图片作者
深入研究数据科学和机器学习的世界,您将遇到的基本技能之一就是读取数据的艺术。如果您已经有一些经验,您可能熟悉 JSON(JavaScript 对象表示法)——一种用于存储和交换数据的流行格式。
想一想像 MongoDB 这样的 NoSQL 数据库如何喜欢以 JSON 格式存储数据,或者 REST API 通常如何以相同的格式进行响应。
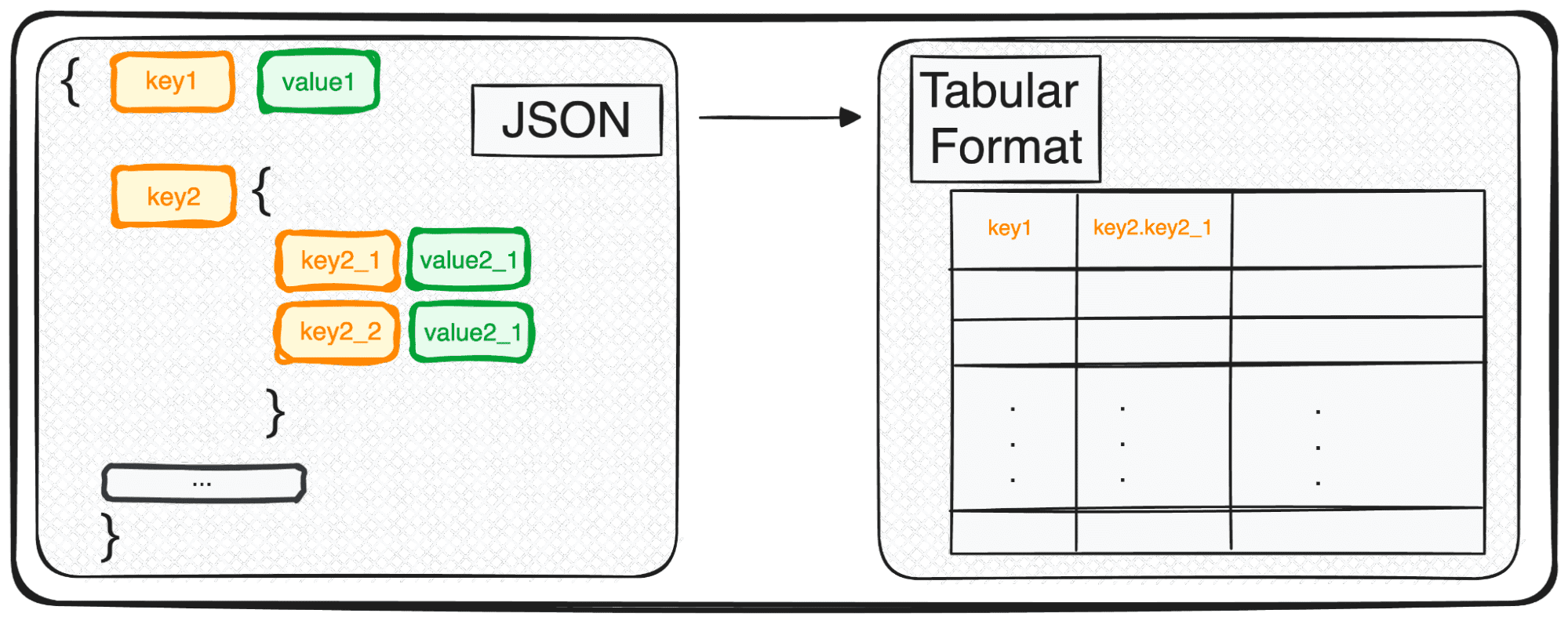
然而,JSON 虽然非常适合存储和交换,但还没有准备好对其原始形式进行深入分析。在这里,我们将其转换为更易于分析的形式——表格格式。
因此,无论您处理的是单个 JSON 对象还是一组令人愉快的对象,用 Python 的术语来说,您本质上是在处理一个字典或一个字典列表。
让我们一起探讨这种转变是如何展开的,使我们的数据适合分析???
今天我将解释一个神奇的命令,它允许我们在几秒钟内轻松地将任何 JSON 解析为表格格式。
这是……pd.json_normalize()
让我们看看它如何处理不同类型的 JSON。
我们可以使用的第一种 JSON 类型是具有一些键和值的单级 JSON。我们定义第一个简单的 JSON 如下:
作者代码
因此,让我们模拟使用这些 JSON 的需要。我们都知道 JSON 格式没什么可做的。我们需要将这些 JSON 转换为某种可读且可修改的格式……这意味着 Pandas DataFrame!
