在这篇文章中,我们演示了如何使用基于神经架构搜索 (NAS) 的结构剪枝来压缩经过微调的 BERT 模型,以提高模型性能并减少推理时间。预训练语言模型 (PLM) 正在生产力工具、客户服务、搜索和推荐、业务流程自动化和内容创建等领域迅速被商业和企业采用。部署 PLM 推理端点通常会因计算要求而导致较高的延迟和较高的基础设施成本,并且由于参数数量过多而导致计算效率降低。修剪 PLM 可减少模型的大小和复杂性,同时保留其预测功能。经过修剪的 PLM 可实现更小的内存占用和更低的延迟。我们证明,通过修剪 PLM 并权衡特定目标任务的参数计数和验证错误,与基本 PLM 模型相比,能够实现更快的响应时间。
多目标优化是决策的一个领域,它优化多个目标函数,例如内存消耗、训练时间和计算资源,同时进行优化。结构修剪是一种通过修剪层或神经元/节点来减少 PLM 大小和计算要求的技术,同时尝试保持模型准确性。通过删除层,结构修剪可以实现更高的压缩率,从而实现硬件友好的结构化稀疏性,从而减少运行时间和响应时间。将结构修剪技术应用于 PLM 模型会产生更轻量级的模型,内存占用更低,当作为推理端点托管在 SageMaker 中时,与原始微调的 PLM 相比,可以提高资源效率并降低成本。
本文中阐述的概念可以应用于使用 PLM 功能的应用程序,例如推荐系统、情感分析和搜索引擎。具体来说,如果您有专门的机器学习 (ML) 和数据科学团队,他们使用特定领域的数据集微调自己的 PLM 模型,并使用以下方法部署大量推理端点,则可以使用此方法: 亚马逊SageMaker。一个例子是一家在线零售商,它部署了大量的推理端点用于文本摘要、产品目录分类和产品反馈情感分类。另一个示例可能是医疗保健提供者使用 PLM 推理端点进行临床文档分类、医疗报告中的命名实体识别、医疗聊天机器人和患者风险分层。
解决方案概述
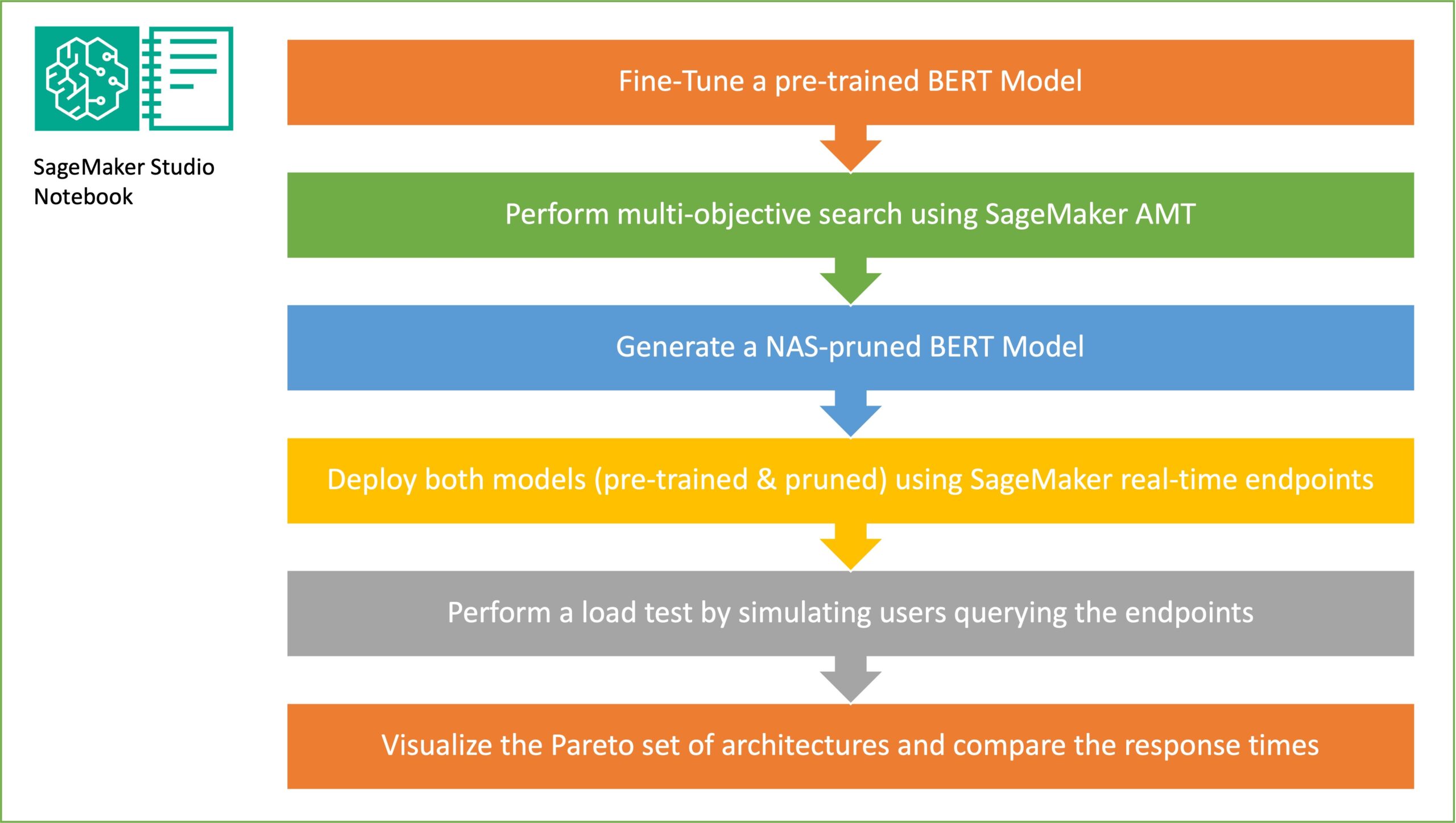
在本节中,我们将介绍总体工作流程并解释该方法。首先,我们使用一个 亚马逊SageMaker Studio 笔记本 使用特定于领域的数据集在目标任务上微调预训练的 BERT 模型。 BERT (Bi Direction Encoder Representations from Transformers)是一个基于 变压器架构 用于自然语言处理(NLP)任务。神经架构搜索(NAS)是一种自动化人工神经网络设计的方法,与机器学习领域广泛使用的超参数优化密切相关。 NAS 的目标是通过使用无梯度优化等技术搜索大量候选架构或通过优化所需指标来找到给定问题的最佳架构。架构的性能通常使用验证损失等指标来衡量。 SageMaker 自动模型调整 (AMT) 自动执行繁琐而复杂的过程,寻找 ML 模型超参数的最佳组合,从而产生最佳模型性能。 AMT 使用智能搜索算法和迭代评估,并使用您指定的一系列超参数。它选择的超参数值可创建性能最佳的模型(通过准确性和 F-1 分数等性能指标来衡量)。
