图片由编辑
14 年 2023 月 4 日,OpenAI 发布了 GPT-XNUMX,这是其语言模型的最新、最强大的版本。
在发布后的短短几个小时内,GPT-4 通过将一个 将手绘草图变成功能性网站, 通过律师考试及 生成维基百科文章的准确摘要.
在基于逻辑和推理解决数学问题和回答问题方面,它也优于其前身 GPT-3.5。
ChatGPT 是建立在 GPT-3.5 之上并向公众发布的聊天机器人,它因“产生幻觉”而臭名昭著。 它会生成看似正确的响应,并会用“事实”来捍卫它的答案,尽管它们充满了错误。
在模型坚持认为象蛋是所有陆生动物中最大的之后,一位用户上了 Twitter:
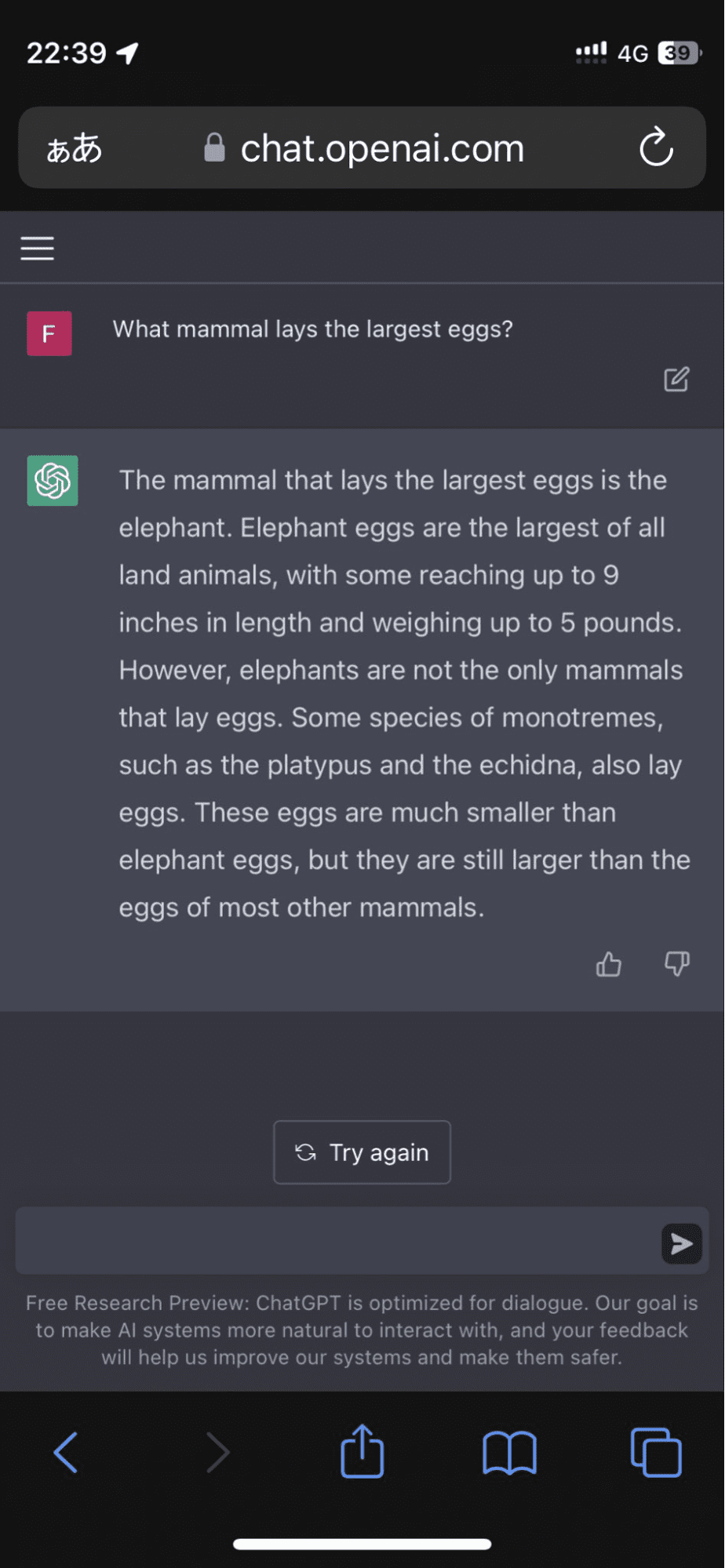
图片来源: 永恒之花
它并没有就此停止。 该算法继续用编造的事实来证实它的反应,这几乎让我相信了一会儿。
另一方面,GPT-4 接受的训练较少出现“幻觉”。 OpenAI 的最新模型更难被欺骗,并且不会自信地频繁地产生虚假信息。
作为一名数据科学家,我的工作要求我找到相关的数据源、预处理大型数据集并构建能够推动业务价值的高度准确的机器学习模型。
我一天中的大部分时间都在从不同的文件格式中提取数据并将其整合到一个地方。
ChatGPT 于 2022 年 XNUMX 月首次推出后,我向聊天机器人寻求日常工作流程的一些指导。我使用该工具节省了花在琐碎工作上的时间,这样我就可以专注于提出新想法和创建更好的模型。
GPT-4 发布后,我很好奇它是否会对我所做的工作产生影响。 使用 GPT-4 与其前身相比有什么显着的好处吗? 与使用 GPT-3.5 相比,它会帮助我节省更多时间吗?
