في العالم الحديث ، تعتمد معظم الشركات على قوة البيانات الضخمة والتحليلات لدعم نموها واستثماراتها الاستراتيجية ومشاركة العملاء. البيانات الكبيرة هي الثابت الأساسي في الإعلان المستهدف ، والتسويق المخصص ، وتوصيات المنتج ، وإنشاء الرؤى ، وتحسين الأسعار ، وتحليل المشاعر ، والتحليلات التنبؤية ، وغير ذلك الكثير.
غالبًا ما يتم جمع البيانات من مصادر متعددة وتحويلها وتخزينها ومعالجتها في بحيرات البيانات في أماكن العمل أو على السحابة. في حين أن الاستيعاب الأولي للبيانات بسيط نسبيًا ويمكن تحقيقه من خلال البرامج النصية المخصصة المطورة داخليًا أو أدوات ETL (Extract Transform Load) التقليدية ، فإن المشكلة تصبح معقدة بشكل باهظ ومكلفة لحلها حيث يتعين على الشركات:
- إدارة دورة حياة البيانات الكاملة - لأغراض التدبير المنزلي والامتثال
- تحسين التخزين - لتقليل التكاليف المرتبطة
- تبسيط العمارة - من خلال إعادة استخدام البنية التحتية للحوسبة
- معالجة البيانات بشكل متزايد - من خلال إدارة الدولة القوية
- تطبيق نفس السياسات على الدُفعات والبيانات المتدفقة - بدون ازدواجية الجهود
- الترحيل بين داخل الشركة و Cloud - بأقل جهد
فمن حيث اباتشي Gobblinيأتي دور إدارة البيانات مفتوحة المصدر ونظام التكامل. يوفر Apache Gobblin إمكانات لا مثيل لها يمكن استخدامها كليًا أو أجزاء اعتمادًا على احتياجات العمل.
في هذا القسم ، سوف نتعمق في القدرات المختلفة لـ Apache Gobblin التي تساعد في مواجهة التحديات الموضحة سابقًا.
إدارة دورة حياة البيانات الكاملة
يوفر Apache Gobblin سلسلة كاملة من القدرات لإنشاء خطوط أنابيب بيانات تدعم المجموعة الكاملة من عمليات دورة حياة البيانات في مجموعات البيانات.
- استيعاب البيانات - من مصادر متعددة إلى أحواض تتراوح من قواعد البيانات و Rest APIs وخوادم FTP / SFTP و Filers و CRMs مثل Salesforce و Dynamics والمزيد.
- نسخ البيانات - بين العديد من بحيرات البيانات ذات الإمكانات المتخصصة لنظام الملفات الموزعة Hadoop عبر Distcp-NG.
- تطهير البيانات - استخدام سياسات الاحتفاظ مثل المستندة إلى الوقت ، أو الأحدث K ، أو الإصدار ، أو مجموعة من السياسات.
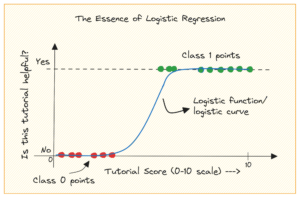
يتكون خط أنابيب Gobblin المنطقي من "المصدر" الذي يحدد توزيع العمل ويخلق "وحدات العمل". ثم يتم اختيار "وحدات العمل" هذه للتنفيذ باعتبارها "مهام" ، والتي تشمل الاستخراج والتحويل وفحص الجودة وكتابة البيانات إلى الوجهة. الخطوة الأخيرة ، "نشر البيانات" ، تتحقق من صحة التنفيذ الناجح لخط الأنابيب وتلتزم ببيانات المخرجات ذريًا ، إذا كانت الوجهة تدعمها.
