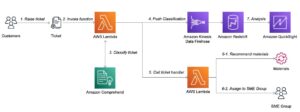
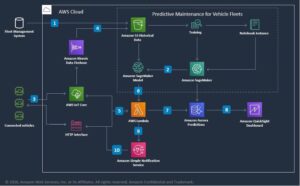
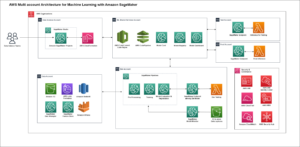
嵌入在自然语言处理(NLP)和机器学习(ML)中发挥着关键作用。 文本嵌入 指将文本转换为驻留在高维向量空间中的数字表示的过程。该技术是通过使用机器学习算法来实现的,该算法能够理解数据的含义和上下文(语义关系)并学习数据内的复杂关系和模式(句法关系)。您可以将生成的矢量表示用于广泛的应用,例如信息检索、文本分类、自然语言处理等。
Amazon Titan 文本嵌入 是一种文本嵌入模型,可将自然语言文本(由单个单词、短语甚至大型文档组成)转换为数字表示,可用于支持基于语义相似性的搜索、个性化和聚类等用例。
在这篇文章中,我们讨论 Amazon Titan 文本嵌入模型、其功能和示例用例。
一些关键概念包括:
- 文本(向量)的数字表示捕获单词之间的语义和关系
- 丰富的嵌入可用于比较文本相似度
- 多语言文本嵌入可以识别不同语言的含义
一段文本如何转换为向量?
有多种技术可以将句子转换为向量。一种流行的方法是使用词嵌入算法,例如 Word2Vec、GloVe 或 FastText,然后聚合词嵌入以形成句子级向量表示。
另一种常见的方法是使用大型语言模型 (LLM),例如 BERT 或 GPT,它们可以为整个句子提供上下文化嵌入。这些模型基于 Transformers 等深度学习架构,可以更有效地捕获句子中单词之间的上下文信息和关系。
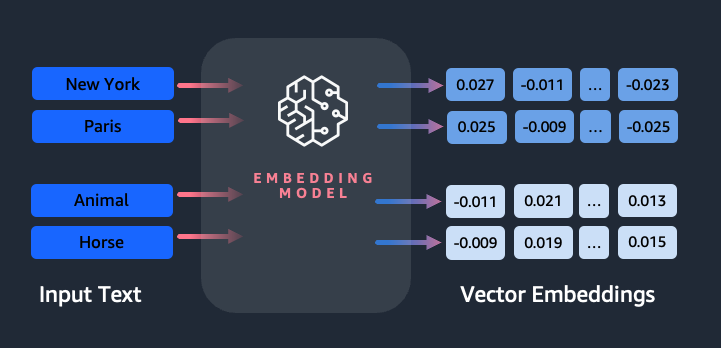
为什么我们需要嵌入模型?
向量嵌入是法学硕士理解语言语义程度的基础,也使法学硕士能够在情感分析、命名实体识别和文本分类等下游 NLP 任务上表现良好。
除了语义搜索之外,您还可以使用嵌入来增强提示,通过检索增强生成 (RAG) 获得更准确的结果,但为了使用它们,您需要将它们存储在具有矢量功能的数据库中。
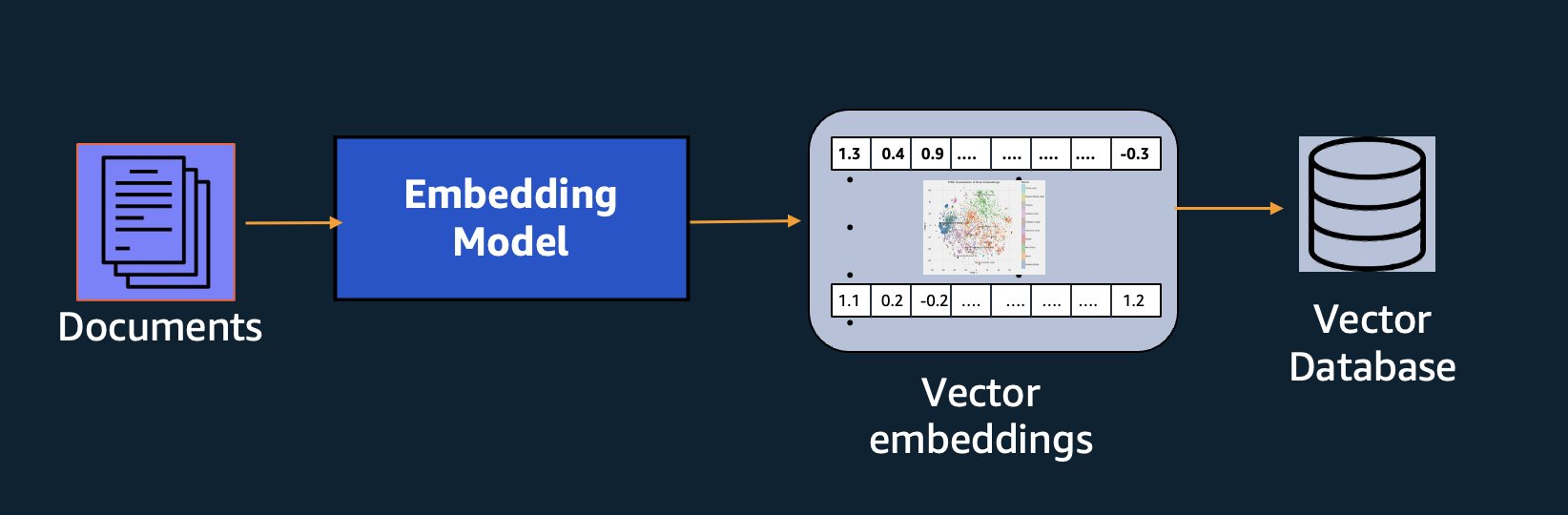
Amazon Titan 文本嵌入模型针对文本检索进行了优化,以支持 RAG 用例。它使您能够首先将文本数据转换为数字表示或向量,然后使用这些向量从向量数据库中准确搜索相关段落,从而使您能够与其他基础模型结合充分利用您的专有数据。
因为 Amazon Titan Text Embeddings 是一个托管模型 亚马逊基岩,它作为完全无服务器的体验提供。您可以通过 Amazon Bedrock REST 使用它 API 或 AWS 开发工具包。所需的参数是您想要生成嵌入的文本和 modelID 参数,代表 Amazon Titan 文本嵌入模型的名称。以下代码是使用适用于 Python 的 AWS 开发工具包 (Boto3) 的示例:
