جیسا کہ گزشتہ 16+ سالوں میں Roblox میں اضافہ ہوا ہے، اسی طرح تکنیکی انفراسٹرکچر کا پیمانہ اور پیچیدگی بھی ہے جو لاکھوں عمیق 3D تعاون کے تجربات کو سپورٹ کرتا ہے۔ جن مشینوں کو ہم سپورٹ کرتے ہیں ان کی تعداد پچھلے دو سالوں میں تین گنا سے زیادہ ہو گئی ہے، 36,000 جون 30 تک تقریباً 2021 سے آج تقریباً 145,000 ہو گئی ہے۔ دنیا بھر کے لوگوں کے لیے ان ہمیشہ جاری رہنے والے تجربات کی حمایت کرنے کے لیے 1,000 سے زیادہ داخلی خدمات کی ضرورت ہوتی ہے۔ لاگت اور نیٹ ورک کی تاخیر کو کنٹرول کرنے میں ہماری مدد کرنے کے لیے، ہم ان مشینوں کو اپنی مرضی کے مطابق بنائے گئے اور ہائبرڈ پرائیویٹ کلاؤڈ انفراسٹرکچر کے حصے کے طور پر تعینات اور ان کا نظم کرتے ہیں جو بنیادی طور پر احاطے پر چلتا ہے۔
ہمارا بنیادی ڈھانچہ فی الحال دنیا بھر میں 70 ملین سے زیادہ یومیہ فعال صارفین کی مدد کرتا ہے، بشمول وہ تخلیق کار جو روبلوکس پر انحصار کرتے ہیں۔ معیشت کو ان کے کاروبار کے لیے۔ یہ تمام لاکھوں لوگ بہت اعلیٰ سطح کی وشوسنییتا کی توقع کرتے ہیں۔ ہمارے تجربات کی عمیق نوعیت کے پیش نظر، وقفے یا تاخیر کے لیے انتہائی کم رواداری ہے، بندش کو چھوڑ دیں۔ Roblox مواصلات اور رابطے کا ایک پلیٹ فارم ہے، جہاں لوگ عمیق 3D تجربات میں اکٹھے ہوتے ہیں۔ جب لوگ ایک عمیق جگہ میں اپنے اوتار کے طور پر بات چیت کر رہے ہوتے ہیں، یہاں تک کہ معمولی تاخیر یا خرابیاں بھی ٹیکسٹ تھریڈ یا کانفرنس کال کی نسبت زیادہ نمایاں ہوتی ہیں۔
اکتوبر 2021 میں، ہمیں پورے نظام کی بندش کا سامنا کرنا پڑا۔ یہ ایک ڈیٹا سینٹر میں ایک جزو میں ایک مسئلہ کے ساتھ، چھوٹا شروع ہوا. لیکن یہ تیزی سے پھیل گیا جب ہم تحقیقات کر رہے تھے اور بالآخر 73 گھنٹے کی بندش کا نتیجہ نکلا۔ اس وقت، ہم نے دونوں کا اشتراک کیا کیا ہوا کے بارے میں تفصیلات اور مسئلے سے ہماری کچھ ابتدائی تعلیمات۔ تب سے، ہم ان سیکھنے کا مطالعہ کر رہے ہیں اور اپنے بنیادی ڈھانچے کی ان ناکامیوں کی قسموں کے لیے لچک کو بڑھانے کے لیے کام کر رہے ہیں جو تمام بڑے پیمانے پر سسٹمز میں بہت زیادہ ٹریفک اسپائکس، موسم، ہارڈ ویئر کی ناکامی، سافٹ ویئر کی خرابیوں، یا صرف انسان غلطیاں کرتے ہیں. جب یہ ناکامیاں ہوتی ہیں، تو ہم کس طرح اس بات کو یقینی بناتے ہیں کہ کسی ایک جزو، یا اجزاء کے گروپ میں کوئی مسئلہ پورے نظام تک نہ پھیلے؟ یہ سوال پچھلے دو سالوں سے ہماری توجہ کا مرکز رہا ہے اور جب کام جاری ہے، ہم نے اب تک جو کچھ کیا ہے وہ پہلے ہی ادا کر رہا ہے۔ مثال کے طور پر، 2023 کی پہلی ششماہی میں، ہم نے 125 کی پہلی ششماہی کے مقابلے میں ہر ماہ 2022 ملین مصروفیات کے گھنٹے بچائے ہیں۔ آج، ہم پہلے سے کیے گئے کام کے ساتھ ساتھ تعمیر کے لیے اپنے طویل مدتی وژن کو بھی شیئر کر رہے ہیں۔ ایک زیادہ لچکدار بنیادی ڈھانچے کا نظام۔
بیک اسٹاپ کی تعمیر
