Pandas 是一个功能强大且广泛使用的开源库,用于使用 Python 进行数据操作和分析。 其主要功能之一是能够使用 groupby 函数对数据进行分组,方法是根据一列或多列将 DataFrame 分成几组,然后对每一列应用各种聚合函数。

图片来源: Unsplash
groupby 功能非常强大,因为它允许您快速汇总和分析大型数据集。 例如,您可以按特定列对数据集进行分组,并计算每组剩余列的平均值、总和或计数。 您还可以按多个列进行分组,以更详细地了解数据。 此外,它还允许您应用自定义聚合函数,这对于复杂的数据分析任务来说是一个非常强大的工具。
在本教程中,您将学习如何使用 Pandas 中的 groupby 函数对不同类型的数据进行分组并执行不同的聚合操作。 在本教程结束时,您应该能够使用此函数以各种方式分析和汇总数据。
当练习得好时,概念就会内化,这就是我们下一步要做的,即动手实践 Pandas groupby 函数。 建议使用 Jupyter笔记本 对于本教程,您可以看到每个步骤的输出。
生成样本数据
导入以下库:
- Pandas:创建数据框并应用分组依据
- 随机 – 生成随机数据
- Pprint – 打印词典
import pandas as pd
import random
import pprint
接下来,我们将初始化一个空数据框并填充每列的值,如下所示:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
额外提示 - 完成相同任务的一种更简洁的方法是创建所有变量和值的字典,然后将其转换为数据帧。
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
