在现代世界中,大多数企业都依赖大数据和分析的力量来推动其增长、战略投资和客户参与。 大数据是定向广告、个性化营销、产品推荐、洞察生成、价格优化、情绪分析、预测分析等的基本常量。
数据通常从多个来源收集,在本地或云端的数据湖中进行转换、存储和处理。 虽然最初的数据摄取相对微不足道,可以通过内部开发的自定义脚本或传统的 ETL(提取转换加载)工具来实现,但由于公司必须:
- 管理完整的数据生命周期——用于管理和合规目的
- 优化存储——降低相关成本
- 简化架构——通过重用计算基础设施
- 增量处理数据——通过强大的状态管理
- 对批处理和流数据应用相同的策略——无需重复工作
- 在本地和云之间迁移——用最少的努力
这是哪里 阿帕奇哥布林,一个开源的数据管理和集成系统出现了。Apache Gobblin 提供了无与伦比的功能,可以根据业务需要整体或部分使用。
在本节中,我们将深入研究 Apache Gobblin 的各种功能,这些功能有助于解决前面概述的挑战。
管理完整的数据生命周期
Apache Gobblin 提供了一系列功能来构建支持数据集上全套数据生命周期操作的数据管道。
- 摄取数据——从多个源到接收器,包括数据库、Rest API、FTP/SFTP 服务器、文件管理器、CRM(如 Salesforce 和 Dynamics 等)。
- 通过 Distcp-NG 在具有 Hadoop 分布式文件系统专用功能的多个数据湖之间复制数据。
