مصنف کی طرف سے تصویر
ڈیٹا سائنس اور مشین لرننگ کی دنیا میں غوطہ لگاتے ہوئے، آپ کو جن بنیادی مہارتوں کا سامنا کرنا پڑے گا وہ ڈیٹا پڑھنے کا فن ہے۔ اگر آپ کو پہلے ہی اس کے بارے میں کچھ تجربہ ہے، تو آپ شاید JSON (JavaScript آبجیکٹ نوٹیشن) سے واقف ہوں گے - ڈیٹا کو ذخیرہ کرنے اور تبادلہ کرنے دونوں کے لیے ایک مقبول فارمیٹ۔
سوچیں کہ کس طرح NoSQL ڈیٹا بیس جیسے MongoDB JSON میں ڈیٹا اسٹور کرنا پسند کرتے ہیں، یا REST APIs اکثر اسی فارمیٹ میں کیسے جواب دیتے ہیں۔
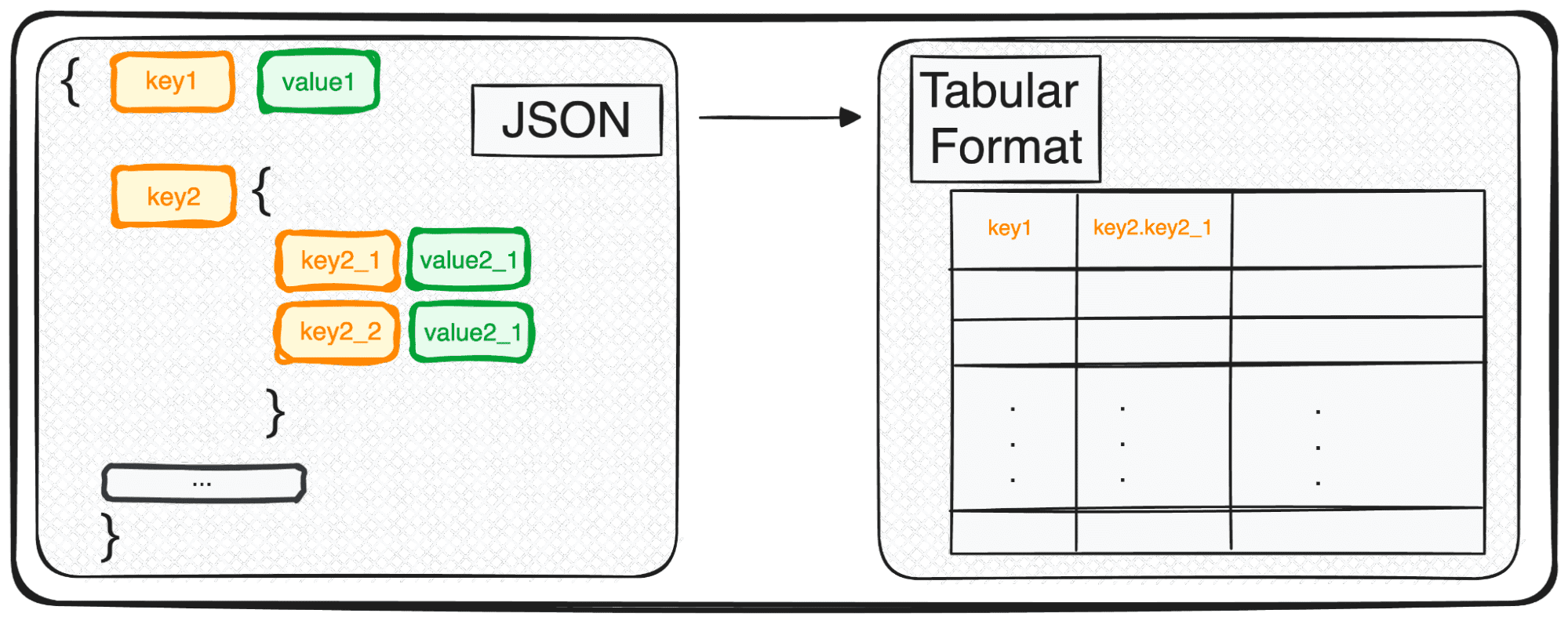
تاہم، JSON، اگرچہ ذخیرہ کرنے اور تبادلے کے لیے بہترین ہے، لیکن اپنی خام شکل میں گہرائی سے تجزیہ کرنے کے لیے بالکل تیار نہیں ہے۔ یہ وہ جگہ ہے جہاں ہم اسے زیادہ تجزیاتی طور پر دوستانہ چیز میں تبدیل کرتے ہیں – ایک ٹیبلر فارمیٹ۔
لہذا، چاہے آپ کسی ایک JSON آبجیکٹ کے ساتھ کام کر رہے ہوں یا ان میں سے ایک خوشگوار صف، Python کی شرائط میں، آپ بنیادی طور پر ایک dict یا dicts کی فہرست کو ہینڈل کر رہے ہیں۔
آئیے مل کر دریافت کریں کہ یہ تبدیلی کیسے سامنے آتی ہے، جس سے ہمارے ڈیٹا کو تجزیہ کے لیے تیار کیا جاتا ہے؟؟؟؟
آج میں ایک جادوئی کمانڈ کی وضاحت کروں گا جو ہمیں آسانی سے کسی بھی JSON کو سیکنڈوں میں ٹیبلر فارمیٹ میں پارس کرنے کی اجازت دیتا ہے۔
اور یہ ہے … pd.json_normalize()
تو آئیے دیکھتے ہیں کہ یہ JSON کی مختلف اقسام کے ساتھ کیسے کام کرتا ہے۔
JSON کی پہلی قسم جس کے ساتھ ہم کام کر سکتے ہیں وہ چند کلیدوں اور اقدار کے ساتھ سنگل لیولڈ JSONs ہے۔ ہم اپنے پہلے سادہ JSONs کی وضاحت اس طرح کرتے ہیں:
مصنف کی طرف سے کوڈ