صورة المؤلف
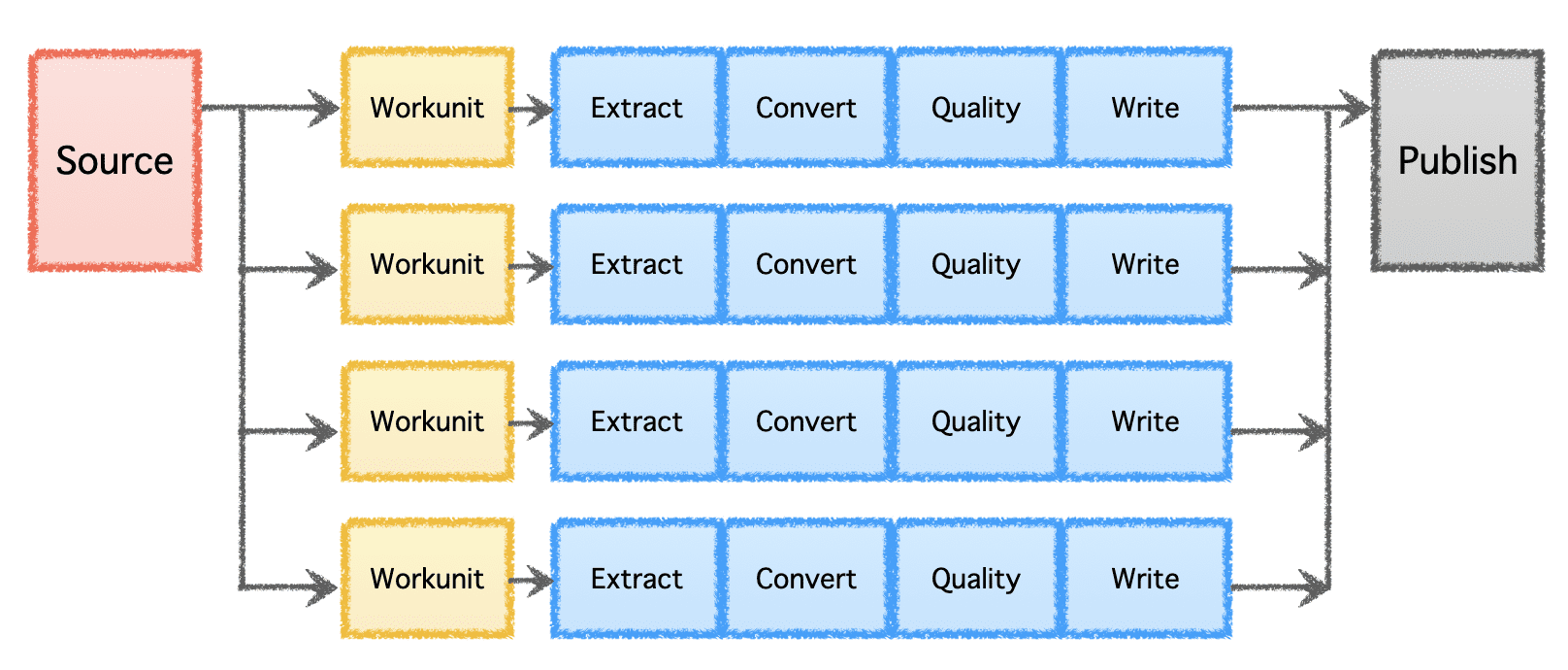
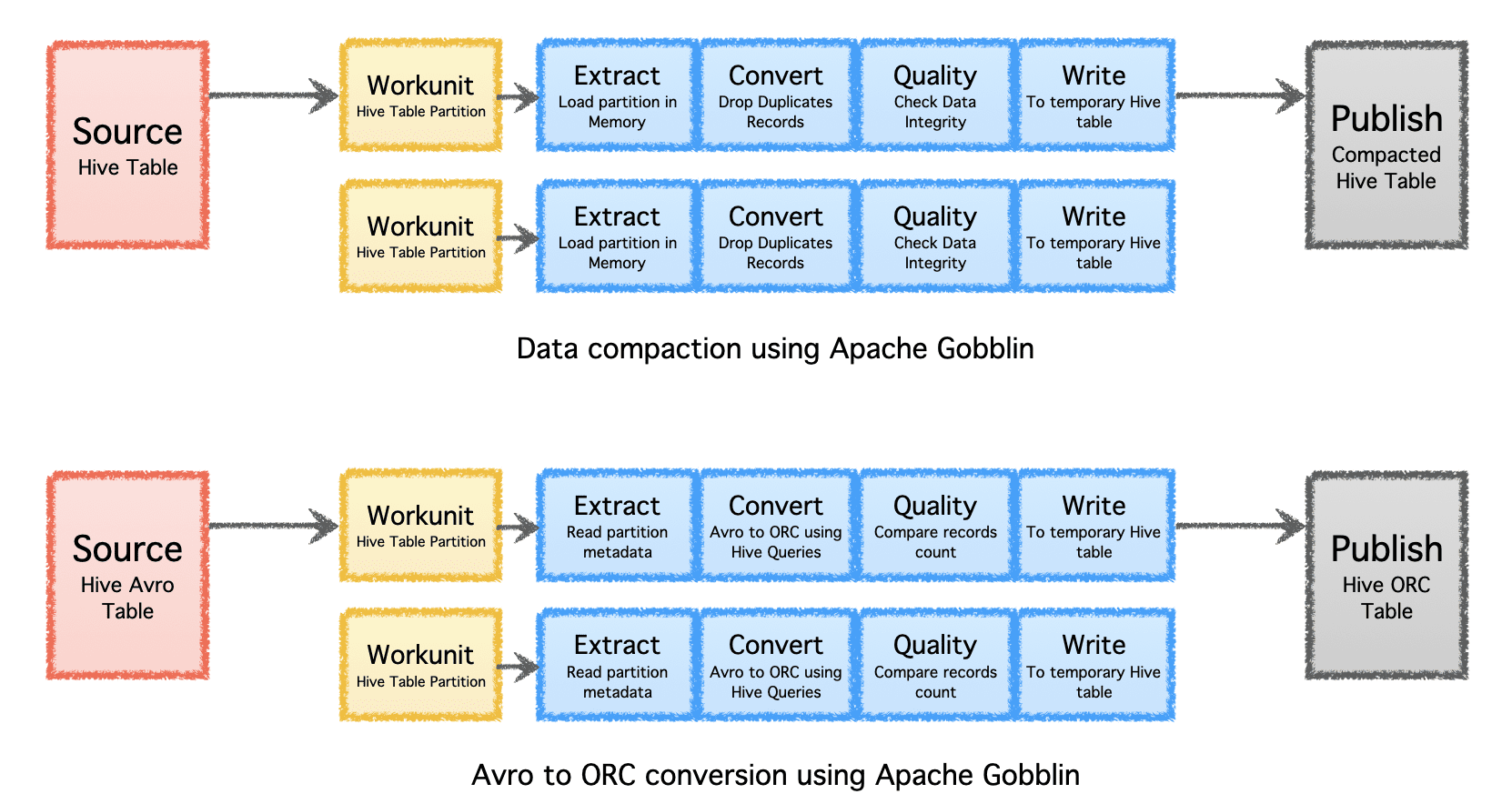
تحسين التخزين
يمكن أن يساعد Apache Gobblin في تقليل مقدار التخزين المطلوب للبيانات من خلال بيانات ما بعد المعالجة بعد الاستيعاب أو النسخ المتماثل من خلال الضغط أو تحويل التنسيق.
- الضغط - بيانات ما بعد المعالجة لإلغاء تكرارها استنادًا إلى جميع الحقول أو الحقول الرئيسية للسجلات ، مع اقتطاع البيانات للاحتفاظ بسجل واحد فقط بأحدث طابع زمني بنفس المفتاح.
- Avro to ORC - كآلية تحويل تنسيق متخصصة لتحويل تنسيق Avro المستند إلى الصفوف إلى تنسيق ORC المستند إلى العمود المحسن للغاية.
