تعارف
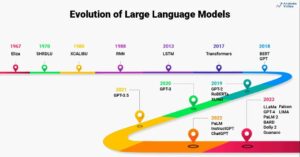
ایک مدھم روشنی والی لائبریری میں کھڑے ہونے کا تصور کریں، درجنوں دیگر متن کو جگاتے ہوئے ایک پیچیدہ دستاویز کو سمجھنے کے لیے جدوجہد کر رہے ہیں۔ یہ ٹرانسفارمرز کی دنیا تھی اس سے پہلے کہ "توجہ صرف آپ کی ضرورت ہے" پیپر نے اپنی انقلابی روشنی کی نقاب کشائی کی۔ توجہ کا طریقہ کار.
فہرست
RNNs کی حدود
روایتی ترتیب وار ماڈل، جیسے ریکرنٹ نیورل نیٹ ورکس (RNNs), زبان کے لفظ کو لفظ کے لحاظ سے پروسیس کیا گیا، جس کی وجہ سے کئی حدود ہیں:
- مختصر فاصلے پر انحصار: RNNs نے دور دراز کے الفاظ کے درمیان تعلق کو سمجھنے کے لیے جدوجہد کی، اکثر ایسے جملوں کے معنی کی غلط تشریح کرتے ہیں جیسے "کل چڑیا گھر کا دورہ کرنے والا آدمی"، جہاں مضمون اور فعل بہت الگ ہیں۔
- محدود ہم آہنگی: ترتیب وار معلومات کی پروسیسنگ فطری طور پر سست ہے، موثر تربیت اور کمپیوٹیشنل وسائل کے استعمال کو روکتی ہے، خاص طور پر طویل ترتیب کے لیے۔
- مقامی سیاق و سباق پر توجہ مرکوز کریں: RNNs بنیادی طور پر قریبی پڑوسیوں پر غور کرتے ہیں، ممکنہ طور پر جملے کے دوسرے حصوں سے اہم معلومات غائب ہیں۔
ان حدود نے ٹرانسفارمرز کی مشینی ترجمہ اور قدرتی زبان کی سمجھ بوجھ جیسے پیچیدہ کاموں کو انجام دینے کی صلاحیت میں رکاوٹ ڈالی۔ پھر آیا توجہ کا طریقہ کار, ایک انقلابی اسپاٹ لائٹ جو الفاظ کے درمیان چھپے رابطوں کو روشن کرتی ہے، زبان کی پروسیسنگ کے بارے میں ہماری سمجھ کو تبدیل کرتی ہے۔ لیکن توجہ نے بالکل کیا حل کیا، اور اس نے ٹرانسفارمرز کے لیے کھیل کو کیسے بدلا؟
آئیے تین اہم شعبوں پر توجہ مرکوز کریں:
طویل فاصلے تک انحصار
- مسئلہ: روایتی ماڈلز اکثر ایسے جملوں پر ٹھوکر کھاتے ہیں جیسے "پہاڑی پر رہنے والی عورت نے کل رات شوٹنگ اسٹار کو دیکھا"۔ انہوں نے اپنی دوری کی وجہ سے "عورت" اور "شوٹنگ اسٹار" کو جوڑنے کے لیے جدوجہد کی، جس کی وجہ سے غلط تشریحات ہوئیں۔
- توجہ کا طریقہ کار: تصور کریں کہ ماڈل پورے جملے میں ایک روشن شہتیر چمکتا ہے، "عورت" کو براہ راست "شوٹنگ اسٹار" سے جوڑتا ہے اور جملہ کو مجموعی طور پر سمجھتا ہے۔ فاصلے سے قطع نظر رشتوں کو حاصل کرنے کی یہ صلاحیت مشینی ترجمہ اور خلاصہ جیسے کاموں کے لیے اہم ہے۔
بھی پڑھیں: لانگ شارٹ ٹرم میموری (LSTM) پر ایک جائزہ
متوازی پروسیسنگ پاور
