লেখকের ছবি
মেশিন লার্নিং এবং ডেটা সায়েন্সের উপর অনেক কোর্স এবং রিসোর্স পাওয়া যায়, কিন্তু ডেটা ইঞ্জিনিয়ারিং এর উপর খুব কম। এটি কিছু প্রশ্ন উত্থাপন করে। এটা কি কঠিন ক্ষেত্র? এটা কম বেতন অফার? এটি কি অন্যান্য প্রযুক্তিগত ভূমিকার মতো উত্তেজনাপূর্ণ বলে মনে করা হয় না? যাইহোক, বাস্তবতা হল যে অনেক কোম্পানি সক্রিয়ভাবে ডেটা ইঞ্জিনিয়ারিং প্রতিভা খুঁজছে এবং যথেষ্ট বেতন অফার করছে, কখনও কখনও $200,000 USD ছাড়িয়ে যায়। ডেটা ইঞ্জিনিয়াররা ডেটা প্ল্যাটফর্মের স্থপতি হিসাবে একটি গুরুত্বপূর্ণ ভূমিকা পালন করে, ভিত্তিগত সিস্টেমগুলি ডিজাইন এবং তৈরি করে যা ডেটা বিজ্ঞানী এবং মেশিন লার্নিং বিশেষজ্ঞদের কার্যকরভাবে কাজ করতে সক্ষম করে।
এই শিল্পের ব্যবধান পূরণ করে, DataTalkClub একটি রূপান্তরমূলক এবং বিনামূল্যের বুটক্যাম্প চালু করেছে, “ডেটা ইঞ্জিনিয়ারিং জুমক্যাম্প" এই কোর্সটি নতুনদের বা পেশাজীবীদের ক্ষমতায়ন করার জন্য ডিজাইন করা হয়েছে যারা কেরিয়ার পরিবর্তন করতে চাইছেন, প্রয়োজনীয় দক্ষতা এবং ডেটা ইঞ্জিনিয়ারিংয়ে বাস্তব অভিজ্ঞতা সহ।
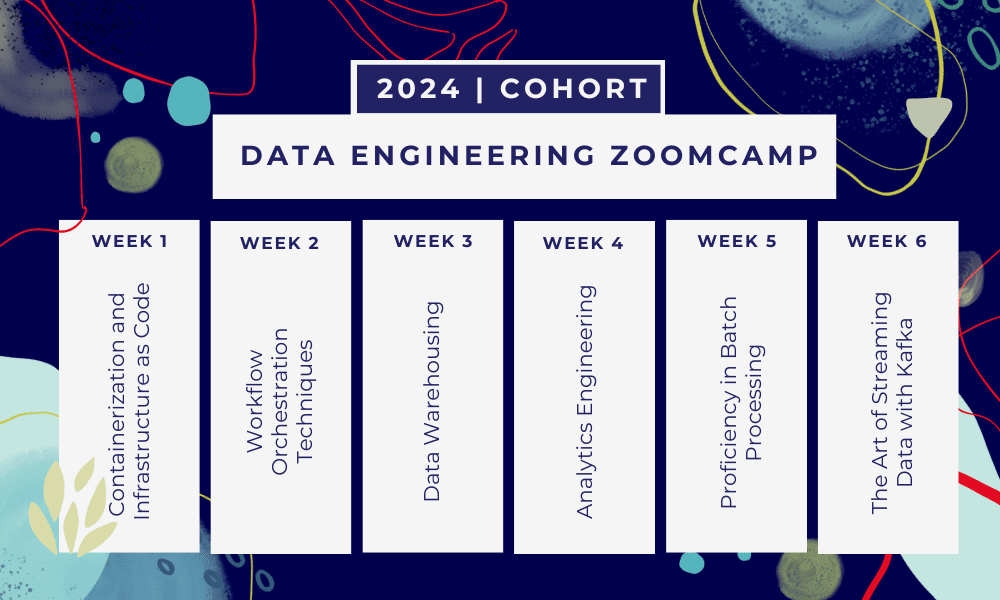
এটা একটা 6-সপ্তাহের বুটক্যাম্প যেখানে আপনি একাধিক কোর্স, পড়ার উপকরণ, কর্মশালা এবং প্রকল্পের মাধ্যমে শিখবেন। প্রতিটি মডিউলের শেষে, আপনি যা শিখেছেন তা অনুশীলন করার জন্য আপনাকে হোমওয়ার্ক দেওয়া হবে।
- সপ্তাহ 1: GCP, Docker, Postgres, Terraform এবং পরিবেশ সেটআপের ভূমিকা।
- সপ্তাহ 2: Mage সঙ্গে ওয়ার্কফ্লো অর্কেস্ট্রেশন.
