这篇文章是与 LSEG 低延迟小组的 Pramod Nayak、LakshmiKanth Mannem 和 Vivek Aggarwal 共同撰写的。
交易成本分析 (TCA) 被交易者、投资组合经理和经纪商广泛用于交易前和交易后分析,帮助他们衡量和优化交易成本及其交易策略的有效性。在这篇文章中,我们分析了期权买卖价差 LSEG 变动历史 – PCAP 数据集使用 适用于 Apache Spark 的亚马逊雅典娜。我们向您展示如何访问数据、定义应用于数据的自定义函数、查询和过滤数据集以及可视化分析结果,所有这些都无需担心设置基础架构或配置 Spark,即使对于大型数据集也是如此。
背景
期权价格报告局 (OPRA) 是一个重要的证券信息处理机构,负责收集、整合和传播美国期权的最新销售报告、报价和相关信息。 OPRA 拥有 18 个活跃的美国期权交易所和超过 1.5 万份合格合约,在提供全面的市场数据方面发挥着关键作用。
5 年 2024 月 48 日,证券业自动化公司 (SIAC) 计划将 OPRA 源从 96 个多播通道升级到 37.3 个。此增强功能旨在优化符号分布和线路容量利用率,以应对美国期权市场不断升级的交易活动和波动性。 SIAC 建议各公司为高达每秒 XNUMX GB 的峰值数据速率做好准备。
尽管升级不会立即改变已发布数据的总量,但它使 OPRA 能够以明显更快的速度传播数据。这种转变对于满足动态期权市场的需求至关重要。
OPRA 是数量最多的 Feed 之一,在 150.4 年第三季度达到单日 3 亿条消息的峰值,并且单日的容量空间需求为 2023 亿条消息。捕获每条消息对于交易成本分析、市场流动性监控、交易策略评估和市场研究至关重要。
关于数据
LSEG 变动历史 – PCAP 是一个基于云的存储库,超过 30 PB,容纳超高质量的全球市场数据。这些数据是在交换数据中心内直接捕获的,采用战略性地位于全球主要主要和备份交换数据中心的冗余捕获流程。 LSEG 的捕获技术可确保无损数据捕获,并使用 GPS 时间源实现纳秒时间戳精度。此外,还采用复杂的数据套利技术来无缝填补任何数据缺口。捕获后,数据经过细致的处理和仲裁,然后使用以下方法将其规范化为 Parquet 格式: LSEG 的实时超直接 (RTUD) 饲料处理机。
规范化过程是准备分析数据不可或缺的一部分,每天生成多达 6 TB 的压缩 Parquet 文件。海量数据归因于 OPRA 的包容性,跨越多个交易所,并具有众多具有不同属性的期权合约。市场波动性的增加和期权交易所的做市活动进一步增加了 OPRA 上发布的数据量。
Tick History – PCAP 的属性使公司能够进行各种分析,包括以下内容:
- 交易前分析 – 评估潜在的贸易影响并根据历史数据探索不同的执行策略
- 交易后评估 – 根据基准衡量实际执行成本,以评估执行策略的绩效
- 优化 执行 – 根据历史市场模式微调执行策略,以尽量减少市场影响并降低总体交易成本
- 风险管理 – 识别滑点模式、识别异常值并主动管理与交易活动相关的风险
- 绩效归因 – 在分析投资组合表现时将交易决策与投资决策的影响分开
LSEG Tick History – PCAP 数据集可在 AWS数据交换 并且可以访问 AWS Marketplace。 同 适用于 Amazon S3 的 AWS 数据交换,您可以直接从 LSEG 访问 PCAP 数据 亚马逊简单存储服务 (Amazon S3) 存储桶,企业无需存储自己的数据副本。这种方法简化了数据管理和存储,使客户能够立即访问高质量的 PCAP 或标准化数据,并且易于使用、集成和 节省大量数据存储.
