所有行业的组织都对跨不同分析系统的分析用例有复杂的数据处理要求,例如 AWS 上的数据湖, 数据仓库 (亚马逊Redshift), 搜索 (亚马逊开放搜索服务), 非数据库 (Amazon DynamoDB), 机器学习 (亚马逊SageMaker), 和更多。 分析专业人员的任务是从存储在这些分布式系统中的数据中获取价值,从而为他们的客户创造更好、更安全且成本优化的体验。 例如,数字媒体公司寻求合并和处理内部和外部数据库中的数据集,以建立统一的客户档案视图,激发创新功能的想法,并提高平台参与度。
在这些场景中,寻找无服务器数据集成产品的客户使用 AWS胶水 作为处理和分类数据的核心组件。 AWS Glue 与 AWS 服务和合作伙伴产品很好地集成,并提供低代码/无代码提取、转换和加载 (ETL) 选项以支持分析、机器学习 (ML) 或应用程序开发工作流程。 AWS Glue ETL 作业可能是更复杂管道中的一个组件。 协调这些组件的运行和管理这些组件之间的依赖关系是数据策略中的一项关键功能。 适用于 Apache Airflows 的 Amazon 托管工作流 (Amazon MWAA) 使用分布式技术编排数据管道,包括本地资源、AWS 服务和第三方组件。
在本文中,我们展示了如何使用 Amazon MWAA 的最新功能简化对由 Airflow 编排的 AWS Glue 作业的监控。
解决方案概述
这篇文章讨论了以下内容:
- 如何将 Amazon MWAA 环境升级到版本 2.4.3。
- 如何从 Airflow 编排 AWS Glue 作业 有向无环图 (DAG)。
- Airflow Amazon 提供程序包在 Amazon MWAA 中的可观察性增强。 您现在可以在 Airflow 控制台上整合 AWS Glue 作业的运行日志,以简化数据管道的故障排除。 Amazon MWAA 控制台成为监控和分析 AWS Glue 作业运行的单一参考。 以前,支持团队需要访问 AWS管理控制台 并为此可见性采取手动步骤。 Amazon MWAA 2.4.3 版默认提供此功能。