- 清除数据——使用保留策略,例如基于时间的、最新的 K、版本化的或策略的组合。
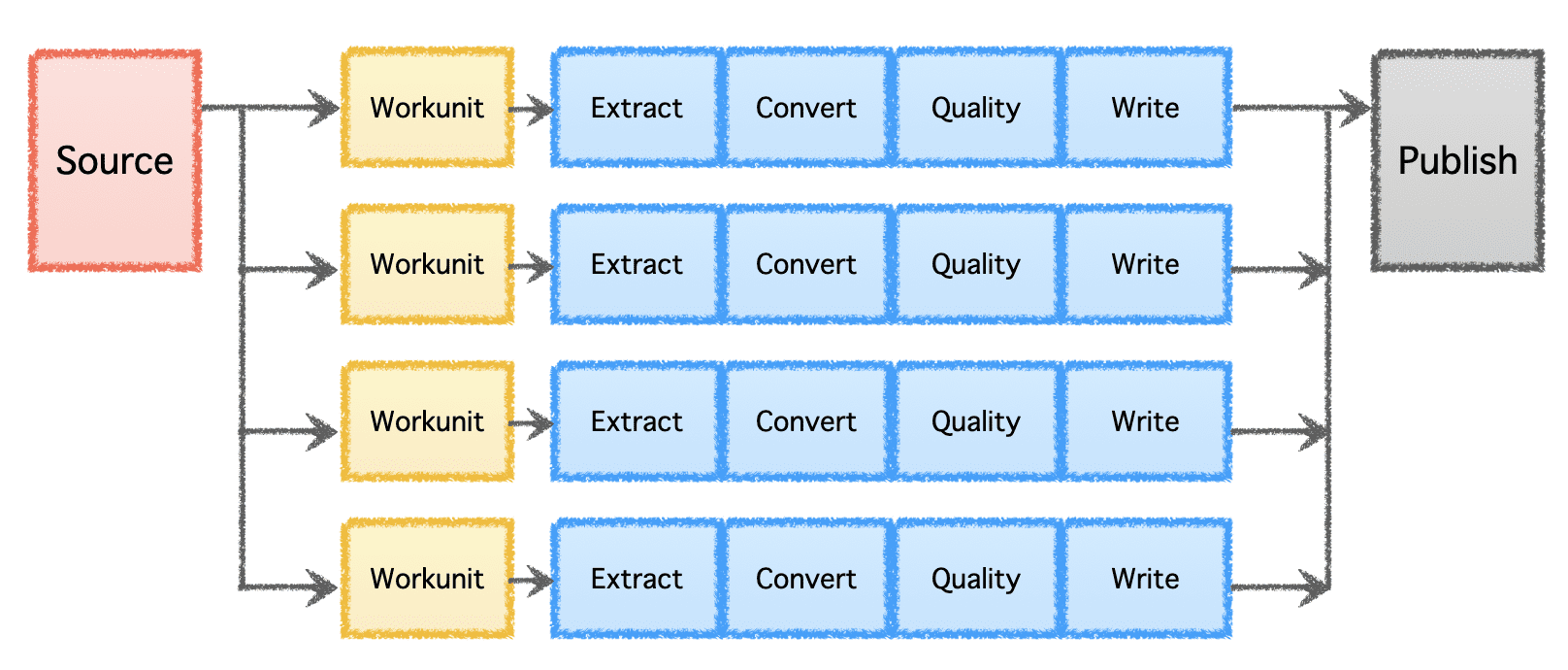
Gobblin 的逻辑管道由确定工作分配和创建“工作单元”的“源”组成。 然后,这些“工作单元”将作为“任务”执行,包括提取、转换、质量检查和将数据写入目的地。 最后一步“数据发布”验证管道是否成功执行并自动提交输出数据(如果目标支持)。
图片作者
优化存储
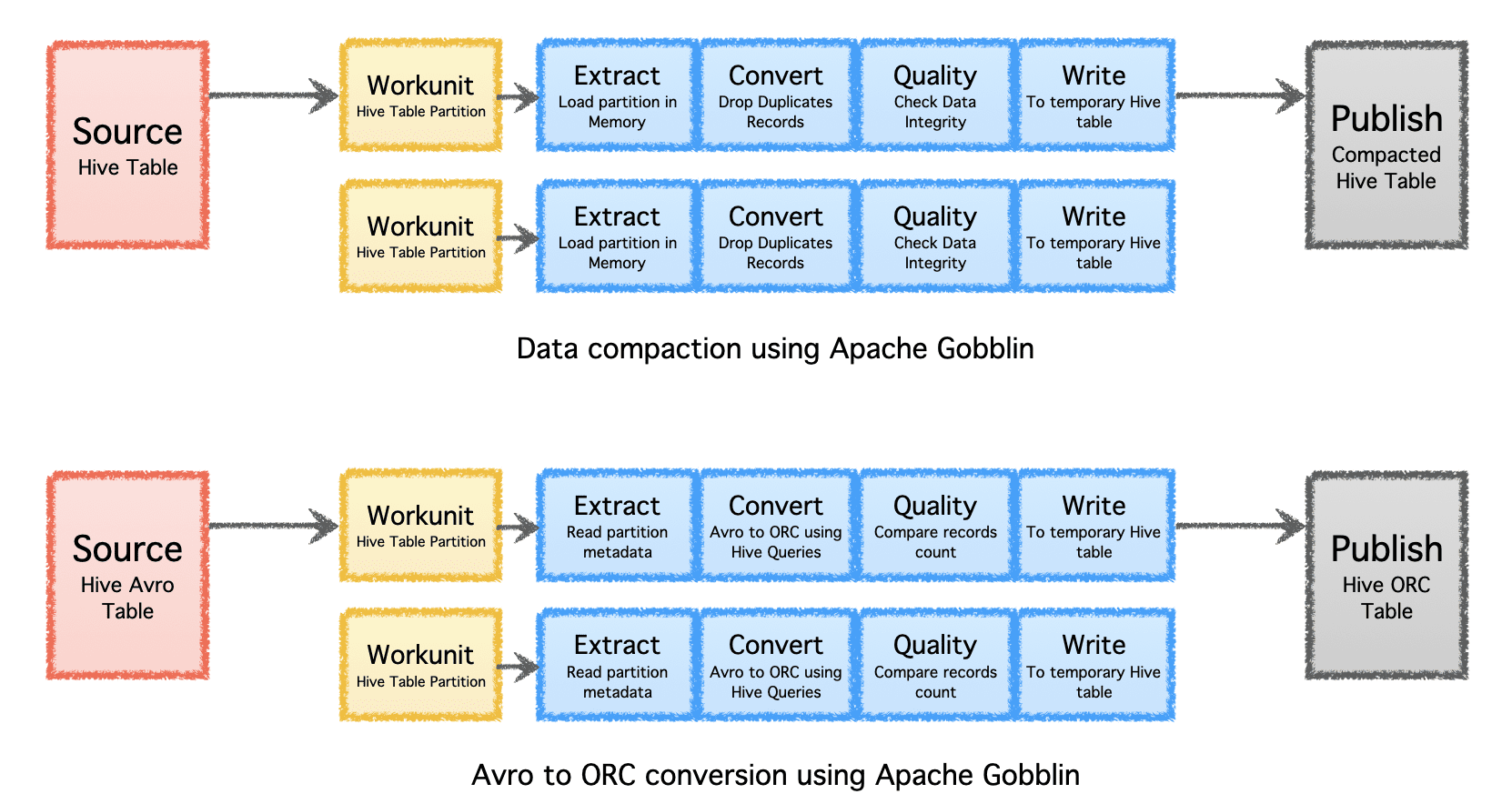
Apache Gobblin 可以在通过压缩或格式转换摄取或复制后对数据进行后处理,从而帮助减少数据所需的存储量。
- Compaction——基于记录的所有字段或关键字段对数据进行去重后处理,修剪数据以仅保留具有相同键的最新时间戳的记录。
- Avro 到 ORC——作为一种专门的格式转换机制,将流行的基于行的 Avro 格式转换为超优化的基于列的 ORC 格式。
图片作者
简化架构
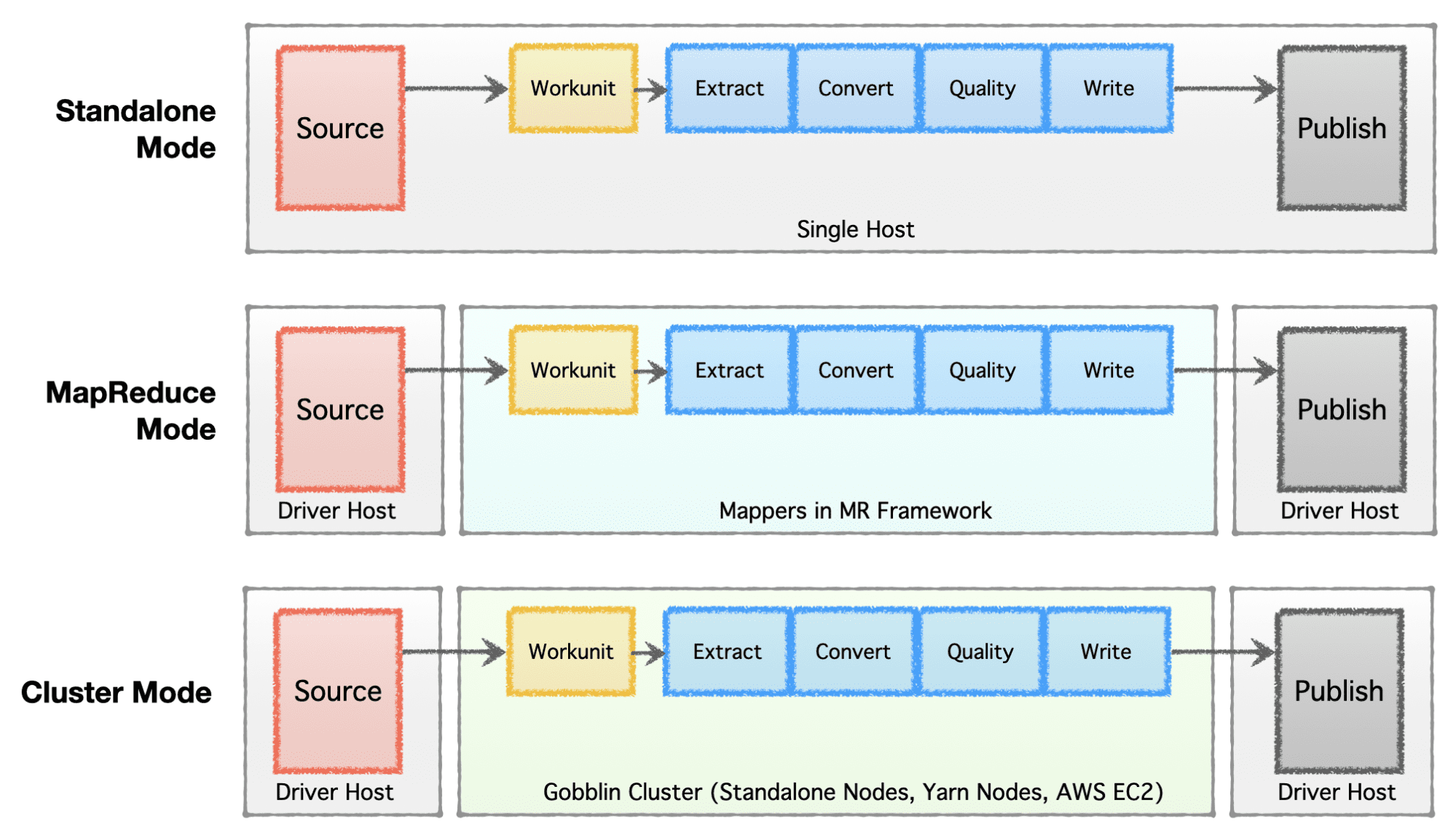
根据公司所处的阶段(初创企业到企业)、规模要求和各自的架构,公司更愿意建立或发展他们的数据基础设施。 Apache Gobblin 非常灵活,支持多种执行模型。
- 独立模式——在裸机上作为独立进程运行,即用于简单用例和低要求情况的单个主机。
