الصورة عن طريق Freepik
يشير الذكاء الاصطناعي للمحادثة إلى الوكلاء الافتراضيين وروبوتات الدردشة التي تحاكي التفاعلات البشرية ويمكنها إشراك البشر في المحادثة. أصبح استخدام الذكاء الاصطناعي للمحادثة أسلوب حياة سريعًا - بدءًا من سؤال Alexa إلى "ابحث عن أقرب مطعم” ليطلب من سيري ""إنشاء تذكير" غالبًا ما يتم استخدام المساعدين الافتراضيين وروبوتات الدردشة للإجابة على أسئلة المستهلكين وحل الشكاوى وإجراء الحجوزات وغير ذلك الكثير.
يتطلب تطوير هؤلاء المساعدين الافتراضيين جهدًا كبيرًا. ومع ذلك، فإن فهم التحديات الرئيسية ومعالجتها يمكن أن يؤدي إلى تبسيط عملية التنمية. لقد استخدمت تجربتي المباشرة في إنشاء روبوت دردشة ناضج لمنصة التوظيف كنقطة مرجعية لشرح التحديات الرئيسية والحلول المقابلة لها.
لإنشاء روبوت محادثة يعمل بالذكاء الاصطناعي، يمكن للمطورين استخدام أطر عمل مثل RASA، أو Amazon's Lex، أو Dialogflow من Google لإنشاء روبوتات الدردشة. يفضل معظمهم RASA عندما يخططون لإجراء تغييرات مخصصة أو عندما يكون الروبوت في مرحلة النضج لأنه إطار عمل مفتوح المصدر. الأطر الأخرى مناسبة أيضًا كنقطة انطلاق.
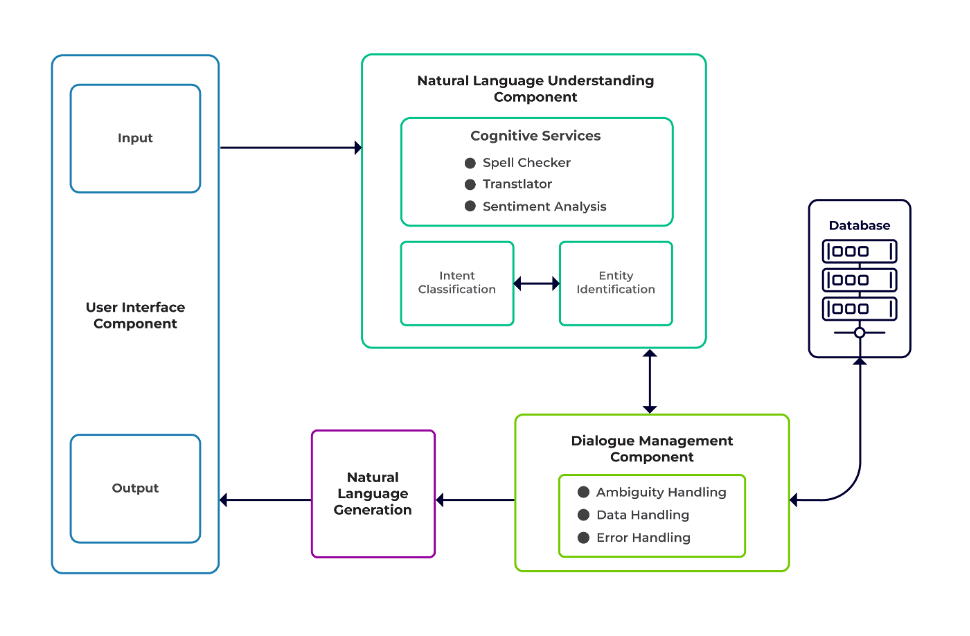
يمكن تصنيف التحديات إلى ثلاثة مكونات رئيسية لروبوت الدردشة.
فهم اللغة الطبيعية (NLU) هي قدرة الروبوت على فهم الحوار البشري. يقوم بتصنيف النية واستخراج الكيان واسترجاع الاستجابات.