صورة المؤلف
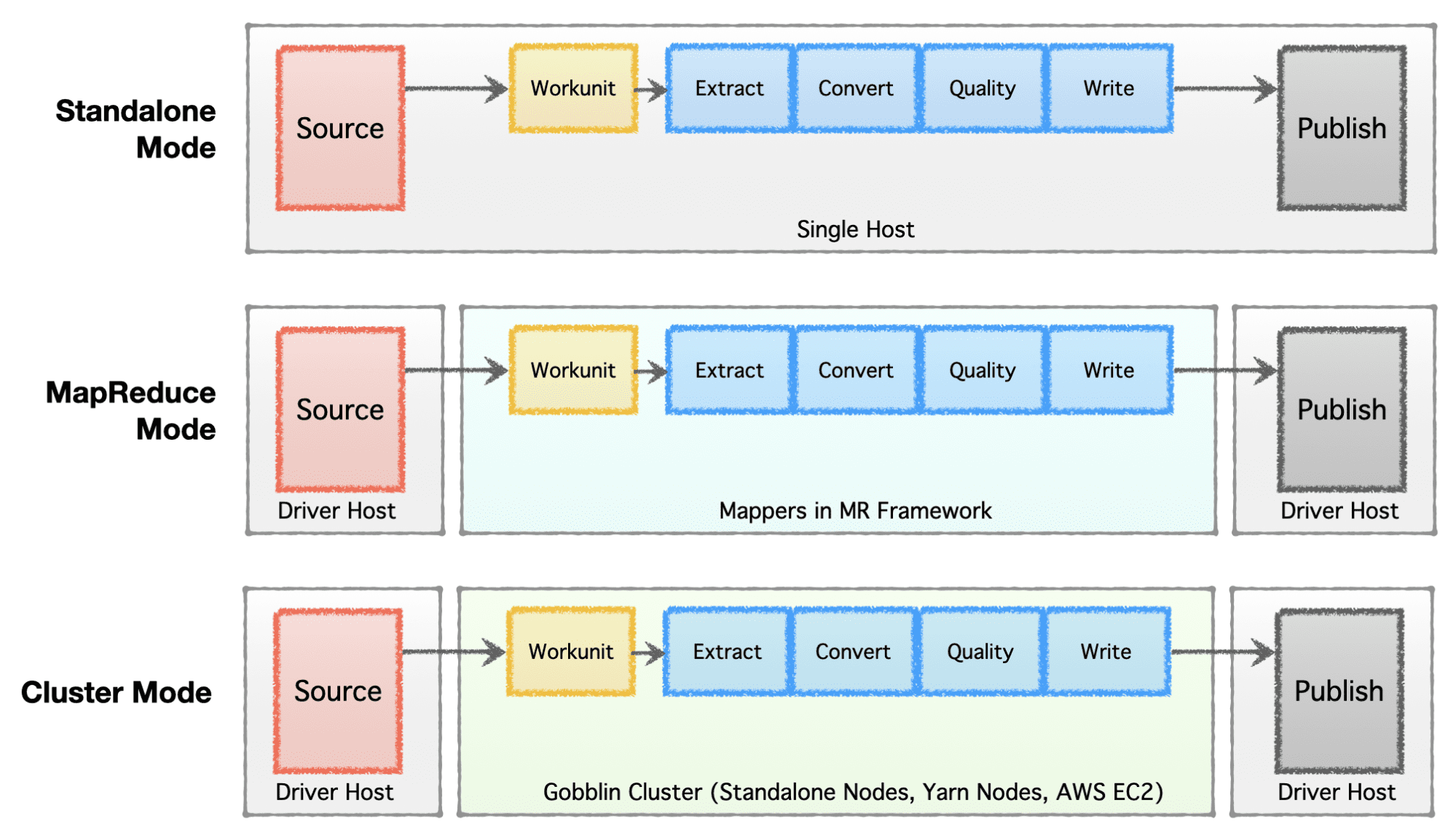
تبسيط العمارة
اعتمادًا على مرحلة الشركة (بدء التشغيل لمؤسسة) ، ومتطلبات الحجم ، والهندسة المعمارية الخاصة بكل منها ، تفضل الشركات إعداد أو تطوير البنية التحتية للبيانات الخاصة بها. Apache Gobblin مرن للغاية ويدعم نماذج تنفيذ متعددة.
