介绍
的合并 人工智能 (人工智能)和艺术揭示了创意数字艺术的新途径,尤其是通过扩散模型。这些模型在创意人工智能艺术中脱颖而出,提供了与传统神经网络不同的方法。本文将带您踏上扩散模型深度的探索之旅,阐明其在制作视觉上令人惊叹且创意丰富的艺术品时的独特机制。了解扩散模型的细微差别,并通过先进的人工智能技术深入了解它们在重新定义艺术表达方面的作用。

学习目标
- 了解人工智能中扩散模型的基本概念。
- 探索艺术生成中扩散模型和传统神经网络之间的区别。
- 使用扩散模型分析艺术创作的过程。
- 评估人工智能在数字艺术中的创意和美学影响。
- 讨论人工智能生成的艺术作品中的道德考虑。
这篇文章是作为 数据科学博客马拉松。
目录
了解扩散模型

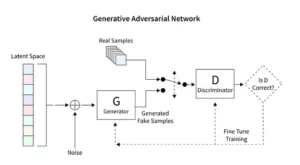
扩散模型彻底改变了生成式人工智能,提出了一种不同于生成对抗网络 (GAN) 等传统技术的独特图像创建方法。这些模型从随机噪声开始,逐渐对其进行细化,就像艺术家对绘画进行微调一样,从而产生复杂且连贯的图像。
这种渐进的细化过程反映了扩散的有条不紊的本质。在这里,每次迭代都会巧妙地改变噪音,使其更接近最终的艺术愿景。输出不仅仅是随机性的产物,而且是一件进化的艺术品,其进程和完成都截然不同。
扩散模型的编码需要深入掌握神经网络和机器学习框架,例如 TensorFlow 或 PyTorch。由此产生的代码非常复杂,需要对广泛的数据集进行广泛的训练才能实现人工智能生成的艺术中观察到的微妙效果。
稳定扩散在艺术中的应用
稳定扩散模型等人工智能艺术生成器的出现需要在 TensorFlow 或 PyTorch 等平台内进行复杂的编码。这些模型因其能够有条不紊地将随机性转化为结构而脱颖而出,就像艺术家将初步草图打磨成生动的杰作一样。
稳定的扩散模型通过从随机性中塑造有序图像来重塑人工智能艺术场景,避开 GAN 的竞争动态特征。他们擅长将概念提示解释为视觉艺术,促进人工智能能力和人类创造力之间的协同舞蹈。通过利用 PyTorch,我们观察这些模型如何迭代地将混乱提炼为清晰,反映了艺术家从萌芽想法到精美创作的旅程。
尝试人工智能生成的艺术
该演示使用称为“ 卷积扩散模型。该模型接受了各种艺术图像的训练,包括素描、绘画、雕塑和雕刻,来源自 这个 Kaggle 数据集。我们的目标是探索模型捕捉和再现这些艺术品的复杂美学的能力。
模型架构和训练
建筑设计
ConvDiffusionModel 的核心是神经工程的奇迹,具有专为艺术生成的需求而定制的复杂的编码器-解码器架构。该模型的结构是一个复杂的神经网络,集成了专门为艺术生成而磨练的精细编码器-解码器机制。通过附加的卷积层和模拟艺术直觉的跳跃连接,该模型可以通过对构图和风格的敏锐理解来剖析和重新组合艺术。
- 编码器: 编码器是模型的分析眼睛,仔细检查每个输入图像的微小细节。当图像通过编码器的卷积层时,它们逐渐被压缩到一个潜在空间——原始艺术品的紧凑的编码表示。我们的编码器不仅仔细检查输入图像,而且现在通过附加层和批量归一化技术增强了感知深度。这种扩展的检查可以在潜在空间中提供更丰富、更浓缩的表现,反映艺术家对某个主题的深刻思考。
- 解码器: 相比之下,解码器充当模型的创意之手,从编码器获取抽象草图并为其注入生命。它从潜在的空间中逐层、逐个细节地重建艺术品,直到出现完整的图像。我们的解码器受益于跳过连接,并且可以更精确地重建艺术品。它重新审视输入的抽象本质并逐步对其进行修饰,从而实现更忠实于源材料的再现。增强层协同工作,确保最终图像生动、复杂,反映了输入的艺术性。
训练过程
ConvDiffusionModel 的训练是一次跨越 150 个时代的艺术景观之旅。每个时期代表对整个数据集的完整遍历,模型努力完善其理解并提高其生成图像的保真度。
