
جیسے ہی AI کلاؤڈ سے Edge کی طرف منتقل ہوتا ہے، ہم دیکھتے ہیں کہ ٹیکنالوجی کو استعمال کے مختلف کیسز میں استعمال کیا جا رہا ہے - جس میں بے ضابطگی کا پتہ لگانے سے لے کر سمارٹ شاپنگ، سرویلنس، روبوٹکس، اور فیکٹری آٹومیشن سمیت ایپلی کیشنز شامل ہیں۔ لہٰذا، کوئی ایک ہی سائز کے فٹ ہونے والا حل نہیں ہے۔ لیکن کیمرے سے چلنے والے آلات کی تیزی سے ترقی کے ساتھ، AI کو ریئل ٹائم ویڈیو ڈیٹا کا تجزیہ کرنے کے لیے سب سے زیادہ وسیع پیمانے پر اپنایا گیا ہے تاکہ حفاظت کو بڑھانے، آپریشنل افادیت کو بہتر بنانے، اور صارفین کے بہتر تجربات فراہم کرنے کے لیے ویڈیو مانیٹرنگ کو خودکار بنایا جا سکے، اور بالآخر ان کی صنعتوں میں مسابقتی برتری حاصل کی جا سکے۔ . ویڈیو تجزیہ کو بہتر طریقے سے سپورٹ کرنے کے لیے، آپ کو ایج AI کی تعیناتیوں میں سسٹم کی کارکردگی کو بہتر بنانے کی حکمت عملیوں کو سمجھنا چاہیے۔
- مطلوبہ کارکردگی کی سطح کو پورا کرنے یا اس سے زیادہ کرنے کے لیے صحیح سائز کے کمپیوٹ انجنوں کا انتخاب کرنا۔ AI ایپلیکیشن کے لیے، ان کمپیوٹ انجنوں کو پوری وژن پائپ لائن کے افعال انجام دینے چاہئیں (یعنی، ویڈیو پری اور پوسٹ پروسیسنگ، نیورل نیٹ ورک انفرنسنگ)۔
ایک وقف شدہ AI ایکسلریٹر، چاہے وہ مجرد ہو یا کسی SoC میں ضم ہو (جیسا کہ CPU یا GPU پر AI انفرنسنگ چلانے کے برخلاف) کی ضرورت ہو سکتی ہے۔
- تھرو پٹ اور تاخیر کے درمیان فرق کو سمجھنا؛ جس کے تحت تھرو پٹ وہ شرح ہے جس میں ڈیٹا کو سسٹم میں پروسیس کیا جا سکتا ہے اور لیٹینسی سسٹم کے ذریعے ڈیٹا پروسیسنگ میں تاخیر کی پیمائش کرتی ہے اور اکثر ریئل ٹائم ردعمل سے منسلک ہوتی ہے۔ مثال کے طور پر، ایک سسٹم 100 فریم فی سیکنڈ (تھرو پٹ) کے حساب سے تصویری ڈیٹا تیار کر سکتا ہے لیکن سسٹم سے گزرنے میں ایک تصویر کے لیے 100ms (لیٹنسی) لگتی ہے۔
- بڑھتی ہوئی ضروریات، بدلتی ہوئی تقاضوں اور ترقی پذیر ٹیکنالوجیز (مثلاً فعالیت اور درستگی کے لیے مزید جدید ترین AI ماڈلز) کو ایڈجسٹ کرنے کے لیے مستقبل میں AI کارکردگی کو آسانی سے پیمانہ کرنے کی صلاحیت پر غور کرنا۔ آپ ماڈیول فارمیٹ میں AI ایکسلریٹر کا استعمال کرتے ہوئے یا اضافی AI ایکسلریٹر چپس کے ساتھ کارکردگی کی پیمائش کو پورا کر سکتے ہیں۔
