介绍
在快速发展的生成人工智能领域,矢量数据库的关键作用变得越来越明显。本文深入探讨矢量数据库和生成式人工智能解决方案之间的动态协同作用,探讨这些技术基石如何塑造人工智能创造力的未来。与我们一起了解这个强大联盟的复杂性,深入了解矢量数据库为创新人工智能解决方案的前沿带来的变革性影响。
学习目标
本文将帮助您了解矢量数据库的以下各个方面。
- 矢量数据库及其关键组成部分的意义
- Vector数据库与传统数据库对比详解
- 从应用角度探索向量嵌入
- 使用 Pincone 构建矢量数据库
- 使用langchain LLM模型实现Pinecone Vector数据库
这篇文章是作为 数据科学博客马拉松。
目录
什么是矢量数据库?
矢量数据库是存储在空间中的数据集合的一种形式。尽管如此,在这里,它仍然以数学表示形式存储,因为存储在数据库中的格式使开放式人工智能模型更容易记住输入,并允许我们的开放式人工智能应用程序针对各种用例使用认知搜索、推荐和文本生成。数字化转型的行业。存储数据和检索称为“向量嵌入”或“嵌入”。此外,这是以数字数组格式表示的。搜索比用于人工智能视角的传统数据库要容易得多,具有大量的索引功能。
矢量数据库的特点
- 它利用这些向量嵌入的强大功能,从而可以在海量数据集中进行索引和搜索。
- 可压缩所有数据格式(图像、文本或数据)。
- 由于它采用嵌入技术和高度索引的功能,因此它可以提供用于管理给定问题的数据和输入的完整解决方案。
- 矢量数据库通过包含数百个维度的高维矢量来组织数据。我们可以非常快速地配置它们。
- 每个维度对应于它所代表的数据对象的特定特征或属性。
传统与。矢量数据库
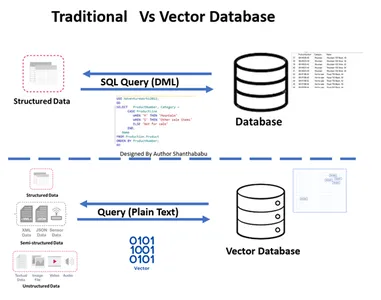
- 图为传统和矢量数据库高层工作流程
- 正式的数据库交互通过 SQL 以行基和表格格式存储的语句和数据。
- 在 Vector 数据库中,交互通过纯文本(例如英语)和以数学表示形式存储的数据进行。
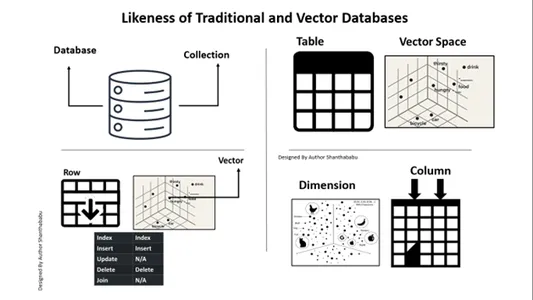
传统数据库和矢量数据库的相似之处
我们必须考虑 Vector 数据库与传统数据库有何不同。我们在这里讨论一下这个问题。我可以给出的一个快速区别是在传统数据库中。数据按原样精确存储;我们可以添加一些业务逻辑来调整数据,并根据业务需求或要求合并或拆分数据。然而,矢量数据库发生了巨大的转变,数据变成了复杂的矢量表示。
这是一张供您理解和清晰视角的地图 关系数据库 针对矢量数据库。下图对于理解向量数据库和传统数据库来说是不言自明的。简而言之,我们可以对向量数据库执行插入和删除,而不是更新语句。
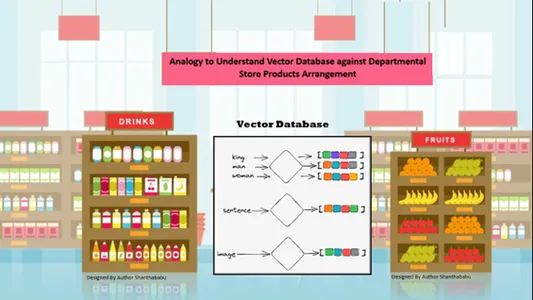
通过简单的类比来理解向量数据库
根据存储信息中的内容相似度自动在空间上排列数据。因此,让我们考虑用矢量数据库来类比百货商店;所有产品都根据性质、用途、制造、用途和数量基础排列在货架上。在类似的行为中,数据是
即使在存储或访问数据时没有明确定义流派,也会按类似的排序在矢量数据库中自动排列。
矢量数据库允许特定相似性具有显着的粒度和维度,因此客户可以搜索所需的产品、制造商和数量,并将该商品保留在购物车中。矢量数据库以完善的存储结构存储所有数据;在这里,机器学习和人工智能工程师不需要手动标记或标记存储的内容。
矢量数据库背后的基本理论
- 向量嵌入及其范围
