پوری دنیا کی تنظیمیں - منافع اور غیر منفعتی دونوں - بہتر کاروباری کارکردگی کے لیے ڈیٹا اینالیٹکس کا فائدہ اٹھانے پر غور کر رہی ہیں۔ ایک سے نتائج میک کینسی سروے اس بات کی نشاندہی کرتے ہیں کہ ڈیٹا سے چلنے والی تنظیمیں گاہک حاصل کرنے کے امکانات 23 گنا زیادہ، صارفین کو برقرار رکھنے کے امکانات چھ گنا، اور 19 گنا زیادہ منافع بخش ہیں [1]۔ MIT کی طرف سے تحقیق پتہ چلا کہ ڈیجیٹل طور پر بالغ فرم اپنے ساتھیوں کے مقابلے میں 26 فیصد زیادہ منافع بخش ہیں [2]۔ لیکن بہت سی کمپنیاں، ڈیٹا سے بھرپور ہونے کے باوجود، کاروباری ضروریات، دستیاب صلاحیتوں اور وسائل کے درمیان متضاد ترجیحات کی وجہ سے ڈیٹا اینالیٹکس کو نافذ کرنے کے لیے جدوجہد کرتی ہیں۔ گارٹنر کی تحقیق پتہ چلا کہ 85% سے زیادہ ڈیٹا اور تجزیاتی منصوبے ناکام ہو جاتے ہیں [3] اور a مشترکہ رپورٹ IBM اور Carnegie Melon سے پتہ چلتا ہے کہ کسی بھی تنظیم میں 90% ڈیٹا کبھی بھی کسی اسٹریٹجک مقصد کے لیے کامیابی کے ساتھ استعمال نہیں ہوتا ہے [4]۔
اس پس منظر کے ساتھ، ہم "ڈیٹا اینالیٹکس فیبرک (DAF)" تصور متعارف کراتے ہیں، ایک ماحولیاتی نظام یا ایک ڈھانچے کے طور پر جو ڈیٹا اینالیٹکس کو مؤثر طریقے سے کام کرنے کے قابل بناتا ہے (a) کاروباری ضروریات یا مقاصد، (b) دستیاب صلاحیتیں جیسے کہ لوگ/مہارتیں ، عمل، ثقافت، ٹیکنالوجی، بصیرت، فیصلہ سازی کی قابلیت، اور بہت کچھ، اور (c) وسائل (یعنی، وہ اجزاء جن کی کاروبار کو چلانے کے لیے ضرورت ہوتی ہے)۔
ڈیٹا اینالیٹکس فیبرک کو متعارف کرانے کا ہمارا بنیادی مقصد اس بنیادی سوال کا جواب دینا ہے: "فیصلہ کرنے کے قابل نظام کو مؤثر طریقے سے بنانے کے لیے کس چیز کی ضرورت ہے۔ ڈیٹا سائنس کاروباری کارکردگی کی پیمائش اور بہتری کے لیے الگورتھم؟ ڈیٹا اینالیٹکس فیبرک اور اس کے پانچ کلیدی مظاہر ذیل میں دکھائے گئے ہیں اور ان پر تبادلہ خیال کیا گیا ہے۔
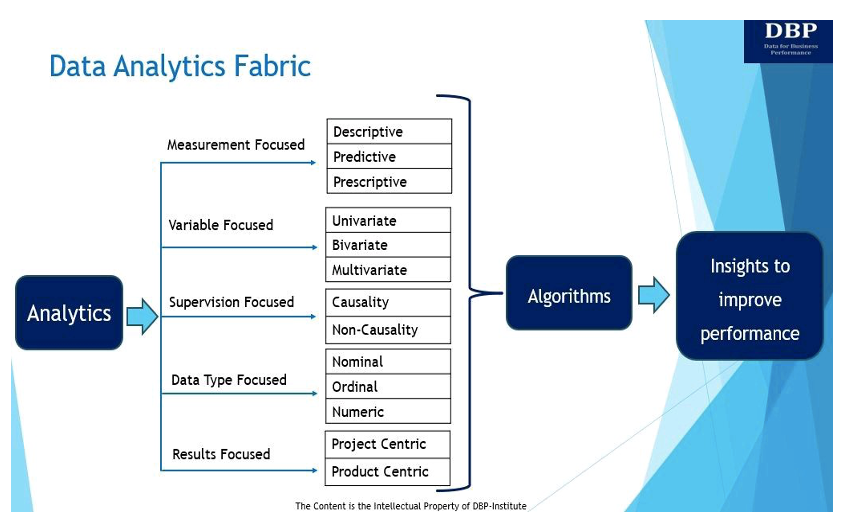
1. پیمائش پر مرکوز
اس کے بنیادی طور پر، تجزیات بصیرت کی پیمائش اور کاروباری کارکردگی کو بہتر بنانے کے لیے ڈیٹا کے استعمال کے بارے میں ہے [5]۔ کاروباری کارکردگی کی پیمائش اور بہتری کے لیے تجزیات کی تین اہم اقسام ہیں:
- وضاحتی تجزیات۔ سوال پوچھتا ہے، "کیا ہوا؟" وضاحتی تجزیات کا استعمال تاریخی اعداد و شمار کا تجزیہ کرنے کے لیے کیا جاتا ہے تاکہ نمونوں، رجحانات، اور تعلقات کو تلاش کرنے، ہم آہنگی اور اعداد و شمار کے تجزیے کی تکنیک کا استعمال کرتے ہوئے شناخت کیا جا سکے۔ تحقیقی ڈیٹا کے تجزیہ کی تکنیک ڈیٹا سیٹوں کا تجزیہ اور خلاصہ کرتی ہے۔ ایسوسی ایٹیو وضاحتی تجزیہ متغیر کے درمیان تعلق کی وضاحت کرتا ہے۔ سیمپل ڈیٹا سیٹ کی بنیاد پر ایک بڑی آبادی کے بارے میں رجحانات کا اندازہ لگانے یا نتیجہ اخذ کرنے کے لیے inferential وضاحتی ڈیٹا کا تجزیہ استعمال کیا جاتا ہے۔