输出将如下所示:
请参阅 亚马逊基岩 boto3 设置 有关如何安装所需包、连接到 Amazon Bedrock 以及调用模型的更多详细信息。
Amazon Titan 文本嵌入的功能
借助 Amazon Titan Text Embeddings,您最多可以输入 8,000 个令牌,使其非常适合根据您的使用案例处理单个单词、短语或整个文档。 Amazon Titan 返回维度为 1536 的输出向量,使其具有很高的准确性,同时还针对低延迟、经济高效的结果进行了优化。
Amazon Titan Text Embeddings 支持创建和查询超过 25 种不同语言的文本嵌入。这意味着您可以将模型应用于您的用例,而无需为您想要支持的每种语言创建和维护单独的模型。
使用经过多种语言训练的单一嵌入模型具有以下主要优势:
- 更广泛的影响范围 – 通过开箱即用地支持超过 25 种语言,您可以将应用程序的覆盖范围扩展到许多国际市场的用户和内容。
- 一致的表现 – 通过涵盖多种语言的统一模型,您可以在不同语言之间获得一致的结果,而不是针对每种语言分别进行优化。该模型经过全面训练,因此您可以获得跨语言的优势。
- 多语言查询支持 – Amazon Titan Text Embeddings 允许查询任何受支持语言的文本嵌入。这提供了跨语言检索语义相似内容的灵活性,而不受限于单一语言。您可以构建使用相同的统一嵌入空间查询和分析多语言数据的应用程序。
截至撰写本文时,支持以下语言:
- 阿拉伯语
- 简体中文
- 中国(繁体)
- 捷克
- 荷兰人
- 英语
- 法语
- 德语
- 希伯来语
- 印地语
- 意大利语
- 日文
- 卡纳达语
- 韩语
- 马拉雅拉姆语
- 马拉
- 波兰语
- 葡萄牙语
- 俄语
- 西班牙语
- 瑞典语
- 菲律宾他加禄语
- 淡米尔文
- 泰卢固语
- 土耳其语
将 Amazon Titan 文本嵌入与 LangChain 结合使用
浪链 是一个流行的开源框架,用于处理生成人工智能模型和支持技术。它包括一个 BedrockEmbeddings 客户端 它可以方便地用抽象层包装 Boto3 SDK。这 BedrockEmbeddings 客户端允许您直接使用文本和嵌入,而无需了解 JSON 请求或响应结构的详细信息。下面是一个简单的例子:
您还可以使用LangChain的 BedrockEmbeddings 客户端与 Amazon Bedrock LLM 客户端一起简化 RAG、语义搜索和其他嵌入相关模式的实施。
