今天,在 AWS re:Invent 主题演讲舞台上,AWS 数据和人工智能副总裁斯瓦米·西瓦苏布拉马尼亚 (Swami Sivasubramanian) 谈到了数据、生成式人工智能和人类之间的有益关系,所有这些都共同努力释放效率和创造力的新可能性。现代技术从未有过如此激动人心的时刻。创新无处不在,未来充满可能性。虽然斯瓦米在今天的主题演讲中探讨了这种有益关系的许多方面,但如果我们的客户希望看到生成式人工智能的成功,那么对于他们来说,特别重要的一个领域就是数据。当您想要构建满足您的业务需求的生成式人工智能应用程序时,数据就是差异化因素。本周,我们推出了许多新工具来帮助您将数据转化为差异化优势。其中包括帮助您自定义基础模型的工具,以及构建强大数据基础以推动生成式 AI 应用程序的新服务和功能。
定制基础模型
如果您正在构建自己的基础模型 (FM),那么对数据的需求是非常明显的。这些模型需要大量数据。但即使您是在 FM 之上进行构建,数据也是必要的。如果你想一想,每个人都可以使用相同的模型来构建生成式人工智能应用程序。数据是从通用应用程序转向生成式 AI 应用程序的关键,可以为您的客户和业务创造真正的价值。例如,Intuit 的新型生成式人工智能助理 Intuit Assist 使用涵盖小型企业、消费者金融和税务信息的相关上下文数据集,为客户提供个性化的财务见解。和 亚马逊基岩,您可以通过可视化界面使用一小组您自己的标记数据针对您的特定用例私下定制 FM,而无需编写任何代码。今天,我们宣布除了能够对 Cohere Command 和 Meta Llama 2 进行微调之外, 亚马逊泰坦。除了微调之外,我们还让您可以使用检索增强生成 (RAG) 更轻松地为模型提供来自数据源的最新且上下文相关的信息。 Amazon Bedrock 的知识库功能已于今天正式发布,支持整个 RAG 工作流程,从摄取、检索到提示增强。知识库可与流行的矢量数据库和引擎配合使用,包括 亚马逊 OpenSearch 无服务器、Redis Enterprise Cloud 和 Pinecone,支持 亚马逊极光 MongoDB 即将推出。
建立强大的数据基础
为了生成构建或定制生成式 AI 的 FM 所需的高质量数据,您需要强大的数据基础。当然,强大的数据基础的价值并不新鲜,而且对数据基础的需求远远超出了生成人工智能的范畴。在从生成式人工智能到商业智能 (BI) 的所有类型用例中,我们发现强大的数据基础包括一整套满足您所有用例需求的服务、跨这些服务的集成以打破数据孤岛、以及跨端到端数据工作流程管理数据的工具,以便您可以更快地进行创新。这些工具还需要智能化,以消除数据管理的繁重工作。
全面的
首先,您需要一套全面的数据服务,以便您可以获得适合任何用例的性价比、速度、灵活性和功能。 AWS 提供了一组广泛的工具,使您能够存储、组织、访问和处理各种类型的数据。我们拥有最广泛的数据库服务选择,包括 Aurora 和 亚马逊关系数据库服务 (Amazon RDS) — 周一,我们推出了 RDS 系列的最新成员:Amazon RDS for Db2。现在,Db2 客户可以在云中轻松设置、操作和扩展高度可用的 Db2 数据库。