بڑے پیمانے پر بنیادی ڈھانچے کے نظام کے اندر، چھوٹے پیمانے پر ناکامیاں دن میں کئی بار ہوتی ہیں۔ اگر ایک مشین میں کوئی مسئلہ ہے اور اسے سروس سے ہٹانا ہے، تو یہ قابل انتظام ہے کیونکہ زیادہ تر کمپنیاں اپنی بیک اینڈ سروسز کی متعدد مثالیں برقرار رکھتی ہیں۔ لہذا جب ایک مثال ناکام ہوجاتی ہے، تو دوسرے کام کا بوجھ اٹھا لیتے ہیں۔ ان متواتر ناکامیوں کو دور کرنے کے لیے، درخواستوں کو عام طور پر خود بخود دوبارہ کوشش کرنے کے لیے سیٹ کیا جاتا ہے اگر ان میں کوئی غلطی ہو جائے۔
یہ اس وقت مشکل ہو جاتا ہے جب کوئی نظام یا شخص بہت زیادہ جارحانہ انداز میں دوبارہ کوشش کرتا ہے، جو ان چھوٹے پیمانے پر ناکامیوں کے لیے پورے انفراسٹرکچر میں دیگر سروسز اور سسٹمز تک پھیلانے کا ایک طریقہ بن سکتا ہے۔ اگر نیٹ ورک یا صارف مسلسل کوشش کرتا ہے، تو یہ بالآخر اس سروس کی ہر مثال، اور ممکنہ طور پر دوسرے سسٹمز کو عالمی سطح پر اوورلوڈ کر دے گا۔ ہماری 2021 کی بندش کسی ایسی چیز کا نتیجہ تھی جو بڑے پیمانے پر سسٹمز میں کافی عام ہے: ایک ناکامی چھوٹی سے شروع ہوتی ہے پھر سسٹم کے ذریعے پھیلتی ہے، اتنی جلدی بڑی ہو جاتی ہے کہ سب کچھ ختم ہونے سے پہلے اسے حل کرنا مشکل ہو جاتا ہے۔
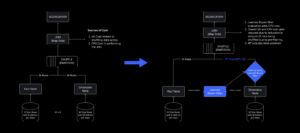
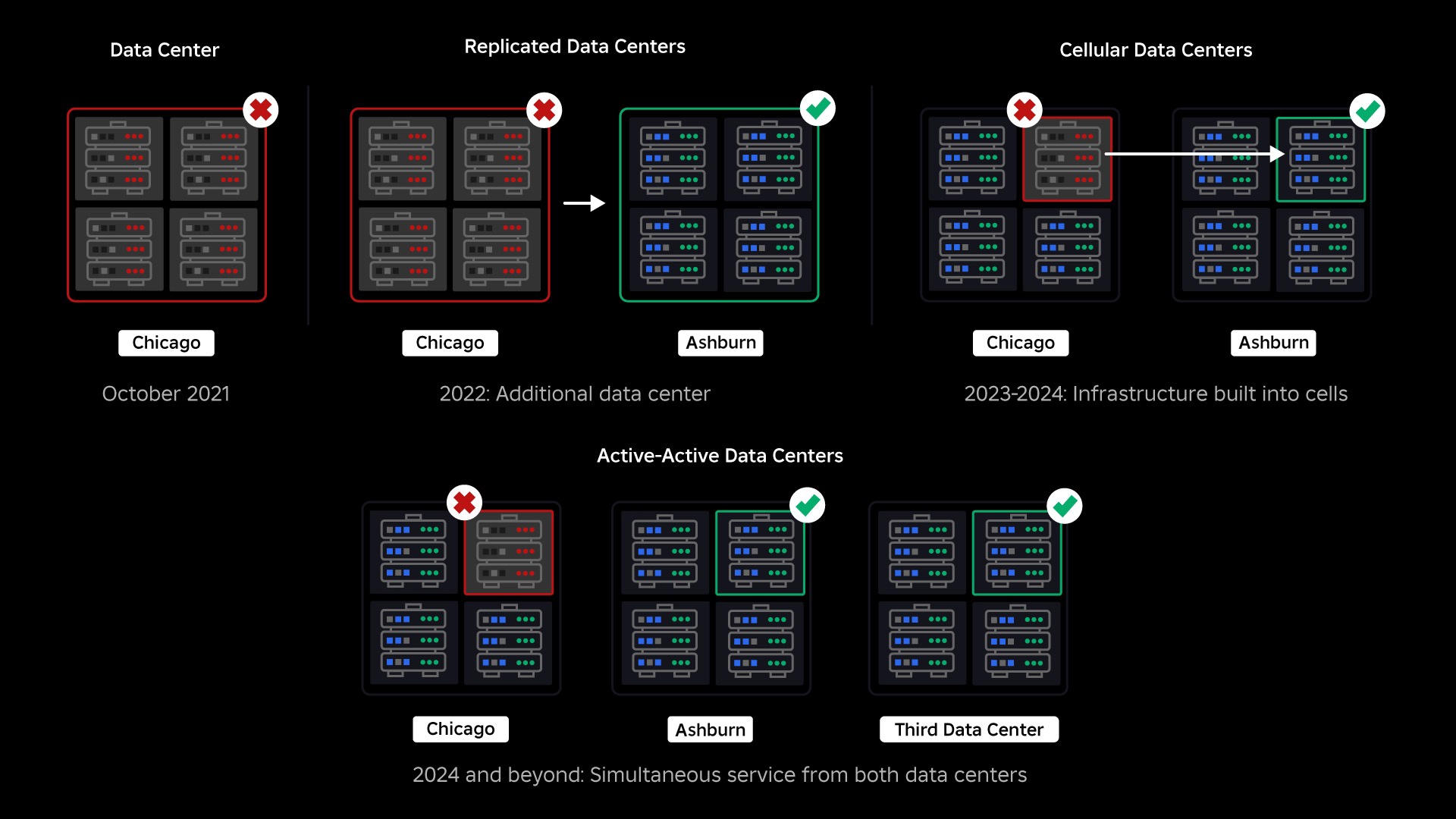
ہماری بندش کے وقت، ہمارے پاس ایک فعال ڈیٹا سینٹر تھا (اس کے اندر موجود اجزاء بیک اپ کے طور پر کام کر رہے تھے)۔ ہمیں نئے ڈیٹا سینٹر میں دستی طور پر ناکام ہونے کی صلاحیت کی ضرورت ہوتی ہے جب کوئی مسئلہ موجودہ کو نیچے لے آتا ہے۔ ہماری پہلی ترجیح اس بات کو یقینی بنانا تھی کہ ہمارے پاس Roblox کی بیک اپ تعیناتی ہے، لہذا ہم نے اس بیک اپ کو ایک نئے ڈیٹا سینٹر میں بنایا، جو ایک مختلف جغرافیائی خطے میں واقع ہے۔ اس نے بدترین صورت حال کے لیے تحفظ میں اضافہ کیا: ڈیٹا سینٹر کے اندر کافی اجزاء تک پھیلنے والی بندش کہ یہ مکمل طور پر ناکارہ ہو جاتا ہے۔ ہمارے پاس اب ایک ڈیٹا سینٹر ہے جو کام کے بوجھ کو سنبھالتا ہے (فعال) اور ایک اسٹینڈ بائی پر، بیک اپ (غیر فعال) کے طور پر کام کرتا ہے۔ ہمارا طویل مدتی مقصد اس ایکٹو-غیر فعال کنفیگریشن سے ایک فعال-ایکٹو کنفیگریشن کی طرف جانا ہے، جس میں دونوں ڈیٹا سینٹرز کام کے بوجھ کو ہینڈل کرتے ہیں، ایک لوڈ بیلنسر کے ساتھ ان کے درمیان تاخیر، صلاحیت اور صحت کی بنیاد پر درخواستوں کی تقسیم ہوتی ہے۔ ایک بار جب یہ ہو جائے گا، تو ہم توقع کرتے ہیں کہ تمام Roblox کے لیے اور بھی زیادہ بھروسا ہو گا اور کئی گھنٹوں کے بجائے تقریباً فوری طور پر ناکام ہو جائیں گے۔ 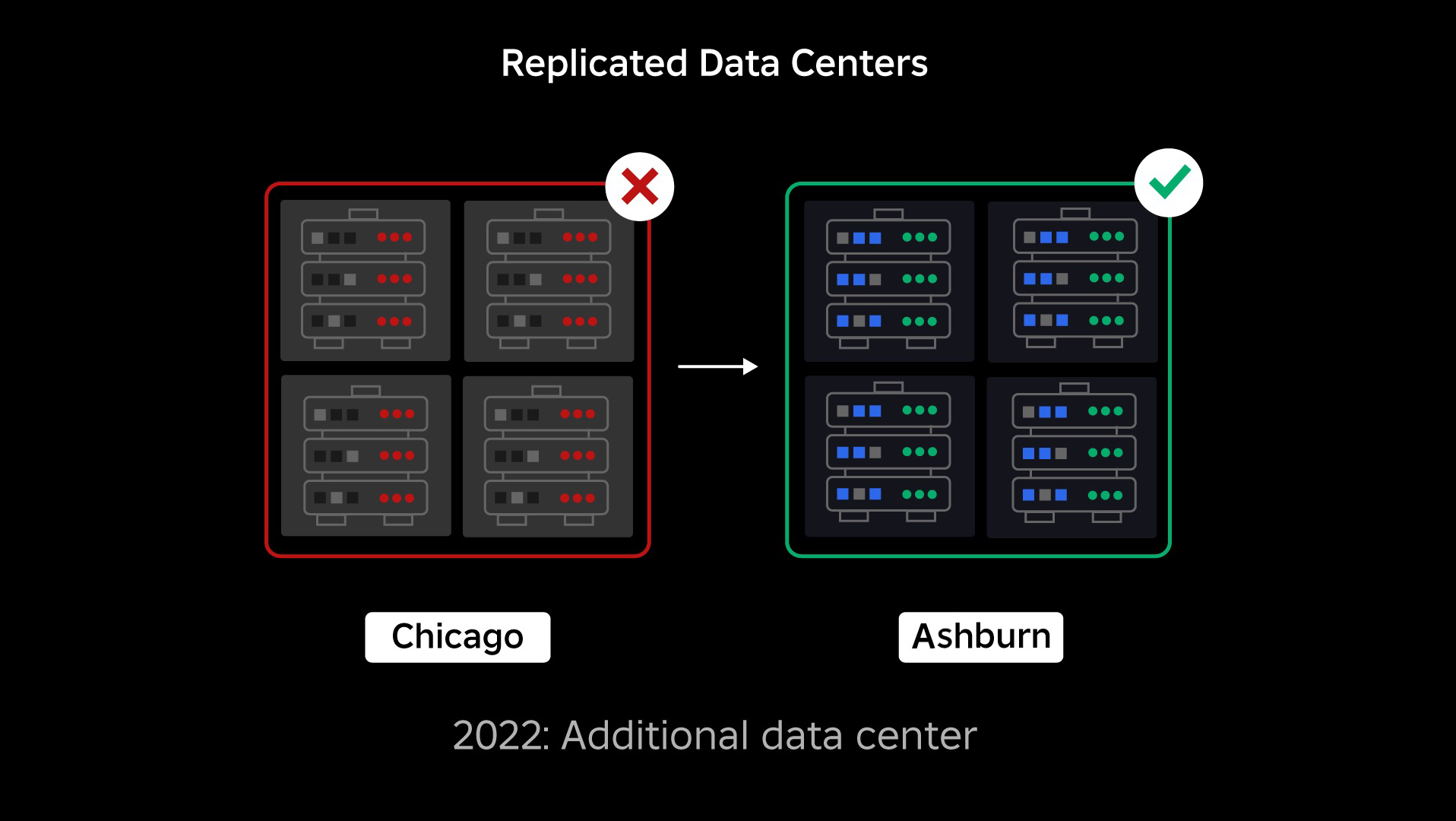
سیلولر انفراسٹرکچر میں منتقل ہونا
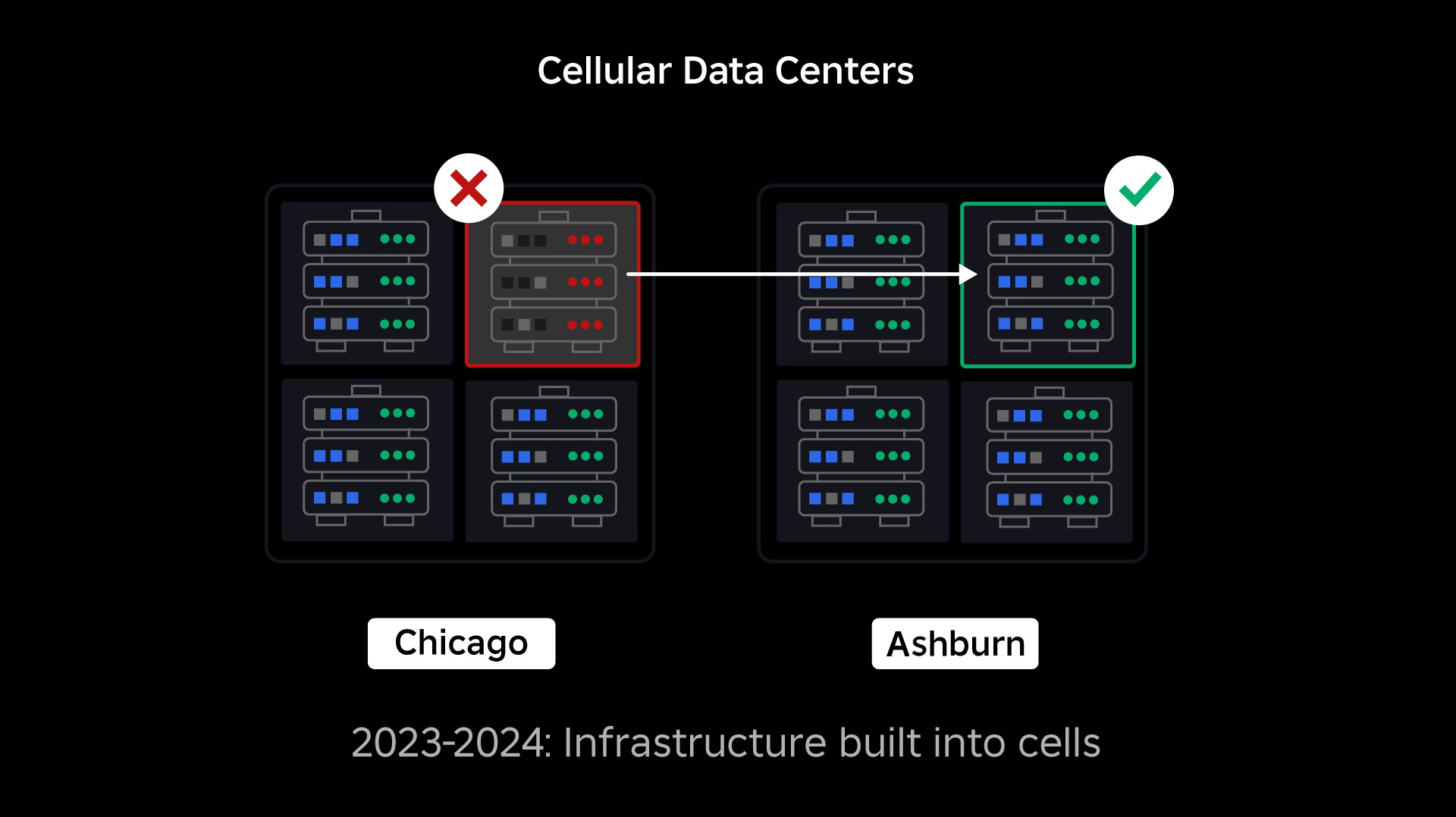
ہماری اگلی ترجیح ہر ڈیٹا سینٹر کے اندر مضبوط دھماکے والی دیواریں بنانا تھی تاکہ پورے ڈیٹا سینٹر کے ناکام ہونے کے امکان کو کم کیا جا سکے۔ سیل (کچھ کمپنیاں انہیں کلسٹر کہتے ہیں) بنیادی طور پر مشینوں کا ایک سیٹ ہیں اور ہم ان دیواروں کو کیسے بنا رہے ہیں۔ اضافی فالتو پن کے لیے ہم سیل کے اندر اور اس کے پار خدمات کی نقل تیار کرتے ہیں۔ بالآخر، ہم چاہتے ہیں کہ روبلوکس کی تمام سروسز سیلز میں چلیں تاکہ وہ مضبوط دھماکے والی دیواروں اور بے کار پن دونوں سے فائدہ اٹھا سکیں۔ اگر کوئی سیل اب فعال نہیں ہے، تو اسے محفوظ طریقے سے غیر فعال کیا جا سکتا ہے۔ سیلوں میں نقل کرنا سروس کو اس قابل بناتا ہے کہ وہ سیل کی مرمت کے دوران چلتا رہے۔ بعض صورتوں میں، سیل کی مرمت کا مطلب سیل کی مکمل بحالی ہو سکتا ہے۔ پوری صنعت میں، ایک انفرادی مشین، یا مشینوں کے ایک چھوٹے سیٹ کو صاف کرنا اور دوبارہ ترتیب دینا، کافی عام ہے، لیکن ایسا ایک پورے سیل کے لیے کرنا، جس میں ~1,400 مشینیں ہیں، ایسا نہیں ہے۔
