随着人工智能从云端迁移到边缘,我们看到该技术被用于不断扩大的各种用例中——从异常检测到智能购物、监控、机器人和工厂自动化等应用。 因此,不存在一刀切的解决方案。 但随着支持摄像头的设备的快速增长,人工智能已被最广泛地应用于分析实时视频数据,以实现视频监控自动化,从而增强安全性、提高运营效率并提供更好的客户体验,最终在行业中获得竞争优势。 为了更好地支持视频分析,您必须了解边缘人工智能部署中优化系统性能的策略。
- 选择大小合适的计算引擎以满足或超过所需的性能水平。 对于人工智能应用程序,这些计算引擎必须执行整个视觉管道的功能(即视频预处理和后处理、神经网络推理)。
可能需要专用的 AI 加速器,无论是分立的还是集成到 SoC 中(而不是在 CPU 或 GPU 上运行 AI 推理)。
- 理解吞吐量和延迟之间的区别; 其中吞吐量是数据在系统中处理的速率,延迟衡量通过系统的数据处理延迟,并且通常与实时响应性相关。 例如,系统可以每秒 100 帧(吞吐量)生成图像数据,但图像通过系统需要 100 毫秒(延迟)。
- 考虑未来轻松扩展人工智能性能的能力,以适应不断增长的需求、不断变化的需求和不断发展的技术(例如,更先进的人工智能模型以提高功能和准确性)。 您可以使用模块格式的 AI 加速器或附加的 AI 加速器芯片来实现性能扩展。
实际性能要求取决于应用。 通常,对于视频分析,系统必须以每秒 30-60 帧的速度处理来自摄像机的数据流,分辨率为 1080p 或 4k。 支持人工智能的相机将处理单个流; 边缘设备将并行处理多个流。 无论哪种情况,边缘 AI 系统都必须支持预处理功能,将相机的传感器数据转换为符合 AI 推理部分输入要求的格式(图 1)。
预处理功能接收原始数据并执行调整大小、标准化和色彩空间转换等任务,然后将输入输入到人工智能加速器上运行的模型中。 预处理可以使用OpenCV等高效的图像处理库来减少预处理时间。 后处理涉及分析推理的输出。 它使用非极大值抑制(NMS 解释大多数对象检测模型的输出)和图像显示等任务来生成可操作的见解,例如边界框、类标签或置信度分数。

图 1. 对于 AI 模型推理,预处理和后处理功能通常在应用处理器上执行。
AI 模型推理可能面临每帧处理多个神经网络模型的额外挑战,具体取决于应用程序的功能。 计算机视觉应用通常涉及多个人工智能任务,需要多个模型的管道。 此外,一个模型的输出通常是下一个模型的输入。 换句话说,应用程序中的模型通常相互依赖,并且必须按顺序执行。 要执行的确切模型集可能不是静态的,并且可能动态变化,甚至逐帧变化。
动态运行多个模型的挑战需要外部人工智能加速器,具有专用且足够大的内存来存储模型。 由于共享内存子系统和 SoC 中其他资源的限制,SoC 内的集成 AI 加速器通常无法管理多模型工作负载。