在本文中,我将向您展示我如何使用 ChatGPT 来自动化数据科学工作流程。
我将创建相同的提示并将它们提供给 GPT-4 和 GPT-3.5,看看前者是否确实表现更好并节省更多时间。
如果您想按照我在本文中所做的一切进行操作,则需要能够访问 GPT-4 和 GPT-3.5。
GPT-3.5
GPT-3.5 在 OpenAI 的网站上公开可用。 只需导航至 https://chat.openai.com/auth/login,填写所需的详细信息,您将可以访问语言模型:
图片来源: ChatGPT
GPT-4
另一方面,GPT-4 目前隐藏在付费专区后面。 要访问该模型,您需要通过单击“升级到 Plus”来升级到 ChatGPTPlus。
每月订阅费为 20 美元,可以随时取消:
图片来源: ChatGPT
如果您不想支付月费,您也可以加入 API候补名单 对于 GPT-4。 获得 API 访问权限后,您可以按照 Free Introduction 在 Python 中使用它的指南。
如果您目前无法访问 GPT-4 也没关系。
您仍然可以使用在后端使用 GPT-3.5 的免费版 ChatGPT 来学习本教程。
1.数据可视化
在执行探索性数据分析时,用 Python 生成快速可视化通常可以帮助我更好地理解数据集。
不幸的是,这项任务可能会变得非常耗时——尤其是当您不知道使用正确的语法来获得所需结果时。
我经常发现自己在搜索 Seaborn 的大量文档并使用 StackOverflow 生成单个 Python 图。
让我们看看 ChatGPT 是否可以帮助解决这个问题。
我们将使用 皮马印第安人糖尿病 本节中的数据集。 如果您想了解 ChatGPT 生成的结果,可以下载数据集。
下载数据集后,让我们使用 Pandas 库将其加载到 Python 中并打印数据帧的头部:
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
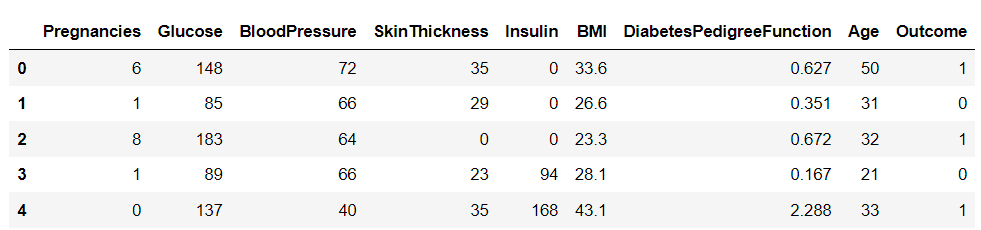
该数据集中有九个变量。 其中之一,“结果”,是告诉我们一个人是否会患上糖尿病的目标变量。 其余的是用于预测结果的自变量。
好的! 所以我想看看这些变量中的哪些变量会影响一个人是否会患上糖尿病。
为实现这一点,我们可以创建一个聚类条形图来可视化数据集中所有因变量的变量“糖尿病”。
