大型语言模型 (LLM) 越来越受欢迎,新的用例不断被探索。一般来说,您可以通过将即时工程合并到代码中来构建由法学硕士支持的应用程序。然而,在某些情况下,对现有的法学硕士的激励是不够的。这就是模型微调可以提供帮助的地方。提示工程是通过制作输入提示来指导模型的输出,而微调是在自定义数据集上训练模型,使其更适合特定的任务或领域。
在微调模型之前,您需要找到特定于任务的数据集。常用的一个数据集是 通用爬取数据集。 Common Crawl 语料库包含自 2008 年以来定期收集的 PB 级数据,并包含原始网页数据、元数据提取和文本提取。除了确定应使用哪个数据集之外,还需要根据微调的特定需求来清理和处理数据。
我们最近与一位客户合作,他想要预处理最新 Common Crawl 数据集的子集,然后使用清理后的数据微调他们的 LLM。客户正在寻找如何在 AWS 上以最具成本效益的方式实现这一目标。在讨论了需求之后,我们建议使用 Amazon EMR 无服务器 作为他们的数据预处理平台。 EMR Serverless 非常适合大规模数据处理,并且无需基础设施维护。在成本方面,它仅根据每个作业使用的资源和持续时间进行收费。客户能够使用 EMR Serverless 在一周内预处理数百 TB 的数据。他们对数据进行预处理后,使用 亚马逊SageMaker 微调LLM。
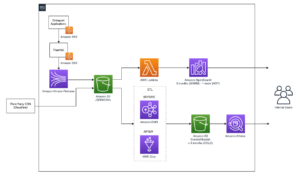
在这篇文章中,我们将引导您了解客户的用例和所使用的架构。
在下面的章节中,我们首先介绍 Common Crawl 数据集以及如何探索和过滤我们需要的数据。 亚马逊雅典娜 仅按扫描的数据大小收费,用于快速探索和过滤数据,同时具有成本效益。 EMR Serverless 为 Spark 数据处理提供了经济高效且免维护的选项,用于处理过滤后的数据。接下来,我们使用 亚马逊SageMaker JumpStart 来微调 骆驼2模型 与预处理的数据集。 SageMaker JumpStart 为最常见的用例提供了一组解决方案,只需单击几下即可部署。您不需要编写任何代码来微调 Llama 2 等 LLM。最后,我们使用以下命令部署微调后的模型 亚马逊SageMaker 并比较原始 Llama 2 模型和微调后的 Llama XNUMX 模型之间同一问题的文本输出差异。
下图说明了此解决方案的体系结构。
在深入了解解决方案详细信息之前,请完成以下先决步骤:
Common Crawl 是通过爬取超过 50 亿个网页获得的开放语料数据集。它包含多种语言的海量非结构化数据,从 2008 年开始,达到 PB 级别。它不断更新。
在GPT-3的训练中,Common Crawl数据集占其训练数据的60%,如下图所示(来源: 语言模型是学习者很少).
另一个值得一提的重要数据集是 C4数据集。 C4 是 Colossal Clean Crawled Corpus 的缩写,是对 Common Crawl 数据集进行后处理而得到的数据集。在 Meta 的 LLaMA 论文中,他们概述了所使用的数据集,其中 Common Crawl 占 67%(利用 3.3 TB 数据),C4 占 15%(利用 783 GB 数据)。该论文强调了合并不同预处理的数据对于增强模型性能的重要性。尽管原始 C4 数据是 Common Crawl 的一部分,但 Meta 选择了该数据的重新处理版本。
在本节中,我们将介绍交互、过滤和处理 Common Crawl 数据集的常见方法。
Common Crawl原始数据集包括三种类型的数据文件:原始网页数据(WARC)、元数据(WAT)和文本提取(WET)。
2013年后收集的数据以WARC格式存储,包括相应的元数据(WAT)和文本提取数据(WET)。数据集位于Amazon S3中,每月更新一次,可以直接通过 AWS Marketplace.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzCommon Crawl数据集还提供了一个用于过滤数据的索引表,称为cc-index-table。
cc-index-table 是现有数据的索引,提供基于表的 WARC 文件索引。它允许轻松查找信息,例如哪个 WARC 文件对应于特定的 URL。