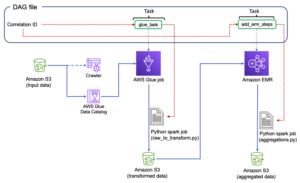
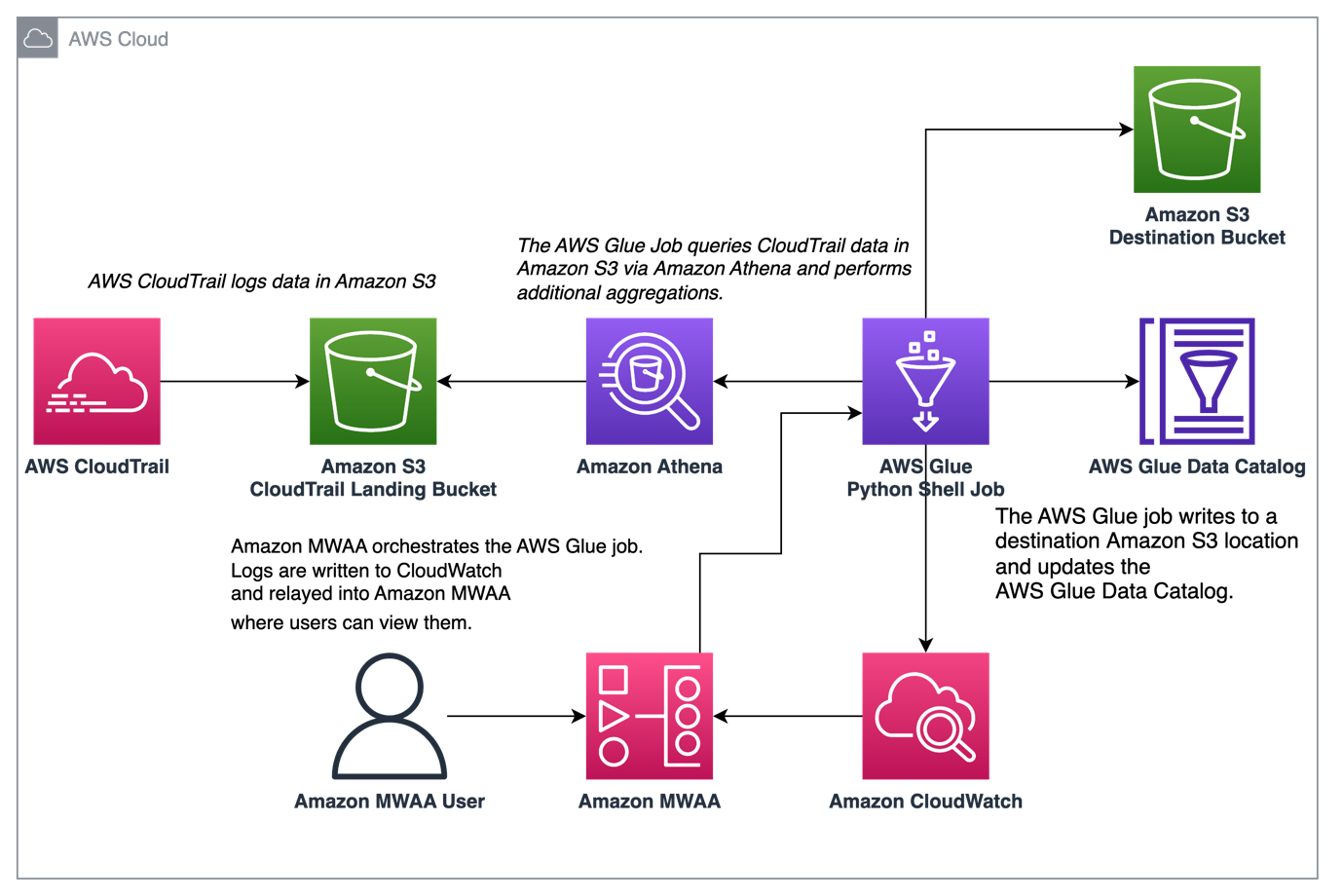
下图说明了我们的解决方案体系结构。
先决条件
您需要满足以下先决条件:
设置亚马逊 MWAA 环境
有关创建环境的说明,请参阅 创建 Amazon MWAA 环境. 对于现有用户,我们建议升级到版本 2.4.3 以利用本文中介绍的可观察性增强功能。
将 Amazon MWAA 升级到版本 2.4.3 的步骤因当前版本是 1.10.12 还是 2.2.2 而异。 我们在这篇文章中讨论了这两种选择。
设置 Amazon MWAA 环境的先决条件
您必须满足以下先决条件:
从版本 1.10.12 升级到 2.4.3
如果您使用的是 Amazon MWAA 版本 1.10.12,请参阅 迁移到新的 Amazon MWAA 环境 升级到 2.4.3。
从版本 2.0.2 或 2.2.2 升级到 2.4.3
如果您使用的是 Amazon MWAA 环境版本 2.2.2 或更低版本,请完成以下步骤:
- 创建一个 任何自定义依赖项的 requirements.txt 具有您的 DAG 所需的特定版本。
- 将文件上传到 Amazon S3 在 Amazon MWAA 环境指向用于安装依赖项的 requirements.txt 的适当位置。
- 按照中的步骤 迁移到新的 Amazon MWAA 环境 并选择版本 2.4.3。
更新您的 DAG
从较旧的 Amazon MWAA 环境升级的客户可能需要对现有 DAG 进行更新。 在 Airflow 2.4.3 版本中,Airflow 环境将默认使用 Amazon provider package 6.0.0 版本。 此软件包可能包含一些潜在的重大更改,例如对操作员名称的更改。 例如, AWSGlueJob操作员 已被弃用并替换为 GlueJob操作员. 为了保持兼容性,请更新您的 Airflow DAG,将之前版本中任何已弃用或不受支持的运算符替换为新运算符。 完成以下步骤:
- 导航 亚马逊 AWS 运营商.