我们还提供非关系数据库,例如 Amazon DynamoDB因其无服务器、任何规模的个位数毫秒性能而被超过 1 万客户使用。您还需要存储数据以进行分析和机器学习 (ML) 的服务,例如 亚马逊简单存储服务 (亚马逊 S3)。客户已在 Amazon S3 上创建了数十万个数据湖。它还包括我们的数据仓库, 亚马逊Redshift,其性价比是其他云数据仓库的 6 倍以上。我们还拥有使您能够对数据采取行动的工具,包括 亚马逊QuickSight 对于商业智能, 亚马逊SageMaker 用于 ML,当然还有用于生成 AI 的 Amazon Bedrock。
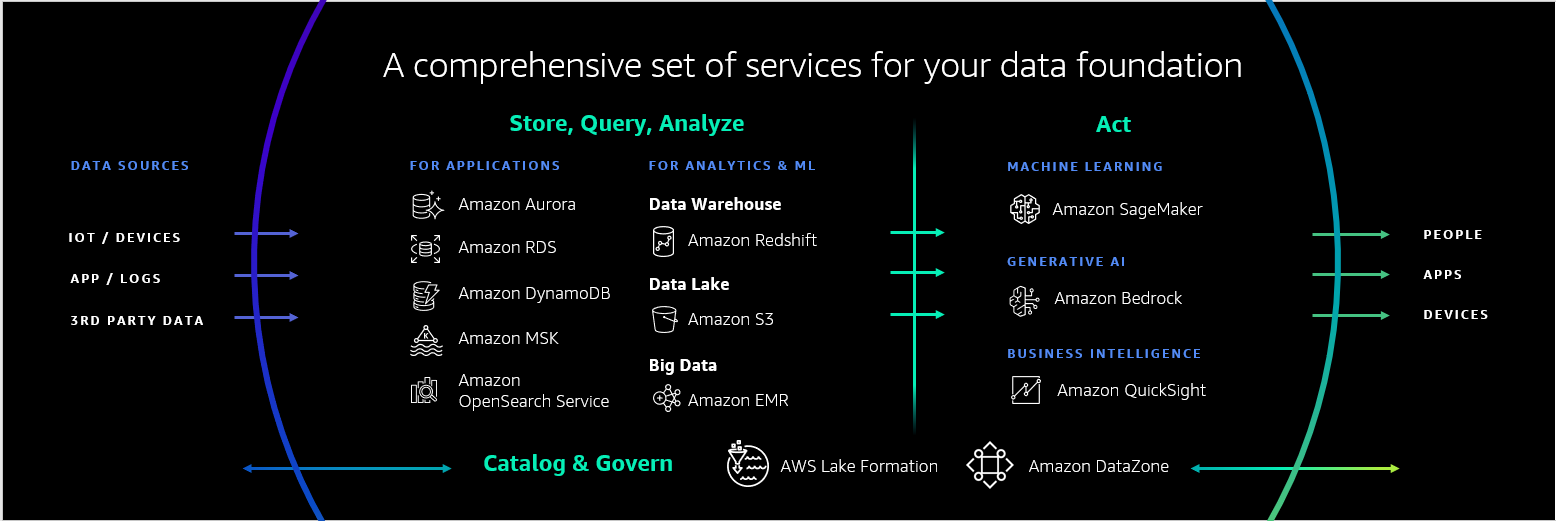
无服务器增强功能
数据的动态特性使其非常适合无服务器技术,这就是 AWS 提供广泛的无服务器数据库和分析产品来帮助支持客户最苛刻的工作负载的原因。本周,我们对该领域的无服务器选项进行了更多改进,包括新的 Aurora 功能,该功能可自动扩展到每秒数百万个写入事务并管理 PB 级数据,同时保持操作单个数据库的简单性。我们还发布了一个新的无服务器选项 亚马逊 ElastiCache,这使得创建高度可用的缓存变得更快、更容易,并可以立即扩展以满足应用程序需求。最后,我们宣布了新的人工智能驱动的扩展和优化 Amazon Redshift 无服务器 使服务能够从您的模式中学习并主动在多个维度上进行扩展,包括并发用户、数据可变性和查询复杂性。它在完成所有这一切的同时考虑了您的性价比目标,以便您可以在成本和性能之间进行优化。
跨更多数据库的矢量功能
您的数据基础还需要包括存储、索引、检索和搜索矢量数据的服务。由于我们的客户需要将向量嵌入作为其生成式 AI 应用程序工作流程的一部分,他们告诉我们,他们希望在现有数据库中使用向量功能,以消除新编程工具、API 和 SDK 的陡峭学习曲线。他们还更有信心知道自己的现有数据库已在生产中得到验证并满足可扩展性、可用性以及存储和计算的要求。当您的向量和业务数据存储在同一位置时,您的应用程序将运行得更快,并且无需担心数据同步或数据移动。
出于所有这些原因,我们投资向一些最受欢迎的数据服务添加矢量功能,包括 亚马逊开放搜索服务 以及 OpenSearch Serverless、Aurora 和 Amazon RDS。今天,我们在该列表中又添加了四个,并添加了矢量支持 适用于 Redis 的 Amazon MemoryDB, 亚马逊文件数据库 (与 MongoDB 兼容)、DynamoDB 和 亚马逊海王星。现在,您可以将矢量和生成人工智能与您选择的数据库结合使用。
集成
数据基础的另一个关键是跨数据源集成数据,以获得更完整的业务视图。通常,跨不同数据源连接数据需要复杂的提取、转换和加载 (ETL) 管道,这可能需要数小时(甚至数天)才能构建。这些管道还必须持续维护并且可能很脆弱。 AWS 正在投资零 ETL 的未来,以便您可以快速轻松地连接所有数据并对其采取行动,无论数据位于何处。我们正在通过多种方式实现这一愿景,包括我们最受欢迎的数据存储之间的零 ETL 集成。今年早些时候,我们为您带来了完全托管的零 ETL 集成 Amazon Aurora MySQL 兼容版 和亚马逊红移。在数据写入 Aurora 后的几秒钟内,您就可以使用 Amazon Redshift 对 PB 级数据进行近实时分析和机器学习。 Woolworths 是零售业的先驱,帮助构建了当今的零售模式,利用 Aurora 零 ETL 与 Amazon Redshift 集成,能够将促销和其他活动分析的开发时间从 2 个月缩短到 1 天。