例如,您可以使用以下代码创建 Athena 表来映射 cc-index 数据:
前面的 SQL 语句演示了如何创建 Athena 表、添加分区和运行查询。
从 Common Crawl 数据集中过滤数据
从建表SQL语句中可以看到,有几个字段可以帮助过滤数据。例如,如果要获取特定时间段内中文文档的数量,则 SQL 语句可以如下:
如果您想进行进一步处理,可以将结果保存到另一个S3存储桶中。
分析过滤后的数据
常见爬取 GitHub 存储库 提供了几个用于处理原始数据的 PySpark 示例。
我们来看一个运行的例子 server_count.py (Common Crawl GitHub 存储库提供的示例脚本)位于以下位置的数据 s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
首先,您需要一个Spark环境,例如EMR Spark。例如,您可以在 EC2 集群上启动 Amazon EMR us-east-1 (因为数据集位于 us-east-1)。在 EC2 集群上使用 EMR 可以帮助您在将作业提交到生产环境之前进行测试。
在 EC2 集群上启动 EMR 后,您需要通过 SSH 登录集群的主节点。然后,打包Python环境并提交脚本(参考 康达文档 安装 Miniconda):
处理 warc.path 中的所有引用可能需要一些时间。出于演示目的,您可以使用以下策略来缩短处理时间:
- 下载文件
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gz到本地计算机,解压缩,然后上传到 HDFS 或 Amazon S3。这是因为 .gzip 文件不可分割。您需要解压缩它才能并行处理该文件。 - 修改
warc.path文件,删除其大部分行,只保留两行以使作业运行得更快。
作业完成后,可以看到结果 s3://xxxx-common-crawl/output/,采用 Parquet 格式。
实现自定义拥有逻辑
Common Crawl GitHub 存储库提供了处理 WARC 文件的通用方法。一般来说,您可以延长 CCSparkJob 重写单个方法(process_record),这对于许多情况来说已经足够了。
让我们看一个获取最近电影的 IMDB 评论的示例。首先,您需要过滤掉 IMDB 网站上的文件:
然后,您可以获得包含 IMDB 审阅数据的 WARC 文件列表,并将 WARC 文件名作为列表保存在文本文件中。
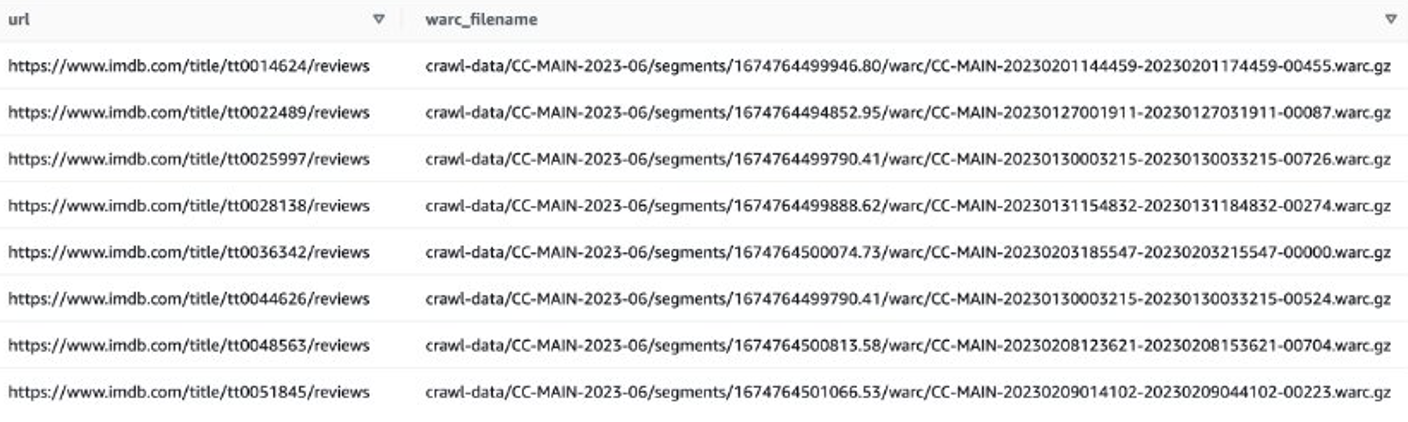
或者,您可以使用 EMR Spark 获取 WARC 文件列表并将其存储在 Amazon S3 中。例如:
输出文件应类似于 s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
下一步是从这些 WARC 文件中提取用户评论。您可以延长 CCSparkJob 覆盖 process_record() 方法:
您可以将前面的脚本保存为 imdb_extractor.py,您将在以下步骤中使用它。准备好数据和脚本后,您可以使用EMR Serverless来处理过滤后的数据。
EMR 无服务器
EMR Serverless 是一种无服务器部署选项,可使用 Apache Spark 和 Hive 等开源框架运行大数据分析应用程序,而无需配置、管理和扩展集群或服务器。
借助 EMR Serverless,您可以运行任何规模的分析工作负载,并通过自动扩展在几秒钟内调整资源大小,以满足不断变化的数据量和处理要求。 EMR Serverless 会自动扩展和缩减资源,以为您的应用程序提供适量的容量,并且您只需为使用的资源付费。
处理 Common Crawl 数据集通常是一项一次性处理任务,使其适合 EMR Serverless 工作负载。
创建 EMR 无服务器应用程序
您可以在 EMR Studio 控制台上创建 EMR Serverless 应用程序。完成以下步骤:
- 在 EMR Studio 控制台上,选择 应用领域 下 无服务器 在导航窗格中。
- 建立申请.

