由 AWS 提供支持的数据湖,由无与伦比的可用性提供支持 亚马逊简单存储服务 (Amazon S3),可以处理组合不同数据和分析方法所需的规模、敏捷性和灵活性。随着数据湖规模的扩大和使用的成熟,可以花费大量的精力来保持数据与业务事件的一致。为了确保文件以事务一致的方式更新,越来越多的客户正在使用开源事务表格式,例如 阿帕奇·冰山, 阿帕奇·胡迪及 Linux 基金会 Delta Lake 它可以帮助您以高压缩率存储数据、与您的应用程序和框架进行本机交互,并简化基于 Amazon S3 构建的数据湖中的增量数据处理。这些格式支持 ACID(原子性、一致性、隔离性、持久性)事务、更新插入和删除,以及以前仅在数据仓库中可用的时间旅行和快照等高级功能。每种存储格式实现此功能的方式略有不同;如需比较,请参阅 为 AWS 上的事务数据湖选择开放表格式.
2023年, AWS 宣布全面上市 适用于 Apache Iceberg、Apache Hudi 和 Linux Foundation Delta Lake 适用于 Apache Spark 的亚马逊雅典娜,无需安装单独的连接器或关联的依赖项和管理版本,并简化了使用这些框架所需的配置步骤。
在这篇文章中,我们将向您展示如何使用 Spark SQL 亚马逊雅典娜 笔记本并可使用 Iceberg、Hudi 和 Delta Lake 表格式。我们演示了常见操作,例如创建数据库和表、将数据插入表、查询数据以及使用 Athena 中的 Spark SQL 查看 Amazon S3 中的表快照。
先决条件
完成以下先决条件:
从 Amazon S3 下载并导入示例笔记本
要继续操作,请从以下位置下载本文中讨论的笔记本:
下载笔记本后,按照以下步骤将它们导入到您的 Athena Spark 环境中 导入笔记本 部分 管理笔记本文件.
导航到特定的开放表格式部分
如果您对 Iceberg 表格式感兴趣,请导航至 使用 Apache Iceberg 表 部分。
如果您对 Hudi 表格式感兴趣,请导航至 使用 Apache Hudi 表 部分。
如果您对 Delta Lake 表格式感兴趣,请导航至 使用 Linux 基金会 Delta Lake 表 部分。
使用 Apache Iceberg 表