本文中描述的微调方法是通用的,可以应用于任何基于文本的数据集。分配给 BERT PLM 的任务可以是基于文本的任务,例如情感分析、文本分类或问答。在此演示中,目标任务是二元分类问题,其中 BERT 用于从由文本片段对集合组成的数据集中识别一个文本片段的含义是否可以从另一个片段推断出来。我们使用 识别文本蕴涵数据集 来自 GLUE 基准测试套件。我们使用 SageMaker AMT 执行多目标搜索,以确定在目标任务的参数计数和预测准确性之间提供最佳权衡的子网络。在执行多目标搜索时,我们首先将准确性和参数计数定义为我们要优化的目标。
在 BERT PLM 网络中,可以存在模块化、独立的子网络,使模型具有语言理解和知识表示等专门功能。 BERT PLM 使用多头自注意力子网络和前馈子网络。多头自注意力层允许 BERT 关联单个序列的不同位置,以便通过允许多个头关注多个上下文信号来计算序列的表示。输入被分成多个子空间,并将自注意力分别应用于每个子空间。 Transformer PLM 中的多个头允许模型共同处理来自不同表示子空间的信息。前馈子网络是一种简单的神经网络,它获取多头自注意力子网络的输出,处理数据,并返回最终的编码器表示。
随机子网络采样的目标是训练能够在目标任务上表现足够好的较小的 BERT 模型。我们从微调的基本 BERT 模型中抽取 100 个随机子网络,并同时评估 10 个网络。评估经过训练的子网络的客观指标,并根据客观指标之间的权衡选择最终模型。我们可视化 帕累托前沿 对于采样的子网络,其中包含修剪模型,该模型提供模型精度和模型大小之间的最佳权衡。我们根据我们愿意权衡的模型大小和模型精度来选择候选子网络(NAS 剪枝的 BERT 模型)。接下来,我们使用 SageMaker 托管端点、预训练的 BERT 基本模型和 NAS 剪枝的 BERT 模型。为了执行负载测试,我们使用 刺槐,一个可以使用 Python 实现的开源负载测试工具。我们使用 Locust 在两个端点上运行负载测试,并使用帕累托前沿可视化结果,以说明两个模型的响应时间和准确性之间的权衡。下图概述了本文中解释的工作流程。
先决条件
对于这篇文章,需要满足以下先决条件:
您还需要增加 服务配额 访问 SageMaker 中至少三个 ml.g4dn.xlarge 实例。实例类型 ml.g4dn.xlarge 是经济高效的 GPU 实例,允许您本机运行 PyTorch。要增加服务配额,请完成以下步骤:
- 在控制台上,导航到服务配额。
- 针对 管理配额,选择 亚马逊SageMaker,然后选择 查看配额.