مدير الحوار مسؤول عن مجموعة من الإجراءات التي سيتم تنفيذها بناءً على المجموعة الحالية والسابقة من مدخلات المستخدم. يأخذ النية والكيانات كمدخلات (كجزء من المحادثة السابقة) ويحدد الاستجابة التالية.
توليد اللغة الطبيعية (NLG) هي عملية توليد جمل مكتوبة أو منطوقة من بيانات معينة. فهو يقوم بتأطير الاستجابة، والتي يتم تقديمها بعد ذلك للمستخدم.
الصورة من برنامج Talentica
البيانات غير كافية
عندما يستبدل المطورون الأسئلة الشائعة أو أنظمة الدعم الأخرى ببرنامج chatbot، فإنهم يحصلون على قدر لا بأس به من بيانات التدريب. لكن الشيء نفسه لا يحدث عندما يقومون بإنشاء الروبوت من الصفر. في مثل هذه الحالات، يقوم المطورون بإنشاء بيانات التدريب بشكل صناعي.
ماذا ستفعلين.. إذًا؟
يمكن لمولد البيانات القائم على القالب إنشاء قدر لا بأس به من استعلامات المستخدم للتدريب. بمجرد أن يصبح برنامج الدردشة الآلي جاهزًا، يمكن لأصحاب المشروع عرضه لعدد محدود من المستخدمين لتعزيز بيانات التدريب وترقيتها خلال فترة معينة.
اختيار نموذج غير مناسب
يعد اختيار النموذج المناسب وبيانات التدريب أمرًا بالغ الأهمية للحصول على أفضل نتائج استخراج النية والكيان. عادةً ما يقوم المطورون بتدريب روبوتات الدردشة على لغة ومجال محددين، وغالبًا ما تكون معظم النماذج المدربة مسبقًا متاحة خاصة بالمجال ويتم تدريبها بلغة واحدة.
يمكن أن تكون هناك حالات لغات مختلطة أيضًا حيث يكون الأشخاص متعددي اللغات. وقد يقومون بإدخال استعلامات بلغة مختلطة. على سبيل المثال، في المنطقة التي يهيمن عليها الفرنسيون، قد يستخدم الأشخاص نوعًا من اللغة الإنجليزية عبارة عن مزيج من اللغتين الفرنسية والإنجليزية.
ماذا ستفعلين.. إذًا؟
إن استخدام النماذج المدربة بلغات متعددة يمكن أن يقلل من المشكلة. يمكن أن يكون النموذج المُدرب مسبقًا مثل LaBSE (تضمين جملة بيرت الحيادية اللغة) مفيدًا في مثل هذه الحالات. يتم تدريب LaBSE على أكثر من 109 لغة في مهمة تشابه الجملة. يعرف النموذج بالفعل كلمات مماثلة بلغة مختلفة. في مشروعنا، كان الأمر جيدًا حقًا.
استخراج الكيان غير لائق
تتطلب Chatbots من الكيانات تحديد نوع البيانات التي يبحث عنها المستخدم. تتضمن هذه الكيانات الوقت والمكان والشخص والعنصر والتاريخ وما إلى ذلك. ومع ذلك، قد تفشل الروبوتات في تحديد كيان من اللغة الطبيعية:
نفس السياق ولكن كيانات مختلفة. على سبيل المثال، يمكن للروبوتات أن تخلط بين مكان ما باعتباره كيانًا عندما يكتب المستخدم "اسم الطلاب من IIT Delhi" ثم "اسم الطلاب من بنغالورو".
السيناريوهات التي يتم فيها التنبؤ الخاطئ بالكيانات مع انخفاض الثقة. على سبيل المثال، يمكن للروبوت تحديد IIT Delhi كمدينة ذات ثقة منخفضة.
استخراج الكيان الجزئي بواسطة نموذج التعلم الآلي. إذا كتب المستخدم "طلاب من IIT Delhi"، فيمكن للنموذج تحديد "IIT" فقط ككيان بدلاً من "IIT Delhi".
يمكن أن تؤدي المدخلات المكونة من كلمة واحدة والتي ليس لها سياق إلى إرباك نماذج التعلم الآلي. على سبيل المثال، كلمة مثل "Rishikesh" يمكن أن تعني اسم شخص بالإضافة إلى اسم مدينة.