- پیشین گوئی کے تجزیات سوال کا جواب دیتے ہوئے دیکھتا ہے، "کیا ہوگا؟" بنیادی طور پر، پیش گوئی کرنے والے تجزیات مستقبل کے رجحانات اور واقعات کی پیشن گوئی کے لیے ڈیٹا کو استعمال کرنے کا عمل ہے۔ پیشن گوئی کا تجزیہ دستی طور پر کیا جا سکتا ہے (عام طور پر تجزیہ کار پر مبنی پیشن گوئی تجزیات کے طور پر جانا جاتا ہے) یا استعمال کرتے ہوئے مشین لرننگ الگورتھم (ڈیٹا پر مبنی پیشن گوئی کے تجزیات کے نام سے بھی جانا جاتا ہے)۔ کسی بھی طرح، تاریخی اعداد و شمار مستقبل کی پیشن گوئی کرنے کے لئے استعمال کیا جاتا ہے.
- وضاحتی تجزیات۔ سوال کا جواب دینے میں مدد کرتا ہے، "ہم اسے کیسے بنا سکتے ہیں؟" بنیادی طور پر، نسخے کے تجزیات اصلاح اور نقلی تکنیک کا استعمال کرتے ہوئے آگے بڑھنے کے لیے بہترین طریقہ کار کی تجویز کرتے ہیں۔ عام طور پر، پیش گوئی کرنے والے تجزیے اور نسخے کے تجزیات ایک ساتھ چلتے ہیں کیونکہ پیش گوئی کرنے والے تجزیات ممکنہ نتائج تلاش کرنے میں مدد کرتے ہیں، جب کہ نسخے کے تجزیات ان نتائج کو دیکھتے ہیں اور مزید اختیارات تلاش کرتے ہیں۔
2. متغیر مرکوز
دستیاب متغیرات کی تعداد کی بنیاد پر ڈیٹا کا تجزیہ بھی کیا جا سکتا ہے۔ اس سلسلے میں، متغیرات کی تعداد کی بنیاد پر، ڈیٹا اینالیٹکس کی تکنیک غیر متغیر، دو متغیر، یا ملٹی ویریٹ ہو سکتی ہے۔
- غیر متغیر تجزیہ: غیر متغیر تجزیہ میں مرکزیت کے اقدامات (مطلب، میڈین، موڈ، اور اسی طرح) اور تغیرات (معیاری انحراف، معیاری غلطی، تغیر، اور اسی طرح) کے اقدامات کا استعمال کرتے ہوئے ایک واحد متغیر میں موجود پیٹرن کا تجزیہ کرنا شامل ہے۔
- متواتر تجزیہ: دو متغیرات ہیں جن میں تجزیہ کا تعلق وجہ اور دو متغیرات کے درمیان تعلق سے ہے۔ یہ دو متغیرات ایک دوسرے پر منحصر یا آزاد ہو سکتے ہیں۔ ارتباط کی تکنیک سب سے زیادہ استعمال شدہ بائیوریٹیٹ تجزیہ تکنیک ہے۔
- کثیر الجہتی تجزیہ: یہ تکنیک دو سے زیادہ متغیرات کے تجزیہ کے لیے استعمال ہوتی ہے۔ ملٹی ویریٹ سیٹنگ میں، ہم عام طور پر پیشین گوئی کرنے والے تجزیاتی میدان میں کام کرتے ہیں اور زیادہ تر معروف مشین لرننگ (ML) الگورتھم جیسے لکیری ریگریشن، لاجسٹک ریگریشن، ریگریشن ٹریز، سپورٹ ویکٹر مشینیں، اور نیورل نیٹ ورکس کو عام طور پر ملٹی ویریٹ پر لاگو کیا جاتا ہے۔ ترتیب
3. نگرانی پر مرکوز
تیسری قسم کا ڈیٹا اینالیٹکس فیبرک ان پٹ ڈیٹا یا آزاد متغیر ڈیٹا کی تربیت سے متعلق ہے جس پر کسی خاص آؤٹ پٹ (یعنی منحصر متغیر) کے لیے لیبل لگایا گیا ہے۔ بنیادی طور پر، آزاد متغیر وہی ہے جسے تجربہ کار کنٹرول کرتا ہے۔ منحصر متغیر وہ متغیر ہے جو آزاد متغیر کے جواب میں تبدیل ہوتا ہے۔ نگرانی پر مرکوز DAF دو اقسام میں سے ایک ہو سکتا ہے۔