- সপ্তাহ 3: BigQuery-এর সাহায্যে ডেটা গুদামজাত করা এবং BigQuery-এর সাহায্যে মেশিন লার্নিং।
- সপ্তাহ 4: ডিবিটি, গুগল ডেটা স্টুডিও এবং মেটাবেসের সাথে বিশ্লেষণাত্মক প্রকৌশলী।
- সপ্তাহ 5: স্পার্কের সাথে ব্যাচ প্রক্রিয়াকরণ।
- সপ্তাহ 6: কাফকার সাথে স্ট্রিমিং।
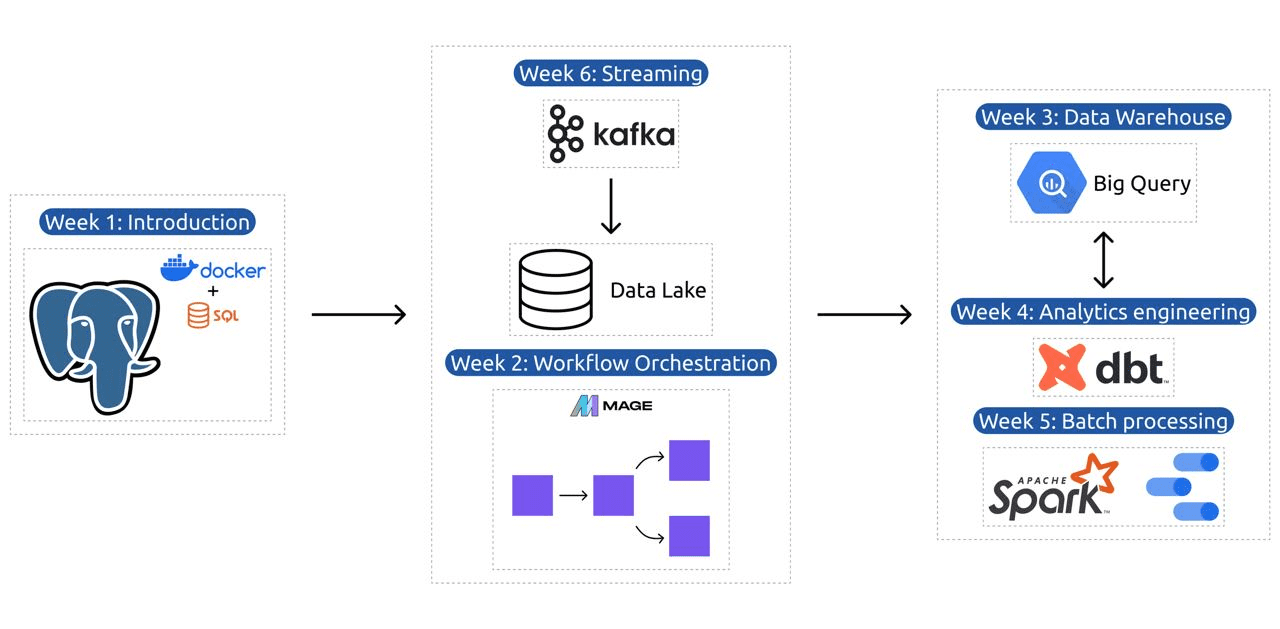
চিত্র থেকে DataTalksClub/data-engineering-zoomcamp
সিলেবাসটিতে 6টি মডিউল, 2টি কর্মশালা এবং একটি প্রকল্প রয়েছে যা পেশাদার ডেটা ইঞ্জিনিয়ার হওয়ার জন্য প্রয়োজনীয় সমস্ত কিছু কভার করে।
মডিউল 1: কোড হিসাবে কন্টেইনারাইজেশন এবং পরিকাঠামো আয়ত্ত করা
এই মডিউলে, আপনি ডকার এবং পোস্টগ্রেস সম্পর্কে শিখবেন, বেসিকগুলি দিয়ে শুরু করে এবং ডেটা পাইপলাইন তৈরি, ডকারের সাথে পোস্টগ্রেস চালানো এবং আরও অনেক কিছু সম্পর্কে বিস্তারিত টিউটোরিয়ালের মাধ্যমে অগ্রসর হবেন।
মডিউলটি পিজিএডমিন, ডকার-কম্পোজ, এবং এসকিউএল রিফ্রেশার বিষয়গুলির মতো প্রয়োজনীয় সরঞ্জামগুলিও কভার করে, ডকার নেটওয়ার্কিং-এ ঐচ্ছিক বিষয়বস্তু এবং উইন্ডোজ সাবসিস্টেম লিনাক্স ব্যবহারকারীদের জন্য একটি বিশেষ ওয়াক-থ্রু। শেষ পর্যন্ত, কোর্সটি আপনাকে GCP এবং Terraform-এর সাথে পরিচয় করিয়ে দেয়, যা আধুনিক ক্লাউড-ভিত্তিক পরিবেশের জন্য অপরিহার্য কোড হিসাবে কন্টেইনারাইজেশন এবং পরিকাঠামোর একটি সামগ্রিক বোঝাপড়া প্রদান করে।
মডিউল 2: ওয়ার্কফ্লো অর্কেস্ট্রেশন কৌশল
মডিউলটি Mage-এর একটি গভীর অনুসন্ধান অফার করে, যা ডেটা রূপান্তর এবং ইন্টিগ্রেশনের জন্য একটি উদ্ভাবনী ওপেন-সোর্স হাইব্রিড ফ্রেমওয়ার্ক। এই মডিউলটি ওয়ার্কফ্লো অর্কেস্ট্রেশনের প্রাথমিক বিষয়গুলি দিয়ে শুরু হয়, ম্যাজের সাথে হ্যান্ডস-অন অনুশীলনে অগ্রসর হয়, যার মধ্যে এটি ডকারের মাধ্যমে সেট আপ করা এবং API থেকে পোস্টগ্রেস এবং Google ক্লাউড স্টোরেজ (GCS) এবং তারপর BigQuery-এ ETL পাইপলাইন তৈরি করা।
ভিডিও, রিসোর্স এবং ব্যবহারিক কাজগুলির মডিউলের মিশ্রণ একটি বিস্তৃত শিক্ষার অভিজ্ঞতা নিশ্চিত করে, মেজ ব্যবহার করে অত্যাধুনিক ডেটা ওয়ার্কফ্লো পরিচালনা করার দক্ষতা দিয়ে শিক্ষার্থীদের সজ্জিত করে।
