图片作者
在本教程中,我们将学习如何针对各种用例设置和使用 OpenAI API。本教程旨在易于理解,即使对于那些 Python 编程知识有限的人来说也是如此。我们将探索任何人如何生成响应并访问高质量的大型语言模型。
开放人工智能API 允许开发人员轻松访问 OpenAI 开发的各种 AI 模型。它提供了一个用户友好的界面,使开发人员能够将最先进的 OpenAI 模型支持的智能功能融入到他们的应用程序中。该 API 可用于多种用途,包括文本生成、多轮聊天、嵌入、转录、翻译、文本转语音、图像理解和图像生成。此外,该 API 与curl、Python 和 Node.js 兼容。
要开始使用 OpenAI API,您首先需要在 openai.com 上创建一个帐户。以前,每个用户都会获得免费积分,但现在新用户需要购买积分。
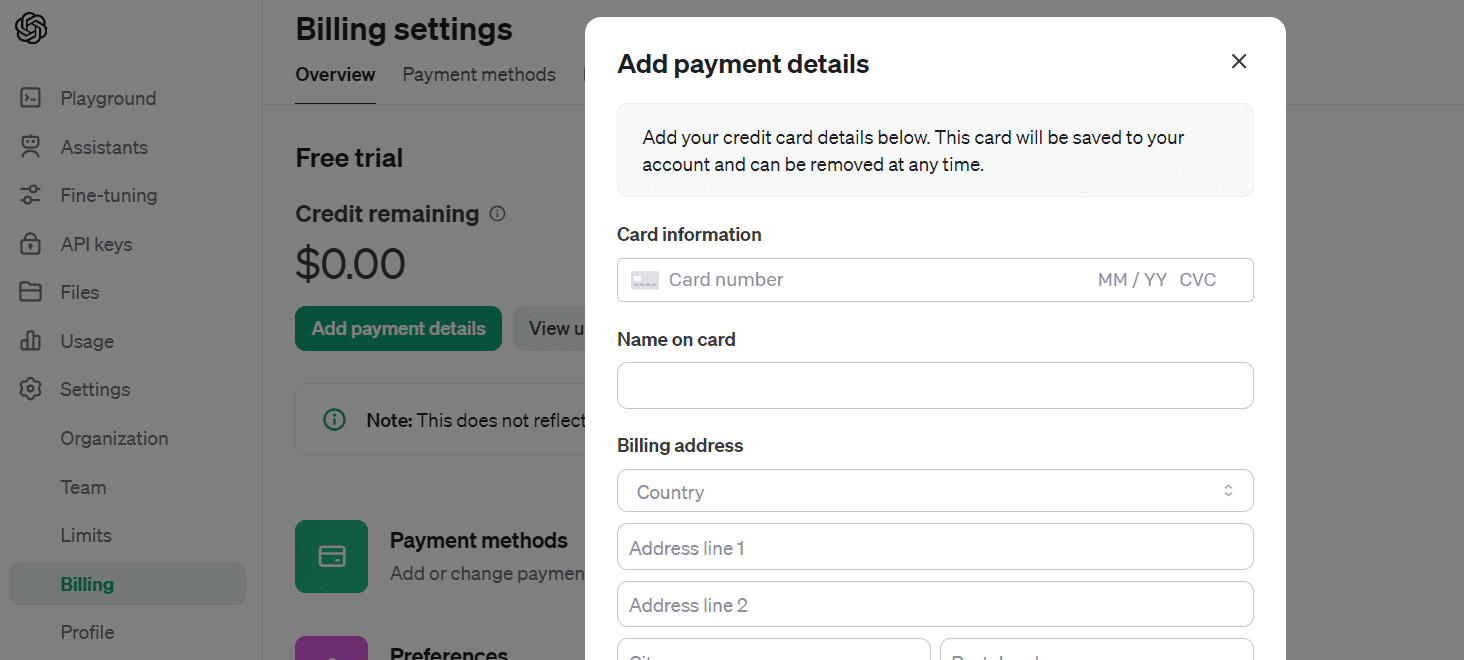
要购买积分,请转到“设置”,然后“账单”,最后“添加付款详细信息”。输入您的借记卡或信用卡信息,并确保禁用自动充值。充值 10 美元后,您可以使用一年。
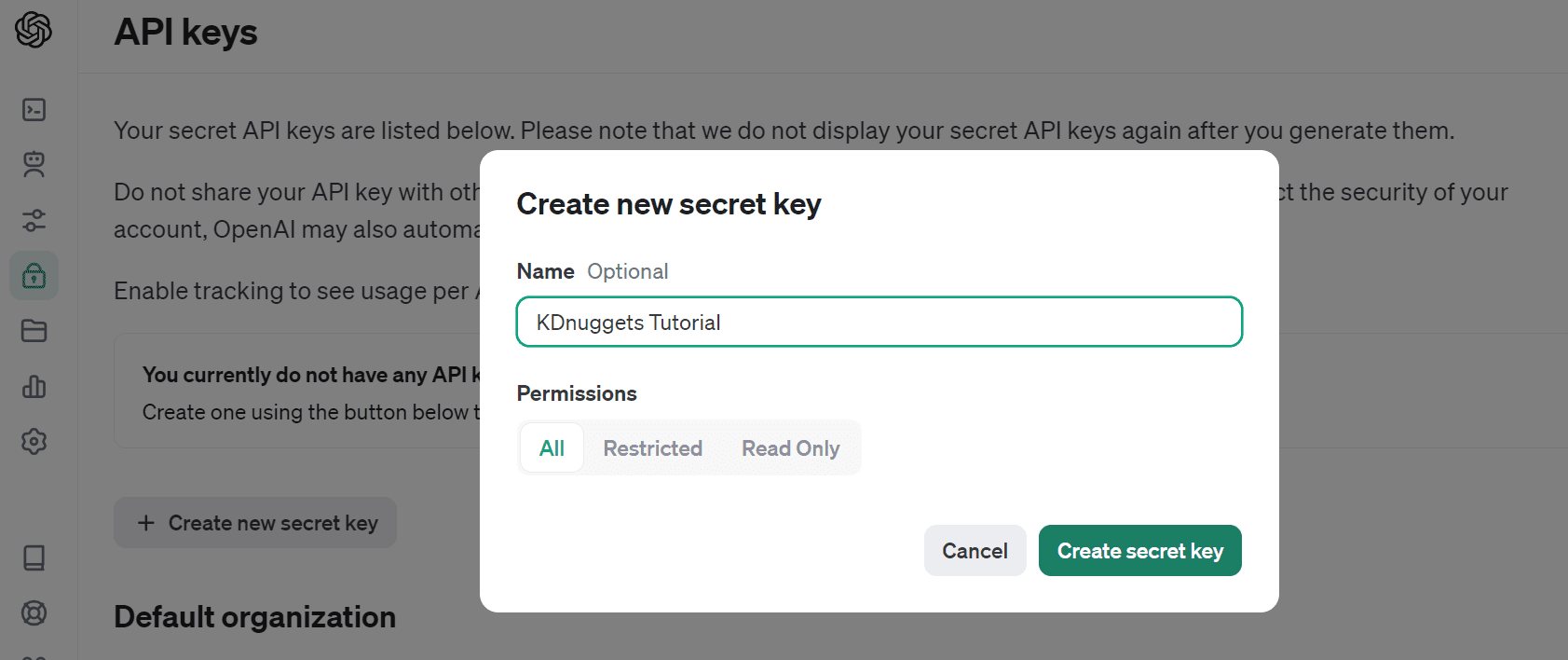
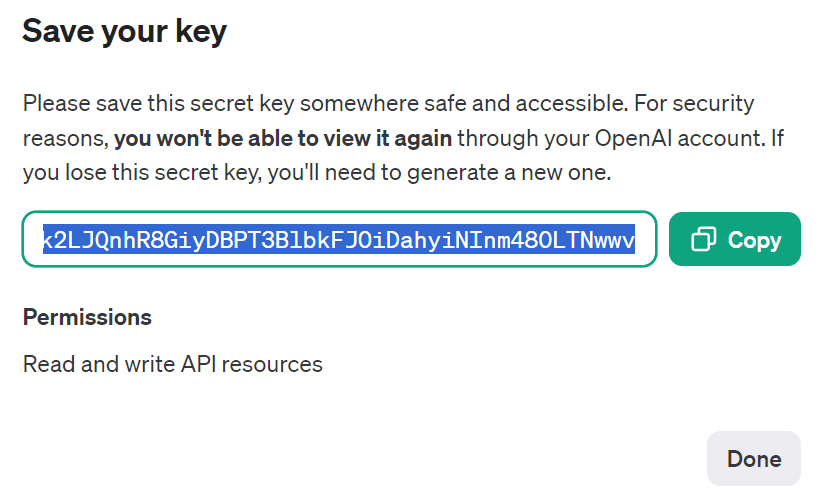
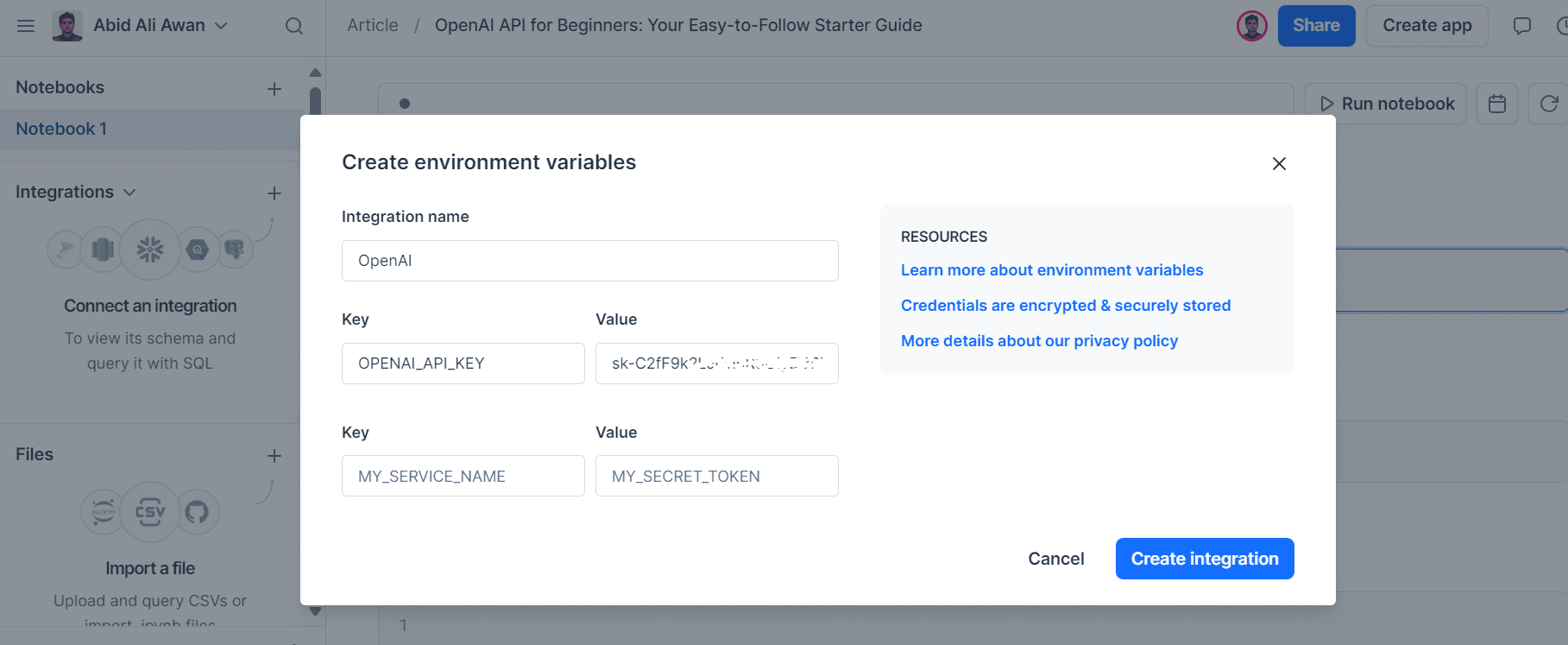
让我们通过导航到“API 密钥”并选择“创建新密钥”来创建 API 密钥。为其命名并单击“创建密钥”。
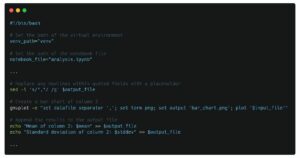
复制 API 并在本地计算机上创建环境变量。
我使用 Deepnote 作为我的 IDE。创建环境变量很容易。只需转到“集成”,选择“创建环境变量”,提供密钥的名称和值,然后创建集成。
接下来,我们将使用 pip 安装 OpenAI Python 包。
%pip install --upgrade openai我们现在将创建一个可以在全球范围内访问各种类型模型的客户端。
如果您已将环境变量设置为“OPENAI_API_KEY”,则无需向 OpenAI 客户端提供 API 密钥。
from openai import OpenAI
client = OpenAI()请注意,仅当您的环境变量名称与默认名称不同时,您才应提供 API 密钥。
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("SECRET_KEY"),
)我们将使用遗留函数来生成响应。完成函数需要模型名称、提示和其他参数来生成回复。