- 选择安装在您的 Amazon MWAA 实例中的适当版本(默认为 6.0.0。)以查找受支持的 Airflow 运算符列表。
- 对现有 DAG 代码进行必要的更改,并将修改后的文件上传到 Amazon S3 中的 DAG 位置。
从 Airflow 编排 AWS Glue 作业
本节介绍在 Airflow DAG 中编排 AWS Glue 作业的详细信息。 Airflow 通过异构系统之间的依赖关系(例如本地流程、外部依赖关系、其他 AWS 服务等)简化了数据管道的开发。
使用 AWS Glue 和 Amazon MWAA 编排 CloudTrail 日志聚合
在此示例中,我们通过使用 Amazon MWAA 编排 AWS Glue Python Shell 作业的用例,该作业保留基于 CloudTrail 日志的聚合指标。
CloudTrail 支持查看在您的 AWS 账户中进行的 AWS API 调用。 此数据的一个常见用例是收集委托人的使用指标,这些委托人作用于您帐户的资源,以满足审计和监管需求。
在记录 CloudTrail 事件时,它们在 Amazon S3 中作为 JSON 文件传送,这对于分析查询来说并不理想。 我们希望聚合此数据并将其保存为 Parquet 文件以实现最佳查询性能。 作为初始步骤,我们可以使用 Athena 对数据进行初始查询,然后再在我们的 AWS Glue 作业中进行额外的聚合。 有关创建 AWS Glue 数据目录表的更多信息,请参阅 使用分区投影在 Athena 中为 CloudTrail 日志创建表 数据。 在我们通过 Athena 探索数据并决定要在聚合表中保留哪些指标后,我们可以创建一个 AWS Glue 作业。
在 Athena 中创建 CloudTrail 表
首先,我们需要在数据目录中创建一个表,允许通过 Athena 查询 CloudTrail 数据。 以下示例查询创建一个表,该表在区域和日期(称为 snapshot_date)上具有两个分区。 请务必替换 CloudTrail 存储桶、AWS 账户 ID 和 CloudTrail 表名称的占位符:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')在 Athena 控制台上运行上述查询,并记下表名称和创建它的 AWS Glue 数据目录数据库。 我们稍后会在 Airflow DAG 代码中使用这些值。
示例 AWS Glue 作业代码
以下代码是示例 AWS Glue Python Shell 作业 执行以下操作:
- 接受关于哪一天要处理的数据的参数(我们从我们的 Amazon MWAA DAG 传递)
- 使用 适用于熊猫的 AWS 开发工具包 运行 Athena 查询以在 AWS Glue 之外对 CloudTrail JSON 数据进行初始过滤
- 使用 Pandas 对过滤后的数据进行简单的聚合
- 将聚合数据输出到表中的 AWS Glue 数据目录
- 在处理期间使用日志记录,这将在 Amazon MWAA 中可见
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
以下是此 AWS Glue 作业的一些主要优势:
- 我们使用 Athena 查询来确保初始过滤是在我们的 AWS Glue 作业之外完成的。 因此,具有最小计算量的 Python Shell 作业仍然足以聚合大型 CloudTrail 数据集。
- 我们确保 分析库设置选项 在创建我们的 AWS Glue 作业以使用 AWS SDK for Pandas 库时打开。
创建 AWS Glue 作业
完成以下步骤以创建您的 AWS Glue 作业:
- 复制上一节的脚本,保存在本地文件中。 对于这篇文章,该文件被称为
script.py. - 在 AWS Glue 控制台上,选择 ETL职位 在导航窗格中。
- 创建一个新作业并选择 Python Shell 脚本编辑器.