- 搜索“ml-g4dn.xlarge 用于训练作业使用”并选择配额项。
- 在帐户级别请求增加.
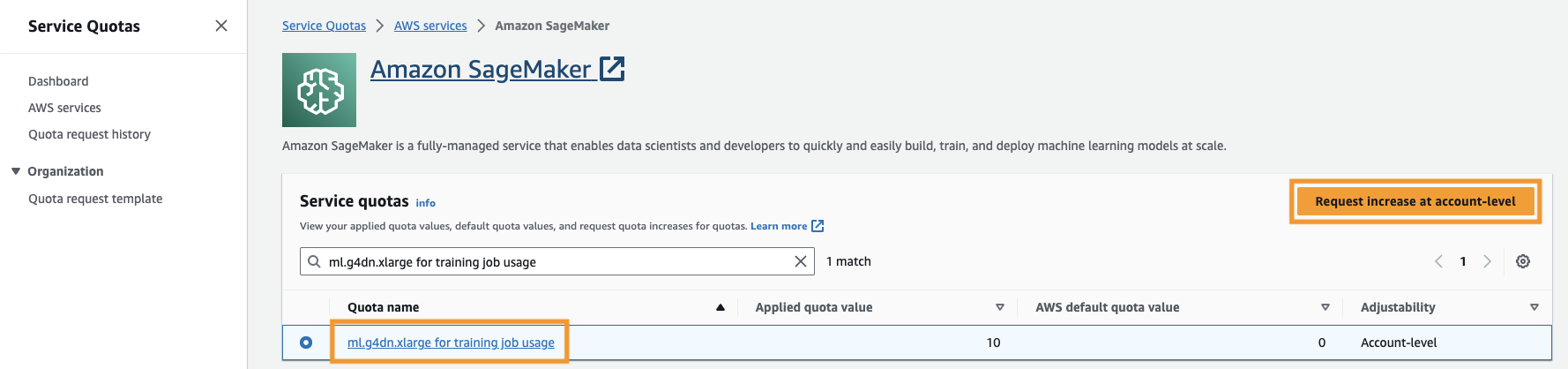
- 针对 增加配额值,输入 5 或更高的值。
- 请求.
请求的配额批准可能需要一些时间才能完成,具体取决于帐户权限。

- 从 SageMaker 控制台打开 SageMaker Studio。

- 系统终端 下 实用程序和文件.

- 运行以下命令来克隆 GitHub回购 到 SageMaker Studio 实例:
- 导航
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - 打开文件
nas_for_llm_with_amt.ipynb. - 设置环境
ml.g4dn.xlarge实例并选择 选择.