例如,基于运动预测的对象跟踪依赖于连续检测来确定用于识别未来位置处的被跟踪对象的矢量。 这种方法的有效性是有限的,因为它缺乏真正的重新识别能力。 通过运动预测,对象的轨迹可能会由于错过检测、遮挡或对象离开视野(即使是暂时的)而丢失。 一旦丢失,就无法重新关联对象的轨迹。 添加重新识别可以解决此限制,但需要视觉外观嵌入(即图像指纹)。 外观嵌入需要第二个网络通过处理第一个网络检测到的对象的边界框内包含的图像来生成特征向量。 这种嵌入可以用来再次重新识别对象,无论时间或空间如何。 由于必须为视野中检测到的每个对象生成嵌入,因此处理要求随着场景变得更加繁忙而增加。 具有重新识别功能的对象跟踪需要仔细考虑执行高精度/高分辨率/高帧率检测和为嵌入可扩展性保留足够的开销。 解决处理需求的一种方法是使用专用的人工智能加速器。 如前所述,SoC 的 AI 引擎可能会因缺乏共享内存资源而受到影响。 模型优化也可用于降低处理要求,但它可能会影响性能和/或准确性。
在智能相机或边缘设备中,集成 SoC(即主机处理器)获取视频帧并执行我们之前描述的预处理步骤。 这些功能可以通过SoC的CPU核心或GPU(如果有的话)来执行,但它们也可以通过SoC中的专用硬件加速器(例如,图像信号处理器)来执行。 完成这些预处理步骤后,集成到 SoC 中的 AI 加速器可以直接从系统内存访问该量化输入,或者在离散 AI 加速器的情况下,通常通过以下方式传递输入以进行推理: USB 或 PCIe 接口。
集成 SoC 可以包含一系列计算单元,包括 CPU、GPU、AI 加速器、视觉处理器、视频编码器/解码器、图像信号处理器 (ISP) 等。 这些计算单元都共享相同的内存总线,因此访问相同的内存。 此外,CPU 和 GPU 可能还必须在推理中发挥作用,并且这些单元将忙于在已部署的系统中运行其他任务。 这就是我们所说的系统级开销(图 2)。
许多开发人员错误地评估了SoC中内置AI加速器的性能,而没有考虑系统级开销对总体性能的影响。 例如,考虑在 SoC 中集成的 50 TOPS AI 加速器上运行 YOLO 基准测试,可能会获得每秒 100 次推理 (IPS) 的基准测试结果。 但在所有其他计算单元都处于活动状态的已部署系统中,假设利用率高达 50%,那么这 12 TOPS 可能会减少到 25 TOPS 左右,并且整体性能只会产生 25 IPS。 如果平台连续处理视频流,系统开销始终是一个因素。 或者,使用独立的 AI 加速器(例如 Kinara Ara-1、Hailo-8、Intel Myriad X),系统级利用率可能大于 90%,因为一旦主机 SoC 启动推理功能并传输 AI 模型的输入数据时,加速器利用其专用内存自主运行来访问模型权重和参数。
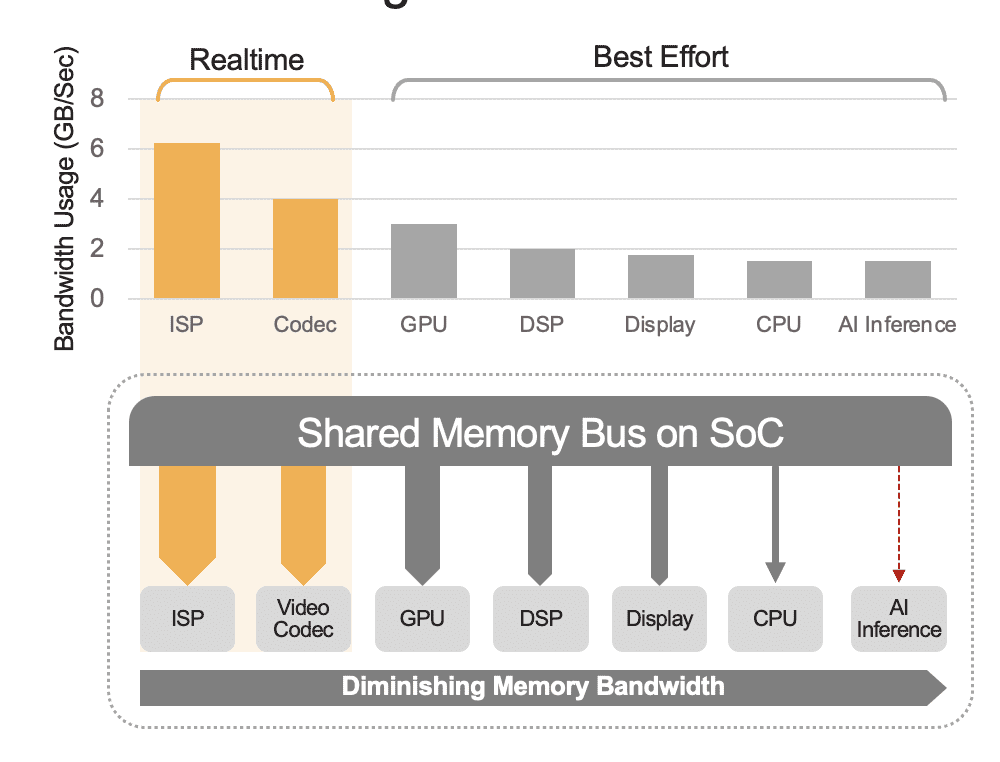
图 2. 共享内存总线将控制系统级性能,此处显示了估计值。 实际值将根据您的应用程序使用模型和 SoC 的计算单元配置而有所不同。
到目前为止,我们已经讨论了每秒帧数和 TOPS 方面的 AI 性能。 但低延迟是提供系统实时响应能力的另一个重要要求。 例如,在游戏中,低延迟对于无缝且响应灵敏的游戏体验至关重要,尤其是在运动控制游戏和虚拟现实 (VR) 系统中。 在自动驾驶系统中,低延迟对于实时物体检测、行人识别、车道检测和交通标志识别至关重要,以避免影响安全。 自动驾驶系统通常要求从检测到实际行动的端到端延迟小于150毫秒。 同样,在制造业中,低延迟对于实时缺陷检测、异常识别和机器人引导至关重要,它们依赖于低延迟视频分析来确保高效运行并最大限度地减少生产停机时间。
