高斯朴素贝叶斯分类器的决策区域。 图片由作者提供。
我认为这是每个数据科学职业生涯开始时的经典之作: 朴素贝叶斯分类器. 或者我应该说 家庭 朴素贝叶斯分类器,因为它们有很多种。 例如,有一个多项式朴素贝叶斯、一个伯努利朴素贝叶斯和一个高斯朴素贝叶斯分类器,它们只有一个小细节不同,我们会发现。 朴素贝叶斯算法在设计上非常简单,但在许多复杂的现实世界中被证明是有用的。
在本文中,您可以学习
- 朴素贝叶斯分类器是如何工作的,
- 为什么按原样定义它们是有意义的,以及
- 如何使用 NumPy 在 Python 中实现它们。
你可以在上面找到代码 我的Github.
查看我的贝叶斯统计入门可能会有所帮助 贝叶斯推理简介 习惯贝叶斯公式。 由于我们将以符合 scikit 学习的方式实现分类器,因此也值得查看我的文章 构建您自己的自定义 scikit-learn 回归. 但是,scikit-learn 开销非常小,无论如何您都应该能够跟进。
我们将开始探索简单得惊人的朴素贝叶斯分类理论,然后转向实现。
分类时我们真正感兴趣的是什么? 我们实际上在做什么,输入和输出是什么? 答案很简单:
给定一个数据点 x,x 属于某个类 c 的概率是多少?
这就是我们想要回答的全部 任何 分类。 您可以直接将此语句建模为条件概率: p(c|x).
例如,如果有
- 3班 c₁, cXNUMX, c₃及
- x 由2个特征组成 x₁, xXNUMX,
分类器的结果可能类似于 p(c₁|x₁, xXNUMX)= 0.3, p(cXNUMX|x₁, xXNUMX)=0.5 和 p(c₃|x₁, xXNUMX)=0.2。 如果我们关心单个标签作为输出,我们会选择概率最高的标签,即 cXNUMX 这里的概率为 50%。
朴素贝叶斯分类器试图直接计算这些概率。
朴素贝叶斯
好的,给定一个数据点 x, 我们要计算 p(c|x) 对于所有类 c 然后输出 c 以最高的概率。 在公式中,您经常将其视为

图片由作者提供。
请注意: 最大 p(c|x) 返回最大概率,而 argmax p(c|x) 返回 c 以这个最高的概率。
但在我们优化之前 p(c|x),我们必须能够计算它。 为此,我们使用 贝叶斯定理:

贝叶斯定理。 图片由作者提供。
这是朴素贝叶斯的贝叶斯部分。 但是现在,我们有以下问题:什么是 p(x|c) 以及 p(c)?
这就是训练朴素贝叶斯分类器的全部内容。
培训
为了说明一切,让我们使用玩具数据集 两个真实的特征 x₁, xXNUMX及 三班 c₁, cXNUMX, c₃ 在下面的。

数据,可视化。 图片由作者提供。
您可以通过创建这个确切的数据集
from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=20, centers=[(0,0), (5,5), (-5, 5)], random_state=0)让我们从 类别概率 p(c), 某些类的概率 c 在标记的数据集中观察到。 估计这一点的最简单方法是只计算类别的相对频率并将它们用作概率。 我们可以使用我们的数据集来查看这到底意味着什么。
7 分中有 20 分标记为类 c₁ (蓝色)在数据集中,因此我们说 p(c₁)=7/20。 我们班有7分 cXNUMX (红色)也是如此,因此我们设置 p(cXNUMX)=7/20。 最后一节课 c₃ (黄色)只有 6 分,因此 p(c₃)=6/20。
这种类概率的简单计算类似于最大似然法。 但是,您也可以使用另一个 先 分布,如果你喜欢。 例如,如果您知道此数据集不代表真实人口,因为类 c₃ 应该出现在 50% 的情况下,那么你设置 p(c₁)= 0.25, p(cXNUMX)=0.25 和 p(c₃)=0.5。 任何可以帮助您提高测试集性能的东西。
我们现在转向 可能性 p(x|c)=p(x₁, xXNUMX|c). 计算这种可能性的一种方法是过滤带有标签的样本的数据集 c 然后尝试找到捕获特征的分布(例如二维高斯分布) x₁, xXNUMX.
不幸的是,通常我们没有足够的每个类别的样本来正确估计可能性。
为了能够建立一个更健壮的模型,我们使 天真的假设 该功能 x₁, xXNUMX ,那恭喜你, 随机独立,给定 c. 这只是一种使数学更容易的奇特方法