اس کے کام کرنے کے لیے، ان خلیوں کو زیادہ تر یکساں ہونے کی ضرورت ہے، تاکہ ہم تیزی سے اور مؤثر طریقے سے کام کے بوجھ کو ایک خلیے سے دوسرے خلیے میں منتقل کر سکیں۔ ہم نے کچھ تقاضے طے کیے ہیں جو خدمات کو سیل میں چلنے سے پہلے پورا کرنے کی ضرورت ہے۔ مثال کے طور پر، خدمات کا کنٹینرائز ہونا ضروری ہے، جو انہیں بہت زیادہ پورٹیبل بناتا ہے اور کسی کو بھی OS کی سطح پر کنفیگریشن تبدیلیاں کرنے سے روکتا ہے۔ ہم نے سیلز کے لیے بنیادی ڈھانچے کے بطور کوڈ فلسفہ اپنایا ہے: اپنے ماخذ کوڈ کے ذخیرے میں، ہم سیل میں موجود ہر چیز کی تعریف شامل کرتے ہیں تاکہ ہم خودکار ٹولز کا استعمال کرتے ہوئے اسے جلد از جلد دوبارہ بنا سکیں۔
فی الحال سبھی سروسز ان تقاضوں کو پورا نہیں کرتی ہیں، اس لیے ہم نے جہاں ممکن ہو سکے سروس کے مالکان کی ان کو پورا کرنے میں مدد کرنے کے لیے کام کیا ہے، اور ہم نے نئے ٹولز بنائے ہیں تاکہ تیار ہونے پر سروسز کو سیلز میں منتقل کرنا آسان بنایا جا سکے۔ مثال کے طور پر، ہمارا نیا تعیناتی ٹول سیلز میں سروس کی تعیناتی کو خود بخود "سٹرائپ" کرتا ہے، لہذا سروس مالکان کو نقل کی حکمت عملی کے بارے میں سوچنے کی ضرورت نہیں ہے۔ سختی کی یہ سطح نقل مکانی کے عمل کو بہت زیادہ مشکل اور وقت طلب بناتی ہے، لیکن طویل مدتی ادائیگی ایک ایسا نظام ہو گا جہاں:
- ناکامی پر قابو پانا اور اسے دوسرے خلیوں میں پھیلنے سے روکنا بہت آسان ہے۔
- ہمارے بنیادی ڈھانچے کے انجینئرز زیادہ موثر اور تیزی سے آگے بڑھ سکتے ہیں۔ اور
- وہ انجینئر جو پروڈکٹ کی سطح کی خدمات تیار کرتے ہیں جو بالآخر سیلز میں لگائی جاتی ہیں انہیں یہ جاننے یا فکر کرنے کی ضرورت نہیں ہوتی کہ ان کی خدمات کن سیلوں میں چل رہی ہیں۔
بڑے چیلنجز کو حل کرنا
جس طرح سے آگ کے دروازے شعلوں پر قابو پانے کے لیے استعمال کیے جاتے ہیں، اسی طرح خلیے ہمارے بنیادی ڈھانچے کے اندر مضبوط دھماکے کی دیواروں کے طور پر کام کرتے ہیں تاکہ کسی بھی خلیے کے اندر ناکامی کا باعث بننے والے کسی بھی مسئلے پر قابو پایا جا سکے۔ آخر کار، روبلوکس بنانے والی تمام خدمات کو سیل کے اندر اور اس کے پار بے کار طور پر تعینات کر دیا جائے گا۔ ایک بار جب یہ کام مکمل ہو جاتا ہے تو، مسائل اب بھی کافی حد تک پھیل سکتے ہیں تاکہ ایک پورے سیل کو ناقابل عمل بنایا جا سکے، لیکن کسی مسئلے کے لیے اس سیل سے باہر پھیلنا بہت مشکل ہو گا۔ اور اگر ہم خلیات کو قابل تبادلہ بنانے میں کامیاب ہو جاتے ہیں، تو بحالی نمایاں طور پر تیز ہو جائے گی۔ کیونکہ ہم ایک مختلف سیل میں ناکام ہونے کے قابل ہو جائیں گے اور اس مسئلے کو اختتامی صارفین کو متاثر کرنے سے روکیں گے۔
