مصنف کی طرف سے تصویر
مشین لرننگ اور ڈیٹا سائنس پر بہت سے کورسز اور وسائل دستیاب ہیں، لیکن ڈیٹا انجینئرنگ پر بہت کم ہیں۔ اس سے کچھ سوالات اٹھتے ہیں۔ کیا یہ ایک مشکل میدان ہے؟ کیا یہ کم تنخواہ کی پیشکش کر رہا ہے؟ کیا اسے دوسرے ٹیک کرداروں کی طرح دلچسپ نہیں سمجھا جاتا؟ تاہم، حقیقت یہ ہے کہ بہت سی کمپنیاں فعال طور پر ڈیٹا انجینئرنگ کے ٹیلنٹ کی تلاش میں ہیں اور کافی تنخواہوں کی پیشکش کر رہی ہیں، بعض اوقات $200,000 USD سے بھی زیادہ ہوتی ہیں۔ ڈیٹا انجینئرز ڈیٹا پلیٹ فارمز کے معمار کے طور پر ایک اہم کردار ادا کرتے ہیں، ایسے بنیادی نظاموں کی ڈیزائننگ اور تعمیر کرتے ہیں جو ڈیٹا سائنسدانوں اور مشین لرننگ کے ماہرین کو مؤثر طریقے سے کام کرنے کے قابل بناتے ہیں۔
صنعت کے اس فرق کو دور کرتے ہوئے، DataTalkClub نے ایک تبدیلی اور مفت بوٹ کیمپ متعارف کرایا ہے،ڈیٹا انجینئرنگ زوم کیمپ" یہ کورس ابتدائی افراد یا پیشہ ور افراد کو بااختیار بنانے کے لیے ڈیزائن کیا گیا ہے جو کیرئیر کو تبدیل کرنا چاہتے ہیں، ڈیٹا انجینئرنگ میں ضروری مہارتوں اور عملی تجربے کے ساتھ۔
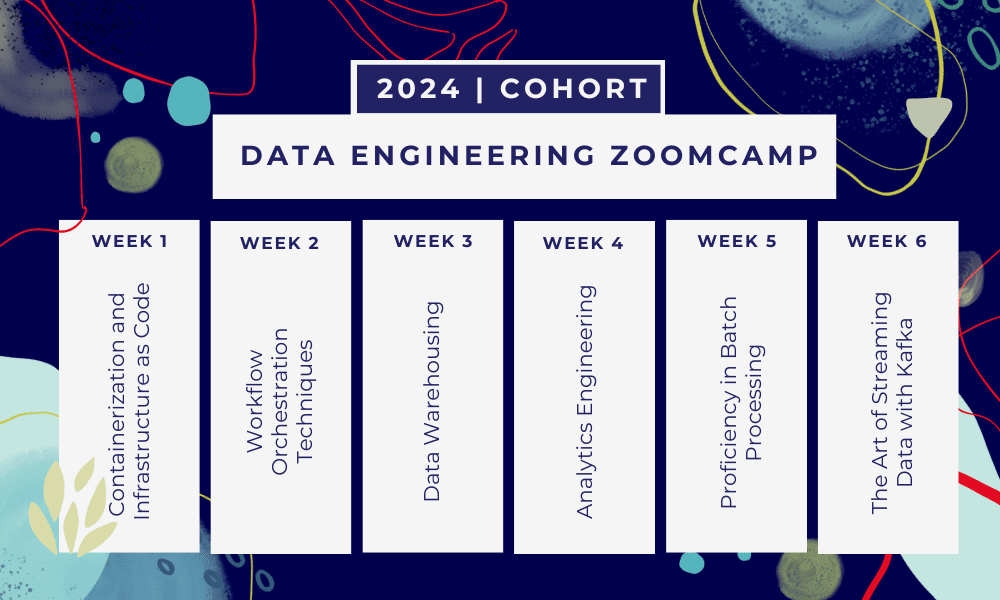
یہ ایک ہے 6 ہفتے کا بوٹ کیمپ جہاں آپ متعدد کورسز، پڑھنے کے مواد، ورکشاپس اور پروجیکٹس کے ذریعے سیکھیں گے۔ ہر ماڈیول کے اختتام پر، آپ کو ہوم ورک دیا جائے گا تاکہ آپ نے جو سیکھا ہے اس پر عمل کریں۔
- ہفتہ 1: GCP، Docker، Postgres، Terraform، اور ماحولیاتی سیٹ اپ کا تعارف۔
- ہفتہ 2: میج کے ساتھ ورک فلو آرکیسٹریشن۔
- ہفتہ 3: BigQuery کے ساتھ ڈیٹا ویئر ہاؤسنگ اور BigQuery کے ساتھ مشین لرننگ۔
- ہفتہ 4: ڈی بی ٹی، گوگل ڈیٹا اسٹوڈیو، اور میٹا بیس کے ساتھ تجزیاتی انجینئر۔
