مصنف کی طرف سے تصویر
جب آپ مشین لرننگ کے ساتھ شروعات کر رہے ہوتے ہیں، تو لاجسٹک ریگریشن پہلے الگورتھم میں سے ایک ہے جسے آپ اپنے ٹول باکس میں شامل کریں گے۔ یہ ایک سادہ اور مضبوط الگورتھم ہے، جو عام طور پر بائنری درجہ بندی کے کاموں کے لیے استعمال ہوتا ہے۔
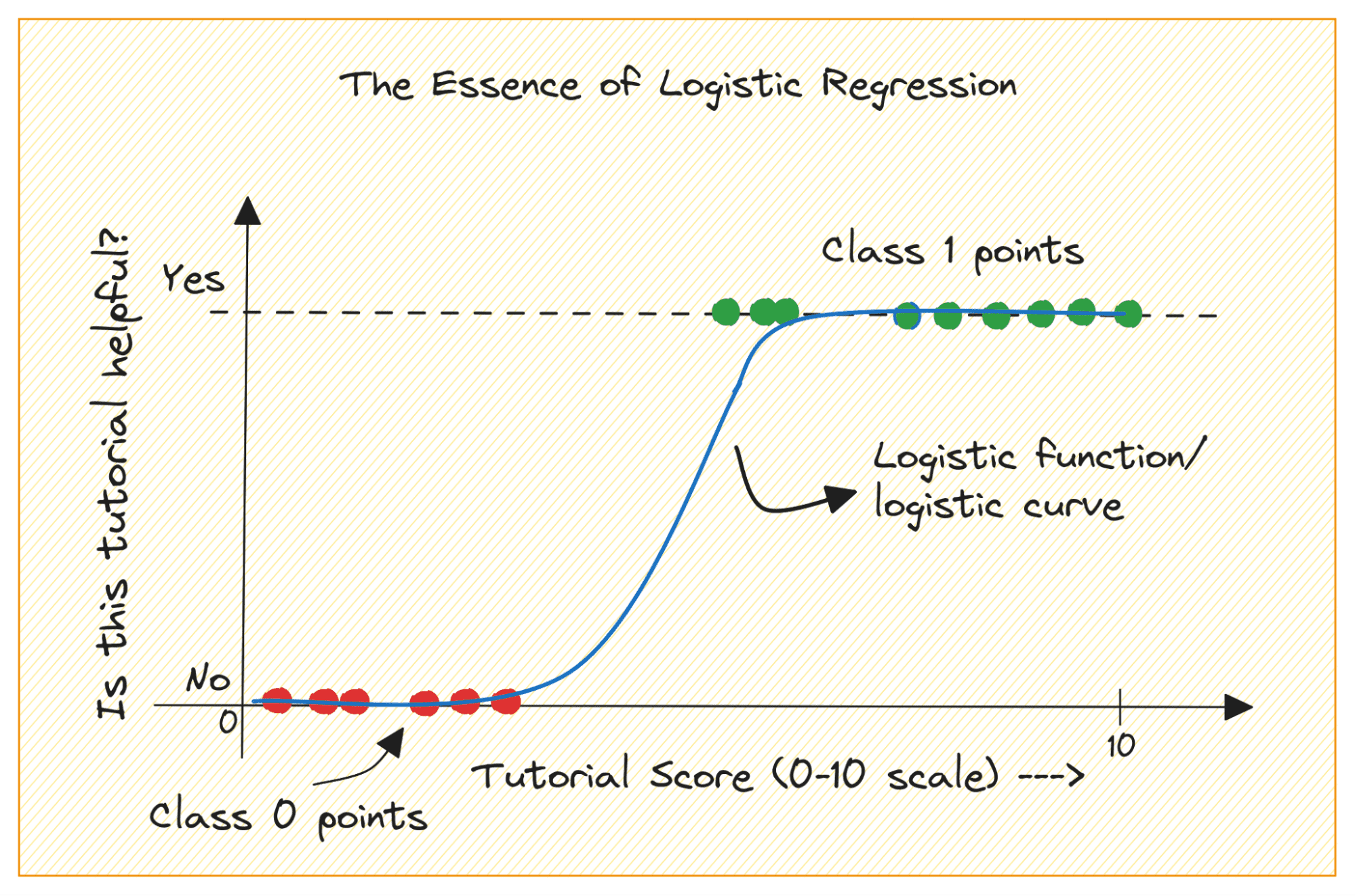
کلاس 0 اور 1 کے ساتھ بائنری درجہ بندی کے مسئلے پر غور کریں۔ لاجسٹک ریگریشن ان پٹ ڈیٹا کے لیے ایک لاجسٹک یا سگمائیڈ فنکشن میں فٹ بیٹھتا ہے اور کلاس 1 سے تعلق رکھنے والے استفسار کے ڈیٹا پوائنٹ کے امکان کی پیش گوئی کرتا ہے۔ دلچسپ، ہاں؟
اس ٹیوٹوریل میں، ہم گراؤنڈ اپ کورنگ سے لاجسٹک ریگریشن کے بارے میں سیکھیں گے:
- لاجسٹک (یا سگمائڈ) فنکشن
- ہم لکیری سے لاجسٹک ریگریشن کی طرف کیسے جاتے ہیں۔
- لاجسٹک ریگریشن کیسے کام کرتا ہے۔
آخر میں، ہم ایک سادہ لوجسٹک ریگریشن ماڈل بنائیں گے۔ ionosphere سے RADAR کی واپسی کی درجہ بندی کریں۔.
