图片作者
数据科学项目有很多要素。 这个过程涉及到的人很多,过程中也面临很多挑战。 许多公司都看到了数据科学的需求,并且它已经在我们今天的生活中得到了应用。 然而,有些人却在如何利用数据分析以及使用哪种路径来实现这一目标方面遇到了困难。
The biggest assumption that companies make when using data science, is to imply that due to their use of programming language, it imitates the same methodology as software engineering. However, the models’ built-in data science and software are different.
数据科学需要其独特的生命周期和方法才能取得成功。
数据科学生命周期可以分为 7 个步骤。
业务理解
如果您为公司生产任何产品,您的第一个问题应该是“为什么?”。 为什么我们需要这样做? 为什么它对企业很重要? 为什么? 为什么? 为什么?
数据科学团队负责构建模型并根据业务需求进行数据分析。 在数据科学生命周期的这个阶段,数据科学团队和公司高管应该确定项目的中心目标,例如研究需要预测的变量。
这是基于什么样的数据科学项目? 它是回归或分类任务、聚类还是异常检测? 一旦您了解了对象的总体目标,您就可以继续询问原因、内容、地点、时间和方式! 提出正确的问题是一门艺术,将为数据科学团队提供项目的深入背景。
数据挖掘
一旦您了解了项目所需的所有业务,下一步将是通过收集数据来启动项目。 数据挖掘阶段包括从符合您的项目目标的各种来源收集数据。
在此阶段您将提出的问题是:该项目需要哪些数据? 我可以从哪里获取这些数据? 这些数据有助于实现我的目标吗? 我将在哪里存储这些数据?
数据清理
一些数据科学家选择将数据挖掘和数据清理阶段混合在一起。 但是,最好区分各个阶段以获得更好的工作流程。
Data cleaning is the most time-consuming phase in the data science workflow. The bigger your data, the longer it takes. It can typically take up to 50-80% of a data scientist’s time to complete. The reason it takes so long is because data is never clean. You can be dealing with data that has inconsistencies, missing data, incorrect labels, spelling mistakes, and more.
在执行任何分析工作之前,您需要更正这些错误,以确保您计划使用的数据正确并产生准确的输出。
数据探索
在花费大量时间和精力清理数据之后,您现在拥有可以使用的极其干净的数据。 数据探索时间! 此阶段是对总体项目目标进行集思广益。 您想要深入了解可以从数据中找到什么、隐藏的模式、创建可视化以找到进一步的见解等等。
有了这些信息,您将能够创建一个符合您的业务目标的假设,并将其用作参考点,以确保您完成任务。
特征工程
特征工程是从原始数据中开发和构建新的数据特征。 您获取原始数据并创建符合您的业务目标的信息功能。 特征工程阶段包括特征选择和特征构建。
特征选择是指减少特征的数量,这些特征会给数据带来更多的噪音,而不是实际有价值的信息。 拥有太多的特征可能会导致维数灾难,增加数据的复杂性,使模型无法轻松有效地学习。
功能构建就在名称中。 这是新功能的构建。 使用您当前拥有的功能,您可以创建新功能,例如,如果您的目标集中于高级会员,您可以为您想要的年龄创建阈值。
此阶段非常重要,因为它将影响预测模型的准确性。
预测建模
这就是乐趣的开始,您将看到是否已实现业务目标。 预测建模包括训练数据、测试数据以及使用综合统计方法来确保模型的结果对所创建的假设具有重要意义。
根据您在“业务理解”阶段提出的所有问题,您将能够确定哪种模型适合您手头的任务。 您选择的模型可能是一个反复试验的过程,但这对于确保您创建一个能够产生准确输出的成功模型非常重要。
构建模型后,您将需要在数据集上对其进行训练并评估其性能。 您可以使用不同的评估指标(例如 k 折交叉验证)来衡量准确性,并继续这样做,直到您对准确性值感到满意为止。
使用测试和验证数据测试您的模型可确保准确性并确保您的模型表现良好。 向数据提供未见过的数据是了解模型如何使用之前未训练过的数据执行操作的好方法。 它使您的模型发挥作用!
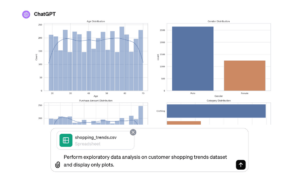
数据可视化
Once you are happy with your model’s performance, you are ready to go back and explain it all to the executives in the company. Creating data visualizations is a good way to explain your findings to people who are not technical, and is also a good way to tell a story about the data.