- ہفتہ 5: اسپارک کے ساتھ بیچ پروسیسنگ۔
- ہفتہ 6: کافکا کے ساتھ سلسلہ بندی۔
سے تصویر DataTalksClub/data-engineering-zoomcamp
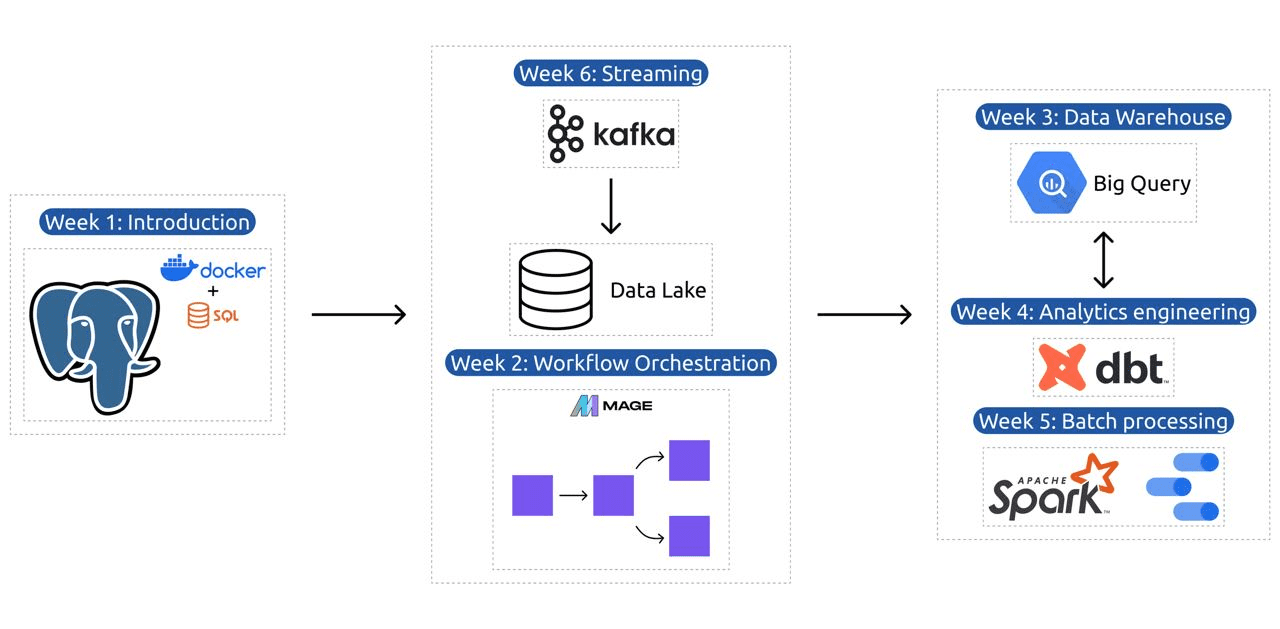
اس نصاب میں 6 ماڈیولز، 2 ورکشاپس، اور ایک پروجیکٹ ہے جس میں پیشہ ور ڈیٹا انجینئر بننے کے لیے درکار ہر چیز کا احاطہ کیا گیا ہے۔
ماڈیول 1: کوڈ کے طور پر کنٹینرائزیشن اور انفراسٹرکچر میں مہارت حاصل کرنا
اس ماڈیول میں، آپ ڈوکر اور پوسٹگریس کے بارے میں سیکھیں گے، بنیادی باتوں سے شروع ہو کر ڈیٹا پائپ لائنز بنانے، ڈاکر کے ساتھ پوسٹگریس چلانے، اور مزید بہت کچھ کے بارے میں تفصیلی سبق کے ذریعے آگے بڑھنا۔
اس ماڈیول میں ضروری ٹولز جیسے pgAdmin، Docker-compose، اور SQL ریفریشر موضوعات کا بھی احاطہ کیا گیا ہے، جس میں Docker نیٹ ورکنگ پر اختیاری مواد اور ونڈوز سب سسٹم لینکس کے صارفین کے لیے خصوصی واک تھرو ہے۔ آخر میں، کورس آپ کو GCP اور Terraform سے متعارف کراتا ہے، جو کہ کنٹینرائزیشن اور بنیادی ڈھانچے کو ایک کوڈ کے طور پر ایک جامع سمجھ فراہم کرتا ہے، جو جدید کلاؤڈ پر مبنی ماحول کے لیے ضروری ہے۔
ماڈیول 2: ورک فلو آرکیسٹریشن تکنیک
ماڈیول ڈیٹا کی تبدیلی اور انضمام کے لیے ایک جدید اوپن سورس ہائبرڈ فریم ورک، میج کی گہرائی سے تحقیق پیش کرتا ہے۔ یہ ماڈیول ورک فلو آرکیسٹریشن کی بنیادی باتوں سے شروع ہوتا ہے، میج کے ساتھ ہینڈ آن ایکسرسائز تک ترقی کرتا ہے، جس میں اسے Docker کے ذریعے ترتیب دینا اور API سے Postgres اور Google Cloud Storage (GCS) اور پھر BigQuery میں ETL پائپ لائن بنانا شامل ہے۔