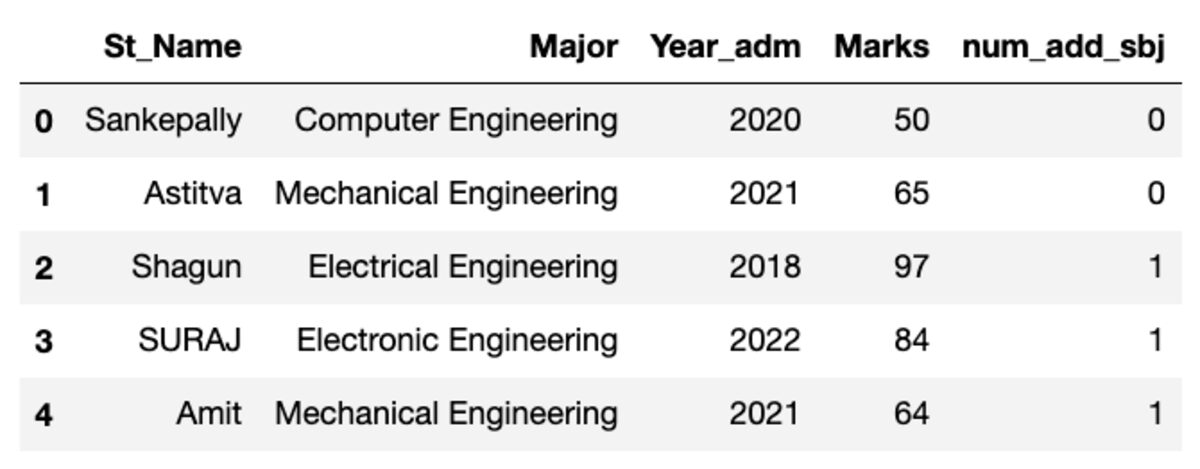
数据框如下所示。 运行此代码时,某些值将不匹配,因为我们使用的是随机样本。
分组
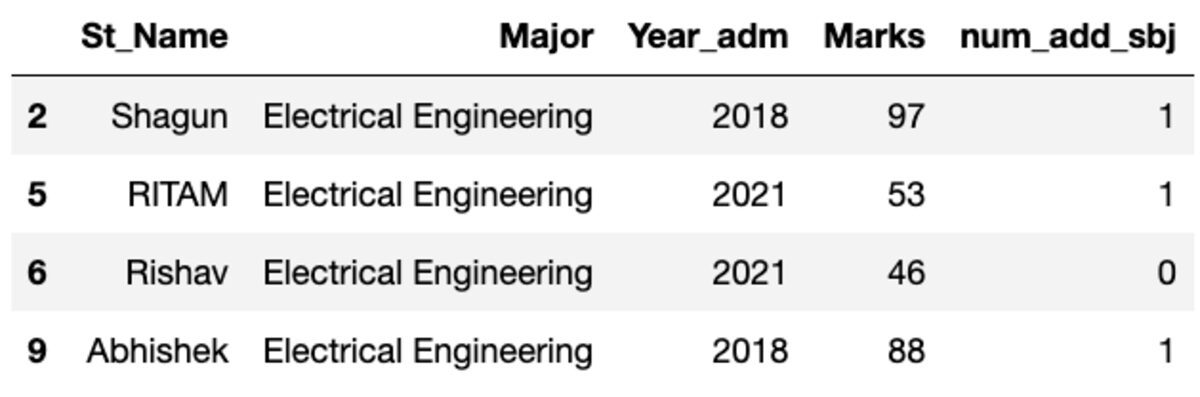
让我们按“主要”主题对数据进行分组,并应用组过滤器来查看有多少记录属于该组。
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
因此,有四名学生属于电气工程专业。
您还可以按多列进行分组(本例中为 Major 和 num_add_sbj)。
groups = df.groupby(['Major', 'num_add_sbj'])
请注意,所有可应用于具有一列的组的聚合函数都可以应用于具有多列的组。 在本教程的其余部分中,我们以单列为例重点介绍不同类型的聚合。
