图片由编辑
关键精华
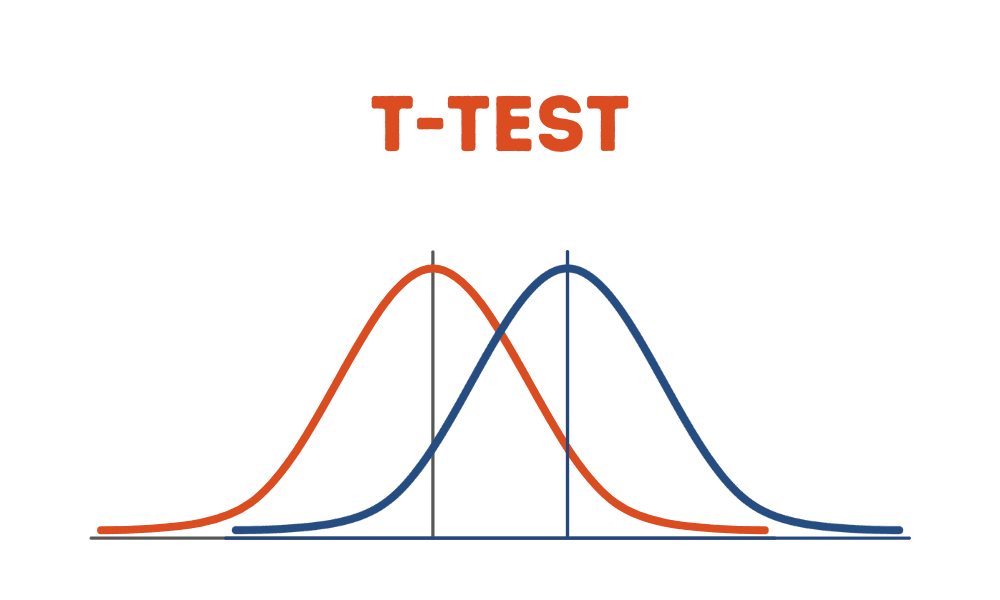
- t 检验是一种统计检验,可用于确定两个独立数据样本的均值之间是否存在显着差异。
- 我们说明了如何使用 iris 数据集和 Python 的 Scipy 库应用 t 检验。
t 检验是一种统计检验,可用于确定两个独立数据样本的均值之间是否存在显着差异。 在本教程中,我们将说明 t 检验的最基本版本,为此我们将假设两个样本具有相等的方差。 t 检验的其他高级版本包括 Welch 的 t 检验,它是 t 检验的一种改编,当两个样本具有不相等的方差和可能不相等的样本量时更可靠。
t 统计量或 t 值计算如下:
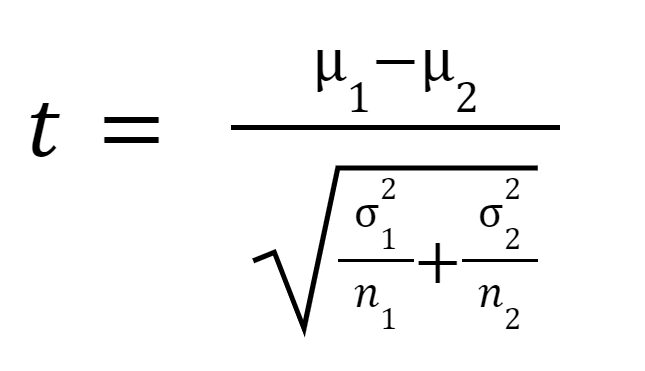
哪里
是样本 1 的平均值,
是样本 2 的平均值,
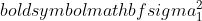 是样本1的方差,
是样本1的方差, 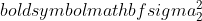 是样本2的方差,
是样本2的方差, 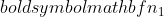 是样本 1 的样本量,并且
是样本 1 的样本量,并且 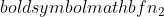 是样本 2 的样本量。
是样本 2 的样本量。
为了说明 t 检验的使用,我们将展示一个使用 iris 数据集的简单示例。 假设我们观察到两个独立的样本,例如花萼片长度,并且我们正在考虑这两个样本是来自同一种群(例如,同一种类的花或具有相似萼片特征的两种植物)还是两个不同的种群。
t检验量化了两个样本的算术平均值之间的差异。 p 值量化获得观察结果的概率,假设零假设(样本是从具有相同总体均值的总体中抽取的)为真。 大于选定阈值(例如 5% 或 0.05)的 p 值表明我们的观察不太可能是偶然发生的。 因此,我们接受人口均值相等的原假设。 如果 p 值小于我们的阈值,那么我们就有证据反对人口均值相等的原假设。
T 检验输入
执行 t 检验所需的输入或参数是:
- 两个数组 a 和 b 包含样本 1 和样本 2 的数据
T 检验输出
t 检验返回以下内容:
- 计算的 t 统计量
- p值
导入必要的库
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