ماڈیول میں ویڈیوز، وسائل اور عملی کاموں کا امتزاج ایک جامع سیکھنے کے تجربے کو یقینی بناتا ہے، سیکھنے والوں کو Mage کا استعمال کرتے ہوئے نفیس ڈیٹا ورک فلو کو منظم کرنے کی مہارتوں سے آراستہ کرتا ہے۔
ورکشاپ 1: ڈیٹا کے اندراج کی حکمت عملی
پہلی ورکشاپ میں آپ موثر ڈیٹا انجیکشن پائپ لائنز بنانے میں مہارت حاصل کریں گے۔ ورکشاپ میں ضروری مہارتوں پر توجہ مرکوز کی گئی ہے جیسے APIs اور فائلوں سے ڈیٹا نکالنا، ڈیٹا کو نارملائز کرنا اور لوڈ کرنا، اور اضافی لوڈنگ تکنیک۔ اس ورکشاپ کو مکمل کرنے کے بعد، آپ ایک سینئر ڈیٹا انجینئر کی طرح موثر ڈیٹا پائپ لائنز بنانے کے قابل ہو جائیں گے۔
ماڈیول 3: ڈیٹا ویئر ہاؤسنگ
یہ ماڈیول ڈیٹا اسٹوریج اور تجزیہ کی گہرائی سے تلاش ہے، جو BigQuery کا استعمال کرتے ہوئے ڈیٹا ویئر ہاؤسنگ پر توجہ مرکوز کرتا ہے۔ یہ کلیدی تصورات جیسے کہ پارٹیشننگ اور کلسٹرنگ کا احاطہ کرتا ہے، اور BigQuery کے بہترین طریقوں میں ڈوبتا ہے۔ ماڈیول جدید موضوعات میں ترقی کرتا ہے، خاص طور پر BigQuery کے ساتھ مشین لرننگ (ML) کا انضمام، ML کے لیے SQL کے استعمال کو نمایاں کرنا، اور ہائپر پیرامیٹر ٹیوننگ، فیچر پری پروسیسنگ، اور ماڈل کی تعیناتی پر وسائل فراہم کرنا۔
ماڈیول 4: تجزیاتی انجینئرنگ
اینالیٹکس انجینئرنگ ماڈیول موجودہ ڈیٹا گودام کے ساتھ dbt (ڈیٹا بلڈ ٹول) کا استعمال کرتے ہوئے پروجیکٹ بنانے پر توجہ مرکوز کرتا ہے، یا تو BigQuery یا PostgreSQL۔
ماڈیول کلاؤڈ اور مقامی ماحول دونوں میں dbt ترتیب دینے کا احاطہ کرتا ہے، تجزیاتی انجینئرنگ کے تصورات، ETL بمقابلہ ELT، اور ڈیٹا ماڈلنگ کو متعارف کرواتا ہے۔ یہ اعلی درجے کی ڈی بی ٹی خصوصیات کا بھی احاطہ کرتا ہے جیسے انکریمنٹل ماڈلز، ٹیگز، ہکس، اور سنیپ شاٹس۔