设置预训练的 BERT 模型
在本节中,我们从数据集库导入识别文本蕴涵数据集,并将数据集拆分为训练集和验证集。该数据集由句子对组成。 BERT PLM 的任务是识别给定两个文本片段,是否可以从另一个文本片段推断出一个文本片段的含义。在下面的例子中,我们可以从第二个短语推断出第一个短语的含义:
我们从以下位置加载文本识别蕴含数据集 胶 基准测试套件通过 数据集库 来自我们的训练脚本中的“Hugging Face”(./training.py)。我们将 GLUE 中的原始训练数据集拆分为训练集和验证集。在我们的方法中,我们使用训练数据集微调基本 BERT 模型,然后执行多目标搜索来识别在目标指标之间实现最佳平衡的子网络集。我们专门使用训练数据集来微调 BERT 模型。然而,我们通过测量保留验证数据集的准确性来使用验证数据进行多目标搜索。
使用特定领域的数据集微调 BERT PLM
原始 BERT 模型的典型用例包括下一句预测或屏蔽语言建模。为了将基本 BERT 模型用于文本识别蕴涵等下游任务,我们必须使用特定领域的数据集进一步微调模型。您可以使用经过微调的 BERT 模型来执行序列分类、问答和标记分类等任务。然而,出于本演示的目的,我们使用微调模型进行二元分类。我们使用以下超参数,使用之前准备的训练数据集对预训练的 BERT 模型进行微调:
我们将模型训练的检查点保存到 亚马逊简单存储服务 (Amazon S3)存储桶,以便在基于NAS的多目标搜索过程中加载模型。在训练模型之前,我们定义诸如历元、训练损失、参数数量和验证误差等指标:
微调过程开始后,训练作业大约需要 15 分钟才能完成。
执行多目标搜索以选择子网络并可视化结果
在下一步中,我们通过使用 SageMaker AMT 对随机子网络进行采样,对微调的基本 BERT 模型执行多目标搜索。为了访问超级网络(微调的 BERT 模型)内的子网络,我们屏蔽掉不属于子网络的 PLM 的所有组件。屏蔽超级网络以查找 PLM 中的子网络是一种用于隔离和识别模型行为模式的技术。请注意,Hugging Face 变换器需要隐藏大小是头部数量的倍数。 Transformer PLM 中的隐藏大小控制隐藏状态向量空间的大小,这会影响模型学习数据中复杂表示和模式的能力。在 BERT PLM 中,隐藏状态向量具有固定大小 (768)。我们无法改变隐藏的大小,因此头的数量必须在 [1, 3, 6, 12] 中。
与单目标优化相反,在多目标设置中,我们通常没有一个解决方案可以同时优化所有目标。相反,我们的目标是收集一组解决方案,这些解决方案至少在一个目标(例如验证错误)中主导所有其他解决方案。现在我们可以通过设置我们想要减少的指标(验证误差和参数数量)来通过 AMT 开始多目标搜索。随机子网络由参数定义 max_jobs 同时作业的数量由参数定义 max_parallel_jobs。加载模型检查点和评估子网络的代码可在 evaluate_subnetwork.py 脚本。
AMT 调整作业运行大约需要 2 小时 20 分钟。 AMT调优作业成功运行后,我们解析作业的历史记录并收集子网络的配置,例如头数、层数、单元数以及相应的指标(例如验证错误和参数数量)。以下屏幕截图显示了成功的 AMT 调谐器作业的摘要。
接下来,我们使用帕累托集(也称为帕累托前沿或帕累托最优集)可视化结果,这有助于我们识别在目标度量(验证误差)中主导所有其他子网络的最佳子网络集:
首先,我们从 AMT 调优作业中收集数据。然后我们使用以下方法绘制帕累托集 matplotlob.pyplot x 轴为参数数量,y 轴为验证错误。这意味着,当我们从帕累托集的一个子网络转移到另一个子网络时,我们必须牺牲性能或模型大小,但改进另一个。最终,帕累托集使我们能够灵活地选择最适合我们偏好的子网络。我们可以决定要减少多少网络规模以及愿意牺牲多少性能。

使用 SageMaker 部署经过微调的 BERT 模型和 NAS 优化的子网络模型
接下来,我们部署 Pareto 集中最大的模型,该模型会导致性能退化最小化 SageMaker端点。最好的模型是在验证误差和我们的用例的参数数量之间提供最佳权衡的模型。
模型比较
我们采用预先训练的基本 BERT 模型,使用特定于领域的数据集对其进行微调,运行 NAS 搜索以根据客观指标识别主要子网络,并将修剪后的模型部署在 SageMaker 端点上。此外,我们采用了预训练的基本 BERT 模型,并将基本模型部署在第二个 SageMaker 端点上。接下来,我们跑了 负载测试 在两个推理端点上使用 Locust 并根据响应时间评估性能。
首先,我们导入必要的 Locust 和 Boto3 库。然后我们构造一个请求元数据并记录用于负载测试的开始时间。然后,有效负载通过 BotoClient 传递到 SageMaker 端点调用 API 以模拟真实的用户请求。我们使用 Locust 生成多个虚拟用户以并行发送请求并测量负载下的端点性能。通过分别增加两个端点的用户数量来运行测试。测试完成后,Locust 会为每个已部署的模型输出一个请求统计 CSV 文件。
接下来,我们从使用 Locust 运行测试后下载的 CSV 文件生成响应时间图。绘制响应时间与用户数量的关系的目的是通过可视化模型端点响应时间的影响来分析负载测试结果。在下图中,我们可以看到,与基本 BERT 模型端点相比,NAS 剪枝模型端点实现了更短的响应时间。
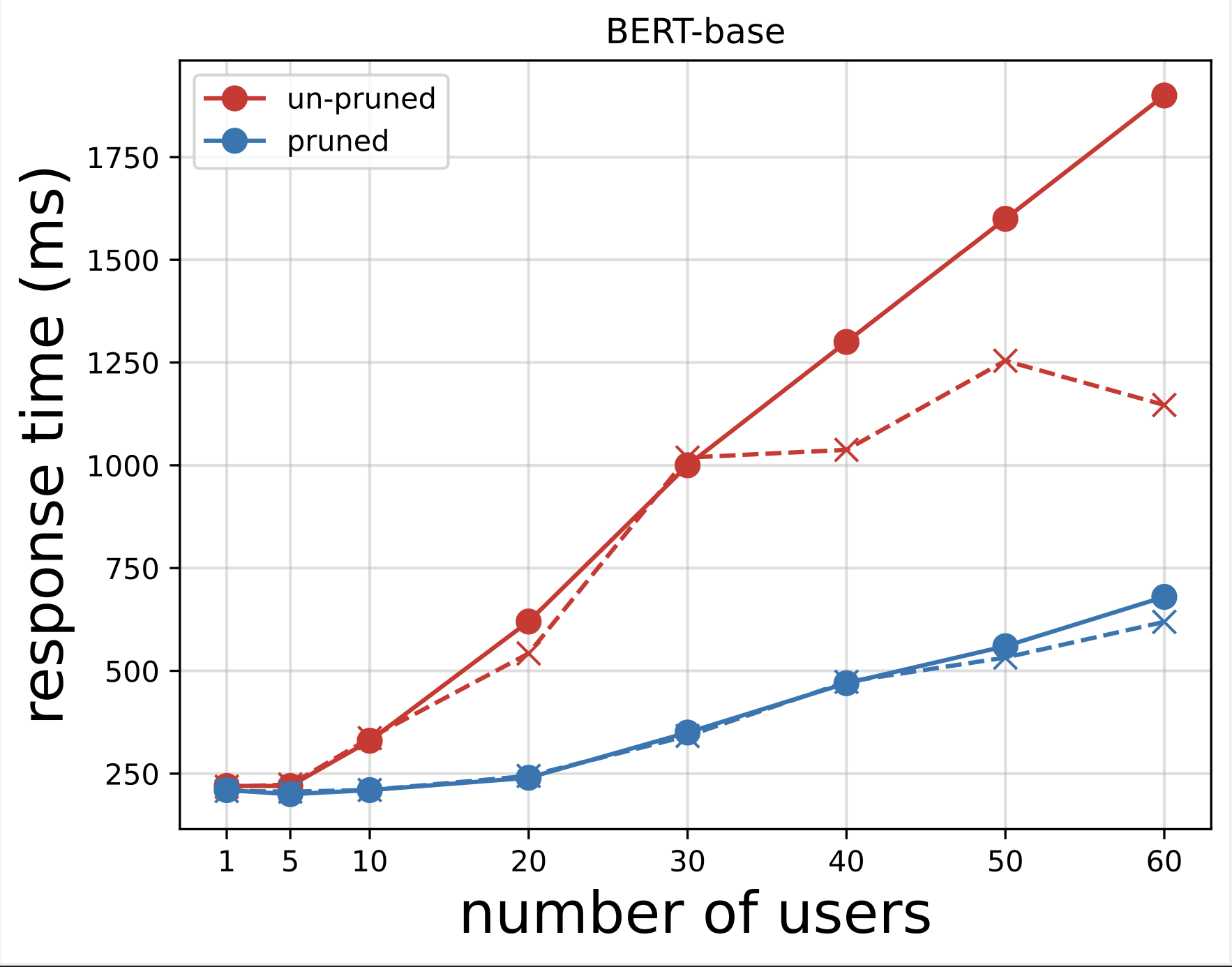
在第二个图表(第一个图表的扩展)中,我们观察到,在大约 70 个用户之后,SageMaker 开始限制基本 BERT 模型端点并引发异常。然而,对于 NAS 修剪模型端点,限制发生在 90-100 个用户之间,并且响应时间较短。

从这两个图表中,我们观察到与未修剪的模型相比,修剪后的模型具有更快的响应时间和更好的扩展性。随着我们扩展推理端点的数量(就像为其 PLM 应用程序部署大量推理端点的用户一样),成本效益和性能改进开始变得相当可观。
清理
要删除微调基础 BERT 模型和 NAS 剪枝模型的 SageMaker 终端节点,请完成以下步骤:
- 在SageMaker控制台上,选择 推理 和 端点 在导航窗格中。
- 选择端点并将其删除。
或者,从 SageMaker Studio 笔记本中,通过提供端点名称来运行以下命令:
结论
在这篇文章中,我们讨论了如何使用 NAS 来修剪微调的 BERT 模型。我们首先使用特定领域的数据训练基本 BERT 模型,并将其部署到 SageMaker 端点。我们使用 SageMaker AMT 对目标任务的微调基础 BERT 模型执行多目标搜索。我们可视化 Pareto 前端并选择 Pareto 最优 NAS 剪枝 BERT 模型,并将该模型部署到第二个 SageMaker 端点。我们使用 Locust 执行负载测试来模拟用户查询两个端点,并测量响应时间并将其记录在 CSV 文件中。我们绘制了两个模型的响应时间与用户数量的关系图。