这实际上很容易编写出来,但让我们从简单的开始。 随着文章的进展,我们将转向更复杂的提示。
使用 GPT-3.5 进行数据可视化
由于我付费订阅了 ChatGPT,该工具允许我在每次访问它时选择我想使用的基础模型。
我要选择 GPT-3.5:
图片来自 ChatGPT Plus
如果您没有订阅,您可以使用 ChatGPT 的免费版本,因为聊天机器人默认使用 GPT-3.5。
现在,让我们输入以下提示以使用糖尿病数据集生成可视化:
我有一个包含 8 个自变量和 1 个因变量的数据集。因变量“结果”告诉我们一个人是否会患上糖尿病。
自变量“妊娠”、“血糖”、“血压”、“皮肤厚度”、“胰岛素”、“BMI”、“糖尿病谱系函数”和“年龄”用于预测该结果。
您能否生成 Python 代码来按结果可视化所有这些自变量?输出应该是一张由“结果”变量着色的簇状条形图。总共应有 16 个条形图,每个自变量 2 个。
以下是模型对上述提示的响应:
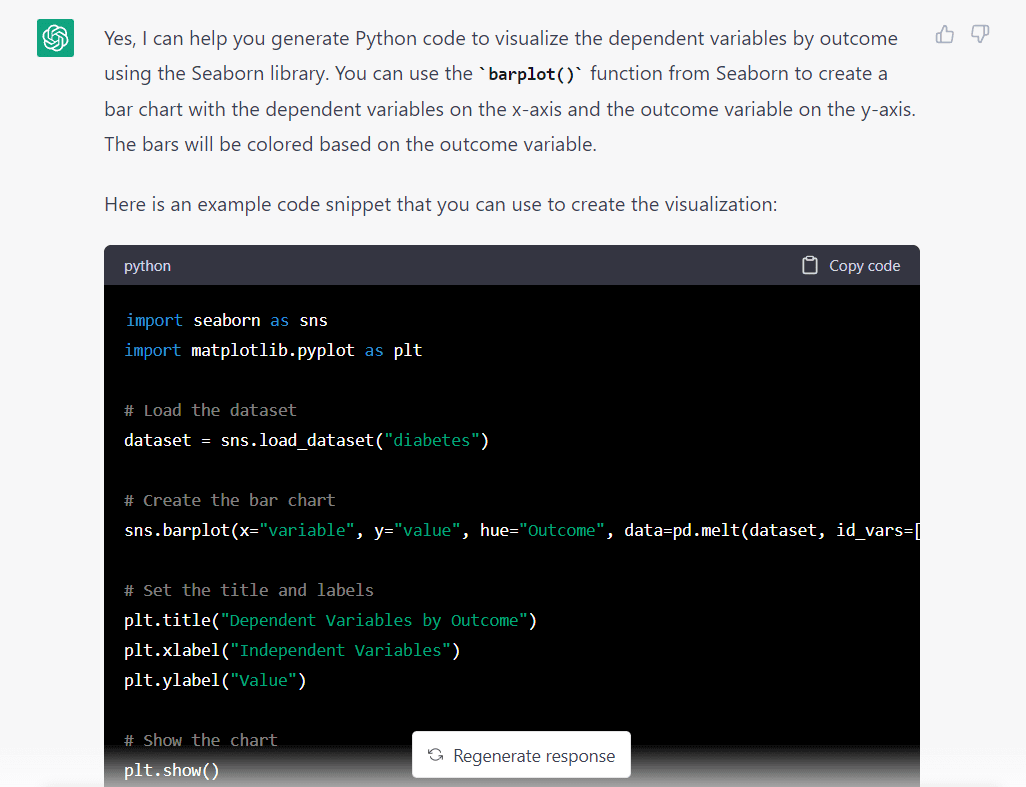
立即突出的一件事是该模型假定我们想要从 Seaborn 导入数据集。 它可能做出了这个假设,因为我们要求它使用 Seaborn 库。
这不是一个大问题,我们只需要在运行代码之前更改一行。
下面是 GPT-3.5 生成的完整代码片段:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
您可以将其复制并粘贴到您的 Python IDE 中。
以下是运行上述代码后生成的结果:
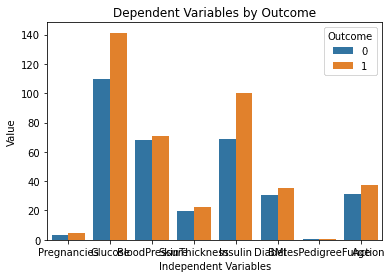
这张图表看起来很完美! 这正是我在 ChatGPT 中输入提示时的设想。
然而,一个突出的问题是该图表上的文本重叠。 我将通过键入以下提示询问模型是否可以帮助我们解决此问题:
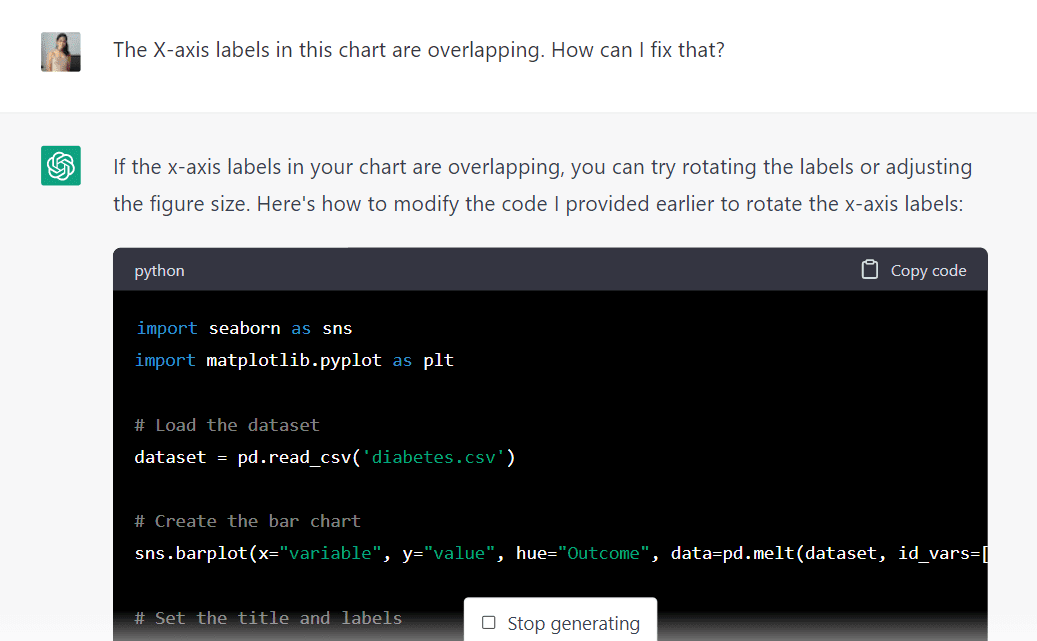
该算法解释说,我们可以通过旋转图表标签或调整图形大小来防止这种重叠。 它还生成了新代码来帮助我们实现这一目标。
让我们运行这段代码,看看它是否给了我们想要的结果:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
上面的代码行应该生成以下输出:
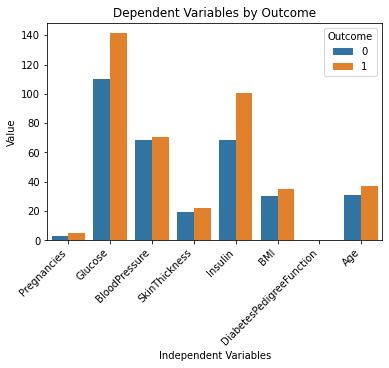
这看起来很棒!