- 索引要求
- 了解语义和相似性搜索
向量嵌入及其范围
向量嵌入是用数值表示的向量。以压缩格式,嵌入捕获原始数据的固有属性和关联,使它们成为人工智能和机器学习用例的主要内容。设计嵌入将原始数据的相关信息编码到低维空间中,确保高检索速度、计算效率和高效存储。
以更一致的结构方式捕获数据的本质是向量嵌入的过程,形成“嵌入模型”。最终,这些模型考虑所有数据对象,提取数据源中有意义的模式和关系,并将其转换为向量嵌入。随后,算法利用这些向量嵌入来执行各种任务。许多高度发达的嵌入模型可以免费或按需付费在线提供,有助于实现矢量嵌入。
从应用的角度来看向量嵌入的范围
这些嵌入结构紧凑,包含复杂的信息,继承矢量数据库中存储的数据之间的关系,实现高效的数据处理分析以促进理解和决策,并在任何组织中动态构建各种创新数据产品。
向量嵌入技术对于连接可读数据和复杂算法之间的差距至关重要。由于数据类型是数值向量,我们能够释放各种生成式 AI 应用程序以及可用的开放式 AI 模型的潜力。
向量嵌入的多项作业
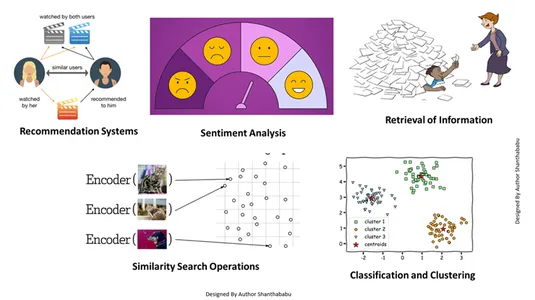
这种向量嵌入可以帮助我们完成多项工作:
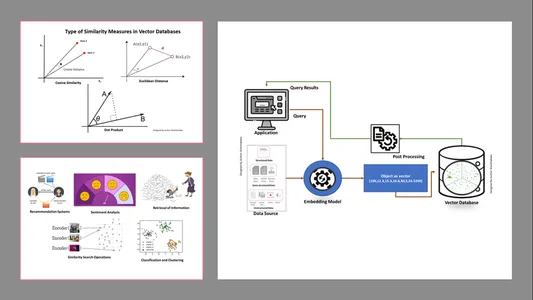
- 信息检索: 借助这些强大的技术,我们可以构建有影响力的搜索引擎,帮助我们根据存储的文件、文档或媒体中的用户查询找到响应
- 相似性搜索操作: 这是组织良好且索引良好的;它帮助我们找到矢量数据中不同事件之间的相似性。
- 分类和聚类: 使用这些嵌入技术,我们可以执行这些模型来训练相关的机器学习算法并对它们进行分组和分类。
- 推荐系统: 由于嵌入技术组织得当,因此推荐系统可以根据历史数据准确地关联产品、媒体和文章。
- 情绪分析: 这种嵌入模型帮助我们分类和导出情感解决方案。
索引要求
我们知道,索引将改进传统数据库中从表中搜索数据的方式,类似于矢量数据库,并提供索引功能。
向量数据库提供“平面索引”,它是向量嵌入的直接表示。搜索能力很全面,并且不使用预先训练的集群。它在每个单个向量嵌入上执行查询向量,并为每对计算 K 个距离。
- 由于该索引很简单,因此创建新索引所需的计算量最少。
- 事实上,平面索引可以有效地处理查询并提供快速的检索时间。
了解语义和相似性搜索
我们在向量数据库中执行两种不同的搜索:语义搜索和相似性搜索。
- 语义搜索: 在搜索信息时,您可以根据有意义的对话方法找到它们,而不是通过关键字搜索。及时的工程设计在将输入传递到系统方面发挥着至关重要的作用。这种搜索无疑可以提供更高质量的搜索和结果,可用于创新应用、搜索引擎优化、文本生成和摘要。
- 相似性搜索: 在数据分析中,相似性搜索始终允许非结构化、给定更好的数据集。对于向量数据库,我们必须确定两个向量的接近度以及它们之间的相似程度:表格、文本、文档、图像、单词和音频文件。在理解的过程中,向量之间的相似性被揭示为给定数据集中的数据对象之间的相似性。此练习有助于我们理解交互、识别模式、提取见解并从应用程序角度做出决策。语义和相似性搜索将帮助我们构建以下应用程序以实现行业利益。
- 信息检索: 使用开放人工智能和矢量数据库,我们将使用业务用户或最终用户的查询以及矢量数据库内的索引文档来构建用于信息检索的搜索引擎。
- 分类和聚类:对相似的数据点或对象组进行分类或聚类涉及根据共享特征将它们分配到多个类别。