جہاں یہ مشکل ہو جاتا ہے وہ ان خلیوں کو کافی حد تک الگ کر رہا ہے تاکہ چیزوں کو پرفارمنس اور فعال رکھتے ہوئے غلطیوں کو پھیلانے کے مواقع کو کم کیا جا سکے۔ ایک پیچیدہ بنیادی ڈھانچے کے نظام میں، خدمات کو سوالات، معلومات، کام کے بوجھ وغیرہ کا اشتراک کرنے کے لیے ایک دوسرے کے ساتھ بات چیت کرنے کی ضرورت ہوتی ہے۔ جب ہم ان خدمات کو سیلوں میں نقل کرتے ہیں، ہمیں اس بارے میں سوچنے کی ضرورت ہوتی ہے کہ ہم کس طرح کراس کمیونیکیشن کا انتظام کرتے ہیں۔ ایک مثالی دنیا میں، ہم ٹریفک کو ایک غیر صحت مند سیل سے دوسرے صحت مند خلیوں کی طرف بھیجتے ہیں۔ لیکن ہم "موت کے سوال" کو کس طرح منظم کرتے ہیں - وہ ایک ہے۔ باعث ایک سیل غیر صحت مند ہو؟ اگر ہم اس استفسار کو کسی دوسرے سیل کی طرف بھیجتے ہیں، تو یہ اس سیل کو بالکل اسی طرح سے غیر صحت بخش بنا سکتا ہے جس سے ہم بچنے کی کوشش کر رہے ہیں۔ ہمیں غیر صحت مند خلیوں سے "اچھی" ٹریفک کو منتقل کرنے کے لیے میکانزم تلاش کرنے کی ضرورت ہے جبکہ اس ٹریفک کا پتہ لگانا اور اس کا پتہ لگانا جو خلیات کے غیر صحت مند ہونے کا سبب بن رہے ہیں۔
مختصر مدت میں، ہم نے کمپیوٹنگ سروسز کی کاپیاں ہر ایک کمپیوٹ سیل میں تعینات کر دی ہیں تاکہ ڈیٹا سینٹر کو زیادہ تر درخواستیں ایک سیل کے ذریعے پیش کی جا سکیں۔ ہم سیلوں میں ٹریفک کو متوازن کر رہے ہیں۔ مزید تلاش کرتے ہوئے، ہم نے اگلی نسل کی سروس کی دریافت کے عمل کی تعمیر شروع کر دی ہے جس کا فائدہ ایک سروس میش سے لیا جائے گا، جسے ہم 2024 میں مکمل کرنے کی امید کرتے ہیں۔ یہ فیل اوور سیلز پر منفی اثر نہیں ڈالے گا۔ اس کے علاوہ 2024 میں آنے والا ایک ہی سیل میں ایک سروس ورژن پر منحصر درخواستوں کو بھیجنے کا ایک طریقہ ہوگا، جو کراس سیل ٹریفک کو کم سے کم کرے گا اور اس طرح ناکامیوں کے کراس سیل پروپیگیشن کے خطرے کو کم کرے گا۔
عروج پر، ہماری بیک اینڈ سروس ٹریفک کا 70 فیصد سے زیادہ سیلز سے باہر پیش کیا جا رہا ہے اور ہم نے سیلز بنانے کے طریقے کے بارے میں بہت کچھ سیکھا ہے، لیکن ہمیں مزید تحقیق اور جانچ کی توقع ہے کیونکہ ہم اپنی خدمات کو 2024 تک منتقل کرنا جاری رکھیں گے اور دسترس سے باہر. جیسے جیسے ہم ترقی کریں گے، یہ دھماکے کی دیواریں تیزی سے مضبوط ہوتی جائیں گی۔
ہمیشہ جاری رکھنے والے انفراسٹرکچر کو منتقل کرنا
روبلوکس ایک عالمی پلیٹ فارم ہے جو پوری دنیا کے صارفین کو سپورٹ کرتا ہے، اس لیے ہم آف پیک یا "ڈاؤن ٹائم" کے دوران سروسز کو منتقل نہیں کر سکتے، جو ہماری تمام مشینوں کو سیلز میں منتقل کرنے کے عمل کو مزید پیچیدہ بناتا ہے اور ہماری سروسز کو ان سیلز میں چلانے کے لیے . ہمارے پاس لاکھوں ہمیشہ رہنے والے تجربات ہیں جن کی حمایت جاری رکھنے کی ضرورت ہے، یہاں تک کہ جب ہم ان مشینوں کو منتقل کرتے ہیں جن پر وہ چلتی ہیں اور ان کی مدد کرنے والی خدمات۔ جب ہم نے یہ عمل شروع کیا تو ہمارے پاس دسیوں ہزار مشینیں نہیں تھیں جو صرف غیر استعمال شدہ اور ان کام کے بوجھ کو منتقل کرنے کے لیے دستیاب تھیں۔
