介绍
链表是一种由一系列节点组成的数据结构,每个节点都包含一个值和对该序列中下一个节点的引用。与数组不同,链表不需要连续的内存分配,这使得它们对于某些操作更加灵活和高效。在本文中,我们将探讨链表的优点和缺点以及如何在 Python 中实现它们。

目录
链表的优点和缺点
与其他数据结构相比,链接列表具有多种优势。首先,它们允许有效地插入和删除元素,因为它们只需要更新相邻节点的引用。这使得 LinkedLists 非常适合需要频繁修改的场景。此外,与具有固定大小的数组不同,LinkedList 的大小可以动态增长或缩小。
然而,链表也有一些缺点。与数组不同,链表不支持对元素的随机访问,这意味着访问特定索引处的元素需要从头开始遍历列表。这可能会导致某些操作的性能降低。此外,链表需要额外的内存来存储对下一个节点的引用,这对于小型数据集来说可能效率低下。
在 Python 中实现链表
Python 提供了一种灵活直观的方式来实现链表。链表主要有三种类型:单链表、双向链表和循环链表。让我们详细探讨它们中的每一个。
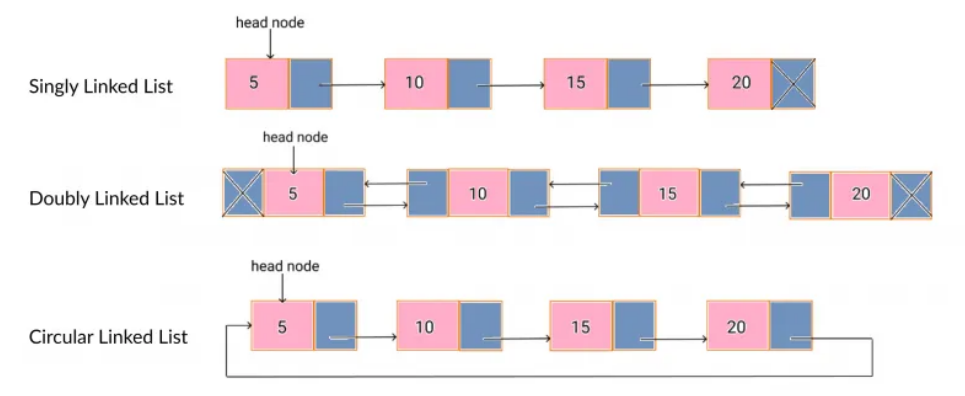
单链表
单链表由节点组成,其中每个节点都包含一个值和对序列中下一个节点的引用。以下是如何在 Python 中创建单链表:
class Node:
def __init__(self, value):
self.value = value
self.next = None
class Linked List:
def __init__(self):
self.head = None
创建单链表
要创建单向链表,我们需要定义一个 Node 类来表示列表中的每个节点。每个节点都包含一个值和对下一个节点的引用。 Linked List 类充当节点的容器,其 head 属性指向列表中的第一个节点。
在单链表中插入节点
在单链表中插入节点涉及更新相邻节点的引用。以下是在列表开头插入节点的示例:
def insert_at_beginning(self, value):
new_node = Node(value)
new_node.next = self.head
self.head = new_node从单链表中删除节点
从单链表中删除节点需要更新相邻节点的引用。下面是删除具有特定值的节点的示例:
def delete_node(self, value):
current = self.head
if current.value == value:
self.head = current.next
else:
while current.next:
if current.next.value == value:
current.next = current.next.next
break
current = current.next
在单链表中搜索
在单链表中搜索特定值涉及遍历列表,直到找到该值或到达列表末尾。以下是搜索值的示例:
def search(self, value):
current = self.head
while current:
if current.value == value:
return True
current = current.next
return False
反转单链表
反转单链表需要更新每个节点的引用以指向前一个节点。这是反转单链表的示例:
def reverse(self):
previous = None
current = self.head
while current:
next_node = current.next
current.next = previous
previous = current
current = next_node
self.head = previous
双向链表
双链表与单链表类似,但每个节点都包含对序列中下一个节点和前一个节点的引用。这允许在两个方向上进行有效的遍历。以下是如何在 Python 中创建双向链表:
class Node:
def __init__(self, value):
self.value = value
self.next = None
self.previous = None
class DoublyLinked List:
def __init__(self):
self.head = None
创建双向链表
为了创建双向链表,我们定义一个 Node 类,其中包含一个值、对下一个节点的引用以及对前一个节点的引用。 DoublyLinked List 类充当节点的容器,其 head 属性指向列表中的第一个节点。
在双向链表中插入节点
在双向链表中插入节点涉及更新相邻节点的引用。以下是在列表开头插入节点的示例:
def insert_at_beginning(self, value):
new_node = Node(value)