Apache Spark 的 Athena
对于分析工作, Apache Spark 的 Athena 提供可通过 Athena 控制台或 Athena API 访问的简化笔记本体验,允许您构建交互式 Apache Spark 应用程序。借助优化的 Spark 运行时,Athena 通过在不到一秒的时间内动态扩展 Spark 引擎的数量来帮助分析 PB 级数据。此外,pandas 和 NumPy 等常用 Python 库无缝集成,允许创建复杂的应用程序逻辑。这种灵活性还延伸到了在笔记本中使用的自定义库的导入。 Athena for Spark 可容纳大多数开放数据格式,并与 AWS胶水 数据目录。
数据集
在本次分析中,我们使用了 17 年 2023 月 XNUMX 日的 LSEG Tick History – PCAP OPRA 数据集。该数据集包含以下组成部分:
- 最佳买价和卖价(BBO) – 报告给定交易所证券的最高出价和最低要价
- 全国最佳买入价和卖出价(NBBO) – 报告所有交易所中证券的最高出价和最低要价
- 交易 – 记录所有交易所已完成的交易
该数据集涉及以下数据量:
- 交易 – 160 MB 分布在大约 60 个压缩的 Parquet 文件中
- BBO – 2.4 TB 分布在大约 300 个压缩 Parquet 文件中
- NBBO – 2.8 TB 分布在大约 200 个压缩 Parquet 文件中
分析概览
分析 OPRA 报价历史数据以进行交易成本分析 (TCA) 涉及仔细审查特定交易事件的市场报价和交易。我们使用以下指标作为本研究的一部分:
- 报价点差 (QS) – 计算为 BBO 卖价和 BBO 买价之间的差额
- 有效价差 (ES) – 计算为交易价格与 BBO 中点之间的差额(BBO 买价 +(BBO 卖价 – BBO 买价)/2)
- 有效/报价价差 (EQF) – 计算公式为 (ES / QS) * 100
我们在交易前以及交易后的四个时间间隔(交易后、1 秒、10 秒和 60 秒)计算这些点差。
为 Apache Spark 配置 Athena
要为 Apache Spark 配置 Athena,请完成以下步骤:
- 在 Athena 控制台上,在 前往在线商城, 选择 使用 PySpark 和 Spark SQL 分析数据.
- 如果这是您第一次使用 Athena Spark,请选择 创建工作组.

- 针对 工作组名称¸ 输入工作组的名称,例如
tca-analysis. - 在 分析引擎 部分,选择 Apache Spark.
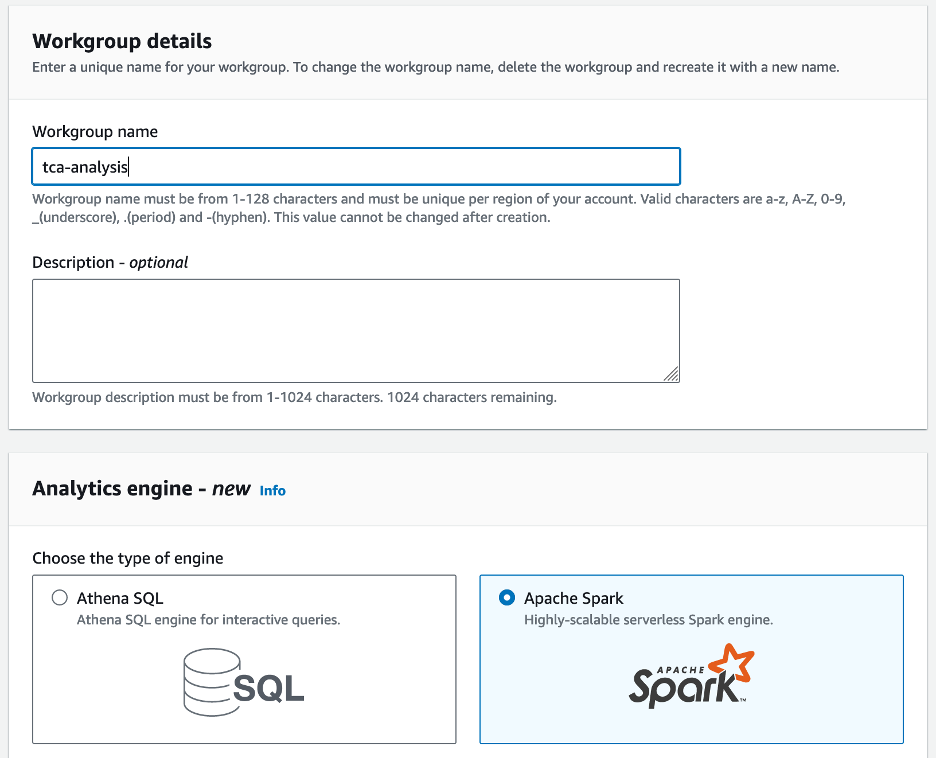
- 在 附加配置 部分,您可以选择 使用默认值 或提供自定义 AWS身份和访问管理 (IAM) 角色和计算结果的 Amazon S3 位置。
- 创建工作组.
- 创建工作组后,导航至 笔记本电脑 标签并选择 创建笔记本.
- 输入笔记本的名称,例如
tca-analysis-with-tick-history. - 创建 创建你的笔记本。
启动你的笔记本
如果您已经创建了 Spark 工作组,请选择 启动笔记本编辑器 下 前往在线商城.