تو آئیے ان JSON کے ساتھ کام کرنے کی ضرورت کی تقلید کریں۔ ہم سب جانتے ہیں کہ ان کے JSON فارمیٹ میں کرنے کے لیے بہت کچھ نہیں ہے۔ ہمیں ان JSONs کو کچھ پڑھنے کے قابل اور قابل ترمیم فارمیٹ میں تبدیل کرنے کی ضرورت ہے… جس کا مطلب ہے Pandas DataFrames!
1.1 سادہ JSON ڈھانچے سے نمٹنا
سب سے پہلے، ہمیں پانڈاس لائبریری کو درآمد کرنے کی ضرورت ہے اور پھر ہم pd.json_normalize() کمانڈ استعمال کرسکتے ہیں، جیسا کہ:
import pandas as pd
pd.json_normalize(json_string)
ایک ریکارڈ کے ساتھ JSON پر اس کمانڈ کو لاگو کرنے سے، ہم سب سے بنیادی جدول حاصل کرتے ہیں۔ تاہم، جب ہمارا ڈیٹا تھوڑا زیادہ پیچیدہ ہوتا ہے اور JSONs کی فہرست پیش کرتا ہے، تب بھی ہم اسی کمانڈ کو مزید پیچیدگیوں کے بغیر استعمال کر سکتے ہیں اور آؤٹ پٹ ایک سے زیادہ ریکارڈ والے ٹیبل کے مطابق ہوگا۔

مصنف کی طرف سے تصویر
آسان… ٹھیک ہے؟
اگلا فطری سوال یہ ہے کہ جب کچھ اقدار غائب ہوں تو کیا ہوتا ہے۔
1.2 کالعدم اقدار سے نمٹنا
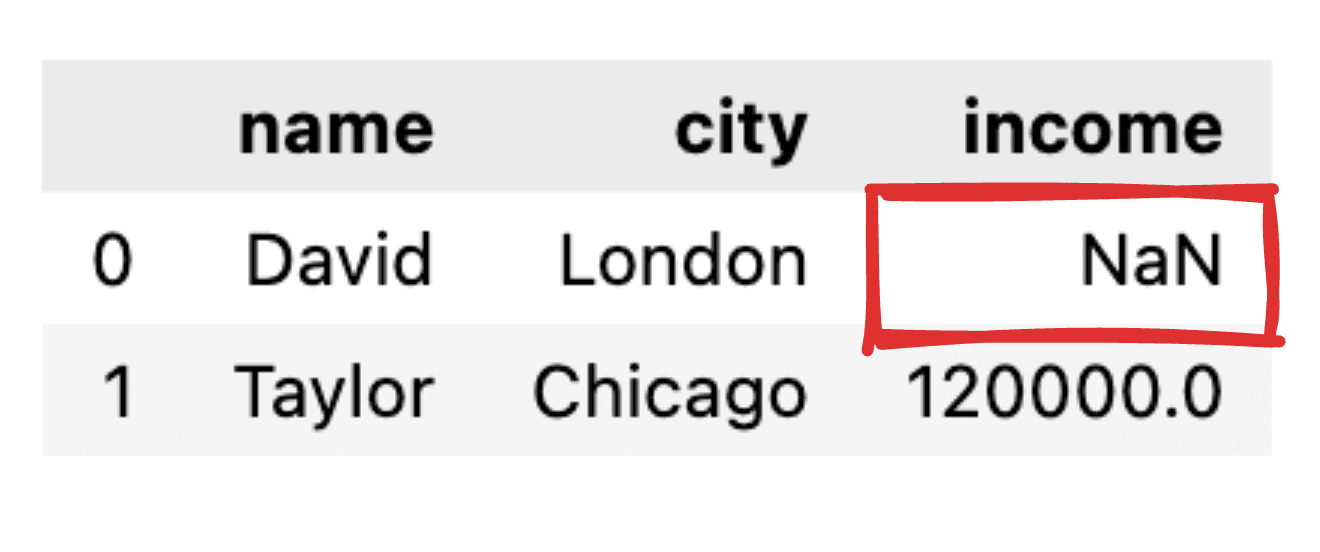
تصور کریں کہ کچھ اقدار کی اطلاع نہیں ہے، جیسے کہ ڈیوڈ کے لیے آمدنی کا ریکارڈ غائب ہے۔ ہمارے JSON کو ایک سادہ پانڈاس ڈیٹا فریم میں تبدیل کرتے وقت، متعلقہ قدر NaN کے بطور ظاہر ہوگی۔
مصنف کی طرف سے تصویر
اور اگر میں صرف کچھ کھیتوں کو حاصل کرنا چاہتا ہوں تو کیا ہوگا؟
1.3 صرف دلچسپی کے ان کالموں کا انتخاب کرنا
اگر ہم صرف کچھ مخصوص فیلڈز کو ٹیبلر پانڈا ڈیٹا فریم میں تبدیل کرنا چاہتے ہیں، تو json_normalize() کمانڈ ہمیں یہ منتخب کرنے کی اجازت نہیں دیتی کہ کن فیلڈز کو تبدیل کرنا ہے۔
لہذا، JSON کی ایک چھوٹی سی پری پروسیسنگ کی جانی چاہئے جہاں ہم دلچسپی کے صرف ان کالموں کو فلٹر کرتے ہیں۔
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
تو، آئیے کچھ اور جدید JSON ڈھانچے کی طرف چلتے ہیں۔
