图片作者
关于机器学习和数据科学的课程和资源有很多,但关于数据工程的课程和资源却很少。这引发了一些问题。这是一个困难的领域吗?它提供的工资低吗?难道它不像其他技术角色一样令人兴奋吗?然而,现实情况是,许多公司正在积极寻找数据工程人才,并提供丰厚的薪水,有时甚至超过 200,000 万美元。数据工程师作为数据平台的架构师发挥着至关重要的作用,他们设计和构建使数据科学家和机器学习专家能够有效运作的基础系统。
为了解决这一行业差距,DataTalkClub 推出了变革性的免费训练营,“数据工程 Zoomcamp”。本课程旨在帮助初学者或希望转行的专业人士掌握数据工程方面的基本技能和实践经验。
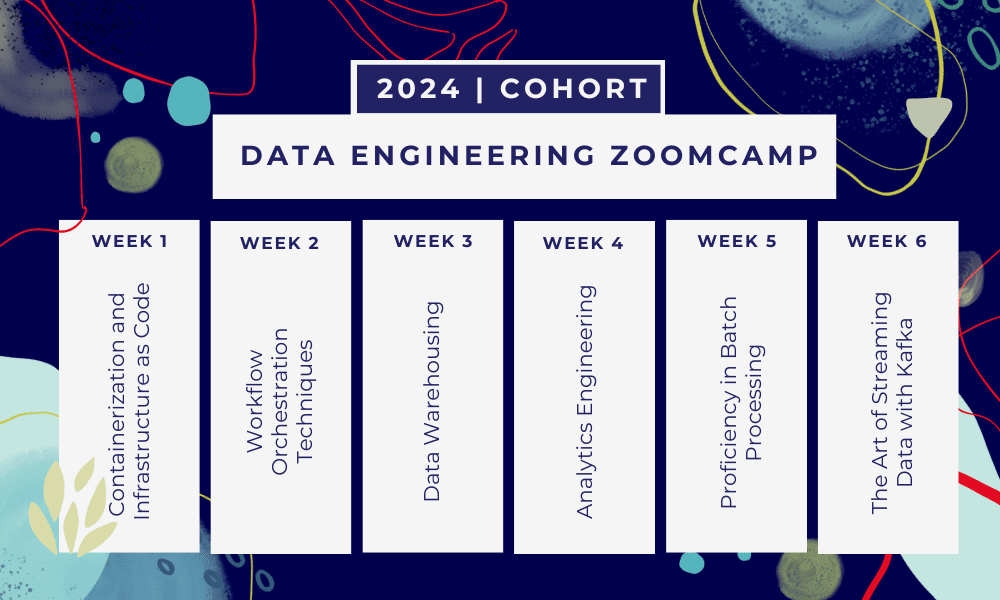
这是一个 6周训练营 您将在这里通过多种课程、阅读材料、研讨会和项目进行学习。在每个模块结束时,您将获得作业来练习所学知识。
- 第1周: GCP、Docker、Postgres、Terraform 和环境设置简介。
- 第2周: 使用 Mage 进行工作流程编排。
- 第3周: 使用 BigQuery 进行数据仓库以及使用 BigQuery 进行机器学习。
- 第4周: 使用 dbt、Google Data Studio 和 Metabase 的分析工程师。
- 第5周: 使用 Spark 进行批处理。
- 第6周: 使用卡夫卡进行流式传输。
图片来源: DataTalksClub/数据工程-zoomcamp
该课程大纲包含 6 个模块、2 个研讨会和一个项目,涵盖成为专业数据工程师所需的一切。
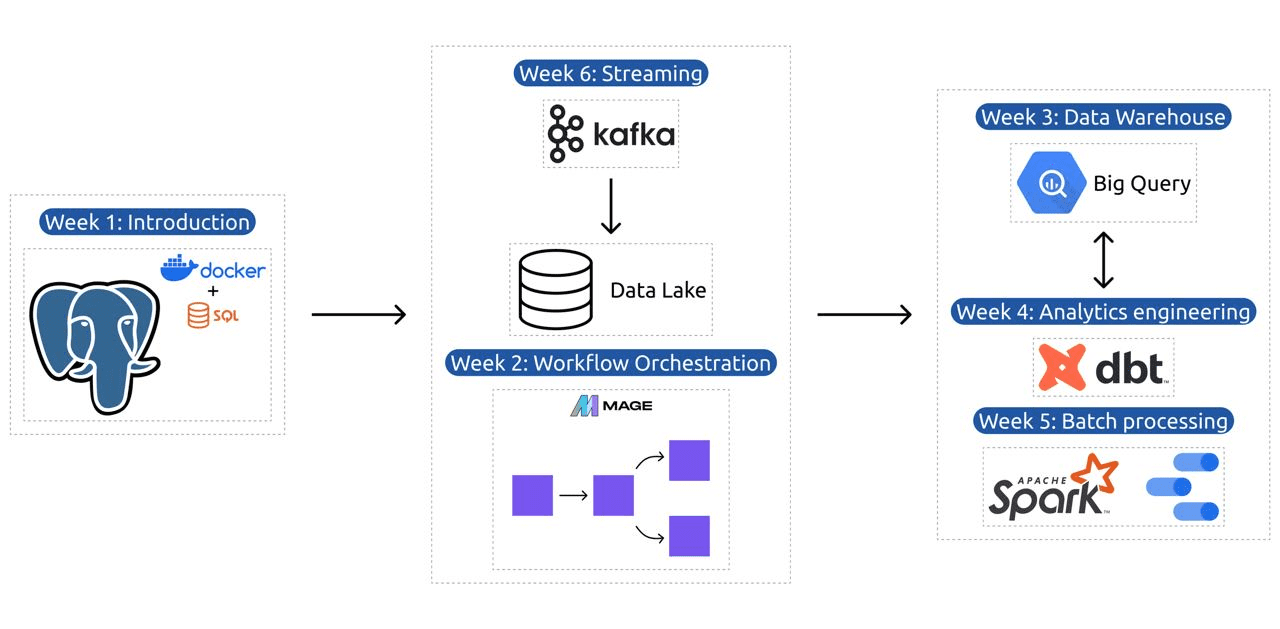
模块 1:掌握容器化和基础设施即代码
在本模块中,您将了解 Docker 和 Postgres,从基础知识开始,逐步了解有关创建数据管道、使用 Docker 运行 Postgres 等的详细教程。
该模块还涵盖了 pgAdmin、Docker-compose 和 SQL 复习主题等基本工具,以及有关 Docker 网络的可选内容以及针对 Windows 子系统 Linux 用户的特殊演练。最后,本课程向您介绍 GCP 和 Terraform,让您全面了解容器化和基础设施即代码,这对于现代基于云的环境至关重要。
第 2 单元:工作流编排技术
该模块深入探索 Mage,这是一种用于数据转换和集成的创新开源混合框架。本模块从工作流程编排的基础知识开始,然后进行 Mage 的实践练习,包括通过 Docker 设置并构建从 API 到 Postgres 和 Google Cloud Storage (GCS),然后再到 BigQuery 的 ETL 管道。
该模块融合了视频、资源和实践任务,确保了全面的学习体验,使学习者具备使用 Mage 管理复杂数据工作流程的技能。
研讨会 1:数据摄取策略
在第一个研讨会中,您将掌握构建高效的数据摄取管道。该研讨会重点关注基本技能,例如从 API 和文件中提取数据、规范化和加载数据以及增量加载技术。完成本次研讨会后,您将能够像高级数据工程师一样创建高效的数据管道。
