یہ ایک دلچسپ خیال ہے، جس میں ہارڈ ویئر سے تعاون یافتہ قیاس آرائی پر مبنی ہم آہنگی کا استعمال کرتے ہوئے تخروپن کو تیز کرنے کے لیے، ایک موڑ کے ساتھ اپنی مرضی کے مطابق ہارڈویئر کی ضرورت ہوتی ہے۔ پال کننگھم (سینئر VP/GM، تصدیق میں Cadence)، Raúl Camposano (Silicon Catalyst، کاروباری، سابق Synopsys CTO اور اب Silvaco CTO) اور میں تحقیقی نظریات پر اپنا سلسلہ جاری رکھتا ہوں۔ ہمیشہ کی طرح، تاثرات کا خیر مقدم کرتے ہیں۔

دی انوویشن
اس مہینے کا انتخاب ہے۔ Chronos: ایکسلریٹر کے لیے موثر قیاس آرائی پر مبنی ہم آہنگی. مصنفین نے یہ مقالہ پروگرامنگ زبانوں اور آپریٹنگ سسٹمز کے لیے آرکیٹیکچرل سپورٹ پر 2020 کانفرنس میں پیش کیا اور ان کا تعلق MIT سے ہے۔
ملٹی کور پروسیسرز کا استعمال کرتے ہوئے ہم آہنگی کا فائدہ اٹھانا ایپلی کیشنز کے لیے ایک آپشن ہے جہاں متوازی خود واضح ہے۔ دوسرے الگورتھم اتنی آسانی سے تقسیم نہیں ہوسکتے ہیں لیکن اندرونی ہم آہنگی کا استحصال کرتے ہوئے قیاس آرائی پر عمل درآمد سے فائدہ اٹھا سکتے ہیں۔ عام طور پر، قیاس آرائی پر عمل درآمد کا انحصار کیشے کی ہم آہنگی پر ہوتا ہے، خاص طور پر نقلی کے لیے ایک اعلی اوور ہیڈ۔ یہ طریقہ ہم آہنگی کی ضرورت کو نظرانداز کرتا ہے، ٹارگٹ ریڈ رائٹ آبجیکٹ کے ذریعے ٹائلوں کی گنتی کرنے کے لیے جسمانی طور پر ٹاسک ایگزیکیوشن کو لوکلائز کرتا ہے، اس بات کو یقینی بناتا ہے کہ عالمی ہم آہنگی کے انتظام کی ضرورت کے بغیر، مقامی طور پر تنازعات کا پتہ لگایا جا سکے۔ ٹاسک متوازی طور پر قیاس آرائی سے انجام دے سکتے ہیں۔ کسی بھی تنازعہ کا پتہ چلا اسے اس کے چائلڈ ٹاسک کے ذریعے ٹاسک سے ہٹایا جا سکتا ہے پھر دوسرے تھریڈز کو روکنے کی ضرورت کے بغیر دوبارہ عمل میں لایا جا سکتا ہے۔
یہاں ایک اور نکتہ قابل توجہ ہے۔ یہ طریقہ زیادہ تر ہارڈویئر ایکسلریشن تکنیکوں کے برعکس تاخیر پر مبنی تخروپن کی حمایت کرتا ہے۔
پال کا نظریہ
واہ، ایم آئی ٹی سے کتنا شاندار ہائی آکٹین پیپر ہے! جب متوازی حساب کے بارے میں پوچھا گیا تو میں فوری طور پر تھریڈز، میٹیکسز، اور میموری ہم آہنگی کے بارے میں سوچتا ہوں۔ بلاشبہ یہ ہے کہ جدید ملٹی کور CPUs کو کس طرح ڈیزائن کیا گیا ہے۔ لیکن ہارڈ ویئر میں ہم آہنگی کی حمایت کرنے کا یہ واحد طریقہ نہیں ہے۔
یہ مقالہ متوازی کے لیے ایک متبادل فن تعمیر کی تجویز پیش کرتا ہے جسے Chronos کہتے ہیں جو کاموں کی ترتیب شدہ قطار پر مبنی ہے۔ رن ٹائم کے وقت، کاموں کو ٹائم اسٹیمپ ترتیب میں انجام دیا جاتا ہے اور ہر کام نئے ذیلی کام بنا سکتا ہے جو متحرک طور پر قطار میں شامل کیے جاتے ہیں۔ عمل درآمد کچھ ابتدائی کاموں کو قطار میں ڈال کر شروع ہوتا ہے اور قطار میں مزید کام نہ ہونے پر ختم ہوتا ہے۔