- MapReduce 模式——在 Hadoop 基础架构上作为 MapReduce 作业运行,适用于大数据案例,以处理 PB 级规模的数据集。
- 集群模式:独立——在一组裸机或主机上作为由 Apache Helix 和 Apache Zookeeper 支持的集群运行,以处理独立于 Hadoop MR 框架的大规模。
- 集群模式:Yarn——在没有 Hadoop MR 框架的情况下在原生 Yarn 上作为集群运行。
- 集群模式:AWS——在亚马逊的公共云产品上作为集群运行,即。 AWS 用于托管在 AWS 上的基础设施。
图片作者
增量处理数据
在具有多个数据管道和大量数据的大规模情况下,数据需要分批处理并随着时间的推移进行处理。 因此,它需要检查点,以便数据管道可以从上次中断的地方恢复并继续向前。 Apache Gobblin 支持低水位线和高水位线,并通过 HDFS、AWS S3、MySQL 和更透明的状态存储支持强大的状态管理语义。
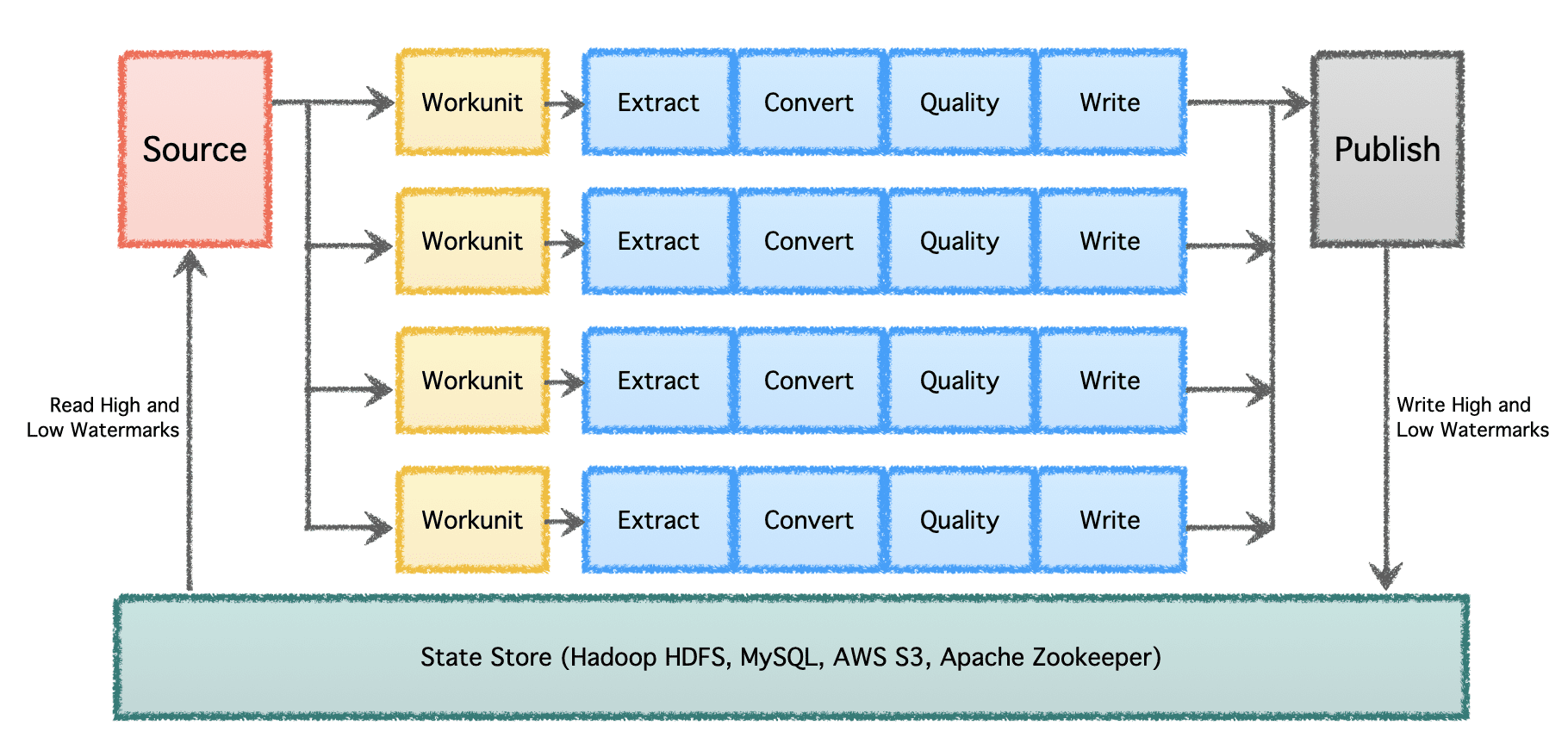
图片作者
批处理和流数据的相同策略
今天的大多数数据管道必须写入两次,一次用于批处理数据,另一次用于近线或流数据。 它加倍了工作量,并在应用于不同类型管道的策略和算法中引入了不一致。 如果在 Gobblin 集群模式、Gobblin on AWS 模式或 Gobblin on Yarn 模式下使用,Apache Gobblin 允许用户编写一次管道并在批处理和流数据上运行它来解决这个问题。