更多零 ETL 选项
在 re:Invent 上,我们宣布了另外三个与 Amazon Redshift 的零 ETL 集成,包括 Amazon Aurora PostgreSQL 兼容版, 适用于MySQL的Amazon RDS和 DynamoDB,让您更轻松地利用近实时分析来改善业务成果。除了 Amazon Redshift 之外,我们还将零 ETL 支持扩展到 OpenSearch Service,数以万计的客户使用该服务来实时搜索、监控和分析业务和运营数据。这包括与 DynamoDB 和 Amazon S3 的零 ETL 集成。通过所有这些零 ETL 集成,我们可以更轻松地利用应用程序的相关数据,包括生成式 AI。
治理
最后,您的数据基础需要安全并受到监管,以确保在生成式 AI 应用程序的整个开发周期中使用的数据是高质量且合规的。为了帮助解决这个问题,我们推出了 亚马逊数据区 去年。 Guardant Health 和 Bristol Meyers Squibb 等公司正在使用 Amazon DataZone 来编目、发现、共享和管理整个组织的数据。 Amazon DataZone 使用 ML 自动将元数据添加到您的数据目录,使您的所有数据更易于发现。本周,我们向 Amazon DataZone 添加了一项新功能,该功能使用生成式 AI,只需单击几下即可自动为您的数据集创建业务描述和上下文,从而使数据更易于理解和应用。虽然 Amazon DataZone 可以帮助您在组织内以受管控的方式共享数据,但许多客户还希望与其合作伙伴安全地共享数据。
在整个数据基础中注入智能
我们不仅在 Amazon DataZone 中添加了生成式 AI,而且还在我们的数据服务中利用智能技术,使数据更易于使用、更直观且更易于访问。 亚马逊Q是我们新的生成式 AI 助手,可帮助您在 QuickSight 中创作仪表板,并使用自然语言根据仪表板数据创建引人注目的视觉故事。我们还宣布 Amazon Q 可以帮助您使用自然语言创建数据集成管道。例如,您可以要求 Q“从 S3 读取 JSON 文件,加入“accountid”,然后加载到 DynamoDB”,Q 将返回端到端数据集成作业来执行此操作。 Amazon Q 还让您可以通过 Amazon Redshift 查询编辑器(预览版)中的生成式 AI SQL 更轻松地查询数据仓库中的数据。现在,数据分析师、科学家和工程师可以使用生成式 AI 文本到代码功能提高工作效率。您还可以通过允许特定用户访问查询历史记录来提高准确性,而不会影响数据隐私。
这些新的创新将使您能够轻松地利用数据来使您的生成式人工智能应用程序脱颖而出,并为您的客户和业务创造新的价值。我们期待看到您创造的作品!