اصل کارکردگی کی ضروریات درخواست پر منحصر ہیں۔ عام طور پر، کوئی یہ توقع کر سکتا ہے کہ ویڈیو اینالیٹکس کے لیے، سسٹم کو 30-60 فریم فی سیکنڈ اور 1080p یا 4k کی ریزولوشن کے ساتھ کیمروں سے آنے والے ڈیٹا اسٹریمز پر کارروائی کرنی چاہیے۔ ایک AI سے چلنے والا کیمرہ ایک اسٹریم پر کارروائی کرے گا۔ ایک کنارے کا سامان متوازی طور پر متعدد اسٹریمز پر کارروائی کرے گا۔ دونوں صورتوں میں، ایج AI سسٹم کو کیمرے کے سینسر ڈیٹا کو ایک ایسے فارمیٹ میں تبدیل کرنے کے لیے پری پروسیسنگ فنکشنز کو سپورٹ کرنا چاہیے جو AI انفرنسنگ سیکشن کی ان پٹ ضروریات سے میل کھاتا ہو (شکل 1)۔
AI ایکسلریٹر پر چلنے والے ماڈل میں ان پٹ کو فیڈ کرنے سے پہلے پری پروسیسنگ فنکشنز خام ڈیٹا کو لیتے ہیں اور سائز تبدیل کرنے، نارملائزیشن، اور رنگ کی جگہ کی تبدیلی جیسے کام انجام دیتے ہیں۔ پری پروسیسنگ وقت کو کم کرنے کے لیے OpenCV جیسی موثر امیج پروسیسنگ لائبریریوں کا استعمال کر سکتی ہے۔ پوسٹ پروسیسنگ میں تخمینہ کے آؤٹ پٹ کا تجزیہ کرنا شامل ہے۔ یہ غیر زیادہ سے زیادہ دبانے جیسے کاموں کا استعمال کرتا ہے (NMS زیادہ تر آبجیکٹ کا پتہ لگانے والے ماڈلز کے آؤٹ پٹ کی ترجمانی کرتا ہے) اور قابل عمل بصیرت پیدا کرنے کے لیے امیج ڈسپلے، جیسے باؤنڈنگ بکس، کلاس لیبل، یا اعتماد کے اسکورز۔

شکل 1. AI ماڈل کی انفرنسنگ کے لیے، پروسیسنگ سے پہلے اور پوسٹ پروسیسنگ کے افعال عام طور پر ایپلی کیشن پروسیسر پر کیے جاتے ہیں۔
اے آئی ماڈل کا اندازہ لگانے میں ایپلی کیشن کی صلاحیتوں کے لحاظ سے ایک سے زیادہ نیورل نیٹ ورک ماڈلز کو فی فریم پروسیس کرنے کا اضافی چیلنج ہو سکتا ہے۔ کمپیوٹر وژن ایپلی کیشنز میں عام طور پر متعدد AI کام شامل ہوتے ہیں جن میں متعدد ماڈلز کی پائپ لائن کی ضرورت ہوتی ہے۔ مزید برآں، ایک ماڈل کا آؤٹ پٹ اکثر اگلے ماڈل کا ان پٹ ہوتا ہے۔ دوسرے لفظوں میں، ایک ایپلی کیشن میں ماڈل اکثر ایک دوسرے پر منحصر ہوتے ہیں اور انہیں ترتیب وار عمل میں لایا جانا چاہیے۔ عمل کرنے کے لیے ماڈلز کا صحیح سیٹ جامد نہیں ہو سکتا اور متحرک طور پر مختلف ہو سکتا ہے، یہاں تک کہ فریم بہ فریم کی بنیاد پر۔
متعدد ماڈلز کو متحرک طور پر چلانے کے چیلنج کے لیے ماڈلز کو ذخیرہ کرنے کے لیے وقف اور کافی بڑی میموری کے ساتھ ایک بیرونی AI ایکسلریٹر کی ضرورت ہوتی ہے۔ اکثر ایس او سی کے اندر مربوط AI ایکسلریٹر مشترکہ میموری سب سسٹم اور ایس او سی میں دیگر وسائل کی طرف سے عائد رکاوٹوں کی وجہ سے ملٹی ماڈل ورک بوجھ کا انتظام کرنے سے قاصر ہوتا ہے۔