在本地和云之间迁移
由于其可以在单个盒子、节点集群或云上本地运行的多种模式,Apache Gobblin 可以在本地和云上部署和使用。 因此,允许用户编写一次数据管道,并根据特定需求在本地和云之间轻松地将它们与 Gobblin 部署一起迁移。
由于其高度灵活的架构、强大的功能以及它可以支持和处理的极端数据量,Apache Gobblin 被用于生产基础设施 主要科技公司 是当今任何大数据基础架构部署的必备工具。
有关 Apache Gobblin 及其使用方法的更多详细信息,请访问 https://gobblin.apache.org
阿比舍克·蒂瓦里(Abhishek Tiwari) 是 LinkedIn 的高级经理,领导公司的大数据管道组织。 他还是 Apache 软件基金会 Apache Gobblin 的副总裁和英国计算机协会的会员。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- 实现
- 解决
- 广告
- 后
- 援助
- 算法
- 所有类型
- 允许
- 量
- 分析
- 分析
- 和
- 阿帕奇
- APIs
- 应用的
- 架构
- 相关
- 作者
- AWS
- 已备份
- 基于
- 成为
- 之间
- 大
- 大数据运用
- 盒子
- 英国的
- 商业
- 企业
- 能力
- 例
- 挑战
- 检查
- 云端技术
- 簇
- 组合
- 公司