关于作者
 G2 克里希纳莫西 是分析副总裁,负责领导 AWS 数据湖服务、数据集成、Amazon OpenSearch Service 和 Amazon QuickSight。 在担任现职之前,G2 在 Facebook/Meta 构建并运行了分析和机器学习平台,并在 Microsoft 构建了 SQL Server 数据库、Azure Analytics 和 Azure ML 的各个部分。
G2 克里希纳莫西 是分析副总裁,负责领导 AWS 数据湖服务、数据集成、Amazon OpenSearch Service 和 Amazon QuickSight。 在担任现职之前,G2 在 Facebook/Meta 构建并运行了分析和机器学习平台,并在 Microsoft 构建了 SQL Server 数据库、Azure Analytics 和 Azure ML 的各个部分。
 拉胡尔·帕塔克(Rahul Pathak) 是关系数据库引擎副总裁,领导 Amazon Aurora、Amazon Redshift 和 Amazon QLDB。 在担任现职之前,他曾担任 AWS 分析副总裁,负责整个 AWS 数据库产品组合的工作。 他与他人共同创立了两家公司,一家专注于数字媒体分析,另一家专注于 IP 地理定位。
拉胡尔·帕塔克(Rahul Pathak) 是关系数据库引擎副总裁,领导 Amazon Aurora、Amazon Redshift 和 Amazon QLDB。 在担任现职之前,他曾担任 AWS 分析副总裁,负责整个 AWS 数据库产品组合的工作。 他与他人共同创立了两家公司,一家专注于数字媒体分析,另一家专注于 IP 地理定位。
- :具有
- :是
- :不是
- :在哪里
- $UP
- 1
- 100
- 521
- a
- 对,能力--
- Able
- 关于
- 关于它
- 加速
- ACCESS
- 无障碍
- 横过
- 法案
- 操作
- 加
- 添加
- 添加
- 增加
- 优点
- AI
- AI助手
- AI供电
- 所有类型
- 还
- Amazon
- 亚马逊QuickSight
- 亚马逊RDS
- 亚马逊网络服务
- 其中
- 量
- an
- 分析
- 分析师
- 分析
- 和
- 公布
- 任何
- APIs
- 应用领域
- 应用领域
- 使用
- 保健
- 国家 / 地区
- AS
- 问
- 协助
- 助理
- At
- 增强
- Aurora
- 作者
- 自动
- 可用性
- 可使用
- AWS
- AWS re:Invent
- Azure
- BE
- 很
- 作为
- 有利
- 更好
- 之间
- 超越
- 午休
- 布里斯托尔
- 广阔
- 带
- 建立
- 建筑物
- 建
- 商业
- 商业智能
- 但是
- by
- CAN
- 可以得到
- 能力
- 能力
- 案件
- 例
- 检索目录
- 选择
- 云端技术
- 码
- 未来
- 即将公开信息
- 公司
- 兼容性
- 引人注目
- 完成
- 复杂
- 复杂
- 兼容
- 全面
- 折中
- 计算
- 并发
- 信心
- 分享链接
- 连接
- 消费者
- 消费金融
- 上下文
- 上下文
- 一直
- 价格
- 课程
- 创建信息图
- 创建
- 创造力
- 危急
- 电流
- 曲线
- 合作伙伴
- 定制
- 周期
- XNUMX月XNUMX日
- 仪表板
- data
- 数据集成
- 数据湖
- 数据管理
- 数据隐私
- 数据仓库
- 数据仓库
- 数据库
- 数据库
- 数据集
- 天
- 交付
- 交付
- 提供
- 需求
- 严格
- 研发支持
- 不同
- 区分
- 差异化因素
- 数字
- 数字媒体
- 尺寸
- 通过各种方式找到
- do
- 不
- 向下
- 动态
- 此前
- 更容易
- 容易
- 易
- 编辑
- 效率
- 消除
- enable
- 使
- 端至端
- 工程师
- 引擎
- 确保
- 企业
- 整个
- 特别
- 醚(ETH)
- 甚至
- 事件
- 每个人
- 到处
- 例子
- 令人兴奋的
- 现有
- 扩大
- 探讨
- 提取
- 面
- 保理
- 家庭
- 快
- 专栏
- 特征
- 感觉
- 少数
- 档
- 终于
- 金融
- 金融
- 高度灵活
- 重点
- 针对
- 向前
- 发现