- الوضع المستقل - للتشغيل كعملية قائمة بذاتها على صندوق معدني مكشوف ، أي مضيف واحد لحالات الاستخدام البسيطة والمواقف منخفضة المتطلبات.
- وضع MapReduce - للتشغيل كوظيفة MapReduce على البنية التحتية Hadoop لحالات البيانات الكبيرة للتعامل مع مجموعات البيانات التي تتراوح في مقياس بيتابايت.
- وضع الكتلة: مستقل - للتشغيل كمجموعة مدعومة من قبل Apache Helix و Apache Zookeeper على مجموعة من الآلات المعدنية العارية أو الأجهزة المضيفة للتعامل مع نطاق واسع مستقل عن إطار Hadoop MR.
- وضع الكتلة: غزل - للتشغيل كمجموعة على غزل أصلي بدون إطار Hadoop MR.
- وضع الكتلة: AWS - للتشغيل كمجموعة على عرض السحابة العامة من Amazon ، على سبيل المثال. AWS للبنى التحتية المستضافة على AWS.
صورة المؤلف
معالجة البيانات بشكل متزايد
على نطاق كبير مع العديد من خطوط أنابيب البيانات والحجم الكبير ، يجب معالجة البيانات على دفعات وبمرور الوقت. لذلك ، فإنه يستلزم وضع نقاط تفتيش حتى يمكن استئناف خطوط أنابيب البيانات من حيث توقفت في المرة الأخيرة والمتابعة إلى الأمام. يدعم Apache Gobblin العلامات المائية المنخفضة والعالية ويدعم دلالات إدارة الحالة القوية عبر State Store على HDFS و AWS S3 و MySQL والمزيد من الشفافية.