completion = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Write a short story about Elon Musk being the biggest troll.",
max_tokens=300,
temperature=0.7,
)
print(completion.choices[0].text)
GPT3.5 模型生成了关于埃隆·马斯克的精彩故事。

我们还可以通过提供额外的参数“stream”来流式传输我们的响应。
流功能无需等待完整响应,而是可以在输出生成后立即对其进行处理。这种方法通过逐个返回语言模型令牌的输出而不是一次全部返回,有助于减少感知延迟。
stream = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Write a Python code for accessing the REST API securely.",
max_tokens=300,
temperature=0.7,
stream = True
)
for chunk in stream:
print(chunk.choices[0].text, end="")

该模型使用 API 聊天完成。在生成响应之前,让我们探索可用的模型。
您可以查看所有可用型号的列表或阅读 型号 官方文档页面。
print(client.models.list())
我们将使用最新版本的GPT-3.5,并为其提供系统提示和用户消息的字典列表。确保遵循相同的消息模式。
completion = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=[
{
"role": "system",
"content": "You are an experienced data scientist, adept at presenting complex data concepts with creativity.",
},
{
"role": "user",
"content": "What is Feature Engineering, and what are some common methods?",
},
],
)
print(completion.choices[0].message.content)
正如我们所看到的,我们生成了与旧版 API 类似的结果。那么,为什么要使用这个 API?接下来,我们将了解为什么聊天完成 API 更灵活且更易于使用。
