صورة المؤلف
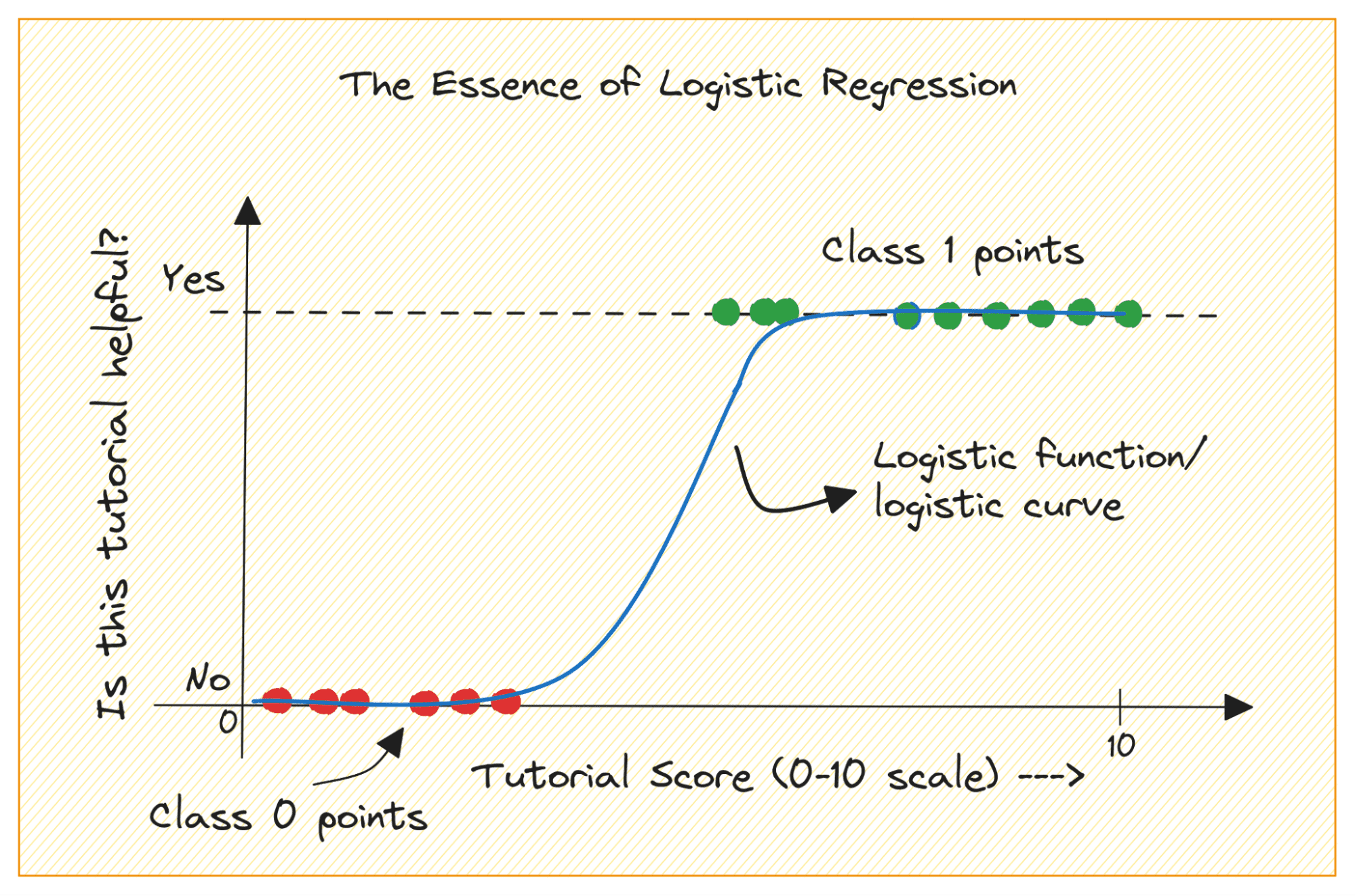
عندما تبدأ في استخدام التعلم الآلي، يعد الانحدار اللوجستي أحد الخوارزميات الأولى التي ستضيفها إلى صندوق الأدوات الخاص بك. إنها خوارزمية بسيطة وقوية، تُستخدم عادةً لمهام التصنيف الثنائي.
النظر في مشكلة التصنيف الثنائي مع الفئتين 0 و 1. الانحدار اللوجستي يناسب وظيفة لوجستية أو سيني لبيانات الإدخال ويتنبأ باحتمالية وجود نقطة بيانات استعلام تنتمي إلى الفئة 1. مثير للاهتمام، نعم؟
في هذا البرنامج التعليمي، سوف نتعرف على الانحدار اللوجستي من الألف إلى الياء:
- الوظيفة اللوجستية (أو السيني).