第 3 单元:数据仓库
该模块深入探索数据存储和分析,重点关注使用 BigQuery 的数据仓库。它涵盖了分区和集群等关键概念,并深入探讨了 BigQuery 的最佳实践。该模块将深入探讨高级主题,特别是机器学习 (ML) 与 BigQuery 的集成,重点介绍 SQL 在 ML 中的使用,并提供有关超参数调整、特征预处理和模型部署的资源。
模块 4:分析工程
分析工程模块侧重于使用 dbt(数据构建工具)与现有数据仓库(BigQuery 或 PostgreSQL)构建项目。
该模块涵盖在云和本地环境中设置 dbt、介绍分析工程概念、ETL 与 ELT 以及数据建模。它还涵盖了高级 dbt 功能,例如增量模型、标签、挂钩和快照。
最后,该模块介绍了使用 Google Data Studio 和 Metabase 等工具可视化转换数据的技术,并提供了用于故障排除和高效数据加载的资源。
模块 5:熟练掌握批处理
本模块涵盖使用 Apache Spark 的批处理,首先介绍批处理和 Spark,以及 Windows、Linux 和 MacOS 的安装说明。
它包括探索 Spark SQL 和 DataFrame、准备数据、执行 SQL 操作以及了解 Spark 内部结构。最后,最后介绍了在云中运行 Spark 并将 Spark 与 BigQuery 集成。
第 6 单元:使用 Kafka 传输数据的艺术
该模块首先介绍流处理概念,然后深入探讨 Kafka,包括其基础知识、与 Confluence Cloud 的集成以及涉及生产者和消费者的实际应用。
该模块还涵盖 Kafka 配置和流,解决流连接、测试、窗口以及 Kafka ksqldb 和 Connect 的使用等主题。此外,它将重点扩展到 Python 和 JVM 环境,包括用于 Python 流处理的 Faust、Pyspark – 结构化流和用于 Kafka Streams 的 Scala 示例。
研讨会 2:使用 SQL 进行流处理
您将学习使用 RisingWave 处理和管理流数据,它提供具有成本效益的解决方案和 PostgreSQL 风格的体验,以增强您的流处理应用程序的能力。
项目:真实世界数据工程应用
该项目的目标是实施我们在本课程中学到的所有概念,以构建端到端数据管道。您将创建一个由两个图块组成的仪表板,方法是选择数据集、构建用于处理数据并将其存储在数据湖中的管道、构建用于将处理后的数据从数据湖传输到数据仓库的管道、转换数据将数据仓库中的数据准备好用于仪表板,最后构建仪表板以可视化方式呈现数据。
2024 年队列详细信息
先决条件
- 基本编码和命令行技能
- SQL 基础
- Python:有益但不是强制性的
专家教练引领您的旅程
- 安库什·卡纳
- 维多利亚·佩雷斯·莫拉
- 阿列克谢·格里戈列夫(Alexey Grigorev)
- 马特·帕尔默(Matt Palmer)