在 Athena 中使用 Spark 笔记本时,您可以直接运行 SQL 查询,而无需使用 PySpark。我们通过使用单元魔术来做到这一点,单元魔术是笔记本单元中的特殊标头,可以改变单元的行为。对于 SQL,我们可以添加 %%sql magic,它将整个单元格内容解释为要在 Athena 上运行的 SQL 语句。
在本部分中,我们将展示如何在 Apache Spark for Athena 上使用 SQL 来创建、分析和管理 Apache Iceberg 表。
设置笔记本会话
为了在 Athena 中使用 Apache Iceberg,在创建或编辑会话时,选择 阿帕奇·冰山 通过扩展选项 Apache Spark 属性 部分。它将预先填充属性,如以下屏幕截图所示。
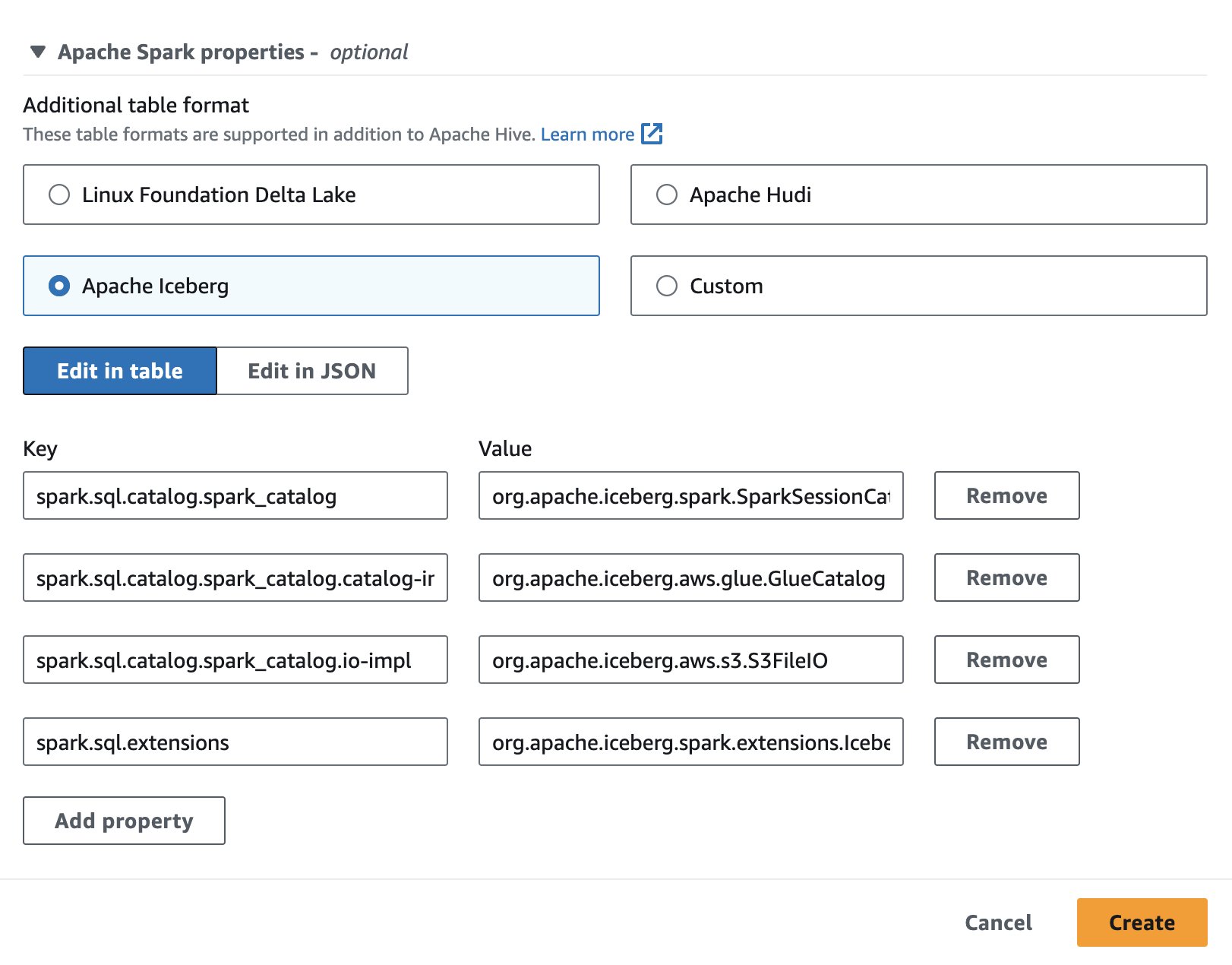
本节中使用的代码可在 SparkSQL_iceberg.ipynb 文件以跟随。
创建数据库和 Iceberg 表
首先,我们在 AWS Glue 数据目录中创建一个数据库。使用以下 SQL,我们可以创建一个名为 icebergdb:
接下来,在数据库中 icebergdb,我们创建一个 Iceberg 表,名为 noaa_iceberg 指向 Amazon S3 中我们将加载数据的位置。运行以下语句并替换位置 s3://<your-S3-bucket>/<prefix>/ 使用您的 S3 存储桶和前缀:
将数据插入表中
填充 noaa_iceberg Iceberg表,我们从Parquet表插入数据 sparkblogdb.noaa_pq 这是作为先决条件的一部分创建的。您可以使用 插入 Spark 中的声明:
或者,您可以使用 将表创建为选择 使用 USINGiceberg 子句创建一个 Iceberg 表并一步从源表插入数据:
查询 Iceberg 表
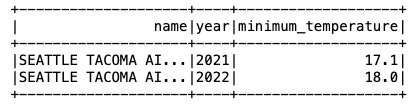
现在数据已插入到 Iceberg 表中,我们可以开始分析它了。让我们运行 Spark SQL 来查找每年记录的最低温度 'SEATTLE TACOMA AIRPORT, WA US' 位置:
我们得到以下输出。