- كيف ننتقل من الانحدار الخطي إلى الانحدار اللوجستي
- كيف يعمل الانحدار اللوجستي
وأخيرًا، سنقوم ببناء نموذج انحدار لوجستي بسيط تصنيف عوائد الرادار من الغلاف الأيوني.
قبل أن نتعلم المزيد عن الانحدار اللوجستي، دعونا نراجع كيفية عمل الوظيفة اللوجستية. يتم إعطاء الوظيفة اللوجستية (أو الدالة السيني) بواسطة:

عند رسم الدالة السيني، سوف تبدو كما يلي:
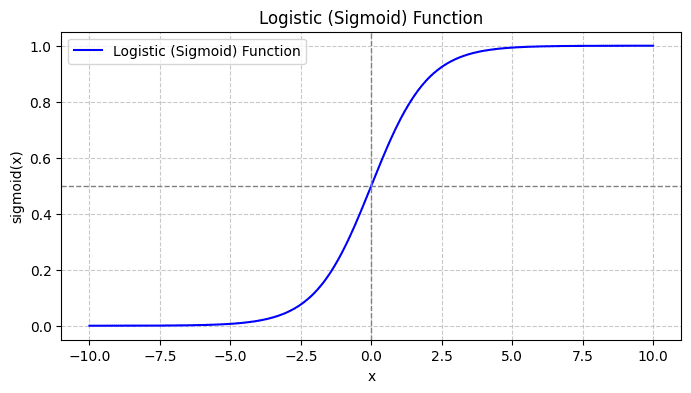
ومن القصة نرى ما يلي:
- عندما تكون x = 0، فإن σ(x) تأخذ القيمة 0.5.
- عندما تقترب x من +∞، فإن σ(x) تقترب من 1.
- عندما تقترب x من -∞، تقترب σ(x) من 0.
لذا، بالنسبة لجميع المدخلات الحقيقية، تقوم الدالة السيني بضغطها لتأخذ قيمًا في النطاق [0، 1].
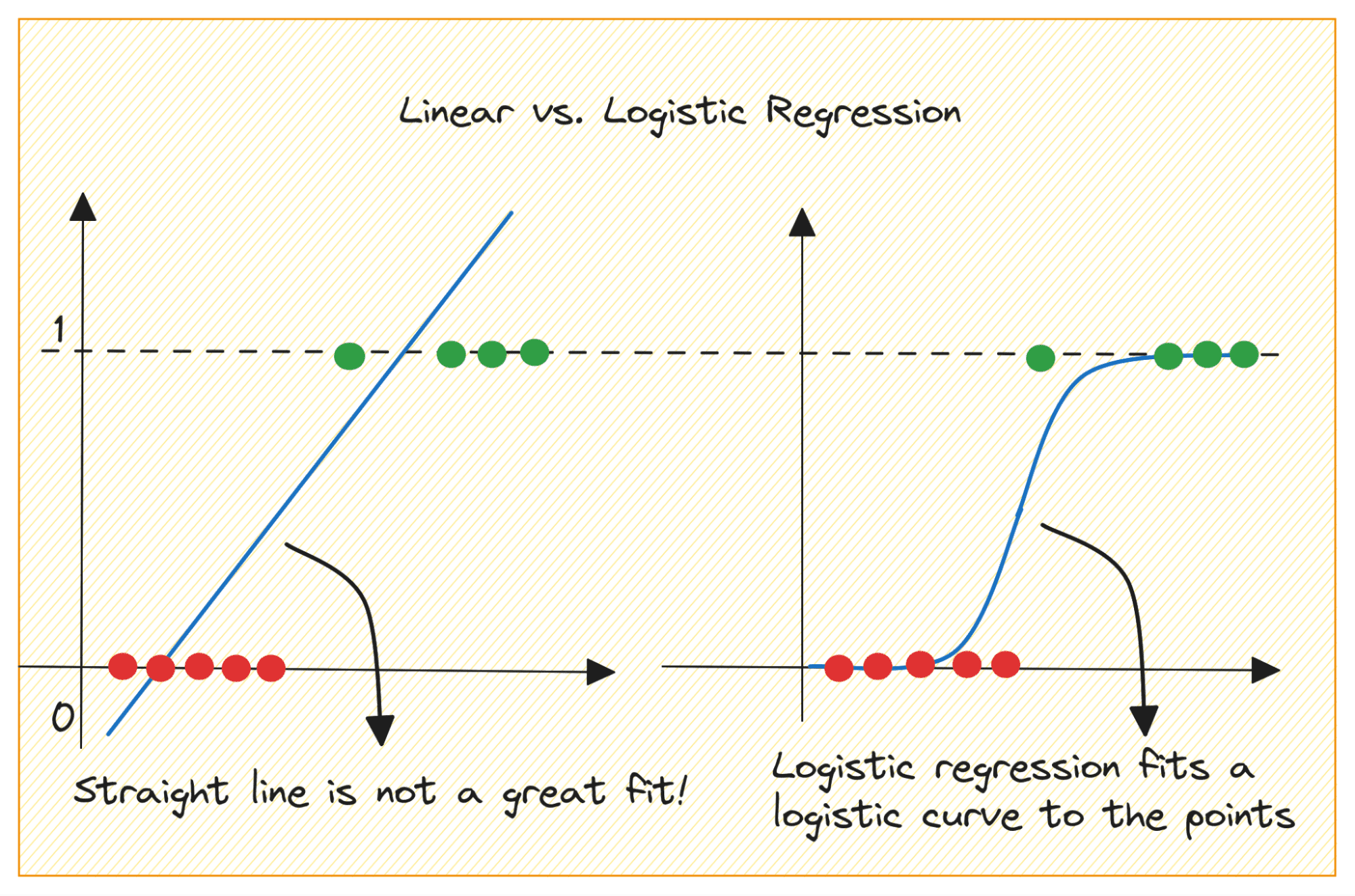
دعونا نناقش أولاً سبب عدم قدرتنا على استخدام الانحدار الخطي لمشكلة التصنيف الثنائي.