آخر میں، ماڈیول گوگل ڈیٹا اسٹوڈیو اور میٹا بیس جیسے ٹولز کا استعمال کرتے ہوئے تبدیل شدہ ڈیٹا کو دیکھنے کے لیے تکنیک متعارف کرایا ہے، اور یہ ٹربل شوٹنگ اور موثر ڈیٹا لوڈنگ کے لیے وسائل فراہم کرتا ہے۔
ماڈیول 5: بیچ پروسیسنگ میں مہارت
یہ ماڈیول اپاچی اسپارک کا استعمال کرتے ہوئے بیچ پروسیسنگ کا احاطہ کرتا ہے، بیچ پروسیسنگ اور اسپارک کے تعارف کے ساتھ، ونڈوز، لینکس اور میک او ایس کے لیے انسٹالیشن ہدایات کے ساتھ۔
اس میں اسپارک ایس کیو ایل اور ڈیٹا فریمز کو تلاش کرنا، ڈیٹا کی تیاری، ایس کیو ایل آپریشنز کرنا، اور اسپارک انٹرنل کو سمجھنا شامل ہے۔ آخر میں، اس کا اختتام اسپارک کو کلاؤڈ میں چلانے اور اسپارک کو BigQuery کے ساتھ ضم کرنے کے ساتھ ہوتا ہے۔
ماڈیول 6: کافکا کے ساتھ ڈیٹا کو سٹریم کرنے کا فن
ماڈیول کا آغاز سٹریم پروسیسنگ کے تصورات کے تعارف کے ساتھ ہوتا ہے، جس کے بعد کافکا کی گہرائی سے تحقیق کی جاتی ہے، بشمول اس کے بنیادی اصول، کنفلوئنٹ کلاؤڈ کے ساتھ انضمام، اور پروڈیوسر اور صارفین پر مشتمل عملی ایپلی کیشنز۔
اس ماڈیول میں کافکا کی ترتیب اور اسٹریمز کا بھی احاطہ کیا گیا ہے، موضوعات جیسے اسٹریم جوائن، ٹیسٹنگ، ونڈونگ، اور کافکا ksqldb اور کنیکٹ کا استعمال۔ مزید برآں، یہ اپنی توجہ Python اور JVM ماحول تک بڑھاتا ہے، جس میں Python سٹریم پروسیسنگ کے لیے Faust، Pyspark – Structured Streaming، اور Kafka Streams کے لیے Scala مثالیں شامل ہیں۔
ورکشاپ 2: ایس کیو ایل کے ساتھ سٹریم پروسیسنگ
آپ RisingWave کے ساتھ سٹریمنگ ڈیٹا پر کارروائی اور ان کا نظم کرنا سیکھیں گے، جو آپ کی سٹریم پروسیسنگ ایپلی کیشنز کو بااختیار بنانے کے لیے PostgreSQL طرز کے تجربے کے ساتھ ایک سستا حل فراہم کرتا ہے۔