- وجہ: لیبل لگا ڈیٹا، چاہے خود بخود بنایا گیا ہو یا دستی طور پر، زیر نگرانی سیکھنے کے لیے ضروری ہے۔ لیبل لگا ڈیٹا کسی کو ایک منحصر متغیر کی واضح طور پر وضاحت کرنے کی اجازت دیتا ہے، اور پھر یہ ایک AI/ML ٹول بنانے کے لیے پیشین گوئی کرنے والے تجزیاتی الگورتھم کا معاملہ ہے جو لیبل (انحصار متغیر) اور آزاد متغیر کے سیٹ کے درمیان تعلق قائم کرے گا۔ حقیقت یہ ہے کہ ہمارے پاس ایک منحصر متغیر کے تصور اور آزاد متغیرات کے مجموعے کے درمیان ایک الگ حد بندی ہے، ہم خود کو اس تعلق کی بہترین وضاحت کرنے کے لیے "وجہ" کی اصطلاح متعارف کرانے کی اجازت دیتے ہیں۔
- عدم سبب: جب ہم اپنے طول و عرض کے طور پر "نگرانی پر مرکوز" کی نشاندہی کرتے ہیں، تو ہمارا مطلب "نگرانی کی غیر موجودگی" بھی ہے، اور یہ غیر کارآمد ماڈلز کو بحث میں لاتا ہے۔ غیر کارگر ماڈلز ذکر کے مستحق ہیں کیونکہ انہیں لیبل والے ڈیٹا کی ضرورت نہیں ہے۔ یہاں بنیادی تکنیک کلسٹرنگ ہے، اور سب سے زیادہ مقبول طریقے k-Means اور Hierarchical Clustering ہیں۔
4. ڈیٹا کی قسم فوکسڈ
اعداد و شمار کے تجزیات کے تانے بانے کی یہ جہت یا مظہر تین مختلف قسم کے ڈیٹا متغیرات پر مرکوز ہے جو آزاد اور منحصر متغیر دونوں سے متعلق ہیں جو بصیرت حاصل کرنے کے لیے ڈیٹا اینالیٹکس تکنیک میں استعمال ہوتے ہیں۔
- برائے نام اعداد و شمار ڈیٹا کو لیبل لگانے یا درجہ بندی کرنے کے لیے استعمال کیا جاتا ہے۔ اس میں عددی قدر شامل نہیں ہے اور اس لیے برائے نام اعداد و شمار کے ساتھ کوئی شماریاتی حساب ممکن نہیں ہے۔ برائے نام ڈیٹا کی مثالیں جنس، پروڈکٹ کی تفصیل، گاہک کا پتہ اور اس طرح کے ہیں۔
- عام یا درجہ بندی کا ڈیٹا اقدار کی ترتیب ہے، لیکن ہر ایک کے درمیان فرق واقعی معلوم نہیں ہے۔ یہاں کی عام مثالیں مارکیٹ کیپٹلائزیشن، وینڈر کی ادائیگی کی شرائط، کسٹمر کے اطمینان کے اسکور، ترسیل کی ترجیح، وغیرہ کی بنیاد پر کمپنیوں کی درجہ بندی کرنا ہیں۔
- عددی ڈیٹا کسی تعارف کی ضرورت نہیں ہے اور قیمت میں عددی ہے۔ یہ متغیرات ڈیٹا کی سب سے بنیادی اقسام ہیں جن کا استعمال ہر قسم کے الگورتھم کو ماڈل کرنے کے لیے کیا جا سکتا ہے۔
5. نتائج پر مرکوز
اس قسم کا ڈیٹا اینالیٹکس فیبرک ان طریقوں کو دیکھتا ہے جن میں تجزیات سے حاصل کردہ بصیرت سے کاروباری قدر فراہم کی جا سکتی ہے۔ دو طریقے ہیں جن میں تجزیات کے ذریعے کاروباری قدر کو آگے بڑھایا جا سکتا ہے، اور وہ مصنوعات یا منصوبوں کے ذریعے ہیں۔ اگرچہ مصنوعات کو صارف کے تجربے اور سافٹ ویئر انجینئرنگ کے ارد گرد اضافی اثرات کو حل کرنے کی ضرورت ہوسکتی ہے، ماڈل کو اخذ کرنے کے لیے کی جانے والی ماڈلنگ کی مشق پروجیکٹ اور مصنوعات دونوں میں یکساں ہوگی۔