تاہم، ہمارے پاس اضافی مشینوں کی ایک چھوٹی سی تعداد تھی جو مستقبل کی ترقی کی توقع میں خریدی گئی تھیں۔ شروع کرنے کے لیے، ہم نے ان مشینوں کا استعمال کرتے ہوئے نئے سیل بنائے، پھر کام کے بوجھ کو ان میں منتقل کیا۔ ہم کارکردگی کے ساتھ ساتھ وشوسنییتا کو بھی اہمیت دیتے ہیں، اس لیے باہر جانے اور مزید مشینیں خریدنے کے بجائے ایک بار جب ہمارے پاس "فالتو" مشینیں ختم ہو جائیں تو ہم نے ان مشینوں کو صاف اور دوبارہ ترتیب دے کر مزید سیل بنائے جن سے ہم ہجرت کر گئے تھے۔ اس کے بعد ہم نے کام کے بوجھ کو دوبارہ پروویژن شدہ مشینوں پر منتقل کیا، اور یہ عمل دوبارہ شروع کر دیا۔ یہ عمل پیچیدہ ہے — چونکہ مشینوں کو تبدیل کیا جاتا ہے اور خلیات میں بننے کے لیے آزاد کیا جاتا ہے، وہ ایک مثالی، منظم انداز میں آزاد نہیں ہو رہی ہیں۔ وہ جسمانی طور پر ڈیٹا ہالوں میں بکھرے ہوئے ہیں، جس سے ہمیں ان کی فراہمی ایک چھوٹے سے انداز میں کرنی پڑتی ہے، جس کے لیے ہارڈ ویئر کے مقامات کو بڑے پیمانے پر جسمانی ناکامی والے ڈومینز کے ساتھ منسلک رکھنے کے لیے ہارڈ ویئر کی سطح کے ڈیفراگمنٹیشن کے عمل کی ضرورت ہوتی ہے۔
ہماری انفراسٹرکچر انجینئرنگ ٹیم کا ایک حصہ ہماری میراث، یا "پری سیل" ماحول سے موجودہ کام کے بوجھ کو خلیات میں منتقل کرنے پر مرکوز ہے۔ یہ کام اس وقت تک جاری رہے گا جب تک ہم ہزاروں مختلف انفراسٹرکچر سروسز اور ہزاروں بیک اینڈ سروسز کو نئے بنائے گئے سیلز میں منتقل نہیں کر دیتے۔ ہم توقع کرتے ہیں کہ کچھ پیچیدہ عوامل کی وجہ سے یہ اگلے سال اور ممکنہ طور پر 2025 تک لے جائے گا۔ سب سے پہلے، اس کام کے لیے مضبوط ٹولنگ کی ضرورت ہوتی ہے۔ مثال کے طور پر، ہمارے صارفین کو متاثر کیے بغیر، جب ہم ایک نیا سیل لگاتے ہیں تو ہمیں بڑی تعداد میں سروسز کو خود بخود دوبارہ متوازن کرنے کے لیے ٹولنگ کی ضرورت ہوتی ہے۔ ہم نے ایسی خدمات بھی دیکھی ہیں جو ہمارے بنیادی ڈھانچے کے بارے میں مفروضوں کے ساتھ بنائی گئی تھیں۔ ہمیں ان خدمات پر نظر ثانی کرنے کی ضرورت ہے تاکہ وہ ان چیزوں پر انحصار نہ کریں جو مستقبل میں ہمارے خلیات میں منتقل ہونے پر تبدیل ہو سکتی ہیں۔ ہم نے معلوم ڈیزائن کے نمونوں کو تلاش کرنے کے دونوں طریقے بھی نافذ کیے ہیں جو سیلولر فن تعمیر کے ساتھ اچھی طرح سے کام نہیں کریں گے، اور ساتھ ہی منتقل ہونے والی ہر سروس کے لیے ایک طریقہ کار جانچ کا عمل بھی۔ یہ عمل کسی بھی صارف کو درپیش مسائل کو حل کرنے میں ہماری مدد کرتے ہیں جو سروس سیلز کے ساتھ مطابقت نہیں رکھتی ہے۔
آج، تقریباً 30,000 مشینوں کا انتظام سیلز کے ذریعے کیا جا رہا ہے۔ یہ ہمارے کل بیڑے کا صرف ایک حصہ ہے، لیکن یہ اب تک ایک بہت ہی ہموار منتقلی رہا ہے جس کا کوئی منفی اثر نہیں ہوا۔ ہمارا حتمی مقصد ہمارے سسٹمز کے لیے ہر ماہ 99.99 فیصد یوزر اپ ٹائم حاصل کرنا ہے، یعنی ہم مصروفیت کے اوقات میں 0.01 فیصد سے زیادہ رکاوٹ نہیں ڈالیں گے۔ پوری صنعت میں، ڈاؤن ٹائم کو مکمل طور پر ختم نہیں کیا جا سکتا، لیکن ہمارا مقصد کسی بھی روبلوکس ڈاؤن ٹائم کو اس حد تک کم کرنا ہے کہ یہ تقریباً ناقابل توجہ ہو۔
جیسا کہ ہم پیمانہ کرتے ہیں مستقبل کا ثبوت