কর্মশালা 1: ডেটা ইনজেশন কৌশল
প্রথম কর্মশালায় আপনি দক্ষ ডেটা ইনজেশন পাইপলাইন তৈরি করতে পারদর্শী হবেন। কর্মশালাটি এপিআই এবং ফাইলগুলি থেকে ডেটা বের করা, ডেটা স্বাভাবিককরণ এবং লোড করা এবং ক্রমবর্ধমান লোডিং কৌশলগুলির মতো প্রয়োজনীয় দক্ষতাগুলির উপর দৃষ্টি নিবদ্ধ করে৷ এই কর্মশালাটি শেষ করার পরে, আপনি একজন সিনিয়র ডেটা ইঞ্জিনিয়ারের মতো দক্ষ ডেটা পাইপলাইন তৈরি করতে সক্ষম হবেন।
মডিউল 3: ডেটা গুদামজাতকরণ
মডিউলটি ডেটা স্টোরেজ এবং বিশ্লেষণের একটি গভীর অনুসন্ধান, যা BigQuery ব্যবহার করে ডেটা গুদামজাতকরণের উপর ফোকাস করে। এটি বিভাজন এবং ক্লাস্টারিংয়ের মতো মূল ধারণাগুলি কভার করে এবং BigQuery-এর সর্বোত্তম অনুশীলনগুলিতে ডুব দেয়৷ মডিউলটি উন্নত বিষয়গুলিতে অগ্রসর হয়, বিশেষ করে BigQuery-এর সাথে মেশিন লার্নিং (ML) এর একীকরণ, ML-এর জন্য SQL-এর ব্যবহার হাইলাইট করে এবং হাইপারপ্যারামিটার টিউনিং, বৈশিষ্ট্য প্রিপ্রসেসিং এবং মডেল স্থাপনে সংস্থান প্রদান করে।
মডিউল 4: অ্যানালিটিক্স ইঞ্জিনিয়ারিং
অ্যানালিটিক্স ইঞ্জিনিয়ারিং মডিউলটি BigQuery বা PostgreSQL, একটি বিদ্যমান ডেটা গুদাম সহ dbt (ডেটা বিল্ড টুল) ব্যবহার করে একটি প্রজেক্ট তৈরি করার উপর ফোকাস করে।
মডিউলটি ক্লাউড এবং স্থানীয় উভয় পরিবেশে dbt সেট আপ, বিশ্লেষণ প্রকৌশল ধারণা, ETL বনাম ELT, এবং ডেটা মডেলিং প্রবর্তন করে। এটি উন্নত dbt বৈশিষ্ট্য যেমন ক্রমবর্ধমান মডেল, ট্যাগ, হুক এবং স্ন্যাপশট কভার করে।
শেষ পর্যন্ত, মডিউলটি Google ডেটা স্টুডিও এবং মেটাবেসের মতো সরঞ্জামগুলি ব্যবহার করে রূপান্তরিত ডেটা ভিজ্যুয়ালাইজ করার কৌশলগুলি প্রবর্তন করে এবং এটি সমস্যা সমাধান এবং দক্ষ ডেটা লোডিংয়ের জন্য সংস্থান সরবরাহ করে।
মডিউল 5: ব্যাচ প্রক্রিয়াকরণে দক্ষতা
এই মডিউলটি Apache Spark ব্যবহার করে ব্যাচ প্রসেসিং কভার করে, ব্যাচ প্রসেসিং এবং স্পার্কের ভূমিকা থেকে শুরু করে, Windows, Linux, এবং MacOS-এর জন্য ইনস্টলেশন নির্দেশাবলী সহ।
