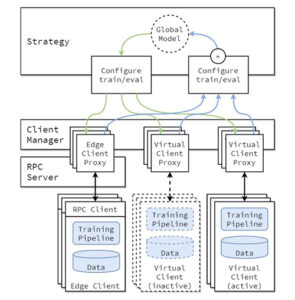
在 第一部分 在这个由三部分组成的系列中,我们提出了一个解决方案,演示如何针对抵押贷款承保用例使用 AWS AI 和机器学习 (ML) 服务大规模自动检测文档篡改和欺诈。
在这篇文章中,我们提出了一种开发基于深度学习的计算机视觉模型的方法,以检测和突出显示抵押贷款承保中的伪造图像。我们提供有关构建、训练和部署深度学习网络的指导 亚马逊SageMaker.
在第 3 部分中,我们演示了如何在 亚马逊欺诈检测器.
解决方案概述
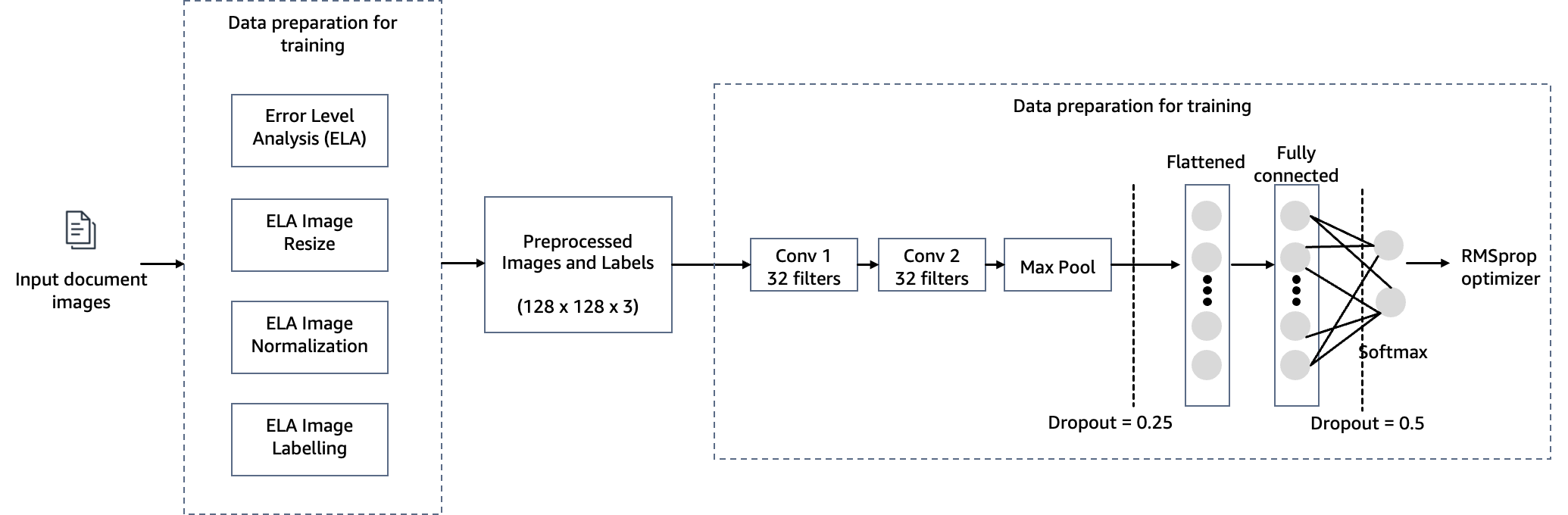
为了实现检测抵押贷款承销中文档篡改的目标,我们采用 SageMaker 上托管的计算机视觉模型作为图像伪造检测解决方案。该模型接收测试图像作为输入,并生成伪造的可能性预测作为其输出。网络架构如下图所示。
图像伪造主要涉及四种技术:拼接、复制移动、去除和增强。根据伪造品的特征,可以使用不同的线索作为检测和定位的基础。这些线索包括 JPEG 压缩伪影、边缘不一致、噪声模式、颜色一致性、视觉相似性、EXIF 一致性和相机型号。
鉴于图像伪造检测的广泛领域,我们使用错误级别分析(ELA)算法作为检测伪造的说明性方法。我们在这篇文章中选择 ELA 技术的原因如下:
- 它的实施速度更快,并且可以轻松捕获图像的篡改。
- 它的工作原理是分析图像不同部分的压缩级别。这使得它能够检测到可能表明篡改的不一致情况,例如,如果一个区域是从以不同压缩级别保存的另一张图像复制并粘贴的。
- 它擅长检测肉眼难以发现的更微妙或无缝的篡改。即使对图像进行微小的更改也会引入可检测到的压缩异常。
- 它不依赖于原始未修改的图像进行比较。 ELA 只能识别受质疑图像本身内的篡改迹象。其他技术通常需要未经修改的原件进行比较。
- 它是一种轻量级技术,仅依赖于分析数字图像数据中的压缩伪影。它不依赖于专门的硬件或取证专业知识。这使得 ELA 可作为首次分析工具。
- 输出的 ELA 图像可以清楚地突出压缩级别的差异,使篡改区域明显可见。这甚至可以让非专家识别出可能被操纵的迹象。
- 它适用于许多图像类型(例如 JPEG、PNG 和 GIF),并且仅需要图像本身进行分析。其他取证技术可能在格式或原始图像要求方面受到更多限制。
但是,在现实场景中,您可能拥有输入文档(JPEG、PNG、GIF、TIFF、PDF)的组合,我们建议将 ELA 与各种其他方法结合使用,例如 检测边缘的不一致, 噪声模式, 颜色均匀度, EXIF数据一致性, 相机型号识别及 字体均匀度。我们的目标是使用额外的伪造检测技术来更新本文的代码。
ELA 的基本前提假设输入图像采用 JPEG 格式,该格式以其有损压缩而闻名。尽管如此,即使输入图像最初是无损格式(例如 PNG、GIF 或 BMP),后来在篡改过程中转换为 JPEG,该方法仍然有效。当 ELA 应用于原始无损格式时,它通常表明图像质量一致,没有任何恶化,这使得精确定位更改区域变得困难。在 JPEG 图像中,预期的标准是整个图片呈现相似的压缩级别。然而,如果图像中的特定部分显示明显不同的错误级别,则通常表明已经进行了数字更改。
ELA 突出了 JPEG 压缩率的差异。颜色均匀的区域可能会具有较低的 ELA 结果(例如,与高对比度边缘相比,颜色较深)。识别篡改或修改需要寻找的内容包括以下内容:
- 相似的边缘在 ELA 结果中应该具有相似的亮度。所有高对比度边缘应看起来相似,所有低对比度边缘应看起来相似。对于原始照片,低对比度边缘应该几乎与高对比度边缘一样明亮。