通过简单地查看此图表,我现在可以更好地理解数据集。 似乎葡萄糖和胰岛素水平较高的人更容易患上糖尿病。
另请注意,“DiabetesPedigreeFunction”变量并未在此图表中提供任何信息。 这是因为该特征的比例较小(介于 0 和 2.4 之间)。 如果您想进一步试验 ChatGPT,您可以提示它在单个图表中生成多个子图来解决这个问题。
使用 GPT-4 进行数据可视化
现在,让我们将相同的提示输入 GPT-4,看看是否会得到不同的响应。 我将在 ChatGPT 中选择 GPT-4 模型并输入与之前相同的提示:
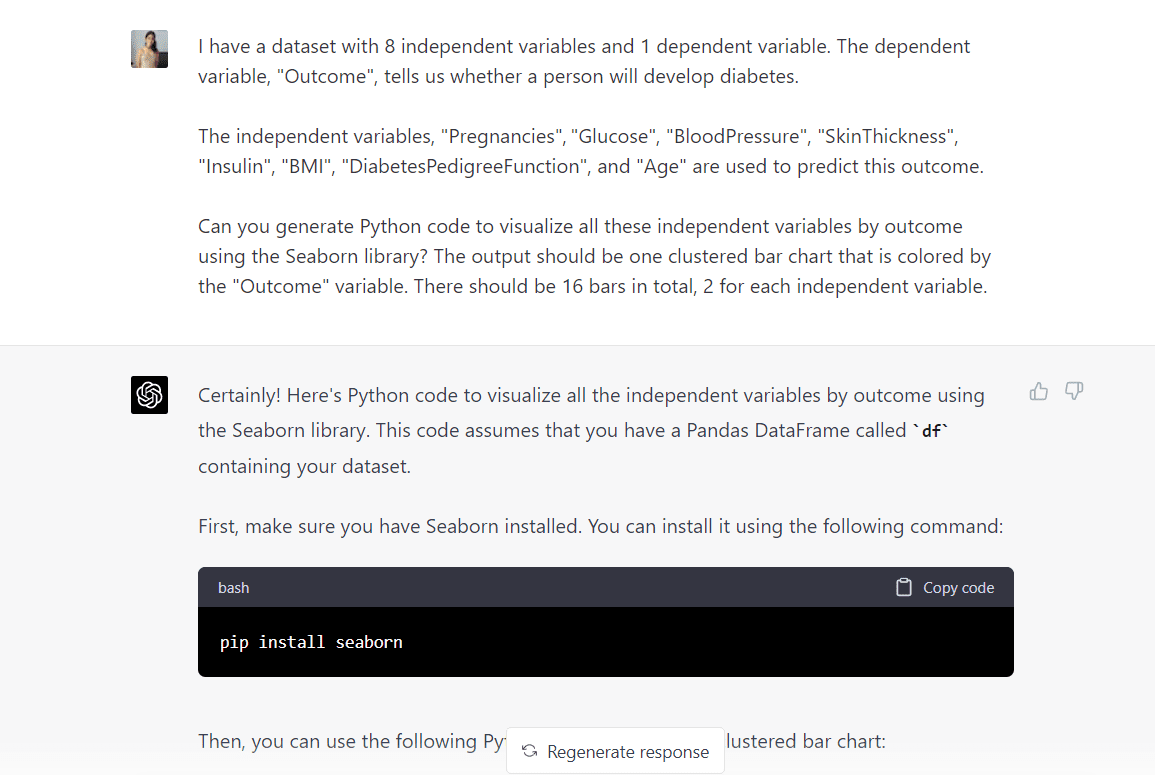
请注意 GPT-4 如何不假设我们将使用 Seaborn 内置的数据框。
它告诉我们它将使用名为“df”的数据框来构建可视化,这是对 GPT-3.5 生成的响应的改进。
下面是这个算法生成的完整代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
上面的代码应该生成以下图:
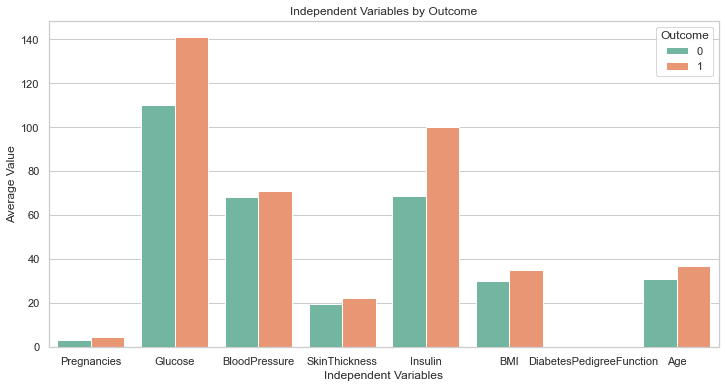
太棒了!
即使我们没有要求,GPT-4 也包含了一行代码来增加绘图大小。 这张图表上的标签都清晰可见,所以我们不必像之前那样回头修改代码。
这是 GPT-3.5 生成的响应之上的一步。
然而,总的来说,GPT-3.5 和 GPT-4 似乎都能有效地生成代码来执行数据可视化和分析等任务。
请务必注意,由于您无法将数据上传到 ChatGPT 的界面,因此您应该为模型提供数据集的准确描述以获得最佳结果。
2. 使用 PDF 文档
虽然这不是常见的数据科学用例,但我不得不从数百个 PDF 文件中提取文本数据来构建情绪分析模型一次。 数据是非结构化的,我花了很多时间来提取和预处理它。
我还经常与研究人员合作,他们阅读和创建有关特定行业发生的时事的内容。 他们需要紧跟新闻,分析公司报告,并了解行业的潜在趋势。
与其阅读 100 页的公司报告,简单地提取您感兴趣的词并只阅读包含这些关键词的句子不是更容易吗?