让我们在“Major”列上使用 groupby 创建组。
groups = df.groupby('Major')应用直接函数
假设您想找到每个专业的平均分。 你会怎么办?
- 选择标记栏
- 应用均值函数
- 应用舍入函数将标记四舍五入到小数点后两位(可选)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
骨料
实现相同结果的另一种方法是使用聚合函数,如下所示:
groups['Marks'].aggregate('mean').round(2)
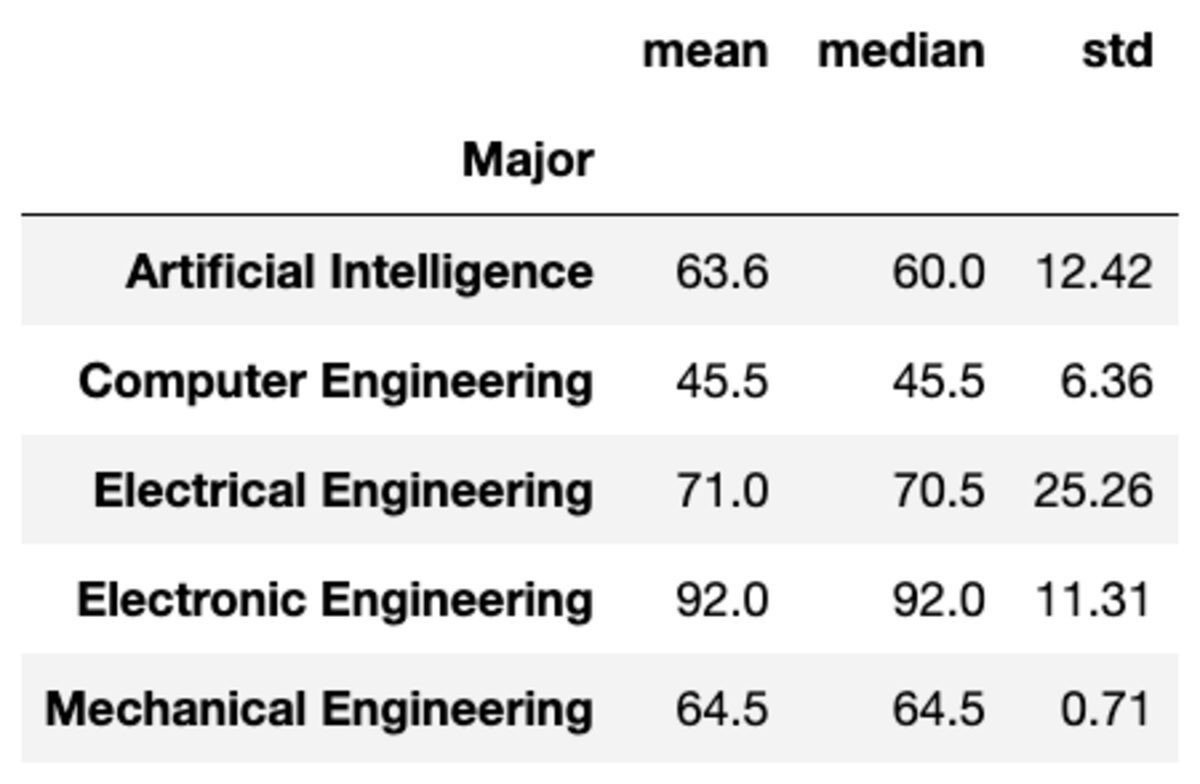
您还可以通过将函数作为字符串列表传递来将多个聚合应用于组。
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