اس سے پہلے کہ ہم لاجسٹک ریگریشن کے بارے میں مزید جانیں، آئیے جائزہ لیں کہ لاجسٹک فنکشن کیسے کام کرتا ہے۔ لاجسٹک (یا سگمائیڈ فنکشن) بذریعہ دیا جاتا ہے:

جب آپ سگمائیڈ فنکشن کو پلاٹ کرتے ہیں تو یہ اس طرح نظر آئے گا:
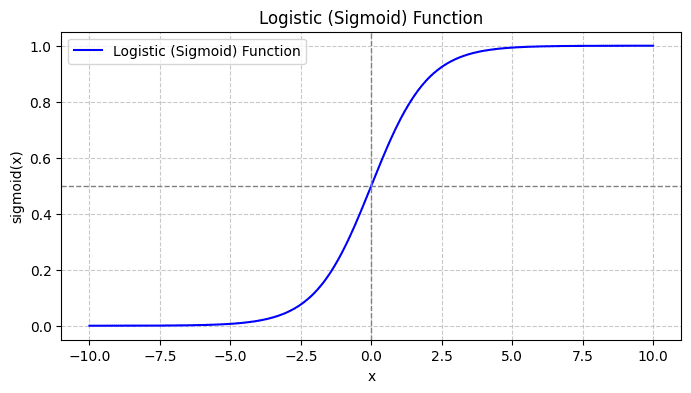
پلاٹ سے، ہم دیکھتے ہیں کہ:
- جب x = 0، σ(x) 0.5 کی قدر لیتا ہے۔
- جب x +∞ کے قریب آتا ہے، σ(x) 1 تک پہنچتا ہے۔
- جب x -∞ کے قریب پہنچتا ہے، σ(x) 0 تک پہنچتا ہے۔
لہٰذا تمام حقیقی ان پٹ کے لیے، سگمائیڈ فنکشن انہیں رینج [0، 1] میں قدروں کو لینے کے لیے اسکویش کرتا ہے۔
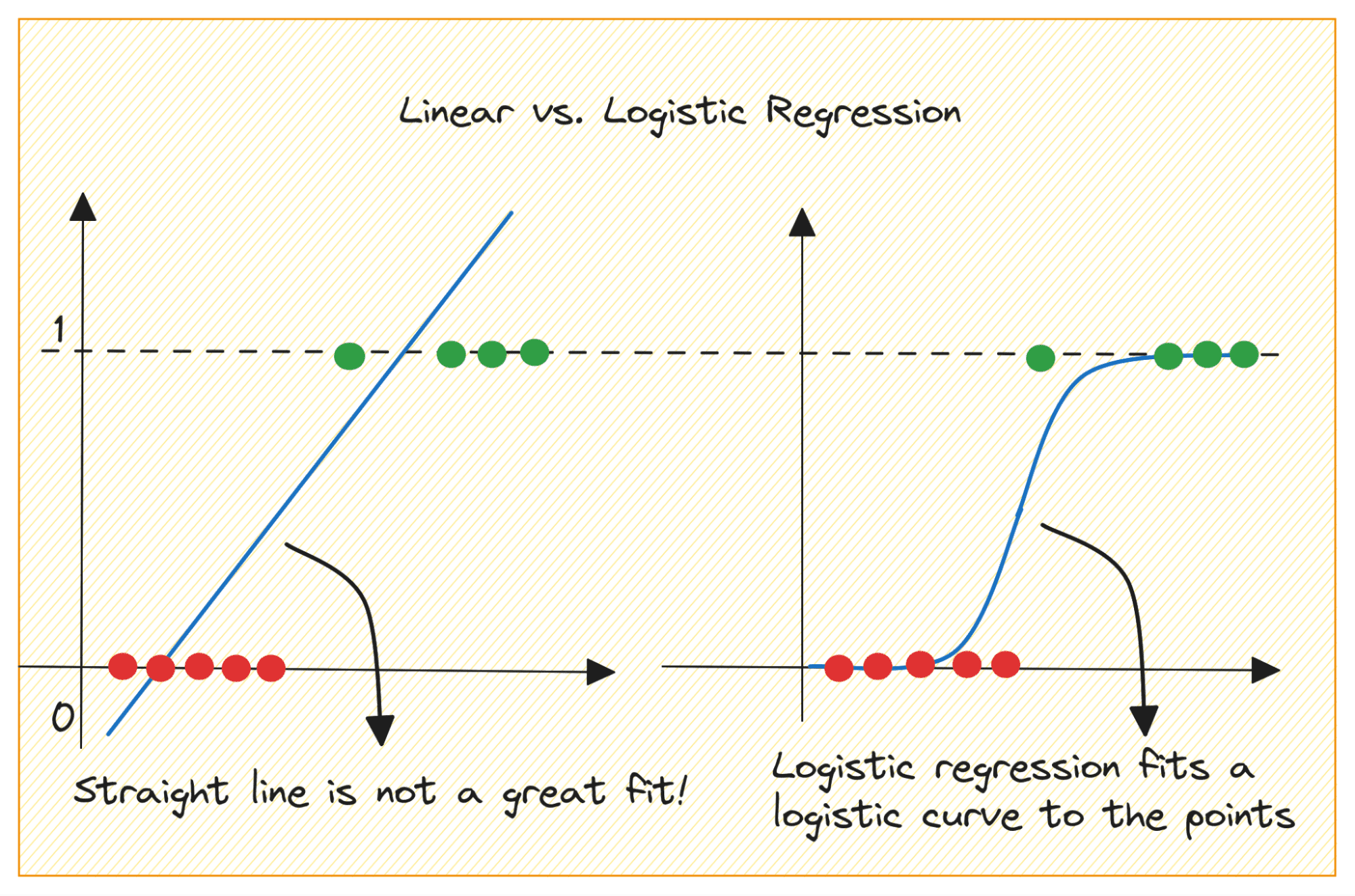
آئیے پہلے بحث کریں کہ ہم بائنری درجہ بندی کے مسئلے کے لیے لکیری رجعت کیوں استعمال نہیں کر سکتے۔
بائنری درجہ بندی کے مسئلے میں، آؤٹ پٹ واضح لیبل (0 یا 1) ہے۔ چونکہ لکیری رجعت مسلسل قابل قدر آؤٹ پٹ کی پیشین گوئی کرتی ہے جو 0 سے کم یا 1 سے زیادہ ہو سکتی ہے، اس لیے اس مسئلے کا کوئی مطلب نہیں ہے۔
نیز، جب آؤٹ پٹ لیبل دو زمروں میں سے کسی ایک سے تعلق رکھتے ہوں تو سیدھی لائن بہترین فٹ نہیں ہوسکتی ہے۔
مصنف کی طرف سے تصویر
تو ہم لکیری سے لاجسٹک ریگریشن کی طرف کیسے جائیں گے؟ لکیری رجعت میں پیش گوئی کی گئی پیداوار بذریعہ دی جاتی ہے:
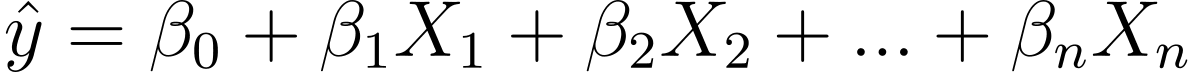
جہاں βs گتانک ہیں اور X_is پیشین گوئی کرنے والے (یا خصوصیات) ہیں۔
عمومیت کے نقصان کے بغیر، آئیے فرض کریں X_0 = 1:

لہذا ہم ایک زیادہ جامع اظہار کر سکتے ہیں:
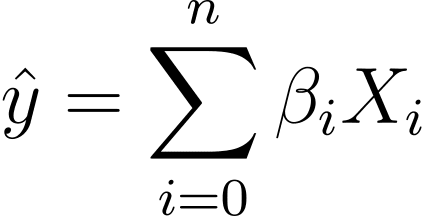
لاجسٹک ریگریشن میں، ہمیں [0,1] وقفہ میں پیش گوئی شدہ امکان p_i کی ضرورت ہوتی ہے۔ ہم جانتے ہیں کہ لاجسٹک فنکشن آدانوں کو نچوڑتا ہے تاکہ وہ [0,1] وقفہ میں قدروں کو حاصل کریں۔
لہذا اس اظہار کو لاجسٹک فنکشن میں شامل کرتے ہوئے، ہمارے پاس پیشین گوئی کا امکان ہے جیسا کہ:
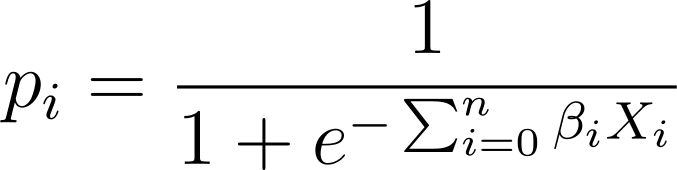
تو ہم دیے گئے ڈیٹا سیٹ کے لیے بہترین فٹ لاجسٹک وکر کیسے تلاش کرتے ہیں؟ اس کا جواب دینے کے لیے، آئیے زیادہ سے زیادہ امکانی تخمینہ کو سمجھتے ہیں۔