更新 Iceberg 表中的数据
让我们看看如何更新表中的数据。我们要更新站名 'SEATTLE TACOMA AIRPORT, WA US' 至 'Sea-Tac'。使用 Spark SQL,我们可以运行 更新 针对 Iceberg 表的声明:
然后我们可以运行前面的 SELECT 查询来查找记录的最低温度 'Sea-Tac' 位置:
我们得到以下输出。

紧凑的数据文件
像 Iceberg 这样的开放表格式的工作原理是在文件存储中创建增量更改,并通过清单文件跟踪行的版本。更多的数据文件会导致清单文件中存储更多的元数据,而小数据文件通常会导致不必要的元数据量,从而导致查询效率较低和 Amazon S3 访问成本较高。运行冰山 rewrite_data_files Spark for Athena 中的过程将压缩数据文件,将许多小的增量更改文件组合成较小的一组读取优化的 Parquet 文件。压缩文件可以加快查询时的读取操作。要对我们的表运行压缩,请运行以下 Spark SQL:
rewrite_data_files 提供选项 指定排序策略,这有助于重新组织和压缩数据。
列出表快照
Iceberg 表上的每次写入、更新、删除、更新插入和压缩操作都会创建表的新快照,同时保留旧数据和元数据以进行快照隔离和时间旅行。要列出 Iceberg 表的快照,请运行以下 Spark SQL 语句:
使旧快照过期
建议定期使用过期快照来删除不再需要的数据文件,并保持表元数据的大小较小。它永远不会删除未过期快照仍需要的文件。在 Spark for Athena 中,运行以下 SQL 以使表的快照过期 icebergdb.noaa_iceberg 早于特定时间戳的:
请注意,时间戳值在 format 中指定为字符串 yyyy-MM-dd HH:mm:ss.fff。输出将给出删除的数据和元数据文件的数量。
删除表和数据库
您可以运行以下 Spark SQL 来清理本练习中的 Iceberg 表和 Amazon S3 中的关联数据:
运行以下 Spark SQL 以删除数据库icebergdb:
要了解有关使用 Spark for Athena 对 Iceberg 表执行的所有操作的更多信息,请参阅 火花查询 和 火花程序 在 Iceberg 文档中。