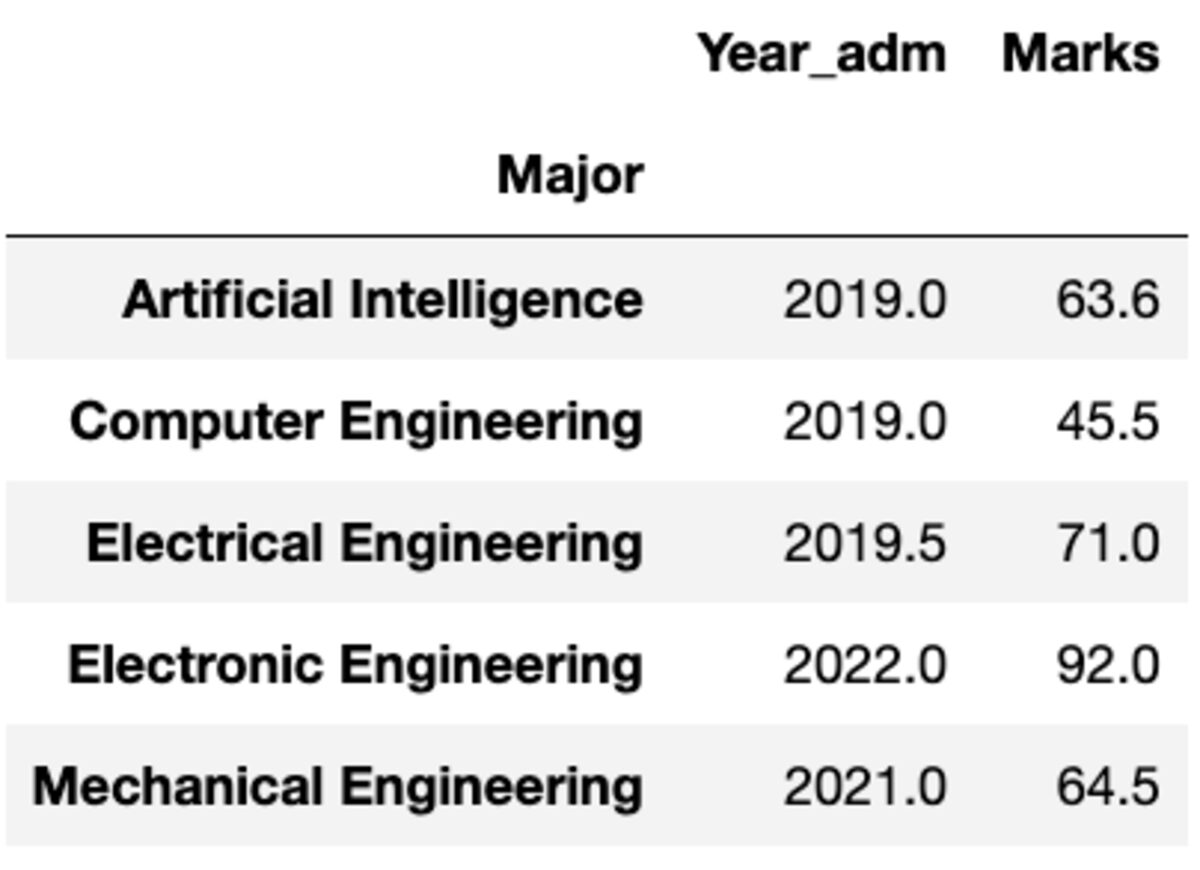
但是如果您需要将不同的函数应用于不同的列该怎么办? 不用担心。 您还可以通过传递 {column: function} 对来做到这一点。
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
变换
您可能非常需要对特定列执行自定义转换,这可以使用 groupby() 轻松实现。 让我们定义一个与 sklearn 预处理模块中可用的标准标量类似的标准标量。 您可以通过调用转换方法并传递自定义函数来转换所有列。
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
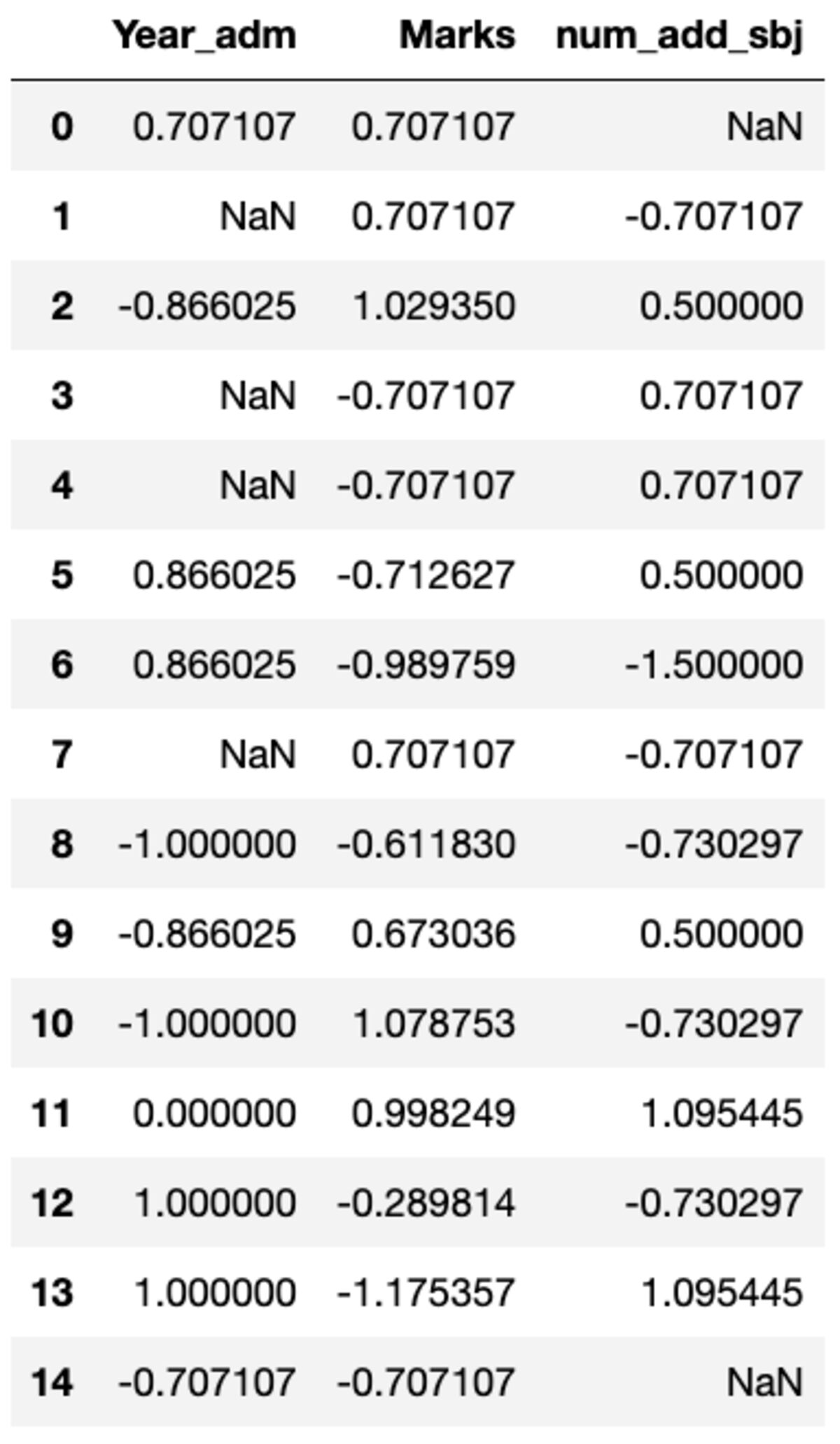
请注意,“NaN”表示标准差为零的组。