এতে স্পার্ক এসকিউএল এবং ডেটাফ্রেমগুলি অন্বেষণ করা, ডেটা প্রস্তুত করা, এসকিউএল ক্রিয়াকলাপ সম্পাদন করা এবং স্পার্ক ইন্টারনাল বোঝার অন্তর্ভুক্ত। অবশেষে, এটি ক্লাউডে স্পার্ক চালানো এবং BigQuery-এর সাথে স্পার্ককে একীভূত করার মাধ্যমে শেষ হয়।
মডিউল 6: কাফকার সাথে স্ট্রিমিং ডেটার শিল্প
মডিউলটি শুরু হয় স্ট্রীম প্রসেসিং ধারণার একটি সূচনা দিয়ে, তারপরে কাফকাকে গভীরভাবে অন্বেষণ করে, যার মধ্যে এর মৌলিক বিষয়গুলি, কনফ্লুয়েন্ট ক্লাউডের সাথে একীকরণ এবং প্রযোজক এবং ভোক্তাদের জড়িত ব্যবহারিক অ্যাপ্লিকেশনগুলি।
মডিউলটি কাফকা কনফিগারেশন এবং স্ট্রীমগুলিও কভার করে, স্ট্রীম যোগদান, পরীক্ষা, উইন্ডো করা এবং কাফকা ksqldb এবং কানেক্ট ব্যবহার করার মতো বিষয়গুলিকে সম্বোধন করে৷ উপরন্তু, এটি পাইথন এবং JVM পরিবেশে তার ফোকাস প্রসারিত করে, যেখানে পাইথন স্ট্রীম প্রক্রিয়াকরণের জন্য ফাউস্ট, পাইসপার্ক - স্ট্রাকচার্ড স্ট্রিমিং এবং কাফকা স্ট্রিমগুলির জন্য স্কালা উদাহরণ রয়েছে।
কর্মশালা 2: SQL এর সাথে স্ট্রিম প্রসেসিং
আপনি RisingWave এর সাথে স্ট্রিমিং ডেটা প্রক্রিয়া এবং পরিচালনা করতে শিখবেন, যা আপনার স্ট্রিম প্রক্রিয়াকরণ অ্যাপ্লিকেশনগুলিকে শক্তিশালী করার জন্য একটি PostgreSQL-শৈলীর অভিজ্ঞতা সহ একটি ব্যয়-দক্ষ সমাধান প্রদান করে।
প্রকল্প: রিয়েল-ওয়ার্ল্ড ডেটা ইঞ্জিনিয়ারিং অ্যাপ্লিকেশন
এই প্রজেক্টের উদ্দেশ্য হল একটি এন্ড-টু-এন্ড ডেটা পাইপলাইন নির্মাণের জন্য এই কোর্সে আমরা যে সমস্ত ধারণা শিখেছি তা বাস্তবায়ন করা। আপনি একটি ডেটাসেট নির্বাচন করে দুটি টাইল সমন্বিত একটি ড্যাশবোর্ড তৈরি করবেন, ডেটা প্রক্রিয়াকরণের জন্য একটি পাইপলাইন তৈরি করবেন এবং এটি একটি ডেটা লেকে সংরক্ষণ করবেন, ডেটা লেক থেকে একটি ডেটা গুদামে স্থানান্তরিত করার জন্য একটি পাইপলাইন তৈরি করবেন, রূপান্তর করবেন। ডেটা গুদামে ডেটা এবং ড্যাশবোর্ডের জন্য এটি প্রস্তুত করা এবং অবশেষে ডেটা দৃশ্যত উপস্থাপন করার জন্য একটি ড্যাশবোর্ড তৈরি করা।
2024 কোহর্টের বিবরণ
- নিবন্ধন: যোগদিন
- শুরুর তারিখ: জানুয়ারী 15, 2024, 17:00 CET এ
- নির্দেশিত সমর্থন সহ স্ব-গতিশীল শিক্ষা
- সমগোত্রীয় ফোল্ডার হোমওয়ার্ক এবং সময়সীমা সহ