- 基金会
- 四
- 止
- 汽油
- 充分
- 功能
- 未来
- G2
- 其他咨询
- 代
- 生成的
- 生成式人工智能
- 得到
- 去
- 治理
- 有
- he
- 健康管理
- 重
- 举重
- 帮助
- 帮助
- 帮助
- 高
- 高品质
- 高度
- 他的
- 历史
- HTTP
- HTTPS
- 数百
- if
- 改善
- 改善
- in
- 包括
- 包括
- 包含
- 指数
- 信息
- 创新
- 創新
- 创新
- 可行的洞见
- 例
- 即刻
- 整合
- 积分
- 集成
- 房源搜索
- 智能化
- 接口
- 成
- 介绍
- 意会
- 直观的
- 投资
- 投资
- IT
- 它的
- 工作
- 加入
- JPG
- JSON
- 只是
- 键
- 主题演讲
- 会心
- 知识
- 湖泊
- 湖泊
- 语言
- 名:
- 去年
- 推出
- 领导
- 学习用品
- 学习
- 杠杆作用
- 借力
- 翻新
- 喜欢
- 清单
- 生活
- 骆驼
- 加载
- 看
- 机
- 机器学习
- 制成
- 维持
- 使
- 制作
- 制作
- 管理
- 颠覆性技术
- 管理
- 许多
- 问题
- 媒体
- 满足
- 元
- 元数据
- 微软
- 百万
- 百万客户
- 百万
- 毫秒
- ML
- 模型
- 模型
- 现代
- 周一
- MongoDB的
- 监控
- 个月
- 更多
- 最先进的
- 最受欢迎的产品
- 运动
- 移动
- 多
- 自然
- 自然语言
- 自然
- 必要
- 需求
- 需要
- 决不要
- 全新
- 新功能
- 最新
- 没有
- 现在
- 数
- 明显
- of
- 提供
- 供品
- 优惠精选
- on
- 一
- 仅由
- 操作
- 操作
- 操作
- 优化
- 附加选项
- 附加选项
- or
- 组织
- 其他名称
- 我们的
- 结果
- 超过
- 己
- 部分
- 伙伴
- 部分
- 模式
- 为
- 完美
- 演出
- 性能
- 个性化你的
- 先驱
- 地方
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 热门
- 个人档案
- 可能性
- 可能性
- 预览
- 先
- 隐私
- 生产
- 生产
- 生产力
- 代码编程
- 促销方案
- 成熟
- 提供
- 质量
- 很快
- 相当
- 范围
- RE
- 真实
- 实际价值
- 实时的
- 原因
- 减少
- 关系
- 发布
- 相应
- 去掉
- 岗位要求
- 需要
- 零售
- 回报
- 右
- 角色
- 运行
- 同
- 可扩展性
- 鳞片
- 秤
- 缩放
- 科学家
- sdk
- 搜索
- 其次
- 秒
- 安全
- 安全
- 看到
- 看到
- 选择
- 服务器
- 无服务器
- 服务
- 特色服务
- 集
- Share
- 筒仓
- 简易
- 简单
- 单
- 小
- 小型企业
- So
- 一些
- 不久
- 来源
- 张力
- 跨度
- 具体的
- 速度
- SQL
- 阶段
- 存储
- 商店
- 存储
- 商店
- 故事
- 强烈
- 成功
- SUPPORT
- 支持
- 同步。
- 采取
- 目标
- 税
- 技术
- 专业技术
- HAST
- 比
- 这
- 未来
- 其
- 那里。
- 博曼
- 他们
- 认为
- Free Introduction
- 本星期
- 今年
- 那些
- 数千
- 三
- 通过
- 始终
- 次
- 时
- 至
- 今晚
- 一起
- 告诉
- 工具
- 最佳
- 交易
- 每秒交易量
- 改造
- 转
- 二
- 类型
- 一般
- 理解
- 独特
- 发挥
- 解锁
- 跟上时代的
- 上
- us
- 使用
- 用例
- 用过的
- 用户
- 使用
- 运用
- 折扣值
- 各个
- 广阔
- 查看
- 愿景
- 视觉
- vp
- 想
- 仓库保管
- 是
- 方法..
- 方法
- we
- 卷筒纸
- Web服务
- 周
- 井
- 去
- 什么是
- ,尤其是
- 这
- 而
- WHO
- 为什么
- 将
- 中
- 也完全不需要
- 工作
- 工作
- 工作流程
- 工作流程
- 加工
- 合作
- 担心
- 写
- 写作
- 书面
- 年
- 您
- 您一站式解决方案
- 和风网
- 零