قطار میں موجود ٹاسک متوازی طور پر متعدد پروسیسنگ عناصر (PEs) کے لیے تیار کیے جاتے ہیں - جس کا مطلب ہے کہ Chronos قیاس آرائی کے ساتھ مستقبل کے کاموں کو موجودہ کام کے مکمل ہونے سے پہلے انجام دے رہا ہے۔ اگر موجودہ ٹاسک مستقبل کے قیاس آرائیوں سے انجام پانے والے کسی بھی کام کو باطل کرتا ہے تو پھر ان مستقبل کے کاموں کی کارروائیاں "کالعدم" ہو جاتی ہیں اور وہ دوبارہ قطار میں لگ جاتے ہیں۔ ہارڈ ویئر میں اس تصور کو درست طریقے سے نافذ کرنا آسان نہیں ہے، لیکن باہر کے صارف کے لیے یہ خوبصورت ہے: آپ صرف اپنے الگورتھم کو اس طرح کوڈ کرتے ہیں جیسے ٹاسک کیو کو ایک ہی PE پر سلسلہ وار عمل میں لایا جا رہا ہو۔ کسی بھی mutexes کو کوڈ کرنے یا تعطل کے بارے میں فکر کرنے کی ضرورت نہیں ہے۔
مصنفین SystemVerilog میں Chronos کو نافذ کرتے ہیں اور اسے FPGA میں مرتب کرتے ہیں۔ زیادہ تر کاغذ یہ بتانے کے لیے وقف ہے کہ انھوں نے کس طرح ٹاسک کیو کو لاگو کیا ہے اور زیادہ سے زیادہ کارکردگی کے لیے ہارڈ ویئر میں کوئی ضروری انرولنگ کیسے کی گئی ہے۔ Chronos کو چار الگورتھم پر بینچ مارک کیا گیا ہے جو ٹاسک کیو پر مبنی فن تعمیر کے لیے موزوں ہے۔ ہر الگورتھم کو دو طریقوں سے لاگو کیا جاتا ہے: پہلا الگورتھم کے لیے مخصوص PE کا استعمال کرتے ہوئے، اور دوسرا آف دی شیلف اوپن سورس 32 بٹ ایمبیڈڈ RISC-V CPU کو بطور PE استعمال کرنا۔ اس کے بعد Chronos کی کارکردگی کا موازنہ Intel Xeon سرور پر چلنے والے الگورتھم کے ملٹی تھریڈڈ سافٹ ویئر کے نفاذ سے کیا جاتا ہے جس کی قیمت Chronos کے لیے FPGA سے ملتی جلتی ہے۔ نتائج متاثر کن ہیں - Chronos اسکیل Xeon سرور استعمال کرنے سے 3x سے 15x بہتر ہے۔ تاہم، ٹیبل 3 کا فگر 14 سے موازنہ کرنا مجھے قدرے پریشان کر دیتا ہے کہ ان میں سے زیادہ تر فوائد خود Chronos فن تعمیر کے بجائے الگورتھم سے متعلق مخصوص PEs سے حاصل ہوئے ہیں۔
یہ ایک تصدیقی بلاگ ہے جسے میں نے قدرتی طور پر گیٹ لیول سمولیشن بینچ مارک پر زوم کیا ہے۔ ای ڈی اے انڈسٹری نے منطقی تخروپن کو آزمانے اور اس کو متوازی بنانے کے لیے بہت زیادہ سرمایہ کاری کی ہے اور استعمال کے چند مخصوص معاملات سے زیادہ بڑے فوائد کو دیکھنا مشکل ثابت ہوا ہے۔ اس کی بنیادی وجہ L3-cache میں لوڈ/اسٹور کی ہدایات کے غائب ہونے اور DRAM پر جانے کی وجہ سے زیادہ تر حقیقی دنیا کے سمولیشنز کی کارکردگی ہے۔ اس مقالے میں صرف ایک ٹیسٹ کیس بینچ مارک کیا گیا ہے اور یہ ایک چھوٹا 32 بٹ کیری سیو ایڈر ہے۔ اگر آپ اس بلاگ کو پڑھ رہے ہیں اور کچھ اور مکمل بینچ مارکنگ کرنے میں دلچسپی رکھتے ہیں تو براہ کرم مجھے بتائیں – اگر Chronos واقعی حقیقی دنیا کے نقوش پر اچھی طرح سے پیمائش کر سکتا ہے تو اس کی بہت بڑی تجارتی قیمت ہوگی!