加载虹膜数据集
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
计算样本均值和样本方差
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
实施 t 检验
stats.ttest_ind(a_1, b_1, equal_var = False)
输出
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
输出
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
输出
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)观察
我们观察到对“equal-var”参数使用“true”或“false”不会对 t 检验结果产生太大影响。 我们还观察到,交换样本数组 a_1 和 b_1 的顺序会产生负的 t 检验值,但不会像预期的那样改变 t 检验值的大小。 由于计算出的 p 值远大于阈值 0.05,我们可以拒绝原假设,即样本 1 和样本 2 的均值之间的差异显着。 这表明样本 1 和样本 2 的萼片长度来自相同的种群数据。
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
计算样本均值和样本方差
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
实施 t 检验
stats.ttest_ind(a_1, b_1, equal_var = False)
输出
stats.ttest_ind(a_1, b_1, equal_var = False)观察
我们观察到使用大小不等的样本不会显着改变 t 统计量和 p 值。
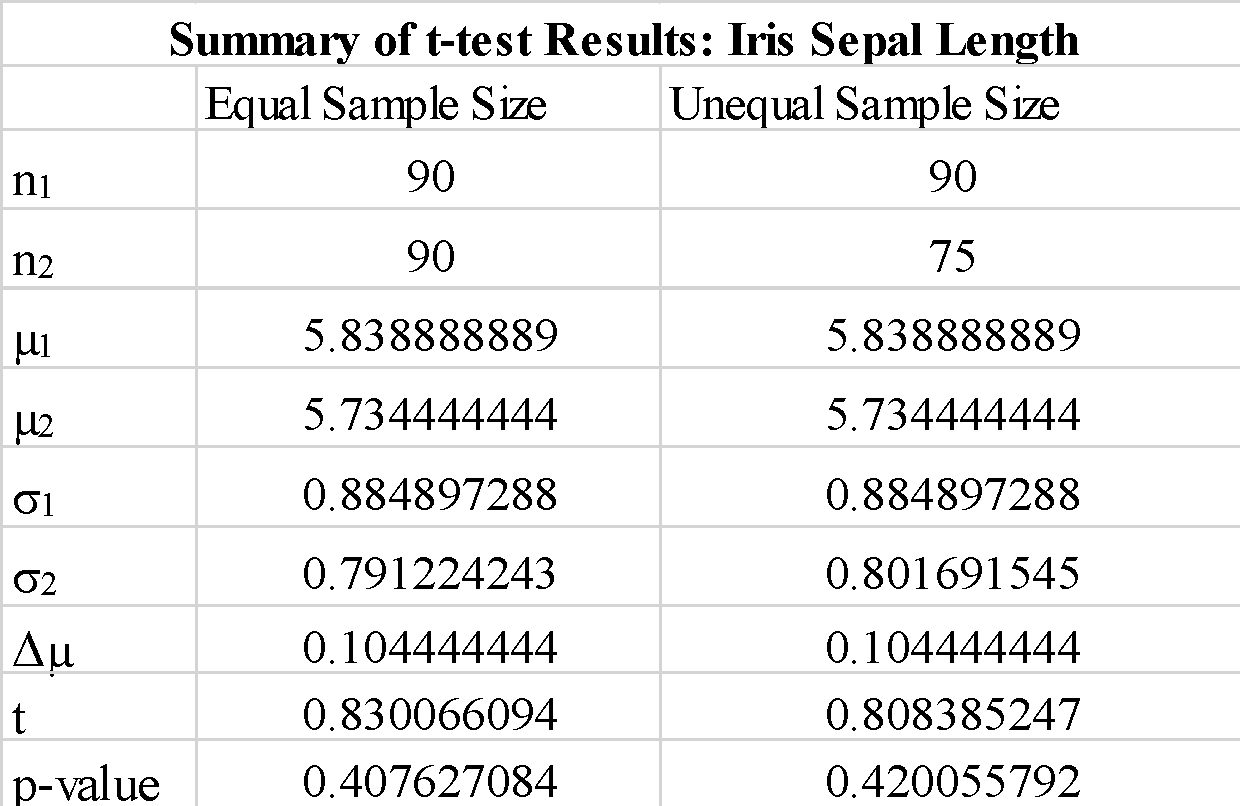
总之,我们展示了如何使用 python 中的 scipy 库实现简单的 t 检验。
本杰明·O·塔约 是物理学家、数据科学教育家和作家,也是 DataScienceHub 的所有者。 此前,本杰明在俄克拉荷马州中部大学、大峡谷大学和匹兹堡州立大学教授工程和物理。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python