ماذا ستفعلين.. إذًا؟
يمكن أن تكون إضافة المزيد من الأمثلة التدريبية حلاً. ولكن هناك حدًا لن يساعد بعده إضافة المزيد. علاوة على ذلك، فهي عملية لا نهاية لها. قد يكون الحل الآخر هو تحديد أنماط التعبير العادي باستخدام كلمات محددة مسبقًا للمساعدة في استخراج الكيانات بمجموعة معروفة من القيم المحتملة، مثل المدينة والبلد وما إلى ذلك.
تشترك النماذج في ثقة أقل عندما لا تكون متأكدة من التنبؤ بالكيان. يمكن للمطورين استخدام هذا كمشغل لاستدعاء مكون مخصص يمكنه تصحيح الكيان منخفض الثقة. دعونا نفكر في المثال أعلاه. لو IIT دلهي من المتوقع أن تكون مدينة ذات ثقة منخفضة، ثم يمكن للمستخدم دائمًا البحث عنها في قاعدة البيانات. بعد الفشل في العثور على الكيان المتوقع في ملف المدينة الجدول، سينتقل النموذج إلى جداول أخرى، وفي النهاية، سيجده في معهد الجدول، مما أدى إلى تصحيح الكيان.
تصنيف النية الخاطئة
كل رسالة مستخدم لها غرض ما مرتبط بها. نظرًا لأن المقاصد تستمد المسار التالي لإجراءات الروبوت، فإن تصنيف استعلامات المستخدم بشكل صحيح مع النية أمر بالغ الأهمية. ومع ذلك، يجب على المطورين تحديد المقاصد مع الحد الأدنى من الارتباك عبر المقاصد. خلاف ذلك، يمكن أن تكون هناك حالات التنصت على الارتباك. على سبيل المثال، "أرني المراكز المفتوحة" ضد. "أرني مرشحي المناصب المفتوحة ".
ماذا ستفعلين.. إذًا؟
هناك طريقتان للتمييز بين الاستعلامات المربكة. أولاً، يمكن للمطور تقديم نية فرعية. ثانيًا، يمكن للنماذج التعامل مع الاستعلامات بناءً على الكيانات المحددة.
يجب أن يكون برنامج الدردشة الآلي الخاص بالمجال نظامًا مغلقًا حيث يجب أن يحدد بوضوح ما يمكنه فعله وما لا يمكنه فعله. يجب على المطورين القيام بالتطوير على مراحل أثناء التخطيط لروبوتات الدردشة الخاصة بالمجال. وفي كل مرحلة، يمكنهم تحديد الميزات غير المدعومة لروبوت الدردشة (عبر نية غير مدعومة).
يمكنهم أيضًا تحديد ما لا يستطيع برنامج الدردشة الآلي التعامل معه بقصد "خارج النطاق". ولكن قد تكون هناك حالات يتم فيها الخلط بين الروبوت بسبب نية غير مدعومة وخارجة عن النطاق. بالنسبة لمثل هذه السيناريوهات، يجب أن تكون هناك آلية احتياطية حيث، إذا كانت ثقة النية أقل من الحد الأدنى، يمكن للنموذج أن يعمل بأمان مع نية احتياطية للتعامل مع حالات الارتباك.
بمجرد أن يحدد الروبوت الغرض من رسالة المستخدم، يجب عليه إرسال رد مرة أخرى. يقرر الروبوت الاستجابة بناءً على مجموعة معينة من القواعد والقصص المحددة. على سبيل المثال، يمكن أن تكون القاعدة بسيطة مثل المطلق "صباح الخير" عندما يحيي المستخدم "أهلاً". ومع ذلك، في أغلب الأحيان، تشتمل المحادثات مع روبوتات الدردشة على تفاعل متابعة، وتعتمد استجاباتها على السياق العام للمحادثة.