- 路易斯·奥利维拉(Luis Oliveira)
- 迈克尔·舒梅克
加入我们的 2024 年队列,开始在令人惊叹的数据工程社区中学习。通过专家主导的培训、实践经验以及针对行业需求量身定制的课程,该训练营不仅为您提供必要的技能,而且使您处于利润丰厚且需求旺盛的职业道路的最前沿。今天就报名吧,将您的愿望变成现实!
阿比德·阿里·阿万 (@1abidaliawan) 是一名经过认证的数据科学家专业人士,他热爱构建机器学习模型。 目前,他专注于内容创建和撰写有关机器学习和数据科学技术的技术博客。 Abid 拥有技术管理硕士学位和电信工程学士学位。 他的愿景是使用图形神经网络为患有精神疾病的学生构建一个人工智能产品。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :具有
- :是
- :不是
- :在哪里
- $UP
- 000
- 1
- 15%
- 17
- 2024
- a
- Able
- 关于
- 积极地
- 另外
- 解决
- 高级
- 前进
- 后
- AI
- 所有类型
- 沿
- 还
- 惊人
- an
- 分析
- 分析
- 分析
- 和
- 和基础设施
- 阿帕奇
- Apache Spark
- API
- APIs
- 应用领域
- 建筑师
- 保健
- 艺术
- AS
- At
- 可使用
- 基础
- BE
- 成为
- 成为
- 初学者
- 有利
- 最佳
- 最佳实践
- BigQuery的
- 混合
- 博客
- 都
- 建立
- 建筑物
- 但是
- by
- 寻找工作
- 人才招聘
- 认证
- 云端技术
- 云存储
- 集群
- 码
- 编码
- 队列
- 社体的一部分
- 公司
- 完成
- 全面
- 概念
- 总结
- 配置
- 连接点
- 分享链接
- 考虑
- 组成
- 建设
- 消费者
- 包含
- 内容
- 内容创造
- 课程
- 课程
- 占地面积
- 创建信息图
- 创造
- 创建
- 关键
- 目前
- 课程设置
- XNUMX月XNUMX日
- data
- 数据工程师
- 数据湖
- 数据科学
- 数据科学家
- 数据存储
- 数据仓库
- 日期
- 学位
- 部署
- 设计
- 设计
- 详细
- 难
- 码头工人
- 每
- 只
- 高效
- 或
- 授权
- enable
- 结束
- 端至端
- 工程师
- 工程师
- 工程师
- 注册
- 确保
- 环境
- 环境中
- 必要
- 醚(ETH)
- 一切
- 例子
- 令人兴奋的
- 现有
- 体验
- 专家
- 勘探
- 探索
- 扩展
- 专栏
- 特征
- 特色
- 少数
- 部分
- 档
- 终于
- 姓氏:
- 专注焦点
- 重点
- 聚焦
- 其次
- 针对
- 第一线
- 基础的
- 骨架
- Free
- 止
- 功能
- 基本原理
- 差距
- GCP
- 特定
- 谷歌
- 谷歌云
- 图形
- 图神经网络
- 制导
- 动手
- 有
- he
- 突出
- 他的
- 持有