راول کا نظریہ
اس مقالے کی اہم شراکت ہے۔ Spatially Located Ordered Tasks (SLOT) پر عمل درآمد کا ماڈل جو ہارڈ ویئر ایکسلریٹر کے لیے کارآمد ہے جو متوازی اور قیاس آرائیوں کا استحصال کرتے ہیں، اور ایسی ایپلی کیشنز کے لیے جو رن ٹائم کے وقت متحرک طور پر کام پیدا کرتے ہیں۔ متحرک متوازی تعاون نقلی کے لیے ناگزیر ہے اور قیاس آرائی پر مبنی ہم آہنگی ایک دلکش آپشن ہے، لیکن ہم آہنگی اوور ہیڈ بہت زیادہ ہے۔
SLOT ہر ٹاسک کو کسی ایک شے پر چلانے (لکھنے) پر پابندی لگا کر ہم آہنگی کی ضرورت سے گریز کرتا ہے اور ملٹی آبجیکٹ ایٹمیسیٹی کو فعال کرنے کے لیے ترتیب شدہ کاموں کی حمایت کرتا ہے۔ SLOT ایپلیکیشنز کا آرڈر دیا جاتا ہے، متحرک طور پر تخلیق کردہ کاموں کو ٹائم اسٹیمپ اور ایک آبجیکٹ آئی ڈی کے ذریعے خصوصیت دی جاتی ہے۔ ٹائم اسٹیمپ آرڈر کی پابندیاں بتاتے ہیں۔ آبجیکٹ آئی ڈی ڈیٹا پر انحصار کی وضاحت کرتی ہے، یعنی کام ڈیٹا پر منحصر ہوتے ہیں اور صرف اس صورت میں جب ان کے پاس ایک ہی آبجیکٹ آئی ڈی ہو۔ (اگر پڑھنے کا انحصار ہے تو اس کام کو قیاس آرائی کے ساتھ انجام دیا جاسکتا ہے)۔ آبجیکٹ آئی ڈی کو کور یا ٹائل میں میپ کرکے اور ہر کام کو جہاں اس کی آبجیکٹ آئی ڈی میپ کی گئی ہے وہاں بھیج کر تنازعات کا پتہ لگانا مقامی ہو جاتا ہے (بغیر پیچیدہ ٹریکنگ ڈھانچے کے)۔
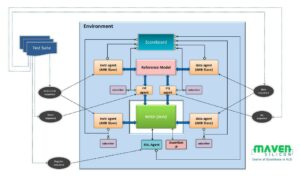
۔ کرونوس سسٹم کو AWS FPGA فریم ورک میں 16 ٹائلوں کے ساتھ ایک سسٹم کے طور پر لاگو کیا گیا تھا، ہر ایک میں 4 ایپلیکیشن مخصوص پروسیسنگ عناصر (PE)، 125MHz پر چل رہا تھا۔ اس سسٹم کا موازنہ 20-core/40-thread 2.4 GHz Intel Xeon E5-2676v3 پر مشتمل ایک بیس لائن سے کیا گیا ہے، خاص طور پر اس لیے منتخب کیا گیا ہے کہ اس کی قیمت FPGA ایک (تقریباً $2/hour) کے ساتھ موازنہ ہے۔ ایک PE پر ایک ہی کام چلانا، Chronos بیس لائن سے 2.45x تیز ہے۔ جیسے جیسے ہم آہنگی کے کاموں کی تعداد میں اضافہ ہوتا ہے، Chronos کا نفاذ 44.9 ٹائلوں پر 8x کی خود ساختہ رفتار تک پہنچ جاتا ہے، جو CPU کے نفاذ کے مقابلے میں 15.3x کی رفتار کے مطابق ہوتا ہے۔ انہوں نے اطلاق کے مخصوص PEs کے بجائے عام مقصد RISC-V پر مبنی عمل کا موازنہ بھی کیا۔ PEs RISC-V سے 5x تیز تھے۔