使用 Apache Hudi 表
接下来,我们将展示如何使用 SQL on Spark for Athena 创建、分析和管理 Apache Hudi 表。
设置笔记本会话
为了在 Athena 中使用 Apache Hudi,在创建或编辑会话时,选择 阿帕奇·胡迪 通过扩展选项 Apache Spark 属性 部分。
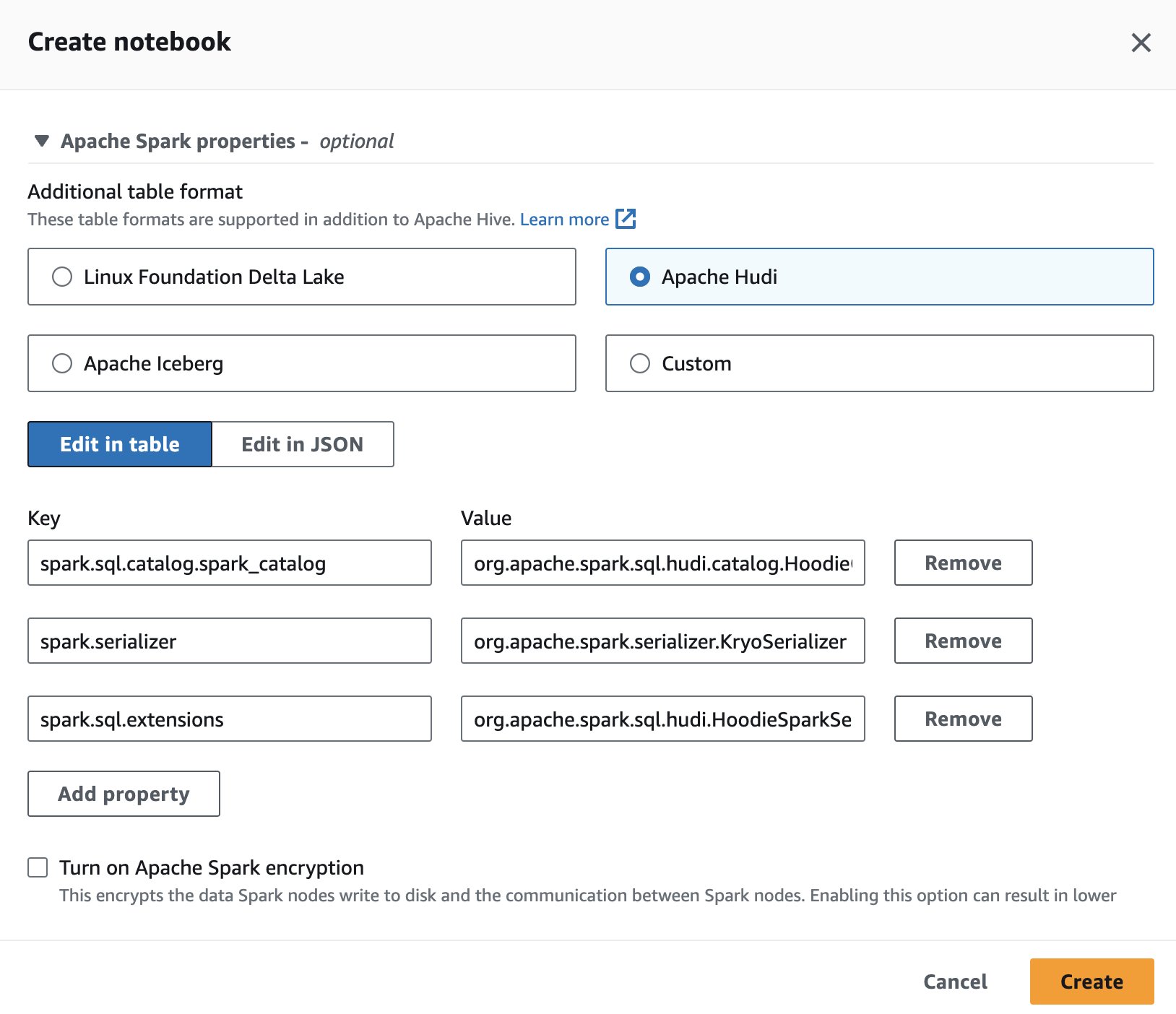
本节中使用的代码应该可以在 SparkSQL_hudi.ipynb 文件以跟随。
创建数据库和Hudi表
首先,我们创建一个数据库,名为 hudidb 它将存储在 AWS Glue 数据目录中,然后创建 Hudi 表:
我们创建一个 Hudi 表,指向 Amazon S3 中我们将加载数据的位置。请注意,该表是 写时复制 类型。它的定义是 type= 'cow' 在表 DDL 中。我们将电台和日期定义为多个主键,将 preCombinedField 定义为年份。此外,该表是按年份分区的。运行以下语句并替换位置 s3://<your-S3-bucket>/<prefix>/ 使用您的 S3 存储桶和前缀:
将数据插入表中
与 Iceberg 一样,我们使用 插入 语句通过读取数据来填充表 sparkblogdb.noaa_pq 在上一篇文章中创建的表:
查询Hudi表
现在表已创建,让我们运行一个查询来查找记录的最高温度 'SEATTLE TACOMA AIRPORT, WA US' 位置:
更新Hudi表中的数据
我们来更改站名 'SEATTLE TACOMA AIRPORT, WA US' 至 'Sea–Tac'。我们可以在 Spark 上为 Athena 运行 UPDATE 语句 更新 的记录 noaa_hudi 表:
我们运行前面的 SELECT 查询来查找记录的最高温度 'Sea-Tac' 位置:
运行时旅行查询
我们可以在 Athena 上的 SQL 中使用时间旅行查询来分析过去的数据快照。例如:
此查询检查过去特定时间的西雅图机场温度数据。时间戳子句让我们可以在不更改当前数据的情况下返回。请注意,时间戳值在 format 中指定为字符串 yyyy-MM-dd HH:mm:ss.fff.