Feature engineering is the process of selecting, creating, or transforming features (variables) in a dataset to improve the performance of machine learning models. It involves identifying the most relevant and informative features and preparing them for model training. Effective feature engineering can significantly enhance the predictive power of a model and its ability to generalize to new data.
Some common methods of feature engineering include:
1. Imputation: Handling missing values in features by filling them in with meaningful values such as the mean, median, or mode of the feature.
2. One-Hot Encoding: Converting categorical variables into binary vectors to represent different categories as individual features.
3. Normalization/Standardization: Scaling numerical features to bring t.........
我们现在将学习如何与我们的人工智能模型进行多轮对话。为此,我们将添加助理对先前对话的响应,并以相同的消息格式包含新提示。之后,我们将向聊天完成功能提供字典列表。
chat=[
{"role": "system", "content": "You are an experienced data scientist, adept at presenting complex data concepts with creativity."},
{"role": "user", "content": "What is Feature Engineering, and what are some common methods?"}
]
chat.append({"role": "assistant", "content": str(completion.choices[0].message.content)})
chat.append({"role": "user", "content": "Can you summarize it, please?"})
completion = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=chat
)
print(completion.choices[0].message.content)
该模型已经理解了上下文并为我们总结了特征工程。
Feature engineering involves selecting, creating, or transforming features in a dataset to enhance the performance of machine learning models. Common methods include handling missing values, converting categorical variables, scaling numerical features, creating new features using interactions and polynomials, selecting important features, extracting time-series and textual features, aggregating information, and reducing feature dimensionality. These techniques aim to improve the model's predictive power by refining and enriching the input features.为了开发高级应用程序,我们需要将文本转换为嵌入。这些嵌入用于相似性搜索、语义搜索和推荐引擎。我们可以通过提供 API 文本和模型名称来生成嵌入。就是这么简单。
text = "Data Engineering is a rapidly growing field that focuses on the collection, storage, processing, and analysis of large volumes of structured and unstructured data. It involves various tasks such as data extraction, transformation, loading (ETL), data modeling, database design, and optimization to ensure that data is accessible, accurate, and relevant for decision-making purposes."