1.1 处理简单的 JSON 结构
首先,我们需要导入pandas库,然后我们可以使用命令pd.json_normalize(),如下:
import pandas as pd
pd.json_normalize(json_string)
通过将此命令应用于具有单个记录的 JSON,我们获得了最基本的表。但是,当我们的数据稍微复杂一点并呈现 JSON 列表时,我们仍然可以使用相同的命令而不会进一步复杂化,并且输出将对应于具有多条记录的表。

图片作者
容易……对吧?
下一个自然问题是当某些值丢失时会发生什么。
1.2 处理空值
想象一下某些值没有被告知,例如,大卫的收入记录丢失了。当将我们的 JSON 转换为简单的 pandas 数据帧时,相应的值将显示为 NaN。
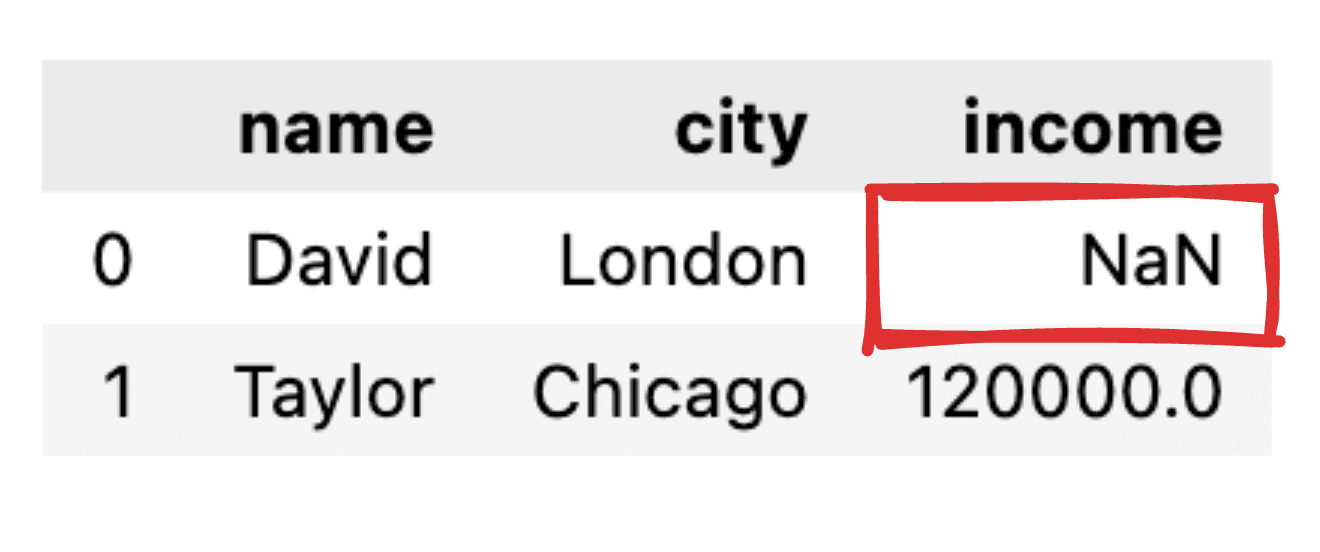
图片作者
如果我只想获取部分字段怎么办?