في مشكلة التصنيف الثنائي، يكون الإخراج عبارة عن تسمية فئوية (0 أو 1). نظرًا لأن الانحدار الخطي يتنبأ بمخرجات ذات قيمة مستمرة والتي يمكن أن تكون أقل من 0 أو أكبر من 1، فهذا لا معنى له بالنسبة للمشكلة المطروحة.
بالإضافة إلى ذلك، قد لا يكون الخط المستقيم هو الأفضل عندما تنتمي تسميات الإخراج إلى إحدى الفئتين.
صورة المؤلف
فكيف ننتقل من الانحدار الخطي إلى الانحدار اللوجستي؟ في الانحدار الخطي يتم إعطاء الناتج المتوقع بواسطة:
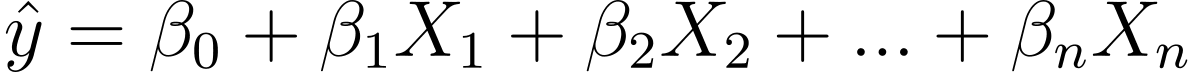
حيث βs هي المعاملات وX_is هي المتنبئات (أو الميزات).
دون فقدان العمومية، لنفترض أن X_0 = 1:

لذلك يمكننا الحصول على تعبير أكثر إيجازا:
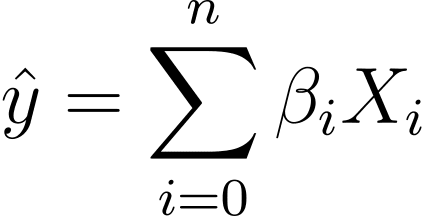
في الانحدار اللوجستي، نحتاج إلى الاحتمالية المتوقعة p_i في الفاصل الزمني [0,1]. نحن نعلم أن الدالة اللوجستية تسحق المدخلات بحيث تأخذ قيمًا في الفاصل الزمني [0,1].
لذا، وبتعويض هذا التعبير في الدالة اللوجستية، نحصل على الاحتمال المتوقع على النحو التالي:
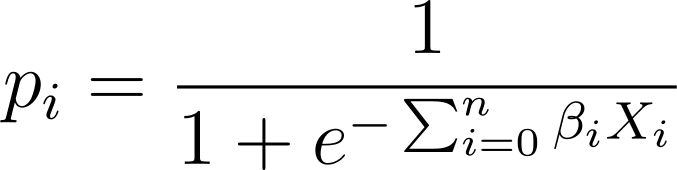
إذًا كيف يمكننا العثور على المنحنى اللوجستي الأفضل لمجموعة البيانات المحددة؟ للإجابة على هذا، دعونا نفهم الحد الأقصى لتقدير الاحتمالية.
تقدير الاحتمالية القصوى (MLE) يستخدم لتقدير معلمات نموذج الانحدار اللوجستي عن طريق تعظيم دالة الاحتمال. دعونا نحلل عملية MLE في الانحدار اللوجستي وكيفية صياغة دالة التكلفة للتحسين باستخدام النسب المتدرج.
كسر تقدير الاحتمالية القصوى
كما تمت مناقشته، فإننا نمثل احتمالية حدوث نتيجة ثنائية كدالة لواحد أو أكثر من متغيرات التوقع (أو الميزات):
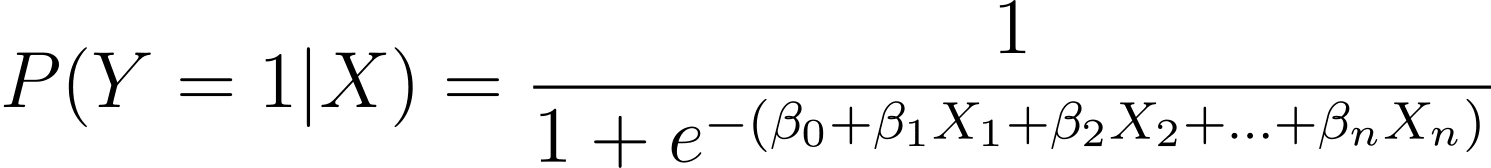
هنا، βs هي معلمات النموذج أو المعاملات. X_1، X_2،…، X_n هي متغيرات التوقع.