اگرچہ ہماری ابتدائی کوششیں کامیاب ثابت ہو رہی ہیں، خلیات پر ہمارا کام بہت دور ہے۔ جیسے جیسے Roblox کی پیمائش جاری ہے، ہم اس اور دیگر ٹیکنالوجیز کے ذریعے اپنے سسٹمز کی کارکردگی اور لچک کو بہتر بنانے کے لیے کام کرتے رہیں گے۔ جیسے جیسے ہم جائیں گے، پلیٹ فارم مسائل کے لیے تیزی سے لچکدار ہوتا جائے گا، اور جو بھی مسائل پیش آتے ہیں وہ آہستہ آہستہ ہمارے پلیٹ فارم پر موجود لوگوں کے لیے کم دکھائی دینے والے اور خلل ڈالنے والے بن جائیں گے۔
خلاصہ طور پر، آج تک، ہمارے پاس ہے:
- دوسرا ڈیٹا سینٹر بنایا اور کامیابی سے فعال/غیر فعال حیثیت حاصل کی۔
- ہمارے فعال اور غیر فعال ڈیٹا سینٹرز میں سیلز بنائے اور ہماری بیک اینڈ سروس ٹریفک کا 70 فیصد سے زیادہ کامیابی سے ان سیلز میں منتقل کر دیا۔
- تمام خلیات کو یکساں رکھنے کے لیے ان تقاضوں اور بہترین طریقوں کو ترتیب دیں جن کی ہمیں پیروی کرنی ہوگی کیونکہ ہم اپنے باقی انفراسٹرکچر کو منتقل کرتے رہتے ہیں۔
- خلیوں کے درمیان مضبوط "دھماکے کی دیواروں" کی تعمیر کے مسلسل عمل کو شروع کیا۔
جیسے جیسے یہ خلیے زیادہ قابل تبادلہ ہوتے جائیں گے، خلیات کے درمیان کم کراسسٹالک ہوگا۔ یہ نگرانی، خرابیوں کا سراغ لگانا، اور یہاں تک کہ کام کے بوجھ کو خود بخود منتقل کرنے کے ارد گرد آٹومیشن کو بڑھانے کے لحاظ سے ہمارے لیے کچھ بہت ہی دلچسپ مواقع کھولتا ہے۔
ستمبر میں ہم نے اپنے ڈیٹا سینٹرز میں فعال/فعال تجربات بھی شروع کر دیے۔ یہ ایک اور طریقہ کار ہے جس کی ہم بھروسے کو بہتر بنانے اور ناکامی کے اوقات کو کم کرنے کے لیے آزما رہے ہیں۔ ان تجربات نے بہت سے سسٹم ڈیزائن کے نمونوں کی شناخت میں مدد کی، زیادہ تر ڈیٹا تک رسائی کے ارد گرد، جس پر ہمیں دوبارہ کام کرنے کی ضرورت ہے کیونکہ ہم مکمل طور پر ایکٹیو ہونے کی طرف بڑھ رہے ہیں۔ مجموعی طور پر، تجربہ اتنا کامیاب رہا کہ اسے ہمارے صارفین کی محدود تعداد سے ٹریفک کے لیے چلایا جا سکے۔
ہم پلیٹ فارم میں زیادہ کارکردگی اور لچک لانے کے لیے اس کام کو آگے بڑھانے کے لیے پرجوش ہیں۔ سیلز اور ایکٹیو ایکٹو انفراسٹرکچر پر یہ کام، ہماری دیگر کوششوں کے ساتھ، ہمارے لیے یہ ممکن بنائے گا کہ ہم لاکھوں لوگوں کے لیے ایک قابل اعتماد، اعلیٰ کارکردگی کا مظاہرہ کرنے والی افادیت میں ترقی کریں اور ہم ایک ارب لوگوں کو حقیقی طور پر جوڑنے کے لیے کام کرتے ہوئے پیمانے کو جاری رکھیں۔ وقت
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- کی صلاحیت
- قابلیت
- ہمارے بارے میں
- تک رسائی حاصل
- حاصل
- حاصل کیا
- کے پار
- ایکٹ
- اداکاری
- فعال
- شامل کیا
- ایڈیشنل
- پتہ
- اپنایا
- پھر
- جارحانہ انداز میں
- منسلک
- تمام
- کی اجازت
- اکیلے
- ساتھ
- پہلے ہی
- بھی
- an
- اور
- ایک اور
- اندازہ
- متوقع
- کوئی بھی
- کسی
- تقریبا
- فن تعمیر
- کیا
- ارد گرد
- AS
- مفروضے
- At
- آٹومیٹڈ
- خود کار طریقے سے
- میشن
- دستیاب
- اوتار
- سے اجتناب
- پیچھے کے آخر میں
- بیک اپ
- سوئنگ
- توازن
- کی بنیاد پر
- BE
- کیونکہ
- بن
- ہو جاتا ہے
- بننے
- رہا
- اس سے پہلے
- شروع
- کیا جا رہا ہے
- فائدہ
- BEST
- بہترین طریقوں
- کے درمیان
- سے پرے
- بگ
- بڑا
- ارب
- بلاگ