- ইন্টারেক্টিভ স্ল্যাক সম্প্রদায় সহকর্মী শেখার জন্য
পূর্বশর্ত
- মৌলিক কোডিং এবং কমান্ড লাইন দক্ষতা
- এসকিউএল-এ ফাউন্ডেশন
- পাইথন: উপকারী কিন্তু বাধ্যতামূলক নয়
আপনার যাত্রার নেতৃত্ব দিচ্ছেন বিশেষজ্ঞ প্রশিক্ষক
- অঙ্কুশ খান্না
- ভিক্টোরিয়া পেরেজ মোলা
- আলেক্সি গ্রিগোরেভ
- ম্যাট পামার
- লুইস অলিভেরা
- মাইকেল শুমেকার
আমাদের 2024 কোহোর্টে যোগ দিন এবং একটি আশ্চর্যজনক ডেটা ইঞ্জিনিয়ারিং সম্প্রদায়ের সাথে শেখা শুরু করুন। বিশেষজ্ঞের নেতৃত্বে প্রশিক্ষণ, হাতে-কলমে অভিজ্ঞতা, এবং শিল্পের প্রয়োজন অনুসারে একটি পাঠ্যক্রম, এই বুটক্যাম্প শুধুমাত্র আপনাকে প্রয়োজনীয় দক্ষতা দিয়েই সজ্জিত করে না বরং একটি লাভজনক এবং চাহিদা-মাফিক ক্যারিয়ারের পথের অগ্রভাগে অবস্থান করে। আজই নথিভুক্ত করুন এবং আপনার আকাঙ্খাকে বাস্তবে রূপান্তর করুন!
আবিদ আলী আওয়ান (@1 আবিদালিয়াওয়ান) একজন প্রত্যয়িত ডেটা সায়েন্টিস্ট পেশাদার যিনি মেশিন লার্নিং মডেল তৈরি করতে পছন্দ করেন। বর্তমানে, তিনি মেশিন লার্নিং এবং ডেটা সায়েন্স টেকনোলজিতে বিষয়বস্তু তৈরি এবং প্রযুক্তিগত ব্লগ লেখার উপর মনোযোগ নিবদ্ধ করছেন। আবিদ টেকনোলজি ম্যানেজমেন্টে স্নাতকোত্তর ডিগ্রি এবং টেলিকমিউনিকেশন ইঞ্জিনিয়ারিংয়ে স্নাতক ডিগ্রি অর্জন করেছেন। তার দৃষ্টিভঙ্গি মানসিক অসুস্থতার সাথে সংগ্রামরত শিক্ষার্থীদের জন্য একটি গ্রাফ নিউরাল নেটওয়ার্ক ব্যবহার করে একটি AI পণ্য তৈরি করা।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- : আছে
- : হয়
- :না
- :কোথায়
- $ ইউপি
- 000
- 1
- 15%
- 17
- 2024
- a
- সক্ষম
- সম্পর্কে
- সক্রিয়ভাবে
- উপরন্তু
- সম্ভাষণ
- অগ্রসর
- আগুয়ান
- পর
- AI
- সব
- বরাবর
- এছাড়াও
- আশ্চর্যজনক
- an
- বিশ্লেষণ
- বিশ্লেষণাত্মক
- বৈশ্লেষিক ন্যায়
- এবং
- এবং অবকাঠামো
- এ্যাপাচি
- আপা স্পার্ক
- API
- API গুলি
- অ্যাপ্লিকেশন
- স্থাপত্যবিদ
- রয়েছি
- শিল্প
- AS
- At
- সহজলভ্য
- মূলতত্ব
- BE
- পরিণত
- মানানসই
- beginners
- উপকারী
- সর্বোত্তম
- সেরা অভ্যাস
- বিগকোয়ারি
- মিশ্রণ
- ব্লগ
- উভয়
- নির্মাণ করা
- ভবন
- কিন্তু
- by