يهدف MLE إلى العثور على قيم β التي تزيد من احتمالية البيانات المرصودة. تمثل دالة الاحتمالية، المشار إليها بالرمز L(β)، احتمالية ملاحظة النتائج المعطاة لقيم التنبؤ المحددة بموجب نموذج الانحدار اللوجستي.
صياغة دالة احتمالية السجل
لتبسيط عملية التحسين، من الشائع العمل باستخدام دالة احتمالية السجل. لأنه يحول منتجات الاحتمالات إلى مجموع احتمالات السجل.
يتم إعطاء دالة احتمالية السجل للانحدار اللوجستي بواسطة:
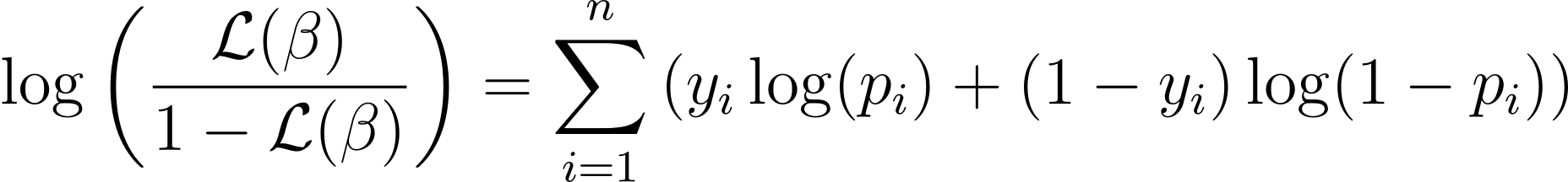
الآن بعد أن عرفنا جوهر احتمالية السجل، فلننتقل إلى صياغة دالة التكلفة للانحدار اللوجستي وبالتالي النسب المتدرج للعثور على أفضل معلمات النموذج
دالة التكلفة للانحدار اللوجستي
لتحسين نموذج الانحدار اللوجستي، نحتاج إلى تعظيم احتمالية السجل. لذلك يمكننا استخدام احتمالية السجل السلبية كدالة تكلفة لتقليلها أثناء التدريب. يتم تعريف احتمالية السجل السلبية، والتي يشار إليها غالبًا بالخسارة اللوجستية، على النحو التالي:
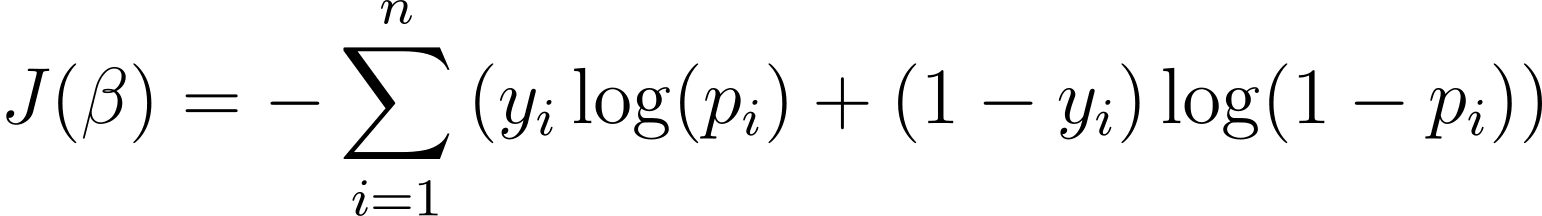
وبالتالي فإن الهدف من خوارزمية التعلم هو العثور على قيم ؟ التي تقلل من وظيفة التكلفة هذه. النزول المتدرج هو خوارزمية تحسين شائعة الاستخدام للعثور على الحد الأدنى من دالة التكلفة هذه.
النسب التدرج في الانحدار اللوجستي
أصل التدرج هي خوارزمية تحسين تكرارية تقوم بتحديث معلمات النموذج β في الاتجاه المعاكس لتدرج دالة التكلفة فيما يتعلق بـ β. قاعدة التحديث في الخطوة t+1 للانحدار اللوجستي باستخدام النسب المتدرج هي كما يلي:
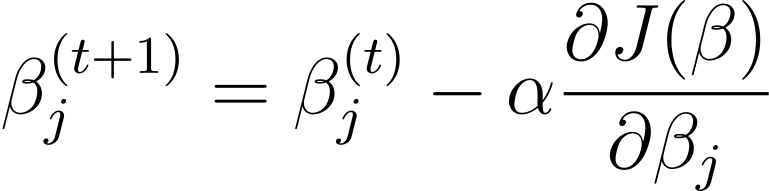
حيث α هو معدل التعلم.