مثال کے طور پر، حرکت کی پیشن گوئی پر مبنی آبجیکٹ ٹریکنگ ایک ویکٹر کا تعین کرنے کے لیے مسلسل کھوجوں پر انحصار کرتی ہے جو مستقبل کی پوزیشن پر ٹریک کردہ آبجیکٹ کی شناخت کے لیے استعمال ہوتا ہے۔ اس نقطہ نظر کی تاثیر محدود ہے کیونکہ اس میں حقیقی شناخت کی صلاحیت کا فقدان ہے۔ حرکت کی پیشن گوئی کے ساتھ، کسی چیز کا ٹریک کھو جانے کی وجہ سے کھویا جا سکتا ہے، وقوع پذیری، یا کسی چیز کے منظر کے میدان کو چھوڑنا، یہاں تک کہ لمحہ بہ لمحہ۔ ایک بار کھو جانے کے بعد، آبجیکٹ کے ٹریک کو دوبارہ منسلک کرنے کا کوئی طریقہ نہیں ہے۔ شناخت کا اضافہ اس حد کو حل کرتا ہے لیکن اس کے لیے بصری ظاہری شکل کو سرایت کرنے کی ضرورت ہوتی ہے (یعنی، تصویری فنگر پرنٹ)۔ ظاہری شکل میں سرایت کرنے کے لیے ایک دوسرے نیٹ ورک کی ضرورت ہوتی ہے تاکہ پہلے نیٹ ورک کے ذریعے دریافت کردہ آبجیکٹ کے باؤنڈنگ باکس کے اندر موجود تصویر پر کارروائی کرکے فیچر ویکٹر تیار کیا جا سکے۔ اس ایمبیڈنگ کو وقت یا جگہ سے قطع نظر آبجیکٹ کو دوبارہ شناخت کرنے کے لیے استعمال کیا جا سکتا ہے۔ چونکہ منظر کے میدان میں پائے جانے والے ہر شے کے لیے سرایت کرنا ضروری ہے، اس لیے منظر کے مصروف ہونے پر پروسیسنگ کی ضروریات بڑھ جاتی ہیں۔ شناخت کے ساتھ آبجیکٹ ٹریکنگ کے لیے اعلی درستگی / ہائی ریزولوشن / ہائی فریم ریٹ کا پتہ لگانے اور سرایت کرنے کی اسکیل ایبلٹی کے لیے کافی اوور ہیڈ محفوظ کرنے کے درمیان محتاط غور و فکر کی ضرورت ہوتی ہے۔ پروسیسنگ کی ضرورت کو حل کرنے کا ایک طریقہ ایک وقف شدہ AI ایکسلریٹر کا استعمال کرنا ہے۔ جیسا کہ پہلے ذکر کیا گیا ہے، SoC کا AI انجن مشترکہ میموری وسائل کی کمی کا شکار ہو سکتا ہے۔ ماڈل کی اصلاح کو پروسیسنگ کی ضرورت کو کم کرنے کے لیے بھی استعمال کیا جا سکتا ہے، لیکن یہ کارکردگی اور/یا درستگی کو متاثر کر سکتا ہے۔
ایک سمارٹ کیمرہ یا ایج اپلائنس میں، مربوط SoC (یعنی، ہوسٹ پروسیسر) ویڈیو فریمز حاصل کرتا ہے اور پروسیسنگ سے پہلے کے مراحل کو انجام دیتا ہے جن کا ہم نے پہلے بیان کیا تھا۔ یہ فنکشنز SoC کے CPU cores یا GPU (اگر کوئی دستیاب ہو) کے ساتھ انجام دیے جا سکتے ہیں، لیکن وہ SoC میں ہارڈویئر ایکسلریٹر کے ذریعے بھی انجام دے سکتے ہیں (مثال کے طور پر، امیج سگنل پروسیسر)۔ ان پری پروسیسنگ مراحل کے مکمل ہونے کے بعد، AI ایکسلریٹر جو SoC میں ضم ہو جاتا ہے اس کے بعد سسٹم میموری سے اس کوانٹائزڈ ان پٹ تک براہ راست رسائی حاصل کر سکتا ہے، یا ایک مجرد AI ایکسلریٹر کی صورت میں، ان پٹ کو تخمینہ کے لیے پہنچایا جاتا ہے، عام طور پر USB یا PCIe انٹرفیس۔