![]()
创建笔记本后,您将被重定向到交互式笔记本编辑器。
![]()
现在我们可以将以下代码添加到我们的笔记本中并运行。
创建分析
完成以下步骤来创建分析:
- 导入常用库:
- 为 BBO、NBBO 和交易创建数据框:
- 现在我们可以确定用于交易成本分析的交易:
我们得到以下输出:
我们使用突出显示的未来交易信息来表示交易产品 (tp)、交易价格 (tpr) 和交易时间 (tt)。
- 这里我们创建了一些辅助函数来进行分析
- 在以下函数中,我们创建包含交易前后所有报价的数据集。 Athena Spark 自动确定启动多少个 DPU 来处理我们的数据集。
- 现在让我们使用所选交易的信息调用 TCA 分析函数:
可视化分析结果
现在让我们创建用于可视化的数据框。每个数据框包含每个数据源的五个时间间隔之一的报价(BBO、NBBO):
在以下部分中,我们提供示例代码来创建不同的可视化效果。
交易前绘制 QS 和 NBBO
使用以下代码绘制交易前的报价点差和 NBBO:
![]()
绘制每个市场的 QS 和交易后的 NBBO
使用以下代码在交易后立即绘制每个市场和 NBBO 的报价点差:
![]()
绘制 BBO 每个时间间隔和每个市场的 QS
使用以下代码绘制 BBO 每个时间间隔和每个市场的报价点差:
![]()
绘制每个时间间隔的 ES 和 BBO 的市场
使用以下代码绘制 BBO 每个时间间隔和市场的有效点差:
绘制 BBO 每个时间间隔和市场的 EQF
使用以下代码绘制 BBO 每个时间间隔和市场的有效/报价点差:
Athena Spark 计算性能
当您运行代码块时,Athena Spark 会自动确定完成计算需要多少 DPU。在最后一个代码块中,我们调用 tca_analysis 函数中,我们实际上是在指示 Spark 处理数据,然后将生成的 Spark 数据帧转换为 Pandas 数据帧。这是分析中最密集的处理部分,当 Athena Spark 运行此块时,它会显示进度条、经过的时间以及当前有多少 DPU 正在处理数据。例如,在以下计算中,Athena Spark 使用 18 个 DPU。
![]()
配置 Athena Spark 笔记本时,您可以选择设置它可以使用的最大 DPU 数量。默认值为 20 个 DPU,但我们使用 10、20 和 40 个 DPU 测试了此计算,以演示 Athena Spark 如何自动扩展以运行我们的分析。我们观察到,Athena Spark 线性扩展,当笔记本配置最多 15 个 DPU 时,耗时 21 分 10 秒;当笔记本配置 8 个 DPU 时,耗时 23 分 20 秒;当笔记本配置最大 DPU 时,耗时 4 分 44 秒。配置40个DPU。由于 Athena Spark 根据 DPU 使用情况进行收费,以每秒为粒度,因此这些计算的成本类似,但如果您设置更高的最大 DPU 值,Athena Spark 可以更快地返回分析结果。有关 Athena Spark 定价的更多详细信息,请点击 此处.
结论
在这篇文章中,我们演示了如何使用来自 LSEG 的 Tick History-PCAP 的高保真 OPRA 数据,通过 Athena Spark 执行交易成本分析。及时提供 OPRA 数据,辅以适用于 Amazon S3 的 AWS Data Exchange 的可访问性创新,可以战略性地缩短那些希望为关键交易决策创建可行见解的公司的分析时间。 OPRA 每天生成约 7 TB 的标准化 Parquet 数据,管理基础设施以提供基于 OPRA 数据的分析具有挑战性。
Athena 在处理 Tick History – PCAP for OPRA 数据的大规模数据处理方面具有可扩展性,使其成为在 AWS 中寻求快速且可扩展的分析解决方案的组织的绝佳选择。这篇文章展示了 AWS 生态系统和 Tick History-PCAP 数据之间的无缝交互,以及金融机构如何利用这种协同作用来推动关键交易和投资策略的数据驱动决策。
作者简介
![]() 普拉莫德·纳亚克 是 LSEG 低延迟团队的产品管理总监。 Pramod 在金融科技行业拥有超过 10 年的经验,专注于软件开发、分析和数据管理。 Pramod 是一名前软件工程师,对市场数据和量化交易充满热情。
普拉莫德·纳亚克 是 LSEG 低延迟团队的产品管理总监。 Pramod 在金融科技行业拥有超过 10 年的经验,专注于软件开发、分析和数据管理。 Pramod 是一名前软件工程师,对市场数据和量化交易充满热情。
![]() 拉克希米·坎特·曼内姆 是 LSEG 低延迟组的产品经理。他专注于低延迟市场数据行业的数据和平台产品。 LakshmiKanth 帮助客户构建满足其市场数据需求的最佳解决方案。
拉克希米·坎特·曼内姆 是 LSEG 低延迟组的产品经理。他专注于低延迟市场数据行业的数据和平台产品。 LakshmiKanth 帮助客户构建满足其市场数据需求的最佳解决方案。
![]() 维韦克·阿加瓦尔 是 LSEG 低延迟小组的高级数据工程师。 Vivek 致力于开发和维护数据管道,以处理和交付捕获的市场数据源和参考数据源。