يمكن حساب المشتقات الجزئية باستخدام قاعدة السلسلة. يقوم المنحدر المتدرج بتحديث المعلمات بشكل متكرر - حتى التقارب - بهدف تقليل الخسارة اللوجستية. أثناء تقاربها، تجد القيم المثالية لـ β التي تزيد من احتمالية البيانات المرصودة.
الآن بعد أن عرفت كيفية عمل الانحدار اللوجستي، دعنا نبني نموذجًا تنبؤيًا باستخدام مكتبة scikit-Learn.
سنستخدم مجموعة بيانات الأيونوسفير من مستودع التعلم الآلي UCI لهذا البرنامج التعليمي. تشتمل مجموعة البيانات على 34 ميزة رقمية. يكون الإخراج ثنائيًا، واحدًا من "جيد" أو "سيئ" (يُشار إليه بـ "g" أو "b"). تشير تسمية الإخراج "جيد" إلى عوائد RADAR التي اكتشفت بعض الهياكل في الأيونوسفير.
الخطوة 1 - تحميل مجموعة البيانات
أولاً، قم بتنزيل مجموعة البيانات وقراءتها في إطار بيانات الباندا:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)الخطوة 2 - استكشاف مجموعة البيانات
دعونا نلقي نظرة على الصفوف القليلة الأولى من dataframe:
# Display the first few rows of the DataFrame
df.head()
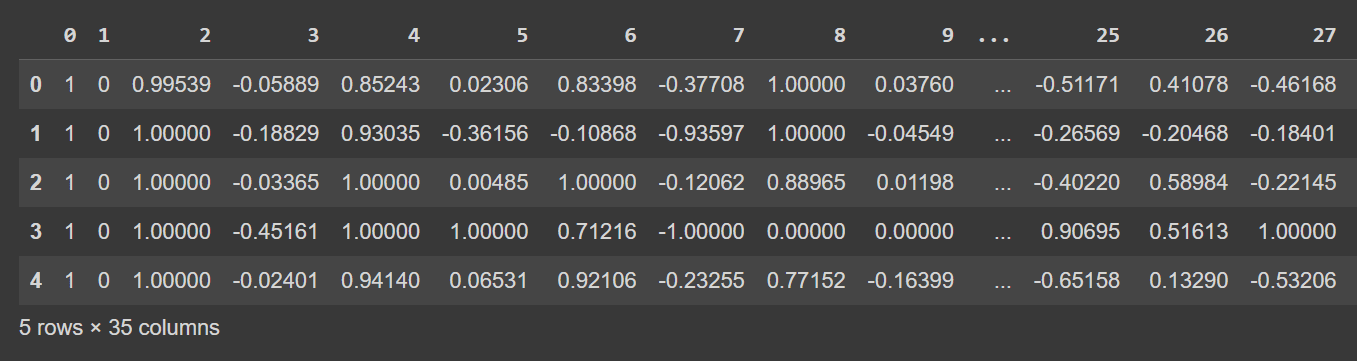
الناتج المقتطع من df.head()
دعنا نحصل على بعض المعلومات حول مجموعة البيانات: عدد القيم غير الخالية وأنواع البيانات لكل عمود:
# Get information about the dataset
print(df.info())
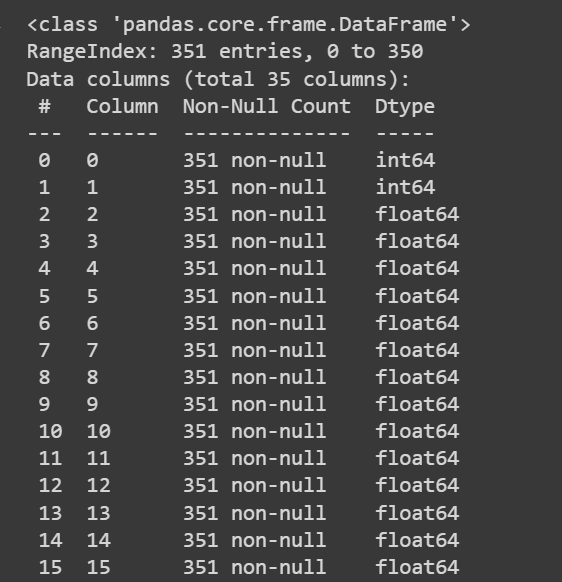 إخراج df.info () مقطوعًا
إخراج df.info () مقطوعًا