嵌入的用例
尽管 RAG 目前是使用嵌入最流行的用例,但还有许多其他可以应用嵌入的用例。以下是一些您可以使用嵌入来解决特定问题的其他场景,无论是单独使用还是与法学硕士合作:
- 问题和答案 – 嵌入可以通过 RAG 模式帮助支持问答界面。嵌入生成与向量数据库相结合,使您可以在知识库中找到问题和内容之间的紧密匹配。
- 个性化推荐 – 与问答类似,您可以使用嵌入根据用户提供的条件查找度假目的地、大学、车辆或其他产品。这可以采用简单的匹配列表的形式,或者您可以使用法学硕士来处理每个推荐并解释它如何满足用户的标准。您还可以使用此方法根据用户的特定需求为用户生成自定义的“10 篇最佳”文章。
- 数据管理 – 当您的数据源彼此之间没有清晰映射,但您确实有描述数据记录的文本内容时,您可以使用嵌入来识别潜在的重复记录。例如,您可以使用嵌入来识别可能使用不同格式、缩写甚至翻译名称的重复候选者。
- 应用组合合理化 – 当寻求协调母公司和收购中的应用程序组合时,从哪里开始寻找潜在的重叠并不总是显而易见的。配置管理数据的质量可能是一个限制因素,并且跨团队协调以了解应用程序环境可能很困难。通过使用嵌入的语义匹配,我们可以跨应用程序组合进行快速分析,以识别高潜力的候选应用程序以进行合理化。
- 内容分组 – 您可以使用嵌入来帮助将类似内容分组到您提前可能不知道的类别中。例如,假设您有一组客户电子邮件或在线产品评论。您可以为每个项目创建嵌入,然后通过运行这些嵌入 k均值聚类 识别客户关注点、产品赞扬或投诉或其他主题的逻辑分组。然后,您可以使用法学硕士从这些分组的内容中生成重点摘要。
语义搜索示例
在我们的 GitHub 上的示例中,我们演示了一个使用 Amazon Titan Text Embeddings、LangChain 和 Streamlit 的简单嵌入搜索应用程序。
该示例将用户的查询与内存向量数据库中最接近的条目进行匹配。然后,我们直接在用户界面中显示这些匹配项。如果您想要对 RAG 应用程序进行故障排除或直接评估嵌入模型,这可能会很有用。
为了简单起见,我们使用内存中的 FAISS 用于存储和搜索嵌入向量的数据库。在大规模的现实场景中,您可能希望使用持久数据存储,例如 Amazon OpenSearch Serverless 的矢量引擎 或者 PG向量 PostgreSQL 的扩展。
尝试使用不同语言的 Web 应用程序发出一些提示,例如以下内容:
- 我如何监控我的使用情况?
- 如何定制模型?
- 我可以使用哪些编程语言?
- 请评论我不安全吗?
- 私のデータはどのように保护されていますか?
- 是否需要基岩模型的配置?
- 在我们的地区是亚马逊基岩 verfügbar 吗?
- 有哪些级别的支持?
