সম্পাদক দ্বারা চিত্র
কী Takeaways
- টি-টেস্ট হল একটি পরিসংখ্যানগত পরীক্ষা যা ডেটার দুটি স্বাধীন নমুনার মাধ্যমের মধ্যে উল্লেখযোগ্য পার্থক্য আছে কিনা তা নির্ধারণ করতে ব্যবহার করা যেতে পারে।
- আইরিস ডেটাসেট এবং পাইথনের সিপি লাইব্রেরি ব্যবহার করে কীভাবে একটি টি-টেস্ট প্রয়োগ করা যেতে পারে তা আমরা চিত্রিত করি।
টি-টেস্ট হল একটি পরিসংখ্যানগত পরীক্ষা যা ডেটার দুটি স্বাধীন নমুনার মাধ্যমের মধ্যে উল্লেখযোগ্য পার্থক্য আছে কিনা তা নির্ধারণ করতে ব্যবহার করা যেতে পারে। এই টিউটোরিয়ালে, আমরা টি-টেস্টের সবচেয়ে মৌলিক সংস্করণটি চিত্রিত করেছি, যার জন্য আমরা ধরে নেব যে দুটি নমুনার মধ্যে সমান পার্থক্য রয়েছে। টি-পরীক্ষার অন্যান্য উন্নত সংস্করণগুলির মধ্যে রয়েছে ওয়েলচের টি-পরীক্ষা, যা টি-পরীক্ষার একটি অভিযোজন, এবং যখন দুটি নমুনার অসম বৈচিত্র্য এবং সম্ভবত অসম নমুনার আকার থাকে তখন এটি আরও নির্ভরযোগ্য।
t পরিসংখ্যান বা টি-মান নিম্নরূপ গণনা করা হয়:
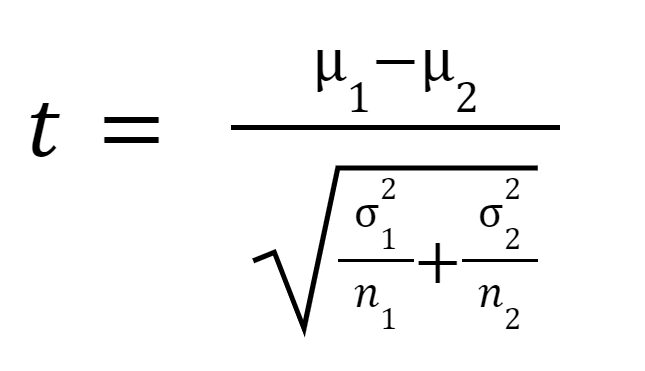
কোথায়
নমুনা 1 এর গড়,
নমুনা 2 এর গড়,
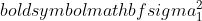 নমুনা 1 এর পার্থক্য হল,
নমুনা 1 এর পার্থক্য হল, 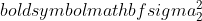 নমুনা 2 এর পার্থক্য হল,
নমুনা 2 এর পার্থক্য হল, 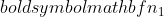 নমুনা 1 এর নমুনা আকার, এবং
নমুনা 1 এর নমুনা আকার, এবং 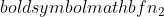 নমুনা 2 এর নমুনা আকার।
নমুনা 2 এর নমুনা আকার।
টি-টেস্টের ব্যবহার ব্যাখ্যা করার জন্য, আমরা আইরিস ডেটাসেট ব্যবহার করে একটি সাধারণ উদাহরণ দেখাব। ধরুন আমরা দুটি স্বাধীন নমুনা পর্যবেক্ষণ করি, যেমন ফুলের সেপালের দৈর্ঘ্য, এবং আমরা বিবেচনা করছি যে দুটি নমুনা একই জনসংখ্যা থেকে (যেমন একই প্রজাতির ফুল বা একই ধরনের সেপাল বৈশিষ্ট্যযুক্ত দুটি প্রজাতি) বা দুটি ভিন্ন জনসংখ্যা থেকে নেওয়া হয়েছে কিনা।
