亚马逊Redshift 是一个快速、完全托管的 PB 级云数据仓库,可让您使用标准 SQL 和现有商业智能 (BI) 工具轻松且经济高效地分析所有数据。 如今,数以万计的客户使用 Amazon Redshift 来分析 EB 级数据并运行分析查询,使其成为使用最广泛的云数据仓库。 Amazon Redshift 可用于无服务器配置和预配置配置。
Amazon Redshift 使您能够直接访问存储在 亚马逊简单存储服务 (Amazon S3) 使用 SQL 查询并连接数据仓库和数据湖中的数据。 借助 Amazon Redshift,您可以使用中央数据库查询 S3 数据湖中的数据 AWS胶水 来自 Redshift 数据仓库的元存储。
Amazon Redshift 支持查询各种数据格式,例如 CSV、JSON、Parquet 和 ORC,以及表格式(例如 Apache Hudi 和 Delta)。 Amazon Redshift 还支持查询结构体、数组和映射等复杂数据类型的嵌套数据。
借助此功能,Amazon Redshift 能够以经济高效的方式将您的 PB 级数据仓库扩展到 Amazon S3 上的 EB 级数据湖。
Apache Iceberg 是 Amazon Redshift 预览版现在支持的最新表格式。 在这篇文章中,我们将向您展示如何使用 Amazon Redshift 查询 Iceberg 表,并探索 Iceberg 支持和选项。
解决方案概述
阿帕奇·冰山 是一种适用于非常大的 PB 级分析数据集的开放表格式。 Iceberg 将大型文件集合作为表进行管理,并支持现代分析数据湖操作,例如记录级插入、更新、删除和时间旅行查询。 Iceberg 规范允许无缝表演化,例如架构和分区演化,其设计针对 Amazon S3 上的使用进行了优化。
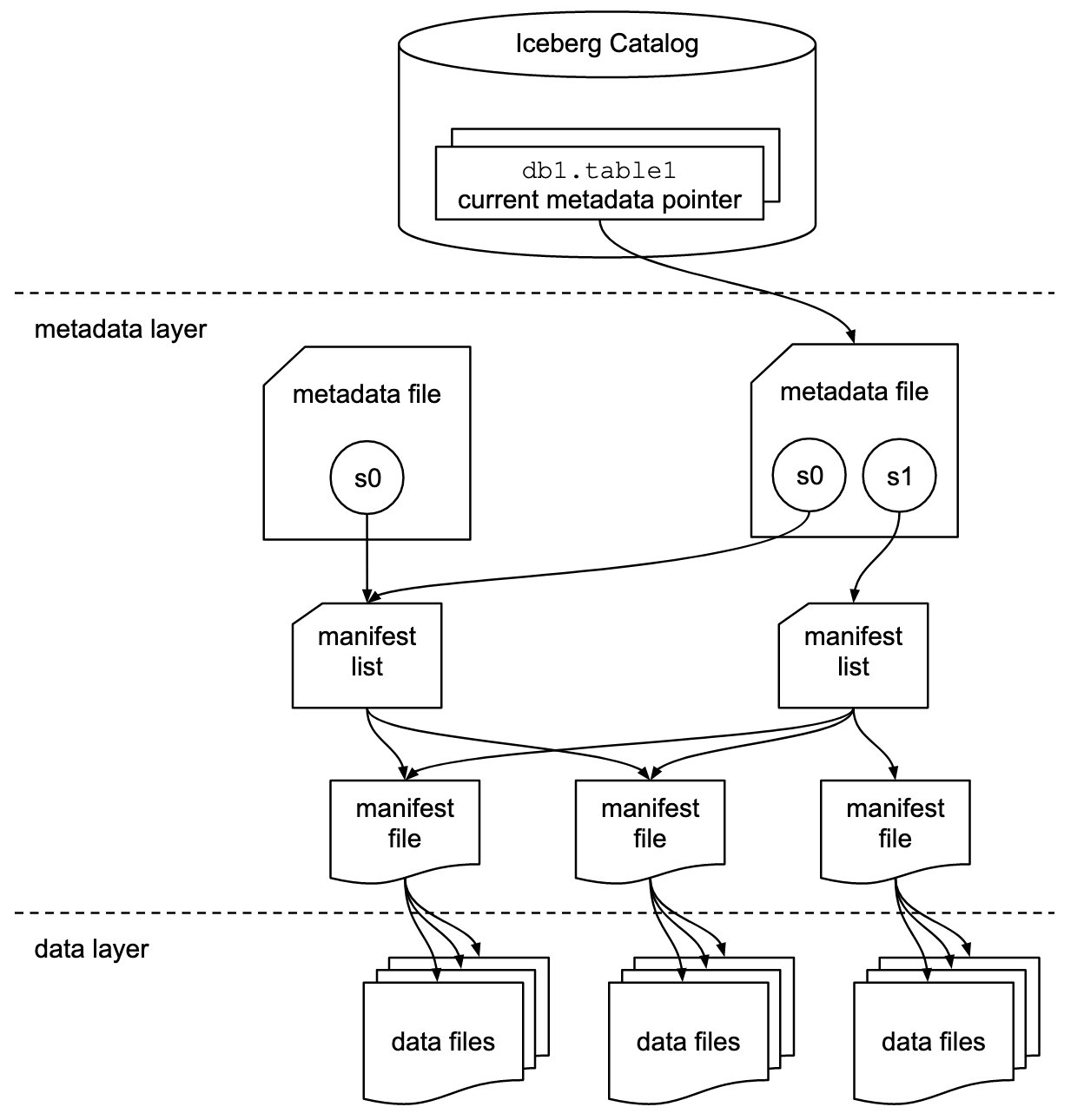
Iceberg 存储所有元数据文件的元数据指针。 当 SELECT 查询读取 Iceberg 表时,查询引擎首先进入 Iceberg 目录,然后检索最新元数据文件位置的条目,如下图所示。