- 相似的纹理在 ELA 下应该具有相似的颜色。具有更多表面细节的区域(例如篮球的特写)可能会比光滑表面具有更高的 ELA 结果。
- 无论表面的实际颜色如何,所有平坦表面在 ELA 下都应具有大致相同的颜色。
JPEG 图像使用有损压缩系统。图像的每次重新编码(重新保存)都会给图像带来更多的质量损失。具体来说,JPEG 算法在 8×8 像素网格上运行。每个 8×8 的方格都是独立压缩的。如果图像完全未修改,则所有 8×8 方块应该具有相似的潜在误差。如果图像未修改并重新保存,则每个方块应以大致相同的速率退化。
ELA 以指定的 JPEG 质量级别保存图像。此重新保存会在整个图像中引入已知数量的错误。然后将重新保存的图像与原始图像进行比较。如果图像被修改,则修改所触及的每个 8×8 方块应该比图像的其余部分具有更高的错误潜力。
ELA 的结果直接取决于图像质量。您可能想知道是否添加了某些内容,但如果图片被复制多次,那么 ELA 可能只允许检测重新保存。尝试找到图片的最佳质量版本。
通过训练和实践,ELA 还可以学习识别图像缩放、质量、裁剪和重新保存转换。例如,如果非 JPEG 图像包含可见网格线(1×8 正方形中 8 像素宽),则表示该图片最初为 JPEG,后来转换为非 JPEG 格式(例如 PNG)。如果图片的某些区域缺少网格线或网格线发生偏移,则表示非 JPEG 图像中存在拼接或绘制部分。
在以下部分中,我们将演示配置、训练和部署计算机视觉模型的步骤。
先决条件
要阅读本文,请满足以下先决条件:
- 有一个AWS账户。
- 成立 亚马逊SageMaker Studio。您可以使用默认预设快速启动 SageMaker Studio,从而促进快速启动。欲了解更多信息,请参阅 Amazon SageMaker 简化了个人用户的 Amazon SageMaker Studio 设置.
- 打开 SageMaker Studio 并启动系统终端。
- 在终端中运行以下命令:
git clone https://github.com/aws-samples/document-tampering-detection.git - 一名用户运行 SageMaker Studio 和笔记本环境配置的总成本为每小时 7.314 美元。
设置模型训练笔记本
请完成以下步骤来设置您的培训笔记本:
- 打开
tampering_detection_training.ipynb文档篡改检测目录中的文件。 - 使用图像 TensorFlow 2.6 Python 3.8 CPU 或 GPU 优化设置笔记本环境。
在选择 GPU 优化实例时,您可能会遇到可用性不足的问题或达到 AWS 账户内 GPU 实例的配额限制。要增加配额,请访问服务配额控制台并增加您需要的特定实例类型的服务限制。在这种情况下,您还可以使用 CPU 优化的笔记本电脑环境。 - 针对 核心,选择 Python3.
- 针对 实例类型,选择 ml.m5d.24xlarge 或任何其他大型实例。
我们选择了更大的实例类型来减少模型的训练时间。对于 ml.m5d.24xlarge 笔记本电脑环境,每小时成本为 7.258 美元/小时。
运行培训笔记本
运行笔记本中的每个单元格 tampering_detection_training.ipynb 为了。我们将在以下部分中更详细地讨论一些单元格。
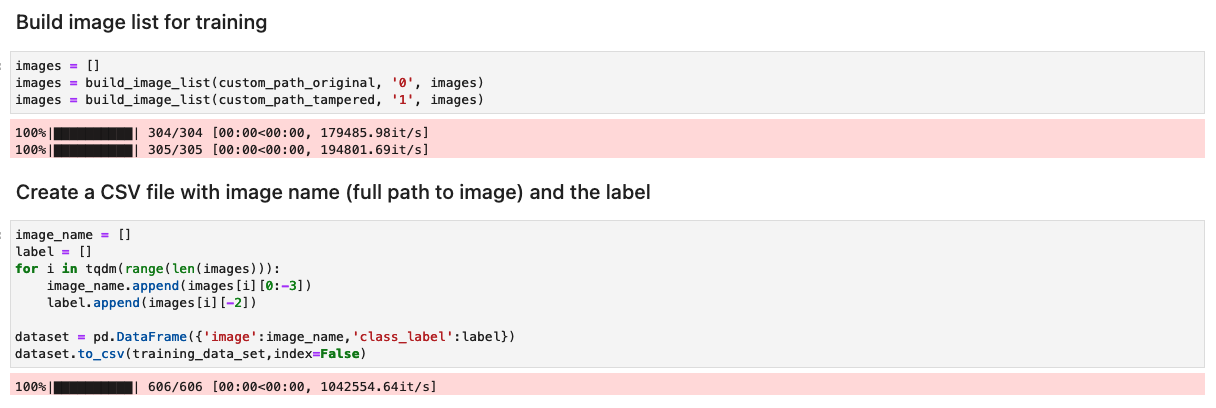
使用原始图像和篡改图像的列表准备数据集
在笔记本中运行以下单元之前,请根据您的特定业务需求准备原始文档和篡改文档的数据集。在这篇文章中,我们使用了被篡改的工资单和银行对账单的样本数据集。该数据集可在图像目录中找到 GitHub存储库.