维韦克·阿加瓦尔 是 LSEG 低延迟小组的高级数据工程师。 Vivek 致力于开发和维护数据管道,以处理和交付捕获的市场数据源和参考数据源。
![]() 阿尔克特·梅穆沙吉 是 AWS 金融服务市场开发团队的首席架构师。 Alket 负责技术战略,与合作伙伴和客户合作,将最苛刻的资本市场工作负载部署到 AWS 云。
阿尔克特·梅穆沙吉 是 AWS 金融服务市场开发团队的首席架构师。 Alket 负责技术战略,与合作伙伴和客户合作,将最苛刻的资本市场工作负载部署到 AWS 云。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :具有
- :是
- :不是
- :在哪里
- $UP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- 关于
- ACCESS
- 访问
- 访问
- 无障碍
- 横过
- 要积极。
- 活动
- 实际
- 通
- 加
- 另外
- 解决
- 优点
- 后
- 驳
- AGGARWAL
- 目标
- 所有类型
- 允许
- 已经
- Amazon
- 亚马逊雅典娜
- 亚马逊网络服务
- an
- 分析
- 分析
- 分析
- 分析
- 分析
- 分析
- 和
- 任何
- 阿帕奇
- Apache Spark
- APIs
- 应用领域
- 应用领域
- 使用
- 的途径
- 约
- 套利
- 仲裁
- 保健
- 围绕
- AS
- 问
- 评估
- 相关
- At
- 属性
- 权威
- 自动
- 自动化
- 可用性
- 可使用
- AWS
- 备份工具
- 酒吧
- 基于
- BE
- 因为
- before
- 基准
- 最佳
- 之间
- 出价
- 亿
- 阻止
- 经纪人
- 建立
- 但是
- by
- 计算
- 计算
- 计算
- 呼叫
- CAN
- 容量
- 资本
- 资本市场
- 捕获
- 捕获
- 捕获
- 检索目录
- 中心
- 挑战
- 通道
- 特征
- 收费
- 选择
- 客户
- 云端技术
- 码
- 收藏
- 相当常见
- 引人注目
- 完成
- 完成
- 组件
- 全面
- 包含
- 进行
- 配置
- 配置
- 安慰
- 巩固
- 包含
- 合同的
- 贡献
- 兑换
- 公司
- 价格
- 成本
- 合写的
- 创建信息图
- 创建
- 创建
- 危急
- 关键
- 目前
- 习俗
- 合作伙伴
- Dash 达世币
- data
- 数据中心
- 数据工程师
- 数据交换
- 数据管理
- 数据处理
- 数据存储
- 数据驱动
- 数据集
- 天
- 决策
- 决定
- 默认
- 定义
- 交货
- 严格
- 需求
- 演示
- 证明
- 部署
- 详情
- 确定
- 发展
- 研发支持
- 开发团队
- 差异
- 不同
- 直接
- 副总经理
- 分布
- 分配
- 不同
- 翻番
- 驾驶
- 动态
- 动态
- 动力学
- 每
- 缓解
- 使用方便
- 生态系统
- 编辑
- 有效
- 效用
- 合格
- 消除
- 就业
- 雇用
- enable
- 使
- 包含
- 努力
- 发动机
- 工程师
- 引擎
- 增强
- 确保
- 输入
- 不断升级
- 醚(ETH)
- 评估
- 评估
- 甚至
- 活动
- 所有的
- 例子
- 交换
- 换货
- 执行
- 体验
- 探索
- 特快
- 扩展
- 快
- 特色
- 二月
- 无花果
- 档
- 填
- 过滤
- 金融
- 金融机构
- 金融服务
- 金融技术
- 企业
- 姓氏:
- 第一次
- 五
- 高度灵活
- 重点
- 聚焦
- 以下
- 针对
- 格式
- 前
- 向前
- 四
- FRAME
- 止
- 功能
- 功能
- 进一步
- 差距
- 产生
- 得到
- 特定
- 全球
- 全球市场
- Go
- 去
- GPS
- 团队
- 处理
- 有
- 有
- he
- 净空
- 帮助
- 高品质
- 更高
- 最高
- 突出
- 历史的
- 历史
- 住房
- 创新中心
- How To
- HTTP
- HTTPS
- IAM
- 鉴定
- 身分
- if
- 即时
- 立即
- 影响力故事
- 进口
- in
- 包含
- 增加
- 行业中的应用:
- 信息
- 基础设施
- 创新
- 可行的洞见
- 机构
- 积分
- 集成
- 积分
- 相互作用
- 互动
- 成
- 错综复杂
- 投资
- 涉及
- IT
- JPG
- 只是
- 大
- 大规模
- 名:
- 潜伏
- 发射
- 减
- 库
- Line
- 流动性
- 圖書分館的位置
- 逻辑
- 寻找
- 低
- 最低
- 维持
- 主要
- 制作
- 制作
- 管理
- 颠覆性技术
- 经理
- 经理
- 管理的
- 方式
- 许多
- 市场
- 市场数据
- 市场影响
- 市场调查
- 市场波动
- 做市
- 市场
- 大规模
- 掌握
- 最多
- 可能..