- 公司
- 复杂
- 符合
- 一台
- 计算
- 常数
- 建设
- 继续
- 转化
- 兑换
- 创建
- 习俗
- 顾客
- 客户参与
- data
- 数据基础设施
- 数据管理
- 数据库
- 数据集
- 根据
- 部署
- 部署
- 部署
- 目的地
- 详情
- 确定
- 发达
- 不同
- 分布
- 分配
- 动力学
- 容易
- 努力
- 订婚
- 企业
- 醚(ETH)
- 发展
- 执行
- 昂贵
- 提取
- 萃取
- 极端
- 特征
- 同伴
- 字段
- 文件
- 最后
- 柔软
- 格式
- 发现
- 基金会
- 骨架
- 止
- 汽油
- ,
- 代
- 事业发展
- Hadoop的
- 处理
- 帮助
- 高
- 高度
- 主持人
- 托管
- 创新中心
- How To
- HTTPS
- in
- 包括
- 独立
- 基础设施
- 基础设施
- 初始
- 可行的洞见
- 积分
- 推出
- 投资
- IT
- 工作
- 掘金队
- 保持
- 键
- 大
- 名:
- 最新
- 领导
- 加载
- 低
- 机
- 颠覆性技术
- 经理
- 营销
- 机制
- 某些金属
- 迁移
- 时尚
- 模型
- 现代
- 模式
- 更多
- 最先进的
- 多
- 一定有
- MySQL的
- 本地人
- 打印车票
- 需要
- 最新
- 节点
- 提供
- 一
- 开放源码
- 运营
- 组织
- 概述
- 部分