زیادہ سے زیادہ امکان کا تخمینہ (MLE) امکان کے فنکشن کو زیادہ سے زیادہ کرکے لاجسٹک ریگریشن ماڈل کے پیرامیٹرز کا اندازہ لگانے کے لیے استعمال کیا جاتا ہے۔ آئیے لاجسٹک ریگریشن میں MLE کے عمل کو توڑتے ہیں اور گراڈینٹ ڈیسنٹ کا استعمال کرتے ہوئے اصلاح کے لیے لاگت کا فنکشن کس طرح تیار کیا جاتا ہے۔
زیادہ سے زیادہ امکانی تخمینہ کو توڑنا
جیسا کہ بحث کی گئی ہے، ہم اس امکان کا نمونہ بناتے ہیں کہ بائنری نتیجہ ایک یا زیادہ پیشین گوئی کرنے والے متغیرات (یا خصوصیات) کے فنکشن کے طور پر ہوتا ہے:
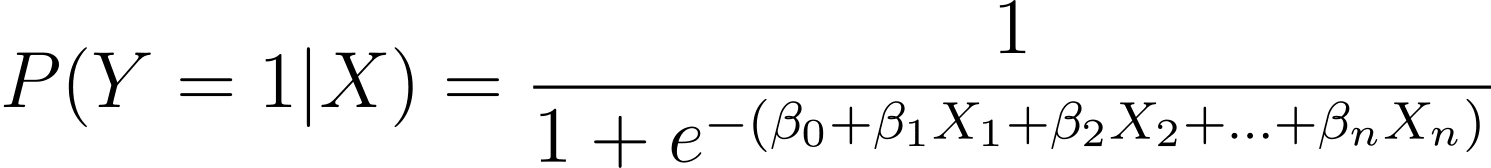
یہاں، βs ماڈل پیرامیٹرز یا گتانک ہیں۔ X_1, X_2,…, X_n پیشین گوئی کرنے والے متغیرات ہیں۔
MLE کا مقصد β کی اقدار کو تلاش کرنا ہے جو مشاہدہ شدہ ڈیٹا کے امکان کو زیادہ سے زیادہ بناتے ہیں۔ امکانی فعل، جسے L(β) کے طور پر ظاہر کیا جاتا ہے، لاجسٹک ریگریشن ماڈل کے تحت دی گئی پیشن گوئی کی اقدار کے لیے دیے گئے نتائج کے مشاہدے کے امکان کی نمائندگی کرتا ہے۔
لاگ-امکان تقریب کی تشکیل
اصلاح کے عمل کو آسان بنانے کے لیے، لاگ ان امکان کے فنکشن کے ساتھ کام کرنا عام ہے۔ کیونکہ یہ احتمالات کی مصنوعات کو لاگ امکانات کے مجموعوں میں تبدیل کرتا ہے۔
لاجسٹک ریگریشن کے لیے لاگ امکان کا فنکشن بذریعہ دیا جاتا ہے:
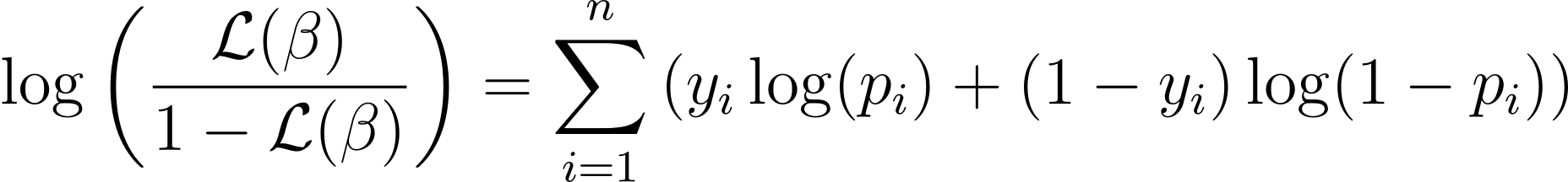
اب جب کہ ہم لاگ ان امکان کے جوہر کو جان چکے ہیں، آئیے لاجسٹک ریگریشن کے لیے لاگت کے فنکشن اور اس کے بعد بہترین ماڈل کے پیرامیٹرز کو تلاش کرنے کے لیے تدریجی نزول وضع کرنے کے لیے آگے بڑھیں۔
لاجسٹک ریگریشن کے لیے لاگت کا فنکشن
لاجسٹک ریگریشن ماڈل کو بہتر بنانے کے لیے، ہمیں لاگ ان کے امکانات کو زیادہ سے زیادہ کرنے کی ضرورت ہے۔ لہذا ہم تربیت کے دوران کم سے کم لاگت کے فنکشن کے طور پر لاگ ان کے منفی امکان کو استعمال کر سکتے ہیں۔ منفی لاگ ان امکان، جسے اکثر لاجسٹک نقصان کہا جاتا ہے، اس کی تعریف اس طرح کی گئی ہے:
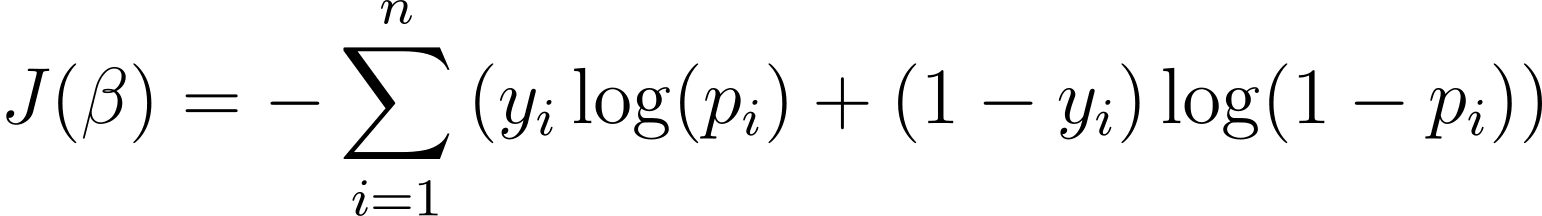