一般来说,视频分析应用程序中的延迟由三个部分组成(图 3):
- 数据捕获延迟是指从摄像头传感器捕获视频帧到该帧可供分析系统进行处理的时间。 您可以通过选择具有快速传感器和低延迟处理器的摄像机、选择最佳帧速率并使用高效的视频压缩格式来优化此延迟。
- 数据传输延迟是指捕获和压缩的视频数据从摄像机传输到边缘设备或本地服务器的时间。 这包括每个端点发生的网络处理延迟。
- 数据处理延迟是指边缘设备执行帧解压缩和分析算法(例如基于运动预测的对象跟踪、人脸识别)等视频处理任务的时间。 如前所述,对于必须为每个视频帧运行多个 AI 模型的应用程序来说,处理延迟更为重要。
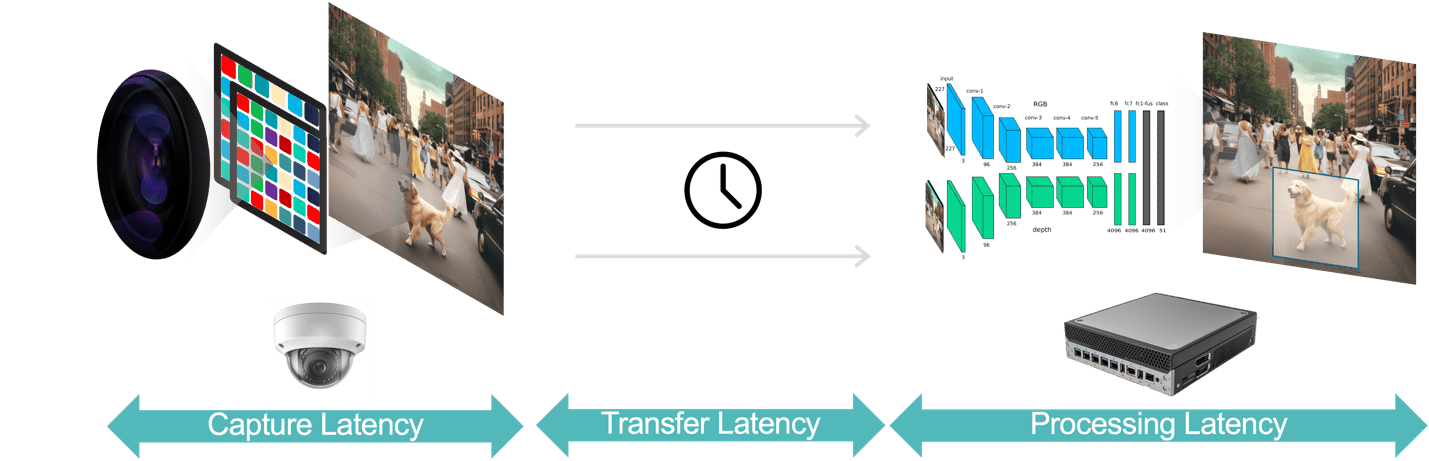
图 3.视频分析管道由数据捕获、数据传输和数据处理组成。
可以使用人工智能加速器来优化数据处理延迟,该加速器的架构旨在最大限度地减少芯片之间以及计算和内存层次结构各个级别之间的数据移动。 此外,为了提高延迟和系统级效率,架构必须支持模型之间的零(或接近零)切换时间,以更好地支持我们之前讨论的多模型应用程序。 提高性能和延迟的另一个因素与算法灵活性有关。 换句话说,某些架构仅针对特定人工智能模型的最佳行为而设计,但随着人工智能环境的快速变化,具有更高性能和更高准确性的新模型似乎每隔一天就会出现一次。 因此,选择对模型拓扑、算子和大小没有实际限制的边缘人工智能处理器。
在最大化边缘人工智能设备的性能时需要考虑许多因素,包括性能和延迟要求以及系统开销。 成功的策略应考虑使用外部 AI 加速器来克服 SoC AI 引擎中的内存和性能限制。
徐志诚 Chee 是一位卓有成就的产品营销和管理高管,在半导体行业推广产品和解决方案方面拥有丰富的经验,专注于面向包括企业和消费者在内的多个市场的基于视觉的人工智能、连接和视频接口。 作为一名企业家,Chee 与他人共同创立了两家视频半导体初创公司,并被一家上市半导体公司收购。 Chee 领导产品营销团队,并喜欢与专注于取得巨大成果的小团队合作。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :具有
- :是
- :不是
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- 对,能力--
- 加速器
- 加速器
- ACCESS
- 访问
- 容纳
- 完成
- 实现
- 后天
- 收购
- 横过
- 操作
- 要积极。
- 实际
- 添加
- 额外
- 采用
- 高级
- 后
- 再次
- AI
- 人工智能引擎
- AI模型
- 算法
- 算法
- 所有类型
- 还
- 时刻
- an
- 分析
- 分析
- 分析
- 和
- 异常检测
- 另一个
- 应用领域
- 应用领域
- 的途径
- 架构
- 保健
- AS
- 相关
- At
- 自动化
- 自动化和干细胞工程