- 选择 上传和编辑现有脚本 并上传您保存在本地的文件。
- 创建.

- 点击 工作细节 选项卡,输入您的 AWS Glue 作业的名称。
- 针对 IAM角色,选择现有角色或创建具有 Amazon S3、AWS Glue 和 Athena 所需权限的新角色。 该角色需要查询您之前创建的 CloudTrail 表并写入输出位置。
您可以使用以下示例策略代码。 将占位符替换为您的 CloudTrail 日志存储桶、输出表名称、输出 AWS Glue 数据库、输出 S3 存储桶、CloudTrail 表名称、包含 CloudTrail 表的 AWS Glue 数据库以及您的 AWS 账户 ID。
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
针对 Python版本,选择 Python的3.9.
- 选择 加载通用分析库.
- 针对 数据处理单元,选择 1个DPU.
- 将其他选项保留为默认值或根据需要进行调整。

- 保存 保存您的作业配置。
配置 Amazon MWAA DAG 以编排 AWS Glue 作业
以下代码适用于可以编排我们创建的 AWS Glue 作业的 DAG。 我们利用此 DAG 中的以下主要功能:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
提高 Amazon MWAA 中 AWS Glue 作业的可观察性
AWS Glue 作业将日志写入 亚马逊CloudWatch. 随着最近对 Airflow 的 Amazon 提供商包的可观察性增强,这些日志现在与 Airflow 任务日志集成在一起。 这种整合为 Airflow 用户提供直接在 Airflow UI 中的端到端可见性,无需在 CloudWatch 或 AWS Glue 控制台中进行搜索。
要使用此功能,请确保附加到 Amazon MWAA 环境的 IAM 角色具有以下权限来检索和写入必要的日志:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}如果 verbose=true,AWS Glue 作业运行日志将显示在 Airflow 任务日志中。 默认为假。 有关详细信息,请参阅 参数.
启用后,DAG 从 AWS Glue 作业的 CloudWatch 日志流中读取并将它们中继到 Airflow DAG AWS Glue 作业步骤日志。 这可以通过 DAG 日志实时详细了解 AWS Glue 作业的运行情况。 请注意,AWS Glue 作业会分别根据作业的 STDOUT 和 STDERR 生成输出和错误 CloudWatch 日志组。 输出日志组中的所有日志以及错误日志组中的异常或错误日志都将中继到 Amazon MWAA。
AWS 管理员现在可以限制支持团队仅访问 Airflow,使 Amazon MWAA 成为作业编排和作业健康管理的单一平台。 以前,用户需要在 Airflow DAG 步骤中检查 AWS Glue 作业运行状态并检索作业运行标识符。 然后,他们需要访问 AWS Glue 控制台以查找作业运行历史记录,使用标识符搜索感兴趣的作业,最后导航到该作业的 CloudWatch 日志以进行故障排除。
创建 DAG
要创建 DAG,请完成以下步骤:
- 将前面的 DAG 代码保存到本地 .py 文件,替换指定的占位符。
您的 AWS 账户 ID、AWS Glue 作业名称、带有 CloudTrail 表的 AWS Glue 数据库和 CloudTrail 表名称的值应该是已知的。 您可以根据需要调整输出 S3 存储桶、输出 AWS Glue 数据库和输出表名称,但请确保您之前使用的 AWS Glue 作业的 IAM 角色已相应配置。
- 在 Amazon MWAA 控制台上,导航到您的环境以查看 DAG 代码的存储位置。
DAGs 文件夹是 S3 存储桶中应放置 DAG 文件的前缀。
- 在那里上传您编辑的文件。

- 打开 Amazon MWAA 控制台以确认 DAG 出现在表中。

运行 DAG
要运行 DAG,请完成以下步骤:
- 从以下选项中选择:
- 触发DAG – 这导致昨天的数据被用作要处理的数据
- 使用配置触发 DAG – 使用此选项,您可以传入不同的日期,可能用于回填,使用
dag_run.conf在 DAG 代码中,然后作为参数传递到 AWS Glue 作业中

如果您选择以下屏幕截图,则会显示其他配置选项 使用配置触发 DAG.