- 异常检测: 通过测量数据点的相似性并发现不规则之处,发现常见模式中的异常情况。
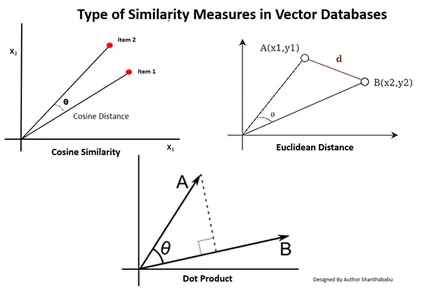
矢量数据库中相似性度量的类型
测量方法取决于数据的性质和具体应用。通常,使用三种方法来衡量机器学习的相似性和熟悉程度。
欧氏距离
简单来说,两个向量之间的距离就是测量st的两个向量点之间的直线距离。
点积
这有助于我们了解两个向量之间的对齐情况,指示它们是否指向相同方向、相反方向或彼此垂直。
余弦相似度
它通过使用两个向量之间的角度来评估两个向量的相似度,如图所示。在这种情况下,向量的值和大小是微不足道的,不会影响结果;计算中仅考虑角度。
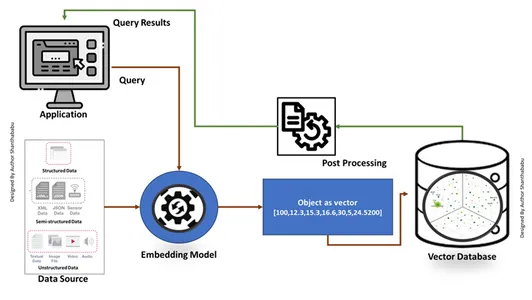
传统数据库 搜索精确的 SQL 语句匹配并以表格格式检索数据。同时,我们使用提示工程技术处理向量数据库,以简单英语搜索与输入查询最相似的向量。该数据库使用近似最近邻(ANN)搜索算法来查找相似数据。始终以高性能、准确性和响应时间提供相当准确的结果。
工作机制
- 向量数据库首先将数据转换为嵌入向量,将其存储在向量数据库中,并创建索引以加快搜索速度。
- 来自应用程序的查询将与嵌入向量交互,使用索引在向量数据库中搜索最近的邻居或类似数据,并检索传递给应用程序的结果。
- 根据业务需求,检索到的数据将被微调、格式化并显示给最终用户端或查询或操作提要。
创建矢量数据库
让我们与松果联系起来。
您可以使用 Google、GitHub 或 Microsoft ID 连接到 Pinecone。
创建一个新的用户登录供您使用。
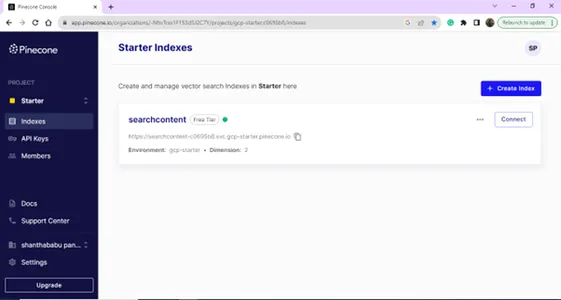
登录成功后,您将进入索引页面;您可以为矢量数据库创建索引。单击创建索引按钮。
通过提供名称和维度来创建新索引。
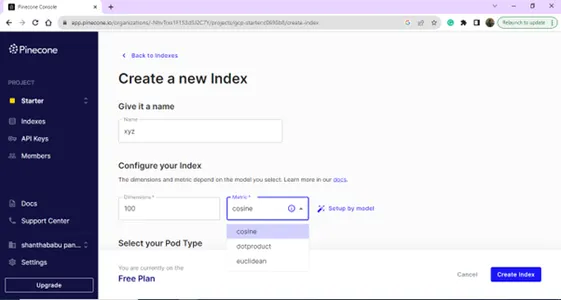
索引列表页,
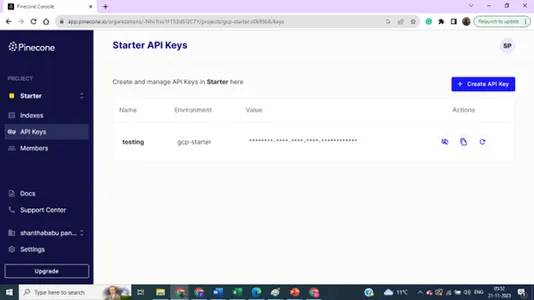
索引详细信息 - 名称、区域和环境 - 我们需要所有这些详细信息来从模型构建代码连接我们的矢量数据库。
项目设置详细信息,
您可以出于项目目的升级多个索引和键的首选项。
到目前为止,我们已经讨论了在 Pinecone 中创建矢量数据库索引和设置。
使用Python实现矢量数据库
现在让我们编写一些代码。
导入库
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAI为 OpenAI 和 Vector 数据库提供 API 密钥
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)启动LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)启动松果
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" 加载 .csv 文件以构建矢量数据库
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()将文本分割成块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)查找text_chunk中的文本
text_chunks输出