- A ڈیٹا اینالیٹکس پروڈکٹ کاروبار کی طویل مدتی ضروریات کو پورا کرنے کے لیے دوبارہ قابل استعمال ڈیٹا اثاثہ ہے۔ یہ متعلقہ ڈیٹا ذرائع سے ڈیٹا اکٹھا کرتا ہے، ڈیٹا کے معیار کو یقینی بناتا ہے، اس پر کارروائی کرتا ہے، اور اسے ہر اس شخص کے لیے قابل رسائی بناتا ہے جسے اس کی ضرورت ہو۔ پروڈکٹس کو عام طور پر شخصیات کے لیے ڈیزائن کیا جاتا ہے اور ان میں زندگی کے متعدد مراحل یا تکرار ہوتے ہیں جن پر پروڈکٹ کی قدر کا احساس ہوتا ہے۔
- A ڈیٹا اینالیٹکس پروجیکٹ کسی خاص یا منفرد کاروباری ضرورت کو پورا کرنے کے لیے ڈیزائن کیا گیا ہے اور اس کا ایک متعین یا تنگ صارف بنیاد یا مقصد ہے۔ بنیادی طور پر، ایک پروجیکٹ ایک عارضی کوشش ہے جس کا مقصد ایک مقررہ دائرہ کار کے لیے بجٹ کے اندر اور وقت پر حل فراہم کرنا ہے۔
آنے والے سالوں میں دنیا کی معیشت ڈرامائی طور پر تبدیل ہو جائے گی کیونکہ تنظیمیں بصیرت حاصل کرنے اور کاروباری کارکردگی کی پیمائش اور بہتر بنانے کے لیے فیصلے کرنے کے لیے ڈیٹا اور تجزیات کا تیزی سے استعمال کریں گی۔ میکنسی پتہ چلا کہ بصیرت سے چلنے والی کمپنیاں EBITDA (سود، ٹیکس، فرسودگی، اور معافی سے پہلے کی آمدنی) میں 25% تک اضافہ کرتی ہیں [5]۔ تاہم، بہت سی تنظیمیں کاروباری نتائج کو بہتر بنانے کے لیے ڈیٹا اور تجزیات کا فائدہ اٹھانے میں کامیاب نہیں ہیں۔ لیکن ڈیٹا اینالیٹکس فراہم کرنے کا کوئی ایک معیاری طریقہ یا طریقہ نہیں ہے۔ ڈیٹا اینالیٹکس سلوشنز کی تعیناتی یا نفاذ کا انحصار کاروباری مقاصد، صلاحیتوں اور وسائل پر ہوتا ہے۔ یہاں زیر بحث ڈی اے ایف اور اس کے پانچ مظاہر تجزیات کو کاروباری ضروریات، دستیاب صلاحیتوں اور وسائل کی بنیاد پر مؤثر طریقے سے تعینات کرنے کے قابل بنا سکتے ہیں۔
حوالہ جات
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-more-profitable-than-their-peers/
- gartner.com/en/newsroom/press-releases/2018-02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- ساؤتھکل، پرشانت، "تجزیہ کے بہترین طرز عمل"، تکنیک، 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ آٹوموٹو / ای وی، کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- چارٹ پرائم۔ ChartPrime کے ساتھ اپنے ٹریڈنگ گیم کو بلند کریں۔ یہاں تک رسائی حاصل کریں۔
- بلاک آفسیٹس۔ ماحولیاتی آفسیٹ ملکیت کو جدید بنانا۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- : ہے
- : ہے
- : نہیں
- $UP
- 1
- 19
- 23
- a
- ہمارے بارے میں