- 提供应用程序的名称并选择 Amazon EMR 版本。

- 如果需要访问 VPC 资源,请添加自定义网络设置。

- 建立申请.
然后您的 Spark 无服务器环境就准备好了。
在将作业提交到 EMR Spark Serverless 之前,您仍需要创建执行角色。参考 开始使用 Amazon EMR 无服务器 以获得更多细节。
使用 EMR Serverless 处理常见爬网数据
当您的 EMR Spark Serverless 应用程序准备就绪后,请完成以下步骤来处理数据:
- 准备一个Conda环境并上传到Amazon S3,该环境将作为EMR Spark Serverless中的环境。
- 将要运行的脚本上传到 S3 存储桶。在以下示例中,有两个脚本:
- imbd_extractor.py – 从数据集中提取内容的定制逻辑。内容可以在本文前面找到。
- cc-pyspark/sparkcc.py – 来自的示例 PySpark 框架 常见爬取 GitHub 存储库,这是必须包括在内的。
- 将 PySpark 作业提交到 EMR Serverless Spark。定义以下参数以在您的环境中运行此示例:
- 应用程序 ID – EMR 无服务器应用程序的应用程序 ID。
- 执行角色 arn – 您的 EMR 无服务器执行角色。要创建它,请参阅 创建作业运行时角色.
- WARC 文件位置 – WARC 文件的位置。
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt包含您在本文前面获得的已过滤的 WARC 文件列表。 - Spark.sql.warehouse.dir – 默认仓库位置(使用您的 S3 目录)。
- 火花档案 – 准备好的Conda环境的S3位置。
- Spark.submit.pyFiles – 准备好的PySpark脚本sparkcc.py。
请参见以下代码:
作业完成后,提取的评论将存储在 Amazon S3 中。要检查内容,您可以使用 Amazon S3 Select,如以下屏幕截图所示。
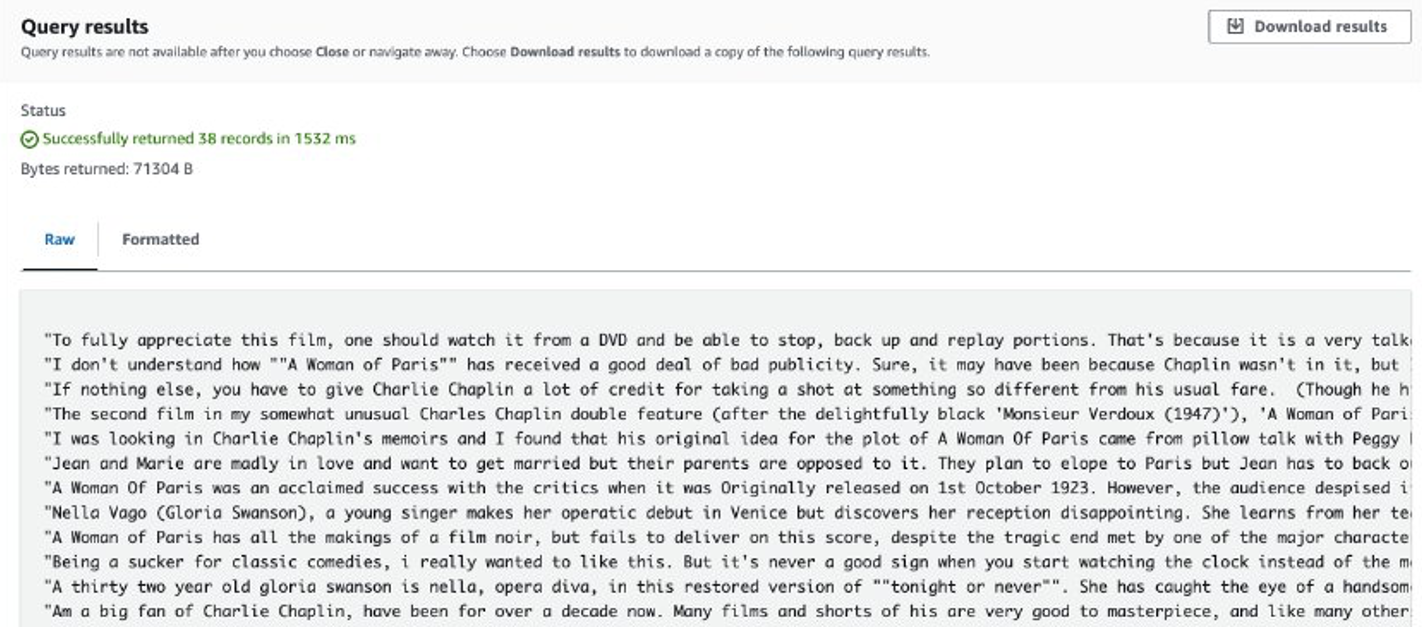
需要考虑的事项
使用定制代码处理海量数据时需要考虑以下几点:
- 某些第三方 Python 库可能在 Conda 中不可用。此时,您可以切换到Python虚拟环境来构建PySpark运行环境。
- 如果需要处理大量数据,请尝试创建并使用多个 EMR Serverless Spark 应用程序来并行处理。每个应用程序都处理文件列表的子集。