ایک سے زیادہ درجے والے JSONs کے ساتھ کام کرتے وقت ہم خود کو مختلف سطحوں کے اندر اندر کے JSONs کے ساتھ پاتے ہیں۔ طریقہ کار پہلے جیسا ہی ہے، لیکن اس معاملے میں، ہم منتخب کر سکتے ہیں کہ ہم کتنی سطحوں کو تبدیل کرنا چاہتے ہیں۔ پہلے سے طے شدہ طور پر، کمانڈ ہمیشہ تمام سطحوں کو پھیلائے گی اور تمام نیسٹڈ لیولز کے مربوط نام پر مشتمل نئے کالم تیار کرے گی۔
لہذا اگر ہم درج ذیل JSONs کو معمول پر لاتے ہیں۔
مصنف کی طرف سے کوڈ
ہمیں فیلڈ اسکلز کے تحت 3 کالموں کے ساتھ درج ذیل ٹیبل ملے گا۔
- skills.python
- سکلز۔ ایس کیو ایل
- سکلز۔ جی سی پی
اور فیلڈ رولز کے تحت 4 کالم
- roles.project مینیجر
- رولز ڈیٹا انجینئر
- رولز ڈیٹا سائنسدان
- رولز ڈیٹا تجزیہ کار

مصنف کی طرف سے تصویر
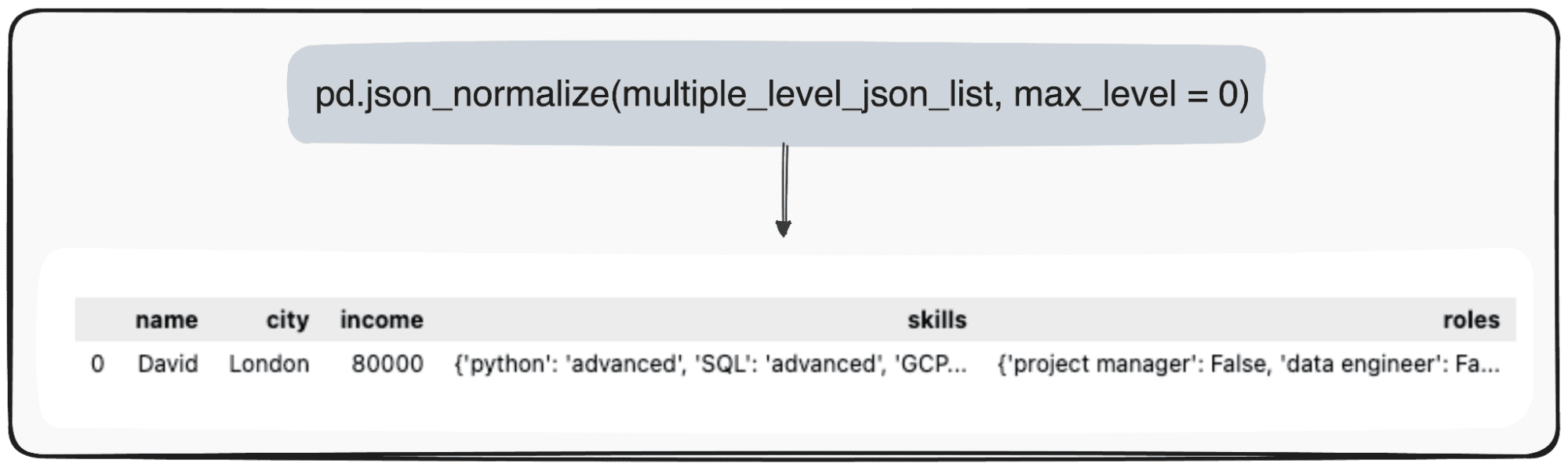
تاہم، تصور کریں کہ ہم صرف اپنی اعلیٰ سطح کو تبدیل کرنا چاہتے ہیں۔ ہم خاص طور پر پیرامیٹر max_level کو 0 (max_level جس کو ہم بڑھانا چاہتے ہیں) کی وضاحت کر کے ایسا کر سکتے ہیں۔
pd.json_normalize(mutliple_level_json_list, max_level = 0)
ہمارے پانڈا ڈیٹا فریم کے اندر JSONs کے اندر زیر التواء اقدار کو برقرار رکھا جائے گا۔
مصنف کی طرف سے تصویر
آخری کیس جو ہم تلاش کر سکتے ہیں وہ ہے ایک JSON فیلڈ میں نیسٹڈ لسٹ۔ لہذا ہم پہلے اپنے JSONs کو استعمال کرنے کی وضاحت کرتے ہیں۔
مصنف کی طرف سے کوڈ
ہم Python میں پانڈوں کا استعمال کرتے ہوئے اس ڈیٹا کو مؤثر طریقے سے منظم کر سکتے ہیں۔ pd.json_normalize() فنکشن اس تناظر میں خاص طور پر مفید ہے۔ یہ JSON ڈیٹا کو فلیٹ کر سکتا ہے، بشمول نیسٹڈ لسٹ، تجزیہ کے لیے موزوں ساختی شکل میں۔ جب یہ فنکشن ہمارے JSON ڈیٹا پر لاگو ہوتا ہے، تو یہ ایک نارملائزڈ ٹیبل تیار کرتا ہے جو اپنے فیلڈز کے حصے کے طور پر نیسٹڈ لسٹ کو شامل کرتا ہے۔