筛选器
您可能想检查哪个“专业”表现不佳,即平均学生“分数”低于 60 分的专业。它要求您对内部有函数的组应用过滤方法。 下面的代码使用了 拉姆达函数 以达到过滤后的结果。
groups.filter(lambda x: x['Marks'].mean() 60)

姓氏:
它为您提供按索引排序的第一个实例。
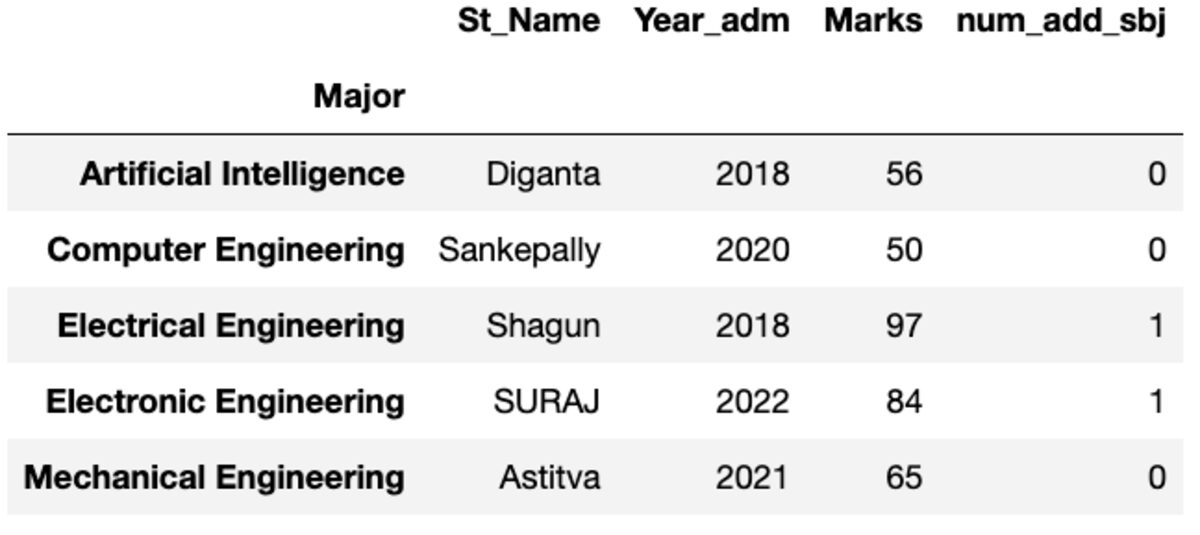
groups.first()
描述
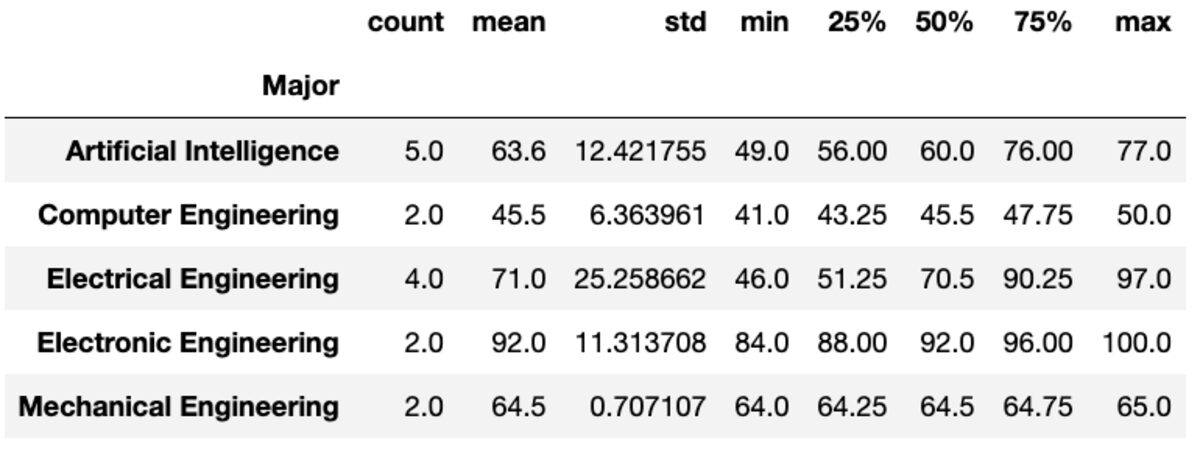
“describe”方法返回给定列的基本统计信息,例如计数、平均值、标准差、最小值、最大值等。
groups['Marks'].describe()
尺寸
Size,顾名思义,以记录数的形式返回每个组的大小。