- قابل رسائی
- حاصل
- عمل
- ایڈیشنل
- پتہ
- AI / ML
- یلگورتم
- یلگوردمز
- تمام
- کی اجازت
- کی اجازت دیتا ہے
- بھی
- قرابت کاری
- an
- تجزیہ
- تجزیاتی
- تجزیے
- تجزیہ کیا
- تجزیہ
- اور
- جواب
- کوئی بھی
- کسی
- اطلاقی
- نقطہ نظر
- کیا
- میدان
- ارد گرد
- AS
- اثاثے
- At
- خود کار طریقے سے
- دستیاب
- b
- پس منظر
- بیس
- کی بنیاد پر
- بنیادی
- بنیادی طور پر
- BE
- کیونکہ
- رہا
- اس سے پہلے
- کیا جا رہا ہے
- نیچے
- BEST
- کے درمیان
- دونوں
- لاتا ہے
- بجٹ
- تعمیر
- کاروبار
- کاروبار کی کارکردگی
- لیکن
- by
- کر سکتے ہیں
- صلاحیتوں
- سرمایہ کاری
- درجہ بندی
- کیونکہ
- مرکز
- تبدیلیاں
- واضح طور پر
- clustering کے
- جمع کرتا ہے
- COM
- آنے والے
- کامن
- عام طور پر
- کمپنیاں
- اجزاء
- تصور
- نتیجہ اخذ
- منعقد
- متضاد
- کنٹرول
- کور
- باہمی تعلق۔
- سکتا ہے
- کورس
- ثقافت
- گاہک
- گاہکوں کی اطمینان
- گاہکوں
- اعداد و شمار
- ڈیٹا تجزیہ
- ڈیٹا تجزیات
- ڈیٹا کی معیار
- ڈیٹا سیٹ
- ڈیٹا سیٹ
- اعداد و شمار پر مبنی ہے
- ڈیٹاورسٹی
- ڈیلز
- فیصلہ کرنا
- فیصلے
- وضاحت
- کی وضاحت
- نجات
- ڈیلیور
- ترسیل
- انحصار
- انحصار کرتا ہے
- تعینات
- تعیناتی
- فرسودگی
- اخذ کردہ
- تفصیل
- مستحق
- ڈیزائن
- کے باوجود
- انحراف
- اختلافات
- مختلف
- ڈیجیٹل
- طول و عرض
- بات چیت
- بحث
- مختلف
- do
- کرتا
- کیا
- ڈرامائی طور پر
- کارفرما
- دو
- e
- ہر ایک
- آمدنی
- EBITDA
- معیشت کو
- ماحول
- مؤثر طریقے
- یا تو
- کو چالو کرنے کے
- کے قابل بناتا ہے
- کوشش کریں
- انجنیئرنگ
- یقینی بناتا ہے
- خرابی
- ضروری
- واقعات
- مثال کے طور پر
- ورزش
- تجربہ
- وضاحت
- بیان کرتا ہے
- تحقیقی ڈیٹا کا تجزیہ
- کپڑے
- حقیقت یہ ہے
- FAIL
- مل
- نتائج
- پتہ ہے
- فرم
- پانچ
- توجہ مرکوز
- کے لئے
- فوربس
- پیشن گوئی
- آگے
- ملا
- سے
- تقریب
- بنیادی
- مستقبل
- گارٹنر
- جنس
- پیدا
- Go
- مقصد
- ہو
- ہوا
- ہے
- مدد کرتا ہے
- لہذا
- یہاں
- تاریخی
- تاہم
- HTTPS
- i
- IBM
- شناخت
- پر عملدرآمد
- نفاذ
- کو بہتر بنانے کے
- بہتر
- کو بہتر بنانے کے
- in
- اضافہ
- دن بدن
- آزاد
- اشارہ کرتے ہیں
- ان پٹ
- بصیرت
- ارادہ
- دلچسپی
- متعارف کرانے
- متعارف کرانے
- تعارف
- شامل
- شامل ہے
- IT
- تکرار
- میں
- کلیدی
- جانا جاتا ہے
- لیبل
- لیبل
- بڑے
- سیکھنے
- لیورنگنگ
- زندگی کا دورانیہ
- کی طرح
- امکان
- طویل مدتی
- تلاش
- دیکھنا
- مشین
- مشین لرننگ
- مشینیں
- مین
- بنا
- بناتا ہے
- دستی طور پر
- بہت سے
- مارکیٹ
- مارکیٹ کیپٹلائزیشن
- معاملہ
- عقلمند و سمجھدار ہو
- زیادہ سے زیادہ چوڑائی
- مئی..