- পেশা
- কেরিয়ার
- প্রত্যয়িত
- মেঘ
- মেঘ স্টোরেজ
- থলোথলো
- কোড
- কোডিং
- দল
- সম্প্রদায়
- কোম্পানি
- পরিপূরক
- ব্যাপক
- ধারণা
- উপসংহারে
- কনফিগারেশন
- মিলিয়া একীভূত
- সংযোগ করা
- বিবেচিত
- গঠিত
- গঠন করা
- কনজিউমার্স
- ধারণ
- বিষয়বস্তু
- বিষয়বস্তু-সৃষ্টি
- পথ
- গতিপথ
- কভার
- সৃষ্টি
- তৈরি করা হচ্ছে
- সৃষ্টি
- কঠোর
- এখন
- পাঠ্যক্রম
- ড্যাশবোর্ড
- উপাত্ত
- ডেটা ইঞ্জিনিয়ার
- ডেটা লেক
- তথ্য বিজ্ঞান
- তথ্য বিজ্ঞানী
- তথ্য ভান্ডার
- তথ্য গুদাম
- তারিখ
- ডিগ্রী
- বিস্তৃতি
- পরিকল্পিত
- ফন্দিবাজ
- বিশদ
- কঠিন
- ডকশ্রমিক
- প্রতি
- কার্যকরীভাবে
- দক্ষ
- পারেন
- ক্ষমতাপ্রদান করা
- সক্ষম করা
- শেষ
- সর্বশেষ সীমা
- প্রকৌশলী
- প্রকৌশল
- প্রকৌশলী
- নথিভুক্ত করা
- নিশ্চিত
- পরিবেশ
- পরিবেশের
- অপরিহার্য
- থার (eth)
- সব
- উদাহরণ
- উত্তেজনাপূর্ণ
- বিদ্যমান
- অভিজ্ঞতা
- বিশেষজ্ঞদের
- অন্বেষণ
- এক্সপ্লোরিং
- প্রসারিত
- বৈশিষ্ট্য
- বৈশিষ্ট্য
- সমন্বিত
- কয়েক
- ক্ষেত্র
- নথি পত্র
- পরিশেষে
- প্রথম
- কেন্দ্রবিন্দু
- গুরুত্ত্ব
- মনোযোগ
- অনুসৃত
- জন্য
- একেবারে পুরোভাগ
- মূল
- ফ্রেমওয়ার্ক
- বিনামূল্যে
- থেকে
- ক্রিয়া
- প্রাথমিক ধারনা
- ফাঁক
- জিসিপি
- প্রদত্ত
- গুগল
- গুগল ক্লাউড
- চিত্রলেখ
- গ্রাফ নিউরাল নেটওয়ার্ক
- পরিচালিত
- হাত
- আছে
- he
- হাইলাইট
- তার
- ঝুলিতে
- হোলিস্টিক
- বাড়ির কাজ
- আঙ্গুলসমূহ
- যাহোক
- HTTPS দ্বারা
- অকুলীন
- হাইপারপ্যারামিটার টিউনিং
- অসুস্থতা
- বাস্তবায়ন
- in
- গভীর
- অন্তর্ভুক্ত
- সুদ্ধ
- ক্রমবর্ধমান
- শিল্প
- পরিকাঠামো
- উদ্ভাবনী
- স্থাপন
- নির্দেশাবলী
- একীভূত
- ইন্টিগ্রেশন
- মধ্যে
- উপস্থাপিত
- পরিচয় করিয়ে দেয়
- উপস্থাপক
- ভূমিকা
- ভূমিকা
- ঘটিত
- IT
- এর
- জানুয়ারী
- যোগদান করেছে
- কাফকা
- কেডনুগেটস
- চাবি
- হ্রদ
- নেতৃত্ব
- শিখতে
- জ্ঞানী
- শিক্ষার্থীদের
- শিক্ষা
- মত
- লাইন
- লিঙ্কডইন
- লিনাক্স
- বোঝাই
- স্থানীয়
- খুঁজছি
- ভালবাসে
- কম
- লাভজনক
- মেশিন
- মেশিন লার্নিং
- MacOS এর
- পরিচালনা করা
- ব্যবস্থাপনা