DE_embeddings = client.embeddings.create(input=text, model="text-embedding-3-small")
print(chat_embeddings.data[0].embedding)
[0.0016297283582389355, 0.0013418874004855752, 0.04802832752466202, -0.041273657232522964, 0.02150309458374977, 0.004967313259840012,.......]现在,我们可以将文本转换为语音,将语音转换为文本,还可以使用音频 API 进行翻译。
抄录
我们将使用 Wi-Fi 7 将改变一切 YouTube 视频并将其转换为 mp3。之后,我们将打开该文件并将其提供给音频转录 API。
audio_file= open("Data/techlinked.mp3", "rb")
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
print(transcript.text)
Whisper 模型非常棒。它有一个完美的音频转录。
The Consumer Electronics Show has officially begun in Las Vegas and we'll be bringing you all the highlights from right here in our regular studio where it's safe and clean and not a desert. I hate sand. The Wi-Fi Alliance announced that they have officially confirmed the Wi-Fi 7 standard and they've already started to certify devices to ensure they work together. Unlike me and Selena, that was never gonna last. The new standard will have twice the channel bandwidth of Wi-Fi 5, 6, and 6E, making it better for, surprise,......翻译
我们还可以将英语音频转录成另一种语言。在我们的例子中,我们将其转换为乌尔都语。我们只需添加另一个参数“语言”并为其提供 ISO 语言代码“ur”。
translations = client.audio.transcriptions.create(
model="whisper-1",
response_format="text",
language="ur",
file=audio_file,
)
print(translations)
非拉丁语言的翻译并不完美,但可用于最小可行产品。
کنسومر ایلیکٹرانک شاہی نے لاس بیگیس میں شامل شروع کیا ہے اور ہم آپ کو جمہوری بہترین چیزیں اپنے ریگلر سٹوڈیو میں یہاں جارہے ہیں جہاں یہ آمید ہے اور خوبصورت ہے اور دنیا نہیں ہے مجھے سانڈ بھولتا ہے وائ فائی آلائنٹس نے اعلان کیا کہ انہوں نے وائ فائی سیبن سٹانڈرڈ کو شامل شروع کیا اور انہوں ن........
文本到语音
为了将您的文本转换为听起来自然的音频,我们将使用语音 API 并为其提供模型名称、配音演员名称和输入文本。接下来,我们将音频文件保存到“Data”文件夹中。
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input= '''I see skies of blue and clouds of white
The bright blessed days, the dark sacred nights
And I think to myself
What a wonderful world
'''
)
response.stream_to_file("Data/song.mp3")
要收听 Deepnote Notebook 中的音频文件,我们将使用 IPython Audio 函数。
from IPython.display import Audio
Audio("Data/song.mp3")

OpenAI API 使用户可以通过聊天完成功能访问多模式模型。为了理解图像,我们可以使用最新的GPT-4视觉模型。
在消息参数中,我们提供了询问有关图像和图像 URL 的问题的提示。图片来源于 Pixabay。请确保您遵循相同的消息格式以避免任何错误。
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Could you please identify this image's contents and provide its location?",
},
{
"type": "image_url",
"image_url": {
"url": "https://images.pexels.com/photos/235731/pexels-photo-235731.jpeg?auto=compress&cs=tinysrgb&w=1260&h=750&dpr=2",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)
输出完美地解释了图像。
This is an image of a person carrying a large number of rice seedlings on a carrying pole. The individual is wearing a conical hat, commonly used in many parts of Asia as protection from the sun and rain, and is walking through what appears to be a flooded field or a wet area with lush vegetation in the background. The sunlight filtering through the trees creates a serene and somewhat ethereal atmosphere.
It's difficult to determine the exact location from the image alone, but this type of scene is typically found in rural areas of Southeast Asian countries like Vietnam, Thailand, Cambodia, or the Philippines, where rice farming is a crucial part of the agricultural industry and landscape.
除了提供图像 URL,我们还可以加载本地图像文件并将其提供给聊天完成 API。为此,我们首先需要通过以下方式下载图像 曼吉特·辛格·亚达夫 来自 pexels.com。
!curl -o /work/Data/indian.jpg "https://images.pexels.com/photos/1162983/pexels-photo-1162983.jpeg?auto=compress&cs=tinysrgb&w=1260&h=750&dpr=2"
然后,我们将加载图像并以 Base64 格式进行编码。
import base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_path = "Data/indian.jpg"
# generating the base64 string
base64_image = encode_image(image_path)
我们将提供元数据和图像的 base64 字符串,而不是提供图像 URL。
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Could you please identify this image's contents.",
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
},
},
],
}
],
max_tokens=100,
)
print(response.choices[0].message.content)
该模型成功地分析了图像并提供了详细的解释。
The image shows a woman dressed in traditional Indian attire, specifically a classical Indian saree with gold and white colors, which is commonly associated with the Indian state of Kerala, known as the Kasavu saree. She is adorned with various pieces of traditional Indian jewelry including a maang tikka (a piece of jewelry on her forehead), earrings, nose ring, a choker, and other necklaces, as well as bangles on her wrists.