نظرًا لأن لدينا جميع الميزات الرقمية، يمكننا أيضًا الحصول على بعض الإحصائيات الوصفية باستخدام describe() الطريقة في إطار البيانات:
# Get descriptive statistics of the dataset
print(df.describe())
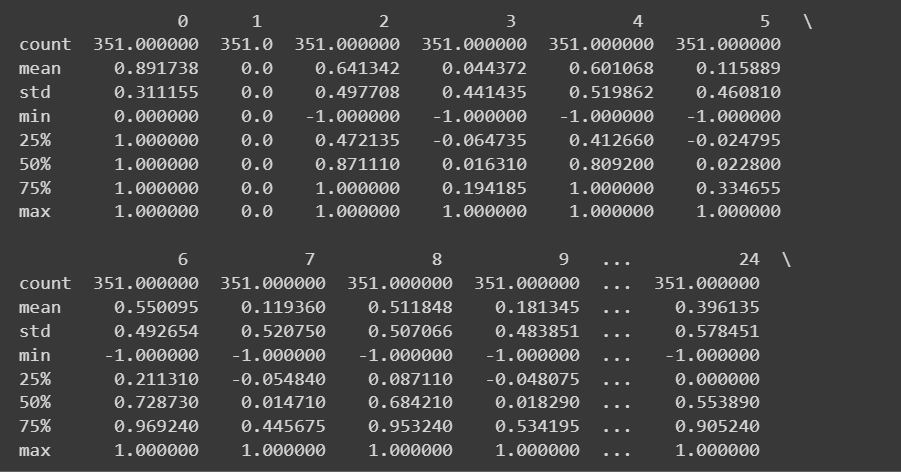
الناتج المقتطع من df.describe()
تتراوح أسماء الأعمدة حاليًا من 0 إلى 34، بما في ذلك التسمية. نظرًا لأن مجموعة البيانات لا توفر أسماء وصفية للأعمدة، فإنها تشير إليها فقط باسم attribute_1 إلى attribute_34 إذا كنت ترغب في إعادة تسمية أعمدة إطار البيانات كما هو موضح:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
ملحوظة: هذه الخطوة اختيارية تمامًا. يمكنك متابعة أسماء الأعمدة الافتراضية إذا كنت تفضل ذلك.
# Display the first few rows of the DataFrame
df.head()
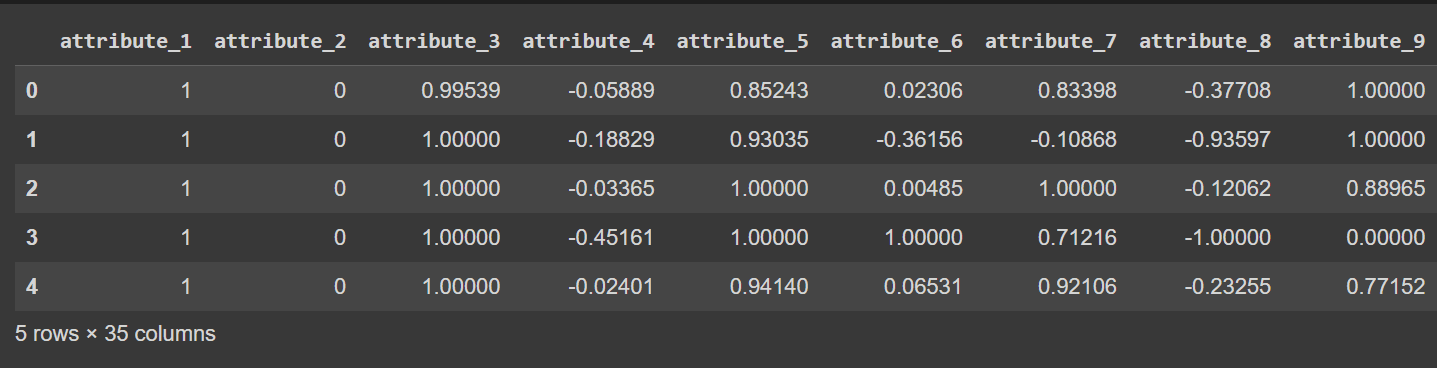
الإخراج المقطوع لـ df.head() [بعد إعادة تسمية الأعمدة]
الخطوة 3 - إعادة تسمية تسميات الفصل وتصور توزيع الفصل
نظرًا لأن تسميات فئة الإخراج هي "g" و"b"، نحتاج إلى تعيينها إلى 1 و0 على التوالي. يمكنك القيام بذلك باستخدام map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
دعونا أيضًا نتصور توزيع تسميات الفصل:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
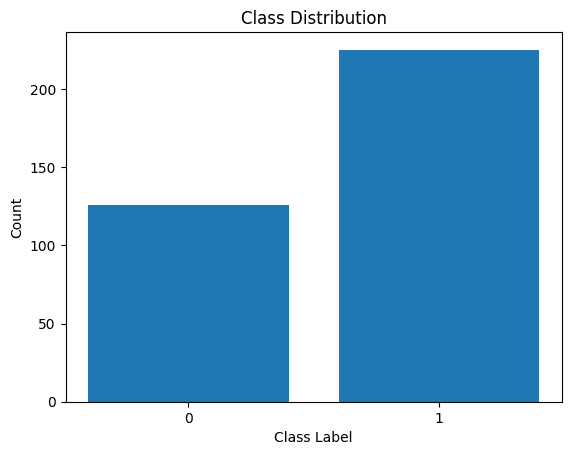
توزيع تسميات الفئة
نرى أن هناك خللاً في التوزيع. يوجد عدد أكبر من السجلات التي تنتمي إلى الفئة 1 مقارنة بالفئة 0. وسنتعامل مع هذا الخلل في الفئة عند بناء نموذج الانحدار اللوجستي.