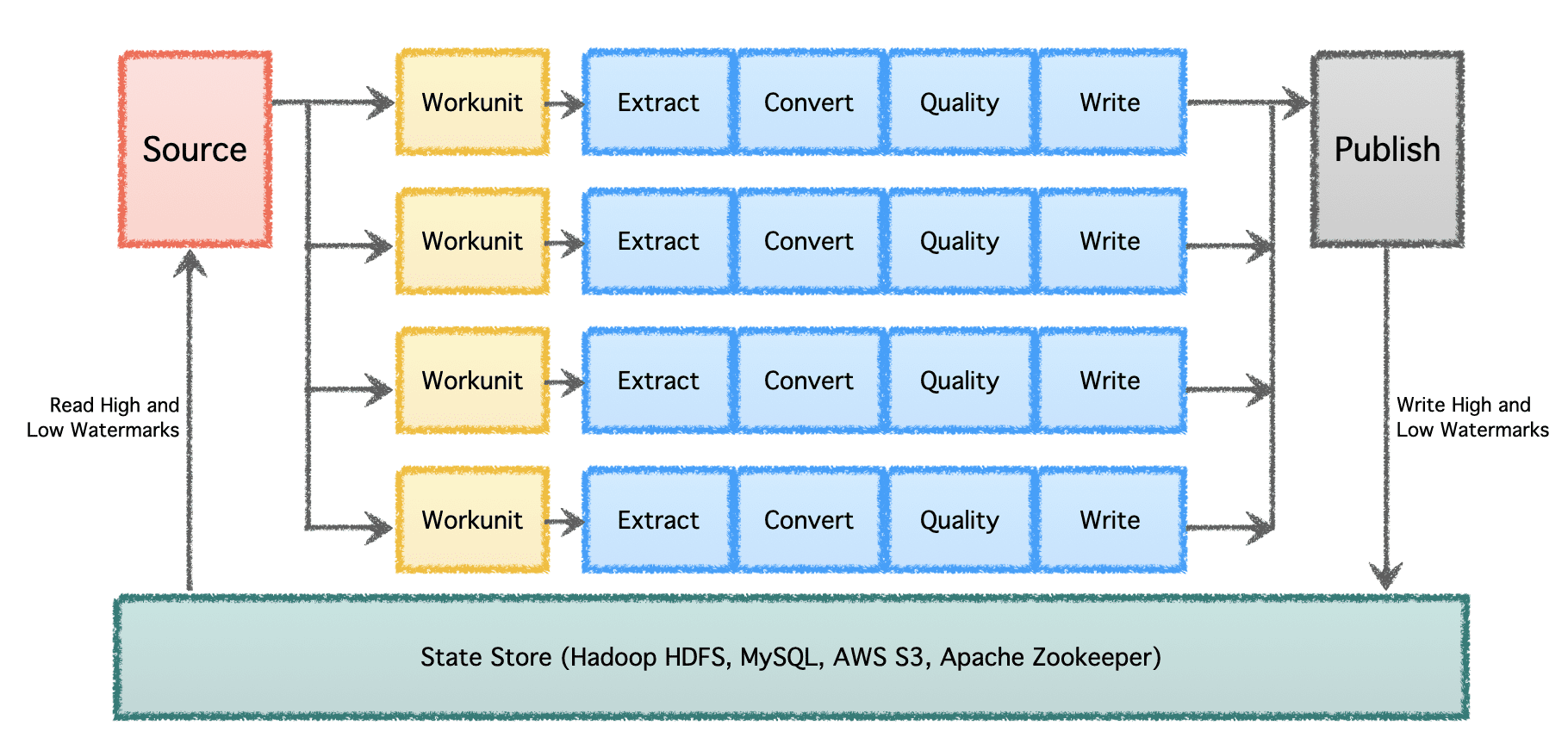
صورة المؤلف
نفس السياسات على الدفعة والبيانات المتدفقة
يجب كتابة معظم خطوط أنابيب البيانات اليوم مرتين ، مرة للبيانات المجمعة ومرة أخرى للبيانات القريبة أو المتدفقة. إنه يضاعف الجهد ويقدم تناقضات في السياسات والخوارزميات المطبقة على أنواع مختلفة من خطوط الأنابيب. يحل Apache Gobblin هذا من خلال السماح للمستخدمين بتأليف خط أنابيب مرة واحدة وتشغيله على كل من بيانات الدُفعات والدفق إذا تم استخدامه في وضع Gobblin Cluster أو Gobblin في وضع AWS أو Gobblin on Yarn.
الترحيل بين On-prem و Cloud
نظرًا لأوضاعها متعددة الاستخدامات التي يمكن تشغيلها محليًا على صندوق واحد أو مجموعة من العقد أو السحابة - يمكن نشر Apache Gobblin واستخدامه محليًا وعلى السحابة. لذلك ، السماح للمستخدمين بكتابة خطوط بياناتهم مرة واحدة وترحيلها جنبًا إلى جنب مع عمليات نشر Gobblin بسهولة بين داخل الشركة والسحابة ، بناءً على احتياجات محددة.
نظرًا لبنيتها المرنة للغاية ، والميزات القوية ، والحجم الهائل لأحجام البيانات التي يمكنها دعمها ومعالجتها ، يتم استخدام Apache Gobblin في البنية التحتية لإنتاج كبرى شركات التكنولوجيا وهو أمر لا بد منه لأي عملية نشر للبنية التحتية للبيانات الضخمة اليوم.