The woman's hairstyle features jasmine flowers arranged in我们还可以使用 DALLE-3 模型生成图像。我们只需向图像 API 提供模型名称、提示、尺寸、质量和图像数量。
response = client.images.generate(
model="dall-e-3",
prompt="a young woman sitting on the edge of a mountain",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
生成的图片在线保存,您可以下载到本地查看。为此,我们将使用“request”函数下载图像,并提供图像 URL 和要保存图像的本地目录。之后,我们将使用 Pillow 库的 Image 函数打开并显示图像。
import urllib.request
from PIL import Image
urllib.request.urlretrieve(image_url, '/work/Data/woman.jpg')
img = Image.open('/work/Data/woman.jpg')
img.show()
我们收到了高质量的生成图像。简直太神奇了!

如果您在运行任何 OpenAI Python API 时遇到困难,请随时查看我的项目 深注.
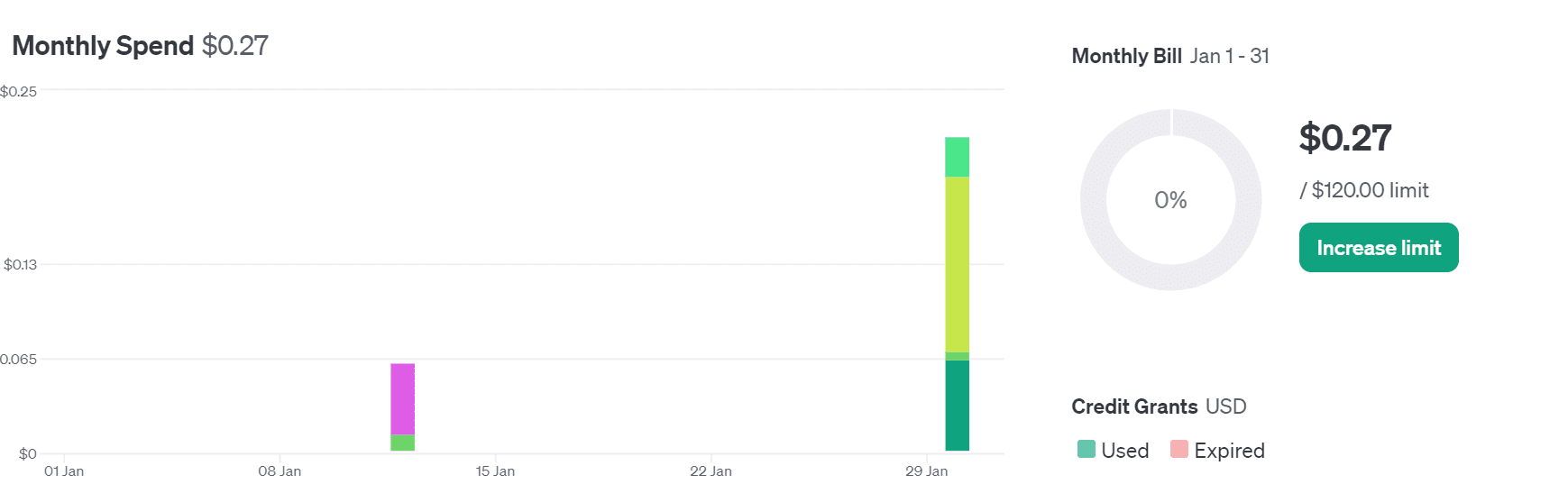
我已经尝试 OpenAPI 一段时间了,最终我们只使用了 0.22 美元的信用额度,我觉得这是相当实惠的。通过我的指南,即使是初学者也可以开始构建自己的人工智能应用程序。这是一个简单的过程 - 您不必训练自己的模型或部署它。您可以使用 API 访问最先进的模型,该 API 会随着每个新版本的发布而不断改进。
在本指南中,我们将介绍如何设置 OpenAI Python API 并生成简单的文本响应。我们还了解多轮聊天、嵌入、转录、翻译、文本转语音、视觉和图像生成 API。
如果您希望我使用这些 API 来构建高级 AI 应用程序,请告诉我。
谢谢您的阅读。
阿比德·阿里·阿万 (@1abidaliawan) 是一名经过认证的数据科学家专业人士,他热爱构建机器学习模型。 目前,他专注于内容创建和撰写有关机器学习和数据科学技术的技术博客。 Abid 拥有技术管理硕士学位和电信工程学士学位。 他的愿景是使用图形神经网络为患有精神疾病的学生构建一个人工智能产品。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://www.kdnuggets.com/openai-api-for-beginners-your-easy-to-follow-starter-guide?utm_source=rss&utm_medium=rss&utm_campaign=openai-api-for-beginners-your-easy-to-follow-starter-guide
- :具有
- :是
- :不是
- :在哪里
- $UP
- 1
- 10
- 12
- 13
- 14
- 16
- 17
- 19
- 2%
- 20
- 21
- 22
- 5
- 6
- 7
- 8
- 9
- a
- 对,能力--
- 关于
- 关于它
- ACCESS
- 无障碍
- 访问
- 账号管理
- 精准的
- 加
- 另外
- 拿手
- 高级
- 实惠
- 后
- 汇总
- 农业
- AI
- AI模型
- 瞄准
- 所有类型
- 联盟
- 允许
- 合金
- 单
- 已经
- 还
- 惊人
- an
- 分析
- 分析
- 和