- 整体
- 功课
- 钩
- 但是
- HTTPS
- 杂交种
- 超参数调整
- 疾病
- 实施
- in
- 深入
- 包括
- 包含
- 增量
- 行业中的应用:
- 基础设施
- 创新
- 安装
- 说明
- 整合
- 积分
- 成
- 介绍
- 推出
- 介绍
- 介绍
- 介绍
- 涉及
- IT
- 它的
- 一月
- 加入
- 卡夫卡
- 掘金队
- 键
- 湖泊
- 领导
- 学习用品
- 知道
- 学习者
- 学习
- 喜欢
- Line
- Linux的
- 装载
- 本地
- 寻找
- 爱
- 低
- 赚钱
- 机
- 机器学习
- MacOS的
- 管理
- 颠覆性技术
- 强制性
- 许多
- 主
- 掌握
- 物料
- 心理
- 精神疾病
- ML
- 模型
- 造型
- 模型
- 现代
- 模块
- 模块
- 更多
- 多
- 必要
- 需求
- 打印车票
- 需要
- 网络
- 工业网络
- 神经
- 神经网络
- 目标
- of
- 提供
- 优惠精选
- on
- 仅由
- 开放源码
- 运营
- or
- 管弦乐编曲
- 其他名称
- 我们的
- 帕尔默
- 尤其
- 径
- 窥视
- 执行
- 管道
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 播放
- 职位
- PostgreSQL的
- 实用
- 实际应用
- 在练习上
- 做法
- 准备
- 当下
- 过程
- 处理
- 处理
- 生产者
- 产品
- 所以专业
- 专业人士
- 进展
- 项目
- 项目
- 提供
- 优
- 蟒蛇
- 有疑问吗?
- 提高
- 阅读
- 真实的世界
- 现实
- 资源
- 角色
- 角色
- 运行
- s
- 工资
- 斯卡拉
- 科学
- 科学家
- 科学家
- 寻求
- 选择
- 前辈
- 设置
- 格局
- 技能
- 松弛
- 方案,
- 一些
- 有时
- 极致
- 火花
- 特别
- SQL
- 开始
- 开始
- 存储
- 流
- 流
- 流
- 结构化
- 奋斗的
- 学生
- 工作室
- 大量
- 这样
- SUPPORT
- Switch 开关
- 产品
- 量身定制
- 天赋
- 任务
- 科技
- 文案
- 技术
- 技术
- 专业技术
- 电信
- Terraform
- 测试
- 这
- 基础知识
- 然后
- Free Introduction
- 通过
- 至
- 今晚
- 工具
- 工具
- Topics
- 产品培训
- 传输
- 改造
- 转型
- 变革
- 转化
- 转型
- 教程
- 二
- 理解
- USD
- 使用
- 用户
- 运用
- Ve
- 非常
- 通过
- 视频
- 愿景
- 视觉
- vs
- 仓库保管
- 仓储服务
- we
- 什么是
- 这
- WHO
- 将
- 窗户
- 工作流程
- 工作流程
- 车间
- 工作坊
- 写作
- 您
- 您一站式解决方案
- 和风网