টি-পরীক্ষা দুটি নমুনার পাটিগণিত উপায়ের মধ্যে পার্থক্য পরিমাপ করে। শূন্য অনুমান (যে নমুনাগুলি একই জনসংখ্যার মানে সহ জনসংখ্যা থেকে আঁকা হয়েছে) সত্য বলে অনুমান করে, পি-মান পর্যবেক্ষণ করা ফলাফলগুলি পাওয়ার সম্ভাবনার পরিমাণ নির্ধারণ করে৷ একটি নির্বাচিত থ্রেশহোল্ডের চেয়ে বড় একটি পি-মান (যেমন 5% বা 0.05) ইঙ্গিত দেয় যে আমাদের পর্যবেক্ষণটি ঘটনাক্রমে ঘটে যাওয়ার সম্ভাবনা কম নয়। অতএব, আমরা সমান জনসংখ্যার অর্থের শূন্য অনুমান গ্রহণ করি। যদি পি-মান আমাদের থ্রেশহোল্ডের চেয়ে ছোট হয়, তাহলে আমাদের কাছে সমান জনসংখ্যার অর্থের শূন্য অনুমানের বিরুদ্ধে প্রমাণ আছে।
টি-টেস্ট ইনপুট
একটি টি-পরীক্ষা সম্পাদনের জন্য প্রয়োজনীয় ইনপুট বা পরামিতিগুলি হল:
- দুটি অ্যারে a এবং b নমুনা 1 এবং নমুনা 2 এর ডেটা রয়েছে
টি-টেস্ট আউটপুট
টি-পরীক্ষা নিম্নলিখিতগুলি প্রদান করে:
- গণনা করা টি-পরিসংখ্যান
- পি-মান
প্রয়োজনীয় লাইব্রেরি আমদানি করুন
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
আইরিস ডেটাসেট লোড করুন
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
নমুনা উপায় এবং নমুনা বৈচিত্র গণনা
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
টি-পরীক্ষা বাস্তবায়ন করুন
stats.ttest_ind(a_1, b_1, equal_var = False)
আউটপুট
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
আউটপুট
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
আউটপুট
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)পর্যবেক্ষণ
আমরা লক্ষ্য করি যে "সমান-ভার" প্যারামিটারের জন্য "সত্য" বা "মিথ্যা" ব্যবহার করা টি-পরীক্ষার ফলাফলকে ততটা পরিবর্তন করে না। আমরা আরও লক্ষ্য করি যে a_1 এবং b_1 নমুনা অ্যারেগুলির ক্রম পরিবর্তন করলে একটি নেতিবাচক t-পরীক্ষার মান পাওয়া যায়, কিন্তু প্রত্যাশিত হিসাবে t-পরীক্ষার মানের মাত্রা পরিবর্তন হয় না। যেহেতু গণনা করা p-মান 0.05-এর থ্রেশহোল্ড মানের থেকে অনেক বড়, তাই আমরা নমুনা 1 এবং নমুনা 2-এর মধ্যকার পার্থক্য যে তাৎপর্যপূর্ণ তা বাতিল অনুমানকে প্রত্যাখ্যান করতে পারি। এটি দেখায় যে নমুনা 1 এবং নমুনা 2 এর জন্য সেপালের দৈর্ঘ্য একই জনসংখ্যার ডেটা থেকে আঁকা হয়েছিল।
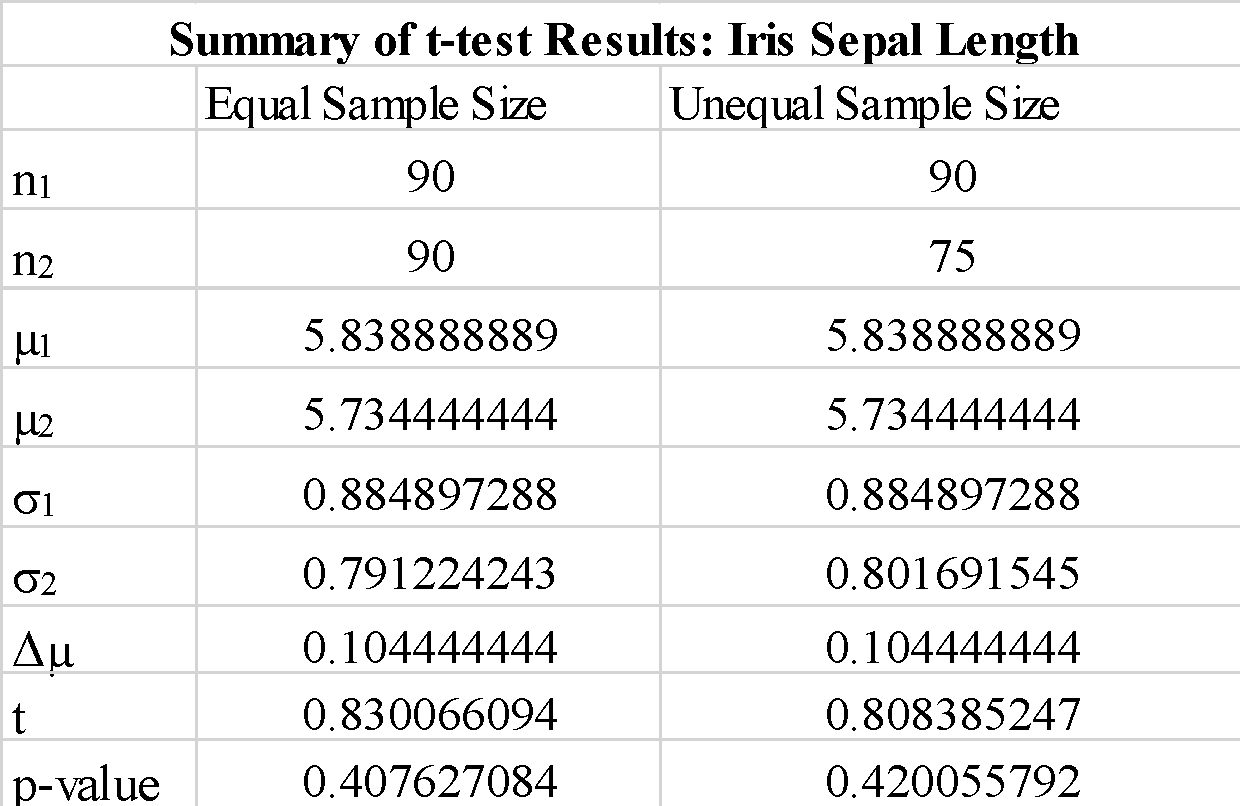
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
নমুনা উপায় এবং নমুনা বৈচিত্র গণনা