- 自主性
- 自主
- 可用性
- 可使用
- 避免
- 基于
- 基础
- BE
- 因为
- 成为
- 很
- before
- 作为
- 基准
- 更好
- 之间
- 都
- 盒子
- 箱
- 内建的
- 总线
- 忙碌
- 但是
- by
- 相机
- 相机
- CAN
- 能力
- 能力
- 捕获
- 捕获
- 捕获
- 小心
- 案件
- 例
- 挑战
- 改变
- 芯片
- 碎屑
- 选择
- 程
- 云端技术
- 颜色
- 未来
- 公司
- 竞争的
- 完成
- 组件
- 折中
- 计算
- 计算
- 计算
- 一台
- 计算机视觉
- 计算机视觉应用
- 信心
- 配置
- 连接方式
- 所以
- 考虑
- 考虑
- 考虑
- 考虑
- 由
- 约束
- 消费者
- 包含
- 包含
- 连续
- 一直
- 转化
- 可以
- 中央处理器
- 危急
- 顾客
- data
- 数据处理
- 天
- 专用
- 延迟
- 延误
- 交付
- 提升
- 依赖的
- 根据
- 部署
- 部署
- 描述
- 设计
- 检测
- 检测
- 确定
- 开发
- 设备
- 差异
- 直接
- 讨论
- 屏 显:
- 停机
- 驾驶
- 两
- 动态
- e
- 每
- 此前
- 容易
- 边缘
- 效果
- 效用
- 效率
- 效率
- 高效
- 或
- 嵌入
- 结束
- 端至端
- 发动机
- 引擎
- 提高
- 确保
- 企业
- 整个
- 企业家
- 环境
- 必要
- 估计
- 评估
- 甚至
- 所有的
- 演变
- 例子
- 超过
- 执行
- 执行
- 执行
- 期望
- 体验
- 体验
- 广泛
- 丰富的经验
- 外部
- 面部彩妆
- 人脸识别
- 因素
- 因素
- 工厂
- 高效率
- 专栏
- 喂养
- 部分
- 数字
- 指纹
- (名字)
- 高度灵活
- 重点
- 聚焦
- 针对
- 格式
- FRAME
- 止
- 功能
- 功能
- 功能
- 此外
- 未来
- 获得
- Games
- 赌博
- 游戏体验
- 其他咨询
- 生成
- 产生
- 慷慨
- Go
- GPU
- 图形处理器
- 大
- 更大的
- 成长
- 事业发展
- 指导
- 硬件
- 有
- 于是
- 相关信息
- 等级制度
- 高
- 更高
- 主持人
- HTTPS
- i
- 鉴定
- if
- 图片
- 影响力故事
- 重要
- 征收
- 改善
- 改善
- in
- 其他
- 包括
- 包含
- 增加
- 增加
- 行业
- 行业中的应用:
- 同修
- 输入
- 内
- 可行的洞见
- 集成
- 英特尔
- 接口
- 接口
- 成
- 涉及
- 涉及
- 不管
- ISP
- IT
- 它的
- 掘金队
- 标签
- 缺乏
- 车道
- 大
- 潜伏
- 离开
- 导致
- 减
- 各级
- 库
- 喜欢
- 局限性
- 限制
- 有限
- 本地
- 丢失
- 低
- 降低
- 管理
- 颠覆性技术
- 制造业
- 许多
- 营销
- 市场
- 生产力
- 最大化
- 可能..