- কার্যভার
- অনেক
- মালিক
- নিয়ন্ত্রণ
- উপকরণ
- মানসিক
- মানসিক অসুখ
- ML
- মডেল
- মূর্তিনির্মাণ
- মডেল
- আধুনিক
- মডিউল
- মডিউল
- অধিক
- বহু
- প্রয়োজনীয়
- প্রয়োজন
- প্রয়োজন
- চাহিদা
- নেটওয়ার্ক
- নেটওয়ার্কিং
- নিউরাল
- স্নায়বিক নেটওয়ার্ক
- উদ্দেশ্য
- of
- নৈবেদ্য
- অফার
- on
- কেবল
- ওপেন সোর্স
- অপারেশনস
- or
- অর্কেস্ট্রারচনা
- অন্যান্য
- আমাদের
- তীর্থযাত্রী
- বিশেষত
- পথ
- বেতন
- সমকক্ষ ব্যক্তি
- করণ
- পাইপলাইন
- প্ল্যাটফর্ম
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- খেলা
- অবস্থানের
- পোস্টগ্রেস্কল
- ব্যবহারিক
- বাস্তবিক দরখাস্তগুলো
- অনুশীলন
- চর্চা
- প্রস্তুতি
- বর্তমান
- প্রক্রিয়া
- প্রক্রিয়াজাত
- প্রক্রিয়াজাতকরণ
- প্রযোজক
- পণ্য
- পেশাদারী
- পেশাদার
- অগ্রগতি
- প্রকল্প
- প্রকল্প
- উপলব্ধ
- প্রদানের
- পাইথন
- প্রশ্ন
- উত্থাপন
- পড়া
- বাস্তব জগতে
- বাস্তবতা
- Resources
- ভূমিকা
- ভূমিকা
- দৌড়
- s
- বেতন
- scala
- বিজ্ঞান
- বিজ্ঞানী
- বিজ্ঞানীরা
- সচেষ্ট
- নির্বাচন
- জ্যেষ্ঠ
- বিন্যাস
- সেটআপ
- দক্ষতা
- ঢিলা
- সমাধান
- কিছু
- কখনও কখনও
- বাস্তববুদ্ধিসম্পন্ন
- স্ফুলিঙ্গ
- প্রশিক্ষণ
- এসকিউএল
- শুরু
- শুরু হচ্ছে
- স্টোরেজ
- প্রবাহ
- স্ট্রিমিং
- স্ট্রিম
- কাঠামোবদ্ধ
- সংগ্রাম
- শিক্ষার্থীরা
- চিত্রশালা
- সারগর্ভ
- এমন
- সমর্থন
- সুইচ
- সিস্টেম
- উপযোগী
- প্রতিভা
- কাজ
- প্রযুক্তি
- কারিগরী
- প্রযুক্তি
- প্রযুক্তি
- প্রযুক্তিঃ
- টেলিযোগাযোগ
- Terraform
- পরীক্ষামূলক
- যে
- সার্জারির
- অধিকার
- তারপর
- এই
- দ্বারা
- থেকে
- আজ
- টুল
- সরঞ্জাম
- টপিক
- প্রশিক্ষণ
- স্থানান্তরিত হচ্ছে
- রুপান্তর
- রুপান্তর
- রূপান্তরিত
- রুপান্তরিত
- রূপান্তর
- টিউটোরিয়াল
- দুই
- বোধশক্তি
- আমেরিকান ডলার
- ব্যবহার
- ব্যবহারকারী
- ব্যবহার
- Ve
- খুব
- মাধ্যমে
- Videos
- দৃষ্টি
- চাক্ষুষরূপে
- vs
- গুদাম
- গুদামজাত করা
- we
- কি
- যে
- হু
- ইচ্ছা
- জানালা
- সঙ্গে
- কর্মপ্রবাহ
- কর্মপ্রবাহ
- কারখানা
- কর্মশালা
- লেখা
- আপনি
- আপনার
- zephyrnet