- 混合损失函数: 训练的核心是均方误差(MSE)损失函数。该函数量化了原始杰作和模型重建之间的差异,提供了一个明确的指标来最小化。我们将引入一个源自预训练 VGG 网络的感知损失组件,它补充了均方误差 (MSE) 指标。这种双重损失策略推动模型尊重原件的艺术完整性,同时完善其细节的技术再现。
- 优化器: Adam 优化器通过调度程序动态调整学习率,以更高的智慧指导模型的学习。这种适应性方法确保模型在学习复制和创新艺术方面的进展既稳定又稳健。
- 迭代和细化: 训练迭代是保留艺术本质和追求技术复制之间的舞蹈。在每个周期中,模型都更接近保真度和创造力的综合。
- 进度可视化:训练过程中定期保存图像,以可视化模型的进度。这些快照为了解模型的学习曲线提供了一个窗口,展示了其生成的艺术如何演变,变得更清晰、更详细,并且在艺术上与每个时代更加一致。



上述内容通过以下代码进行演示:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
可视化生成的艺术作品
展现人工智能艺术
随着 ConvDiffusionModel 现已经过全面训练,焦点从抽象转移到具体,从潜力转移到实现人工智能制作的艺术。随后的代码片段具体化了模型所学到的艺术能力,将输入数据转换为表达的数字画布。
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()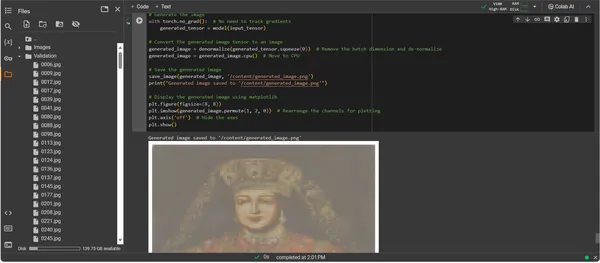

艺术品生成代码演练
- 模型复活: 艺术作品生成的第一步是恢复我们训练过的 ConvDiffusionModel。模型的学习权重被加载并进入评估模式,为创建奠定了基础,而无需进一步更改其参数。
- 图像转换: 为了确保与训练机制的一致性,输入图像通过相同的变换序列进行处理。这包括调整大小以匹配模型的输入维度、用于 PyTorch 兼容性的张量转换以及基于训练数据的统计配置文件的标准化。
- 非规范化实用程序: 自定义函数可反转预处理效果,将张量重新缩放到原始图像的颜色范围。此步骤对于将生成的输出渲染为视觉上准确的表示至关重要。
- 输入准备: 加载图像并进行上述转换。值得注意的是,这张图像是人工智能从中汲取灵感的缪斯——无声的低语点燃了模型的合成想象力。
- 艺术品合成: 在前向传播的微妙舞蹈中,模型解释输入张量,使其各层协作产生新的艺术视觉。执行此过程时无需跟踪梯度,因为我们现在处于应用领域,而不是训练领域。
- 图像转换: 模型的张量输出现在保存着数字生成的艺术品,被非规范化,将模型的创作转换回我们眼睛可以欣赏的熟悉的颜色和光线空间。
- 艺术品启示: 转换后的张量被放置在数字画布上,最终形成保存的图像文件。该文件是了解人工智能创造性灵魂的窗口,是赋予其生命的动态过程的静态回声。
- 艺术品检索: 该脚本最后将生成的图像保存到指定路径并宣布其完成。保存的图像是所学艺术原理和新兴创造力的综合体,可供展示和思考。
分析输出
ConvDiffusionModel 的输出呈现出一个明确向历史艺术致敬的图形。人工智能渲染的图像身着精致的服装,与古典肖像的宏伟相呼应,但又具有独特的现代风格。拍摄对象的服装质感丰富,将模特习得的图案与新颖的诠释融为一体。精致的面部特征和微妙的光影相互作用展示了人工智能对传统艺术技巧的细致入微的理解。这件艺术品证明了模型经过复杂的训练,通过先进的机器学习棱镜反映了历史艺术的优雅综合。从本质上讲,它是用现在的算法精心制作的对过去的数字致敬。
挑战和伦理考虑
实施艺术生成的扩散模型会带来一些您应该考虑的挑战和道德考虑:
- 数据来源: 训练数据集必须负责任地管理。验证用于训练扩散模型的数据不包含未经适当授权的受版权保护或受保护的作品至关重要。
- 偏见和代表性: 人工智能模型可能会使训练数据中存在偏见。确保数据集的多样性和包容性对于避免强化人工智能生成的艺术中的刻板印象非常重要。