或者,如果您对趋势感兴趣,您可以创建一个自动化的工作流程来展示关键字随时间的增长,而不是手动查看每个报告。
在本节中,我们将使用 ChatGPT 在 Python 中分析 PDF 文件。 我们将要求聊天机器人提取 PDF 文件的内容并将其写入文本文件。
同样,这将使用 GPT-3.5 和 GPT-4 来完成,以查看生成的代码是否存在显着差异。
使用 GPT-3.5 阅读 PDF 文件
在本节中,我们将分析一个公开可用的 PDF 文档,标题为 面向工程师的机器学习简介. 如果您想按照此部分进行编码,请务必下载此文件。
首先,让算法生成 Python 代码以从此 PDF 文档中提取数据并将其保存到文本文件中:
下面是算法提供的完整代码:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(注意:确保将 PDF 文件名更改为您在运行此代码之前保存的文件名。)
不幸的是,在运行 GPT-3.5 生成的代码后,我遇到了以下 unicode 错误:

让我们回到 GPT-3.5,看看模型是否可以解决这个问题:
我将错误粘贴到 ChatGPT 中,模型回应说可以通过将使用的编码更改为“utf-8”来修复它。 它还为我提供了一些反映此更改的修改代码:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
此代码成功执行并创建了一个名为“output_file.txt”的文本文件。 PDF文档中的所有内容已经写入文件:
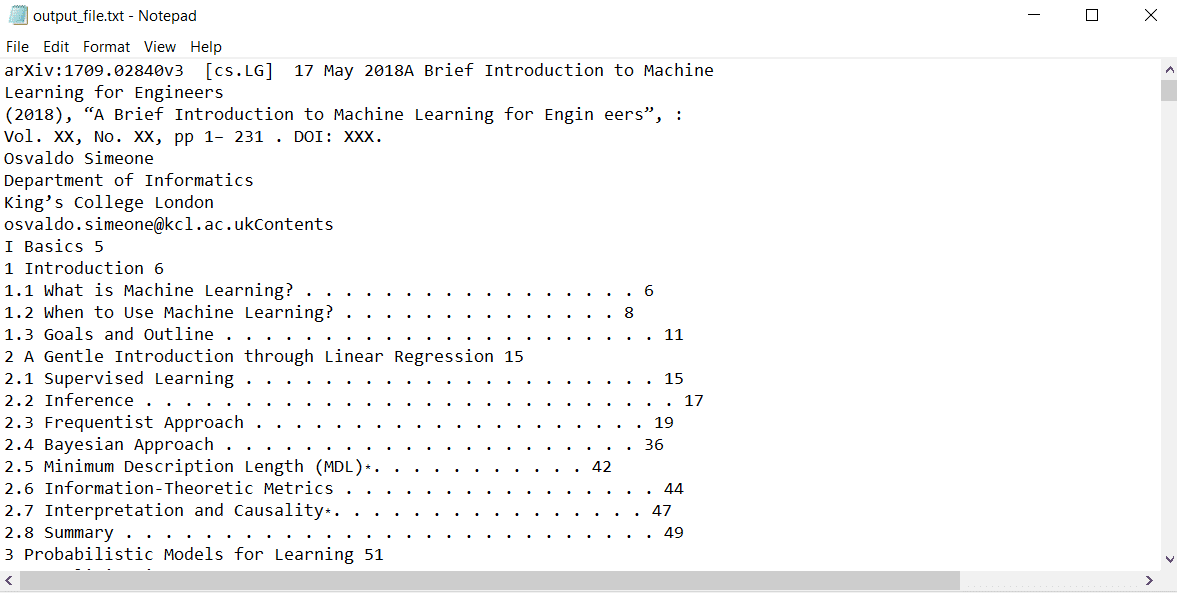
使用 GPT-4 阅读 PDF 文件
现在,我将把相同的提示粘贴到 GPT-4 中,看看模型会产生什么:
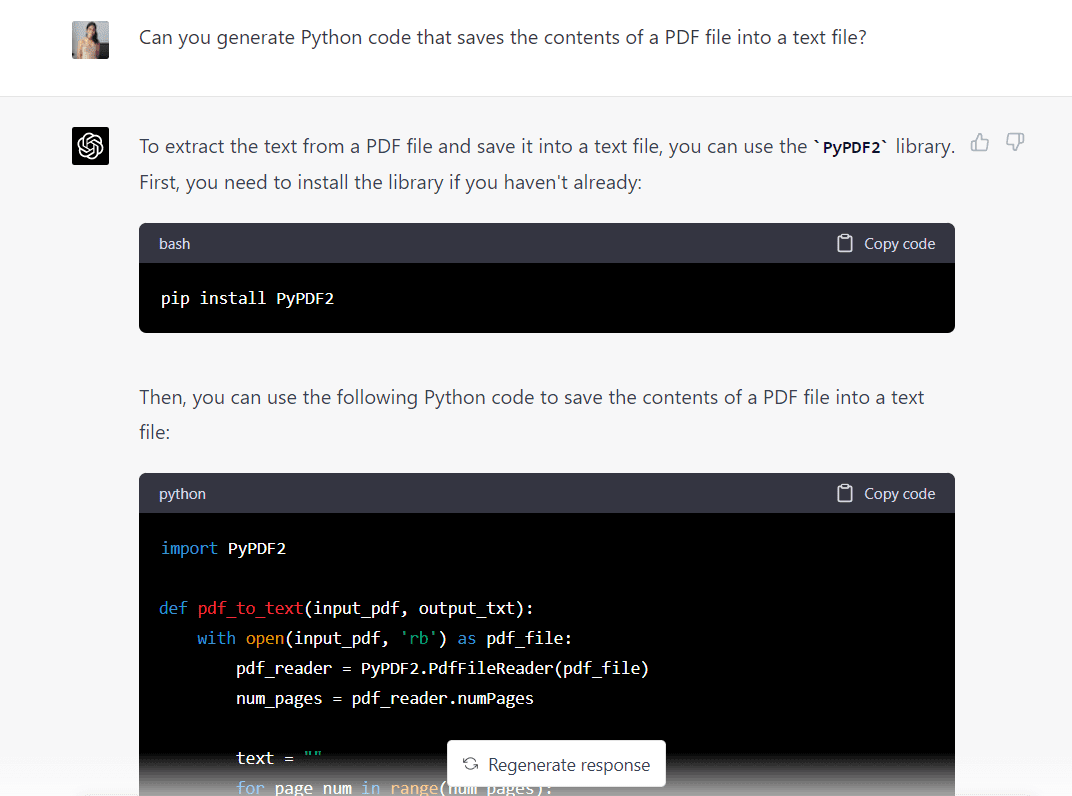
以下是 GPT-4 生成的完整代码:
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
看那个!