笔记本读取原始图像和篡改图像 images/training 目录。
用于训练的数据集是使用包含两列的 CSV 文件创建的:图像文件的路径和图像的标签(0 表示原始图像,1 表示篡改图像)。
通过生成每个训练图像的 ELA 结果来处理数据集
在此步骤中,我们生成输入训练图像的 ELA 结果(质量为 90%)。功能 convert_to_ela_image 采用两个参数:路径(图像文件的路径)和质量(表示 JPEG 压缩的质量参数)。该函数执行以下步骤:
- 将图像转换为 RGB 格式,并将图像重新保存为具有指定质量的 JPEG 文件,名称为 tempresaved.jpg。
- 计算原始图像和重新保存的 JPEG 图像 (ELA) 之间的差异,以确定原始图像和重新保存的图像之间像素值的最大差异。
- 根据最大差异计算比例因子来调整 ELA 图像的亮度。
- 使用计算出的比例因子增强 ELA 图像的亮度。
- 将 ELA 结果大小调整为 128x128x3,其中 3 表示通道数,以减少训练的输入大小。
- 返回 ELA 图像。
在有损图像格式(例如 JPEG)中,初始保存过程会导致相当大的颜色损失。然而,当加载图像并随后以相同的有损格式重新编码时,通常会减少颜色退化。 ELA 结果强调了重新保存时最容易发生颜色退化的图像区域。一般来说,与图像的其余部分相比,在表现出更高的退化潜力的区域中,变化会显着出现。
接下来,将图像处理成 NumPy 数组进行训练。然后,我们将输入数据集随机分为训练数据和测试数据或验证数据 (80/20)。运行这些单元时您可以忽略任何警告。
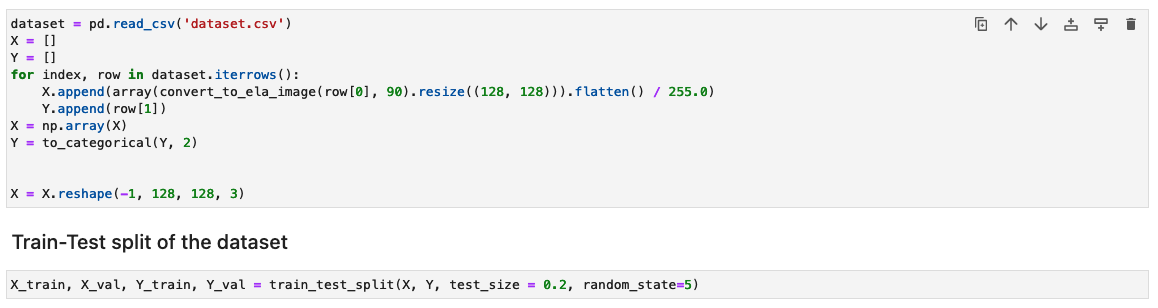
根据数据集的大小,运行这些单元格可能需要一些时间才能完成。对于我们在此存储库中提供的示例数据集,可能需要 5-10 分钟。
配置 CNN 模型
在此步骤中,我们使用小型卷积滤波器构建最小版本的 VGG 网络。 VGG-16 由 13 个卷积层和 XNUMX 个全连接层组成。以下屏幕截图说明了我们的卷积神经网络 (CNN) 模型的架构。
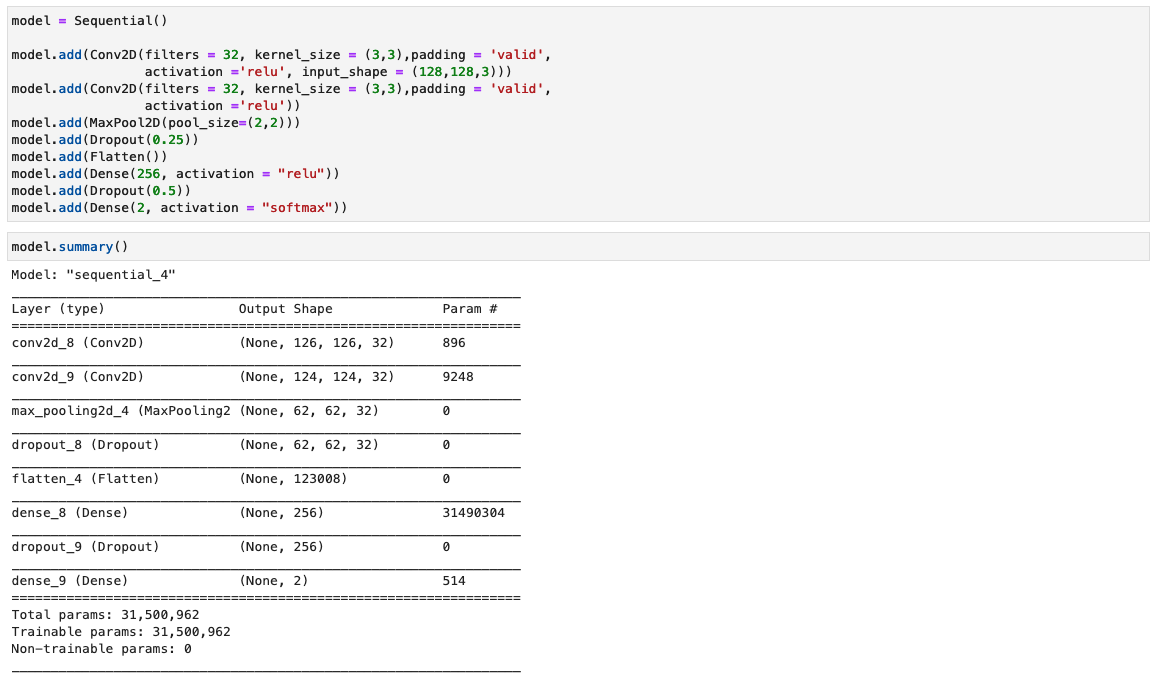
请注意以下配置:
- 输入 – 该模型采用 128x128x3 的图像输入尺寸。
- 卷积层 – 卷积层使用最小感受野 (3×3),即仍然捕获上/下和左/右的最小可能尺寸。接下来是修正线性单元 (ReLU) 激活函数,可减少训练时间。这是一个线性函数,如果输入为正,则输出;否则,输出为零。卷积步幅固定为默认值(1 像素),以保持卷积后保留空间分辨率(步幅是输入矩阵上的像素移位数)。