- 在过滤或处理常见爬网数据时,您可能会遇到 Amazon S3 速度下降的问题。这是因为存储数据的S3存储桶是可公开访问的,其他用户可以同时访问该数据。为了缓解此问题,您可以添加重试机制或将 Common Crawl S3 存储桶中的特定数据同步到您自己的存储桶。
使用 SageMaker 微调 Llama 2
数据准备好后,您可以用它微调 Llama 2 模型。您可以使用 SageMaker JumpStart 执行此操作,而无需编写任何代码。欲了解更多信息,请参阅 在 Amazon SageMaker JumpStart 上微调 Llama 2 以生成文本.
在这种情况下,您将执行域适应微调。对于此数据集,输入由 CSV、JSON 或 TXT 文件组成。您需要将所有评论数据放入 TXT 文件中。为此,您可以向 EMR Spark Serverless 提交一个简单的 Spark 作业。请参阅以下示例代码片段:
准备好训练数据后,输入数据位置 训练数据集,然后选择 培训.
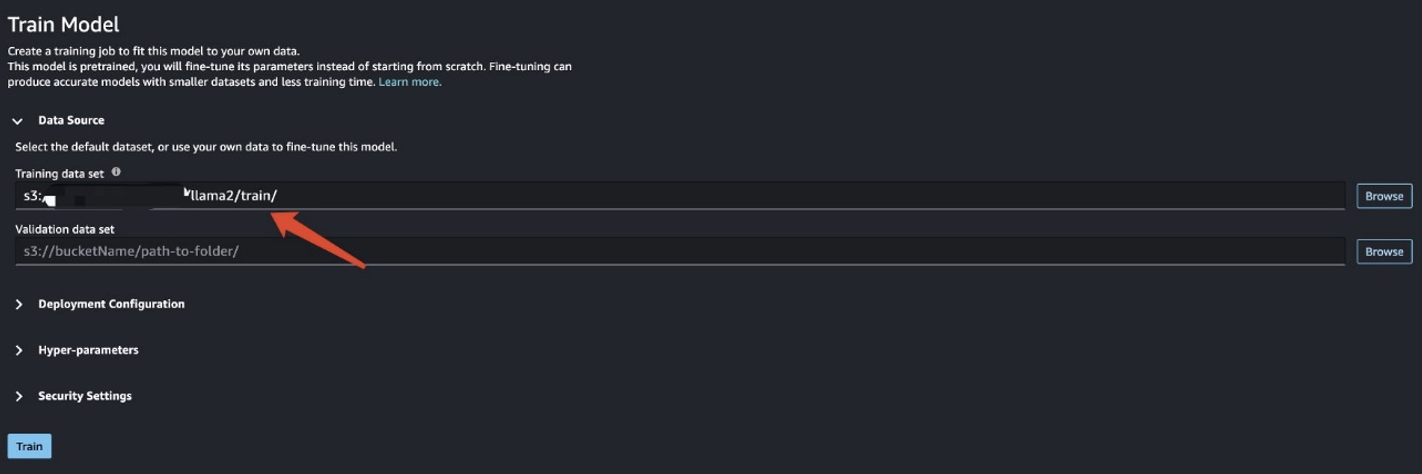
您可以跟踪训练作业状态。
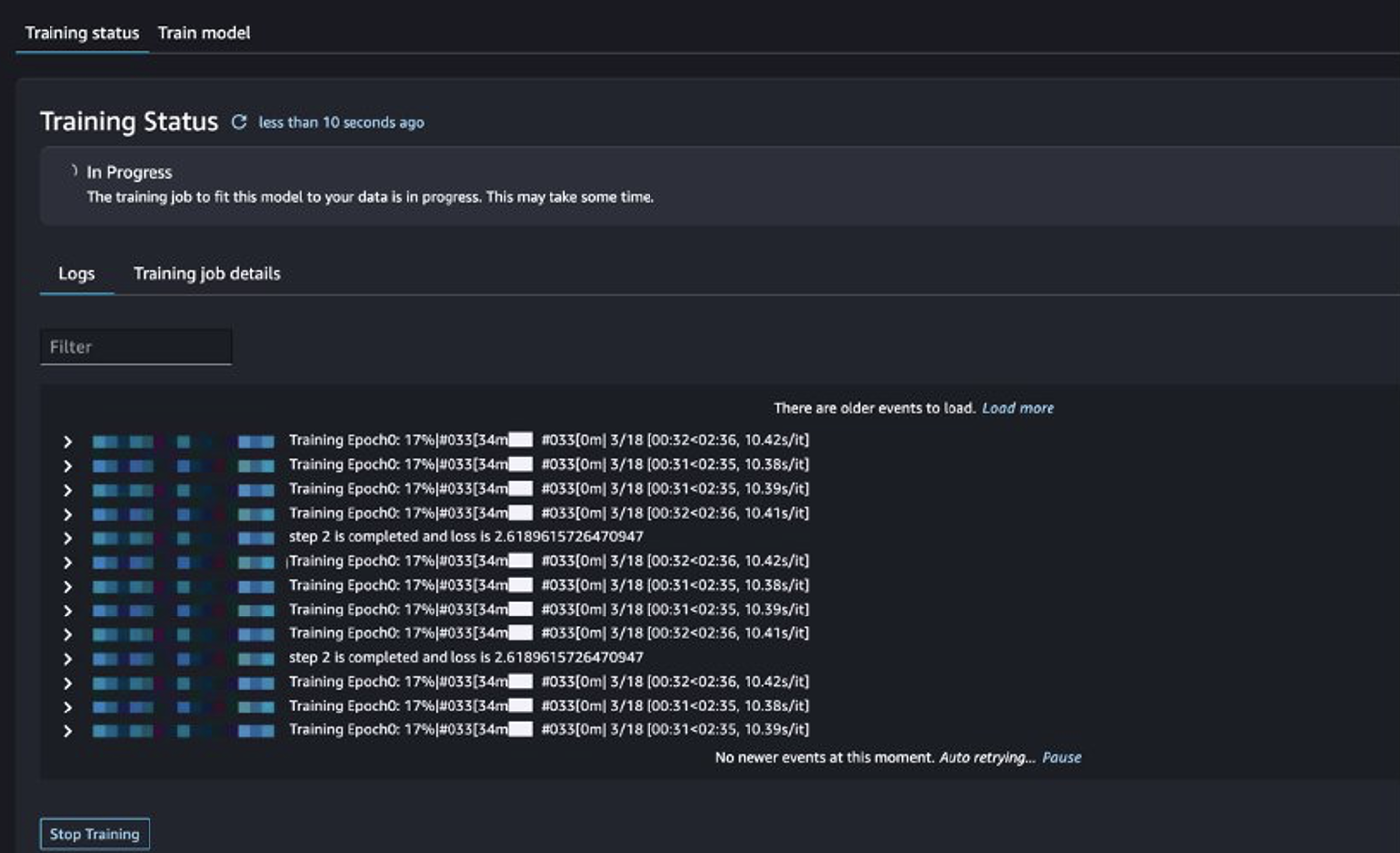