سیکھنے کے الگورتھم کا مقصد، لہذا، کی اقدار کو تلاش کرنا ہے؟ جو اس لاگت کی تقریب کو کم سے کم کرتا ہے۔ گریڈینٹ ڈیسنٹ اس لاگت کے فنکشن کی کم از کم تلاش کرنے کے لیے عام طور پر استعمال ہونے والا اصلاحی الگورتھم ہے۔
لاجسٹک ریگریشن میں گریڈینٹ ڈیسنٹ
تدریجی نزول ایک تکراری اصلاحی الگورتھم ہے جو β کے حوالے سے لاگت کے فنکشن کے گریڈینٹ کی مخالف سمت میں ماڈل پیرامیٹرز β کو اپ ڈیٹ کرتا ہے۔ تدریجی نزول کا استعمال کرتے ہوئے لاجسٹک ریگریشن کے لیے مرحلہ t+1 پر اپ ڈیٹ کا اصول درج ذیل ہے:
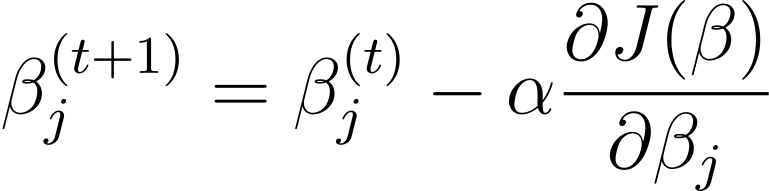
جہاں α سیکھنے کی شرح ہے۔
چین کے اصول کا استعمال کرتے ہوئے جزوی مشتقات کی گنتی کی جا سکتی ہے۔ گراڈینٹ ڈیسنٹ تکراری طور پر پیرامیٹرز کو اپ ڈیٹ کرتا ہے — کنورجنسی تک — جس کا مقصد لاجسٹک نقصان کو کم کرنا ہے۔ جیسا کہ یہ تبدیل ہوتا ہے، یہ β کی بہترین اقدار تلاش کرتا ہے جو مشاہدہ شدہ ڈیٹا کے امکان کو زیادہ سے زیادہ کرتا ہے۔
اب جب کہ آپ جانتے ہیں کہ لاجسٹک ریگریشن کس طرح کام کرتا ہے، آئیے scikit-leabrary کا استعمال کرتے ہوئے ایک پیش گوئی کرنے والا ماڈل بنائیں۔
ہم استعمال کریں گے UCI مشین لرننگ ریپوزٹری سے ionosphere ڈیٹاسیٹ اس ٹیوٹوریل کے لیے۔ ڈیٹاسیٹ 34 عددی خصوصیات پر مشتمل ہے۔ آؤٹ پٹ بائنری ہے، 'اچھا' یا 'خراب' ('g' یا 'b' سے ظاہر ہوتا ہے)۔ آؤٹ پٹ لیبل 'اچھا' سے مراد ریڈار کی واپسی ہے جس نے آئن اسپیئر میں کچھ ساخت کا پتہ لگایا ہے۔
مرحلہ 1 - ڈیٹاسیٹ لوڈ کرنا
سب سے پہلے، ڈیٹاسیٹ ڈاؤن لوڈ کریں اور اسے پانڈا ڈیٹا فریم میں پڑھیں:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)مرحلہ 2 - ڈیٹاسیٹ کی تلاش
آئیے ڈیٹا فریم کی پہلی چند قطاروں پر ایک نظر ڈالتے ہیں:
# Display the first few rows of the DataFrame
df.head()
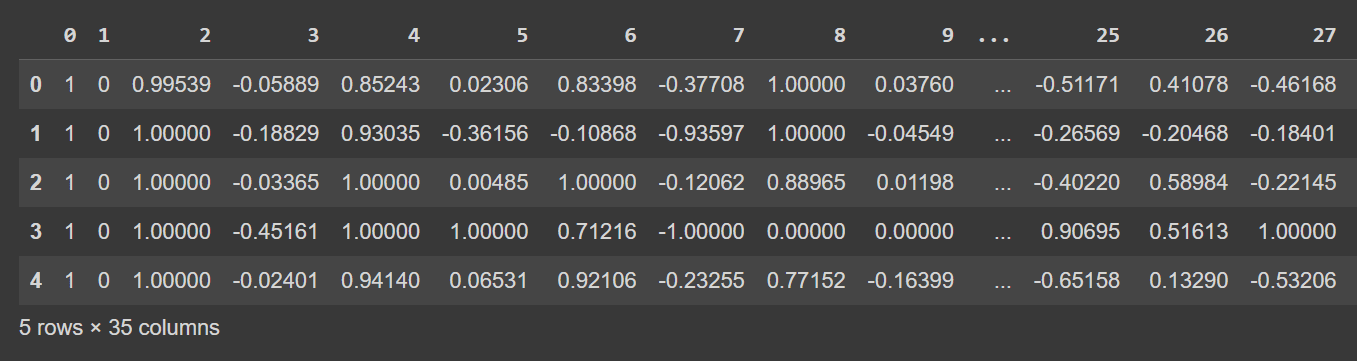
df.head() کا کٹا ہوا آؤٹ پٹ
آئیے ڈیٹاسیٹ کے بارے میں کچھ معلومات حاصل کرتے ہیں: غیر null اقدار کی تعداد اور ہر کالم کے ڈیٹا کی اقسام:
# Get information about the dataset
print(df.info())
 df.info() کا کٹا ہوا آؤٹ پٹ