图片由作者提供
每个班级 c。 这是 天真的 朴素贝叶斯的一部分来自于这个方程一般不成立。 尽管如此,即便如此,朴素贝叶斯在实践中仍能产生良好的、有时甚至是出色的结果。 特别是对于具有词袋特征的 NLP 问题,多项式朴素贝叶斯大放异彩。
上面给出的参数对于您可以找到的任何朴素贝叶斯分类器都是相同的。 现在它只取决于你如何建模 p(x₁|c₁), p(x₁|c₁), p(x₁|c₁), p(x₁|c₁), p(x₁|c₃) 和 p(xXNUMX|cXNUMX).
如果你的特征只有 0 和 1,你可以使用 伯努利分布. 如果它们是整数,则 多项分布. 然而,我们有真实的特征值并决定 高斯 分布,因此得名高斯朴素贝叶斯。 我们假设以下形式

图片由作者提供。
哪里 μᵢ,ⱼ 是平均值并且 σᵢ,ⱼ 是我们必须根据数据估计的标准差。 这意味着我们为每个特征得到一个均值 i 再加上一堂课 cⱼ, 在我们的例子中 2*3=6 意味着。 标准偏差也是如此。 这就需要一个例子。
让我们试着估计 μXNUMX,₁ 和 σXNUMX。 因为 j=1,我们只对类感兴趣 c₁,让我们只保留带有此标签的样品。 保留以下示例:
# samples with label = c_1 array([[ 0.14404357, 1.45427351], [ 0.97873798, 2.2408932 ], [ 1.86755799, -0.97727788], [ 1.76405235, 0.40015721], [ 0.76103773, 0.12167502], [-0.10321885, 0.4105985 ], [ 0.95008842, -0.15135721]])现在,因为 i=2 我们只需要考虑第二列。 μXNUMX,₁ 是均值,并且 σXNUMX,₁ 此列的标准偏差,即 μXNUMX,₁ = 0.49985176 和 σXNUMX,₁ = 0.9789976。
如果您再次从上方查看散点图,这些数字就有意义了。 特点 xXNUMX 来自班级的样本 c₁ 都在 0.5 左右,如图所示。
我们现在为其他五个组合计算这个,我们就完成了!
在 Python 中,你可以这样做:
from sklearn.datasets import make_blobs
import numpy as np # Create the data. The classes are c_1=0, c_2=1 and c_3=2.
X, y = make_blobs( n_samples=20, centers=[(0, 0), (5, 5), (-5, 5)], random_state=0
) # The class probabilities.
# np.bincounts counts the occurence of each label.
prior = np.bincount(y) / len(y) # np.where(y==i) returns all indices where the y==i.
# This is the filtering step.
means = np.array([X[np.where(y == i)].mean(axis=0) for i in range(3)])
stds = np.array([X[np.where(y == i)].std(axis=0) for i in range(3)])
我们收到
# priors
array([0.35, 0.35, 0.3 ])
# means array([[ 0.90889988, 0.49985176], [ 5.4111385 , 4.6491892 ], [-4.7841679 , 5.15385848]])
# stds
array([[0.6853714 , 0.9789976 ], [1.40218915, 0.67078568], [0.88192625, 1.12879666]])这是训练高斯朴素贝叶斯分类器的结果。
做出预测
完整的预测公式为

图片由作者提供。
让我们假设一个新的数据点 x*=(-2, 5) 进来了。

图片由作者提供。
要查看它属于哪个类,让我们计算 p(c|x*) 对于所有类。 从图片上看应该属于类 c₃ = 2,但让我们看看。 让我们忽略分母 p(x) 一秒钟。 使用以下循环计算提名人 j = 1、2、3。
x_new = np.array([-2, 5]) for j in range(3): print( f"Probability for class {j}: {(1/np.sqrt(2*np.pi*stds[j]**2)*np.exp(-0.5*((x_new-means[j])/stds[j])**2)).prod()*p[j]:.12f}" )
我们收到
Probability for class 0: 0.000000000263
Probability for class 1: 0.000000044359
Probability for class 2: 0.000325643718当然,这些 概率 (我们不应该那样称呼它们)不要加起来为一,因为我们忽略了分母。 然而,这没问题,因为我们可以将这些未归一化的概率除以它们的总和,然后它们加起来就是 0.00032569。 因此,将这三个值除以它们的总和约为 XNUMX,我们得到