- 控制输出: 由于扩散模型可以产生广泛的输出,因此有必要设置边界以防止创建不适当或令人反感的内容。
- 法律框架: 缺乏强有力的法律框架来解决人工智能在创作过程中的细微差别是一个挑战。立法需要发展以保护所有相关方的权利。
结论
人工智能和艺术中扩散模型的兴起标志着一个变革时代,将计算精度与美学探索融为一体。他们在艺术界的旅程凸显了巨大的创新潜力,但也充满了复杂性。平衡原创性、影响力、道德创作和对现有作品的尊重是艺术过程中不可或缺的一部分。
关键精华
- 扩散模型处于艺术创作变革的最前沿。他们提供新的数字工具,将艺术表达的画布扩展到传统界限之外。
- 在人工智能增强的艺术中,优先考虑训练数据的道德收集和尊重创作者的知识产权对于保持数字艺术的完整性至关重要。
- 艺术视野和技术创新的融合为艺术家和人工智能开发人员之间的共生关系打开了大门。营造一个可以催生突破性艺术的协作环境。
- 确保人工智能生成的艺术代表广泛的观点至关重要。纳入反映不同文化和观点丰富性的各种数据,从而促进包容性。
- 人们对人工智能艺术日益浓厚的兴趣需要建立强有力的法律框架。这些框架应澄清版权问题、认可贡献并管理人工智能生成的艺术品的商业使用。
这种艺术演变的曙光提供了一条充满创造潜力的道路,但需要细心的守护。我们有责任在负责任和文化敏感的实践的指导下,培育人工智能与艺术融合蓬勃发展的景观。
常见问题
答:扩散模型是生成式机器学习算法,它通过从随机噪声模式开始并逐渐将其塑造成连贯的图片来创建图像。这个过程类似于艺术家从空白画布开始,慢慢添加细节层。
A. GAN、扩散模型不需要单独的网络来判断输出。它们通过迭代地添加和消除噪声来工作,通常会产生更详细和细致的图像。
答:是的,扩散模型可以通过从图像数据集中学习来生成原创艺术作品。然而,原创性受到训练数据的多样性和范围的影响。关于使用现有艺术品来训练这些模型的道德问题一直存在争论。
答:道德问题包括避免人工智能生成的艺术版权侵权。尊重人类艺术家的原创性,防止偏见持续存在,并确保人工智能创作过程的透明度。
答:人工智能生成艺术的未来看起来充满希望,扩散模型为艺术家和创作者提供了新工具。随着技术的进步,我们可以期待看到更加精致和复杂的艺术品。然而,创意社区必须考虑道德因素,并努力制定明确的指导方针和最佳实践。
本文中显示的媒体不属于 Analytics Vidhya 所有,其使用由作者自行决定。
相关
- :是
- :不是
- :在哪里
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- 对,能力--
- 关于
- 以上
- 摘要
- 精准的
- 实现
- Adam
- 自适应
- 添加
- 额外
- 地址
- 调整
- 高级
- 进步
- 来临
- 对抗
- AI
- 人工智能艺术
- 类似的
- 算法
- 所有类型
- 允许
- 允许
- an
- 分析
- 分析
- 分析维迪亚
- 和
- 宣布
- 应用领域
- 欣赏
- 的途径
- 架构
- 保健
- 艺术
- 刊文
- 艺术家
- 艺术的
- 艺术上
- 艺术性
- 艺术家
- 艺术品
- 艺术品
- AS
- At
- 增强
- 授权
- 可使用
- 大道
- 避免
- 避免
- 轴
- 背部
- 坏
- 平衡
- 基于
- BE
- 成为
- 好处
- 最佳
- 最佳实践
- 之间
- 超越
- 偏见
- 偏见
- 空白
- 混纺
- 博客马拉松
- 天生的
- 都
- 边界
- 呼吸
- 充满
- 带来
- 广阔
- 带
- 新兴
- 但是
- by
- 计算
- 被称为
- CAN
- 帆布
- 能力
- 能力
- 捕获
- 挑战
- 挑战
- 通道
- 混沌
- 特点
- 查
- 检查
- 钳
- 明晰
- 程
- 清除