与 GPT-3.5 不同,GPT-4 已经规定打开文本文件应使用“utf-8”编码。 我们不需要像以前那样返回并修改代码。
GPT-4 提供的代码应该可以成功执行,您应该可以在创建的文本文件中看到 PDF 文档的内容。
您可以使用许多其他技术通过 Python 自动化 PDF 文档。 如果您想进一步探索这一点,您可以在 ChatGPT 中输入以下一些其他提示:
- 你能写 Python 代码来合并两个 PDF 文件吗?
- 如何使用 Python 计算 PDF 文档中特定单词或短语的出现次数?
- 您可以编写 Python 代码从 PDF 中提取表格并将其写入 Excel 中吗?
我建议您在空闲时间尝试其中的一些方法 - 您会惊讶地发现 GPT-4 可以如此快速地帮助您完成通常需要数小时才能完成的琐碎任务。
3. 发送自动邮件
我每周都会花几个小时阅读和回复电子邮件。 这不仅耗时,而且在紧迫的截止日期前处理电子邮件也会让人倍感压力。
虽然你不能让 ChatGPT 为你写所有的电子邮件(我希望),但你仍然可以用它来编写在特定时间发送预定电子邮件的程序,或者修改可以发送给多人的单个电子邮件模板.
在本节中,我们将获得 GPT-3.5 和 GPT-4 来帮助我们编写一个 Python 脚本来发送自动电子邮件。
使用 GPT-3.5 发送自动电子邮件
首先,让我们输入以下提示以生成代码以发送自动电子邮件:
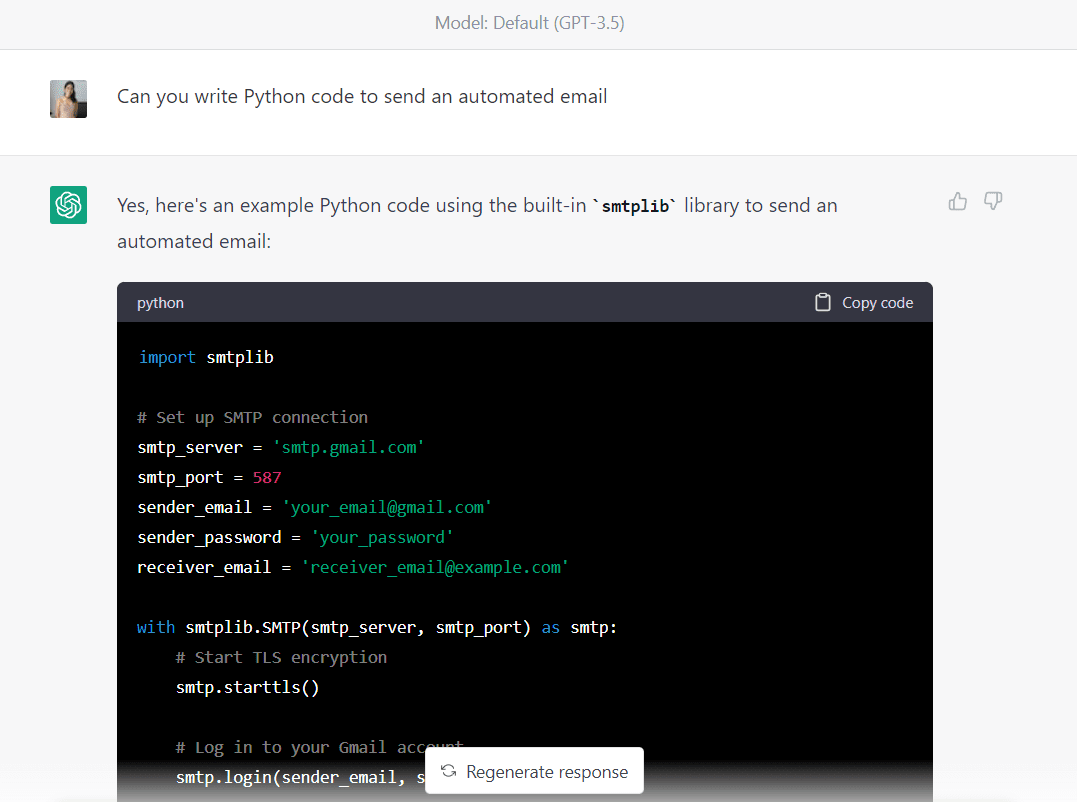
这是 GPT-3.5 生成的完整代码(确保在运行此代码之前更改电子邮件地址和密码):
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
不幸的是,这段代码没有为我成功执行。 它产生了以下错误:
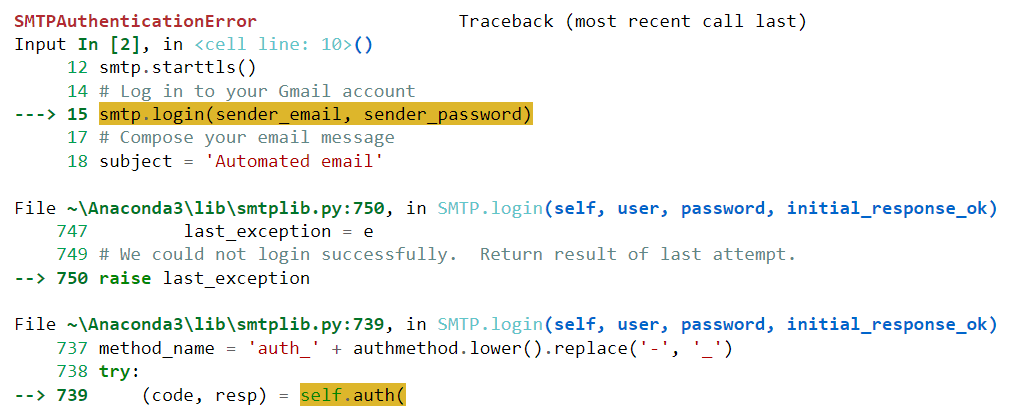
让我们将这个错误粘贴到 ChatGPT 中,看看模型是否可以帮助我们解决它:

好的,算法指出了我们可能会遇到此错误的几个原因。
我知道我的登录凭据和电子邮件地址是有效的,并且代码中没有拼写错误。 所以可以排除这些原因。