我们观察到,修剪后的 BERT 模型在响应时间和实例限制阈值方面都表现得更好。我们得出的结论是,与基本 BERT 模型相比,NAS 剪枝模型对端点负载增加具有更强的弹性,即使更多用户对系统施加压力,也能保持较低的响应时间。您可以将本文中描述的 NAS 技术应用于任何大型语言模型,以找到可以以显着缩短响应时间执行目标任务的修剪模型。除了验证损失之外,您还可以使用延迟作为参数来进一步优化该方法。
尽管我们在本文中使用 NAS,但量化是用于优化和压缩 PLM 模型的另一种常见方法。量化将经过训练的网络中的权重和激活的精度从 32 位浮点降低到较低位宽度(例如 8 位或 16 位整数),从而生成可生成更快推理的压缩模型。量化并不会减少参数的数量;相反,它降低了现有参数的精度以获得压缩模型。 NAS 剪枝删除了 PLM 中的冗余网络,从而创建了参数较少的稀疏模型。通常,NAS 剪枝和量化一起用于压缩大型 PLM,以保持模型准确性、减少验证损失,同时提高性能并减小模型大小。其他常用的减小 PLM 大小的技术包括 知识升华, 矩阵分解及 级联蒸馏.
博文中提出的方法适用于使用 SageMaker 使用特定于域的数据训练和微调模型并部署端点以生成推理的团队。如果您正在寻找一种完全托管的服务,提供构建生成式 AI 应用程序所需的高性能基础模型选择,请考虑使用 亚马逊基岩。如果您正在寻找适用于各种业务用例的预训练开源模型,并希望访问解决方案模板和示例笔记本,请考虑使用 亚马逊SageMaker JumpStart。我们在本文中使用的 Hugging Face BERT 基本案例模型的预训练版本也可从 SageMaker JumpStart 获取。
作者简介
 阿帕拉吉坦·维迪亚纳坦 是 AWS 的首席企业解决方案架构师。他是一名云架构师,在设计和开发企业、大型分布式软件系统方面拥有 24 年以上的经验。他专门研究生成人工智能和机器学习数据工程。他是一名有抱负的马拉松运动员,爱好包括徒步旅行、骑自行车以及与妻子和两个儿子共度时光。
阿帕拉吉坦·维迪亚纳坦 是 AWS 的首席企业解决方案架构师。他是一名云架构师,在设计和开发企业、大型分布式软件系统方面拥有 24 年以上的经验。他专门研究生成人工智能和机器学习数据工程。他是一名有抱负的马拉松运动员,爱好包括徒步旅行、骑自行车以及与妻子和两个儿子共度时光。
 亚伦·克莱恩(Aaron Klein) 是 AWS 的高级应用科学家,致力于深度神经网络的自动化机器学习方法。
亚伦·克莱恩(Aaron Klein) 是 AWS 的高级应用科学家,致力于深度神经网络的自动化机器学习方法。
 雅采克·戈莱比夫斯基 是 AWS 的高级应用科学家。
雅采克·戈莱比夫斯基 是 AWS 的高级应用科学家。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :具有
- :是
- :不是
- :在哪里
- ][p
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- 对,能力--
- Able
- ACCESS
- 账号管理
- 实现
- 激活
- 增加
- 采用
- 后
- AI
- 瞄准
- 致力
- 算法
- 所有类型
- 让
- 允许
- 允许
- 还
- Amazon
- 亚马逊网络服务
- 量
- an
- 分析
- 分析
- 分析
- 和
- 另一个
- 回答
- 任何
- API
- 应用领域
- 应用的
- 使用
- 应用
- 的途径
- 批准
- 约
- 架构
- 保健
- 国家 / 地区
- 地区
- 参数
- 围绕
- 人造的
- 人工神经网络
- AS
- 有志
- 分配
- 相关
- At
- 尝试
- 出席
- 自动化
- 自动化机器学习
