当 OpenAI ChatGPT 吸尽了 24 小时新闻周期的所有氧气时,谷歌悄悄推出了一种新的人工智能模型,可以在给定视频、图像和文本输入时生成视频。 新的 Google Dreamix AI 视频编辑器现在使生成的视频更接近现实。
根据 GitHub 上发布的研究,Dreamix 根据视频和文本提示编辑视频。 生成的视频保持其对颜色、姿势、对象大小和相机姿势的保真度,从而产生时间上一致的视频。 目前,Dreamix 无法仅根据提示生成视频,但是,它可以获取现有材料并使用文本提示修改视频。
谷歌为 Dreamix 使用视频扩散模型,这种方法已成功应用于我们在 DALL-E2 或开源稳定扩散等图像 AI 中看到的大多数视频图像编辑。
该方法涉及大量减少输入视频,添加人工噪声,然后在视频扩散模型中对其进行处理,然后使用文本提示从中生成新视频,保留原始视频的某些属性并根据重新渲染其他视频到文本输入。
视频传播模型提供了一个充满希望的未来,可能会开创一个处理视频的新时代。

例如,在下面的视频中,Dreamix 将吃东西的猴子(左)变成了跳舞的熊(右),给出了提示“一只熊随着欢快的音乐跳舞和跳跃,移动了他的整个身体。”
在下面的另一个示例中,Dreamix 使用单张照片作为模板(如图像到视频),然后通过提示在视频中将对象动画化。 在新场景或随后的延时录制中也可以进行摄像机移动。
在另一个例子中,Dreamix 将水池中的猩猩(左)变成了一只在漂亮的浴室里沐浴着橙色毛发的猩猩。
“虽然扩散模型已成功应用于图像编辑,但很少有作品用于视频编辑。 我们提出了第一个基于扩散的方法,该方法能够对一般视频执行基于文本的运动和外观编辑。”
根据谷歌的研究论文,Dreamix 使用视频扩散模型在推理时将来自原始视频的低分辨率时空信息与其合成的新的高分辨率信息相结合,以与指导文本提示对齐。”
谷歌表示,之所以采用这种方法,是因为“要获得原始视频的高保真度,需要保留其部分高分辨率信息,我们在原始视频上添加了一个微调模型的初步阶段,显着提高了保真度。”
以下是 Dreamix 工作原理的视频概述。
[嵌入的内容]
Dreamix 视频传播模型的工作原理
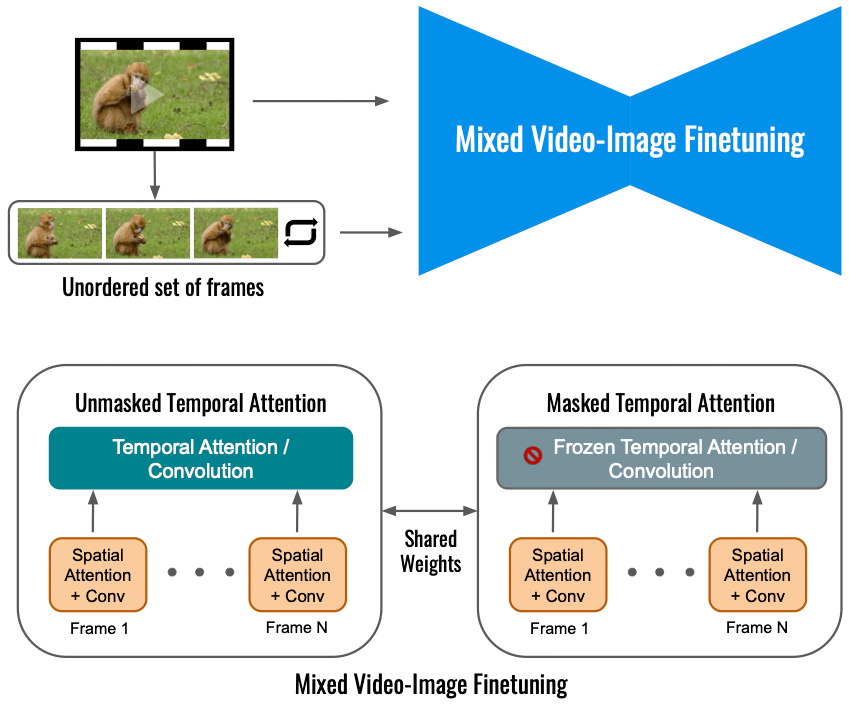
根据谷歌的说法,仅在输入视频上微调 Dreamix 的视频扩散模型就限制了运动变化的程度。 相反,我们使用混合目标,除了原始目标(左下角)之外,还对无序帧集进行微调。 这是通过使用“masked temporal attention”来完成的,防止时间注意力和卷积被微调(右下)。 这允许向静态视频添加运动。
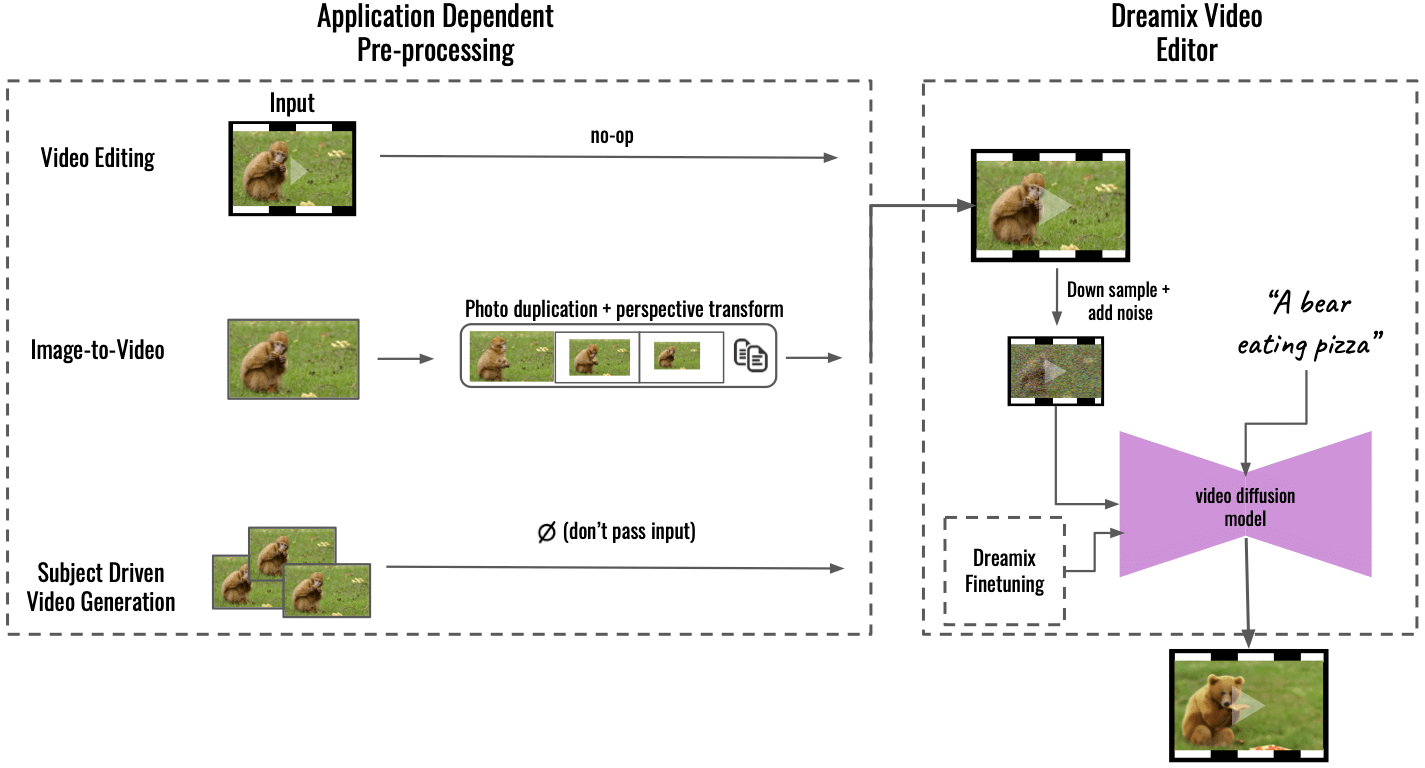