评估微调模型
训练完成后,选择 部署 在 SageMaker JumpStart 中部署您的微调模型。

模型部署成功后,选择 打开笔记本,这会将您重定向到准备好的 Jupyter 笔记本,您可以在其中运行 Python 代码。

您可以将图像 Data Science 2.0 和 Python 3 内核用于笔记本。
然后,您可以在此笔记本中评估微调后的模型和原始模型。
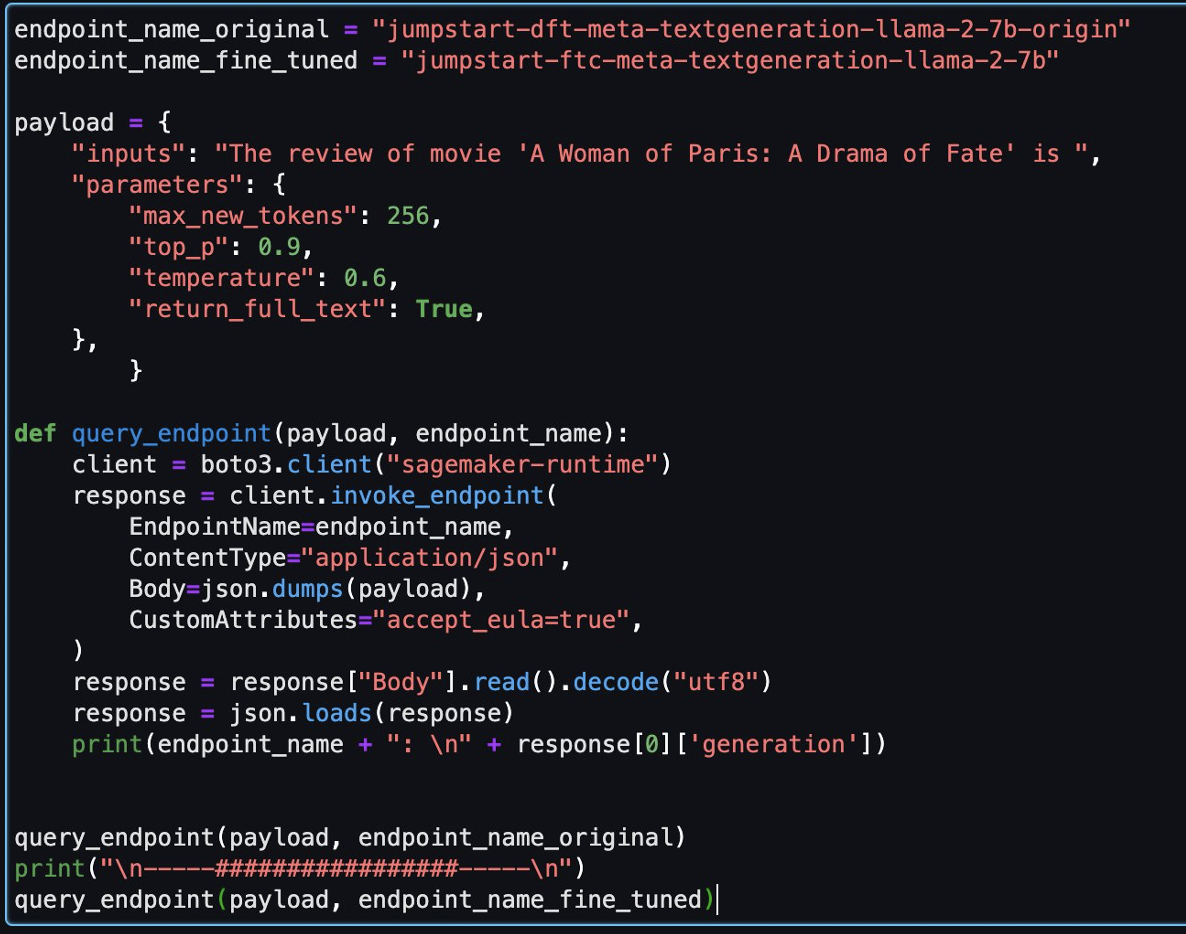
以下是原始模型和微调模型针对同一问题返回的两个响应。

我们为两个模型提供了同一句话:“对电影《巴黎女人:命运之剧》的评论是”,并让他们完成这句话。
原始模型输出无意义的句子:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
相比之下,微调模型的输出更像是电影评论:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
显然,微调后的模型在这个特定场景中表现更好。
清理
完成本练习后,请完成以下步骤来清理资源:
- 删除 S3 存储桶 存储清理后的数据集。
- 停止 EMR Serverless 环境.