- 全连接层 – 该网络有两个完全连接的层。第一个密集层使用 ReLU 激活,第二个密集层使用 softmax 将图像分类为原始图像或篡改图像。
运行这些单元时您可以忽略任何警告。
保存模型工件
使用唯一的文件名(例如,基于当前日期和时间)将经过训练的模型保存到名为 model 的目录中。

模型以 Keras 格式保存,扩展名为 .keras。我们还将模型工件保存为名为 1 的目录,其中包含序列化签名和运行它们所需的状态,包括要部署到 SageMaker 运行时的变量值和词汇表(我们将在本文后面讨论)。
衡量模型性能
以下损失曲线显示了模型损失在训练时期(迭代)中的进展情况。
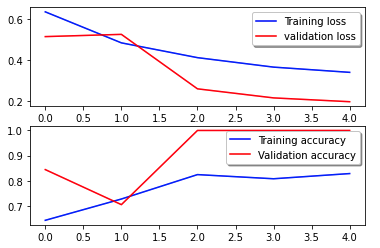
损失函数衡量模型的预测与实际目标的匹配程度。值越低表示预测与真实值之间的一致性越好。历元内损失的减少表明模型正在改进。准确度曲线说明了模型在训练时期的准确度。准确率是正确预测数与预测总数的比率。准确度越高表明模型性能越好。通常,随着模型学习模式并提高其预测能力,训练期间的准确性会提高。这些将帮助您确定模型是否过度拟合(在训练数据上表现良好,但在未见过的数据上表现不佳)或欠拟合(没有从训练数据中学习足够的知识)。
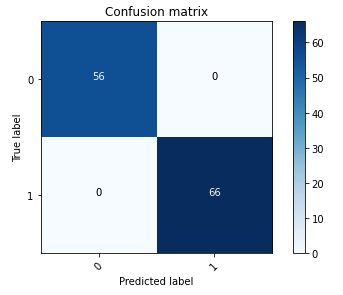
下面的混淆矩阵直观地表示了模型区分正类(伪造图像,表示为值 1)和负类(未篡改图像,表示为值 0)的准确程度。
模型训练完成后,我们的下一步是将计算机视觉模型部署为 API。该 API 将作为承保工作流程的一个组件集成到业务应用程序中。为了实现这一目标,我们使用 Amazon SageMaker Inference,这是一项完全托管的服务。该服务与 MLOps 工具无缝集成,可实现可扩展的模型部署、经济高效的推理、增强生产中的模型管理并降低操作复杂性。在这篇文章中,我们将模型部署为实时推理端点。但是,需要注意的是,根据业务应用程序的工作流程,模型部署也可以定制为批处理、异步处理或通过无服务器部署架构。
设置模型部署笔记本
完成以下步骤来设置模型部署笔记本:
- 打开
tampering_detection_model_deploy.ipynbdocument-tampering-detection 目录中的文件。 - 使用图像 Data Science 3.0 设置笔记本环境。
- 针对 核心,选择 Python3.
- 针对 实例类型,选择 ml.t3.中.