ایک مربوط SoC میں کمپیوٹنگ یونٹس کی ایک رینج شامل ہو سکتی ہے، بشمول CPUs، GPUs، AI ایکسلریٹر، وژن پروسیسرز، ویڈیو انکوڈرز/ڈیکوڈرز، امیج سگنل پروسیسر (ISP) اور بہت کچھ۔ یہ کمپیوٹیشن یونٹس سب ایک ہی میموری بس کا اشتراک کرتے ہیں اور اس کے نتیجے میں ایک ہی میموری تک رسائی حاصل کرتے ہیں۔ مزید برآں، CPU اور GPU کو بھی اندازہ لگانے میں اپنا کردار ادا کرنا پڑ سکتا ہے اور یہ یونٹس تعینات نظام میں دوسرے کاموں کو چلانے میں مصروف ہوں گے۔ سسٹم لیول اوور ہیڈ سے ہمارا مطلب یہی ہے (شکل 2)۔
بہت سے ڈویلپرز غلطی سے ایس او سی میں بلٹ ان AI ایکسلریٹر کی کارکردگی کا مجموعی کارکردگی پر سسٹم لیول اوور ہیڈ کے اثر پر غور کیے بغیر جائزہ لیتے ہیں۔ مثال کے طور پر، کسی SoC میں مربوط 50 TOPS AI ایکسلریٹر پر YOLO بینچ مارک چلانے پر غور کریں، جو 100 inferences/second (IPS) کا بینچ مارک نتیجہ حاصل کر سکتا ہے۔ لیکن ایک متعین کردہ نظام میں اس کی دیگر تمام کمپیوٹیشنل اکائیاں فعال ہیں، وہ 50 ٹاپس کم ہو کر 12 ٹاپس کی طرح کچھ ہو سکتے ہیں اور مجموعی کارکردگی صرف 25 IPS حاصل کرے گی، یہ فرض کرتے ہوئے کہ 25% استعمال کے عنصر کو فراموش کر دیا گیا ہے۔ اگر پلیٹ فارم مسلسل ویڈیو اسٹریمز پر کارروائی کر رہا ہو تو سسٹم اوور ہیڈ ہمیشہ ایک عنصر ہوتا ہے۔ متبادل طور پر، ایک مجرد AI ایکسلریٹر کے ساتھ (مثال کے طور پر، کنارا آرا-1، ہیلو-8، انٹیل مائریڈ ایکس)، سسٹم لیول کا استعمال 90% سے زیادہ ہو سکتا ہے کیونکہ ایک بار میزبان ایس او سی انفرنسنگ فنکشن شروع کرتا ہے اور AI ماڈل کے ان پٹ کو منتقل کرتا ہے۔ ڈیٹا، ایکسلریٹر ماڈل وزن اور پیرامیٹرز تک رسائی کے لیے اپنی وقف شدہ میموری کو استعمال کرتے ہوئے خود مختار طور پر چلتا ہے۔
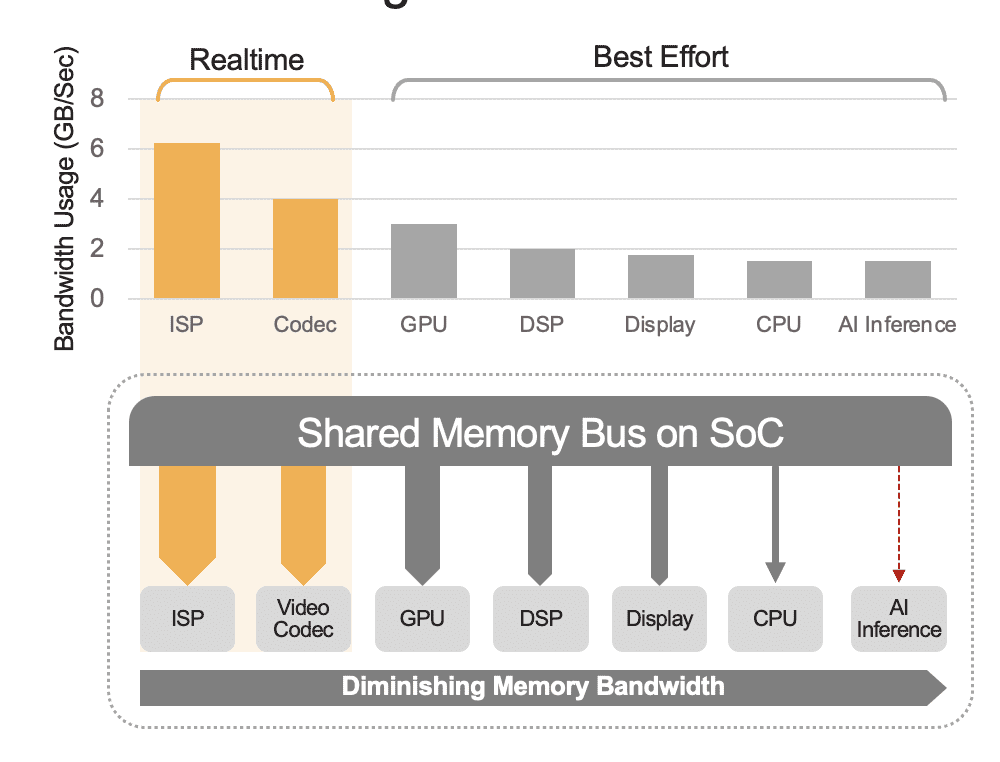
تصویر 2۔ مشترکہ میموری بس سسٹم کی سطح کی کارکردگی کو کنٹرول کرے گی، جو یہاں تخمینی قدروں کے ساتھ دکھائی گئی ہے۔ آپ کے ایپلیکیشن کے استعمال کے ماڈل اور SoC کی کمپیوٹ یونٹ کی ترتیب کی بنیاد پر حقیقی قدریں مختلف ہوں گی۔
اس وقت تک، ہم نے فریم فی سیکنڈ اور ٹاپس کے لحاظ سے AI کارکردگی پر تبادلہ خیال کیا ہے۔ لیکن نظام کی اصل وقتی ردعمل کی فراہمی کے لیے کم تاخیر ایک اور اہم ضرورت ہے۔ مثال کے طور پر، گیمنگ میں، کم تاخیر ایک ہموار اور جوابدہ گیمنگ کے تجربے کے لیے اہم ہے، خاص طور پر موشن کنٹرول گیمز اور ورچوئل رئیلٹی (VR) سسٹمز میں۔ خود مختار ڈرائیونگ سسٹمز میں، کم تاخیر حقیقی وقت میں آبجیکٹ کا پتہ لگانے، پیدل چلنے والوں کی شناخت، لین کا پتہ لگانے، اور ٹریفک کے نشان کی شناخت کے لیے ضروری ہے تاکہ حفاظت سے سمجھوتہ نہ کیا جا سکے۔ خود مختار ڈرائیونگ سسٹمز کو عام طور پر پتہ لگانے سے لے کر اصل کارروائی تک 150ms سے بھی کم وقفہ درکار ہوتا ہے۔ اسی طرح، مینوفیکچرنگ میں، کم تاخیر حقیقی وقت میں خرابی کا پتہ لگانے، بے ضابطگی کی شناخت کے لیے ضروری ہے، اور روبوٹک رہنمائی کا انحصار کم تاخیر والے ویڈیو اینالیٹکس پر ہوتا ہے تاکہ موثر آپریشن کو یقینی بنایا جا سکے اور پروڈکشن ڈاؤن ٹائم کو کم سے کم کیا جا سکے۔
عام طور پر، ویڈیو اینالیٹکس ایپلیکیشن میں تاخیر کے تین اجزاء ہوتے ہیں (شکل 3):
- ڈیٹا کیپچر لیٹینسی وہ وقت ہے جو کیمرے کے سینسر سے ویڈیو فریم کیپچر کرنے سے لے کر پروسیسنگ کے لیے تجزیاتی نظام میں فریم کی دستیابی تک ہوتا ہے۔ آپ تیز رفتار سینسر اور کم لیٹنسی پروسیسر والے کیمرہ کا انتخاب کرکے، زیادہ سے زیادہ فریم ریٹ منتخب کرکے، اور موثر ویڈیو کمپریشن فارمیٹس کا استعمال کرکے اس تاخیر کو بہتر بنا سکتے ہیں۔
- ڈیٹا کی منتقلی میں تاخیر کیپچرڈ اور کمپریسڈ ویڈیو ڈیٹا کا کیمرے سے کنارے والے آلات یا مقامی سرورز تک سفر کرنے کا وقت ہے۔ اس میں نیٹ ورک پروسیسنگ میں تاخیر شامل ہے جو ہر اختتامی نقطہ پر ہوتی ہے۔
- ڈیٹا پروسیسنگ لیٹنسی سے مراد ایج ڈیوائسز کے ویڈیو پروسیسنگ کے کاموں کو انجام دینے کا وقت ہے جیسے کہ فریم ڈیکمپریشن اور اینالیٹکس الگورتھم (مثلاً موشن پریڈیکشن پر مبنی آبجیکٹ ٹریکنگ، چہرے کی شناخت)۔ جیسا کہ پہلے بتایا گیا ہے، پروسیسنگ میں تاخیر ان ایپلی کیشنز کے لیے اور بھی زیادہ اہم ہے جنہیں ہر ویڈیو فریم کے لیے ایک سے زیادہ AI ماڈلز چلانے چاہئیں۔
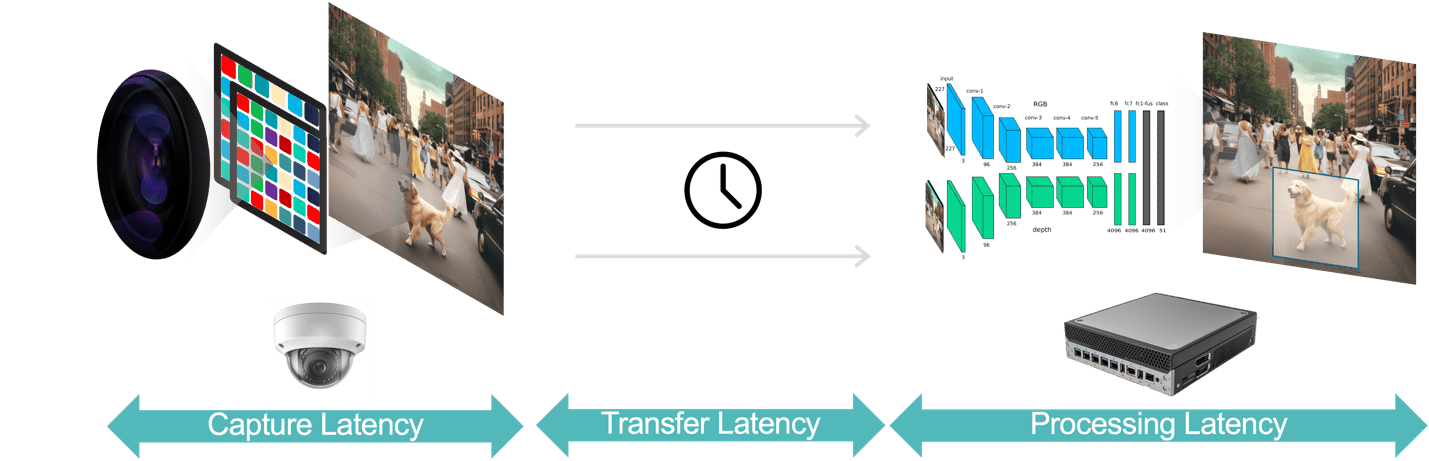
تصویر 3۔ ویڈیو اینالیٹکس پائپ لائن ڈیٹا کیپچر، ڈیٹا ٹرانسفر اور ڈیٹا پروسیسنگ پر مشتمل ہے۔
ڈیٹا پروسیسنگ لیٹینسی کو ایک AI ایکسلریٹر کا استعمال کرتے ہوئے ایک فن تعمیر کے ساتھ بہتر بنایا جا سکتا ہے جس میں ڈیٹا کی نقل و حرکت کو پورے چپ میں اور کمپیوٹ اور میموری کے درجہ بندی کی مختلف سطحوں کے درمیان کم سے کم کرنے کے لیے ڈیزائن کیا گیا ہے۔ نیز، تاخیر اور نظام کی سطح کی کارکردگی کو بہتر بنانے کے لیے، فن تعمیر کو ماڈلز کے درمیان صفر (یا صفر کے قریب) سوئچنگ ٹائم کو سپورٹ کرنا چاہیے، تاکہ ملٹی ماڈل ایپلی کیشنز کو بہتر طریقے سے سپورٹ کیا جا سکے جن پر ہم نے پہلے بات کی تھی۔ بہتر کارکردگی اور تاخیر دونوں کا ایک اور عنصر الگورتھمک لچک سے متعلق ہے۔ دوسرے لفظوں میں، کچھ فن تعمیرات صرف مخصوص AI ماڈلز پر بہترین رویے کے لیے بنائے گئے ہیں، لیکن تیزی سے بدلتے ہوئے AI ماحول کے ساتھ، اعلیٰ کارکردگی اور بہتر درستگی کے لیے نئے ماڈلز ظاہر ہو رہے ہیں جیسا کہ ہر دوسرے دن لگتا ہے۔ لہذا، ماڈل ٹوپولوجی، آپریٹرز اور سائز پر کوئی عملی پابندی کے بغیر ایک کنارے AI پروسیسر کا انتخاب کریں۔
ایک کنارے AI آلات میں کارکردگی کو زیادہ سے زیادہ کرنے میں بہت سے عوامل پر غور کیا جانا چاہئے جس میں کارکردگی اور تاخیر کی ضروریات اور سسٹم اوور ہیڈ شامل ہیں۔ ایک کامیاب حکمت عملی کو ایس او سی کے اے آئی انجن میں میموری اور کارکردگی کی حدود کو دور کرنے کے لیے ایک بیرونی AI ایکسلریٹر پر غور کرنا چاہیے۔
سی ایچ چی ایک کامیاب پروڈکٹ مارکیٹنگ اور مینجمنٹ ایگزیکٹو ہے، Chee کو سیمی کنڈکٹر انڈسٹری میں مصنوعات اور حل کو فروغ دینے کا وسیع تجربہ ہے، جس میں انٹرپرائز اور صارفین سمیت متعدد مارکیٹوں کے لیے وژن پر مبنی AI، کنیکٹیویٹی اور ویڈیو انٹرفیس پر توجہ مرکوز کی گئی ہے۔ ایک کاروباری شخص کے طور پر، Chee نے دو ویڈیو سیمی کنڈکٹر اسٹارٹ اپس کی مشترکہ بنیاد رکھی جو ایک پبلک سیمی کنڈکٹر کمپنی نے حاصل کی تھیں۔ Chee نے مصنوعات کی مارکیٹنگ ٹیموں کی قیادت کی اور ایک چھوٹی ٹیم کے ساتھ کام کرنے سے لطف اندوز ہوتا ہے جو بہترین نتائج حاصل کرنے پر توجہ مرکوز کرتی ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- : ہے
- : ہے
- : نہیں
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- کی صلاحیت
- مسرع
- ایکسلریٹر
- تک رسائی حاصل
- تک رسائی حاصل
- ایڈجسٹ کریں
- پورا
- درستگی
- حصول
- حاصل
- حاصل کرتا ہے
- کے پار
- عمل
- فعال
- اصل
- انہوں نے مزید کہا
- ایڈیشنل
- اپنایا
- اعلی درجے کی
- کے بعد
- پھر
- AI
- اے آئی انجن
- اے آئی ماڈلز
- الگورتھم
- یلگوردمز
- تمام
- بھی
- ہمیشہ
- an
- تجزیہ
- تجزیاتی
- تجزیہ
- اور
- بے ضابطگی کا پتہ لگانا
- ایک اور
- درخواست
- ایپلی کیشنز
- نقطہ نظر
- فن تعمیر
- کیا
- AS
- منسلک
- At
- خود کار طریقے سے
- میشن
- خود مختار
- خود مختاری سے
- دستیابی
- دستیاب
- سے اجتناب
- کی بنیاد پر
- بنیاد
- BE
- کیونکہ
- ہو جاتا ہے
- رہا
- اس سے پہلے
- کیا جا رہا ہے
- معیار
- بہتر
- کے درمیان
- دونوں
- باکس
- باکس
- تعمیر میں
- بس
- مصروف
- لیکن
- by
- کیمرہ
- کیمروں
- کر سکتے ہیں
- صلاحیتوں
- صلاحیت
- قبضہ