数据可视化是通信、统计和艺术的结合。 您可以通过多种方式以美观的方式呈现数据发现。 您可以使用诸如 Matplotlib 文档, Seaborn 教程及 情节图书馆。 如果您使用 Python,请阅读以下内容: 使用 Python Graph Gallery 制作惊人的可视化效果.
就像你处于生命周期的末尾一样,但请记住这是一个周期。 所以你必须回到起点:业务理解。 您将需要根据最初的业务理解和目标以及创建的假设来评估模型的成功。
现在我们已经经历了数据科学的生命周期,您一定认为这看起来很简单。 这只是一步接着一步。 但我们都知道事情并不是那么简单。 为了使其尽可能简单有效,需要制定管理方法。
Data science projects are not solely under the data scientists’ responsibility anymore – it is a team effort. Therefore, standardizing project management is imperative, and there are methods that you can use to ensure this. Let’s look into them.
瀑布方法论
就像瀑布一样,瀑布方法是一个连续的开发过程,贯穿项目的所有阶段。 每个阶段都需要完成才能开始下一阶段。 阶段之间没有重叠,因此不存在冲突,因此是一种有效的方法。 如果你必须重新审视之前的阶段,那就意味着团队计划得很糟糕。
它由五个阶段组成:
- 岗位要求
- 设计
- SAP系统集成计划实施
- 验证(测试)
- 维护(部署)
那么什么时候应该使用瀑布方法呢? 水流如水,一切都要清清楚楚。 这意味着目标已定义,团队对技术堆栈了如指掌,项目要素也已就位,以确保流程顺利有效。
但让我们回到现实。 数据科学项目是否像水一样容易流动? 不。它们需要大量的实验、需求变更等等。 但是,这并不意味着您不能使用瀑布方法的元素。 瀑布方法需要大量规划。 如果你计划好一切,是的,你可能仍然会遇到一两个问题,但过程中的挑战会更少,也不会那么严峻。
敏捷方法论
敏捷方法 诞生于 2001 年初,当时 17 个人聚集在一起讨论软件开发的未来。 它建立在 4 项核心价值观和 12 条原则的基础上。
The agile methodology is more in line with today’s technology, as it works in a fast-paced, ever-changing technology industry. If you are a tech professional, you know that the requirements in a data science or software project change all the time. Therefore, having the right method in place which allows you to quickly adapt to these changes is important.
The agile methodology is a perfect data science project management method as it allows the team to continuously review the requirements of the project as it grows. Executives and data science managers can make decisions about changes that need to be made during the development process, rather than at the end once it’s all complete.
随着模型不断发展以反映以用户为中心的输出,这已被证明是非常有效的,从而节省了时间、金钱和精力。
敏捷方法的一个例子是 争球。 Scrum 方法使用一个框架,该框架有助于使用一组价值观、原则和实践在团队中创建结构。 例如,使用 Scrum,数据科学项目可以将其较大的项目分解为一系列较小的项目。 这些小型项目中的每一个都将被称为冲刺,并包含冲刺计划,以定义目标、要求、责任等。
混合方法论
为什么不一起使用两种不同的方法呢? 这称为混合方法,其中使用两种或多种方法来创建对业务完全独特的方法。 公司可以对所有类型的项目使用混合方法,但是,其背后的原因取决于产品交付。
For example, if a customer requires a product but is not happy with the timeframe of production based on using sprints in an Agile method. So it seems like the company needs to do a bit more planning right? What method has a lot of planning? Yes, that’s right, Waterfall. The company can adopt waterfall into their method to cater specifically for the customer’s requirement.
Some companies may have mixed emotions about combining an agile method with a non-agile method such as Waterfall. These two methods can co-exist, however, it is the company’s responsibility to ensure a simple approach that makes sense, measure the success of the hybrid method, and provide productivity.