- 删除 SageMaker 端点 托管 LLM 模型。
- 删除 SageMaker 域 运行你的笔记本。
默认情况下,您创建的应用程序应在 15 分钟不活动后自动停止。
一般来说,您不需要清理 Athena 环境,因为不使用时不会产生任何费用。
结论
在这篇文章中,我们介绍了 Common Crawl 数据集以及如何使用 EMR Serverless 处理数据以进行 LLM 微调。然后我们演示了如何使用 SageMaker JumpStart 微调 LLM 并在无需任何代码的情况下进行部署。有关 EMR Serverless 的更多用例,请参阅 Amazon EMR 无服务器。 有关在 Amazon SageMaker JumpStart 上托管和微调模型的更多信息,请参阅 Sagemaker JumpStart 文档.
作者简介
 唐世健 是 Amazon Web Services 的分析专家解决方案架构师。
唐世健 是 Amazon Web Services 的分析专家解决方案架构师。
 马修连姆 是 Amazon Web Services 的高级解决方案架构经理。
马修连姆 是 Amazon Web Services 的高级解决方案架构经理。
 徐大雷 是 Amazon Web Services 的分析专家解决方案架构师。
徐大雷 是 Amazon Web Services 的分析专家解决方案架构师。
 肖元军 是 Amazon Web Services 的高级解决方案架构师。
肖元军 是 Amazon Web Services 的高级解决方案架构师。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :是
- :不是
- :在哪里
- $UP
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- Able
- 关于
- ACCESS
- 访问
- 无障碍
- 基本会计和财务报表
- 账户
- 激活
- 加
- 增加
- 非洲
- 后
- 所有类型
- 允许
- 还
- 惊人
- Amazon
- 亚马逊电子病历
- 亚马逊SageMaker
- 亚马逊SageMaker JumpStart
- 亚马逊网络服务
- 量
- 量
- an
- 分析
- 和
- 另一个
- 任何
- 阿帕奇
- Apache Spark
- 应用领域
- 应用领域
- 的途径
- 架构
- 保健
- AS
- At
- 澳大利亚人
- 自动表
- 自动
- 可使用
- AWS
- 背景
- 基于
- 基础
- BE
- 美丽
- 因为
- 成为
- before
- 开始
- 作为
- 更好
- 之间
- 大
- 大数据运用
- 亿
- 身体
- 都
- 建立
- by
- 被称为
- CAN
- 可以得到
- 容量
- 携带
- 案件
- 例
- 改变
- 字符
- 收费
- 查
- 中文
- 程
- 清洁
- 客户
- 簇
- 码
- COM的
- 相当常见
- 常用
- 比较
- 完成
- 配置
- 考虑
- 由
- 安慰
- 经常
- 包含
- 包含
- Contents
- 一直
- 对比
- 相应
- 对应
- 价格
- 经济有效
- 可以
- 数
- 外壳
- 创建信息图
- 创建
- 习俗
- 顾客
- 定制
- data
- 数据分析
- 数据处理
- 数据科学
- 数据集
- 戴维斯
- 处理
- 交易
- 深
- 默认
- 定义
- 演示
- 演示
- 证明
- 部署
- 部署
- 部署
- 派生
- 尽管
- 详情
- 确定
- 图表
- 差异
- 不同
- 针对
- 直接
- 讨论
- 潜水
- do
- 文件
- 域
- 域名
- 唐纳德
- 别
- 向下
- 戏剧
- 司机
- 为期
- ,我们将参加
- 每
- 此前
- 易
- 消除
- 强调
- 遭遇
- 工程师
- 加强
- 输入
- 环境
- 醚(ETH)
- 评估
- 例子
- 例子
- 执行
- 锻炼
- 现有
- 存在
- 探索
- 探讨
- 延长
- 外部
- 提取
- 萃取
- 提取物
- 下降
- false
- 快
- 命运
- 精选
- 少数
- 字段
- 文件
- 档
- 过滤
- 过滤
- 终于
- 找到最适合您的地方
- 完
- 姓氏:
- 以下
- 如下
- 针对
- 格式
- 发现
- 骨架
- 框架
- 止
- 进一步
- 其他咨询
- 通常
- 发电
- 代
- 得到
- 混帐
- GitHub上
- 指导
- 有
- 帮助
- 蜂房
- 托管
- 为了
- 创新中心
- How To
- 但是
- HTML
- HTTPS
- 数百
- i
- IAM
- ID
- if
- 说明
- 图片
- 进口
- 重要
- 改善
- in
- 包括
- 包括
- 结合
- 增加
- 指数
- 信息
- 基础设施
- 输入
- 输入
- 安装
- 相互作用
- 成
- 介绍
- 介绍
- 问题
- IT
- 它的
- 千斤顶
- 工作
- 工作机会
- JSON
- Jupyter笔记本
- 只是
- 保持
- 键
- 语言
- 语言
- 大规模
- 最新
- 发射
- 发射
- 铅
- 让
- Level
- 库
- 喜欢
- 极限
- 线
- 清单
- 书单
- 骆驼
- LLM
- 本地
- 位于
- 圖書分館的位置
- 逻辑
- 登录
- 看
- 寻找
- 查找
- 机
- 保养
- 使
- 制作
- 经理
- 管理的
- 许多
- 地图
- 大规模
- 可能..