- 更清晰
- 接近
- 码
- 编码
- 相干
- 合作
- 共同
- 颜色
- 购买的订单均
- 商业的
- 社体的一部分
- 紧凑
- 兼容性
- 竞争的
- 完成
- 完成
- 复杂
- 复杂性
- 元件
- 写作
- 计算
- 计算
- 概念
- 概念上的
- 关注
- 音乐会
- 总结
- 连接
- 考虑
- 注意事项
- 包含
- 内容
- 对比
- 捐款
- 常规
- 收敛
- 转化
- 转换
- 卷积神经网络
- 版权
- 侵犯版权
- 核心
- 腐败
- 中央处理器
- 精雕细琢
- 创建信息图
- 创造
- 创建
- 创意奖学金
- 创造性地
- 创造力
- 创作者
- 关键
- 高潮
- 培育
- 在文化上
- 策划
- 曲线
- 习俗
- 周期
- 舞蹈
- data
- 数据集
- 辩论
- 深
- 定义
- 需求
- 证明
- 深度
- 深度
- 派生
- 指定
- 细节
- 详细
- 详情
- 开发
- 设备
- 不同
- 差异
- 不同
- 扩散
- 数字
- 数码艺术
- 数字
- 尺寸
- 尺寸
- 酌处权
- 屏 显:
- 显示
- 不同
- 区别
- 不同
- 多元化
- do
- 不
- 门
- 画
- 图纸
- ,我们将参加
- 动态
- 动态
- 动力学
- e
- 每
- 回音
- 呼应
- 影响
- 阐述
- 其他
- 出现
- 编码
- 环绕
- 包含
- 工程师
- 增强
- 确保
- 确保
- 保证
- 整个
- 环境
- 时代
- 时代
- 时代
- 错误
- 本质
- 必要
- 编制
- 醚(ETH)
- 伦理
- 伦理
- 评估
- 所有的
- 进化
- 发展
- 进化
- 演变
- 检查
- Excel
- 除
- 现有
- 扩大
- 膨胀
- 期望
- 勘探
- 探索
- 表达
- 扩展
- 广泛
- 眼
- 眼部彩妆
- 面部
- 忠实
- false
- 熟悉
- 迷人
- 特征
- 特色
- 保真度
- 数字
- 文件
- 档
- 最后
- 完
- (名字)
- 专注焦点
- 以下
- 针对
- 第一线
- 向前
- 培育
- 培养
- 骨架
- 框架
- 止
- 充分
- 功能
- 实用
- 根本
- 进一步
- 聚变
- 未来
- Gain增益
- GAN
- 搜集
- 给
- 生成
- 产生
- 发电
- 代
- 生成的
- 生成对抗网络
- 生成式人工智能
- 发电机
- 给
- 目标
- GPU
- 渐变
- 渐渐
- 富丽堂皇
- 把握
- 更大的
- 奠基
- 制导
- 方针
- 指南
- 手
- 治理
- 胸襟
- 相关信息
- 隐藏
- 亮点
- 历史的
- 保持
- 尊敬
- 兑现
- 创新中心
- 但是
- HTTPS
- 人
- i
- 主意
- if
- 点燃
- 图片
- 图片
- 想像力
- 势在必行
- 实施
- 启示
- 进口
- 重要
- 改善
- in
- 包括
- 包容
- 包容性
- 合并
- 增加
- 增量
- 现任
- 影响
- 影响
- 侵害
- 创造力
- 创新
- 創新
- 输入
- 输入
- 洞察
- 积分
- 整合
- 诚信
- 知识分子
- 知识产权
- 兴趣
- 解释
- 成
- 错综复杂
- 介绍
- 直觉
- 参与
- 问题
- IT
- 迭代
- 迭代
- 它的
- 旅程
- JPG
- 法官
- 缺乏
- 景观
- 层
- 层
- 知道
- 学习
- 法律咨询
- 法律框架
- 立法
- 光学棱镜
- 谎言
- 生活
- 光
- 喜欢
- 装载
- LOOKS
- 离
- 损失
- 机
- 机器学习
- 保持
- 奇迹
- 杰作
- 匹配
- 材料
- matplotlib
- 意味着
- 机制
- 机制
- 媒体
- 仅仅
- 合并
- 方法
- 有条不紊
- 公
- 大幅减低
