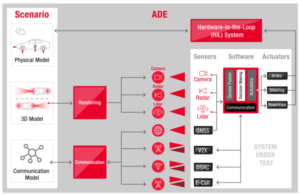
普渡大学的研究人员发表了一篇题为“WWW:内存计算的内容、时间、地点”的技术论文。
摘要:
“内存计算 (CiM) 已成为一种引人注目的解决方案,可降低冯·诺依曼机器中高昂的数据移动成本。 CiM 可以在内存中执行大规模并行通用矩阵乘法 (GEMM) 运算,这是机器学习 (ML) 推理中的主要计算。然而,重新利用内存进行计算提出了以下关键问题:1) 使用哪种类型的 CiM:鉴于有大量模拟和数字 CiM,需要从系统角度确定它们的适用性。 2) 何时使用 CiM:ML 推理包括具有各种内存和计算要求的工作负载,因此很难确定 CiM 何时比标准处理核心更有利。 3) 在何处集成 CiM:每个内存级别都有不同的带宽和容量,这会影响 CiM 集成的数据移动和局部性优势。
在本文中,我们探讨了有关用于 ML 推理加速的 CiM 集成的这些问题的答案。我们使用 Timeloop-Accelergy 对 CiM 原型进行早期系统级评估,包括模拟和数字基元。我们将 CiM 集成到类似 Nvidia A100 的基准架构中的不同缓存级别,并为各种 ML 工作负载定制数据流。我们的实验表明,CiM 架构提高了能源效率,与 INT-0.12 精度的既定基线相比,能耗降低了 8 倍,并且通过权重交错和复制实现了 4 倍的性能提升。拟议的工作提供了有关使用哪种类型的 CiM,以及何时何地将其最佳地集成到缓存层次结构中以实现 GEMM 加速的见解。”
找出 技术论文在这里。 2023 年 XNUMX 月出版(预印本)。
夏尔马、坦维、穆斯塔法·阿里、因德兰尼尔·查克拉博蒂和考希克·罗伊。 “WWW:什么、何时、何地进行内存计算。” arXiv 预印本 arXiv:2312.15896 (2023)。
相关阅读
通过内存计算提高人工智能能源效率
如何处理 zettascale 工作负载并保持在固定的功耗预算内。
具有生物效率的内存计算建模
生成式人工智能迫使芯片制造商更智能地使用计算资源。
AI 中的 SRAM:存储器的未来
为什么 SRAM 被视为新型和传统计算架构中的关键元素。
- :具有
- :是
- :在哪里
- $UP
- 1
- 2023
- a
- 促进
- 实现
- AI
- 缓和
- an
- 和
- 答案
- 架构
- AS
- At
- 带宽
- 底线
- 有利
- 好处
- 都
- 预算
- by
- 缓存
- CAN
- 容量
- 引人注目
- 计算
- 计算
- 成本
- 危急
- data
- 十二月
- 确定
- 不同
- 难
- 数字
- 优势
- 每
- 早
- 效率
- element
- 出现
- 能源
- 能源效率
- 成熟
- 评估
- 实验
- 探索
- 固定
- 针对
- 部队
- 止
- 未来
- 收益
- 其他咨询
- 特定
- 此处
- 等级制度
- 高
- 但是
- HTTPS
- 鉴定
- 改善
- in
- 包括
- 包含
- 可行的洞见
- 整合
- 积分
- 成
- IT
- JPG
- 键
- 学习
- Level
- 各级
- 降低
- 机
- 机器学习
- 机
- 制作
- 大规模
- 矩阵
- 内存
- ML
- 更多
- 运动
- 多数
- 打印车票
- 全新
- Nvidia公司
- of
- on
- 打开
- 运营
- 我们的
- 纸类
- 并行
- 演出
- 性能
- 透视
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 构成
- 功率
- 平台精度
- 过程
- 处理
- 建议
- 原型
- 提供
- 出版
- 有疑问吗?
- 关于
- 岗位要求
- 研究人员
- 资源
- 罗伊
- 显示
- 方案,
- 标准
- 留
- 适应性
- 产品
- 文案
- 比
- 这
- 未来
- 其
- 博曼
- Free Introduction
- 标题
- 至
- 传统
- 类型
- 大学
- 使用
- 各种
- 各个
- 查看
- 的
- 是
- we
- 重量
- 什么是
- ,尤其是
- 中
- 工作
- 和风网