Amazon Redshift 现在提供对 Apache Iceberg 表的支持,这允许数据湖客户以事务一致的方式运行只读分析查询。 这使您能够轻松管理和维护事务数据湖上的表。
Amazon Redshift 使用以下方式支持 Apache Iceberg 的本机架构和分区演化功能: AWS Glue数据目录,无需更改表定义来添加新分区或移动和处理大量数据来更改现有数据湖表的架构。 Amazon Redshift 使用 Apache Iceberg 表元数据中存储的列统计信息来优化其查询计划并减少运行查询所需的文件扫描。
在这篇文章中,我们使用 来自纽约市出租车和豪华轿车委员会的黄色出租车公共数据集 作为我们的源数据。 数据集包含数据文件 阿帕奇木地板 Amazon S3 上的格式。 我们用 亚马逊雅典娜 转换此 Parquet 数据集,然后使用 亚马逊红移频谱 查询并联接 Redshift 本地表、执行行级删除和更新以及分区演变,所有这些都通过 S3 数据湖中的 AWS Glue 数据目录进行协调。
先决条件
您应该具备以下先决条件:
将 Parquet 数据转换为 Iceberg 表
对于这篇文章,您需要 来自纽约市出租车和豪华轿车委员会的黄色出租车公共数据集 以冰山格式提供。 您可以下载文件,然后使用 Athena 将 Parquet 数据集转换为 Iceberg 表,或者参考 使用 Amazon Athena、Amazon EMR 和 AWS Glue 构建 Apache Iceberg 数据湖 创建 Iceberg 表的博客文章。
在这篇文章中,我们使用 Athena 来转换数据。 完成以下步骤:
- 使用前面的链接下载文件或使用 AWS命令行界面 (AWS CLI) 使用以下命令将文件从 3 年和 2020 年的公共 S2021 存储桶复制到您的 S3 存储桶:
有关更多信息,请参阅 设置 Amazon Redshift CLI.
- 建立资料库
Icebergdb并使用 Athena 创建一个表,使用以下语句指向 Parquet 格式文件: - 使用以下 SQL 验证 Parquet 表中的数据:

- 使用以下代码在 Athena 中创建一个 Iceberg 表。 您可以将表类型属性视为具有 Parquet 格式和快速压缩的 Iceberg 表,如下所示
create table陈述。 您需要在运行 SQL 之前更新 S3 位置。 另请注意,Iceberg 表是按以下方式分区的Year键。 - 创建表后,使用之前加载的 Parquet 表将数据加载到 Iceberg 表中
nyc_taxi_yellow_parquet使用以下 SQL: - SQL语句完成后,验证Iceberg表中的数据
nyc_taxi_yellow_iceberg。 在进入下一步之前需要执行此步骤。 - 您可以使用以下命令验证 nyc_taxi_yellow_iceberg 表是否采用 Iceberg 格式表并在 Year 列上进行分区:



在 Amazon Redshift 中创建外部架构
在本部分中,我们演示如何在 Amazon Redshift 中创建指向 AWS Glue 数据库的外部架构 icebergdb 查询 Iceberg 表 nyc_taxi_yellow_iceberg 我们在上一节中看到使用 Athena。
通过以下方式登录 Redshift 查询编辑器 v2 或 SQL 客户端并运行以下命令(请注意,AWS Glue 数据库 icebergdb 和正在使用的区域信息):

要了解如何在 Amazon Redshift 中创建外部架构,请参阅 创建外部模式
创建外部架构后 spectrum_iceberg_schema,您可以查询 Amazon Redshift 中的 Iceberg 表。
查询 Amazon Redshift 中的 Iceberg 表
在查询编辑器 v2 中运行以下查询。 注意 spectrum_iceberg_schema 是在 Amazon Redshift 中创建的外部架构的名称, nyc_taxi_yellow_iceberg 是查询中使用的 AWS Glue 数据库中的表:
以下屏幕截图中的查询数据输出显示可以使用 Redshift Spectrum 查询 Iceberg 格式的 AWS Glue 表。

检查查询Iceberg表的解释计划
您可以使用以下查询来获取解释计划输出,其显示格式为 ICEBERG:

验证更新以确保数据一致性
Iceberg 表更新完成后,您可以查询 Amazon Redshift 以查看数据的事务一致视图。 让我们通过选择一个来运行查询 vendorid 对于特定的接送服务:

接下来,更新值 passenger_count 到4和 trip_distance 到 9.4 vendorid 以及雅典娜的某些接送日期:

最后,在查询编辑器 v2 中运行以下查询以查看更新后的值 passenger_count 和 trip_distance:
如下图所示,Iceberg 表的更新操作可在 Amazon Redshift 中进行。

在 Amazon Redshift 中创建本地表和历史数据的统一视图
作为现代数据架构策略,您可以在数据湖中组织历史数据或不常访问的数据,并将经常访问的数据保留在 Redshift 数据仓库中。 这提供了大规模管理分析并找到最具成本效益的架构解决方案的灵活性。
在此示例中,我们将 2 年的数据加载到 Redshift 表中; 其余数据保留在 S3 数据湖中,因为该数据集的查询频率较低。
- 使用以下代码加载2年的数据
nyc_taxi_yellow_recentAmazon Redshift 中的表,源自 Iceberg 表:
- 接下来,您可以在 Athena 中使用以下命令从 Iceberg 表中删除过去 2 年的数据,因为您在上一步中已将数据加载到 Redshift 表中:

完成这些步骤后,Redshift 表拥有 2 年的数据,其余数据位于 Amazon S3 的 Iceberg 表中。
- 使用创建视图
nyc_taxi_yellow_iceberg冰山桌和nyc_taxi_yellow_recentAmazon Redshift 中的表: - 现在查询视图,根据过滤条件,Redshift Spectrum 将扫描 Iceberg 数据、Redshift 表或两者。 以下示例查询通过扫描两个表从每个源表返回许多记录:

分区演变
冰山用途 隐藏分区,这意味着您无需手动为 Apache Iceberg 表添加分区。 Amazon Redshift 会自动检测 Apache Iceberg 表中的新分区值或新分区规范(添加或删除分区列),无需手动操作即可更新表定义中的分区。 以下示例演示了这一点。
在我们的示例中,如果 Iceberg 表 nyc_taxi_yellow_iceberg 最初按年份分区,后来按列分区 vendorid 添加为附加分区列,然后 Amazon Redshift 可以无缝查询 Iceberg 表 nyc_taxi_yellow_iceberg 在一段时间内使用两种不同的分区方案。