[文档(page_content ='名称:100%Brannmfr:Nntype:Cncalories:70n蛋白质:4nfat:1ns钠:130n纤维:10ncarbo:5ns糖:6npotass:280n维生素:25nshelf:3n重量:1ncups:0.33n评级:68.402973n推荐:孩子们的,元数据={ “来源”:“100%麸皮”,“行”:0}),,……
建筑嵌入
embeddings = OpenAIEmbeddings()从“data”为矢量数据库创建一个 Pinecone 实例
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")创建一个检索器来查询矢量数据库。
retriever = vectordb.as_retriever(score_threshold = 0.7)从矢量数据库检索数据
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocs使用提示并检索数据
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
我们来查询一下数据。
chain('Can you please provide cereal recommendation for Kids?')查询的输出
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]结论
希望您能够了解向量数据库的工作原理、它们的组件、架构以及生成人工智能解决方案中向量数据库的特征。了解矢量数据库与传统数据库有何不同以及与传统数据库元素的比较。事实上,这个类比可以帮助您更好地理解矢量数据库。 Pinecone矢量数据库和索引步骤将帮助您创建矢量数据库并为以下代码实现带来关键。
关键精华
- 可压缩结构化、非结构化和半结构化数据。
- 它采用嵌入技术和高度索引的特征。
- 交互通过使用提示(例如英语)的纯文本进行。以及以数学表示形式存储的数据。
- 矢量数据库中的相似度通过欧几里得距离、余弦相似度和点积进行校准。
常见问题
A.矢量数据库存储空间中的数据集合。它将数据保存为数学表示形式。因为数据库中存储的格式使开放式人工智能模型更容易记住之前的输入,并允许我们的开放式人工智能应用程序针对数字化转型行业中的各种用例使用认知搜索、建议和精确文本生成。
答:其中一些特征是: 1. 它利用了这些向量嵌入的强大功能,从而可以在海量数据集中进行索引和搜索。 2. 可压缩结构化、非结构化和半结构化数据。 3.向量数据库通过包含数百个维度的高维向量来组织数据
A. 数据库==>集合
表==>向量空间
行==>向量
栏==>维度
就像在传统数据库中一样,在 Vector 数据库中可以进行插入和删除。
更新和加入不在范围内。
– 快速检索海量数据采集的信息。
– 从大尺寸文档中进行语义和相似性搜索操作。
– 分类和聚类应用。
– 推荐和情感分析系统。
A5:以下是衡量相似度的三种方法:
– 欧几里得距离
– 余弦相似度
– 点积
本文中显示的媒体不属于 Analytics Vidhya 所有,其使用由作者自行决定。
相关
- :具有
- :是
- :不是
- $UP
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- Able
- 关于
- 访问