- 在 DAG 运行时对其进行监控。
- DAG 完成后,打开运行的详细信息。
在右窗格中,您可以查看日志,或选择 任务实例详细信息 完整视图。

- 得益于
GlueJobOperator详细标志。

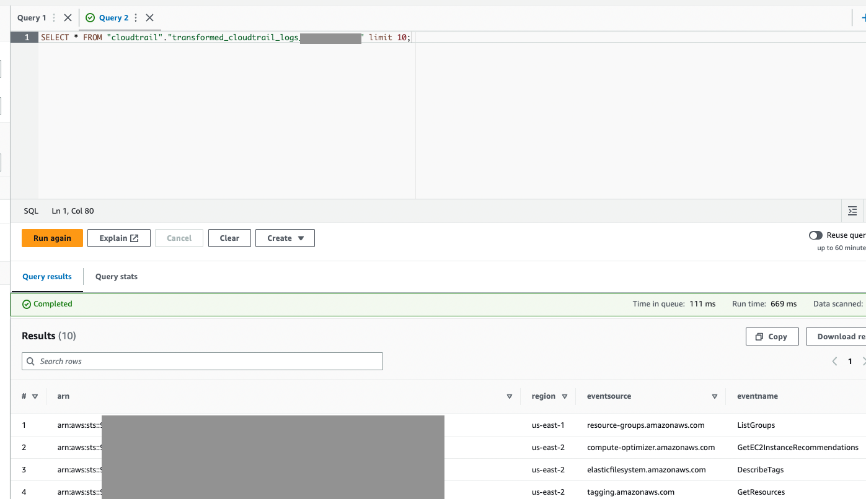
AWS Glue 作业会将结果写入您指定的输出表。
- 通过 Athena 查询此表以确认它是成功的。
总结
Amazon MWAA 现在提供一个位置来跟踪 AWS Glue 作业状态,并使您能够将 Airflow 控制台用作作业编排和运行状况管理的单一管理平台。 在本文中,我们逐步介绍了使用 Airflow 通过 Airflow 编排 AWS Glue 作业的步骤 GlueJobOperator. 借助新的可观察性增强功能,您可以在统一体验中无缝地对 AWS Glue 作业进行故障排除。 我们还演示了如何将您的 Amazon MWAA 环境升级到兼容版本、更新依赖项并相应地更改 IAM 角色策略。
有关常见故障排除步骤的更多信息,请参阅 故障排除:创建和更新 Amazon MWAA 环境. 有关迁移到 Amazon MWAA 环境的详细信息,请参阅 从 1.10 升级到 2. 要了解开源代码更改以提高 Airflow Amazon 提供商包中 AWS Glue 作业的可观察性,请参阅 从 AWS Glue 作业中继日志.