- 自动化
- 自动表
- 自动化
- 自动化和干细胞工程
- 可使用
- AWS
- 轴
- 当前余额
- 基地
- 基于
- BE
- 成为
- before
- 行为
- 标杆
- 好处
- 最佳
- 更好
- 之间
- 位
- 身体
- 都
- 建立
- 商业
- 业务流程
- 业务流程自动化
- 但是
- by
- CAN
- 候选人
- 能力
- 案件
- 例
- 检索目录
- 更改
- 图表
- 图表
- 聊天机器人
- 选择
- 选择
- 程
- 分类
- 临床资料
- 密切
- 云端技术
- 码
- 收集
- 采集
- 组合
- 商业的
- 相当常见
- 常用
- 相比
- 完成
- 完成
- 复杂
- 复杂
- 组件
- 计算
- 计算
- 概念
- 总结
- 考虑
- 由
- 安慰
- 约束
- 建设
- 消费
- 包含
- 内容
- 内容创造
- 上下文
- 继续
- 对比
- 控制
- 相应
- 价格
- 成本
- 数
- 创建信息图
- 创建
- 创建
- 顾客
- 客户服务
- data
- 数据科学
- 数据集
- 日期时间
- 决定
- 决策
- 专用
- 深
- 深度神经网络
- 定义
- 定义
- 定义
- 演示
- 演示
- 根据
- 部署
- 部署
- 部署
- 部署
- 描述
- 设计
- 设计
- 期望
- 发展
- 不同
- 讨论
- 分布
- 文件
- 不会
- 优势
- 主宰
- 别
- 两
- ,我们将参加
- e
- 每
- 效率
- 高效
- 或
- 端点
- 端点
- 工程师
- 引擎
- 更多
- 输入
- 企业
- 企业采用
- 企业解决方案
- 实体
- 条目
- 环境
- 时代
- 错误
- 醚(ETH)
- 评估
- 评估
- 评价
- 甚至
- 事件
- 例子
- 除
- 例外
- 只
- 现有
- 体验
- 说明
- 解释
- 延期
- 面部彩妆
- false
- 快
- 特征
- 反馈
- 少
- 部分
- 文件
- 档
- 最后
- 找到最适合您的地方
- 寻找
- 姓氏:
- 固定
- 高度灵活
- 漂浮的
- 以下
- Footprint
- 针对
- 发现
- 基金会
- 止
- 前
- 边疆
- 充分
- 功能
- 进一步
- 生成
- 产生
- 生成的
- 生成式人工智能
- 得到
- 特定
- 目标
- GPU
- 灰色
- 发生
- 有
- he
- 头
- 元首
- 医疗保健
- 帮助
- 老旧房屋
- 高绩效
- 更高
- 徒步旅行
- 他的
- 历史
- 爱好
- 主持人
- 托管
- HOURS
- 创新中心
- How To
- 但是
- HTML
- HTTP
- HTTPS
- 拥抱脸
- 超参数优化
- 超参数调整
- i
- 鉴定
- IDX
- if
- 说明
- 影响力故事
- 影响
- 实施
- 进口
- 改善
- 改善
- 改进
- 改善
- in
- 包括
- 增加
- 增加
- 增加
- 信息
- 基础设施
- 输入
- 例
- 实例
- 代替
- 智能化
- 成
- IT
- 它的
- 工作
- 工作机会
- JPG
- JSON
- 知识
- 已知
- 语言
- 大
- 大规模
- 最大
- 潜伏
- 层
- 层
- 信息
- 学习用品
- 学习
- 最少
- 让
- 库
- 自学资料库
- Line
- 加载
- 日志
- 记录
- 寻找
- 离
- 损失
- 降低
- 机
- 机器学习
- 保持
- 维持
- 男子
- 管理
- 马拉松
- 面膜
- matplotlib
- 最多
- 可能..