df.info() کا کٹا ہوا آؤٹ پٹ
چونکہ ہمارے پاس تمام عددی خصوصیات ہیں، اس لیے ہم استعمال کر کے کچھ وضاحتی اعدادوشمار بھی حاصل کر سکتے ہیں۔ describe() ڈیٹا فریم پر طریقہ:
# Get descriptive statistics of the dataset
print(df.describe())
df.describe() کا کٹا ہوا آؤٹ پٹ
کالم کے نام فی الحال 0 سے 34 تک ہیں—بشمول لیبل۔ چونکہ ڈیٹاسیٹ کالموں کے لیے وضاحتی نام فراہم نہیں کرتا ہے، اس لیے یہ صرف ان کا حوالہ دیتا ہے attribute_1 to attribute_34 اگر آپ چاہتے ہیں کہ آپ ڈیٹا فریم کے کالموں کا نام بدل سکتے ہیں جیسا کہ دکھایا گیا ہے:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
نوٹ: یہ مرحلہ مکمل طور پر اختیاری ہے۔ اگر آپ چاہیں تو آپ پہلے سے طے شدہ کالم کے ناموں کے ساتھ آگے بڑھ سکتے ہیں۔
# Display the first few rows of the DataFrame
df.head()
df.head() کا کٹا ہوا آؤٹ پٹ [کالموں کا نام تبدیل کرنے کے بعد]
مرحلہ 3 - کلاس لیبلز کا نام تبدیل کرنا اور کلاس کی تقسیم کو تصور کرنا
چونکہ آؤٹ پٹ کلاس لیبلز 'g' اور 'b' ہیں، ہمیں انہیں بالترتیب 1 اور 0 پر نقشہ کرنے کی ضرورت ہے۔ آپ اسے استعمال کرکے کر سکتے ہیں۔ map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
آئیے کلاس لیبلز کی تقسیم کو بھی دیکھیں:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
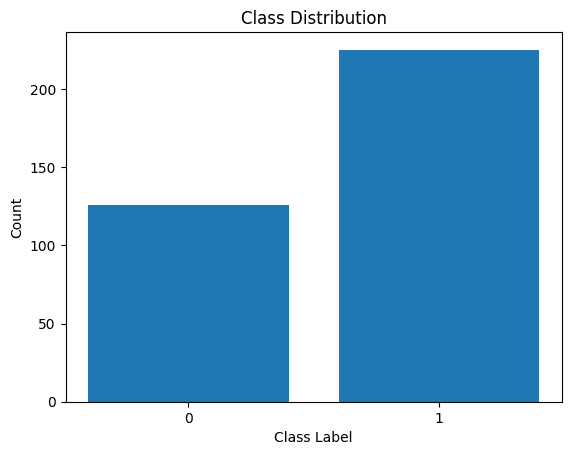
کلاس لیبلز کی تقسیم
ہم دیکھتے ہیں کہ تقسیم میں عدم توازن ہے۔ کلاس 1 کے مقابلے کلاس 0 سے زیادہ ریکارڈز ہیں۔ ہم لاجسٹک ریگریشن ماڈل بناتے وقت اس کلاس کے عدم توازن کو سنبھالیں گے۔
مرحلہ 5 - ڈیٹا سیٹ کو پہلے سے پروسیس کرنا
آئیے اس طرح کی خصوصیات اور آؤٹ پٹ لیبل جمع کرتے ہیں:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
ڈیٹاسیٹ کو ٹرین اور ٹیسٹ سیٹ میں تقسیم کرنے کے بعد، ہمیں ڈیٹاسیٹ کو پہلے سے پروسیس کرنے کی ضرورت ہے۔
جب بہت سے عددی خصوصیات ہیں—ہر ایک ممکنہ طور پر مختلف پیمانے پر—ہمیں عددی خصوصیات کو پہلے سے پروسیس کرنے کی ضرورت ہے۔ ایک عام طریقہ یہ ہے کہ انہیں اس طرح تبدیل کیا جائے کہ وہ صفر اوسط اور اکائی کے تغیر کے ساتھ تقسیم کی پیروی کریں۔