1.3 仅选择感兴趣的列
如果我们只想将某些特定字段转换为表格 pandas DataFrame,则 json_normalize() 命令不允许我们选择要转换的字段。
因此,应该对 JSON 进行少量预处理,仅过滤那些感兴趣的列。
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
那么,让我们转向一些更高级的 JSON 结构。
在处理多级 JSON 时,我们发现自己在不同级别内嵌套了 JSON。过程与之前相同,但在这种情况下,我们可以选择要变换的级别。默认情况下,该命令将始终展开所有级别并生成包含所有嵌套级别的串联名称的新列。
因此,如果我们标准化以下 JSON。
作者代码
我们将得到下表,其中字段技能下有 3 列:
- 技能.python
- SQL技能
- 技能.GCP
字段角色下有 4 列
- 角色.项目经理
- 角色.数据工程师
- 角色.数据科学家
- 角色.数据分析师

图片作者
然而,想象一下我们只是想改变我们的顶层。我们可以通过将参数 max_level 明确定义为 0(我们想要扩展的 max_level)来实现这一点。
pd.json_normalize(mutliple_level_json_list, max_level = 0)
待处理的值将在 pandas DataFrame 内的 JSON 中维护。
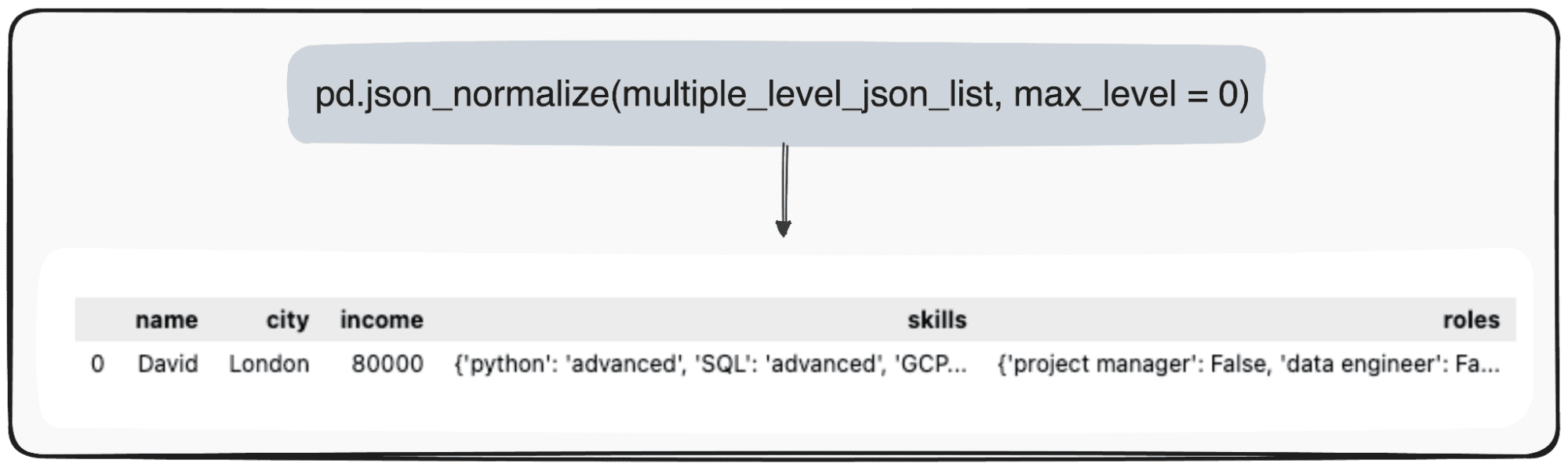
图片作者
我们可以找到的最后一种情况是在 JSON 字段中有一个嵌套列表。所以我们首先定义要使用的 JSON。
作者代码
我们可以使用 Python 中的 Pandas 有效地管理这些数据。 pd.json_normalize() 函数在这种情况下特别有用。它可以将 JSON 数据(包括嵌套列表)扁平化为适合分析的结构化格式。当此函数应用于我们的 JSON 数据时,它会生成一个规范化表,其中包含嵌套列表作为其字段的一部分。
此外,Pandas 还提供了进一步完善此流程的能力。通过利用 pd.json_normalize() 中的 record_path 参数,我们可以指示该函数专门规范化嵌套列表。
此操作会生成一个专门用于列表内容的专用表。默认情况下,此过程只会展开列表中的元素。然而,为了用额外的上下文来丰富该表,例如为每条记录保留关联的 ID,我们可以使用元参数。

图片作者
总之,使用 Python 的 Pandas 库将 JSON 数据转换为 CSV 文件既简单又有效。
JSON 仍然是现代数据存储和交换中最常见的格式,特别是在 NoSQL 数据库和 REST API 中。然而,在处理原始格式的数据时,它提出了一些重要的分析挑战。
Pandas 的 pd.json_normalize() 的关键作用是处理此类格式并将数据转换为 pandas DataFrame 的好方法。
我希望本指南有用,并且下次您处理 JSON 时,可以以更有效的方式进行操作。
你可以去查看对应的Jupyter Notebook 以下 GitHub 存储库。
约瑟夫·费雷尔 是来自巴塞罗那的分析工程师。 他毕业于物理工程专业,目前从事应用于人类移动的数据科学领域。 他是一名专注于数据科学和技术的兼职内容创作者。 你可以联系他 LinkedIn, Twitter or 中.