الخطوة 5 - المعالجة المسبقة لمجموعة البيانات
دعونا نجمع الميزات وتسميات الإخراج مثل ذلك:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
بعد تقسيم مجموعة البيانات إلى مجموعات التدريب والاختبار، نحتاج إلى معالجة مجموعة البيانات مسبقًا.
عندما يكون هناك العديد من الميزات الرقمية - كل منها على نطاق مختلف - نحتاج إلى معالجة الميزات الرقمية مسبقًا. إحدى الطرق الشائعة هي تحويلها بحيث تتبع توزيعًا بمتوسط صفري وتباين الوحدة.
• StandardScaler من وحدة المعالجة المسبقة في scikit-learn تساعدنا على تحقيق ذلك.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])الخطوة 6 – بناء نموذج الانحدار اللوجستي
الآن يمكننا إنشاء مثيل للانحدار اللوجستي. ال LogisticRegression يعد الفصل الدراسي جزءًا من الوحدة النمطية الخطية لـ scikit-Learn.
لاحظ أننا قمنا بتعيين class_weight المعلمة إلى "متوازن". وهذا سوف يساعدنا على حساب عدم التوازن الطبقي. عن طريق تعيين أوزان لكل فئة - بما يتناسب عكسيا مع عدد السجلات في الفئات.
بعد إنشاء مثيل للفصل، يمكننا ملاءمة النموذج لمجموعة بيانات التدريب:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)الخطوة 7 – تقييم نموذج الانحدار اللوجستي
يمكنك الاتصال ب predict() طريقة الحصول على تنبؤات النموذج.
بالإضافة إلى درجة الدقة، يمكننا أيضًا الحصول على تقرير تصنيف بمقاييس مثل الدقة والاستدعاء ودرجة F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
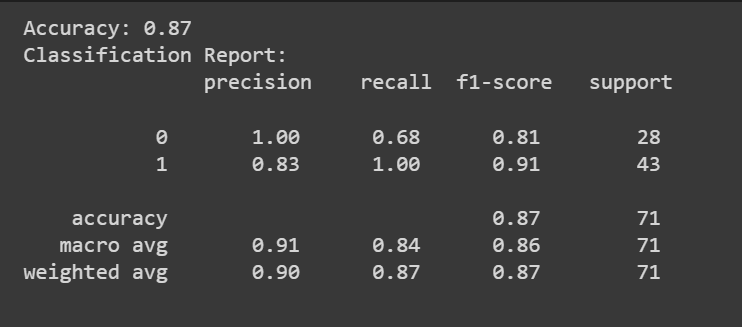
تهانينا، لقد قمت بترميز نموذج الانحدار اللوجستي الأول الخاص بك!
في هذا البرنامج التعليمي، تعلمنا عن الانحدار اللوجستي بالتفصيل: من النظرية والرياضيات إلى ترميز مصنف الانحدار اللوجستي.
كخطوة تالية، حاول بناء نموذج انحدار لوجستي لمجموعة بيانات مناسبة من اختيارك.
مجموعة بيانات الأيونوسفير مرخصة بموجب نسب المشاع الإبداعي 4.0 دولي ترخيص (CC BY 4.0):
سيجيليتو، في، وينج، إس، هوتون، إل، وبيكر، ك.. (1989). الأيونوسفير. مستودع التعلم الآلي UCI. https://doi.org/10.24432/C5W01B.