研究和开发
有些人可能认为这是一种方法论,但是,我相信这是数据科学项目过程的重要基础。 就像瀑布方法一样,计划和准备尽可能多的信息没有什么坏处。
但这不是我在这里谈论的。 是的,在开始一个项目之前研究一切是很棒的。 但确保有效项目管理的一个好方法是将您的项目视为研发项目。 它是数据科学团队协作的有效工具。
在运行和操作你的数据科学项目之前,你需要先走路,就像它是一篇研究论文一样。 一些数据科学项目的截止日期很严格,这使得这个过程变得困难,但是,匆忙完成最终产品总是会带来进一步的挑战。 您希望构建一个有效且成功的模型来满足您的初始数据科学生命周期阶段:业务理解。
数据科学项目的研究和开发为创新敞开了大门,增加了创造力,并且不限制团队接受可能更伟大的东西!
尽管有不同的方法可供选择,但最终还是取决于企业的运营。 有些方法在一家公司流行,但对于另一家公司来说可能不是最好的方法。
每个人可能有不同的工作方式,因此最好的方法是创建一种适合每个人的方法。
想要了解如何自动化数据科学工作流程,请阅读以下内容: 数据科学工作流程中的自动化.
妮莎·艾莉亚 是 KDnuggets 的数据科学家、自由技术作家和社区经理。 她对提供数据科学职业建议或教程以及围绕数据科学的理论知识特别感兴趣。 她还希望探索人工智能是/可以有益于人类长寿的不同方式。 一个敏锐的学习者,寻求拓宽她的技术知识和写作技巧,同时帮助指导他人。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 汽车/电动汽车, 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 块偏移量。 现代化环境抵消所有权。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/07/guide-data-science-project-management-methodologies.html?utm_source=rss&utm_medium=rss&utm_campaign=a-guide-to-data-science-project-management-methodologies
- :具有
- :是
- :不是
- :在哪里
- $UP
- 1
- 12
- 17
- 2001
- 7
- a
- Able
- 关于
- 精准的
- 横过
- 实际
- 适应
- 加
- 采用
- 忠告
- 后
- 年龄
- 敏捷
- 所有类型
- 允许
- 沿
- 还
- 时刻
- am
- 惊人
- an
- 分析
- 分析
- 和
- 异常检测
- 另一个
- 任何
- 再
- 什么
- 的途径
- 保健
- 围绕
- 艺术
- 人造的
- 人工智能
- AS
- 假设
- At
- 自动化
- 背部
- 基于
- BE
- 因为
- 很
- before
- 开始
- 背后
- 相信
- 得益
- 最佳
- 更好
- 之间
- 大
- 最大
- 位
- 混合
- 天生的
- 午休
- 扩大
- 破
- 建立
- 建筑物
- 建
- 内建的
- 商业
- 但是
- by
- 被称为
- 来了
- CAN
- 不能
- 寻找工作
- 迎合
- 中央
- 挑战
- 更改
- 更改
- 选择
- 分类
- 清洁
- 清除
- 集群
- 合作
- 组合
- 结合
- 如何
- 购买的订单均
- 沟通
- 社体的一部分
- 公司
- 公司
- 完成
- 完成
- 复杂
- 全面
- 集中
- 考虑
- 由
- 施工
- 上下文
- 继续
- 一直
- 核心
- 核心价值
- 正确
- 可以
- 创建信息图
- 创建
- 创造
- 创造力
- 目前
- 诅咒
- 顾客
- 切
- 周期
- data
- 数据分析
- 数据挖掘
- 数据科学
- 数据科学家
- 处理
- 决定
- 深
- 定义
- 交货
- 部署
- 检测
- 确定
- 研发支持
- 不同
- 难
- 讨论
- 区分
- do
- 不
- 门
- 向下
- 两
- ,我们将参加
- 每
- 早
- 容易
- 有效
- 只
- 努力
- 分子
- 情绪
- 结束
- 能源
- 工程师
- 确保
- 确保
- 完全
- 错误
- 故障
- 评估
- 评估
- 千变万化
- 每个人
- 一切
- 演变
- 例子
- 管理人员
- 说明
- 勘探
- 探索
- 面临
- 快节奏
- 专栏
- 特征
- 喂养
- 找到最适合您的地方
- 发现
- 五
- 流动
- 流动
- 针对
- 基金会
- 公司成立
- 骨架
- 自由职业者
- 止
- 履行
- 开玩笑
- 进一步
- 未来
- 搜集
- 得到
- Go
- 走了
- 非常好
- 图形
- 大
- 成长
- 指南
- 手
- 快乐
- 伤害
- 有
- 有
- 帮助
- 帮助
- 帮助
- 这里
- 相关信息
- 老旧房屋
- 高度
- 创新中心
- How To
- 但是
- HTML
- HTTPS
- 人
- 杂交种
- i
- 确定
- if
- 势在必行
- 实施
- 重要
- in
- 深入
- 包括
- 增加
- 增加
- 行业中的应用:
- 影响
- 信息
- 信息
- 初始
- 启动
- 創新
- 内
- 可行的洞见
- 房源搜索
- 有兴趣
- 成
- 参与
- IT
- 它的
- 只是
- 只有一个
- 掘金队
- 敏锐
- 保持
- 类
- 知道
- 知识
- 标签
- 语言
- 大
- 铅
- 学习用品
- 学习者
- 减
- 生活
- 生命周期
- 喜欢
- 极限
- Line
- 生活
- 长
- 不再
- 长寿
- 看
- 寻找
- 占地
- 制成
- 使
- 制作
- 制作
- 颠覆性技术
- 经理
- 经理
- 许多
- 很多人
- 可能..