- پر قبضہ کر لیا
- گرفتاری
- ہوشیار
- کیس
- مقدمات
- چیلنج
- تبدیل کرنے
- چپ
- چپس
- منتخب کریں
- طبقے
- بادل
- رنگ
- آنے والے
- کمپنی کے
- مقابلہ
- مکمل
- اجزاء
- سمجھوتہ
- حساب
- کمپیوٹیشنل
- کمپیوٹنگ
- کمپیوٹر
- کمپیوٹر ویژن
- کمپیوٹر وژن ایپلی کیشنز
- آپکا اعتماد
- ترتیب
- رابطہ
- اس کے نتیجے میں
- غور کریں
- غور
- سمجھا
- پر غور
- مشتمل
- رکاوٹوں
- صارفین
- پر مشتمل ہے
- پر مشتمل ہے
- مسلسل
- مسلسل
- تبادلوں سے
- سکتا ہے
- CPU
- اہم
- گاہک
- اعداد و شمار
- ڈیٹا پروسیسنگ
- دن
- وقف
- تاخیر
- تاخیر
- نجات
- ڈیلیور
- انحصار
- منحصر ہے
- تعینات
- تعینات
- بیان کیا
- ڈیزائن
- پتہ چلا
- کھوج
- اس بات کا تعین
- ڈویلپرز
- کے الات
- فرق
- براہ راست
- بات چیت
- دکھائیں
- ٹائم ٹائم
- ڈرائیونگ
- دو
- متحرک طور پر
- e
- ہر ایک
- اس سے قبل
- آسانی سے
- ایج
- اثر
- تاثیر
- استعداد کار
- کارکردگی
- ہنر
- یا تو
- سرایت کرنا
- آخر
- آخر سے آخر تک
- انجن
- انجن
- بڑھانے کے
- کو یقینی بنانے کے
- انٹرپرائز
- پوری
- ٹھیکیدار
- ماحولیات
- ضروری
- اندازے کے مطابق
- اندازہ
- بھی
- ہر کوئی
- تیار ہوتا ہے
- مثال کے طور پر
- حد سے تجاوز
- عملدرآمد
- پھانسی
- ایگزیکٹو
- توقع ہے
- تجربہ
- تجربات
- وسیع
- وسیع تجربہ
- بیرونی
- چہرہ
- چہرے کی شناخت
- عنصر
- عوامل
- فیکٹری
- فاسٹ
- نمایاں کریں
- کھانا کھلانا
- میدان
- اعداد و شمار
- فنگر پرنٹ
- پہلا
- لچک
- توجہ مرکوز
- توجہ مرکوز
- کے لئے
- فارمیٹ
- فریم
- سے
- تقریب
- فعالیت
- افعال
- مزید برآں
- مستقبل
- حاصل کرنا
- کھیل
- گیمنگ
- گیمنگ کا تجربہ
- جنرل
- پیدا
- پیدا
- بے لوث
- Go
- GPU
- GPUs
- عظیم
- زیادہ سے زیادہ
- بڑھتے ہوئے
- ترقی
- رہنمائی
- ہارڈ ویئر
- ہے
- لہذا
- یہاں
- درجہ بندی
- ہائی
- اعلی
- میزبان
- HTTPS
- i
- شناخت
- if
- تصویر
- اثر
- اہم
- عائد کیا
- کو بہتر بنانے کے
- بہتر
- in
- دیگر میں
- شامل ہیں
- سمیت
- اضافہ
- اضافہ
- صنعتوں
- صنعت
- شروع کرتا ہے
- ان پٹ
- کے اندر
- بصیرت
- ضم
- انٹیل
- انٹرفیس
- انٹرفیسز
- میں
- شامل
- شامل ہے
- بے شک
- آئی ایس پی
- IT
- میں
- KDnuggets
- لیبل
- نہیں
- لین
- بڑے
- تاخیر
- چھوڑ کر
- قیادت
- کم
- سطح
- لائبریریوں
- کی طرح
- حد کے
- حدود
- لمیٹڈ
- لنکڈ
- مقامی
- کھو
- لو
- کم
- انتظام
- انتظام
- مینوفیکچرنگ
- بہت سے
- مارکیٹنگ
- Markets
- زیادہ سے زیادہ
- زیادہ سے زیادہ
- مئی..