مزید یہ کہ پانڈاس اس عمل کو مزید بہتر بنانے کی صلاحیت پیش کرتے ہیں۔ pd.json_normalize() میں record_path پیرامیٹر استعمال کرکے، ہم فنکشن کو خاص طور پر نیسٹڈ لسٹ کو نارملائز کرنے کی ہدایت کر سکتے ہیں۔
اس کارروائی کے نتیجے میں فہرست کے مندرجات کے لیے خصوصی طور پر ایک سرشار جدول بنتا ہے۔ پہلے سے طے شدہ طور پر، یہ عمل صرف فہرست کے اندر موجود عناصر کو کھولے گا۔ تاہم، اس جدول کو اضافی سیاق و سباق کے ساتھ افزودہ کرنے کے لیے، جیسے کہ ہر ریکارڈ کے لیے ایک منسلک ID برقرار رکھنا، ہم میٹا پیرامیٹر استعمال کر سکتے ہیں۔

مصنف کی طرف سے تصویر
خلاصہ یہ کہ Python's Pandas لائبریری کا استعمال کرتے ہوئے JSON ڈیٹا کو CSV فائلوں میں تبدیل کرنا آسان اور موثر ہے۔
JSON اب بھی جدید ڈیٹا اسٹوریج اور ایکسچینج میں سب سے عام شکل ہے، خاص طور پر NoSQL ڈیٹا بیسز اور REST APIs میں۔ تاہم، یہ کچھ اہم تجزیاتی چیلنجز پیش کرتا ہے جب اس کے خام فارمیٹ میں ڈیٹا سے نمٹا جاتا ہے۔
پانڈوں کے pd.json_normalize() کا اہم کردار اس طرح کے فارمیٹس کو ہینڈل کرنے اور ہمارے ڈیٹا کو پانڈا ڈیٹا فریم میں تبدیل کرنے کے ایک بہترین طریقہ کے طور پر ابھرتا ہے۔
مجھے امید ہے کہ یہ گائیڈ مفید تھا، اور اگلی بار جب آپ JSON کے ساتھ ڈیل کر رہے ہوں گے، تو آپ اسے زیادہ موثر طریقے سے کر سکتے ہیں۔
آپ اس میں متعلقہ Jupyter نوٹ بک کو چیک کر سکتے ہیں۔ GitHub ریپو کے بعد۔
جوزپ فیرر بارسلونا سے تجزیاتی انجینئر ہے۔ اس نے فزکس انجینئرنگ میں گریجویشن کیا اور فی الحال انسانی نقل و حرکت پر لاگو ڈیٹا سائنس فیلڈ میں کام کر رہا ہے۔ وہ جز وقتی مواد بنانے والا ہے جس کی توجہ ڈیٹا سائنس اور ٹیکنالوجی پر ہے۔ آپ اس پر رابطہ کر سکتے ہیں۔ لنکڈ, ٹویٹر or درمیانہ.