ماذا ستفعلين.. إذًا؟
للتعامل مع هذه المشكلة، يتم تغذية برامج الدردشة الآلية بأمثلة محادثة حقيقية تسمى القصص. ومع ذلك، لا يتفاعل المستخدمون دائمًا على النحو المنشود. يجب أن يتعامل برنامج الدردشة الآلي الناضج مع كل هذه الانحرافات بأمان. يمكن للمصممين والمطورين ضمان ذلك إذا لم يركزوا فقط على المسار السعيد أثناء كتابة القصص ولكنهم أيضًا يعملون على المسارات غير السعيدة.
يعتمد تفاعل المستخدم مع روبوتات الدردشة بشكل كبير على استجابات روبوتات الدردشة. قد يفقد المستخدمون اهتمامهم إذا كانت الإجابات آلية للغاية أو مألوفة للغاية. على سبيل المثال، قد لا يحب المستخدم إجابة مثل "لقد كتبت استعلامًا خاطئًا" لإدخال خاطئ على الرغم من أن الاستجابة صحيحة. الإجابة هنا لا تتطابق مع شخصية المساعد.
ماذا ستفعلين.. إذًا؟
يعمل برنامج chatbot كمساعد ويجب أن يمتلك شخصية معينة ونبرة صوت محددة. يجب أن يكونوا مرحبين ومتواضعين، ويجب على المطورين تصميم المحادثات والأقوال وفقًا لذلك. لا ينبغي أن تبدو الاستجابات آلية أو ميكانيكية. على سبيل المثال، يمكن للروبوت أن يقول: "آسف، يبدو أنه ليس لدي أي تفاصيل. هل يمكنك من فضلك إعادة كتابة استفسارك؟" لمعالجة إدخال خاطئ.
تعد روبوتات الدردشة القائمة على LLM (نموذج اللغة الكبيرة) مثل ChatGPT وBard من الابتكارات التي غيرت قواعد اللعبة وقد حسنت قدرات الذكاء الاصطناعي للمحادثة. إنهم ليسوا جيدين فقط في إجراء محادثات مفتوحة تشبه المحادثات البشرية، ولكن يمكنهم أداء مهام مختلفة مثل تلخيص النص وكتابة الفقرة وما إلى ذلك، والتي لم يكن من الممكن تحقيقها مسبقًا إلا من خلال نماذج محددة.
أحد التحديات التي تواجه أنظمة chatbot التقليدية هو تصنيف كل جملة إلى مقاصد وتحديد الاستجابة وفقًا لذلك. هذا النهج غير عملي. غالبًا ما تكون الردود مثل "آسف، لم أتمكن من فهمك" مزعجة. إن أنظمة chatbot التي لا هدف لها هي الطريق إلى الأمام، ويمكن لـ LLMs أن تجعل هذا حقيقة واقعة.
يمكن لـ LLMs تحقيق أحدث النتائج بسهولة في التعرف على الكيانات المسماة بشكل عام باستثناء التعرف على كيانات معينة خاصة بالمجال. يمكن أن يلهم النهج المختلط لاستخدام LLMs مع أي إطار عمل chatbot نظام chatbot أكثر نضجًا وقوة.
مع أحدث التطورات والأبحاث المستمرة في مجال الذكاء الاصطناعي للمحادثة، تتحسن روبوتات الدردشة كل يوم. تحظى مجالات مثل التعامل مع المهام المعقدة ذات الأغراض المتعددة، مثل "حجز رحلة إلى مومباي وترتيب سيارة أجرة إلى دادار"، باهتمام كبير.
سيتم إجراء محادثات مخصصة قريبًا بناءً على خصائص المستخدم للحفاظ على تفاعله. على سبيل المثال، إذا وجد الروبوت أن المستخدم غير سعيد، فإنه يعيد توجيه المحادثة إلى وكيل حقيقي. بالإضافة إلى ذلك، مع بيانات chatbot المتزايدة باستمرار، يمكن لتقنيات التعلم العميق مثل ChatGPT إنشاء ردود تلقائيًا على الاستعلامات باستخدام قاعدة المعرفة.