在 ml.t3.medium 笔记本环境中,每小时的成本为 0.056 美元。
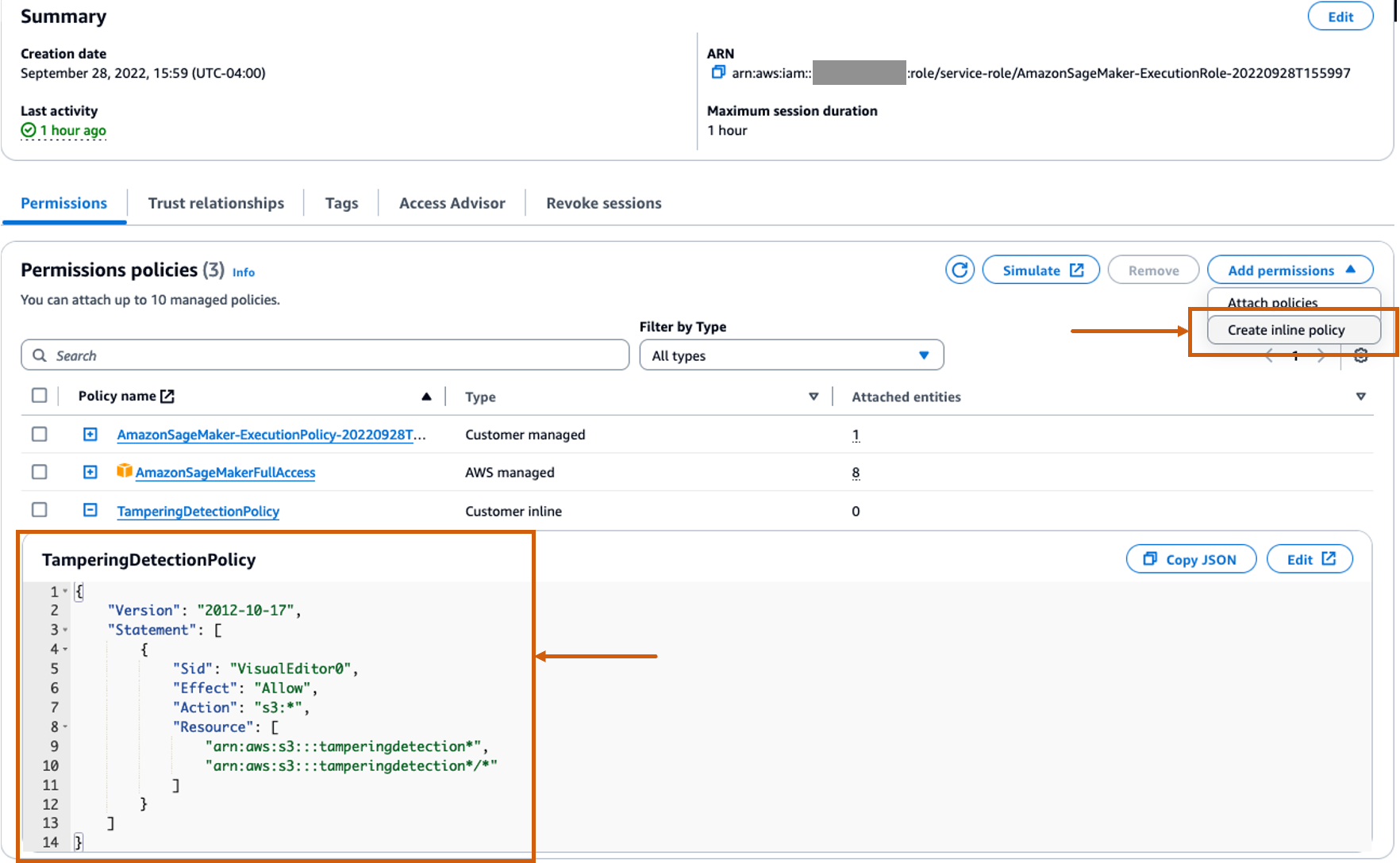
为 SageMaker 角色创建自定义内联策略以允许所有 Amazon S3 操作
AWS身份和访问管理 SageMaker 的 (IAM) 角色将采用以下格式 AmazonSageMaker- ExecutionRole-<random numbers>。确保您使用正确的角色。角色名称可以在 SageMaker 域配置中的用户详细信息下找到。

更新 IAM 角色以包含内联策略以允许所有 亚马逊简单存储服务 (亚马逊 S3)操作。这将需要自动创建和删除存储模型工件的 S3 存储桶。您可以限制对特定 S3 存储桶的访问。请注意,我们在 IAM 策略中对 S3 存储桶名称使用了通配符 (tamperingdetection*).