- دونوں
- لانے
- لایا
- کیڑوں
- تعمیر
- عمارت
- تعمیر
- کاروبار
- لیکن
- خرید
- by
- فون
- کر سکتے ہیں
- نہیں کر سکتے ہیں
- اہلیت
- مقدمات
- کیونکہ
- وجہ
- باعث
- سیل
- خلیات
- سیلولر
- سینٹر
- مراکز
- کچھ
- چیلنج
- تبدیل
- تبدیلیاں
- کلوز
- بادل
- کلاؤڈ بنیادی ڈھانچے
- کوڈ
- کس طرح
- آنے والے
- کامن
- ابلاغ
- بات چیت
- مواصلات
- کمپنیاں
- مقابلے میں
- مکمل
- مکمل طور پر
- پیچیدہ
- پیچیدگی
- جزو
- اجزاء
- کمپیوٹنگ
- کمپیوٹنگ
- کانفرنس
- ترتیب
- رابطہ قائم کریں
- کنکشن
- پر مشتمل ہے
- پر مشتمل ہے
- جاری
- جاری ہے
- مسلسل
- کنٹرول
- کاپیاں
- اخراجات
- سکتا ہے
- تخلیق
- تخلیق
- تخلیق کاروں
- اس وقت
- اپنی مرضی کے مطابق بلٹ
- روزانہ
- اعداد و شمار
- ڈیٹا تک رسائی
- ڈیٹا سینٹر
- ڈیٹا مراکز
- تاریخ
- دن
- تعریف
- ڈگری
- تاخیر
- انحصار
- انحصار
- تعیناتی
- تعینات
- تعیناتی
- ڈیزائن
- ڈیزائن پیٹرن
- DID
- مختلف
- مشکل
- ہدایت
- دریافت
- خلل ڈالنا
- خلل ڈالنے والا
- تقسیم
- do
- کرتا
- کر
- ڈومینز
- کیا
- نہیں
- دروازے
- نیچے
- ٹائم ٹائم
- ڈرائیونگ
- دو
- کے دوران
- ہر ایک
- ابتدائی
- آسان
- آسان
- کارکردگی
- ہنر
- مؤثر طریقے سے
- کوششوں
- ختم ہوگیا
- کے قابل بناتا ہے
- آخر
- مصروفیت
- انجنیئرنگ
- انجینئرز
- کافی
- کو یقینی بنانے کے
- پوری
- مکمل
- ماحولیات
- خرابی
- نقائص
- بنیادی طور پر
- وغیرہ
- بھی
- آخر میں
- ہر کوئی
- سب کچھ
- مثال کے طور پر
- بہت پرجوش
- موجودہ
- توقع ہے
- تجربہ کار
- تجربات
- تجربہ
- تجربات
- انتہائی
- انتہائی
- عوامل
- FAIL
- ناکامی
- ناکام رہتا ہے
- ناکامی
- ناکامیوں
- کافی
- دور
- فیشن
- تیز تر
- مل
- آگ
- پہلا
- فلیٹ
- توجہ مرکوز
- توجہ مرکوز
- پر عمل کریں
- کے لئے
- آگے
- کسر
- بکھری
- مفت
- بار بار اس
- سے
- مکمل
- مکمل طور پر
- فنکشنل
- مزید
- مستقبل
- مستقبل کی ترقی
- عام طور پر
- جغرافیائی
- حاصل
- حاصل کرنے
- دی
- گلوبل
- عالمی سطح پر
- Go
- مقصد
- جاتا ہے
- جا
- زیادہ سے زیادہ
- گروپ
- بڑھائیں
- اضافہ ہوا
- ترقی
- تھا
- نصف
- ہینڈل
- ہینڈلنگ
- ہو
- ہارڈ
- ہارڈ ویئر
- ہے
- سر
- صحت
- صحت مند
- مدد
- مدد
- ہائی
- اعلی
- امید ہے کہ
- HOURS
- کس طرح
- کیسے
- تاہم
- HTTPS
- انسان
- ہائبرڈ
- مثالی
- شناخت
- if
- عمیق
- اثر
- اثر انداز کرنا
- پر عملدرآمد
- عملدرآمد
- کو بہتر بنانے کے
- in
- شامل
- سمیت
- مطابقت
- اضافہ
- اضافہ
- دن بدن
- انفرادی
- صنعت
- معلومات
- انفراسٹرکچر
- کے اندر
- مثال کے طور پر
- واقعات
- فوری طور پر
- دلچسپ
- اندرونی
- میں
- مسئلہ
- مسائل
- IT
- جون
- صرف
- رکھیں
- رکھتے ہوئے
- جان
- جانا جاتا ہے
- بڑے
- بڑے پیمانے پر
- بڑے پیمانے پر
- تاخیر
- سیکھا ہے
- چھوڑ دو
- چھوڑ کر
- کی وراست
- کم
- دو
- سطح
- لیورڈڈ
- کی طرح
- لمیٹڈ
- لوڈ
- واقع ہے
- مقامات
- طویل مدتی
- اب
- تلاش
- بہت
- لو
- مشین
- مشینیں
- برقرار رکھنے کے
- بنا
- بناتا ہے
- بنانا
- انتظام
- میں کامیاب
- دستی طور پر
- بہت سے
- زیادہ سے زیادہ چوڑائی
- مطلب