۔ StandardScaler scikit-learn کے پری پروسیسنگ ماڈیول سے ہمیں اس کو حاصل کرنے میں مدد ملتی ہے۔
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])مرحلہ 6 - ایک لاجسٹک ریگریشن ماڈل بنانا
اب ہم ایک لاجسٹک ریگریشن درجہ بندی کو تیز کر سکتے ہیں۔ دی LogisticRegression کلاس اسکیٹ لرن کے linear_model ماڈیول کا حصہ ہے۔
نوٹ کریں کہ ہم نے سیٹ کیا ہے۔ class_weight پیرامیٹر سے 'متوازن'۔ اس سے ہمیں طبقاتی عدم توازن کا حساب کتاب کرنے میں مدد ملے گی۔ ہر کلاس کو وزن تفویض کر کے—کلاسوں میں ریکارڈ کی تعداد کے الٹا متناسب۔
کلاس کو شروع کرنے کے بعد، ہم ماڈل کو ٹریننگ ڈیٹاسیٹ میں فٹ کر سکتے ہیں:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)مرحلہ 7 - لاجسٹک ریگریشن ماڈل کا جائزہ لینا
آپ کو کال کر سکتے ہیں predict() ماڈل کی پیش گوئیاں حاصل کرنے کا طریقہ۔
درستگی کے اسکور کے علاوہ، ہم درستگی، یاد کرنے، اور F1 سکور جیسے میٹرکس کے ساتھ درجہ بندی کی رپورٹ بھی حاصل کر سکتے ہیں۔
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
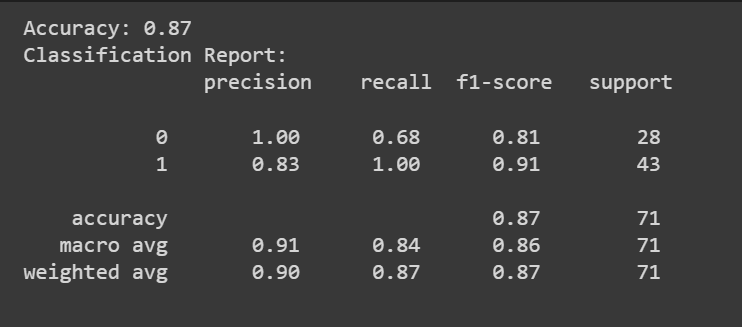
مبارک ہو، آپ نے اپنا پہلا لاجسٹک ریگریشن ماڈل کوڈ کیا ہے!
اس ٹیوٹوریل میں، ہم نے لاجسٹک ریگریشن کے بارے میں تفصیل سے سیکھا: تھیوری اور ریاضی سے لے کر لاجسٹک ریگریشن کلاسیفائر کوڈنگ تک۔
اگلے مرحلے کے طور پر، اپنی پسند کے موزوں ڈیٹاسیٹ کے لیے لاجسٹک ریگریشن ماڈل بنانے کی کوشش کریں۔
Ionosphere ڈیٹاسیٹ a کے تحت لائسنس یافتہ ہے۔ Creative Commons انتساب 4.0 انٹرنیشنل (CC BY 4.0) لائسنس:
سگیلیٹو، وی، ونگ، ایس، ہٹن، ایل، اور بیکر، کے. (1989)۔ ionosphere UCI مشین لرننگ ریپوزٹری۔ https://doi.org/10.24432/C5W01B۔