- 衡量
- 的话
- 条未读消息
- 细致
- 精心
- 指标
- 百万
- 大幅减低
- 分钟
- 监控
- 更多
- 此外
- 最先进的
- 许多
- 多
- 姓名
- 自然
- 导航
- 需求
- 需要
- 不包含
- 笔记本
- 笔记本电脑
- 数
- 众多
- 麻木
- 观察
- of
- 提供
- 优惠精选
- on
- 一
- 最佳
- 优化
- 优化
- 附加选项
- 附加选项
- or
- 组织
- 我们的
- 输出
- 产量
- 超过
- 最划算
- 己
- 大熊猫
- 部分
- 伙伴
- 多情
- 模式
- 高峰
- 为
- 演出
- 性能
- 关键的
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 扮演
- 请
- 情节
- 个人档案
- 投资组合经理
- 定位的
- 帖子
- 交易后
- 潜力
- 平台精度
- Prepare
- 准备
- 车资
- 价格
- 小学
- 校长
- 过程
- 过程
- 处理
- 处理器
- 产品
- 产品管理
- 产品经理
- 热销产品
- 进展
- 提供
- 优
- 出版
- 蟒蛇
- Q3
- 量
- 数量
- 询问
- 报价
- 率
- 价格表
- 阅读
- 真实
- 实时的
- 建议
- 记录
- 红色
- 减少
- 减少
- 参考
- refinitiv
- 报告
- 业务报告
- 知识库
- 需求
- 需要
- 研究
- 响应
- 提供品牌战略规划
- 导致
- 导致
- 成果
- 回报
- 风险
- 角色
- 运行
- 运行
- 盐
- 可扩展性
- 可扩展性
- 秤
- 缩放
- 无缝的
- 无缝
- 其次
- 秒
- 部分
- 部分
- 证券
- 保安
- 寻求
- 选择
- 选
- 前辈
- 分开
- 服务
- 特色服务
- 集
- 设置
- 显示
- 作品
- 显著
- 类似
- 简易
- 简
- 单
- 滑移
- 软件
- 软件开发
- 软件工程师
- 解决方案
- 极致
- 张力
- 火花
- 具体的
- 传播
- 价差
- 看台
- 步骤
- 存储
- 商店
- 从战略
- 策略
- 策略
- 流线
- 学习
- 随后
- 这样
- SWIFT的
- 符号
- 协同
- 采取
- 服用
- 团队
- 文案
- 技术
- 专业技术
- 测试
- 比
- 这
- 信息
- 其
- 他们
- 然后
- 博曼
- Free Introduction
- 通过
- 蜱
- 次
- 及时
- 时间戳
- 标题
- 至
- 合计
- tp
- TPR
- 贸易
- 交易商
- 行业
- 交易
- 交易策略
- 交易策略
- 交易
- 交易成本
- 转型
- 过渡
- 超级
- 下
- 经历
- 升级
- us
- 用法
- 使用
- 用过的
- 使用
- 运用
- 利用
- 折扣值
- 各个
- 可视化
- 想像
- 挥发性
- 体积
- 卷
- 是
- we
- 卷筒纸
- Web服务
- ,尤其是
- 这
- 广泛
- 将
- 中
- 也完全不需要
- 工作组
- 加工
- 合作
- 全世界
- 担心
- X
- 年
- 您
- 您一站式解决方案
- 和风网