مجھے یہ کاغذ متاثر کن لگا کیونکہ اس میں ایک تصور سے لے کر SLOT ایگزیکیوشن ماڈل کی تعریف سے لے کر ہارڈ ویئر کے نفاذ تک اور 4 ایپلی کیشنز کے لیے روایتی Xeon CPU کے ساتھ تفصیلی موازنہ شامل ہے۔ کوشش کافی ہے، Chronos SystemVerilog کی 20,000 لائنوں سے زیادہ ہے۔ نتیجہ سوفٹ ویئر کے متوازی ورژن کے مقابلے میں 5.4x اوسط (4 ایپلی کیشنز میں سے) کی رفتار ہے، زیادہ متوازی اور قیاس آرائی کے زیادہ استعمال کی وجہ سے۔ غیر نقلی کاموں کے اطلاق کے لیے کاغذ بھی پڑھنے کے قابل ہے۔ کاغذ میں تین مثالیں شامل ہیں۔
اس پوسٹ کو بذریعہ شیئر کریں:
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://semiwiki.com/eda/326261-speculation-for-simulation-innovation-in-verification/
- : ہے
- 000
- 2020
- 8
- a
- ہمارے بارے میں
- رفتار کو تیز تر
- تیزی
- ایکسلریٹر
- ACM
- اعمال
- شامل کیا
- یلگورتم
- یلگوردمز
- متبادل
- ہمیشہ
- اور
- اپیل
- درخواست
- درخواست مخصوص
- ایپلی کیشنز
- ارکیٹیکچرل
- فن تعمیر
- کیا
- AS
- At
- مصنفین
- AWS
- کی بنیاد پر
- بیس لائن
- BE
- خوبصورت
- کیونکہ
- ہو جاتا ہے
- اس سے پہلے
- کیا جا رہا ہے
- معیار
- بینچ مارک
- فائدہ
- بہتر
- سے پرے
- بگ
- بٹ
- بلاگ
- by
- کیشے
- Cadence سے
- کہا جاتا ہے
- کر سکتے ہیں
- لے جانے کے
- مقدمات
- عمل انگیز
- خصوصیات
- بچے
- منتخب کیا
- کوڈ
- تجارتی
- موازنہ
- مقابلے میں
- موازنہ
- موازنہ
- مکمل
- پیچیدہ
- حساب
- کمپیوٹنگ
- تصور
- سمورتی
- کانفرنس
- تنازعہ
- پر مشتمل ہے
- رکاوٹوں
- جاری
- شراکت
- اسی کے مطابق
- کورس
- پر محیط ہے
- CPU
- تخلیق
- بنائی
- CTO
- موجودہ
- اپنی مرضی کے
- اعداد و شمار
- وقف
- انحصار
- انحصار کرتا ہے
- ڈیزائن
- تفصیلی
- پتہ چلا
- کھوج
- مشکل
- متحرک
- متحرک طور پر
- e
- ہر ایک
- آسانی سے
- کارکردگی
- ہنر
- کوشش
- عناصر
- ایمبیڈڈ
- کو چالو کرنے کے
- ختم ہو جاتا ہے
- کو یقینی بنانے ہے
- ٹھیکیدار
- خاص طور پر
- سب کچھ
- مثال کے طور پر