通过集群优化查询速度
为了提高查询性能,您可以执行 集群 在 Spark for Athena 中使用 SQL 的 Hudi 表:
紧凑型桌子
压缩是 Hudi 专门在读取合并 (MOR) 表中使用的一项表服务,用于定期将基于行的日志文件的更新合并到相应的基于列的基本文件,以生成新版本的基本文件。压缩不适用于写入时复制 (COW) 表,仅适用于 MOR 表。您可以在 Spark 中运行以下查询,让 Athena 对 MOR 表执行压缩:
删除表和数据库
运行以下 Spark SQL 以从 Amazon S3 位置删除您创建的 Hudi 表和关联数据:
运行以下 Spark SQL 以删除数据库 hudidb:
要了解可以使用 Spark for Athena 对 Hudi 表执行的所有操作,请参阅 SQL数据描述语言 和 程序 在 Hudi 文档中。
使用 Linux 基金会 Delta Lake 表
接下来,我们将展示如何使用 SQL on Spark for Athena 创建、分析和管理 Delta Lake 表。
设置笔记本会话
为了在 Spark for Athena 中使用 Delta Lake,在创建或编辑会话时,选择 Linux 基金会 Delta Lake 通过扩大 Apache Spark 属性 部分。
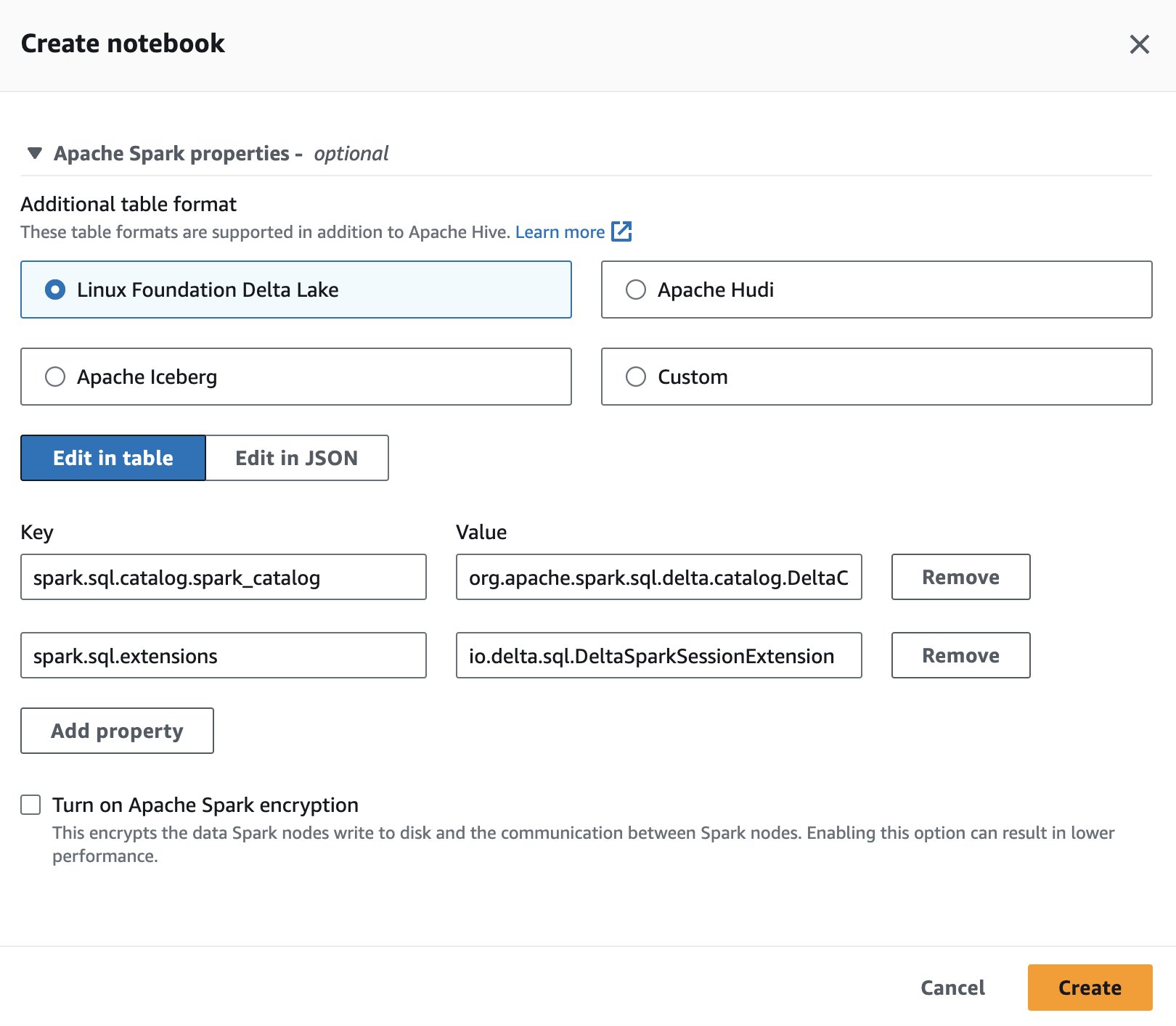
本节中使用的代码应该可以在 SparkSQL_delta.ipynb 文件以跟随。
创建数据库和 Delta Lake 表
在本部分中,我们在 AWS Glue 数据目录中创建一个数据库。使用以下 SQL,我们可以创建一个名为 deltalakedb:
接下来,在数据库中 deltalakedb,我们创建一个 Delta Lake 表,名为 noaa_delta 指向 Amazon S3 中我们将加载数据的位置。运行以下语句并替换位置 s3://<your-S3-bucket>/<prefix>/ 使用您的 S3 存储桶和前缀:
将数据插入表中
我们使用 插入 语句通过读取数据来填充表 sparkblogdb.noaa_pq 在上一篇文章中创建的表:
您还可以使用 CREATE TABLE AS SELECT 创建 Delta Lake 表并在一个查询中从源表插入数据。
查询Delta Lake表
现在数据已插入到 Delta Lake 表中,我们可以开始分析它了。让我们运行 Spark SQL 来查找记录的最低温度 'SEATTLE TACOMA AIRPORT, WA US' 位置:
更新 Delta Lake 表中的数据
我们来更改站名 'SEATTLE TACOMA AIRPORT, WA US' 至 'Sea–Tac'。我们可以运行一个 更新 Spark for Athena 更新记录的声明 noaa_delta 表:
我们可以运行前面的 SELECT 查询来查找记录的最低温度 'Sea-Tac' 位置,结果应该与之前相同:
紧凑的数据文件
在 Spark for Athena 中,您可以在 Delta Lake 表上运行 OPTIMIZE,这会将小文件压缩为更大的文件,因此查询不会受到小文件开销的负担。要执行压缩操作,请运行以下查询:
请参阅 优化 在 Delta Lake 文档中了解运行 OPTIMIZE 时可用的不同选项。
删除 Delta Lake 表不再引用的文件
您可以使用 Spark for Athena 在表上运行 VACCUM 命令,删除存储在 Amazon S3 中、不再被 Delta Lake 表引用且早于保留阈值的文件:
请参阅 删除 Delta 表不再引用的文件 在 Delta Lake 文档中了解 VACUUM 可用的选项。
删除表和数据库
运行以下 Spark SQL 以删除您创建的 Delta Lake 表:
运行以下 Spark SQL 以删除数据库 deltalakedb:
在 Delta Lake 表和数据库上运行 DROP TABLE DDL 会删除这些对象的元数据,但不会自动删除 Amazon S3 中的数据文件。您可以在笔记本的单元中运行以下 Python 代码以从 S3 位置删除数据:
要了解有关可以使用 Spark for Athena 在 Delta Lake 表上运行的 SQL 语句的更多信息,请参阅 快速开始 在 Delta Lake 文档中。
结论
本文演示了如何在 Athena Notebook 中使用 Spark SQL 创建数据库和表、插入和查询数据以及在 Hudi、Delta Lake 和 Iceberg 表上执行更新、压缩和时间旅行等常见操作。开放表格式向数据湖添加 ACID 事务、更新插入和删除,克服了原始对象存储的限制。通过消除安装单独连接器的需要,Spark on Athena 的内置集成减少了使用这些流行框架在 Amazon S3 上构建可靠数据湖时的配置步骤和管理开销。要了解有关为数据湖工作负载选择开放表格式的更多信息,请参阅 为 AWS 上的事务数据湖选择开放表格式.
作者简介
![]() 帕西克·沙(Pathik Shah) 是 Amazon Athena 的高级分析架构师。 他于 2015 年加入 AWS,此后一直专注于大数据分析领域,帮助客户使用 AWS 分析服务构建可扩展且强大的解决方案。
帕西克·沙(Pathik Shah) 是 Amazon Athena 的高级分析架构师。 他于 2015 年加入 AWS,此后一直专注于大数据分析领域,帮助客户使用 AWS 分析服务构建可扩展且强大的解决方案。
![]() 拉杰德纳特 是 Amazon Athena 上 AWS 的产品经理。 他热衷于打造客户喜爱的产品并帮助客户从数据中提取价值。 他的背景是为多个终端市场提供解决方案,例如金融、零售、智能建筑、家庭自动化和数据通信系统。