运行部署笔记本
运行笔记本中的每个单元格 tampering_detection_model_deploy.ipynb 为了。我们将在以下部分中更详细地讨论一些单元格。
创建一个S3存储桶
运行单元以创建 S3 存储桶。该存储桶将被命名 tamperingdetection<current date time> 并且与您的 SageMaker Studio 环境位于同一 AWS 区域。

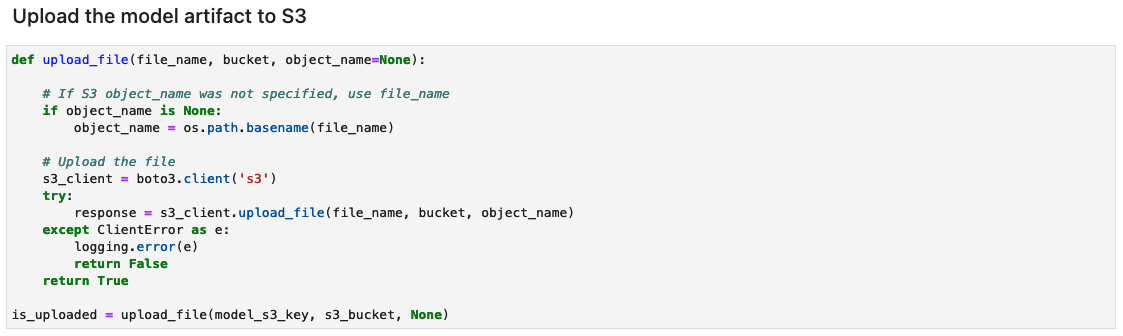
创建模型工件存档并上传到 Amazon S3
从模型工件创建 tar.gz 文件。我们已将模型工件保存为名为 1 的目录,其中包含序列化签名和运行它们所需的状态,包括要部署到 SageMaker 运行时的变量值和词汇表。您还可以包含一个名为的自定义推理文件 inference.py 在模型工件的代码文件夹中。自定义推理可用于输入图像的预处理和后处理。
![]()
创建 SageMaker 推理端点
创建 SageMaker 推理端点的单元可能需要几分钟才能完成。
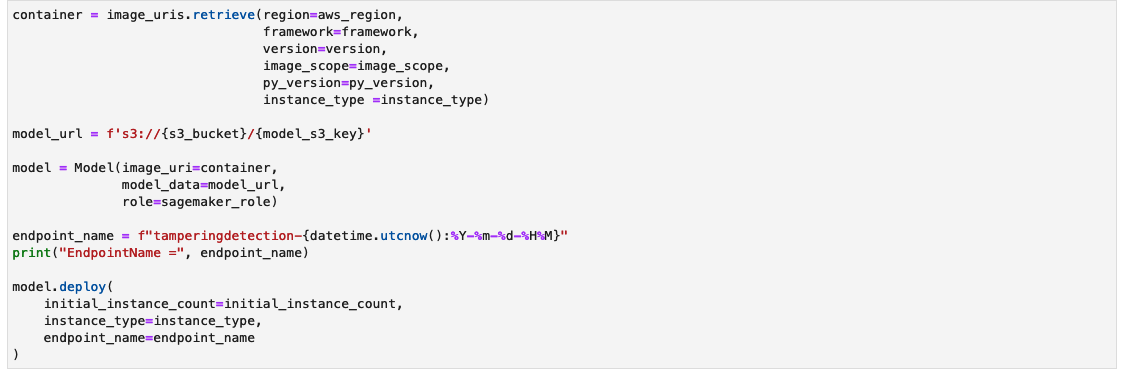
测试推理端点
该功能 check_image 将图像预处理为 ELA 图像,将其发送到 SageMaker 端点进行推理,检索和处理模型的预测,然后打印结果。该模型将输入图像的 NumPy 数组作为 ELA 图像来提供预测。预测输出为 0(表示未篡改的图像)和 1(表示伪造的图像)。

让我们使用未经篡改的工资单图像调用模型并检查结果。

模型输出分类为 0,表示未篡改的图像。
现在,让我们使用被篡改的工资单图像调用模型并检查结果。

模型输出分类为 1,代表伪造图像。
限制
尽管 ELA 是帮助检测修改的出色工具,但也存在许多限制,例如:
- 单个像素更改或较小的颜色调整可能不会在 ELA 中产生明显的变化,因为 JPEG 在网格上运行。
- ELA仅识别哪些区域具有不同的压缩级别。如果将较低质量的图像拼接成较高质量的图片,则较低质量的图像可能会显示为较暗的区域。
- 缩放、重新着色或向图像添加噪声都会修改整个图像,从而可能产生更高的错误级别。
- 如果图像被重新保存多次,那么它可能完全处于最小错误级别,其中更多的重新保存不会改变图像。在这种情况下,ELA 将返回黑色图像,并且使用该算法无法识别任何修改。
- 使用 Photoshop,保存图片这一简单操作就可以自动锐化纹理和边缘,从而可能产生更高的错误级别。此工件无法识别故意修改;它表明使用了 Adobe 产品。从技术上讲,ELA 显示为修改,因为 Adobe 自动执行了修改,但修改不一定是用户有意的。
我们建议将 ELA 与博客中之前讨论的其他技术一起使用,以便检测更大范围的图像处理案例。 ELA 还可以作为视觉检查图像差异的独立工具,特别是当训练基于 CNN 的模型变得具有挑战性时。
清理
要删除您在此解决方案中创建的资源,请完成以下步骤:
- 在下面运行笔记本单元 净化 部分。这将删除以下内容:
- SageMaker 推理端点 – 推理端点名称将为
tamperingdetection-<datetime>. - S3 存储桶内的对象和 S3 存储桶本身 – 存储桶名称将为
tamperingdetection<datetime>.