پروجیکٹ: ریئل ورلڈ ڈیٹا انجینئرنگ ایپلی کیشن
اس پروجیکٹ کا مقصد ان تمام تصورات کو عملی جامہ پہنانا ہے جو ہم نے اس کورس میں سیکھے ہیں ایک اختتام سے آخر تک ڈیٹا پائپ لائن کی تعمیر کے لیے۔ آپ ڈیٹاسیٹ کو منتخب کرکے، ڈیٹا پر کارروائی کرنے اور اسے ڈیٹا جھیل میں ذخیرہ کرنے کے لیے ایک پائپ لائن کی تعمیر، ڈیٹا لیک سے ڈیٹا گودام میں پروسیس شدہ ڈیٹا کی منتقلی کے لیے ایک پائپ لائن تعمیر کرکے، ڈیٹاسیٹ کو منتخب کرکے دو ٹائلوں پر مشتمل ایک ڈیش بورڈ بنائیں گے۔ ڈیٹا گودام میں ڈیٹا اور اسے ڈیش بورڈ کے لیے تیار کرنا، اور آخر میں ڈیٹا کو بصری طور پر پیش کرنے کے لیے ڈیش بورڈ بنانا۔
2024 کوہورٹ کی تفصیلات
- رجسٹریشن: ابھی نام درج کرائیں
- تاریخ آغاز: 15 جنوری 2024، 17:00 CET پر
- رہنمائی کی مدد کے ساتھ خود رفتار سیکھنا
- کوہورٹ فولڈر ہوم ورک اور ڈیڈ لائن کے ساتھ
- انٹرایکٹو سلیک کمیونٹی ہم مرتبہ سیکھنے کے لیے
شرائط
- بنیادی کوڈنگ اور کمانڈ لائن کی مہارت
- ایس کیو ایل میں فاؤنڈیشن
- ازگر: فائدہ مند لیکن لازمی نہیں۔
آپ کے سفر کی رہنمائی کرنے والے ماہر اساتذہ
- انکش کھنہ
- وکٹوریہ پیریز مولا
- الیکسی گریگوریف
- میٹ پامر
- لوئس اولیویرا
- مائیکل شومیکر
ہمارے 2024 کوہورٹ میں شامل ہوں اور ایک حیرت انگیز ڈیٹا انجینئرنگ کمیونٹی کے ساتھ سیکھنا شروع کریں۔ ماہرین کی زیر قیادت تربیت، ہینڈ آن تجربہ، اور صنعت کی ضروریات کے مطابق نصاب کے ساتھ، یہ بوٹ کیمپ نہ صرف آپ کو ضروری مہارتوں سے آراستہ کرتا ہے بلکہ آپ کو ایک منافع بخش اور مطلوبہ کیریئر کے راستے میں سب سے آگے بھی رکھتا ہے۔ آج ہی اندراج کریں اور اپنی خواہشات کو حقیقت میں بدلیں!