- مطلب
- اقدامات
- سے ملو
- یاد داشت
- ذکر کیا
- شاید
- یاد آیا
- ماڈل
- ماڈل
- ماڈیول
- نگرانی
- زیادہ
- سب سے زیادہ
- تحریک
- تحریک
- ایک سے زیادہ
- ضروری
- ہزارہا
- قریب
- ضروریات
- نیٹ ورک
- عصبی
- عصبی نیٹ ورک
- نئی
- اگلے
- نہیں
- اعتراض
- آبجیکٹ کا پتہ لگانا
- واقع
- of
- اکثر
- on
- ایک بار
- ایک
- صرف
- OpenCV
- آپریشن
- آپریشنل
- آپریٹرز
- مخالفت کی
- زیادہ سے زیادہ
- اصلاح کے
- کی اصلاح کریں
- اصلاح
- اصلاح
- or
- دیگر
- باہر
- پیداوار
- پر
- مجموعی طور پر
- پر قابو پانے
- متوازی
- پیرامیٹرز
- خاص طور پر
- فی
- انجام دینے کے
- کارکردگی
- کارکردگی
- کارکردگی کا مظاہرہ
- کارکردگی کا مظاہرہ
- پائپ لائن
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیلیں
- پوائنٹ
- پوزیشن
- پروسیسنگ
- عملی
- کی پیشن گوئی
- عمل
- عملدرآمد
- پروسیسنگ
- پروسیسر
- پروسیسرز
- مصنوعات
- پیداوار
- حاصل
- کو فروغ دینے
- فراہم
- عوامی
- رینج
- لے کر
- تیزی سے
- میں تیزی سے
- شرح
- قیمتیں
- خام
- خام ڈیٹا
- اصلی
- اصل وقت
- حقیقت
- تسلیم
- کو کم
- مراد
- کی ضرورت
- ضرورت
- ضرورت
- ضروریات
- کی ضرورت ہے
- قرارداد
- وسائل
- قبول
- پابندی
- نتیجہ
- نتائج کی نمائش
- روبوٹکس
- کردار
- رن
- چل رہا ہے
- چلتا ہے
- سیفٹی
- اسی
- اسکیل ایبلٹی
- پیمانے
- پیمانہ ai
- سکیلنگ
- منظر
- اسکور
- ہموار
- دوسری
- سیکشن
- دیکھنا
- لگتا ہے
- منتخب
- سیمکولیٹر
- مقرر
- سیکنڈ اور
- مشترکہ
- خریداری
- ہونا چاہئے
- دکھایا گیا
- سائن ان کریں
- اشارہ
- اسی طرح
- بعد
- ایک
- سائز
- چھوٹے
- ہوشیار
- حل
- حل
- حل
- حل کرتا ہے
- کچھ
- کچھ
- خلا
- مخصوص
- شروع اپ
- مراحل
- ذخیرہ
- حکمت عملیوں
- حکمت عملی
- سٹریم
- اسٹریمز
- کامیاب
- اس طرح
- کافی
- حمایت
- دمن
- نگرانی
- کے نظام
- سسٹمز
- لے لو
- لیتا ہے
- کاموں
- ٹیم
- ٹیموں
- ٹیکنالوجی
- ٹیکنالوجی
- شرائط
- سے
- کہ
- ۔
- مستقبل
- ان
- تو
- وہاں.
- لہذا
- یہ
- وہ
- اس
- ان
- تین
- کے ذریعے
- تھرو پٹ
- وقت
- اوقات
- کرنے کے لئے
- ٹاپس
- کل
- ٹریک
- ٹریکنگ
- ٹریفک
- منتقل
- منتقلی
- تبدیل
- سفر
- سچ
- دو
- عام طور پر
- آخر میں
- قابل نہیں
- سمجھ
- یونٹ
- یونٹس
- استعمال
- USB
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- استعمال
- کا استعمال کرتے ہوئے
- عام طور پر
- استعمال کرنا۔
- اقدار
- مختلف اقسام کے
- مختلف
- ویڈیو
- لنک
- مجازی
- مجازی حقیقت
- نقطہ نظر
- اہم
- vr
- راستہ..
- we
- تھے
- کیا
- چاہے
- جس
- بڑے پیمانے پر
- گے
- ساتھ
- بغیر
- الفاظ
- کام کر
- گا
- X
- پیداوار
- Yolo کی
- آپ
- اور
- زیفیرنیٹ
- صفر