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- : ہے
- : نہیں
- :کہاں
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- ہمارے بارے میں
- عمل
- ایڈیشنل
- اعلی درجے کی
- تمام
- کی اجازت
- کی اجازت دیتا ہے
- پہلے ہی
- ہمیشہ
- an
- تجزیہ
- تجزیہ کار
- تجزیاتی
- تجزیاتی
- اور
- کوئی بھی
- APIs
- ظاہر
- اطلاقی
- درخواست دینا
- کیا
- لڑی
- فن
- AS
- منسلک
- بارسلونا
- بنیادی
- BE
- اس سے پہلے
- بٹ
- دونوں
- لیکن
- by
- کر سکتے ہیں
- صلاحیت
- کیس
- چیلنجوں
- چیک کریں
- میں سے انتخاب کریں
- شہر
- کالم
- کامن
- پیچیدہ
- پیچیدگی
- رابطہ کریں
- مواد
- مندرجات
- سیاق و سباق
- تبدیل
- تبدیل کرنا
- correspond,en
- اسی کے مطابق
- خالق
- اس وقت
- اعداد و شمار
- ڈیٹا تجزیہ کار
- ڈیٹا انجینئر
- ڈیٹا سائنس
- ڈیٹا سائنسدان
- ڈیٹا اسٹوریج
- ڈیٹا بیس
- ڈیوڈ
- معاملہ
- وقف
- پہلے سے طے شدہ
- وضاحت
- وضاحت
- خوشگوار
- DICT
- مختلف
- براہ راست
- do
- کرتا
- ہر ایک
- آسانی سے
- آسان
- موثر
- مؤثر طریقے
- عناصر
- ابھرتا ہے
- تصادم
- انجینئر
- انجنیئرنگ
- افزودگی
- بنیادی طور پر
- ایکسچینج
- تبادلہ
- خاص طور سے
- توسیع
- تجربہ
- کی وضاحت
- تلاش
- واقف
- چند
- میدان
- قطعات
- فائلوں
- فلٹر
- مل
- پہلا
- توجہ مرکوز
- کے بعد
- مندرجہ ذیل ہے
- کے لئے
- فارم
- فارمیٹ
- دوستانہ
- سے
- تقریب
- بنیادی
- مزید
- GCP
- پیدا
- حاصل
- GitHub کے
- Go
- عظیم
- رہنمائی
- ہینڈل
- ہینڈلنگ
- ہوتا ہے
- ہے
- ہونے
- he
- اسے
- امید ہے کہ
- کس طرح
- تاہم
- HTTPS
- انسانی
- i
- میں ہوں گے
- ID
- if
- تصور
- درآمد
- اہم
- in
- میں گہرائی
- شامل
- سمیت
- انکم
- شامل
- مطلع
- مثال کے طور پر
