det muligt for os at identificere en konflikt, før du starter søgeprocessen. En konflikt opstår, når to celler, der har brug for en værdi, kun har én kandidat, kandidatværdien er den samme, og de to celler er naboer. Fra tabel 4 kender vi den eneste celle, der har brug for en værdi og kun har én kandidat, er celle (8,7,9). For eksempel 1 er der ingen konflikt.
Hvad ville være en konflikt? Hvis den eneste mulige værdi for celle (3,7,3) var 7 (i stedet for 1, 6, 7), så er der en konflikt. Celle (8,7) og celle (3,7) er naboer - den samme kolonne. Men hvis den eneste mulige værdi for celle (4,9,2) var 7 (i stedet for 1, 2, 7), ville dette ikke være en konflikt. Disse celler er ikke naboer.
Oversigt over fornuftstjek
- Hvis der er dubletter, er startløsningen ikke gennemførlig.
- Hvis en celle, der har brug for en værdi, ikke har nogen kandidater, så er der ingen mulig løsning på dette puslespil. Listen over kandidatværdier for hver celle kan bruges til at reducere søgerummet – både til backtracking og optimering.
- Evnen til at finde konflikter identificerer puslespillet ikke er gennemførligt – har ingen løsning – uden en søgeproces. Derudover identificerer den "problemcellerne".
En tilbagesporingsløsning: Søgeproces
Med kernedatastrukturer og sundhedstjek på plads, vender vi vores opmærksomhed mod søgeprocessen. Det tilbagevendende tema er igen, at få datastrukturer på plads til at understøtte søgning.
Sporing af søgningen
Arrayet Tracker holder styr på de afgivne opgaver
- Kol. 1 er tælleren
- Kol. 2 er antallet af tilgængelige muligheder for at tildele denne celle
- 1 betyder 1 mulighed tilgængelig, 2 betyder to muligheder osv.
- 0 betyder – ingen mulighed tilgængelig eller nulstilling til 0 (ingen tildelt værdi) og tilbagesporing
- Kol. 3 er den celle, der er tildelt et værdiindeksnummer (1 til 81)
- Kol. 4 er den værdi, der er tildelt cellen i sporhistorikken
- En værdi på 9999 betyder, at denne celle var, da blindgyden blev fundet
- Værdien af et heltal mellem 1 og 9 inklusive, er den tildelte værdi til denne celle på dette tidspunkt i søgeprocessen.
- En værdi på 0 betyder, at denne celle skal have en tildeling
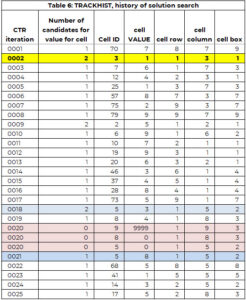
Tracker-arrayet bruges til at understøtte søgeprocessen. Arrayet SPORHIST har samme struktur som trackeren, men gemmer historikken for hele søgeprocessen. Tabel 6 har en del af TRACKHIST f.eks. 1. Det er forklaret mere detaljeret i et senere afsnit.
Derudover arrayet Pav (en vektor af en vektor), holder styr på tidligere tildelte værdier til denne celle. Dette sikrer, at vi ikke genbesøger en fejlslagen løsning – svarende til det, der gøres i TABU.
Der er en valgfri log-proces, hvor søgeprocessen udskriver hvert trin.
Starter søgningen
Med bogføring og fornuftskontrol udført, kan vi nu starte søgeprocessen. Trinene er:
- Er der nogen celler tilbage, der skal have en værdi? – hvis nej, så er vi færdige.
- For hver celle, der har brug for en værdi, skal du finde alle kandidatindstillinger for hver celle. Tabel 4 har disse værdier ved starten af løsningsprocessen. Ved hver iteration opdateres dette for at rumme værdier tildelt til celler.
- Vurder mulighederne i denne rækkefølge.
- Hvis en celle har NUL muligheder, så indled tilbagesporing
- Find alle cellerne med én mulighed, vælg en af disse celler, lav denne opgave,
- og opdatere sporingstabellen, den aktuelle løsning og PAV.
- Hvis alle cellerne har mere end én mulighed, skal du vælge én celle og én værdi og opdatere
- og opdatere sporingstabellen, den aktuelle løsning og PAV
Vi vil bruge tabel 6, som er en del af historien om løsningsprocessen (kaldet TRACKHIST) til at illustrere hvert trin.