بالا پریا سی ہندوستان سے ایک ڈویلپر اور تکنیکی مصنف ہے۔ وہ ریاضی، پروگرامنگ، ڈیٹا سائنس، اور مواد کی تخلیق کے چوراہے پر کام کرنا پسند کرتی ہے۔ اس کی دلچسپی اور مہارت کے شعبوں میں DevOps، ڈیٹا سائنس، اور قدرتی زبان کی پروسیسنگ شامل ہیں۔ وہ پڑھنے، لکھنے، کوڈنگ اور کافی سے لطف اندوز ہوتی ہے! فی الحال، وہ سیکھنے اور اپنے علم کو ڈویلپر کمیونٹی کے ساتھ بانٹنے کے لیے ٹیوٹوریلز، کیسے گائیڈز، رائے کے ٹکڑوں اور مزید بہت کچھ لکھ کر کام کر رہی ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- : ہے
- : نہیں
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- ہمارے بارے میں
- اکاؤنٹ
- درستگی
- حاصل
- شامل کریں
- اس کے علاوہ
- کے بعد
- مقصد ہے
- یلگورتم
- یلگوردمز
- تمام
- بھی
- an
- اور
- جواب
- نقطہ نظر
- کیا
- علاقوں
- AS
- فرض کرو
- At
- تصنیف
- b
- بیکر
- متوازن
- بار
- BE
- کیونکہ
- تعلق رکھتے ہیں
- BEST
- توڑ
- تعمیر
- عمارت
- by
- فون
- کر سکتے ہیں
- نہیں کر سکتے ہیں
- اقسام
- چین
- انتخاب
- طبقے
- کلاس
- درجہ بندی
- کوڈڈ
- کوڈنگ
- جمع
- کالم
- کالم
- کامن
- عام طور پر
- عمومی
- کمیونٹی
- پر مشتمل ہے
- جامع
- مواد
- مواد کی تخلیق
- تبدیل
- قیمت
- ڈھکنے
- تخلیق
- مخلوق
- اس وقت
- وکر
- اعداد و شمار
- ڈیٹا پوائنٹس
- ڈیٹا سائنس
- ڈیٹا سیٹ
- پہلے سے طے شدہ
- کی وضاحت
- مشتق
- تفصیل
- پتہ چلا
- ڈیولپر
- DevOps
- مختلف
- سمت
- بات چیت
- بات چیت
- دکھائیں
- تقسیم
- do
- کرتا
- نیچے
- ڈاؤن لوڈ، اتارنا
- کے دوران
- ہر ایک
- جوہر
- تخمینہ
- کا جائزہ لینے
- مہارت
- ایکسپلور
- اظہار
- خصوصیات
- چند
- مل
- تلاش
- پتہ ہے
- پہلا
- فٹ
- پر عمل کریں
- مندرجہ ذیل ہے
- کے لئے
- فریم
- سے
- تقریب
- حاصل
- حاصل کرنے
- دی
- Go
- مقصد
- گوگل
- زیادہ سے زیادہ
- گراؤنڈ
- ہدایات
- ہاتھ
- ہینڈل
- ہے
- مدد
- مدد کرتا ہے
- اس کی
- کس طرح
- HTTPS
- ICS
- if
- عدم توازن
- درآمد
- in
- شامل
- انڈکس
- بھارت
- Indices
- معلومات
- ان پٹ
- آدانوں
- دلچسپی
- دلچسپ
- چوراہا
- میں
- IT
- صرف
- KDnuggets
- جان
- علم
- لیبل
- لیبل
- زبان
- جانیں
- سیکھا ہے
- سیکھنے
- کم
- دو
- لائبریری
- لائسنس
- لائسنس یافتہ
- کی طرح
- امکان
- پسند
- لائن
- لوڈ کر رہا ہے