请注意,即使源材料是英文的,其他语言的查询也与相关条目相匹配。
结论
基础模型的文本生成功能非常令人兴奋,但重要的是要记住,理解文本、从知识体系中查找相关内容以及在段落之间建立联系对于实现生成式人工智能的全部价值至关重要。随着这些模型的不断改进,我们将在未来几年继续看到新的、有趣的嵌入用例出现。
接下来的步骤
您可以在以下研讨会中找到以笔记本或演示应用程序形式嵌入的其他示例:
作者简介
 杰森·斯特勒 是位于新英格兰地区的 AWS 的高级解决方案架构师。 他与客户合作,使 AWS 功能与他们面临的最大业务挑战保持一致。 工作之余,他花时间建造东西并与家人一起观看漫画电影。
杰森·斯特勒 是位于新英格兰地区的 AWS 的高级解决方案架构师。 他与客户合作,使 AWS 功能与他们面临的最大业务挑战保持一致。 工作之余,他花时间建造东西并与家人一起观看漫画电影。
 尼廷优西比乌斯 是 AWS 的高级企业解决方案架构师,在软件工程、企业架构和 AI/ML 方面经验丰富。他对探索生成人工智能的可能性充满热情。他与客户合作,帮助他们在 AWS 平台上构建架构良好的应用程序,并致力于解决技术挑战并协助他们完成云之旅。
尼廷优西比乌斯 是 AWS 的高级企业解决方案架构师,在软件工程、企业架构和 AI/ML 方面经验丰富。他对探索生成人工智能的可能性充满热情。他与客户合作,帮助他们在 AWS 平台上构建架构良好的应用程序,并致力于解决技术挑战并协助他们完成云之旅。
 拉吉帕塔克 是加拿大和美国财富 50 强大型公司和中型金融服务机构 (FSI) 的首席解决方案架构师和技术顾问。他专注于机器学习应用,例如生成式 AI、自然语言处理、智能文档处理和 MLOps。
拉吉帕塔克 是加拿大和美国财富 50 强大型公司和中型金融服务机构 (FSI) 的首席解决方案架构师和技术顾问。他专注于机器学习应用,例如生成式 AI、自然语言处理、智能文档处理和 MLOps。
 玛尼哈努加 是生成式 AI 专家的技术主管、《AWS 上的应用机器学习和高性能计算》一书的作者,也是女性制造业教育基金会董事会的成员。 她领导计算机视觉、自然语言处理和生成人工智能等多个领域的机器学习 (ML) 项目。 她帮助客户大规模构建、训练和部署大型机器学习模型。 她在 re:Invent、Women in Manufacturing West、YouTube 网络研讨会和 GHC 23 等内部和外部会议上发表演讲。在空闲时间,她喜欢沿着海滩长距离跑步。
玛尼哈努加 是生成式 AI 专家的技术主管、《AWS 上的应用机器学习和高性能计算》一书的作者,也是女性制造业教育基金会董事会的成员。 她领导计算机视觉、自然语言处理和生成人工智能等多个领域的机器学习 (ML) 项目。 她帮助客户大规模构建、训练和部署大型机器学习模型。 她在 re:Invent、Women in Manufacturing West、YouTube 网络研讨会和 GHC 23 等内部和外部会议上发表演讲。在空闲时间,她喜欢沿着海滩长距离跑步。
 马克·罗伊 是 AWS 的首席机器学习架构师,帮助客户设计和构建 AI/ML 解决方案。 Mark 的工作涵盖了广泛的 ML 用例,主要关注计算机视觉、深度学习和在整个企业中扩展 ML。 他为许多行业的公司提供过帮助,包括保险、金融服务、媒体和娱乐、医疗保健、公用事业和制造业。 Mark 拥有六项 AWS 认证,包括 ML 专业认证。 在加入 AWS 之前,Mark 担任架构师、开发人员和技术领导者超过 25 年,其中 19 年从事金融服务工作。
马克·罗伊 是 AWS 的首席机器学习架构师,帮助客户设计和构建 AI/ML 解决方案。 Mark 的工作涵盖了广泛的 ML 用例,主要关注计算机视觉、深度学习和在整个企业中扩展 ML。 他为许多行业的公司提供过帮助,包括保险、金融服务、媒体和娱乐、医疗保健、公用事业和制造业。 Mark 拥有六项 AWS 认证,包括 ML 专业认证。 在加入 AWS 之前,Mark 担任架构师、开发人员和技术领导者超过 25 年,其中 19 年从事金融服务工作。