سومان سوراف هو عالم بيانات في شركة Talentica Software، وهي شركة لتطوير منتجات البرمجيات. وهو أحد خريجي NIT Agartala ويتمتع بخبرة تزيد عن 8 سنوات في تصميم وتنفيذ حلول الذكاء الاصطناعي الثورية باستخدام البرمجة اللغوية العصبية والذكاء الاصطناعي للمحادثة والذكاء الاصطناعي التوليدي.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :لديها
- :يكون
- :ليس
- :أين
- 8
- a
- القدرة
- من نحن
- فوق
- وفقا لذلك
- التأهيل
- تحقق
- في
- الإجراءات
- مضيفا
- وبالإضافة إلى ذلك
- العنوان
- معالجة
- التطورات
- بعد
- الوكيل
- عملاء
- AI
- منظمة العفو الدولية chatbot
- اليكسا
- الكل
- سابقا
- أيضا
- ألمونيومي
- دائما
- كمية
- an
- و
- آخر
- إجابة
- أي وقت
- نهج
- هي
- المناطق
- AS
- يسأل
- المساعد
- مساعدين
- أسوشيتد
- At
- اهتمام
- تلقائيا
- متاح
- تجنب
- الى الخلف
- قاعدة
- على أساس
- BE
- أن تصبح
- البشر
- أقل من
- أفضل
- أفضل
- أحذية طويلة
- على حد سواء
- البوتات
- نساعدك في بناء
- لكن
- by
- دعوة
- تسمى
- CAN
- لا تستطيع
- قدرات
- قادر على
- الحالات
- التصنيف
- معين
- التحديات
- التغييرات
- الخصائص
- chatbot
- chatbots
- شات جي بي تي
- المدينة
- تصنيف
- مبوب
- بوضوح
- صندوق توظيف برأس مال محدود
- حول الشركة
- شكاوي
- مجمع
- عنصر
- مكونات
- فهم
- الثقة
- الخلط
- مربك
- ارتباك
- نظر
- سياق الكلام
- متواصل
- محادثة
- تحادثي
- محادثة منظمة العفو الدولية
- المحادثات
- تصحيح
- بشكل صحيح
- المقابلة
- استطاع
- البلد
- الدورة
- خلق
- خلق
- حاسم
- حالياًّ
- على
- البيانات
- عالم البيانات
- قاعدة البيانات
- التاريخ
- يوم
- لائق
- اتخاذ القرار
- عميق
- التعلم العميق
- حدد
- تعريف
- دلهي
- تعتمد
- استخلاص
- تصميم
- المصممين
- تصميم
- تفاصيل
- المطور
- المطورين
- التطوير التجاري
- dialogflow
- حوار
- مختلف
- تميز
- do
- لا
- نطاق
- لا
- كل
- في وقت سابق
- بسهولة
- جهد
- تضمين
- التي لا نهاية لها
- جذب
- مخطوب
- اشتباك
- انجليزي
- تعزيز
- أدخل
- الكيانات
- كيان
- إلخ
- حتى
- في النهاية
- يتزايد باستمرار
- كل
- كل يوم
- مثال
- أمثلة
- الخبره في مجال الغطس
- شرح
- استخراج
- استخلاص
- يفشلون
- الفشل
- مألوف
- FAST
- المميزات
- بنك الاحتياطي الفيدرالي
- ويرى
- طيران
- تركز
- في حالة
- إلى الأمام
- الإطار
- الأطر
- الفرنسية
- تبدأ من
- العلاجات العامة
- توليد
- توليد
- جيل
- توليدي
- الذكاء الاصطناعي التوليدي
- مولد كهربائي
- دولار فقط واحصل على خصم XNUMX% على جميع
- الحصول على
- معطى
- خير
- جوجل
- ضمان
- مقبض
- معالجة
- يحدث
- سعيد
- يملك
- وجود
- he
- بشكل كبير
- مساعدة
- مفيد
- هنا
- كيفية
- كيفية
- لكن
- HTTPS
- الانسان
- متواضع
- i
- محدد
- يحدد
- تحديد
- if
- تحقيق
- تحسن
- in
- تتضمن
- الابتكارات
- إدخال
- المدخلات
- إلهام
- مثل
- بدلًا من ذلك
- معد
- نية
- تفاعل
- تفاعل
- التفاعلات
- مصلحة
- إلى
- تقديم
- IT
- JPG
- م
- KD nuggets
- احتفظ
- القفل
- نوع
- المعرفة
- معروف
- يعرف
- لغة
- اللغات
- كبير
- آخر
- تعلم
- الحياة
- مثل
- مما سيحدث
- محدود
- لينكدين:
- فقد
- منخفض
- خفض
- آلة
- آلة التعلم
- رائد
- جعل
- القيام ب
- مباراة
- ناضج
- مايو..