if self.head:
self.head.previous = new_node
new_node.next = self.head
self.head = new_node
从双向链表中删除节点
从双向链表中删除节点需要更新相邻节点的引用。下面是删除具有特定值的节点的示例:
def delete_node(self, value):
current = self.head
if current.value == value:
self.head = current.next
if self.head:
self.head.previous = None
else:
while current.next:
if current.next.value == value:
current.next = current.next.next
if current.next:
current.next.previous = current
break
current = current.next
在双向链表中搜索
在双向链表中搜索特定值涉及沿任一方向遍历列表,直到找到该值或到达列表末尾。以下是搜索值的示例:
def search(self, value):
current = self.head
while current:
if current.value == value:
return True
current = current.next
return False
反转双向链表
反转双向链表需要更新每个节点的引用以交换下一个和上一个指针。这是反转双向链表的示例:
def reverse(self):
current = self.head
while current:
next_node = current.next
current.next = current.previous
current.previous = next_node
if not next_node:
self.head = current
current = next_node
循环链表
循环链表是单链表的变体,其中最后一个节点指向第一个节点,从而创建循环结构。这允许从列表中的任何节点进行有效的遍历。以下是如何在 Python 中创建循环链表:
class Node:
def __init__(self, value):
self.value = value
self.next = None
class CircularLinked List:
def __init__(self):
self.head = None
创建循环链表
为了创建循环链表,我们定义一个 Node 类,其中包含一个值和对下一个节点的引用。 CircularLinked List 类充当节点的容器,其 head 属性指向列表中的第一个节点。此外,最后一个节点的下一个引用设置为头部,创建一个圆形结构。
在循环链表中插入节点
在循环链表中插入节点涉及更新相邻节点的引用。以下是在列表开头插入节点的示例:
def insert_at_beginning(self, value):
new_node = Node(value)
if not self.head:
self.head = new_node
new_node.next = self.head
else:
current = self.head
while current.next != self.head:
current = current.next
current.next = new_node
new_node.next = self.head
self.head = new_node
从循环链表中删除节点
从循环链表中删除节点需要更新相邻节点的引用。下面是删除具有特定值的节点的示例:
def delete_node(self, value):
if not self.head:
return
current = self.head
if current.value == value:
while current.next != self.head:
current = current.next
if current == self.head:
self.head = None
else:
current.next = self.head.next
self.head = self.head.next
else:
previous = None
while current.next != self.head:
previous = current
current = current.next
if current.value == value:
previous.next = current.next
break
在循环链表中搜索
在循环链表中搜索特定值涉及遍历列表,直到找到该值或遍历整个列表。以下是搜索值的示例:
def search(self, value):
if not self.head:
return False
current = self.head
while True:
if current.value == value:
return True
current = current.next
if current == self.head:
break
return False
反转循环链表
反转循环链表需要更新每个节点的引用以反转循环结构。下面是一个反转循环链表的例子:
def reverse(self):
if not self.head:
return
previous = None
current = self.head
next_node = current.next
while True:
current.next = previous
previous = current
current = next_node
next_node = next_node.next
if current == self.head:
break
self.head = previous
链表的常见操作
链接列表支持可以对元素执行的各种常见操作。让我们探讨其中一些操作:
访问链接列表中的元素
要访问链表中的元素,我们可以从头节点开始遍历链表,然后移动到下一个节点,直到到达所需的位置。以下是访问特定索引处的元素的示例:
def get_element(self, index):
current = self.head
count = 0
while current:
if count == index:
return current.value
count += 1
current = current.next
raise IndexError("Index out of range")
修改链接列表中的元素
修改链接列表中的元素涉及遍历列表以查找所需元素并更新其值。下面是修改特定索引处的元素的示例:
def modify_element(self, index, new_value):
current = self.head
count = 0
while current:
if count == index:
current.value = new_value
return
count += 1
current = current.next
raise IndexError("Index out of range")
求链表的长度
为了找到链表的长度,我们可以遍历链表并计算节点的数量。以下是查找链表长度的示例:
def get_length(self):
current = self.head
count = 0
while current:
count += 1
current = current.next
return count
检查链接列表是否为空
要检查链表是否为空,我们只需检查头节点是否为 None 即可。这是检查链接列表是否为空的示例:
def is_empty(self):
return self.head is None
连接链表
要连接两个链表,我们可以遍历第一个链表以找到最后一个节点,并将其下一个引用更新为第二个链表的头。这是连接两个链接列表的示例:
def concatenate(self, other_list):
if not self.head:
self.head = other_list.head
else:
current = self.head
while current.next:
current = current.next
current.next = other_list.head
链表与数组
链表和数组都是常用的数据结构,但它们有不同的特点,适合不同的场景。我们从内存效率、插入删除效率、随机访问效率等方面来对比一下链表和数组。
内存效率
链表比数组更节省内存,因为它们不需要连续的内存分配。链表中的每个节点只需要存储值和对下一个节点的引用,而数组需要为所有元素分配内存,即使它们没有被使用。
插入和删除效率
链接列表在插入和删除操作方面表现出色,尤其是当元素频繁添加或从列表中间删除时。在链表中插入或删除元素只需要更新相邻节点的引用,而数组可能需要移动元素来适应更改。
随机存取效率
数组根据元素的索引提供对元素的高效随机访问,因为它们允许直接内存寻址。相比之下,链表需要从头开始遍历列表来访问特定索引处的元素,从而导致随机访问操作的性能降低。
选择正确的数据结构
链表和数组之间的选择取决于应用程序的具体要求。如果需要频繁修改和动态调整大小,则链接列表是更好的选择。另一方面,如果随机访问和内存效率至关重要,则数组更合适。
链表应用
现在我们已经很好地了解了链表及其工作原理,接下来让我们探讨一些可以有效使用链表的实际应用。

您也可以报名参加我们的 免费课程 今天!