- 意味着
- 措施
- 满足
- 内存
- 提到
- 可能
- 错过
- 模型
- 模型
- 模块
- 监控
- 更多
- 最先进的
- 运动
- 运动
- 多
- 必须
- 无数的
- 近
- 需要
- 网络
- 神经
- 神经网络
- 全新
- 下页
- 没有
- 对象
- 物体检测
- 发生
- of
- 经常
- on
- 一旦
- 一
- 仅由
- OpenCV的
- 操作
- 操作
- 运营商
- 反对
- 最佳
- 优化
- 优化
- 优化
- 追求项目的积极优化
- or
- 其他名称
- 输出
- 产量
- 超过
- 最划算
- 克服
- 并行
- 参数
- 尤其
- 为
- 演出
- 性能
- 执行
- 执行
- 施行
- 管道
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 播放
- 点
- 位置
- 后处理
- 实用
- 预测
- 过程
- 处理
- 处理
- 处理器
- 处理器
- 产品
- 生产
- 核心产品
- 促进
- 提供
- 国家
- 范围
- 范围
- 快
- 急速
- 率
- 价格表
- 原
- 原始数据
- 真实
- 实时的
- 现实
- 承认
- 减少
- 指
- 要求
- 必须
- 需求
- 岗位要求
- 需要
- 分辨率
- 资源
- 响应
- 限制
- 导致
- 成果
- 机器人
- 角色
- 运行
- 运行
- 运行
- 实现安全
- 同
- 可扩展性
- 鳞片
- 规模艾
- 缩放
- 现场
- 分数
- 无缝的
- 其次
- 部分
- 看到
- 似乎
- 选择
- 半导体
- 集
- Share
- 共用的,
- 购物
- 应该
- 如图
- 签署
- 信号
- 同样
- 自
- 单
- 尺寸
- 小
- 智能
- 方案,
- 解决方案
- 解决
- 解决
- 一些
- 东西
- 太空
- 具体的
- 初创公司
- 步骤
- 商店
- 策略
- 策略
- 流
- 流
- 成功
- 这样
- 足够
- SUPPORT
- 抑制
- 监控
- 系统
- 产品
- 采取
- 需要
- 任务
- 团队
- 队
- 技术
- 专业技术
- 条款
- 比
- 这
- 未来
- 其
- 然后
- 那里。
- 因此
- 博曼
- 他们
- Free Introduction
- 那些
- 三
- 通过
- 吞吐量
- 次
- 时
- 至
- 上衣
- 合计
- 跟踪时
- 跟踪
- 交通
- 转让
- 转让
- 改造
- 旅行
- true
- 二
- 一般
- 最终
- 无法
- 理解
- 单元
- 单位
- 用法
- USB
- 使用
- 用过的
- 使用
- 运用
- 平时
- 利用
- 价值观
- 各种
- 各个
- 视频
- 查看
- 在线会议
- 虚拟现实
- 愿景
- 重要
- vr
- 方法..
- we
- 为
- 什么是
- 是否
- 这
- 广泛
- 将
- 也完全不需要
- 话
- 加工
- 将
- X
- 产量
- YOLO
- 您
- 您一站式解决方案
- 和风网
- 零