- me
- تعني
- ميكانيكي
- آلية
- الرسالة
- ربما
- أدنى
- مزيج
- مختلط
- نموذج
- عارضات ازياء
- الأكثر من ذلك
- علاوة على ذلك
- أكثر
- كثيرا
- متعدد
- مومباي
- يجب
- my
- الاسم
- عين
- طبيعي
- اللغة الطبيعية
- التالي
- NLG
- البرمجة اللغوية العصبية
- نلو
- لا
- عدد
- of
- غالبا
- on
- مرة
- فقط
- جاكيت
- المصدر المفتوح
- or
- أخرى
- وإلا
- لنا
- على مدى
- الكلي
- أصحاب
- جزء
- مسار
- مسارات
- أنماط
- مجتمع
- نفذ
- تنفيذ
- ينفذ
- فترة
- شخص
- مخصصه
- مرحلة جديدة
- المراحل
- المكان
- خطة
- تخطيط
- المنصة
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- من فضلك
- البوينت
- ان يرتفع المركز
- تملك
- ممكن
- عملية
- وتوقع
- تنبؤ
- تفضل
- قدم
- سابق
- المشكلة
- والمضي قدما
- عملية المعالجة
- المنتج
- تطوير المنتج
- تنفيذ المشاريع
- الاستفسارات
- الأسئلة المتكررة
- R
- في الخلف
- استعداد
- حقيقي
- واقع
- في الحقيقة
- اعتراف
- تجنيد
- تخفيض
- مرجع
- يشير
- منطقة
- اعتمد
- تذكير
- يحل محل
- تطلب
- يتطلب
- بحث
- حل
- استجابة
- ردود
- مسؤول
- مما أدى
- النتائج
- ثوري
- قوي
- قاعدة
- القواعد
- نفسه
- قول
- سيناريوهات
- عالم
- خدش
- بحث
- البحث
- يبدو
- اختيار
- إرسال
- عقوبة
- يخدم
- طقم
- مشاركة
- ينبغي
- مماثل
- الاشارات
- منذ
- عزباء
- سيري
- تطبيقات الكمبيوتر
- حل
- الحلول
- بعض
- محدد
- تحدث
- المسرح
- ابتداء
- دولة من بين الفن
- قصص
- تبسيط
- عدد الطلبة
- جوهري
- هذه
- مناسب
- الدعم
- نظم الدعم
- بالتأكيد
- صناعيا
- نظام
- أنظمة
- T
- جدول
- أخذ
- يأخذ
- مهمة
- المهام
- تقنيات
- نص
- من
- أن
- •
- من مشاركة
- منهم
- then
- هناك.
- تشبه
- هم
- على الرغم من؟
- ثلاثة
- عتبة
- الوقت
- إلى
- TONE
- نبرة صوت
- جدا
- تقليدي
- قطار
- متدرب
- قادة الإيمان
- يثير
- اثنان
- نوع
- أنواع
- فهم
- ترقية
- تستخدم
- مستعمل
- مستخدم
- المستخدمين
- استخدام
- عادة
- القيم
- بواسطة
- افتراضي
- صوت
- vs
- W
- طريق..
- طرق
- ترحيب
- حسن
- ابحث عن
- متى
- كلما
- التي
- في حين
- سوف
- مع
- كلمة
- كلمات
- للعمل
- عمل
- سوف
- جاري الكتابة
- مكتوب
- خاطئ
- سنوات
- لصحتك!
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت