亚马逊雅典娜 是一种交互式查询服务,可以轻松地分析数据 亚马逊简单存储服务 (Amazon S3) 以及驻留在 AWS、本地或其他使用 SQL 或 Python 的云系统中的数据源。 Athena 基于开源 Trino 和 Presto 引擎以及 Apache Spark 框架构建,无需进行预配或配置工作。 Athena 是无服务器的,因此无需管理基础设施,您只需为运行的查询付费。
阿帕奇·冰山 是一种适用于非常大的分析数据集的开放表格式。 它将大量文件作为表进行管理,并支持现代分析数据湖操作,例如记录级插入、更新、删除和时间旅行查询。 Athena 支持对 Apache Iceberg 表进行读取、时间旅行、写入和 DDL 查询,这些表使用 Apache Parquet 格式的数据和 AWS Glue数据目录 对于他们的元存储。
特征工程 是识别和转换原始数据(图像、文本文件、视频等)、回填缺失数据以及添加一个或多个有意义的数据元素以提供上下文以便机器学习 (ML) 模型可以从中学习的过程。 各种用例都需要数据标签,包括预测、计算机视觉、自然语言处理和语音识别。
结合 Athena 的功能,Apache Iceberg 为数据科学家提供了简化的工作流程,以创建新的数据功能,而无需复制或重新创建整个数据集。 您可以在 Athena 上使用标准 SQL 创建功能,而无需使用任何其他功能工程服务。 数据科学家可以减少准备和复制数据集所花费的时间,而专注于数据特征工程、实验和大规模数据分析。
在这篇文章中,我们回顾了将 Athena 与 Apache Iceberg 开放表格式结合使用的好处,以及它如何简化数据科学家的常见特征工程任务。 我们演示 Athena 如何转换 Apache Iceberg 格式的现有表,然后添加列、删除列以及修改表中的数据,而无需重新创建或复制数据集,并使用这些功能在 Apache Iceberg 表上创建新功能。
解决方案概述
数据科学家通常习惯于处理大型数据集。 数据集通常存储在 JSON、CSV、ORC 或 阿帕奇木地板 格式或类似的读取优化格式以实现快速读取性能。 数据科学家经常创建新的数据特征,并用聚合数据和辅助数据回填这些数据特征。 从历史上看,此任务是通过在表顶部使用 Apache Parquet 格式的基础数据创建视图来完成的,其中此类列和数据是在运行时添加的,或者通过创建包含其他列的新表来完成的。 尽管此工作流程非常适合许多用例,但对于大型数据集来说效率较低,因为需要在运行时生成数据,或者需要复制和转换数据集。
雅典娜介绍了 ACID(原子性、一致性、隔离性、持久性)事务 添加插入、更新、删除、合并和时间旅行操作的功能 Apache Iceberg 表。 这些功能使数据科学家能够创建新的数据特征并将现有数据特征删除到现有数据集上,而无需担心复制或转换数据集或使用视图对其进行抽象。 数据科学家可以专注于特征工程工作,避免复制和转换数据集。
Athena Iceberg UPDATE 操作将 Apache Iceberg 位置删除文件和新更新的行写入同一事务中的数据文件。 您可以通过单个 UPDATE 语句进行记录更正。
随着 Athena 引擎版本 3 的发布,Apache Iceberg 表的功能得到增强,支持以下操作: 创建表作为选择 (CTAS) MERGE 命令可简化 Iceberg 数据的生命周期管理。 CTAS 可以快速高效地从其他格式(例如 Apache Paquet)创建表, 合并成 有条件更新、删除行或将行插入到 Iceberg 表中。 单个语句可以组合更新、删除和插入操作。
先决条件
使用 Athena 引擎版本 3 设置 Athena 工作组,以对 Apache Iceberg 表使用 CTAS 和 MERGE 命令。 要将 Athena 工作组中的现有 Athena 引擎升级到版本 3,请按照以下中的说明操作 升级到 Athena 引擎版本 3 以提高查询性能并访问更多分析功能 或参考 在 Athena 控制台中更改引擎版本.
数据集
为了进行演示,我们使用 Apache Parquet 表,该表包含存储在 S3 存储桶中的过去几年随机分布的虚构销售数据的数百万条记录。 下载 将数据集解压到本地计算机,然后上传到 S3 存储桶。 在这篇文章中,我们将数据集上传到 s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
下表显示了表格的布局 customer_orders.
| 栏名 | 数据类型 | 课程描述 |
| 订单密钥 | 绳子 | 订单的订单号 |
| 自定义键 | 绳子 | 客户识别号码 |
| 订单状态 | 绳子 | 订单状态 |
| 总价 | 绳子 | 订单总价 |
| 订购日期 | 绳子 | 订单日期 |
| 订单优先级 | 绳子 | 订单的优先级 |
| 营业员 | 绳子 | 处理订单的职员姓名 |
| 船舶优先权 | 绳子 | 优先发货 |
| 姓名 | 绳子 | 顾客姓名 |
| 地址 | 绳子 | 客户地址 |
| 国家键 | 绳子 | 客户国家键 |
| 电话 | 绳子 | 客户电话号码 |
| 帐户 | 绳子 | 客户账户余额 |
| 市场细分 | 绳子 | 客户细分市场 |
执行特征工程
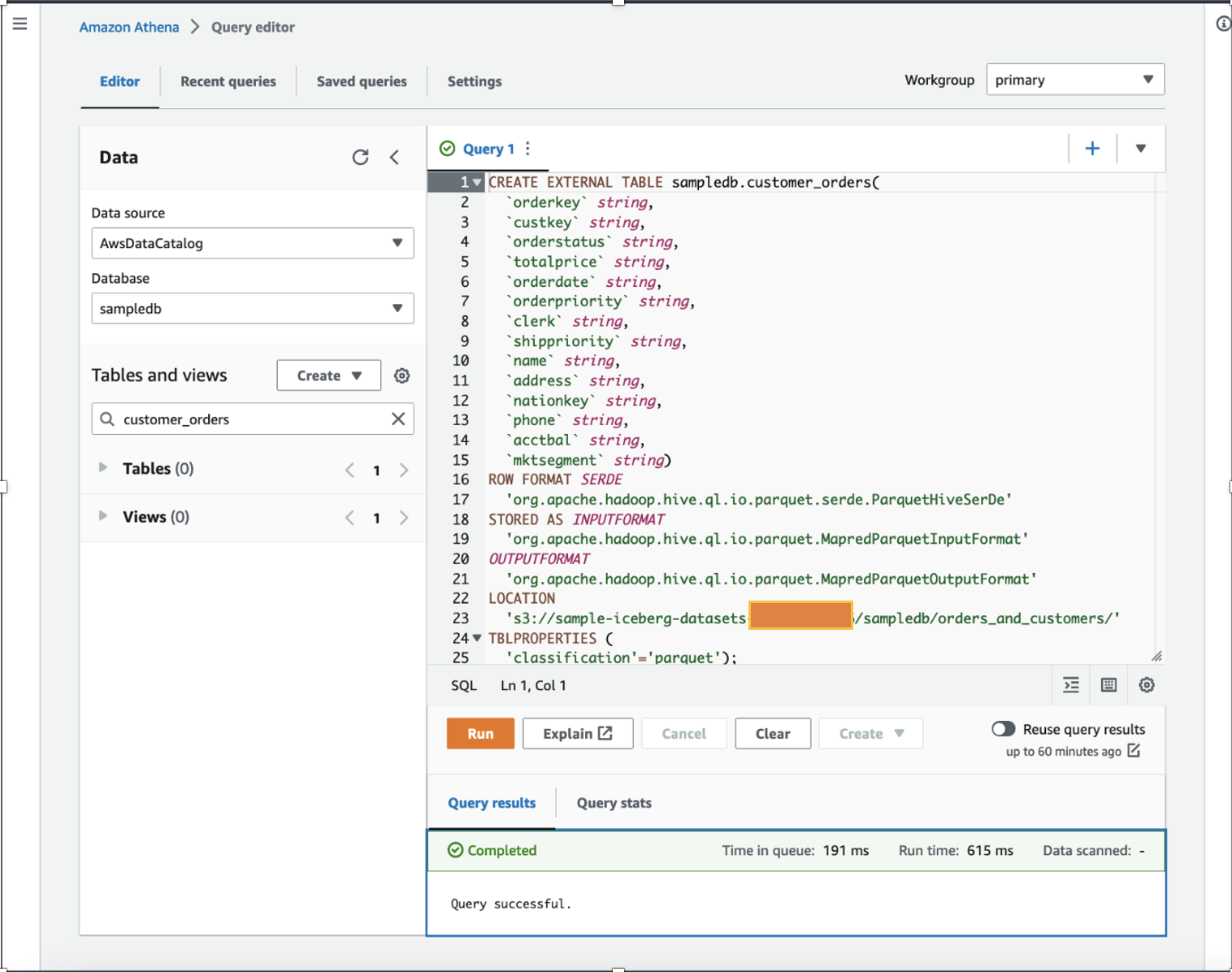
作为一名数据科学家,我们想要执行 特征工程 通过在现有数据集中添加计算出的每个客户的一年总购买量和一年平均购买量来分析客户订单数据。 出于演示目的,我们创建了 customer_orders 表中的 sampledb 使用 Athena 的数据库,如以下 DDL 命令所示。 (您可以使用任何现有的数据集并按照本文中提到的步骤操作。) customer_orders 数据集已生成并存储在 S3 存储桶位置 s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ 采用镶木地板格式。 该表不是 Apache Iceberg 表。
![]()
通过运行查询验证表中的数据:
![]()
我们希望为此表添加新功能,以更深入地了解客户销售情况,从而实现更快的模型训练和更有价值的见解。 要向数据集添加新特征,请将 customer_orders Athena 表到 Athena 上的 Apache Iceberg 表。 发出一个 CTAS 查询语句以 Apache Iceberg 格式创建一个新表 customer_orders 桌子。 在此过程中,添加了一个新功能来获取每个客户在过去一年(数据集的最大年份)的总购买金额。
在以下 CTAS 查询中,一个名为 one_year_sales_aggregate 默认值为 0.0 数据类型 double 添加和 table_type 被设置为 ICEBERG:
![]()
发出以下查询以使用新列验证 Apache Iceberg 表中的数据 one_year_sales_aggregate 价值为 0.0:
![]()
我们想要填充新功能的值 one_year_sales_aggregate 在数据集中根据过去一年(数据集的最大年份)的购买情况获取每个客户的总购买金额。 使用 Athena 向 Apache Iceberg 表发出 MERGE 查询语句来填充 one_year_sales_aggregate 功能:
![]()
发出以下查询来验证每个客户在过去一年中总支出的更新值:
![]()
我们决定在现有的 Apache Iceberg 表上添加另一个功能,以计算和存储每个客户过去一年的平均购买金额。 发出 ALTER 查询语句以将新列添加到现有表中以获取功能 one_year_sales_average:
![]()
在将值填充到此新功能之前,您可以设置该功能的默认值 one_year_sales_average 至 0.0。 在 Athena 上使用相同的 Apache Iceberg 表,发出 UPDATE 查询语句来填充新功能的值,如下所示 0.0:
![]()
发出以下查询以验证过去一年中每个客户的平均支出的更新值是否设置为 0.0:
![]()
现在我们要填充新特征的值 one_year_sales_average 在数据集中根据过去一年(数据集的最大年份)的购买情况获取每个客户的平均购买金额。 使用 Athena 引擎向 Athena 上的现有 Apache Iceberg 表发出 MERGE 查询语句以填充该功能的值 one_year_sales_average:
![]()
发出以下查询来验证每个客户的平均支出的更新值:
![]()
将其他数据特征添加到数据集中后,数据科学家通常会继续训练 ML 模型并使用 Amazon Sagemaker 或等效工具集进行推理。
结论
在这篇文章中,我们演示了如何使用 Athena 和 Apache Iceberg 执行特征工程。 我们还演示了使用 CTAS 查询从 Apache Parquet 格式的现有数据集在 Athena 上创建 Apache Iceberg 表,使用 ALTER 查询在 Athena 上的现有 Apache Iceberg 表中添加新功能,以及使用 UPDATE 和 MERGE 查询语句更新现有列的特征值。
我们鼓励您使用 CTAS 查询快速高效地创建表,并使用 MERGE 查询语句一步同步表,以简化使用 Athena 与 Apache Iceberg 进行功能转换时的数据准备和更新任务。 如果您有意见或反馈,请在评论部分留下。
作者简介
![]() 维维克高塔姆 是 AWS Professional Services 的一名数据架构师,专门研究数据湖。 他与企业客户合作在 AWS 上构建数据产品、分析平台和解决方案。 在构建和设计现代数据平台之余,Vivek 是一位美食爱好者,也喜欢探索新的旅游目的地和徒步旅行。
维维克高塔姆 是 AWS Professional Services 的一名数据架构师,专门研究数据湖。 他与企业客户合作在 AWS 上构建数据产品、分析平台和解决方案。 在构建和设计现代数据平台之余,Vivek 是一位美食爱好者,也喜欢探索新的旅游目的地和徒步旅行。
![]() 米哈伊尔·韦恩施泰因 是 Amazon Web Services 的解决方案架构师。 Mikhail 与医疗保健和生命科学客户合作,构建有助于改善患者预后的解决方案。 Mikhail 专门从事数据分析服务。
米哈伊尔·韦恩施泰因 是 Amazon Web Services 的解决方案架构师。 Mikhail 与医疗保健和生命科学客户合作,构建有助于改善患者预后的解决方案。 Mikhail 专门从事数据分析服务。
![]() 纳雷什·高塔姆 是 AWS 的数据分析和 AI/ML 领导者,拥有 20 年的经验,他乐于帮助客户构建高度可用、高性能且具有成本效益的数据分析和 AI/ML 解决方案,使客户能够做出数据驱动的决策. 在空闲时间,他喜欢冥想和烹饪。
纳雷什·高塔姆 是 AWS 的数据分析和 AI/ML 领导者,拥有 20 年的经验,他乐于帮助客户构建高度可用、高性能且具有成本效益的数据分析和 AI/ML 解决方案,使客户能够做出数据驱动的决策. 在空闲时间,他喜欢冥想和烹饪。
![]() 哈沙·塔迪帕蒂 是 AWS 分析专家首席解决方案架构师。 他喜欢解决数据库和分析方面的复杂客户问题并取得成功。 工作之余,他喜欢与家人共度时光、看电影和旅游。
哈沙·塔迪帕蒂 是 AWS 分析专家首席解决方案架构师。 他喜欢解决数据库和分析方面的复杂客户问题并取得成功。 工作之余,他喜欢与家人共度时光、看电影和旅游。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- EVM财务。 去中心化金融的统一接口。 访问这里。
- 量子传媒集团。 IR/PR 放大。 访问这里。
- 柏拉图爱流。 Web3 数据智能。 知识放大。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :具有
- :是
- :不是
- :在哪里
- $UP
- 10
- 100
- 12
- 17
- 20
- 20 年
- 23
- 27
- 7
- a
- 关于
- 加快
- ACCESS
- 完成
- 账号管理
- 行动
- 加
- 添加
- 添加
- 额外
- 地址
- AI / ML
- 还
- 尽管
- Amazon
- 亚马逊雅典娜
- 亚马逊SageMaker
- 亚马逊网络服务
- 量
- an
- 解析
- 分析
- 分析
- 分析
- 分析
- 和
- 另一个
- 任何
- 阿帕奇
- Apache Spark
- 保健
- AS
- At
- 可使用
- 避免
- AWS
- AWS专业服务
- 基于
- BE
- 因为
- 很
- 好处
- 建立
- 建筑物
- 建
- by
- 计算
- CAN
- 能力
- 例
- 分类
- 云端技术
- 收藏
- 柱
- 列
- 结合
- 注释
- 相当常见
- 复杂
- 计算
- 一台
- 计算机视觉
- 配置
- 包含
- 上下文
- 兑换
- 烹调
- 仿形
- 矫正
- 经济有效
- 创建信息图
- 创建
- 创造
- 顾客
- 合作伙伴
- data
- 数据分析
- 数据湖
- 数据科学
- 数据科学家
- 数据驱动
- 数据库
- 数据库
- 数据集
- 日期
- 决定
- 决策
- 更深
- 默认
- 交付
- 提供
- 演示
- 证明
- 设计
- 旅游目的地
- 分布
- 做
- 翻番
- 下降
- 耐久力
- 每
- 易
- 高效
- 有效
- 努力
- 或
- 分子
- 授权
- enable
- 鼓励
- 发动机
- 工程师
- 引擎
- 增强
- 企业
- 企业客户
- 爱好者
- 整个
- 醚(ETH)
- 现有
- 体验
- 探索
- 外部
- false
- 家庭
- 高效率
- 快
- 专栏
- 特征
- 反馈
- 档
- 专注焦点
- 遵循
- 以下
- 食品
- 针对
- 格式
- 框架
- 自由的
- 止
- 通常
- 产生
- 得到
- Go
- 团队
- Hadoop的
- 有
- he
- 医疗保健
- 帮助
- 帮助
- 高性能
- 高度
- 远足
- 他的
- 历史
- 蜂房
- 创新中心
- How To
- HTML
- HTTPS
- 鉴定
- 确定
- if
- 图片
- 改善
- in
- 包含
- 增加
- 低效
- 基础设施
- 刀片
- 可行的洞见
- 代替
- 说明
- 互动
- 成
- 介绍
- 隔离
- 问题
- IT
- JPG
- JSON
- 标签
- 湖泊
- 语言
- 大
- (姓氏)
- 布局
- 领导者
- 学习用品
- 学习
- 离开
- 生活
- 生命科学
- 生命周期
- 极限
- 本地
- 圖書分館的位置
- 爱
- 机
- 机器学习
- 使
- 制作
- 管理
- 颠覆性技术
- 管理
- 许多
- 市场
- 匹配
- 最大
- 有意义的
- 静坐
- 提到
- 合并
- 百万
- 失踪
- ML
- 模型
- 模型
- 现代
- 修改
- 更多
- 电影
- 姓名
- 命名
- 国家
- 自然
- 自然语言
- 自然语言处理
- 需求
- 需要
- 全新
- 新功能
- 新功能
- 新
- 没有
- 数
- of
- 经常
- on
- 一
- 仅由
- 打开
- 开放源码
- 操作
- 运营
- or
- 订单
- 其他名称
- 我们的
- 结果
- 学校以外
- 过去
- 演出
- 性能
- 电话
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 请
- 位置
- 可能
- 帖子
- 准备
- 车资
- 校长
- 问题
- 过程
- 处理
- 处理
- 核心产品
- 所以专业
- 提供
- 采购
- 购买
- 目的
- 蟒蛇
- 查询
- 很快
- 原
- 原始数据
- 阅读
- 承认
- 记录
- 记录
- 减少
- 释放
- 必须
- 导致
- 检讨
- 行
- 运行
- 运行
- sagemaker
- 销售
- 同
- 鳞片
- 科学
- 科学
- 科学家
- 科学家
- 部分
- 无服务器
- 服务
- 特色服务
- 集
- 几个
- 如图
- 作品
- 类似
- 简易
- 简
- 简化
- 单
- So
- 解决方案
- 解决
- 来源
- 火花
- 专家
- 专业
- 言语
- 语音识别
- 花
- 花费
- SQL
- 标准
- 个人陈述
- 声明
- 步
- 步骤
- 存储
- 商店
- 存储
- 精简
- 串
- 成功
- 这样
- SUPPORT
- 支持
- 产品
- 表
- 任务
- 任务
- 这
- 合并
- 其
- 他们
- 然后
- 那里。
- 博曼
- Free Introduction
- 次
- 时间旅行
- 至
- 最佳
- 合计
- 培训
- 产品培训
- 交易
- 交易
- 转化
- 转型
- 旅行
- 类型
- 相关
- 理解
- 更新
- 更新
- 最新动态
- 升级
- 上传
- 使用
- 运用
- 平时
- 验证
- 有价值
- 折扣值
- 价值观
- 各个
- 确认
- 版本
- 非常
- 通过
- 视频
- 查看
- 愿景
- 想
- 是
- 了解
- we
- 卷筒纸
- Web服务
- 为
- ,尤其是
- 每当
- 这
- 而
- WHO
- 也完全不需要
- 工作
- 工作流程
- 工作组
- 加工
- 合作
- 将
- 写
- 年
- 年
- 您
- 您一站式解决方案
- 和风网
- 压缩