最后,我们建议访问 AWS 大数据博客 有关 AWS 上的分析、ML 和数据治理的其他材料。
作者简介
 鲁沙布·洛坎德 是 AWS 专业服务分析实践的数据和机器学习工程师。 他帮助客户实施大数据、机器学习和分析解决方案。 工作之余,他喜欢与家人共度时光、阅读、跑步和打高尔夫球。
鲁沙布·洛坎德 是 AWS 专业服务分析实践的数据和机器学习工程师。 他帮助客户实施大数据、机器学习和分析解决方案。 工作之余,他喜欢与家人共度时光、阅读、跑步和打高尔夫球。
 瑞安·戈麦斯 是 AWS 专业服务分析实践的数据和机器学习工程师。 他热衷于通过云中的分析和机器学习解决方案帮助客户取得更好的成果。 工作之余,他喜欢健身、烹饪以及与朋友和家人共度美好时光。
瑞安·戈麦斯 是 AWS 专业服务分析实践的数据和机器学习工程师。 他热衷于通过云中的分析和机器学习解决方案帮助客户取得更好的成果。 工作之余,他喜欢健身、烹饪以及与朋友和家人共度美好时光。
 维斯瓦·古普塔 是 AWS 专业服务分析实践的高级数据架构师。 他帮助客户实施大数据和分析解决方案。 工作之余,他喜欢与家人共度时光、旅行和尝试新食物。
维斯瓦·古普塔 是 AWS 专业服务分析实践的高级数据架构师。 他帮助客户实施大数据和分析解决方案。 工作之余,他喜欢与家人共度时光、旅行和尝试新食物。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图爱流。 Web3 数据智能。 知识放大。 访问这里。
- 与 Adryenn Ashley 一起铸造未来。 访问这里。
- 使用 PREIPO® 买卖 PRE-IPO 公司的股票。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :具有
- :是
- :不是
- :在哪里
- $UP
- 1
- 10
- 100
- 12
- 8
- a
- 关于
- ACCESS
- 因此
- 账号管理
- 横过
- 操作
- 无环
- 额外
- 优点
- 优点
- 后
- 聚合
- 所有类型
- 让
- 允许
- 已经
- 还
- Amazon
- 亚马逊网络服务
- an
- 分析
- 分析
- 分析
- 和
- 任何
- 阿帕奇
- API
- 应用领域
- 应用程序开发
- 适当
- 架构
- 保健
- 论点
- 参数
- AS
- At
- 属性
- 审计
- 可使用
- AWS
- AWS胶水
- AWS专业服务
- 基于
- BE
- 成为
- 很
- before
- 作为
- 更好
- 之间
- 大
- 大数据运用
- 都
- 破坏
- 建立
- 但是
- by
- 被称为
- 呼叫
- CAN
- 案件
- 例
- 检索目录
- 原因
- 更改
- 更改
- 查
- 云端技术
- 码
- COM的
- 结合
- 评论
- 相当常见
- 公司
- 兼容性
- 兼容
- 完成
- 复杂
- 元件
- 组件
- 计算
- 配置
- 确认
- 安慰
- 巩固
- 合并
- 烹调
- 核心
- 占地面积
- 创建信息图
- 创建
- 创建
- 创造
- 电流
- 习俗
- 顾客
- 合作伙伴
- DAG
- data
- 数据集成
- 数据处理
- 数据策略
- 数据仓库
- 数据库
- 数据库
- 数据集
- 日期
- 重要日期
- 日期时间
- 一年中的
- 决定
- 默认
- 提升
- 证明
- 根据
- 弃用
- 详细
- 详情
- 研发支持
- 不同
- 不同
- 数字
- 数字媒体
- 直接
- 讨论
- 分布
- 分布式系统
- do
- 不
- 做
- 完成
- ,我们将参加
- e
- 此前
- 例
- 效果
- 消除
- 其他
- enable
- 启用
- 使
- 端至端
- 订婚
- 工程师
- 增强
- 确保
- 输入
- 环境
- 错误
- 醚(ETH)
- 事件
- 例子
- 除
- 例外
- 存在
- 现有
- 存在
- 体验
- 体验
- 探讨
- 表达
- 外部
- 提取
- 失败
- false
- 家庭
- 专栏
- 精选
- 特征
- 文件
- 档
- 过滤
- 终于
- 找到最适合您的地方
- 运动健身
- 以下
- 食品
- 针对
- 格式
- 朋友
- 止
- ,
- 收集
- 生成
- 玻璃
- Go
- 高尔夫球
- 治理
- 团队
- Hadoop的
- 有
- he
- 健康管理
- 帮助
- 帮助
- 历史
- 蜂房
- 创新中心
- How To
- HTML
- HTTP
- HTTPS
- IAM
- ID
- 理想
- 思路
- 识别码
- if
- 说明
- 实施
- 进口
- in
- 深入
- 包括
- 包含
- 增加
- 增加
- 表示
- 行业
- info
- 信息
- 初始
- 创新
- 可行的洞见
- 安装
- 例
- 说明
- 集成
- 积分
- 兴趣
- 内部
- 成
- IT
- 工作
- 工作机会
- JPG
- JSON
- 键
- 已知
- 大
- 后来
- 最新
- 学习用品
- 学习
- 自学资料库
- 极限
- 清单
- 加载
- 本地
- 当地
- 圖書分館的位置
- 日志
- 记录
- 记录
- 寻找
- 机
- 机器学习
- 制成
- 保持
- 使
- 制作
- 管理
- 颠覆性技术
- 管理的
- 手册
- 材料
- 可能..