- :具有
- :是
- :不是
- :在哪里
- $UP
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- 关于
- 抽象化
- 接受
- 精准的
- 准确
- 实现
- 实现
- 获得
- 横过
- 增加
- 额外
- 优点
- 顾问
- 向前
- AI
- AI模型
- AI / ML
- 算法
- 对齐
- 所有类型
- 让
- 允许
- 允许
- 沿
- 靠
- 还
- 时刻
- Amazon
- 亚马逊网络服务
- an
- 分析
- 分析
- 和
- 回答
- 任何
- 应用领域
- 应用领域
- 应用的
- 使用
- 的途径
- 架构
- 架构
- 保健
- 国家 / 地区
- 刊文
- AS
- 协助
- At
- 增加
- 增强
- 作者
- 可使用
- AWS
- 基于
- BE
- 海滩
- 作为
- 好处
- 之间
- 板
- 董事会
- 身体
- 书
- 盒子
- 建立
- 建筑物
- 商业
- 但是
- by
- CAN
- 加拿大
- 候选人
- 候选人
- 能力
- 捕获
- 捕获
- 案件
- 例
- 类别
- 证书
- 认证
- 挑战
- 分类
- 客户
- 关闭
- 云端技术
- 集群
- 码
- 采集
- 宿舍
- 组合
- 相当常见
- 公司
- 公司
- 比较
- 投诉
- 复杂
- 一台
- 计算机视觉
- 计算
- 概念
- 关注
- 会议
- 配置
- 分享链接
- 地都
- 连接
- 一贯
- 内容
- 上下文
- 上下文
- 继续
- 方便地
- 兑换
- 转换
- 合作
- 协调
- 经济有效
- 可以
- 覆盖
- 占地面积
- 创建信息图
- 创造
- 标准
- 关键
- 目前
- 习俗
- 顾客
- 合作伙伴
- 定制
- data
- 数据库
- de
- 专用
- 深
- 深入学习
- 深深
- 定义
- 学位
- 演示
- 演示
- 部署
- 介绍
- 设计
- 旅游目的地
- 详情
- 开发商
- 不同
- 难
- 尺寸
- 直接
- 团队介绍
- 讨论
- 屏 显:
- do
- 文件
- 文件
- 域名
- 别
- 每
- 教育
- 只
- 或
- 电子邮件
- 嵌入
- 出现
- enable
- 使
- 发动机
- 工程师
- 英国
- 英语
- 企业
- 企业解决方案
- 娱乐
- 整个
- 完全
- 实体
- 醚(ETH)
- 评估
- 甚至
- 例子
- 例子
- 令人兴奋的
- 扩大
- 体验
- 有经验
- 说明
- 探索
- 延期
- 外部
- 促进
- 因素
- 家庭
- 特征
- 少数
- 金融
- 金融服务
- 找到最适合您的地方
- 寻找
- 姓氏:
- 高度灵活
- 重点
- 以下
- 针对
- 申请
- 运气
- 基金会
- 骨架
- Free
- 止
- ,
- 根本
- 生成
- 代
- 生成的
- 生成式人工智能
- 得到
- 越来越
- 给予
- 手套
- Go
- 最大的
- 民政事务总署
- 有
- he
- 医疗保健
- 帮助
- 帮助
- 帮助
- 帮助
- 这里
- 高
- 高性能计算
- 他的
- 持有
- 创新中心
- How To
- HTML
- HTTPS
- i
- 鉴定
- if
- 实施
- 进口
- 重要
- 改善
- in
- 其他
- 包括
- 包括
- 包含
- 行业
- 信息
- 输入
- 安装
- 代替
- 机构
- 保险
- 智能化
- 智能文档处理
- 兴趣
- 有趣
- 接口
- 接口
- 内部
- 国际
- 成
- IT
- 它的
- 加盟
- 旅程
- JPG
- JSON
- 键
- 知道
- 会心
- 知识
- 景观
- 语言
- 语言
- 大
- 层
- 铅
- 领导者
- 信息