- 精准的
- 准确
- 横过
- 适应
- 加
- 影响
- AI
- AI模型
- 算法
- 算法
- 对准
- 所有类型
- 联盟
- 让
- 允许
- 沿
- 时刻
- 其中
- an
- 分析
- 分析
- 分析维迪亚
- 和
- 回答
- 任何
- API
- 明显的
- 应用领域
- 特定应用
- 应用领域
- 近似
- 架构
- 保健
- 安排
- 排列
- 刊文
- 刊文
- 人造的
- 人工智能
- 人工智能和机器学习
- AS
- 方面
- 评估
- 协会
- At
- 音频
- 自动
- 可使用
- 基于
- BE
- 成为
- 成为
- 行为
- 背后
- 作为
- 如下。
- 好处
- 更好
- 之间
- 博客马拉松
- 带来
- 建立
- 建筑物
- 商业
- 按键
- by
- 计算
- 计算
- 被称为
- CAN
- 能力
- 能力
- 捕获
- 案件
- 例
- 类别
- 链
- 链
- 特点
- 明晰
- 分类
- 分类
- 点击
- 集群
- 码
- 编码
- 认知
- 采集
- 常用
- 紧凑
- 比较
- 对照
- 完成
- 复杂
- 组件
- 全面
- 计算
- 计算
- 分享链接
- 连接
- 考虑
- 考虑
- 包含
- 内容
- 上下文
- 常规
- 谈话
- 兑换
- 对应
- 可以
- 创建信息图
- 创造
- 创造力
- 顾客
- data
- 数据分析
- 数据点
- 数据处理
- 数据库
- 数据库
- 数据集
- 处理
- 决策
- 决定
- 需求
- 漂移
- 设计
- 期望
- 详情
- 检测
- 发达
- 不同
- 差异
- 不同
- 数字
- 尺寸
- 尺寸
- 直接
- 方向
- 方向
- 发现
- 酌处权
- 讨论
- 讨论
- 显示
- 距离
- do
- 文件
- 不
- 不
- DOT
- 动态
- 动态
- e
- 每
- 缓解
- 更容易
- 只
- 效率
- 高效
- 或
- 分子
- 嵌入
- enable
- 结束
- 工程师
- 工程师
- 引擎
- 英语
- 确保
- 环境
- 本质
- 必要
- 醚(ETH)
- 甚至
- 演变
- 执行
- 锻炼
- 探索
- 提取
- 促进
- 熟悉
- 远
- 专栏
- 特征
- 美联储
- 数字
- 文件
- 档
- 找到最适合您的地方
- 姓氏:
- 平面
- 以下
- 针对
- 第一线
- 申请
- 格式
- Free
- 止
- 未来
- 差距
- 生成
- 代
- 生成的
- 生成式人工智能
- 类型
- GitHub上
- 给
- 特定
- 谷歌
- 团队
- 组的
- 处理
- 发生
- 有
- 帮助
- 帮助
- 相关信息
- 高
- 高水平
- 高度
- 历史的
- 创新中心
- 但是
- HTTPS
- 巨大
- 数百
- i
- ID
- 鉴定
- if
- 图片
- 影响力故事
- 履行
- 进口
- 改善
- in
- 日益
- 指数
- 索引
- 指标
- 说明
- 指数
- 行业
- 行业中的应用:
- 有影响
- 信息
- 固有
- 创新
- 输入
- 输入
- 刀片
- 内
- 可行的洞见
- 例
- 代替
- 房源搜索
- 相互作用
- 相互作用
- 互动
- 成
- 错综复杂
- 涉及
- IT
- 它的
- 工作机会
- 加入
- 来参加我们的
- 旅程
- 只是
- 键
- 键
- 关键词