拉杰德纳特 是 Amazon Athena 上 AWS 的产品经理。 他热衷于打造客户喜爱的产品并帮助客户从数据中提取价值。 他的背景是为多个终端市场提供解决方案,例如金融、零售、智能建筑、家庭自动化和数据通信系统。
- :具有
- :是
- :不是
- :在哪里
- $UP
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- 关于
- ACCESS
- 加
- 高级
- 驳
- 机场
- 所有类型
- 沿
- 还
- Amazon
- 亚马逊雅典娜
- 亚马逊网络服务
- 量
- an
- 分析
- 分析
- 分析
- 和
- 公布
- 阿帕奇
- Apache Spark
- 相应
- 应用领域
- 适用
- 方法
- 保健
- 围绕
- AS
- 相关
- At
- 自动
- 自动化和干细胞工程
- 可用性
- 可使用
- AWS
- AWS胶水
- 背部
- 背景
- 基地
- BE
- 很
- 行为
- 大
- 大数据运用
- 建立
- 建筑物
- 建
- 内建的
- 商业
- 但是
- by
- 呼叫
- 被称为
- CAN
- 检索目录
- 原因
- 细胞
- 更改
- 更改
- 支票
- 清洁
- 码
- 结合
- 结合
- 相当常见
- 沟通
- 通讯系统
- 紧凑
- 对照
- 配置
- 一贯
- Contents
- 相应
- 成本
- 数
- 创建信息图
- 创建
- 创建
- 创造
- 创建
- 电流
- 合作伙伴
- data
- 数据分析
- 数据湖
- 数据处理
- 数据仓库
- 数据库
- 数据库
- 日期
- 定义
- 交付
- Delta
- 演示
- 证明
- 依赖
- 不同
- 直接
- 讨论
- do
- 文件
- 不会
- 下载
- 下降
- 耐久力
- 每
- 此前
- 编辑
- 高效
- 努力
- 就业
- enable
- 结束
- 确保
- 整个
- 环境
- 醚(ETH)
- 事件
- 例子
- 锻炼
- 扩大
- 提取
- 特征
- 文件
- 档
- 金融
- 找到最适合您的地方
- 姓氏:
- 高度灵活
- 聚焦
- 遵循
- 其次
- 以下
- 针对
- 格式
- 基金会
- 框架
- 止
- 功能
- 其他咨询
- 得到
- 给
- 团队
- 成长
- 长大的
- 处理
- 有
- 有
- he
- 头
- 帮助
- 帮助
- hh
- 高
- 更高
- 他的
- 主页
- 家庭自动化
- 创新中心
- How To
- HTML
- HTTP
- HTTPS
- 图片
- 器物
- 进口
- 改善
- in
- 增量
- 安装
- 积分
- 有兴趣
- 接口
- 成
- 隔离
- IT
- 加盟
- JPG
- 保持
- 保持
- 键
- 湖泊
- 湖泊