- 学习
- 让
- 喜欢
- 容易
- 喜欢
- 限制
- 清单
- LLM
- 合乎逻辑的
- 长
- 看
- 寻找
- 机
- 机器学习
- 保持
- 使
- 制作
- 管理
- 颠覆性技术
- 制造业
- 许多
- 地图
- 标记
- 分数
- 市场
- 匹配
- 火柴
- 匹配
- 材料
- me
- 意
- 手段
- 媒体
- 会员
- 方法
- 可能
- ML
- ML算法
- 多播
- 模型
- 模型
- 显示器
- 更多
- 最先进的
- 最受欢迎的产品
- 电影
- 多
- my
- 姓名
- 命名
- 名称
- 自然
- 自然语言
- 自然语言处理
- 需求
- 需要
- 需要
- 全新
- 下页
- NLP
- 笔记本电脑
- 明显
- of
- 最多线路
- on
- 一
- 在线
- 打开
- 开放源码
- 优化
- 追求项目的积极优化
- or
- 秩序
- 其他名称
- 其它
- 我们的
- 输出
- 产量
- 学校以外
- 超过
- 己
- 包
- 配对
- 参数
- 参数
- 母公司
- 段落
- 多情
- 模式
- 模式
- 为
- 演出
- 性能
- 个性化
- 短语
- 片
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 播放
- 请
- 热门
- BY
- 个人档案
- 投资组合
- 可能性
- 帖子
- PostgreSQL的
- 潜力
- 功率
- 小学
- 校长
- 打印
- 先
- 问题
- 过程
- 处理
- 产品
- 产品评论
- 热销产品
- 代码编程
- 编程语言
- 项目
- 提示
- 所有权
- 提供
- 提供
- 提供
- 蟒蛇
- 质量
- 查询
- 询问
- 题
- 有疑问吗?
- 快速
- 抹布
- 范围
- RE
- 达到
- 真实的世界
- 承认
- 推荐
- 建议
- 记录
- 记录
- 指
- 关系
- 相应
- 纪念
- 知识库
- 表示
- 代表
- 请求
- 必须
- 响应
- REST的
- 受限
- 导致
- 成果
- 恢复
- 回报
- 评论
- 角色
- 运行
- 运行
- s
- 同
- 对工资盗窃
- 鳞片
- 缩放
- 脚本
- 情景
- SDK
- 搜索
- 看到
- 语义
- 语义
- 前辈
- 句子
- 情绪
- 分开
- 无服务器
- 特色服务
- 她
- 类似
- 简易
- 简单
- 简
- 简化
- 单
- SIX
- So
- 软件
- 软件工程
- 解决方案
- 解决
- 解决
- 一些
- 东西
- 来源
- 来源
- 太空
- 说
- 专家
- 专业
- 其他
- 具体的
- 开始
- 开始
- 州
- 商店
- 结构
- 这样
- SUPPORT
- 支持
- 支持
- 支持
- 采取
- 任务
- 队
- 科技
- 文案
- 技术
- 技术
- 技术
- 专业技术
- 展示
- 文本
- 文字分类
- 文字产生
- 这
- 其
- 他们
- 主题
- 然后
- 那里。
- 博曼
- 事
- Free Introduction
- 那些
- 虽然?
- 通过
- 次
- 泰坦
- 至
- 令牌
- 传统
- 培训
- 熟练
- 变形金刚
- 转型
- 理解
- 理解
- 统一
- 联合的
- 美国
- 用法
- 使用
- 用例
- 用过的
- 有用
- 用户
- 用户界面
- 用户
- 运用
- 公用事业
- 假期
- 折扣值
- 各个
- 车辆
- 非常
- 通过
- 愿景
- 想
- 是
- 观看
- we
- 卷筒纸
- Web应用程序
- Web服务
- 在线研讨会
- 井
- 为
- 西部
- ,尤其是
- 这
- 而
- 宽
- 大范围
- 将
- 中
- 也完全不需要
- 女性
- Word
- 话
- 工作
- 加工
- 合作
- 工作坊
- 将
- 写
- 写作
- 年
- 您
- 您一站式解决方案
- YouTube的
- 和风网