- عملدرآمد
- پھانسی
- پھانسی
- کی وضاحت
- دھماکہ
- تیز تر
- آراء
- چند
- اعداد و شمار
- پہلا
- کے لئے
- سابق
- ملا
- fpga
- فریم ورک
- سے
- مستقبل
- فوائد
- جنرل
- پیدا
- گیگا ہرٹز انٹیل
- گلوبل
- جا
- ہارڈ ویئر
- ہے
- بھاری
- یہاں
- ہائی
- کس طرح
- تاہم
- HTTPS
- بھاری
- i
- ID
- خیال
- خیالات
- فوری طور پر
- پر عملدرآمد
- نفاذ
- عملدرآمد
- پر عمل درآمد
- متاثر کن
- in
- شامل ہیں
- اضافہ
- صنعت
- ناگزیر
- ابتدائی
- جدت طرازی
- ہدایات
- انٹیل
- دلچسپی
- دلچسپ
- اندرونی
- سرمایہ کاری کی
- IT
- میں
- خود
- جان
- زبانیں
- لائنوں
- مقامی
- مقامی طور پر
- واقع ہے
- مین
- بناتا ہے
- انتظام
- تعریفیں
- زیادہ سے زیادہ چوڑائی
- زیادہ سے زیادہ
- کا مطلب ہے کہ
- یاد داشت
- طریقہ
- شاید
- لاپتہ
- ایم ائی ٹی
- ماڈل
- جدید
- زیادہ
- سب سے زیادہ
- ایک سے زیادہ
- ضروری
- ضرورت ہے
- نئی
- تعداد
- اعتراض
- of
- on
- ایک
- کھول
- اوپن سورس
- کام
- کام
- آپریٹنگ سسٹم
- اختیار
- حکم
- دیگر
- باہر
- پی اینڈ ای
- کاغذ.
- متوازی
- پال
- کارکردگی
- جسمانی طورپر
- لینے
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- مہربانی کرکے
- پوائنٹ
- پوسٹ
- پیش
- قیمت
- پروسیسنگ
- پروسیسرز
- پروگرامنگ
- پروگرامنگ زبانوں
- تجویز کرتا ہے
- ثابت
- مقصد
- ڈالنا
- بلکہ
- پڑھیں
- پڑھنا
- اصلی
- حقیقی دنیا
- تحقیق
- پابندی لگانا
- نتیجہ
- نتائج کی نمائش
- چل رہا ہے
- اسی
- محفوظ کریں
- پیمانے
- ترازو
- دوسری
- بھیجنا
- سینئر
- سیریز
- شیلف
- سلیکن
- اسی طرح
- تخروپن
- ایک
- So
- سافٹ ویئر کی
- کچھ
- ماخذ
- مخصوص
- خاص طور پر
- قیاس
- کافی
- حمایت
- کی حمایت کرتا ہے
- ہم آہنگی
- کے نظام
- سسٹمز
- ٹیبل
- TAG
- ہدف
- ٹاسک
- کاموں
- تکنیک
- کہ
- ۔
- یہ
- تین
- کے ذریعے
- ٹائمسٹیمپ
- کرنے کے لئے
- بھی
- ٹریکنگ
- روایتی
- موڑ
- استعمال کی شرائط
- رکن کا
- عام طور پر
- توثیق
- کی طرف سے
- راستہ..
- طریقوں
- آپ کا استقبال ہے
- اچھا ہے
- کیا
- جس
- ساتھ
- بغیر
- بہت اچھا
- دنیا
- قابل
- گا
- لکھنا
- اور
- زیفیرنیٹ