I den første iteration (CTR=1) er celle 70 (række 8, kol. 7, boks 9) valgt til at blive tildelt en værdi. Der er kun kandidat (7), og denne værdi er tildelt til celle 70. Derudover tilføjes værdien 7 til vektoren af tidligere tildelte værdier (PAV) for celle 70.
I den anden iteration er celle 30 tildelt værdien 1. Denne celle havde to kandidatværdier. Den mindste kandidatværdi tildeles cellen (bare en vilkårlig regel for at gøre logikken nem at følge).
Processen med at identificere en celle, der har brug for en værdi og tildele en værdi, fungerer fint indtil iteration (CTR) 20. Celle 9 har brug for værdi, men antallet af kandidater er NUL. Der er to muligheder:
- Der er ingen løsning på dette puslespil.
- Vi fortryder (backtrack) nogle af opgaverne og går en anden vej.
Vi ledte efter den celletildeling, der lå tættest på dette, hvor der var mere end én mulighed. I dette eksempel skete dette ved iteration 18, hvor celle 5 er tildelt værdien 3, men der var to kandidatværdier for celle 5 – værdierne 3 og 8.
Mellem celle 5 (CTR = 18) og celle 9 (CTR = 20) tildeles celle 8 værdien 4 (CTR=19). Vi sætter celle 8 og 5 tilbage på listen "brug for en værdi". Dette fanges i den anden og tredje CTR=20-indtastning, hvor værdien er sat til 0. Værdien 3 bevares i PAV-vektoren for celle 5. Det vil sige, at søgemaskinen ikke kan tildele værdien 3 til celle 5.
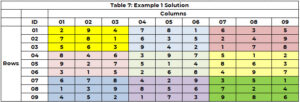
Søgemaskinen starter op igen for at identificere en værdi for celle 5 (med 3 ikke længere en mulighed) og tildeler værdien 8 til celle 5 (CTR=21). Det fortsætter, indtil alle celler har en værdi, eller der er en celle uden mulighed, og der ikke er nogen tilbagesporingssti. Løsningen er vist i tabel 7.
Bemærk, hvor der er mere end én kandidat til en celle, er dette en chance for parallel behandling.
Sammenligning med MILP Optimization Solution
På overfladeniveau er repræsentationen af Sudoku-puslespillet dramatisk anderledes. AI-tilgangen bruger heltal og er på enhver måde en strammere og mere intuitiv repræsentation. Derudover giver fornuftskontrollen nyttige oplysninger til at lave en stærkere formulering. MILP-repræsentationen er uendelig binære filer (0/1). Imidlertid er de binære filer kraftfulde repræsentationer givet styrken af moderne MILP-løsere.
Internt beholder MILP-løseren dog ikke de binære filer, men bruger en sparse array-metode til at eliminere lagring af alle nuller. Derudover dukker algoritmerne til at løse binære filer først op i 1980'erne og 1990'erne. Avisen fra 1983 af Crowder, Johnson og Padberg rapporter om en af de første praktiske løsninger til optimering med binære filer. De bemærker vigtigheden af smart forbehandling og forgrening og bundne metoder som afgørende for en vellykket løsning.
Den seneste eksplosion af brugen af begrænsningsprogrammering og software som f.eks lokal løser har gjort det klart vigtigheden af at bruge AI-metoder med de originale optimeringsmetoder såsom lineær programmering og mindste kvadrater.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 20
- 29
- 30
- 31
- 600
- 7
- 70
- 8
- 9
- a
- evne
- imødekomme
- tilføjet
- Desuden
- Yderligere
- Derudover
- fremskreden
- igen
- AI
- algoritme
- algoritmer
- Alle
- tilladt
- allerede
- også
- altid
- Amazon
- an
- ,
- En anden
- enhver
- vises
- tilgang
- vilkårlig
- ER
- OMRÅDE
- Array
- kunstig
- kunstig intelligens
- Kunstig intelligens (AI)
- AS
- tildelt
- antage
- At
- opmærksomhed
- til rådighed
- tilbage
- BE
- været
- før
- tilhører
- tilhører
- mellem
- blank
- Blog
- board
- både
- bundet
- Boks
- kasser
- Branch
- men
- by
- kaldet
- CAN
- kandidat
- kandidater
- kan ikke
- fanget
- loft
- Celebration
- celle
- Celler
- udfordringer
- chance
- kontrollere
- kontrol
- hævdede
- klar
- farve
- Kolonne
- Kolonner
- almindeligt
- Afsluttet
- komplekse
- betingelser
- konflikt
- Konflikter
- indeholder
- indhold
- fortsætter
- Core
- hjørnesten
- oprettet
- kritisk
- Nuværende
- data
- dag
- døde
- beslutte
- beskrivelse
- detail
- detaljeret
- detaljer
- bestemmes
- forskellige
- cifre
- do
- gør
- dominerende
- færdig
- Dont
- dramatisk
- dubletter
- hver
- let
- enten
- elementer
- eliminere
- emerge
- muliggør
- vedrører generelt
- ende
- Endless
- Engine (Motor)
- Motorer
- sikrer
- Hele
- etc.