使用 Amazon Redshift 查询 Iceberg 表时的注意事项
在预览期间,将 Amazon Redshift 与 Iceberg 表结合使用时请考虑以下事项:
- 仅支持 AWS Glue 数据目录中定义的 Iceberg 表。
- 不支持 CREATE 或 ALTER 外部表命令,这意味着 Iceberg 表应该已存在于 AWS Glue 数据库中。
- 不支持时间旅行查询。
- 支持 Iceberg 版本 1 和 2。 有关 Iceberg 格式版本的更多详细信息,请参阅 格式版本控制.
- 有关 Iceberg 表支持的数据类型的列表,请参阅 Apache Iceberg 表支持的数据类型(预览).
- 查询 Iceberg 表的定价与使用 Amazon Redshift 访问任何其他数据格式的定价相同。
有关 Iceberg 格式表预览注意事项的更多详细信息,请参阅 将 Apache Iceberg 表与 Amazon Redshift 结合使用(预览).
客户的反馈意见
“Tinuiti 是最大的独立绩效营销公司,每天处理大量数据,必须拥有强大的数据湖和数据仓库策略,以便我们的市场情报团队能够以简单、经济、安全的方式存储和分析所有客户数据。以及稳健的方式,”Tinuiti 首席技术官 Justin Manus 说道。 “Amazon Redshift 对我们数据湖中的 Apache Iceberg 表(单一事实来源)的支持解决了优化性能和可访问性方面的关键挑战,并进一步简化了我们的数据集成管道,以访问从不同来源提取的所有数据,并为我们的数据提供支持。客户的品牌潜力。”
结论
在这篇文章中,我们向您展示了一个使用存储在 Amazon S3 中的文件(在 AWS Glue 数据目录中编目为表)在 Redshift 中查询 Iceberg 表的示例,并演示了一些关键功能,例如高效的行级更新和删除、以及用户使用 Athena 释放大数据力量的模式演化体验。
您可以使用 Amazon Redshift 对各种文件和表格式的数据湖表运行查询,例如 阿帕奇·胡迪 和 三角洲湖,现在 Apache 冰山(预览),它为您的现代数据架构需求提供了额外的选项。
我们希望这能为您在 Amazon Redshift 中查询 Iceberg 表提供一个良好的起点。
作者简介
 罗希特·班萨尔(Rohit Bansal) 是 AWS 的分析专家解决方案架构师。 他擅长 Amazon Redshift,并与客户合作使用其他 AWS Analytics 服务构建下一代分析解决方案。
罗希特·班萨尔(Rohit Bansal) 是 AWS 的分析专家解决方案架构师。 他擅长 Amazon Redshift,并与客户合作使用其他 AWS Analytics 服务构建下一代分析解决方案。
 萨蒂什·萨蒂亚 是 Amazon Redshift 的高级产品工程师。 他是一位狂热的大数据爱好者,他与全球客户合作以取得成功并满足他们的数据仓库和数据湖架构需求。
萨蒂什·萨蒂亚 是 Amazon Redshift 的高级产品工程师。 他是一位狂热的大数据爱好者,他与全球客户合作以取得成功并满足他们的数据仓库和数据湖架构需求。
 兰詹·伯曼 是 AWS 的分析专家解决方案架构师。 他专注于 Amazon Redshift 并帮助客户构建可扩展的分析解决方案。 他在不同的数据库和数据仓库技术方面拥有超过 16 年的经验。 他热衷于使用云解决方案自动化和解决客户问题。
兰詹·伯曼 是 AWS 的分析专家解决方案架构师。 他专注于 Amazon Redshift 并帮助客户构建可扩展的分析解决方案。 他在不同的数据库和数据仓库技术方面拥有超过 16 年的经验。 他热衷于使用云解决方案自动化和解决客户问题。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 汽车/电动汽车, 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- 图表Prime。 使用 ChartPrime 提升您的交易游戏。 访问这里。
- 块偏移量。 现代化环境抵消所有权。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :具有
- :是
- :不是
- :在哪里
- $UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- 关于
- ACCESS
- 访问
- 访问
- 访问
- 横过
- 加
- 添加
- 额外
- 地址
- 实惠
- 所有类型
- 允许
- 已经
- 还
- Amazon
- 亚马逊雅典娜
- 亚马逊电子病历
- 亚马逊网络服务
- 量
- an
- 解析
- 分析
- 分析
- 分析
- 和
- 任何