- میکنسی
- مطلب
- پیمائش
- اقدامات
- ذکر
- طریقوں
- ایم ائی ٹی
- ML
- موڈ
- ماڈل
- ماڈلنگ
- ماڈل
- زیادہ
- سب سے زیادہ
- سب سے زیادہ مقبول
- منتقل
- ایک سے زیادہ
- ضرورت ہے
- ضروریات
- نیٹ ورک
- عصبی
- نیند نیٹ ورک
- کبھی نہیں
- نہیں
- غیر منفعتی
- تصور
- تعداد
- مقاصد
- of
- on
- ایک
- کام
- اصلاح کے
- آپشنز کے بھی
- or
- حکم
- تنظیم
- تنظیمیں
- دیگر
- ہمارے
- خود
- نتائج
- پیداوار
- پر
- خاص طور پر
- پاٹرن
- پیٹرن
- ادائیگی
- کارکردگی
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- مقبول
- آبادی
- ممکن
- ممکنہ
- پیشن گوئی
- پیشن گوئی
- پیش قیاسی تجزیہ
- پیش گوئی کے تجزیات
- حال (-)
- پرائمری
- ترجیح
- عمل
- عمل
- مصنوعات
- حاصل
- منافع
- منافع بخش
- منصوبے
- منصوبوں
- مقصد
- معیار
- سوال
- اثرات
- رینکنگ
- رینکنگ
- احساس ہوا
- واقعی
- تجویز ہے
- شمار
- رجعت
- متعلقہ
- تعلقات
- تعلقات
- متعلقہ
- رپورٹ
- کی ضرورت
- ضرورت
- وسائل
- جواب
- برقرار رکھنے
- قابل اعتماد
- کی اطمینان
- گنجائش
- اسکور
- خدمت
- مقرر
- سیٹ
- قائم کرنے
- دکھایا گیا
- شوز
- اسی طرح
- تخروپن
- ایک
- چھ
- So
- سافٹ ویئر کی
- سافٹ ویئر انجینئرنگ
- حل
- حل
- ماخذ
- ذرائع
- مراحل
- معیار
- شماریات
- حکمت عملی
- ساخت
- جدوجہد
- کامیاب
- کامیابی کے ساتھ
- اس طرح
- مختصر
- زیر نگرانی سیکھنے
- نگرانی
- حمایت
- کے نظام
- ٹیکس
- تکنیک
- ٹیکنالوجی
- عارضی
- اصطلاح
- شرائط
- سے
- کہ
- ۔
- دنیا
- ان
- تو
- وہاں.
- یہ
- وہ
- تھرڈ
- اس
- ان
- تین
- کے ذریعے
- وقت
- اوقات
- کرنے کے لئے
- مل کر
- کے آلے
- ٹریننگ
- تبدیل
- درخت
- رجحانات
- دو
- قسم
- اقسام
- عام طور پر
- منفرد
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- رکن کا
- صارف کا تجربہ
- کا استعمال کرتے ہوئے
- قیمت
- اقدار
- متغیر
- وینڈر
- راستہ..
- طریقوں
- we
- اچھی طرح سے جانا جاتا ہے
- جب
- چاہے
- جس
- جبکہ
- ڈبلیو
- گے
- ساتھ
- کے اندر
- دنیا
- دنیا کی
- گا
- سال
- زیفیرنیٹ