图片由作者提供。
正如我们所料,这是一个明显的赢家。 现在,让我们来实施吧!
这种实现目前效率不高,数值不稳定,它仅用于教育目的。 我们已经讨论了大部分内容,所以现在应该很容易跟进了。 你可以忽略所有 check 功能,或阅读我的文章 构建您自己的自定义 scikit-learn 如果您对他们的确切工作感兴趣。
请注意,我实施了一个 predict_proba 方法首先计算概率。 方法 predict 只需调用此方法并使用 argmax 函数以最高概率返回索引(=类)(又来了!)。 类等待类从 0 到 k-1,哪里 k 是类的数量。
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted class GaussianNaiveBayesClassifier(BaseEstimator, ClassifierMixin): def fit(self, X, y): X, y = check_X_y(X, y) self.priors_ = np.bincount(y) / len(y) self.n_classes_ = np.max(y) + 1 self.means_ = np.array( [X[np.where(y == i)].mean(axis=0) for i in range(self.n_classes_)] ) self.stds_ = np.array( [X[np.where(y == i)].std(axis=0) for i in range(self.n_classes_)] ) return self def predict_proba(self, X): check_is_fitted(self) X = check_array(X) res = [] for i in range(len(X)): probas = [] for j in range(self.n_classes_): probas.append( ( 1 / np.sqrt(2 * np.pi * self.stds_[j] ** 2) * np.exp(-0.5 * ((X[i] - self.means_[j]) / self.stds_[j]) ** 2) ).prod() * self.priors_[j] ) probas = np.array(probas) res.append(probas / probas.sum()) return np.array(res) def predict(self, X): check_is_fitted(self) X = check_array(X) res = self.predict_proba(X) return res.argmax(axis=1)测试实施
虽然代码很短,但仍然太长,无法完全确定我们没有犯任何错误。 那么,让我们看看它的表现如何 scikit-learn GaussianNB 分类器.
my_gauss = GaussianNaiveBayesClassifier()
my_gauss.fit(X, y)
my_gauss.predict_proba([[-2, 5], [0,0], [6, -0.3]])输出
array([[8.06313823e-07, 1.36201957e-04, 9.99862992e-01], [1.00000000e+00, 4.23258691e-14, 1.92051255e-11], [4.30879705e-01, 5.69120295e-01, 9.66618838e-27]])使用的预测 predict 方法是
# my_gauss.predict([[-2, 5], [0,0], [6, -0.3]])
array([2, 0, 1])现在,让我们使用 scikit-learn。 投入一些代码
from sklearn.naive_bayes import GaussianNB gnb = GaussianNB()
gnb.fit(X, y)
gnb.predict_proba([[-2, 5], [0,0], [6, -0.3]])产量
array([[8.06314158e-07, 1.36201959e-04, 9.99862992e-01], [1.00000000e+00, 4.23259111e-14, 1.92051343e-11], [4.30879698e-01, 5.69120302e-01, 9.66619630e-27]])这些数字看起来有点类似于我们分类器的数字,但它们在最后几个显示的数字中有点偏差。 我们做错了什么吗? 没有 scikit-learn 版本仅仅使用另一个超参数 var_smoothing=1e-09 . 如果我们将这个设置为 零,我们得到了我们的数字。 完美的!
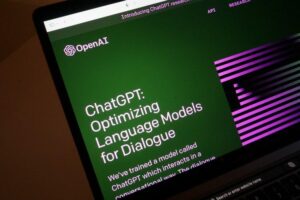
看看我们分类器的决策区域。 我还标记了我们用于测试的三个点。 靠近边界的那个点只有56.9%的几率属于红色类,从图中可以看出 predict_proba 输出。 其他两点的分类置信度更高。