يمكن العثور على مزيد من التفاصيل حول Apache Gobblin وكيفية استخدامه على https://gobblin.apache.org
ابهيشيك تيواري هو مدير أول في LinkedIn ، ويقود مؤسسة خطوط أنابيب البيانات الكبيرة للشركة. وهو أيضًا نائب رئيس Apache Gobblin في مؤسسة Apache Software Foundation وزميل جمعية الكمبيوتر البريطانية.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- تحقق
- معالجة
- الإعلانات
- بعد
- مساعدة
- خوارزميات
- الكل
- السماح
- كمية
- تحليل
- تحليلات
- و
- أباتشي
- واجهات برمجة التطبيقات
- تطبيقي
- هندسة معمارية
- أسوشيتد
- المؤلفة
- AWS
- المدعومة
- على أساس
- يصبح
- ما بين
- كبير
- البيانات الكبيرة
- صندوق
- بريطاني
- الأعمال
- الأعمال
- قدرات
- الحالات
- التحديات
- تدقيق
- سحابة
- كتلة
- مجموعة
- الشركات
- حول الشركة
- مجمع
- الالتزام
- الكمبيوتر
- الحوسبة
- ثابت
- بناء
- استمر
- تحويل
- تحول
- يخلق
- على
- زبون
- إشراك العملاء
- البيانات
- البنية التحتية للبيانات
- إدارة البيانات
- قواعد البيانات
- قواعد البيانات
- اعتمادا
- نشر
- نشر
- نشر
- افضل الرحلات السياحية
- تفاصيل
- يحدد
- المتقدمة
- مختلف
- وزعت
- توزيع
- دينامية
- بسهولة
- جهد
- اشتباك
- مشروع
- الأثير (ETH)
- يتطور
- ذو تكلفة باهظة
- استخراج
- استخلاص
- أقصى
- المميزات
- زميل
- مجال
- قم بتقديم
- نهائي
- مرن
- شكل
- وجدت
- دورة تأسيسية
- الإطار
- تبدأ من
- وقود
- بالإضافة إلى
- جيل
- التسويق
- Hadoop
- مقبض
- مساعدة
- مرتفع
- جدا
- مضيف
- استضافت
- كيفية
- كيفية
- HTTPS
- in
- تتضمن
- مستقل
- البنية التحتية
- البنية التحتية
- في البداية
- رؤى
- التكامل
- يدخل
- الاستثمارات
- IT
- وظيفة
- KD nuggets
- احتفظ
- القفل
- كبير
- اسم العائلة
- آخر
- قيادة
- لينكدين:
- تحميل
- منخفض
- الآلات
- إدارة
- مدير
- التسويق
- آلية
- معدن
- الهجرة
- موضة
- عارضات ازياء
- تقدم
- وسائط
- الأكثر من ذلك
- أكثر
- متعدد
- يجب أن يكون
- MySQL
- محلي
- بحاجة
- إحتياجات
- الأحدث
- العقد
- الوهب
- ONE
- المصدر المفتوح
- عمليات
- منظمة
- أوجز
- أجزاء
- مخصصه
- التقطت
- خط أنابيب
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- سياسات الخصوصية والبيع
- الرائج
- قوة
- قوي
- التحليلات التنبؤية
- تفضل
- رئيس
- سابقا
- السعر
- المشكلة
- عملية المعالجة
- المنتج
- الإنتــاج
- ويوفر
- جمهور
- السحابة العامة
- نشر
- جودة
- بسرعة
- تتراوح
- ساندي خ. ميليك
- سجل
- تسجيل
- تخفيض
- نسبيا
- تكرار
- المتطلبات الأساسية
- هؤلاء
- REST
- استئنف
- استبقاء
- قوي
- يجري
- SALESFORCE
- نفسه
- حجم
- التحجيم
- مخطوطات
- القسم
- دلالات
- كبير
- عاطفة
- طقم
- هام
- الاشارات
- عزباء
- حالات
- So
- جاليات
- تطبيقات الكمبيوتر
- حل
- يحل
- مصدر
- مصادر
- متخصص
- محدد
- المسرح
- مستقل
- بدء التشغيل
- الولايه او المحافظه
- خطوة
- تخزين
- متجر
- تخزين
- إستراتيجي
- مجرى
- متدفق
- ناجح
- جناح
- الدعم
- الدعم
- نظام
- المستهدفة
- المهام
- تكنولوجيا
- •
- من مشاركة
- وبالتالي
- عبر
- الوقت
- الطابع الزمني
- إلى
- اليوم
- أدوات
- تقليدي
- تحول
- تحول
- أنواع
- التي تقوم عليها
- لا نظير له
- تستخدم
- المستخدمين
- مختلف
- متعدد الجوانب
- بواسطة
- Vice President
- حجم
- مجلدات
- التي
- في حين
- سوف
- بدون
- للعمل
- العالم
- اكتب
- جاري الكتابة
- مكتوب
- زفيرنت