- 意味着
- 手段
- 衡量
- 会见
- 成员
- 一半
- 方法
- 方法
- 研究方法
- 方法
- 指标
- 采矿
- 失踪
- 错误
- 杂
- 模型
- 造型
- 模型
- 钱
- 更多
- 最先进的
- 许多
- 必须
- my
- 姓名
- 需求
- 需要
- 决不要
- 全新
- 新功能
- 下页
- 没有
- 噪声
- 现在
- 数
- 数1
- 对象
- 目标
- 目标
- of
- on
- 一旦
- 一
- 打开
- 操作
- 运营
- or
- 秩序
- 原版的
- 其他名称
- 其它
- 我们的
- 输出
- 结果
- 最划算
- 纸类
- 尤其
- 径
- 模式
- 员工
- 性能
- 执行
- 施行
- 相
- 地方
- 计划
- 计划
- 规划行程
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 点
- 热门
- 可能
- 做法
- 都曾预测
- 准备
- 当下
- 以前
- 原则
- 问题
- 过程
- 生产
- 产生
- 生产
- 产品
- 生产
- 生产率
- 所以专业
- 代码编程
- 项目
- 项目管理
- 项目
- 提供
- 优
- 放
- 认沽期权
- 蟒蛇
- 题
- 有疑问吗?
- 很快
- 宁
- 原
- 原始数据
- 阅读
- 准备
- 现实
- 原因
- 反映
- 关于
- 回归
- 纪念
- 要求
- 需求
- 岗位要求
- 需要
- 研究
- 研究和开发
- 责任
- 责任
- 提供品牌战略规划
- 检讨
- 右
- 运行
- s
- 同
- 保存
- 科学
- 科学家
- 科学家
- 看到
- 寻求
- 似乎
- 选择
- 前辈
- 感
- 系列
- 集
- 解决
- 她
- 应该
- 如图
- 显著
- 简易
- 技能
- 小
- 光滑
- So
- 软件
- 软件开发
- 软件工程
- 独自
- 一些
- 东西
- 来源
- 特别是
- 拼字
- 花费
- 短跑
- 堆
- 实习
- 标准化
- 开始
- 启动
- 统计
- 统计
- 步
- 步骤
- 仍
- 商店
- 故事
- 简单的
- 结构体
- 奋斗
- 成功
- 成功
- 这样
- 采取
- 需要
- 说
- 任务
- 团队
- 科技
- 文案
- 专业技术
- 展示
- 测试
- 比
- 这
- 未来
- 其
- 他们
- 理论
- 那里。
- 因此
- 博曼
- 他们
- 事
- 思维
- Free Introduction
- 门槛
- 通过
- 至
- 次
- 耗时的
- 时间表
- 至
- 今晚
- 一起
- 也有
- 工具
- 工具
- 培训
- 熟练
- 产品培训
- 试用
- 反复试验
- 教程
- 二
- 类型
- 一般
- 最终
- 下
- 理解
- 理解
- 独特
- 使用
- 用过的
- 使用
- 运用
- 验证
- 有价值
- 有价值的信息
- 折扣值
- 价值观
- 各种
- 非常
- 可视化
- 想
- 是
- 水
- 方法..
- 方法
- we
- 井
- 什么是
- ,尤其是
- 这
- 虽然
- WHO
- 为什么
- 将
- 祝愿
- 工作
- 工作流程
- 加工
- 合作
- 作家
- 写作
- 含
- 您
- 您一站式解决方案
- 你自己
- 和风网