- 大
- 纬度
- 信息
- 学习用品
- 减
- 让
- 喜欢
- 限制
- Linux的
- linux基金会
- 清单
- 加载
- 圖書分館的位置
- 地点
- 日志
- 不再
- 看
- 寻找
- 爱
- 魔法
- 管理
- 颠覆性技术
- 经理
- 方式
- 许多
- 市场
- 最大
- 最多
- 合并
- 元数据
- 分钟
- 最低限度
- 更多
- 多
- 姓名
- 本地
- 导航
- 需求
- 打印车票
- 决不要
- 全新
- 没有
- 注意
- 笔记本
- 笔记本电脑
- 数
- 对象
- 对象存储
- 对象
- of
- 优惠精选
- 经常
- 老
- 老年人
- on
- 一
- 仅由
- OP
- 打开
- 开放源码
- 操作
- 运营
- 优化
- 附加选项
- 附加选项
- or
- 秩序
- 我们的
- 产量
- 克服
- 己
- 部分
- 多情
- 过去
- 演出
- 性能
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 热门
- 帖子
- 先决条件
- 以前
- 先前
- 小学
- 程序
- 处理
- 生产
- 产品
- 产品经理
- 热销产品
- 蟒蛇
- 查询
- 价格表
- 原
- 阅读
- 阅读
- 建议
- 记录
- 记录
- 减少
- 参考
- 引用
- 可靠
- 去掉
- 移除了
- 删除
- 更换
- 必须
- 导致
- 导致
- 零售
- 保留
- 健壮
- 运行
- 运行
- 同
- 可扩展性
- 鳞片
- 西雅图
- 其次
- 部分
- 看到
- 选择
- 选择
- 分开
- 服务
- 特色服务
- 会议
- 集
- 应该
- 显示
- 如图
- 作品
- 显著
- 简易
- 简化
- 简化
- 自
- 尺寸
- 略有不同
- SLP
- 小
- 小
- 智能
- 快照
- So
- 解决方案
- 来源
- 太空
- 火花
- 特别
- 具体的
- 特别是
- 指定
- 速度
- 速度
- 花费
- SQL
- 开始
- 个人陈述
- 声明
- 站
- 步
- 步骤
- 仍
- 存储
- 商店
- 存储
- 策略
- 串
- 这样
- 支持
- 系统
- 产品
- 表
- 塔科马
- 比
- 这
- 其
- 他们
- 然后
- 博曼
- Free Introduction
- 门槛
- 通过
- 次
- 时间旅行
- 时间戳
- 至
- 跟踪
- 交易
- 交易
- 旅行
- 类型
- 无与伦比
- 更新
- 更新
- 最新动态
- us
- 用法
- 使用
- 用过的
- 运用
- 真空
- 折扣值
- 版本
- 版本
- 想
- 是
- 方法
- we
- 卷筒纸
- Web服务
- 为
- ,尤其是
- 这
- 而
- 将
- 也完全不需要
- 工作
- 写
- 年
- 您
- 您一站式解决方案
- 和风网