- 分钟
- 镜像
- ML
- ML算法
- 时尚
- 模型
- 模型
- 现代
- 模块
- 更多
- 移动
- 许多
- MUSE
- 必须
- 名称
- 新生的
- 自然
- 导航
- 必要
- 需要
- 网络
- 网络
- 神经
- 神经工程
- 神经网络
- 神经网络
- 全新
- 噪声
- 注意
- 小说
- 现在
- 细微之处
- 观察
- 观察
- of
- 折扣
- 进攻
- 提供
- 提供
- 优惠精选
- 经常
- on
- 正在进行
- 仅由
- 打开
- 优化
- or
- 原版的
- 独创性
- 原稿
- OS
- 其他名称
- 我们的
- 输出
- 产量
- 输出
- 超过
- 拥有
- 画
- 画
- 参数
- 参数
- 部分
- 各方
- 通过
- 过去
- 径
- 模式
- 模式
- 知觉
- 完善
- 演出
- 观点
- 图片
- 片
- 件
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 肖像
- 潜力
- 做法
- 平台精度
- 初步
- 当下
- 礼物
- 保存
- 防止
- 预防
- 原则
- 印刷
- 优先顺序
- 过程
- 处理
- 生产
- 产品
- 本人简介
- 深刻的
- 进展
- 级数
- 逐步
- 有希望
- 促进
- 提示
- 传播
- 正确
- 财产
- 保护
- 保护
- 出处
- 优
- 出版
- 追求
- pytorch
- 量化
- 随机
- 随机性
- 范围
- 率
- 准备
- 境界
- 承认
- 重新定义
- 提炼
- 精
- 反映
- 反映
- 政权
- 定期
- 关系
- 删除
- 翻译
- 复制
- 表示
- 代表
- 复制
- 要求
- 需要
- 类似
- 重塑
- 尊重
- 关于
- 提供品牌战略规划
- 负责任
- 导致
- 回报
- 启示
- 复活
- 革命化
- RGB
- 丰富
- 权利
- 上升
- 健壮
- 角色
- 同
- 保存
- 保存
- 现场
- 科学
- 范围
- 脚本
- 看到
- 自
- 敏感
- 分开
- 序列
- 服务
- 集
- 设置
- 格局
- 几个
- 阴影
- 成型
- 转移
- 转移
- 应该
- 展示
- 陈列宣传
- 如图
- 显著
- 自
- 慢慢地
- 片段
- So
- 极致
- 灵魂
- 来源
- 采购
- 太空
- 张力
- 特别是
- 光谱
- 平方
- 稳定
- 阶段
- 站
- 开始
- 统计
- 稳定
- 步
- 策略
- 努力
- 结构体
- 令人惊叹
- 样式
- 主题
- 随后
- 这样
- 共生
- 协同作用
- 合成
- 合成的
- 量身定制
- 需要
- 服用
- 目标
- 文案
- 技术
- 技术性
- 技术
- 专业技术
- tensorflow
- 遗嘱
- 这
- 未来
- 其
- 他们
- 那里。
- 博曼
- 他们
- Free Introduction
- 蓬勃发展
- 通过
- 从而
- 至
- 工具
- 火炬
- 火炬视
- 触摸
- 向
- 跟踪
- 传统
- 培训
- 熟练
- 产品培训
- 改造
- 转型
- 转换
- 变革
- 转化
- 转型
- 变换
- 用户评论透明
- true
- 尝试
- 理解
- 理解
- 独特
- 直到
- 推出
- 更新
- 上
- us
- 使用
- 用过的
- 运用
- 效用
- 有效
- 验证
- 通过
- 查看
- 观点
- 愿景
- 视觉
- 视觉艺术
- 可视化
- 想像
- 视觉
- 重要
- 是
- we
- 网页
- 什么是
- 什么是
- 这
- 而
- 耳语
- WHO
- 宽
- 大范围
- 将
- 窗口
- 中
- 也完全不需要
- 工作
- 合作
- 世界
- X
- 含
- 但
- 您
- 和风网
- 零