- دلچسپی
- میں
- نہیں
- IT
- میں
- جاوا سکرپٹ
- JSON
- Jupyter نوٹ بک
- صرف
- KDnuggets
- کلیدی
- چابیاں
- جان
- آخری
- سیکھنے
- سطح
- سطح
- لائبریری
- کی طرح
- لنکڈ
- لسٹ
- تھوڑا
- ll
- محبت
- مشین
- مشین لرننگ
- ماجک
- برقرار رکھا
- بنانا
- انتظام
- مینیجر
- بہت سے
- کا مطلب ہے کہ
- میٹا
- لاپتہ
- موبلٹی
- جدید
- منگو ڈی بی
- زیادہ
- سب سے زیادہ
- منتقل
- بہت
- ایک سے زیادہ
- نام
- قدرتی
- ضرورت ہے
- گھوںسلا
- نئی
- اگلے
- نہیں
- خاص طور پر
- نوٹ بک
- اعتراض
- حاصل
- of
- تجویز
- اکثر
- on
- ایک
- صرف
- or
- ہمارے
- خود
- پیداوار
- pandas
- پیرامیٹر
- حصہ
- خاص طور پر
- زیر التواء
- کامل
- کارکردگی
- طبعیات
- اہم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- مقبول
- تحفہ
- شاید
- طریقہ کار
- عمل
- پیدا کرتا ہے
- منصوبے
- ازگر
- سوال
- بہت
- خام
- RE
- پڑھنا
- تیار
- ریکارڈ
- ریکارڈ
- بہتر
- جواب
- باقی
- نتائج کی نمائش
- برقرار رکھنے
- ٹھیک ہے
- کردار
- s
- اسی
- سائنس
- سائنس اور ٹیکنالوجی
- سائنسدان
- سیکنڈ
- دیکھنا
- منتخب
- ہونا چاہئے
- سادہ
- نقلی
- ایک
- مہارت
- چھوٹے
- So
- کچھ
- کچھ
- مخصوص
- خاص طور پر
- SQL
- ابھی تک
- ذخیرہ
- ذخیرہ
- ساخت
- منظم
- اس طرح
- موزوں
- خلاصہ
- T
- ٹیبل
- ٹیکنالوجی
- شرائط
- کہ
- ۔
- دنیا
- ان
- ان
- تو
- یہ
- اس
- ان
- وقت
- کرنے کے لئے
- مل کر
- سب سے اوپر
- تبدیل
- تبدیلی
- تبدیل
- قسم
- اقسام
- کے تحت
- us
- استعمال کی شرائط
- مفید
- کا استعمال کرتے ہوئے
- استعمال کرنا۔
- قیمت
- اقدار
- چاہتے ہیں
- تھا
- راستہ..
- we
- کیا
- جب
- چاہے
- جس
- جبکہ
- گے
- ساتھ
- کے اندر
- کام
- کام کر
- کام کرتا ہے
- دنیا
- گا
- آپ
- زیفیرنیٹ