- 公布
- 另一个
- 任何
- 任何人
- API
- APIs
- 出现
- 应用领域
- 应用领域
- 的途径
- 保健
- 国家 / 地区
- 地区
- 论点
- 参数
- 安排
- AS
- 亚洲
- 亚洲的
- 问
- 助理
- 相关
- At
- 气氛
- 音频
- 可使用
- 避免
- 背景
- 带宽
- BE
- 很
- before
- 初学者
- 开始
- 作为
- 更好
- 最大
- 计费
- 二进制
- 幸福
- 博客
- 蓝色
- 光明
- 带来
- 瞻
- 建立
- 建筑物
- 但是
- by
- 柬埔寨
- CAN
- 卡
- 携带
- 案件
- 例
- 类别
- 认证
- 证明
- 更改
- 渠道
- 即时通话
- 查
- 清洁
- 点击
- 客户
- 码
- 采集
- COM的
- 相当常见
- 常用
- 兼容
- 完成
- 完成
- 复杂
- 理解
- 概念
- CONFIRMED
- 消费者
- 消费类电子产品
- 内容
- 内容创造
- Contents
- 上下文
- 不断
- 谈话
- 兑换
- 转换
- 可以
- 国家
- 外壳
- 创建信息图
- 创建
- 创造
- 创建
- 创造力
- 信用
- 信用卡
- 关键
- 目前
- 黑暗
- data
- 数据科学
- 数据科学家
- 数据库
- 一年中的
- 借方
- 决策
- DEF
- 默认
- 学位
- 部署
- 沙漠
- 设计
- 设计
- 详细
- 详情
- 确定
- 开发
- 发达
- 开发
- 设备
- 不同
- 难
- 屏 显:
- do
- 文件
- 美元
- 不
- 下载
- 每
- 更容易
- 容易
- 易
- 边缘
- 有效
- 电子
- 伊隆
- 伊隆麝香
- 嵌入
- 使
- 编码
- 截至
- 工程师
- 引擎
- 英语
- 提高
- 充实
- 确保
- 输入
- 环境
- 故障
- 醚(ETH)
- 空灵
- 甚至
- 所有的
- 确切
- 有经验
- 试验
- 说明
- 解释
- 探索
- 额外
- 萃取
- 农业
- 专栏
- 特征
- 感觉
- 部分
- 文件
- 填充
- 过滤
- 终于
- 找到最适合您的地方
- 姓氏:
- 柔软
- 潦
- 重点
- 聚焦
- 遵循
- 针对
- 前额
- 格式
- 发现
- Free
- 止
- 功能
- 生成
- 产生
- 发电
- 代
- 得到
- GIF
- 给
- 特定
- 在全球范围内
- Go
- 黄金
- 图形
- 图神经网络
- 成长
- 指南
- 处理
- 帽子
- 恨
- 有
- he
- 帮助
- 这里
- 此处
- 高品质
- 亮点
- 他的
- 持有
- 创新中心
- How To
- HTTPS
- i
- 鉴定
- 确定
- if
- 疾病
- 图片
- 图像生成
- 图片
- 进口
- 重要
- 改善
- 改善
- in
- 包括
- 包含
- 合并
- 印度
- 个人
- 行业中的应用:
- 信息
- 信息
- 输入
- 安装
- 积分
- 智能化
- 互动
- 接口
- 成
- 涉及
- ISO
- IT
- 它的
- 首饰
- JPG
- 只是
- 掘金队
- 键
- 键
- 知道
- 知识
- 已知
- 景观
- 语言
- 语言
- 大
- LAS
- 拉斯维加斯
- 名:
- 潜伏
- 最新
- 学习用品
- 学习
- 遗产
- 让
- 自学资料库
- 喜欢
- 有限
- 清单
- ll
- 加载
- 装载
- 本地
- 当地
- 圖書分館的位置
- 爱
- 机
- 机器学习
- 使
- 制作
- 颠覆性技术
- 许多
- 主
- me
- 意味着
- 有意义的
- 心理
- 精神疾病
- 的话
- 条未读消息
- 元数据