GPT-3.5 还建议允许安全性较低的应用程序可能会解决此问题。
但是,如果您尝试这样做,您将不会在您的 Google 帐户中找到允许访问安全性较低的应用程序的选项。
这是因为谷歌 不再? 允许用户出于安全考虑允许安全性较低的应用程序。
最后,GPT-3.5 还提到如果启用了双因素身份验证,则应生成应用程序密码。
我没有启用双因素身份验证,所以我打算(暂时)放弃这个模型,看看 GPT-4 是否有解决方案。
使用 GPT-4 发送自动电子邮件
好的,所以如果你在 GPT-4 中输入相同的提示,你会发现该算法生成的代码与 GPT-3.5 给我们的非常相似。 这将导致我们之前遇到的相同错误。
让我们看看 GPT-4 是否可以帮助我们修复这个错误:

GPT-4 的建议与我们之前看到的非常相似。
然而,这一次,它为我们提供了如何完成每个步骤的分步分解。
GPT-4 还建议创建一个应用程序密码,所以让我们试一试。
首先,访问您的 Google 帐户,导航至“安全”,然后启用双因素身份验证。 然后,在同一部分中,您应该会看到一个显示“App Passwords”的选项。
单击它,将出现以下屏幕:
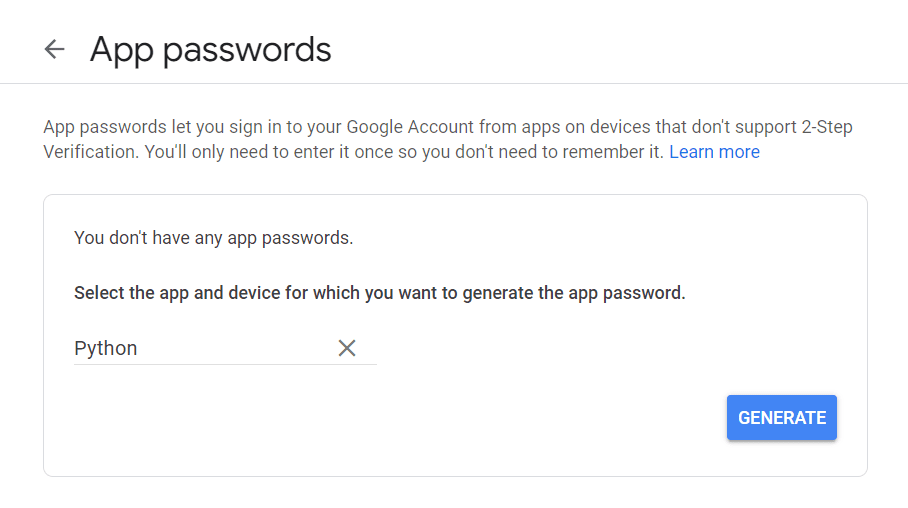
您可以输入您喜欢的任何名称,然后单击“生成”。
将出现一个新的应用程序密码。
用此应用程序密码替换 Python 代码中的现有密码,然后再次运行代码:
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
这次它应该会成功运行,您的收件人将收到一封如下所示的电子邮件:
完美!
感谢 ChatGPT,我们已经成功地使用 Python 发送了一封自动电子邮件。
如果您想更进一步,我建议生成允许您执行以下操作的提示:
- 同时向多个收件人发送批量电子邮件
- 将预定的电子邮件发送到预定义的电子邮件地址列表
- 向收件人发送一封根据他们的年龄、性别和位置量身定制的电子邮件。
娜塔莎·塞尔瓦拉吉 是一位自学成才的数据科学家,对写作充满热情。 你可以和她联系 LinkedIn.