- 意
- 衡量
- 测量
- 测量
- 医生
- 满足
- 内存
- 元数据
- 方法
- 公
- 指标
- 可能
- 大幅减低
- 分钟
- ML
- 模型
- 造型
- 模型
- 模块化
- 更多
- 移动
- 许多
- 多
- 必须
- 姓名
- 命名
- 名称
- 在
- 自然
- 自然语言
- 自然语言处理
- 导航
- 旅游导航
- 必要
- 需求
- 打印车票
- 需要
- 网络
- 网络
- 神经
- 神经网络
- 神经网络
- 下页
- NLP
- 不包含
- 注意
- 笔记本
- 笔记本电脑
- 现在
- 数
- 对象
- 目标
- 目标
- 观察
- 观察
- of
- 折扣
- 提供
- 优惠精选
- on
- 一
- 在线
- 网上零售商
- 仅由
- 打开
- 开放源码
- 最佳
- 优化
- 优化
- 优化
- 优化
- 追求项目的积极优化
- or
- 秩序
- 原版的
- 其他名称
- 我们的
- 输出
- 产量
- 输出
- 超过
- 最划算
- 简介
- 己
- 对
- 面包
- 并行
- 参数
- 参数
- 帕累托
- 部分
- 通过
- 径
- 病人
- 模式
- 演出
- 性能
- 执行
- 执行
- 施行
- 权限
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 点
- 点
- 职位
- 帖子
- 平台精度
- 预测
- 预测
- 预报器
- 喜好
- 准备
- 先决条件
- 当下
- 先前
- 校长
- 市场问题
- 过程
- 过程自动化
- 过程
- 处理
- 产品
- 生产率
- 生产力工具
- 建议
- 提供者
- 提供
- 优
- 拉
- 拉
- 目的
- 目的
- 蟒蛇
- pytorch
- Q&A
- 题
- 相当
- 随机
- 范围
- 快
- 价格表
- 原
- 真实
- 承认
- 承认
- 认识
- 推荐
- 建议
- 记录
- 记录
- 红色
- 减少
- 减少
- 减少
- 回归
- 有关
- 移除了
- 删除
- 业务报告
- 表示
- 请求
- 要求
- 要求
- 必须
- 岗位要求
- 弹性
- 资源
- 资源
- 分别
- 响应
- 成果
- 零售商
- 护
- 回报
- 骑术
- 风险
- 行
- 运行
- 亚军
- 运行
- 运行
- s
- 牺牲
- sagemaker
- SageMaker 推理
- 保存
- 鳞片
- 秤
- 科学
- 科学家
- 得分了
- 脚本
- 搜索
- 搜索引擎
- 搜索
- 其次
- 部分
- 看到
- 选择
- 选
- 自
- 提交
- 句子
- 情绪
- 序列
- 服务
- 特色服务
- 会议
- 集
- 套数
- 设置
- 作品
- 信号
- 显著
- 简易
- 同时
- 同时
- 单
- 尺寸
- 小
- So
- 软件
- 方案,
- 解决方案
- 一些
- 来源
- 太空
- 卵
- 专门
- 专业
- 具体的
- 特别是
- 花费
- 分裂
- 开始
- 启动
- 州/领地
- 统计
- 步
- 步骤
- 存储
- 结构
- 结构化
- 工作室
- 大量
- 成功
- 顺利
- 这样
- 合适的
- 套房
- 概要
- 系统
- 产品
- T
- 采取
- 需要
- 目标
- 任务
- 任务
- 队
- 技术
- 技术
- 模板
- 条款
- 测试
- 测试
- 文本
- 文字分类
- 文字的
- 比
- 这
- 其
- 然后
- 那里。
- 因此
- 博曼
- Free Introduction
- 三
- 门槛
- 通过
- 次
- 时
- 至
- 一起
- 象征
- 了
- 工具
- 工具
- 贸易
- 交易
- 培训
- 熟练
- 产品培训
- 变压器
- 变形金刚
- true
- 尝试
- 二
- 类型
- 类型
- 普遍
- 一般
- 最终
- 下
- 经历
- 理解
- 单位
- us
- 使用
- 用例
- 用过的
- 用户
- 用户
- 使用
- 运用
- 验证
- 折扣值
- 价值观
- 版本
- 通过
- 在线会议
- 想像
- vs
- 想
- 是
- we
- 卷筒纸
- Web服务
- 井
- ,尤其是
- 是否
- 这
- 而
- WHO
- 宽
- 大范围
- 广泛
- 妻子
- 维基百科上的数据
- 将
- 愿意
- 中
- 工作
- 工作流程
- 加工
- X
- 年
- 产量
- 您
- 您一站式解决方案
- 和风网