- 方法
- 最低限度
- 最小可行产品
- 失踪
- 时尚
- 模型
- 造型
- 模型
- 更多
- 最先进的
- 山
- 麝香
- my
- 我自己
- 姓名
- 导航
- 需求
- 网络
- 神经
- 神经网络
- 决不要
- 全新
- 新功能
- 新用户
- 下页
- 节点
- Node.js的
- 鼻子
- 注意
- 笔记本
- 现在
- 数
- of
- 官方
- 正式
- on
- 一旦
- 一
- 在线
- 仅由
- 打开
- OpenAI
- 优化
- or
- OS
- 其他名称
- 我们的
- 输出
- 产量
- 己
- 包
- 页
- 部分
- 部分
- 模式
- 付款
- 感知
- 完美
- 性能
- 人
- 菲律宾
- 片
- 件
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 请
- 多项式
- 功率
- 供电
- 预测
- 准备
- 以前
- 先前
- 过程
- 处理
- 产品
- 所以专业
- 代码编程
- 项目
- 提示
- 保护
- 提供
- 提供
- 提供
- 优
- 采购
- 目的
- 蟒蛇
- 质量
- 有疑问吗?
- 相当
- RAIN
- 范围
- 急速
- 宁
- 阅读
- 阅读
- 收到
- 推荐
- 减少
- 减少
- 精制
- 定期
- 释放
- 相应
- 一个回复
- 代表
- 请求
- 必须
- 需要
- 响应
- 回复
- REST的
- 导致
- 回报
- 返回
- 米类
- 右
- 戒指
- 角色
- 运行
- 乡村
- 乡下地方
- s
- 神圣
- 安全
- 同
- SAND
- 保存
- 保存
- 缩放
- 现场
- 科学
- 科学家
- 搜索
- 秘密
- 安全
- 看到
- 选择
- 选择
- 语义
- 集
- 设置
- 她
- 短
- 应该
- 显示
- 作品
- 显著
- 类似
- 简易
- 只是
- 坐在
- 尺寸
- 天空
- So
- 一些
- 有些
- 不久
- 采购
- 东南
- 特别是
- 言语
- 标准
- 开始
- 开始
- 州/领地
- 国家的最先进的
- 存储
- 故事
- 流
- 串
- 结构化
- 结构化和非结构化数据
- 奋斗的
- 学生
- 工作室
- 顺利
- 这样
- 总结
- 周日
- 阳光
- 肯定
- 惊
- 系统
- T
- 任务
- 文案
- 技术
- 技术
- 专业技术
- 电信
- 文本
- 文字产生
- 文字转语音
- 文字的
- 泰国
- 比
- 这
- 菲律宾人
- 其
- 他们
- 然后
- 博曼
- 他们
- 认为
- Free Introduction
- 那些
- 通过
- 次
- 至
- 一起
- 象征
- 传统
- 培训
- 产品培训
- 成绩单
- 转型
- 转型
- 翻译
- 翻译
- 中英口译 笔译
- 树
- 轮唱
- true
- 教程
- 两次
- 类型
- 类型
- 一般
- 理解
- 了解
- 不像
- 非结构化
- 乌尔都语
- 网址
- us
- 可用
- USD
- 使用
- 用过的
- 用户
- 用户友好
- 用户
- 运用
- 折扣值
- 价值观
- 变量
- 变量
- 各个
- Ve
- 矢量
- VEGAS
- 版本
- 可行
- 视频
- 越南
- 查看
- 愿景
- 音色
- 卷
- 等候
- 步行
- 想
- 是
- we
- 井
- 什么是
- 什么是
- 这
- 耳语
- 白色
- WHO
- 为什么
- 无线网络连接
- 宽
- 大范围
- 将
- 中
- 女子
- 精彩
- 工作
- 一起工作
- 世界
- 写
- 写作
- 年
- 您
- 年轻
- 您一站式解决方案
- YouTube的
- 和风网