بالا بريا سي مطور وكاتب تقني من الهند. تحب العمل في تقاطع الرياضيات والبرمجة وعلوم البيانات وإنشاء المحتوى. تشمل مجالات اهتمامها وخبرتها DevOps وعلوم البيانات ومعالجة اللغة الطبيعية. تستمتع بالقراءة والكتابة والترميز والقهوة! تعمل حاليًا على التعلم ومشاركة معرفتها مع مجتمع المطورين من خلال تأليف برامج تعليمية وأدلة إرشادية ومقالات رأي والمزيد.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :يكون
- :ليس
- $ UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- من نحن
- حسابي
- دقة
- التأهيل
- تضيف
- إضافة
- بعد
- وتهدف
- خوارزمية
- خوارزميات
- الكل
- أيضا
- an
- و
- إجابة
- اقتراب
- هي
- المناطق
- AS
- افترض
- At
- التأليف
- b
- خباز
- متوازن
- شريط
- BE
- لان
- انتماء
- أفضل
- استراحة
- نساعدك في بناء
- ابني
- by
- دعوة
- CAN
- لا تستطيع
- الفئات
- سلسلة
- خيار
- فئة
- فصول
- تصنيف
- مشفرة
- البرمجة
- جمع
- عمود
- الأعمدة
- مشترك
- عادة
- جميل
- مجتمع
- يتألف
- مختصرا
- محتوى
- انشاء محتوى
- تحول
- التكلفة
- تغطية
- خلق
- خلق
- حاليا
- منحنى
- البيانات
- نقاط البيانات
- علم البيانات
- مجموعة البيانات
- الترتيب
- تعريف
- المشتقات
- التفاصيل
- الكشف عن
- المطور
- DevOps
- مختلف
- اتجاه
- بحث
- ناقش
- العرض
- توزيع
- do
- هل
- إلى أسفل
- بإمكانك تحميله
- أثناء
- كل
- جوهر
- تقدير
- تقييم
- خبرة
- استكشاف
- التعبير
- المميزات
- قليل
- العثور على
- ويرى
- الاسم الأول
- تناسب
- اتباع
- متابعات
- في حالة
- FRAME
- تبدأ من
- وظيفة
- دولار فقط واحصل على خصم XNUMX% على جميع
- الحصول على
- معطى
- Go
- هدف
- شراء مراجعات جوجل
- أكبر
- أرض
- دليل
- يد
- مقبض
- يملك
- مساعدة
- يساعد
- لها
- كيفية
- HTTPS
- ICS
- if
- عدم التوازن
- استيراد
- in
- تتضمن
- مؤشر
- الهند
- المؤشرات
- معلومات
- إدخال
- المدخلات
- مصلحة
- وكتابة مواضيع مثيرة للاهتمام
- تقاطع طرق
- إلى
- IT
- م
- KD nuggets
- علم
- المعرفة
- تُشير
- ملصقات
- لغة
- تعلم
- تعلم
- تعلم
- أقل
- اسمحوا
- المكتبة
- حقوق الملكية الفكرية
- مرخص
- مثل
- أرجحية
- الإعجابات
- خط
- جار التحميل
- سجل
- بحث
- يبدو مثل
- خسارة
- آلة
- آلة التعلم
- جعل
- كثير
- رسم خريطة
- الرياضيات
- matplotlib
- تعظيم
- تعظيم
- أقصى
- مايو..
- تعني
- طريقة
- المقاييس
- تقليل
- الحد الأدنى
- نموذج
- عارضات ازياء
- وحدة
- الأكثر من ذلك
- خطوة
- أسماء
- طبيعي
- اللغة الطبيعية
- معالجة اللغات الطبيعية
- حاجة
- سلبي
- التالي
- عدد
- ملاحظ
- of
- غالبا
- on
- ONE
- مراجعة
- مقابل
- الأمثل
- التحسين
- الأمثل
- or
- نتيجة
- النتائج
- الناتج
- النتائج
- الباندا
- المعلمة
- المعلمات
- جزء
- قطعة
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- البوينت
- نقاط
- يحتمل
- دقة
- وتوقع
- تنبؤات
- تنبؤي
- متنبئ
- تتوقع
- تفضل
- الاحتمالات
- المشكلة
- والمضي قدما
- عملية المعالجة
- معالجة
- المنتجات
- برمجة وتطوير
- تزود
- بحت
- بايثون
- رادار
- نطاق
- معدل
- عرض
- نادي القراءة
- حقيقي
- تسجيل
- يشار
- يشير
- تراجع
- تقرير
- مستودع
- يمثل
- طلب
- احترام
- على التوالي
- عائدات
- مراجعة
- قوي
- قاعدة
- s
- علوم
- تعلم الحروف
- أحرز هدفاً
- انظر تعريف
- إحساس
- طقم
- باكجات
- مشاركة
- هي
- أظهرت
- الاشارات
- تبسيط
- So
- بعض
- انقسم
- بدأت
- إحصائيات
- خطوة
- مستقيم
- بناء
- بعد ذلك
- هذه
- مناسب
- مسائل حسابية
- أخذ
- يأخذ
- الهدف
- المهام
- تقني
- تجربه بالعربي
- الاختبار
- من
- أن
- •
- منهم
- نظرية
- هناك.
- وبالتالي
- هم
- عبر
- إلى
- الأدوات
- قطار
- متدرب
- قادة الإيمان
- تحول
- التحويلات
- محاولة
- البرنامج التعليمي
- الدروس
- اثنان
- أنواع
- مع
- فهم
- وحدة
- تحديث
- آخر التحديثات
- URL
- us
- حساب أمريكي
- تستخدم
- مستعمل
- استخدام
- قيمنا
- القيم
- تصور
- we
- متى
- التي
- لماذا
- ويكيبيديا
- سوف
- جناح
- مع
- للعمل
- عامل
- أعمال
- سوف
- كاتب
- جاري الكتابة
- X
- نعم فعلا
- لصحتك!
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت
- صفر