- SageMaker 推理端点 – 推理端点名称将为
- 关闭 SageMaker Studio 笔记本资源。
结论
在这篇文章中,我们提出了一种使用深度学习和 SageMaker 检测文档篡改和欺诈的端到端解决方案。我们使用 ELA 来预处理图像并识别可能表明存在操纵的压缩级别差异。然后,我们在这个处理后的数据集上训练 CNN 模型,将图像分类为原始图像或篡改图像。
该模型可以实现强大的性能,准确率超过 95%,数据集(伪造和原始)适合您的业务需求。这表明它可以可靠地检测伪造的文件,例如工资单和银行对账单。经过训练的模型被部署到 SageMaker 端点,以实现大规模低延迟推理。通过将该解决方案集成到抵押贷款工作流程中,机构可以自动标记可疑文件以进行进一步的欺诈调查。
虽然 ELA 功能强大,但在识别某些类型的更微妙的操纵方面存在一些局限性。下一步,可以通过将额外的取证技术纳入训练并使用更大、更多样化的数据集来增强模型。总体而言,该解决方案演示了如何使用深度学习和 AWS 服务来构建有影响力的解决方案,从而提高效率、降低风险并防止欺诈。
在第 3 部分中,我们演示如何在 Amazon Fraud Detector 上实施该解决方案。
关于作者
 阿努普·拉文德拉纳特 是位于加拿大多伦多的 Amazon Web Services (AWS) 的高级解决方案架构师,与金融服务组织合作。 他帮助客户实现业务转型并在云上进行创新。
阿努普·拉文德拉纳特 是位于加拿大多伦多的 Amazon Web Services (AWS) 的高级解决方案架构师,与金融服务组织合作。 他帮助客户实现业务转型并在云上进行创新。
 维尼塞尼 是位于加拿大多伦多的 Amazon Web Services (AWS) 的高级解决方案架构师。 她一直在帮助金融服务客户在云上转型,将 AI 和 ML 驱动的解决方案建立在卓越架构的强大基础支柱之上。
维尼塞尼 是位于加拿大多伦多的 Amazon Web Services (AWS) 的高级解决方案架构师。 她一直在帮助金融服务客户在云上转型,将 AI 和 ML 驱动的解决方案建立在卓越架构的强大基础支柱之上。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/
- :具有
- :是
- :不是
- :在哪里
- $UP
- 056
- 1
- 100
- 13
- 195
- 258
- 408
- 75
- 8
- 95%
- a
- 对,能力--
- 关于
- ACCESS
- 无障碍
- 账号管理
- 准确
- 横过
- 法案
- 行动
- 活化
- 实际
- 添加
- 添加
- 额外
- 添加
- 调整
- 调整
- 土砖
- 后
- 驳
- AI
- 瞄准
- 算法
- 对准
- 所有类型
- 让
- 允许
- 几乎
- 沿
- 靠
- 还
- 改变
- Amazon
- 亚马逊欺诈检测器
- 亚马逊SageMaker
- 亚马逊SageMaker Studio
- 亚马逊网络服务
- 亚马逊网络服务(AWS)
- 量
- an
- 分析
- 分析
- 分析
- 和
- 另一个
- 任何
- API
- 出现
- 出现
- 应用领域
- 应用的
- 的途径
- 约
- 建筑的
- 架构
- 档案
- 保健
- 国家 / 地区
- 地区
- 排列
- AS
- 假设
- At
- 自动化
- 自动
- 可用性
- 可使用
- AWS
- 银行
- 基于
- 篮球
- BE
- 因为
- 成为
- 很
- 最佳
- 更好
- 之间
- 黑色
- 博客
- 促进
- 光明
- 建立
- 建筑物
- 商业
- 商业应用
- 企业
- 但是
- by
- 计算
- 被称为
- 相机
- CAN
- 加拿大
- 捕获
- 案件
- 例
- 摔角
- 细胞
- 细胞
- 一定
- 挑战
- 更改
- 更改
- 通道
- 特点
- 查
- 类
- 分类
- 分类
- 明确地
- 云端技术
- 美国有线电视新闻网
- 码
- 颜色
- 列
- 组合
- 比较
- 相比
- 对照
- 完成
- 完全
- 复杂
- 元件
- 一台
- 计算机视觉
- 配置
- 混乱
- 结合
- 已联繫
- 大量
- 一贯
- 由
- 安慰
- 建设
- 包含
- 兑换
- 转换
- 卷积神经网络
- 正确
- 价格
- 可以
- 中央处理器
- 创建信息图
- 创建
- 创造
- 创建
- 电流
- 曲线
- 习俗
- 合作伙伴
- 暗
- data
- 数据科学
- 数据集
- 日期
- 减少
- 深
- 深入学习
- 默认
- 演示
- 演示
- 表示
- 密
- 依赖
- 依赖的
- 根据
- 部署
- 部署
- 部署
- 部署
- 细节
- 详情
- 检测
- 检测
- 确定
- 开发
- 图表
- 差异
- 差异
- 不同
- 数字
- 直接
- 讨论
- 讨论
- 显示器
- 区别
- 不同
- do
- 文件
- 文件
- 不会
- 域
- 画
- 驱动
- ,我们将参加
- 每
- 容易
- 边缘
- 有效
- 效率
- 强调
- 雇用
- enable
- 使
- 端至端
- 端点
- 增强
- 增强
- 更多
- 整个
- 完全
- 环境
- 时代
- 错误
- 故障
- 特别
- 醚(ETH)
- 甚至
- 所有的
- 检查
- 例子
- 追求卓越
- 优秀
- 展览
- 展览中
- 膨胀
- 预期
- 专门知识
- 延期
- 眼
- 促进
- 因素
- 少数
- 部分
- 文件
- 过滤器
- 金融
- 金融服务
- 找到最适合您的地方
- 姓氏:
- 固定
- 平面
- 遵循
- 其次
- 以下
- 针对
- 法医
- 取证
- 伪造的
- 格式
- 发现
- 基金会
- 基础的
- 四
- 骗局
- 止
- 充分
- 功能
- 进一步
- 通常
- 生成
- 产生
- 发电
- GIF
- 混帐
- 非常好
- GPU
- 更大的
- 格
- 指导
- 民政事务总署
- 处理
- 硬
- 硬件
- 有
- 有
- he
- 帮助
- 帮助
- 帮助
- 更高
- 近期亮点
- 亮点
- 击中
- 主持人
- 托管
- 小时
- 创新中心
- How To
- 但是
- HTML
- HTTP
- HTTPS
- IAM
- 确定
- 识别
- 鉴定
- 确定
- 身分
- IEEE
- if
- 忽略
- 说明
- 图片
- 图片
- 有影响力的
- 实施
- 重要
- 提高
- 改善
- in
- 包括
- 包含
- 不一致
- 结合
- 增加
- 增加
- 独立
- 独立地
- 表明
- 表示
- 个人
- 信息
- 初始
- 开始
- 创新
- 输入
- 例
- 实例
- 机构
- 集成
- 集成
- 整合
- 故意
- 成
- 介绍
- 推出
- 调查
- 涉及
- 问题
- IT
- 迭代
- 它的
- 本身
- JPG
- 保持
- 凯拉斯
- 知道
- 已知
- 标签
- 缺乏
- 大
- 大
- 后来
- 发射
- 层
- 层
- 信息
- 学习用品
- 学习
- 减
- Level
- 各级
- 轻巧
- 喜欢
- 可能性
- 容易
- 极限
- 限制
- 线性
- 线
- 清单
- 本地化
- 看
- 离
- 降低
- 机
- 机器学习
- 制成
- 主要
- 使
- 制作
- 制作
- 管理
- 颠覆性技术
- 操作
- 许多
- 匹配
- 矩阵
- 最多
- 可能..