- 个性化你的
- 采摘的
- 管道
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 政策
- 热门
- 功率
- 强大
- 预测分析
- 比较喜欢
- 总统
- 先前
- 车资
- 市场问题
- 过程
- 产品
- 生产
- 提供
- 国家
- 公共云
- 发布
- 质量
- 很快
- 范围
- 建议
- 记录
- 记录
- 减少
- 相对
- 复制
- 岗位要求
- 那些
- REST的
- 简历
- 保留
- 健壮
- 运行
- Salesforce的
- 同
- 鳞片
- 缩放
- 脚本
- 部分
- 语义
- 前辈
- 情绪
- 集
- 显著
- 简易
- 单
- 情况
- So
- 社会
- 软件
- 解决
- 解决
- 来源
- 来源
- 专门
- 具体的
- 阶段
- 独立
- 启动
- 州/领地
- 步
- 存储
- 商店
- 存储
- 善用
- 流
- 流
- 成功
- 套房
- SUPPORT
- 支持
- 系统
- 针对
- 任务
- 专业技术
- 其
- 因此
- 通过
- 次
- 时间戳
- 至
- 今晚
- 工具
- 传统
- 改造
- 转化
- 类型
- 相关
- 空前的
- 使用
- 用户
- 各个
- 多才多艺
- 通过
- 副总裁
- 体积
- 卷
- 这
- 而
- 将
- 也完全不需要
- 工作
- 世界
- 写
- 写作
- 书面
- 和风网