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
টি-পরীক্ষা বাস্তবায়ন করুন
stats.ttest_ind(a_1, b_1, equal_var = False)
আউটপুট
stats.ttest_ind(a_1, b_1, equal_var = False)পর্যবেক্ষণ
আমরা লক্ষ্য করি যে অসম আকারের নমুনাগুলি ব্যবহার করে টি-পরিসংখ্যান এবং পি-মান উল্লেখযোগ্যভাবে পরিবর্তন হয় না।
সংক্ষেপে, আমরা দেখিয়েছি কিভাবে একটি সাধারণ টি-টেস্ট পাইথনে স্কাইপি লাইব্রেরি ব্যবহার করে প্রয়োগ করা যেতে পারে।
বেঞ্জামিন ও. তাইয়ো একজন পদার্থবিদ, ডেটা সায়েন্স এডুকেটর এবং লেখক, সেইসাথে ডেটাসায়েন্সহাবের মালিক৷ পূর্বে, বেঞ্জামিন সেন্ট্রাল ওকলাহোমা, গ্র্যান্ড ক্যানিয়ন ইউ. এবং পিটসবার্গ স্টেট ইউ-তে ইঞ্জিনিয়ারিং এবং পদার্থবিদ্যা পড়াচ্ছিলেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- সমর্থন দিন
- অগ্রসর
- বিরুদ্ধে
- এবং
- ফলিত
- মৌলিক
- বেঞ্জামিন
- মধ্যে
- গণিত
- মধ্য
- সুযোগ
- পরিবর্তন
- বৈশিষ্ট্য
- মনোনীত
- বিবেচনা করা
- পারা
- উপাত্ত
- তথ্য বিজ্ঞান
- ডেটাসেট
- নির্ধারণ
- পার্থক্য
- বিভিন্ন
- টানা
- প্রকৌশল
- প্রমান
- উদাহরণ
- প্রত্যাশিত
- ফুল
- অনুসরণ
- অনুসরণ
- থেকে
- কিভাবে
- HTTPS দ্বারা
- বাস্তবায়িত
- আমদানি
- in
- অন্তর্ভুক্ত করা
- স্বাধীন
- ইঙ্গিত
- কেডনুগেটস
- বৃহত্তর
- লাইব্রেরি
- লিঙ্কডইন
- matplotlib
- মানে
- অধিক
- সেতু
- প্রয়োজনীয়
- নেতিবাচক
- অসাড়
- মান্য করা
- উপগমন
- ঘটেছে
- ওকলাহোমা
- ক্রম
- অন্যান্য
- মালিক
- স্থিতিমাপ
- পরামিতি
- করণ
- পদার্থবিদ্যা
- পিটসবার্গ
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- জনসংখ্যা
- জনসংখ্যা
- পূর্বে
- সম্ভাবনা
- পাইথন
- বিশ্বাসযোগ্য
- ফলাফল
- আয়
- একই
- বিজ্ঞান
- প্রদর্শনী
- প্রদর্শিত
- শো
- গুরুত্বপূর্ণ
- উল্লেখযোগ্যভাবে
- অনুরূপ
- সহজ
- থেকে
- আয়তন
- মাপ
- ক্ষুদ্রতর
- So
- রাষ্ট্র
- পরিসংখ্যানসংক্রান্ত
- পরিসংখ্যান
- সংক্ষিপ্তসার
- শিক্ষাদান
- পরীক্ষা
- সার্জারির
- অতএব
- গোবরাট
- থেকে
- সত্য
- অভিভাবকসংবঁধীয়
- ব্যবহার
- মূল্য
- সংস্করণ
- কিনা
- যে
- ইচ্ছা
- লেখক
- উৎপাদনের
- zephyrnet