“我们的方法通过依赖于应用程序的预处理(左)支持多种应用程序,将输入内容转换为统一的视频格式。 对于图像到视频,输入图像被复制并使用透视变换进行变换,合成带有一些相机运动的粗略视频。 对于主题驱动的视频生成,输入被省略——微调单独处理保真度。 然后使用我们的通用“Dreamix 视频编辑器”(右)编辑这个粗糙的视频:我们首先通过下采样破坏视频,然后添加噪声。 然后,我们应用微调的文本引导视频扩散模型,将视频放大到最终的时空分辨率,”Dream 在上写道 GitHub上.
您可以阅读下面的研究论文。
谷歌 Dreamix- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- Able
- 根据
- AI
- 艾视频
- AI供电
- 所有类型
- 允许
- 单
- 和
- 另一个
- 应用领域
- 应用的
- 使用
- 的途径
- 人造的
- 关注我们
- 基于
- 承担
- 美丽
- 因为
- 作为
- 如下。
- 身体
- 提高
- 半身裙/裤
- 带来
- 相机
- 不能
- 关心
- 更改
- ChatGPT
- 接近
- 颜色
- 结合
- 一贯
- 内容
- 创造
- 周期
- 跳舞
- 扩散
- 梦想
- 编辑
- 嵌入式
- 时代
- 例子
- 现有
- 少数
- 保真度
- 最后
- 姓氏:
- 其次
- 格式
- 止
- 未来
- 总类
- 生成
- 产生
- 代
- GIF
- GitHub上
- 特定
- 谷歌
- 头发
- 严重
- 高分辨率
- 创新中心
- 但是
- HTTPS
- 图片
- 图片
- in
- 信息
- 输入
- 代替
- IT
- 启动
- 范围
- 维护
- 材料
- 最大
- 方法
- 杂
- 模型
- 模型
- 修改
- 时刻
- 最先进的
- 运动
- 运动
- 移动
- 多
- 音乐
- 全新
- 消息
- 噪声
- 对象
- 目标
- 优惠精选
- 开放源码
- OpenAI
- 橘色
- 原版的
- 其它
- 简介
- 氧
- 纸类
- 演出
- 透视
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 池
- 可能
- 当下
- 预防
- 处理
- 有希望
- 出版
- 悄悄
- 阅读
- 现实
- 了解
- 减少
- 需要
- 研究
- 分辨率
- 导致
- 护
- 说
- 现场
- 集
- 显著
- 单
- 尺寸
- So
- 一些
- 稳定
- 阶段
- 随后
- 顺利
- 这样
- 支持
- 采取
- 模板
- 次
- 至
- 转换
- 转化
- 亮相
- 使用
- 通过
- 视频
- 视频
- 水
- 这
- 加工
- 合作
- YouTube的
- 和风网