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64计数和努尼克
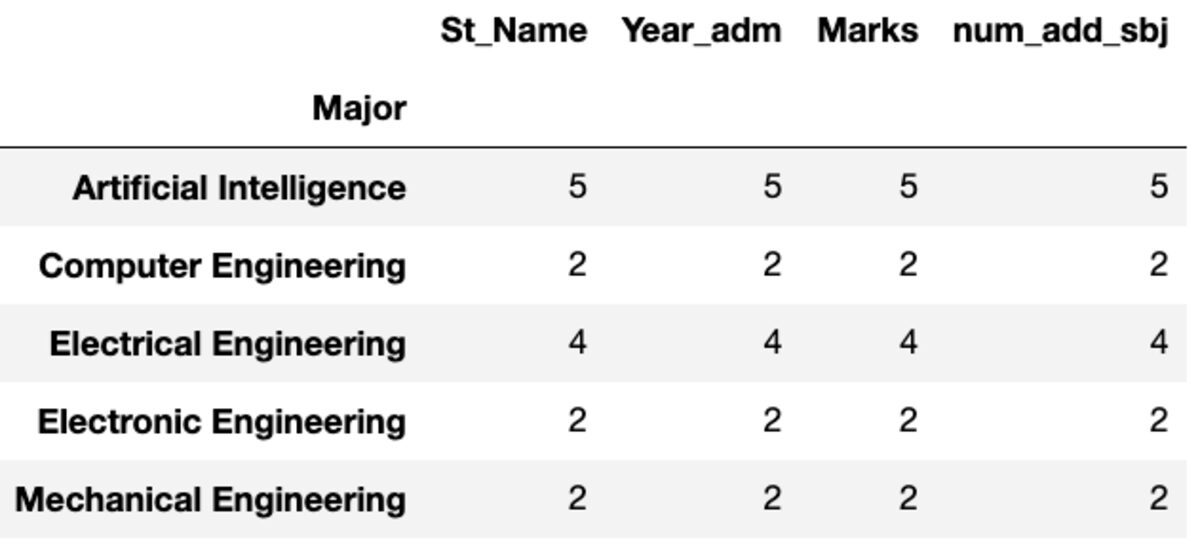
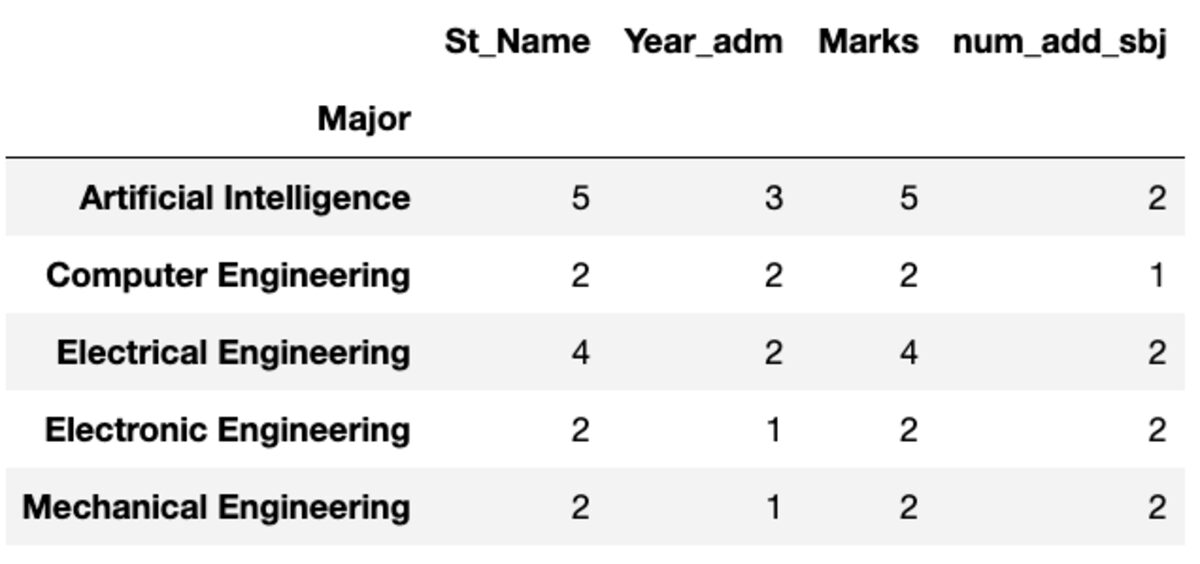
“Count”返回所有值,而“Nunique”仅返回该组中的唯一值。
groups.count()
groups.nunique()
重命名
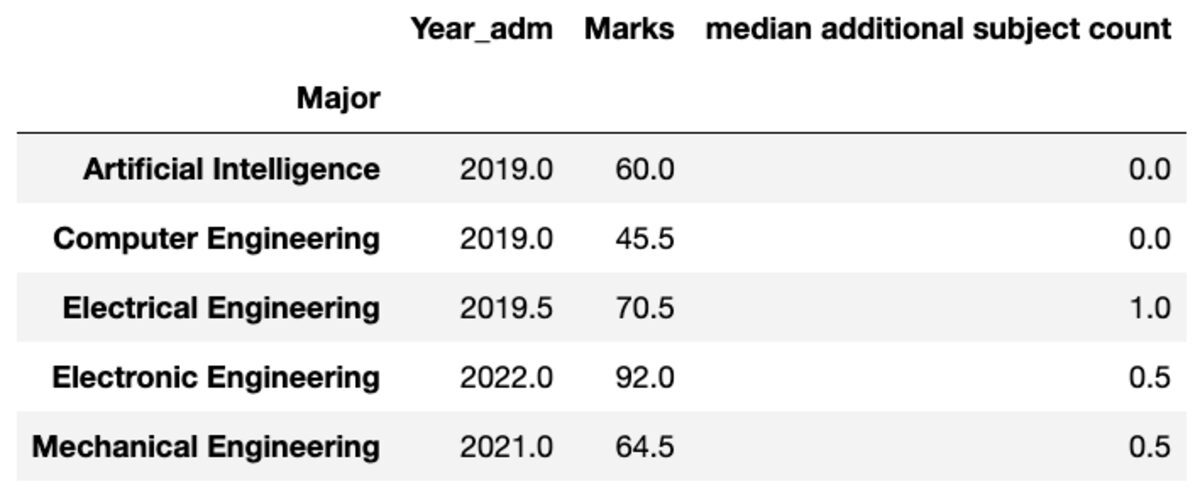
您还可以根据您的喜好重命名聚合列的名称。
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- 明确 groupby 的目的: 您是否试图按一列对数据进行分组以获得另一列的平均值? 或者您是否尝试按多列对数据进行分组以获取每组中的行数?