- 媒体
- 满足
- 的话
- 指标
- 迁移
- 最小
- ML
- 改性
- 模块
- 显示器
- 监控
- 更多
- 必须
- 姓名
- 名称
- 导航
- 旅游导航
- 必要
- 需求
- 打印车票
- 需要
- 全新
- 没什么
- 现在
- of
- 提供
- on
- 一
- 那些
- 仅由
- 打开
- 开放源码
- 开源代码
- 操作者
- 运营商
- 最佳
- 附加选项
- 附加选项
- or
- 精心策划
- 管弦乐编曲
- 其他名称
- 我们的
- 结果
- 产量
- 学校以外
- 包
- 大熊猫
- 面包
- 参数
- 合伙人
- 通过
- 通过
- 多情
- 性能
- 权限
- 仍然存在
- 管道
- 地方
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 点
- 政策
- 帖子
- 可能
- 在练习上
- 先决条件
- 以前
- 先前
- 过程
- 过程
- 处理
- 核心产品
- 所以专业
- 专业人士
- 简介
- 投影
- 提供者
- 供应商
- 提供
- 蟒蛇
- 质量
- 查询
- 提高
- 范围
- 阅读
- 阅读
- 真实
- 实时的
- 最近
- 建议
- 地区
- 监管
- 继电器
- 更换
- 更换
- 必须
- 岗位要求
- 资源
- 资源
- 分别
- 响应
- 成果
- 保留
- 右
- 角色
- 行
- 运行
- 运行
- s
- 保存
- 情景
- SDK
- 无缝
- 搜索
- 部分
- 安全
- 看到
- 寻找
- 前辈
- 无服务器
- 特色服务
- 设置
- 格局
- 壳
- 应该
- 显示
- 作品
- 简易
- 简化
- 自
- 单
- 快照
- 方案,
- 解决方案
- 一些
- 具体的
- 指定
- 花费
- 个人陈述
- Status
- 步
- 步骤
- 仍
- 存储
- 存储
- 策略
- 流
- 串
- 成功
- 这样
- 足够
- SUPPORT
- 支持
- 产品
- 表
- 采取
- 服用
- 任务
- 队
- 技术
- 模板
- 谢谢
- 这
- 其
- 他们
- 然后
- 那里。
- 博曼
- 他们
- 第三方
- Free Introduction
- 通过
- 次
- 至
- 跟踪时
- 改造
- 旅游
- true
- 尝试
- 周二
- 转身
- 二
- 类型
- ui
- 统一
- 单元
- 更新
- 最新动态
- 更新
- 升级
- 升级
- 上传
- 用法
- 使用
- 用例
- 用过的
- 用户
- 运用
- 折扣值
- 价值观
- 版本
- 通过
- 查看
- 意见
- 能见度
- 可见
- 走
- 想
- 是
- we
- 卷筒纸
- Web服务
- 井
- 什么是
- ,尤其是
- 是否
- 这
- WHO
- 将
- 中
- 也完全不需要
- 工作
- 工作流程
- 将
- 写
- 书面
- 您
- 您一站式解决方案
- 和风网