- 手段
- 措施
- 中等
- 满足
- 方法
- 方法
- 最小
- 最低限度
- 未成年人
- 分钟
- ML
- 多播
- 模型
- 修改
- 改性
- 修改
- 更多
- 抵押
- 最先进的
- 多
- 姓名
- 命名
- 一定
- 需求
- 打印车票
- 负
- 网络
- 网络
- 神经
- 神经网络
- 虽然
- 下页
- 没有
- 噪声
- 注意
- 笔记本
- 数
- 麻木
- 目标
- 明显
- of
- 经常
- on
- 一
- 仅由
- 运营
- 操作
- 优化
- or
- 秩序
- 组织
- 原版的
- 本来
- 其他名称
- 除此以外
- 我们的
- 结果
- 产量
- 输出
- 超过
- 最划算
- 参数
- 参数
- 部分
- 特别
- 部分
- 径
- 模式
- 为
- 性能
- 执行
- 执行
- 施行
- 照片
- Photoshop中
- 图片
- 支柱
- 像素
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 情节
- 政策
- 一部分
- 积极
- 可能
- 帖子
- 潜力
- 潜力
- 强大
- 在练习上
- 预测
- 预测
- 预测
- Prepare
- 先决条件
- 当下
- 呈现
- 罐头
- 防止
- 先前
- 打印
- 过程
- 处理
- 过程
- 处理
- 产品
- 生产
- 级数
- 提供
- 提供
- 蟒蛇
- 质量
- 质疑
- 更快
- 随机
- 范围
- 快
- 率
- 比
- 真实的世界
- 实时的
- 境界
- 原因
- 接收
- 承认
- 建议
- 纠正的
- 减少
- 减少
- 减少
- 参考
- 地区
- 地区
- 复牌
- 依靠
- 切除
- 去掉
- 翻译
- 知识库
- 代表
- 代表
- 代表
- 要求
- 必须
- 岗位要求
- 需要
- 分辨率
- 资源
- REST的
- 受限
- 导致
- 成果
- 回报
- RGB
- 风险
- 角色
- 运行
- 运行
- sagemaker
- SageMaker 推理
- 同
- 样本数据集
- 保存
- 保存
- 保存
- 可扩展性
- 鳞片
- 缩放
- 情景
- 科学
- 无缝的
- 无缝
- 其次
- 部分
- 部分
- 选
- 选择
- 发送
- 前辈
- 系列
- 服务
- 无服务器
- 服务
- 特色服务
- 集
- 格局
- 她
- 转移
- 转移
- 应该
- 作品
- 签名
- 表示
- 迹象
- 类似
- 简易
- 简化
- 单
- 尺寸
- 小
- 光滑
- 方案,
- 解决方案
- 一些
- 东西
- 空间的
- 专门
- 具体的
- 特别是
- 指定
- 分裂
- Spot
- 广场
- 广场
- 开始
- 州/领地
- 声明
- 步
- 步骤
- 仍
- 存储
- 商店
- 步幅
- 强烈
- 工作室
- 后来
- 这样
- 提示
- 肯定
- 磁化面
- 易感
- 可疑
- 如飞
- 系统
- 量身定制
- 采取
- 需要
- 目标
- 技术上
- 技术
- 技术
- tensorflow
- 终端
- test
- 测试
- 比
- 这
- 国家
- 其
- 他们
- 然后
- 那里。
- 博曼
- 事
- Free Introduction
- 三
- 通过
- 次
- 时
- 至
- 工具
- 工具
- 多伦多
- 合计
- 感动
- 培训
- 熟练
- 产品培训
- 改造
- 转换
- true
- 尝试
- 二
- 类型
- 类型
- 一般
- 下
- 相关
- 保险业
- 独特
- 单元
- 更新
- 上
- USD
- 使用
- 用例
- 用过的
- 用户
- 使用
- 运用
- 验证
- 折扣值
- 价值观
- 变量
- 各个
- 版本
- 可见
- 愿景
- 参观
- 视觉
- 视觉
- 想
- 是
- we
- 卷筒纸
- Web服务
- 井
- 为
- 什么是
- ,尤其是
- 这
- 宽
- 将
- 中
- 也完全不需要
- 工作流程
- 工作流程
- 加工
- 合作
- 您
- 您一站式解决方案
- 和风网
- 零