- 了解数据框的索引: groupby 函数使用索引对数据进行分组。 如果要按列对数据进行分组,请确保将该列设置为索引,或者可以使用 .set_index()
- 使用适当的聚合函数:它可以与各种聚合函数一起使用,例如mean()、sum()、count()、min()、max()
- 使用 as_index 参数: 当设置为 False 时,此参数告诉 pandas 使用分组列作为常规列而不是索引。
您还可以将 groupby() 与其他 pandas 函数(例如pivot_table()、crosstab() 和 cut())结合使用,从数据中提取更多见解。
groupby 函数是一种强大的数据分析和操作工具,因为它允许您根据一列或多列对数据行进行分组,然后对组执行聚合计算。 本教程借助代码示例演示了使用 groupby 函数的各种方法。 希望它能让您了解它附带的不同选项以及它们如何帮助数据分析。
维迪·楚(Vidhi Chugh) 是一名 AI 战略家和数字转型领导者,致力于产品、科学和工程的交叉领域,以构建可扩展的机器学习系统。 她是屡获殊荣的创新领袖、作家和国际演说家。 她的使命是使机器学习民主化并打破行话,让每个人都成为这一转变的一部分。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- 对,能力--
- Able
- 实现
- 额外
- 另外
- 聚合
- AI
- 所有类型
- 允许
- 分析
- 分析
- 和
- 另一个
- 应用的
- 使用
- 应用
- 适当
- 人造的
- 人工智能
- 作者
- 可使用
- 屡获殊荣
- 基于
- 基本包
- 如下。
- 生物技术
- 午休
- 建立
- 计算
- 调用
- 案件
- 查
- 清除
- 码
- 柱
- 列
- 如何
- 复杂
- 一台
- 计算机工程
- 创建信息图
- 创造
- 习俗
- data
- 数据分析
- 数据集
- 民主化
- 证明
- 偏差
- 不同
- 数字
- 数字化改造
- 直接
- 别
- 每
- 容易
- 只
- 电气工程
- 电子
- 工程师
- 等
- 每个人
- 例子
- 例子
- 提取
- 秋季
- 特征
- 填
- 过滤
- 找到最适合您的地方
- 姓氏:
- 专注焦点
- 以下
- FRAME
- 止
- 功能
- 功能
- 生成
- 得到
- 特定
- 给
- 去
- 团队
- 组的
- 动手
- 帮助
- 抱有希望
- 创新中心
- How To
- HTML
- HTTPS
- 进口
- in
- 令人难以置信
- 指数
- 創新
- 可行的洞见
- 例
- 代替
- 房源搜索
- 国际
- 路口
- IT
- 行话
- 掘金队
- 键
- 大
- 领导者
- 学习用品
- 学习
- 库
- 自学资料库
- 清单
- LOOKS
- 机
- 机器学习
- 主要
- 使
- 操作
- 许多
- 匹配
- 最大
- 机械
- 机械工业
- 中等
- 方法
- 使命
- 模块
- 更多
- 多
- 姓名
- 名称
- 需求
- 下页
- 数
- 一
- 开放源码
- 运营
- 附加选项
- 其他名称
- 大熊猫
- 参数
- 部分
- 特别
- 通过
- 演出
- 地方
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 强大
- 打印
- 产品
- 提供
- 目的
- 蟒蛇
- 很快
- 随机
- 建议
- 记录
- 定期
- 其余
- 代表
- 需要
- REST的
- 导致
- 成果
- 回报
- 回报
- 理查德
- 圆
- 运行
- 同
- 可扩展性
- 科学
- 集
- 应该
- 如图
- 类似
- 单
- 尺寸
- 一些
- 喇叭
- 具体的
- 标准
- 统计
- 步
- 战略家
- 学生
- 学生
- 主题
- 提示
- 总结
- 产品
- 任务
- 任务
- 告诉
- 条款
- 类型
- 至
- 工具
- 改造
- 转型
- 转换
- 教程
- 类型
- 理解
- 独特
- 使用
- 价值观
- 各个
- 方法
- 什么是
- 这
- 将
- 加工
- 将
- X
- 年
- 您一站式解决方案
- 和风网
- 零