- لاگ ان کریں
- دیکھو
- کی طرح دیکھو
- بند
- مشین
- مشین لرننگ
- بنا
- بہت سے
- نقشہ
- ریاضی
- matplotlib
- زیادہ سے زیادہ
- زیادہ سے زیادہ
- زیادہ سے زیادہ
- مئی..
- مطلب
- طریقہ
- پیمائش کا معیار
- کم سے کم
- کم سے کم
- ماڈل
- ماڈل
- ماڈیول
- زیادہ
- منتقل
- نام
- قدرتی
- قدرتی زبان
- قدرتی زبان عملیات
- ضرورت ہے
- منفی
- اگلے
- تعداد
- مشاہدہ
- of
- اکثر
- on
- ایک
- رائے
- اس کے برعکس
- زیادہ سے زیادہ
- اصلاح کے
- کی اصلاح کریں
- or
- نتائج
- نتائج
- پیداوار
- نتائج
- pandas
- پیرامیٹر
- پیرامیٹرز
- حصہ
- ٹکڑے ٹکڑے
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- پوائنٹ
- پوائنٹس
- ممکنہ طور پر
- صحت سے متعلق
- پیش گوئی
- پیشن گوئی
- پیشن گوئی
- پیش گو
- پیش گوئیاں
- کو ترجیح دیتے ہیں
- امکان
- مسئلہ
- آگے بڑھو
- عمل
- پروسیسنگ
- حاصل
- پروگرامنگ
- فراہم
- خالص
- ازگر
- ریڈار
- رینج
- شرح
- پڑھیں
- پڑھنا
- اصلی
- ریکارڈ
- کہا جاتا ہے
- مراد
- رجعت
- رپورٹ
- ذخیرہ
- کی نمائندگی کرتا ہے
- درخواست
- احترام
- بالترتیب
- واپسی
- کا جائزہ لینے کے
- مضبوط
- حکمرانی
- s
- سائنس
- سائنٹ سیکھنا
- سکور
- دیکھنا
- احساس
- مقرر
- سیٹ
- اشتراک
- وہ
- دکھایا گیا
- سادہ
- آسان بنانے
- So
- کچھ
- تقسیم
- شروع
- کے اعداد و شمار
- مرحلہ
- براہ راست
- ساخت
- بعد میں
- اس طرح
- موزوں
- رقم
- لے لو
- لیتا ہے
- ہدف
- کاموں
- ٹیکنیکل
- ٹیسٹ
- ٹیسٹنگ
- سے
- کہ
- ۔
- ان
- نظریہ
- وہاں.
- لہذا
- وہ
- اس
- کے ذریعے
- کرنے کے لئے
- آلات
- ٹرین
- تربیت یافتہ
- ٹریننگ
- تبدیل
- تبادلوں
- کوشش
- سبق
- سبق
- دو
- اقسام
- کے تحت
- سمجھ
- یونٹ
- اپ ڈیٹ کریں
- تازہ ترین معلومات
- URL
- us
- امریکی اکاؤنٹ
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- کا استعمال کرتے ہوئے
- قیمت
- اقدار
- تصور کرنا
- we
- جب
- جس
- کیوں
- وکیپیڈیا
- گے
- ونگ
- ساتھ
- کام
- کام کر
- کام کرتا ہے
- گا
- مصنف
- تحریری طور پر
- X
- جی ہاں
- آپ
- اور
- زیفیرنیٹ
- صفر