- 机制
- 满足
- 会见
- 提
- 元
- 元数据
- 方法
- 分钟
- 减轻
- 模型
- 模型
- 每月一次
- 更多
- 最先进的
- 电影
- 电影
- 许多
- 多
- 姓名
- 名称
- 旅游导航
- 必要
- 需求
- 网络
- 全新
- 下页
- 没有
- 节点
- 笔记本
- 笔记本电脑
- 获得
- 十月
- of
- on
- 一
- 仅由
- 打开
- 开放源码
- 附加选项
- or
- 原版的
- 其他名称
- 输出
- 概述
- 产量
- 输出
- 超过
- 覆盖
- 己
- 类型
- 包
- 面包
- 纸类
- 并行
- 参数
- 巴黎
- 部分
- 径
- 路径
- 员工
- 性能
- 表演
- 施行
- 期间
- 拍字节
- 彼得
- 摄影师
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 情节
- 点
- 热门
- 帖子
- 供电
- 预
- 前
- Prepare
- 准备
- 小学
- 过程
- 处理
- 处理
- 生产
- 提示
- 提供
- 提供
- 提供
- 优
- 公然
- 目的
- 放
- 蟒蛇
- 询问
- 题
- 很快
- 原
- 原始数据
- 达
- 阅读
- 准备
- 最近
- 最近
- 建议
- 记录
- 参考
- 引用
- 经常
- 关系
- 发布
- 修复
- 更换
- 要求
- 必须
- 岗位要求
- 资源
- 响应
- 回复
- 导致
- 成果
- 检讨
- 评论
- 右
- 角色
- 罗里
- 运行
- 运行
- 运行
- sagemaker
- 同
- 保存
- 鳞片
- 秤
- 缩放
- 扫描
- 脚本
- 科学
- 脚本
- 脚本
- 秒
- 部分
- 部分
- 看到
- 段
- 选择
- 自
- 前辈
- 句子
- 无服务器
- 服务器
- 特色服务
- 集
- 设置
- 几个
- 她
- 短
- 应该
- 如图
- 意义
- 类似
- 自
- 单
- 网站
- 尺寸
- 慢一点
- 片段
- So
- 方案,
- 解决方案
- 汤
- 来源
- 火花
- 专家
- 具体的
- SQL
- SSH
- 开始
- 开始
- 个人陈述
- 声明
- Status
- 步
- 步骤
- 仍
- Stop 停止
- 商店
- 存储
- 商店
- 故事
- 简单的
- 策略
- 串
- 工作室
- 提交
- 提交
- 顺利
- 这样
- 足够
- 合适的
- Switch 开关
- 同步。
- 表
- 采取
- 目标
- 任务
- 任务
- tensorflow
- 条款
- 测试
- 文本
- 文字产生
- 这
- 其
- 他们
- 然后
- 那里。
- 博曼
- 他们
- 第三方
- Free Introduction
- 三
- 通过
- 次
- 时间戳
- 至
- 跟踪时
- 产品培训
- 旅行
- true
- 尝试
- 二
- 类型
- 下
- 非结构化
- 更新
- 网址
- 使用
- 用例
- 用过的
- 用户
- 用户评论
- 用户
- 运用
- 利用
- 版本
- 在线会议
- 卷
- 走
- 想
- 通缉
- 仓库保管
- 是
- 方法..
- 方法
- we
- 卷筒纸
- Web服务
- 周
- 井
- 什么是
- ,尤其是
- 而
- 这
- 而
- WHO
- 野生动物
- 将
- 威廉
- 中
- 也完全不需要
- 女子
- 工作
- 价值
- 写
- 写作
- 产量
- 您
- 您一站式解决方案
- 和风网