- مطلب
- میکانزم
- نظام
- سے ملو
- میش
- طریقہ
- طریقہ کار
- شاید
- منتقلی
- منتقل
- ہجرت کرنا
- منتقلی
- دس لاکھ
- لاکھوں
- کم سے کم
- معمولی
- غلطیوں
- نگرانی
- مہینہ
- زیادہ
- زیادہ موثر
- سب سے زیادہ
- منتقل
- بہت
- ایک سے زیادہ
- ضروری
- فطرت، قدرت
- تقریبا
- ضرورت ہے
- ضرورت
- منفی
- منفی طور پر
- نیٹ ورک
- نئی
- نیا
- اگلے
- اگلی نسل
- نہیں
- اب
- تعداد
- تعداد
- واقع
- اکتوبر
- of
- بند
- on
- ایک بار
- ایک
- جاری
- صرف
- مواقع
- مواقع
- or
- OS
- دیگر
- دیگر
- ہمارے
- باہر
- گزرنا
- بندش
- پر
- مجموعی طور پر
- مالکان
- حصہ
- غیر فعال
- گزشتہ
- پیٹرن
- ادائیگی
- چوٹی
- لوگ
- فی
- فیصد
- کارکردگی کا مظاہرہ
- مستقل طور پر
- انسان
- فلسفہ
- جسمانی
- جسمانی طورپر
- لینے
- مقام
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھلاڑی
- پالیسیاں
- پورٹیبل
- حصہ
- امکان
- ممکن
- ممکنہ طور پر
- ممکنہ طور پر
- طریقوں
- کی روک تھام
- روکتا ہے
- بنیادی طور پر
- ترجیح
- نجی
- عمل
- عمل
- پیش رفت
- آہستہ آہستہ
- تبلیغ
- تحفظ
- ثابت
- پراجیکٹ
- خریدا
- پش
- سوالات
- سوال
- جلدی سے
- بلکہ
- تیار
- اصلی
- اصل وقت
- توازن
- وصولی
- ری ڈائریکٹ
- کو کم
- خطے
- وشوسنییتا
- قابل اعتماد
- انحصار کرو
- مرمت
- کی جگہ
- نقل
- ذخیرہ
- درخواستوں
- ضروریات
- کی ضرورت ہے
- تحقیق
- لچک
- لچکدار
- حل
- باقی
- نتیجہ
- نتیجے
- نظر ثانی
- رسک
- Roblox
- مضبوط
- رن
- چل رہا ہے
- چلتا ہے
- محفوظ طریقے سے
- اسی
- محفوظ
- پیمانے
- منظر نامے
- فیرنا
- تلاش کریں
- دوسری
- دیکھا
- الگ کرنا
- ستمبر
- خدمت کی
- سروس
- سروسز
- خدمت
- مقرر
- کئی
- سیکنڈ اور
- مشترکہ
- اشتراک
- منتقل
- منتقلی
- مختصر
- ہونا چاہئے
- نمایاں طور پر
- بعد
- ایک
- بیٹھنا
- چھوٹے
- ہموار
- So
- اب تک
- سافٹ ویئر کی
- کچھ
- کچھ
- بہتر
- ماخذ
- ماخذ کوڈ
- خلا
- spikes
- پھیلانے
- پھیلانا
- شروع کریں
- شروع
- شروع ہوتا ہے
- درجہ
- ابھی تک
- حکمت عملی
- مضبوط
- مضبوط
- مطالعہ
- کامیاب ہوں
- کامیاب
- کامیابی کے ساتھ
- خلاصہ
- حمایت
- تائید
- امدادی
- کی حمایت کرتا ہے
- کے نظام
- سسٹمز
- لے لو
- لیا
- ٹیم
- ٹیکنیکل
- ٹیکنالوجی
- دہلی
- اصطلاح
- شرائط
- ٹیسٹنگ
- متن
- سے
- کہ
- ۔
- مستقبل
- دنیا
- ان
- ان
- تو
- وہاں.
- اس طرح
- یہ
- وہ
- چیزیں
- لگتا ہے کہ
- اس
- ان
- ہزاروں
- کے ذریعے
- بھر میں
- وقت
- اوقات
- کرنے کے لئے
- آج
- مل کر
- رواداری
- بھی
- کے آلے
- اوزار
- کل
- کی طرف
- ٹریفک
- منتقلی
- ٹرگر
- کی کوشش کر رہے
- دو
- اقسام
- حتمی
- آخر میں
- غیر مقفل ہے
- جب تک
- غیر استعمال شدہ
- صلی اللہ علیہ وسلم
- اپ ٹائم
- us
- استعمال کیا جاتا ہے
- رکن کا
- صارفین
- کا استعمال کرتے ہوئے
- کی افادیت
- قیمت
- ورژن
- بہت
- نظر
- نقطہ نظر
- چاہتے ہیں
- تھا
- راستہ..
- we
- موسم
- اچھا ہے
- تھے
- کیا
- جو کچھ بھی
- جب
- جس
- جبکہ
- ڈبلیو
- وسیع
- گے
- مسح
- ساتھ
- کے اندر
- کام
- کام کیا
- کام کر
- دنیا
- فکر
- گا
- سال
- سال
- زیفیرنیٹ