- eksempel
- forklarede
- eksplosion
- mislykkedes
- langt
- gennemførlig
- udfylde
- Finde
- fund
- ende
- Fornavn
- fast
- fokuserede
- følger
- efter
- Til
- Formula
- formulering
- fundet
- fra
- sjovt
- funktion
- funktioner
- få
- given
- Grid
- havde
- Håndterer
- Have
- Hjerte
- hjælpsom
- historie
- Hvordan
- How To
- Men
- HTML
- HTTPS
- ID
- identificerer
- identificere
- identificere
- if
- illustrere
- implementeret
- betydning
- in
- Inklusive
- indeks
- angivet
- angiver
- individuel
- oplysninger
- oplyser
- indvendig
- i stedet
- Institut
- Intelligens
- internt
- intuitiv
- IT
- iteration
- ITS
- Johnson
- jpg
- lige
- Holde
- holdt
- Kend
- Sprog
- Efternavn
- senere
- latin
- læring
- mindst
- til venstre
- Niveau
- lineær
- Liste
- log
- logik
- længere
- Se
- kiggede
- leder
- maskine
- machine learning
- lavet
- lave
- max-bredde
- Kan..
- midler
- måle
- metode
- metoder
- Moderne
- mere
- national
- Behov
- behov
- naboer
- ni
- ingen
- Bemærk
- nu
- nummer
- objektiv
- observere
- forekom
- of
- on
- engang
- ONE
- kun
- optimering
- Option
- Indstillinger
- or
- ordrer
- original
- vores
- ud
- Papir
- Parallel
- del
- sti
- perfekt
- ydeevne
- stykke
- Place
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Punkt
- Populær
- mulig
- indsendt
- vigtigste
- Praktisk
- tidligere
- Problem
- behandle
- forarbejdning
- Programmering
- give
- giver
- sætte
- puslespil
- Puslespil
- Rage
- rækkevidde
- nylige
- tilbagevendende
- Rød
- reducere
- regioner
- regression
- forstærkning læring
- gentaget
- Rapporter
- repræsentation
- RÆKKE
- Herske
- samme
- planlægning
- Søg
- søgemaskine
- Anden
- Sektion
- Sikrer
- se
- Vælg
- valgt
- sæt
- Shape
- vist
- Shows
- lignende
- enkelt
- So
- Software
- løsninger
- Løsninger
- SOLVE
- nogle
- Kilde
- Space
- firkant
- firkanter
- starte
- Starter
- starter
- Trin
- Steps
- Stadig
- butik
- opbevaret
- styrke
- stærkere
- struktur
- strukturer
- vellykket
- sådan
- overlegen
- support
- overflade
- bord
- tackle
- Tag
- end
- at
- The Source
- tema
- derefter
- Der.
- Disse
- de
- Tredje
- denne
- strammere
- gange
- til
- I alt
- spor
- Sporing
- prøv
- TUR
- vender
- To gange
- to
- typen
- typisk
- enestående
- ukendt
- indtil
- Opdatering
- opdateret
- us
- brug
- anvendte
- bruger
- ved brug af
- værdi
- Værdier
- variabel
- meget
- var
- we
- var
- Hvad
- Hvad er
- hvornår
- som
- hvid
- bred
- Bred rækkevidde
- Wikipedia
- vilje
- med
- uden
- virker
- ville
- år
- gul
- zephyrnet
- nul