عابد علی اعوان (@1abidaliawan) ایک سرٹیفائیڈ ڈیٹا سائنٹسٹ پروفیشنل ہے جو مشین لرننگ ماڈل بنانا پسند کرتا ہے۔ فی الحال، وہ مشین لرننگ اور ڈیٹا سائنس ٹیکنالوجیز پر مواد کی تخلیق اور تکنیکی بلاگ لکھنے پر توجہ دے رہا ہے۔ عابد کے پاس ٹیکنالوجی مینجمنٹ میں ماسٹر ڈگری اور ٹیلی کمیونیکیشن انجینئرنگ میں بیچلر ڈگری ہے۔ اس کا وژن دماغی بیماری کے ساتھ جدوجہد کرنے والے طلباء کے لیے گراف نیورل نیٹ ورک کا استعمال کرتے ہوئے ایک AI پروڈکٹ بنانا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 000
- 1
- 15٪
- 17
- 2024
- a
- قابلیت
- ہمارے بارے میں
- فعال طور پر
- اس کے علاوہ
- خطاب کرتے ہوئے
- اعلی درجے کی
- پیش قدمی کرنا
- کے بعد
- AI
- تمام
- ساتھ
- بھی
- حیرت انگیز
- an
- تجزیہ
- تجزیاتی
- تجزیاتی
- اور
- اور بنیادی ڈھانچہ
- اپاچی
- اپاچی چمک
- اے پی آئی
- APIs
- ایپلی کیشنز
- آرکیٹیکٹس
- کیا
- فن
- AS
- At
- دستیاب
- مبادیات
- BE
- بن
- بننے
- ابتدائی
- فائدہ مند
- BEST
- بہترین طریقوں
- بڑی پوچھ گچھ
- مرکب
- بلاگز
- دونوں
- تعمیر
- عمارت
- لیکن
- by
- کیریئر کے
- کیریئرز
- مصدقہ
- بادل
- بادل سٹوریج
- clustering کے
- کوڈ
- کوڈنگ
- کوورٹ
- کمیونٹی
- کمپنیاں
- مکمل کرنا
- وسیع
- تصورات
- اختتام
- ترتیب
- میں confluent
- رابطہ قائم کریں
- سمجھا
- پر مشتمل ہے
- تعمیر
- صارفین
- پر مشتمل ہے
- مواد
- مواد کی تخلیق
- کورس
- کورسز
- پر محیط ہے
- تخلیق
- تخلیق
- مخلوق
- اہم
- اس وقت
- نصاب
- ڈیش بورڈ
- اعداد و شمار
- ڈیٹا انجینئر
- ڈیٹا لیک
- ڈیٹا سائنس
- ڈیٹا سائنسدان
- ڈیٹا اسٹوریج
- ڈیٹا گودام
- تاریخ
- ڈگری
- تعیناتی
- ڈیزائن
- ڈیزائننگ
- تفصیلی
- مشکل
- میں Docker
- ہر ایک
- مؤثر طریقے
- ہنر
- یا تو
- بااختیار
- کو چالو کرنے کے
- آخر
- آخر سے آخر تک
- انجینئر
- انجنیئرنگ
- انجینئرز
- انرول
- یقینی بناتا ہے
- ماحولیات
- ماحول
- ضروری
- Ether (ETH)
- سب کچھ
- مثال کے طور پر
- دلچسپ
- موجودہ
- تجربہ
- ماہرین
- کی تلاش
- ایکسپلور
- توسیع
- نمایاں کریں
- خصوصیات
- خاصیت
- چند
- میدان
- فائلوں
- آخر
- پہلا
- توجہ مرکوز
- توجہ مرکوز
- توجہ مرکوز
- پیچھے پیچھے
- کے لئے
- سب سے اوپر
- بنیادی
- فریم ورک
- مفت
- سے
- تقریب
- بنیادی
- فرق
- GCP
- دی
- گوگل
- گوگل کلاؤڈ
- گراف
- گراف نیورل نیٹ ورک
- ہدایت دی
- ہاتھوں پر
- ہے
- he
- اجاگر کرنا۔
- ان
- کی ڈگری حاصل کی
- کلی
- گھر کا کام
- ہکس
- تاہم
- HTTPS
- ہائبرڈ