实现堆栈和队列
链表最常见的应用之一是实现堆栈和队列。堆栈和队列都是抽象数据类型,可以使用链表轻松实现。
堆栈是一种遵循后进先出(LIFO)原则的数据结构。元素从同一端添加和删除,称为栈顶。链表提供了一种实现堆栈的有效方法,因为我们可以轻松地在链表头部添加或删除元素。
下面是在 Python 中使用链表实现堆栈的示例:
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Stack:
def __init__(self):
self.head = None
def push(self, data):
new_node = Node(data)
new_node.next = self.head
self.head = new_node
def pop(self):
if self.head is None:
return None
popped = self.head.data
self.head = self.head.next
return popped另一方面,队列遵循先进先出 (FIFO) 原则。元素在一端(称为后部)添加,并从另一端(称为前部)删除。链表也可以用来有效地实现队列。
下面是在 Python 中使用链表实现队列的示例:
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Queue:
def __init__(self):
self.front = None
self.rear = None
def enqueue(self, data):
new_node = Node(data)
if self.rear is None:
self.front = new_node
self.rear = new_node
else:
self.rear.next = new_node
self.rear = new_node
def dequeue(self):
if self.front is None:
return None
dequeued = self.front.data
self.front = self.front.next
if self.front is None:
self.rear = None
return dequeued
处理大型数据集
在处理大型数据集时,链接列表也很有用。与数组不同,链表不需要连续的内存分配。这意味着链表可以有效地处理不同大小的数据集,而无需调整大小或重新分配。
例如,假设我们有一个包含数百万条记录的数据集,我们需要执行插入、删除或遍历等操作。使用数组来执行此任务可能效率很低,因为它需要在插入或删除时移动元素。然而,使用链表,我们可以通过更新指针轻松插入或删除元素,从而提高操作速度。
图遍历算法
图遍历算法,例如广度优先搜索(BFS)和深度优先搜索(DFS),也可以使用链表来实现。在图遍历中,我们以特定顺序访问图中的每个顶点或节点。
链表可以用来表示图的邻接表,其中链表中的每个节点代表一个顶点,其相邻顶点存储为链表节点。这种表示允许有效地遍历和探索图。
多项式表示
链表可用于有效地表示多项式。在数学中,多项式是由变量和系数组成的表达式。多项式中的每一项都可以表示为链表中的一个节点,其中系数和指数存储为数据。
通过使用链表,我们可以轻松地对多项式进行运算,例如加法、减法和乘法。可以操纵节点来执行这些操作,从而得到多项式的简洁有效的表示。
音乐和视频播放列表
链接列表通常用于在音乐和视频播放器中实现播放列表。每首歌曲或视频可以表示为链接列表中的一个节点,其中数据包含有关媒体文件的信息,并且指针指向播放列表中的下一首歌曲或视频。
使用播放列表的链接列表可以在歌曲或视频之间轻松导航。我们可以通过更新指针轻松地在播放列表中添加或删除歌曲,从而提供无缝的用户体验。
结论
总之,链表是通用的数据结构,可以在各个领域找到应用。它们可用于实现堆栈和队列、处理大型数据集、执行图形遍历、表示多项式以及创建播放列表。链表利用其动态内存分配和易于操作的节点,为这些问题提供了有效的解决方案。
通过了解链表的应用,我们可以在为程序选择数据结构时做出明智的决定。无论是管理数据、实现算法还是创建用户友好的界面,链表都为程序员的工具包提供了宝贵的工具。
因此,下次遇到需要高效插入、删除或遍历的问题时,请考虑使用链表来简化您的解决方案并优化您的代码。
您还可以在此处阅读更多与 Python 列表相关的文章:
常见问题
答:链表是一种由节点组成的数据结构,其中每个节点都包含一个值和对序列中下一个节点的引用(或链接)。
答:链表提供高效的插入和删除操作、动态调整大小,并且不需要连续的内存分配。
A:链表缺乏随机访问,需要遍历才能访问元素。它们还消耗额外的内存来存储引用,这对于小型数据集可能效率低下。