- 阿帕奇
- 架构
- 保健
- 围绕
- 排列
- AS
- At
- 自动
- 自动化
- 可使用
- AWS
- AWS胶水
- 基础
- 因为
- before
- 作为
- 大
- 大数据运用
- 捆绑
- 博客
- 都
- 品牌
- 建立
- 商业
- 商业智能
- by
- CAN
- 能力
- 能力
- 检索目录
- 中央
- 一定
- 挑战
- 更改
- 首席
- 首席技术官
- 客户
- 云端技术
- 码
- 收藏
- 柱
- 列
- 完成
- 复杂
- 条件
- 考虑
- 注意事项
- 一贯
- 包含
- 兑换
- 协调
- 经济有效
- 创建信息图
- 创建
- 创造
- 危急
- 顾客
- 客户数据
- 合作伙伴
- 每天
- data
- 数据集成
- 数据湖
- 数据仓库
- 数据库
- 数据集
- 重要日期
- 默认
- 定义
- 定义
- 定义
- Delta
- 演示
- 证明
- 演示
- 根据
- 设计
- 详情
- 检测
- 开发
- 不同
- 直接
- 别
- 翻番
- 下载
- 每
- 容易
- 易
- 编辑
- 高效
- 或
- 消除
- 使
- 发动机
- 工程师
- 爱好者
- 条目
- 醚(ETH)
- 进化
- 例子
- 存在
- 现有
- 体验
- 说明
- 探索
- 扩展
- 外部
- 额外
- 高效率
- 特征
- 文件
- 档
- 过滤
- 找到最适合您的地方
- 公司
- (名字)
- 高度灵活
- 以下
- 针对
- 格式
- 频繁
- 止
- 充分
- 进一步
- 得到
- 给
- 地球
- GOES
- 大
- 团队
- 手柄
- 有
- he
- 帮助
- 历史的
- 抱有希望
- 创新中心
- How To
- HTML
- HTTP
- HTTPS
- if
- in
- 独立
- 信息
- 积分
- 房源搜索
- 成
- IT
- 它的
- 加入
- JPG
- JSON
- 贾斯汀
- 保持
- 键
- 湖泊
- 大
- 最大
- (姓氏)
- 后来
- 最新
- 学习用品
- 减
- 喜欢
- 极限
- Line
- 友情链接
- 清单
- 加载
- 本地
- 圖書分館的位置
- 保持
- 制作
- 制作
- 管理
- 管理
- 管理
- 方式
- 手册
- 手动
- 地图
- 市场
- 营销
- 手段
- 满足
- 元数据
- 现代
- 更多
- 最先进的
- 移动
- 移动
- 必须
- 姓名
- 本地人
- 需求
- 打印车票
- 需要
- 全新
- 下页
- 下一代
- 没有
- 注意
- 现在
- 数
- 纽约市
- of
- 官
- on
- 打开
- 操作
- 运营
- 优化
- 优化
- 追求项目的积极优化
- 附加选项
- or
- 本来
- 其他名称
- 我们的
- 产量
- 超过
- 页
- 多情
- 演出
- 性能
- 期间
- 计划
- 计划
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 点
- 帖子
- 潜力
- 功率
- 先决条件
- 预览
- 以前
- 先前
- 问题
- 过程
- 产品
- 提供
- 国家
- 查询
- 阅读
- 记录
- 减少
- 地区
- 去掉
- 更换
- 必须
- REST的
- 回报
- 健壮
- 运行
- 运行
- 同
- 锯
- 说
- 可扩展性
- 鳞片
- 浏览
- 扫描
- 扫描
- 方案
- 无缝的
- 无缝
- 部分
- 安全
- 看到
- 前辈
- 无服务器
- 特色服务
- 集
- 应该
- 显示
- 显示
- 如图
- 作品
- 简易
- 单
- 方案,
- 解决方案
- 解决
- 一些
- 来源
- 来源
- 采购
- 专家
- 专业
- 规范
- 眼镜
- 光谱
- SQL
- 标准
- 开始
- 个人陈述
- 统计
- 步
- 步骤
- 存储
- 商店
- 存储
- 商店
- 策略
- 串
- 成功
- 这样
- SUPPORT
- 支持
- 支持
- 表
- 队
- 技术
- 专业技术
- HAST
- 比
- 这
- 其
- 然后
- 博曼
- Free Introduction
- 数千
- 通过
- 次
- 时间旅行
- 时间戳
- 至
- 今晚
- 工具
- 交易
- 旅行
- 真相
- 二
- 类型
- 类型
- 统一
- 工会
- 开锁
- 更新
- 更新
- 最新动态
- 用法
- 使用
- 用过的
- 用户
- 使用
- 运用
- 验证
- 折扣值
- 价值观
- 各种
- 各个
- 非常
- 通过
- 查看
- 卷
- 仓库保管
- 仓储服务
- 是
- 方法..
- we
- 卷筒纸
- Web服务
- ,尤其是
- 这
- WHO
- 宽
- 广泛
- 将
- 合作
- 年
- 年
- 您
- 您一站式解决方案
- 和风网