- ہائپر پیرامیٹر ٹیوننگ
- بیماری
- پر عملدرآمد
- in
- میں گہرائی
- شامل ہیں
- سمیت
- اضافہ
- صنعت
- انفراسٹرکچر
- جدید
- تنصیب
- ہدایات
- انضمام کرنا
- انضمام
- میں
- متعارف
- متعارف کرواتا ہے
- متعارف کرانے
- تعارف
- تعارف
- شامل
- IT
- میں
- جنوری
- کے ساتھ گفتگو
- kafka
- KDnuggets
- کلیدی
- جھیل
- معروف
- جانیں
- سیکھا ہے
- سیکھنے والے
- سیکھنے
- کی طرح
- لائن
- لنکڈ
- لینکس
- لوڈ کر رہا ہے
- مقامی
- تلاش
- سے محبت کرتا ہے
- لو
- منافع بخش
- مشین
- مشین لرننگ
- MacOS کے
- انتظام
- انتظام
- لازمی
- بہت سے
- ماسٹر
- ماسٹرنگ
- مواد
- ذہنی
- ذہنی بیماری
- ML
- ماڈل
- ماڈلنگ
- ماڈل
- جدید
- ماڈیول
- ماڈیولز
- زیادہ
- ایک سے زیادہ
- ضروری
- ضرورت ہے
- ضرورت
- ضروریات
- نیٹ ورک
- نیٹ ورکنگ
- عصبی
- عصبی نیٹ ورک
- مقصد
- of
- کی پیشکش
- تجویز
- on
- صرف
- اوپن سورس
- آپریشنز
- or
- آرکیسٹرا
- دیگر
- ہمارے
- پالمر
- خاص طور پر
- راستہ
- ادا
- ساتھی
- کارکردگی کا مظاہرہ
- پائپ لائن
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیلیں
- پوزیشنوں
- پوسٹگریسقیل
- عملی
- عملی ایپلی کیشنز
- پریکٹس
- طریقوں
- کی تیاری
- حال (-)
- عمل
- عملدرآمد
- پروسیسنگ
- پروڈیوسرس
- مصنوعات
- پیشہ ورانہ
- پیشہ ور ماہرین
- ترقی
- منصوبے
- منصوبوں
- فراہم کرتا ہے
- فراہم کرنے
- ازگر
- سوالات
- اٹھاتا ہے
- پڑھنا
- حقیقی دنیا
- حقیقت
- وسائل
- کردار
- کردار
- چل رہا ہے
- s
- تنخواہ
- بڑے پیمانے پر
- سائنس
- سائنسدان
- سائنسدانوں
- کی تلاش
- منتخب
- سینئر
- قائم کرنے
- سیٹ اپ
- مہارت
- سست
- حل
- کچھ
- کبھی کبھی
- بہتر
- چنگاری
- خصوصی
- SQL
- شروع کریں
- شروع
- ذخیرہ
- سٹریم
- محرومی
- اسٹریمز
- منظم
- جدوجہد
- طلباء
- سٹوڈیو
- کافی
- اس طرح
- حمایت
- سوئچ کریں
- سسٹمز
- موزوں
- ٹیلنٹ
- کاموں
- ٹیک
- ٹیکنیکل
- تکنیک
- ٹیکنالوجی
- ٹیکنالوجی
- ٹیلی مواصلات
- ٹرافیفار
- ٹیسٹنگ
- کہ
- ۔
- مبادیات
- تو
- اس
- کے ذریعے
- کرنے کے لئے
- آج
- کے آلے
- اوزار
- موضوعات
- ٹریننگ
- منتقلی
- تبدیل
- تبدیلی
- تبدیلی
- تبدیل
- تبدیل
- سبق
- دو
- افہام و تفہیم
- امریکی ڈالر
- استعمال کی شرائط
- صارفین
- کا استعمال کرتے ہوئے
- Ve
- بہت
- کی طرف سے
- ویڈیوز
- نقطہ نظر
- ضعف
- vs
- گودام
- سٹوریج
- we
- کیا
- جس
- ڈبلیو
- گے
- کھڑکیاں
- ساتھ
- کام کا بہاؤ
- کام کے بہاؤ
- ورکشاپ
- ورکشاپ
- تحریری طور پر
- آپ
- اور
- زیفیرنیٹ