答:链表的主要类型有单链表、双向链表和循环链表。
答:在处理动态调整大小和频繁插入或删除时,链表比数组更节省内存,因为它们不需要连续的内存分配。
相关
- :是
- :不是
- :在哪里
- 1
- 10
- 16
- 48
- 5
- 9
- a
- 关于
- 摘要
- ACCESS
- 访问
- 容纳
- 加
- 添加
- 增加
- 另外
- 解决
- 邻
- 优点
- 算法
- 所有类型
- 分配
- 分配
- 让
- 允许
- 还
- an
- 和
- 任何
- 应用领域
- 应用领域
- 保健
- 排列
- 刊文
- 刊文
- AS
- At
- 背部
- 基于
- BE
- 因为
- 开始
- 更好
- 之间
- 都
- 午休
- 但是
- by
- CAN
- 一定
- 更改
- 特点
- 查
- 检查
- 选择
- 选择
- 通告
- 程
- 码
- 系数
- 相当常见
- 常用
- 比较
- 简洁
- 结论
- 考虑
- 组成
- 由
- 消耗
- 容器
- 包含
- 对比
- 数
- 创建信息图
- 创造
- 关键
- 电流
- data
- 数据集
- 处理
- 决定
- DEF
- 定义
- 删除
- 依靠
- 期望
- 细节
- 不同
- 直接
- 方向
- 方向
- do
- 域名
- 双
- 动态
- 动态
- 每
- 容易
- 易
- 只
- 效率
- 高效
- 有效
- 或
- element
- 分子
- 其他
- 空的
- 遭遇
- 结束
- 注册
- 整个
- 特别
- 醚(ETH)
- 甚至
- 例子
- Excel
- 预期
- 体验
- 勘探
- 探索
- 指数
- 表达式
- 额外
- false
- 快
- 文件
- 找到最适合您的地方
- 寻找
- 姓氏:
- 固定
- 柔软
- 如下
- 针对
- 发现
- 频繁
- 频繁
- 止
- 前
- 此外
- 非常好
- 图形
- 增长
- 手
- 处理
- 有
- 头
- 此处
- 高
- 创新中心
- How To
- 但是
- HTTPS
- 理想
- if
- 实施
- 实施
- 实施
- in
- 指数
- 指数
- 低效
- 信息
- 通知
- 接口
- 直观的
- 涉及
- IT
- 它的
- 已知
- 缺乏
- 大
- 名:
- 长度
- 借力
- 友情链接
- 链接
- 清单
- 书单
- 主要
- 使
- 制作
- 制作
- 管理的
- 操纵
- 操作
- 数学
- 最大宽度
- 可能..
- 意
- 手段
- 媒体
- 内存
- 中间
- 百万
- 修改
- 更多
- 最先进的
- 移动
- 乘法
- 音乐
- 旅游导航
- 需求
- 需要
- 邻接
- 下页
- 节点
- 节点
- 不包含
- 数
- of
- 提供
- on
- 一
- 仅由
- 运营
- 优化
- or
- 秩序
- 其他名称
- 我们的
- 输出
- 超过
- 演出
- 性能
- 执行
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 球员
- 点
- 点
- 多项式
- 多项式
- 位置
- 实用
- 实际应用
- 以前
- 原理
- 市场问题
- 问题
- 训练课程
- 提供
- 提供
- 优
- 蟒蛇
- 提高
- 随机
- 范围
- 达到
- 达到
- 阅读
- 记录
- 参考
- 引用
- 有关
- 去掉
- 去除
- 代表
- 表示
- 代表
- 代表
- 要求
- 岗位要求
- 需要
- 导致
- 导致
- 回报
- 反转
- 右
- 同
- 对工资盗窃
- 情景
- 无缝的
- 搜索
- 搜索
- 其次
- 自
- 序列
- 服务
- 集
- 几个
- 转换中
- 类似
- 简化
- 只是
- 尺寸
- 尺寸
- 小
- 方案,
- 解决方案
- 一些
- 歌曲
- 具体的
- 堆
- 堆栈
- 开始
- 商店
- 存储
- 结构体
- 结构
- 减法
- 这样
- 合适的
- SUPPORT
- SVG的
- 交换
- 任务
- 术语
- 条款
- 比
- 这
- 图
- 其
- 他们
- 那里。
- 博曼
- 他们
- Free Introduction
- 三
- 次
- 至
- 工具
- 工具箱
- 最佳
- 横过
- true
- 二
- 类型
- 类型
- 理解
- 不像
- 直到
- 更新
- 更新
- 用过的
- 有用
- 用户
- 用户体验
- 用户友好
- 运用
- 有价值
- 折扣值
- 变量
- 各个
- 变化
- 多才多艺
- 视频
- 视频
- 参观
- vs
- 方法..
- we
- 什么是
- 什么是
- ,尤其是
- 而
- 是否
- 这
- 而
- 将
- 也完全不需要
- 工作
- 您
- 您一站式解决方案
- 和风网