- 孩子们
- 知道
- 标签
- 土地
- 景观
- 大
- 领导
- 信息
- 学习
- 杠杆作用
- 杠杆
- 喜欢
- 清单
- 装载机
- 逻辑
- 登录
- 机
- 机器学习
- 主要
- 使
- 制作
- 制作
- 管理的
- 方式
- 手动
- 生产厂家
- 地图
- 大规模
- 火柴
- 数学的
- 有意义的
- 衡量
- 措施
- 测量
- 机制
- 媒体
- 合并
- 研究方法
- 方法
- 微软
- 最小
- 模型
- 模型
- 更多
- 此外
- 最先进的
- 许多
- 多
- 必须
- 姓名
- 自然
- 需求
- 全新
- 现在
- 众多
- 对象
- 对象
- of
- 提供
- on
- 一
- 那些
- 在线
- 仅由
- 打开
- OpenAI
- 运营
- 相反
- or
- 组织
- 举办
- 举办
- 原版的
- OS
- 其他名称
- 我们的
- 拥有
- 页
- 对
- 部分
- 通过
- 通过
- 模式
- 演出
- 性能
- 执行
- 施行
- 透视
- 观点
- 图片
- 关键的
- 朴素
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 扮演
- 请
- 点
- 点
- 可能
- 潜力
- 功率
- 强大
- 实用
- 实际应用
- 精确的
- 恰恰
- 喜好
- 以前
- 市场问题
- 过程
- 产品
- 核心产品
- 项目
- 突出
- 提示
- 正确
- 财产
- 提供
- 优
- 规定
- 出版
- 泡芙
- 目的
- 目的
- 数量
- 查询
- 题
- 快速
- 更快
- 很快
- 急速
- 推荐
- 建议
- 关于
- 地区
- 关系
- 关系
- 相应
- 表示
- 代表
- 代表
- 必须
- 岗位要求
- 响应
- 回复
- 导致
- 成果
- 揭密
- 角色
- 行
- s
- 同
- 科学
- 范围
- 搜索
- 搜索引擎
- 搜索
- 搜索
- 情绪
- 搜索引擎优化
- 设置
- 形状
- 成型
- 共用的,
- 架
- 短
- 如图
- 作品
- 侧
- 类似
- 相似之处
- 简易
- 自
- 单
- 尺寸
- So
- 方案,
- 解决方案
- 一些
- 来源
- 太空
- 具体的
- 速度
- 分裂
- 斑点
- SQL
- 州/领地
- 个人陈述
- 声明
- 步骤
- 仍
- 存储
- 商店
- 存储
- 商店
- 结构体
- 结构化
- 学习
- 后来
- 成功
- 协同
- 系统
- 产品
- T
- 表
- 行李牌
- 任务
- 技术
- 技术性
- 条款
- 文本
- 文字产生
- 比
- 这
- 未来
- 其
- 他们
- 博曼
- 他们
- Free Introduction
- 三
- 通过
- 次
- 时
- 至
- 传统
- 培训
- 改造
- 转型
- 变革
- 转化
- 尝试
- 二
- 类型
- 最终
- 理解
- 理解
- 无疑
- 开锁
- 解锁
- 更新
- 升级
- us
- 用法
- 使用
- 用过的
- 用户
- 使用
- 运用
- 通常
- 价值观
- 各种
- 各个
- 非常
- 重要
- vs
- 是
- we
- 网页
- 定义明确
- 为
- 什么是
- 什么是
- 是否
- 这
- 而
- 将
- 中
- 话
- 工作
- 加工
- 将
- 您
- 您一站式解决方案
- 和风网