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python
- :是
- $UP
- 1
- 100
- 2022
- 2023
- 7
- 8
- a
- 关于
- 以上
- ACCESS
- 完成
- 账号管理
- 精准的
- 横过
- 通
- 地址
- 后
- 算法
- 所有类型
- 允许
- 允许
- 已经
- 尽管
- 量
- 分析
- 分析
- 分析
- 和
- 动物
- 答案
- API
- 应用
- 出现
- 应用
- 保健
- 刊文
- AS
- 假定
- 假设
- At
- 认证
- 自动化
- 自动化
- 可使用
- 背部
- 后端
- 酒吧
- 酒吧
- 基于
- BE
- 因为
- 成为
- before
- 背后
- 好处
- 更好
- 之间
- BMI
- 身体
- Boring
- 击穿
- 建立
- 建
- 商业
- by
- 被称为
- CAN
- 取消
- 不能
- 原因
- 更改
- 改变
- 图表
- 聊天机器人
- ChatGPT
- 明确地
- 点击
- 码
- COM的
- 未来
- 相当常见
- 公司
- 公司的
- 完成
- 复杂
- 关注
- 信心十足地
- 分享链接
- 地都
- 巩固
- 内容
- Contents
- 证实
- 可以
- 创建信息图
- 创建
- 创造
- 资历
- 好奇
- 电流
- 目前
- 定制
- 定制
- 每天
- data
- 数据分析
- 数据科学
- 数据科学家
- 数据可视化
- 数据集
- 天
- 默认
- 依赖的
- 描述
- 详情
- 开发
- 糖尿病
- DID
- 差异
- 不同
- 文件
- 文件
- 文件
- 不会
- 做
- 别
- 下载
- 驾驶
- ,我们将参加
- 每
- 此前
- 更容易
- 有效
- 蛋类
- 或
- 象
- 邮箱地址
- 电子邮件
- enable
- 启用
- 加密
- 输入
- 错误
- 故障
- 特别
- 醚(ETH)
- 事件
- 所有的
- 一切
- 究竟
- Excel
- 执行
- 现有
- 实验
- 解释
- 探索性数据分析
- 探索
- 广泛
- 提取
- 专栏
- 费
- 少数
- 数字
- 文件
- 档
- 填
- 找到最适合您的地方
- 姓氏:
- 固定
- 固定
- 专注焦点
- 遵循
- 以下
- 针对
- 前
- Free
- 频繁
- 止
- 实用
- 进一步
- 性别
- 生成
- 产生
- 产生
- 发电
- 得到
- 给
- 给
- Gmail的
- Go
- 去
- 谷歌
- 事业发展
- 指导
- 指南
- 手
- 有
- 头
- 帮助
- 帮助
- 此处
- 老旧房屋
- 更高
- 高度
- 横
- HOURS
- 创新中心
- How To
- 但是
- HTTPS
- 巨大
- 数百
- i
- 思路
- 立即
- 影响力故事
- 进口
- 重要
- 改进
- in
- 包括
- 增加
- 令人难以置信
- 独立
- 行业
- 行业中的应用:
- 信息
- 代替
- 有兴趣
- 接口
- 介绍
- 问题
- IT
- 它的
- 工作
- 加入
- 掘金队
- 知道
- 标签
- 土地
- 语言
- 大
- 最大
- 最新
- 发射
- 推出
- 学习
- 让
- 各级
- 自学资料库
- 喜欢
- 容易
- Line
- 线
- 清单
- 加载
- 圖書分館的位置
- 看着
- 寻找
- LOOKS
- 占地
- 机
- 机器学习
- 制成
- 使
- 手动
- 许多
- 三月
- 数学
- matplotlib
- 提到
- 合并
- 的话
- 可能
- 时尚
- 模型
- 模型
- 改性
- 修改
- 时刻
- 每月一次
- 每月订阅
- 更多
- 最先进的
- 移动
- 多
- 姓名
- 导航
- 需求
- 全新
- 新应用程序
- 最新
- 消息
- 臭名昭著
- 十一月
- 数
- 对象
- of
- 好
- on
- 一
- 打开
- OpenAI
- 最佳
- 附加选项
- 其他名称
- 成果
- 性能优于
- 产量
- 页
- 支付
- 大熊猫
- 情
- 密码
- 密码
- 员工
- 演出
- 执行
- 人
- 地方
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 加
- 潜力
- 强大
- 前任
- 预测
- 漂亮
- 防止
- 先前
- 打印
- 大概
- 市场问题
- 问题
- 训练课程
- 进展
- 提供
- 提供
- 国家
- 公然
- 蟒蛇
- 有疑问吗?
- 快速
- 很快
- 阅读
- 读者
- 阅读
- 原因
- 接收
- 收件人
- 反映
- 发布
- 相应
- 其余
- 报告
- 业务报告
- 必须
- 需要
- 研究人员
- 回应
- 响应
- 导致
- 成果
- 运行
- 运行
- 同
- 保存
- 储
- 说
- 鳞片
- 预定
- 科学
- 科学家
- 屏风
- 海生的
- 搜索
- 部分
- 安全
- 保安
- 发送
- 情绪
- 集
- 应该
- 显示
- 显著
- 类似
- 简易
- 只是
- 自
- 单
- 尺寸
- 小
- So
- 方案,
- 解决
- 解决
- 一些
- 来源
- 具体的
- 指定
- 花
- 花费
- 看台
- 开始
- 留
- 步
- 仍
- Stop 停止
- 主题
- 订阅
- 顺利
- 提示
- 合适的
- 感到惊讶
- 句法
- 量身定制
- 采取
- 服用
- 目标
- 任务
- 任务
- 技术
- 告诉
- 模板
- 这
- 其
- 他们
- 那里。
- 博曼
- 事
- 通过
- 次
- 耗时的
- 标题
- 标题
- TLS
- 至
- 工具
- 最佳
- 合计
- 熟练
- 趋势
- 谈到
- 教程
- 相关
- 理解
- 统一
- 升级
- us
- 使用
- 用户
- 用户
- 平时
- 折扣值
- 版本
- 可见
- 参观
- 可视化
- W
- 通缉
- 您的网站
- 什么是
- 是否
- 这
- WHO
- 维基百科上的数据
- 将
- 中
- Word
- 话
- 工作
- 工作流程
- 工作流程
- 加工
- 将
- 写
- 写作
- 书面
- 您一站式解决方案
- 和风网