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :是
- :不是
- :在哪里
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- 关于
- 操作
- 额外
- 高级
- 所有类型
- 让
- 允许
- 已经
- 时刻
- an
- 分析
- 分析人士
- 解析
- 分析
- 和
- 任何
- APIs
- 出现
- 应用的
- 应用
- 保健
- 排列
- 艺术
- AS
- 相关
- 巴塞罗那
- 基本包
- BE
- before
- 位
- 都
- 但是
- by
- CAN
- 能力
- 案件
- 挑战
- 查
- 城市
- 列
- 相当常见
- 复杂
- 并发症
- CONTACT
- 内容
- Contents
- 上下文
- 兑换
- 转换
- 对应
- 相应
- 创造者
- 目前
- data
- 数据分析师
- 数据工程师
- 数据科学
- 数据科学家
- 数据存储
- 数据库
- David
- 处理
- 专用
- 默认
- 定义
- 定义
- 愉快
- 信息通信技术部
- 不同
- 直接
- do
- 不
- 每
- 容易
- 易
- 有效
- 只
- 分子
- 出现
- 遭遇
- 工程师
- 工程师
- 丰富
- 本质上
- 交换
- 交换
- 只
- 扩大
- 体验
- 说明
- 探索
- 熟悉
- 少数
- 部分
- 字段
- 档
- 过滤
- 找到最适合您的地方
- 姓氏:
- 重点
- 以下
- 如下
- 针对
- 申请
- 格式
- 友好
- 止
- 功能
- 根本
- 进一步
- GCP
- 生成
- 得到
- GitHub上
- Go
- 大
- 指南
- 处理
- 处理
- 发生
- 有
- 有
- he
- 他
- 抱有希望
- 创新中心
- 但是
- HTTPS
- 人
- i
- 生病
- ID
- if
- 想像
- 进口
- 重要
- in
- 深入
- 包括
- 包含
- 收入
- 合并
- 通知
- 例
- 兴趣
- 成
- ISN
- IT
- 它的
- JavaScript的
- JSON
- Jupyter笔记本
- 只是
- 掘金队
- 键
- 键
- 知道
- 名:
- 学习
- Level
- 各级
- 自学资料库
- 喜欢
- 清单
- 小
- ll
- 爱
- 机
- 机器学习
- 魔法
- 维持
- 制作
- 管理
- 经理
- 许多
- 手段
- 元
- 失踪
- 流动性
- 现代
- MongoDB的
- 更多
- 最先进的
- 移动
- 许多
- 多
- 姓名
- 自然
- 需求
- 嵌套
- 全新
- 下页
- 没有
- 特别是
- 笔记本
- 对象
- 获得
- of
- 优惠精选
- 经常
- on
- 一
- 仅由
- or
- 我们的
- 我们自己
- 产量
- 大熊猫
- 参数
- 部分
- 尤其
- 有待
- 执行
- 物理
- 关键的
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 热门
- 礼物
- 大概
- 程序
- 过程
- 产生
- 项目
- 蟒蛇
- 题
- 相当
- 原
- RE
- 阅读
- 准备
- 记录
- 记录
- 提炼
- 回应
- REST的
- 成果
- 护
- 右
- 角色
- s
- 同
- 科学
- 科学与技术
- 科学家
- 秒
- 看到
- 选择
- 应该
- 简易
- 模拟
- 单
- 技能
- 小
- So
- 一些
- 东西
- 具体的
- 特别是
- SQL
- 仍
- 存储
- 商店
- 结构体
- 结构化
- 这样
- 合适的
- 概要
- T
- 表
- 专业技术
- 条款
- 这
- 世界
- 其
- 他们
- 然后
- 博曼
- Free Introduction
- 那些
- 次
- 至
- 一起
- 最佳
- 改造
- 转型
- 转型
- 类型
- 类型
- 下
- us
- 使用
- 有用
- 运用
- 利用
- 折扣值
- 价值观
- 想
- 是
- 方法..
- we
- 什么是
- ,尤其是
- 是否
- 这
- 而
- 将
- 中
- 工作
- 加工
- 合作
- 世界
- 将
- 您
- 和风网