具有 3 个新点的决策区域。 图片由作者提供。
在本文中,我们了解了高斯朴素贝叶斯分类器的工作原理,并直观地了解了为何以这种方式设计它——它是一种对兴趣概率建模的直接方法。 将其与 Logistic 回归进行比较:概率是使用线性函数建模的,并在其之上应用了 sigmoid 函数。 它仍然是一个简单的模型,但感觉不像朴素贝叶斯分类器那么自然。
我们继续计算一些示例并在此过程中收集一些有用的代码片段。 最后,我们以与 scikit-learn 配合良好的方式实现了一个完整的高斯朴素贝叶斯分类器。 这意味着您可以在管道或网格搜索中使用它。
最后,我们通过导入 scikit-learn 自己的高斯朴素贝叶斯分类器并测试我们和 scikit-learn 的分类器是否产生相同的结果来做一个小的健全性检查。 这个测试是成功的。
罗伯特·库伯勒博士 是 Publicis Media 的数据科学家和 Towards Data Science 的作者。
原版。 经许可重新发布。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/03/gaussian-naive-bayes-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=gaussian-naive-bayes-explained
- :是
- $UP
- 1
- 7
- 8
- 9
- a
- Able
- 关于
- 以上
- 通
- 驳
- 算法
- 所有类型
- 和
- 另一个
- 回答
- 出现
- 应用的
- 的途径
- 保健
- 参数
- 围绕
- 刊文
- AS
- At
- 作者
- 基地
- 贝叶斯
- BE
- 因为
- before
- 开始
- 位
- 蓝色
- 边界
- 建立
- by
- 计算
- 计算
- 呼叫
- 呼叫
- CAN
- 捕获
- 关心
- 寻找工作
- 案件
- 例
- 机会
- 查
- 程
- 类
- 经典
- 分类
- 机密
- 清除
- 关闭
- 码
- 收藏
- 柱
- 组合
- 如何
- 比较
- 完成
- 完全
- 复杂
- 计算
- 信心
- 考虑
- 持续
- 可以
- 再加
- 课程
- 创建信息图
- 习俗
- data
- 数据科学
- 数据科学家
- 数据集
- 决定
- 决定
- 依靠
- 设计
- 设计
- 细节
- 偏差
- DID
- 不同
- 数字
- 直接
- 直接
- 讨论
- 分配
- 做
- 别
- e
- 每
- 更容易
- 教育的
- 高效
- 更多
- 特别
- 评估
- 甚至
- 所有的
- 一切
- 究竟
- 例子
- 例子
- 预期
- 解释
- 探索
- 专栏
- 特征
- 少数
- 过滤
- 过滤
- 终于
- 找到最适合您的地方
- 姓氏:
- 遵循
- 以下
- 针对
- 公式
- 止
- 功能
- 功能
- 其他咨询
- 温和
- 得到
- 特定
- GOES
- 非常好
- 格
- 有
- 帮助
- 帮助
- 此处
- 更高
- 最高
- 举行
- 创新中心
- 但是
- HTML
- HTTPS
- i
- 图片
- 实施
- 履行
- 实施
- 进口
- 输入
- 改善
- in
- 指数
- 指数
- 输入
- 兴趣
- 有兴趣
- 介绍
- 直觉
- IT
- 掘金队
- 保持
- 类
- 知道
- 标签
- 名:
- 知道
- 喜欢
- 小
- 长
- 看
- 使
- 制作
- 制作
- 许多
- 标
- 数学
- 最多
- 手段
- 媒体
- 仅仅
- 方法
- 可能
- 错误
- 模型
- 更多
- 最先进的
- 姓名
- 自然
- 全新
- NLP
- 数
- 数字
- 麻木
- of
- on
- 一
- 其他名称
- 产量
- 优秀
- 己
- 部分
- 性能
- 允许
- 图片
- 件
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 点
- 点
- 人口
- 在练习上
- 预测
- 预测
- 底漆
- 先
- 可能性
- 市场问题
- 问题
- 正确
- 证明
- 目的
- 蟒蛇
- 宁
- 阅读
- 真实
- 真实的世界
- 红色
- 地区
- 地区
- 回归
- 留
- 代表
- 酷似
- 导致
- 成果
- 回报
- 回报
- ROBERT
- 健壮
- 同
- 科学
- 科学家
- scikit学习
- 搜索
- 其次
- 自
- 感
- 服务
- 集
- 短
- 应该
- 类似
- 简易
- 自
- 单
- 情况
- 小
- So
- 一些
- 东西
- 稳定
- 标准
- 开始
- 个人陈述
- 步
- 仍
- 成功
- 采取
- test
- 测试
- 这
- 其
- 他们
- 因此
- 博曼
- 事
- 三
- 投掷
- 至
- 也有
- 最佳
- 向
- 玩具
- 产品培训
- true
- 转
- us
- 使用
- 平时
- 验证
- 价值观
- 版本
- 方法..
- 井
- 什么是
- 什么是
- 这
- 而
- 维基百科上的数据
- 将
- 工作
- 合作
- 合算
- 将
- 错误
- X
- 产量
- 产量
- 您一站式解决方案
- 和风网