- مسئلہ: روایتی ماڈلز نے ترتیب وار معلومات کو پروسیس کیا، جیسے کتاب کا صفحہ بہ صفحہ پڑھنا۔ یہ سست اور غیر موثر تھا، خاص طور پر لمبی تحریروں کے لیے۔
- توجہ کا طریقہ کار: لائبریری کو بیک وقت اسکین کرنے والی متعدد اسپاٹ لائٹس کا تصور کریں، متن کے مختلف حصوں کا متوازی طور پر تجزیہ کریں۔ یہ ڈرامائی طور پر ماڈل کے کام کو تیز کرتا ہے، جس سے یہ ڈیٹا کی بڑی مقدار کو مؤثر طریقے سے سنبھال سکتا ہے۔ یہ متوازی پروسیسنگ پاور پیچیدہ ماڈلز کی تربیت اور حقیقی وقت کی پیشین گوئیاں کرنے کے لیے ضروری ہے۔
عالمی سیاق و سباق سے آگاہی
- مسئلہ: روایتی ماڈلز اکثر انفرادی الفاظ پر توجہ مرکوز کرتے ہیں، جملے کے وسیع تر سیاق و سباق سے محروم رہتے ہیں۔ اس سے طنز یا دوہرے معنی جیسے معاملات میں غلط فہمیاں پیدا ہوئیں۔
- توجہ کا طریقہ کار: تصور کریں کہ اسپاٹ لائٹ پوری لائبریری میں پھیلی ہوئی ہے، ہر کتاب کو لے کر سمجھیں کہ وہ ایک دوسرے سے کیسے تعلق رکھتے ہیں۔ یہ عالمی سیاق و سباق سے آگاہی ماڈل کو ہر لفظ کی ترجمانی کرتے وقت متن کی مکمل تفہیم پر غور کرنے کی اجازت دیتی ہے، جس سے ایک بھرپور اور زیادہ باریک بینی کی سمجھ حاصل ہوتی ہے۔
پولیسیموس الفاظ کو واضح کرنا
- مسئلہ: "بینک" یا "ایپل" جیسے الفاظ اسم، فعل، یا کمپنیاں بھی ہو سکتے ہیں، جو ابہام پیدا کرتے ہیں جسے حل کرنے کے لیے روایتی ماڈلز کو جدوجہد کرنا پڑتی ہے۔
- توجہ کا طریقہ کار: ایک جملے میں لفظ "بینک" کے تمام واقعات پر روشنی ڈالنے والے ماڈل کا تصور کریں، پھر ارد گرد کے سیاق و سباق اور دوسرے الفاظ کے ساتھ تعلقات کا تجزیہ کریں۔ گرائمر کی ساخت، قریبی اسم، اور یہاں تک کہ ماضی کے جملوں پر غور کرنے سے، توجہ کا طریقہ کار مطلوبہ معنی نکال سکتا ہے۔ مشینی ترجمہ، متن کا خلاصہ، اور ڈائیلاگ سسٹم جیسے کاموں کے لیے پولیسیموس الفاظ کو غیر واضح کرنے کی یہ صلاحیت بہت اہم ہے۔
یہ چار پہلو - طویل فاصلے پر انحصار، متوازی پروسیسنگ پاور، عالمی سیاق و سباق سے آگاہی، اور ابہام - توجہ کے طریقہ کار کی تبدیلی کی طاقت کو ظاہر کرتے ہیں۔ انہوں نے ٹرانسفارمرز کو قدرتی لینگویج پروسیسنگ میں سب سے آگے بڑھایا ہے، جس سے وہ پیچیدہ کاموں کو قابل ذکر درستگی اور کارکردگی سے نمٹ سکتے ہیں۔
جیسا کہ NLP اور خاص طور پر LLMs کا ارتقا جاری ہے، توجہ کا طریقہ کار بلاشبہ اس سے بھی زیادہ اہم کردار ادا کرے گا۔ وہ الفاظ کی لکیری ترتیب اور انسانی زبان کی بھرپور ٹیپسٹری کے درمیان پل ہیں، اور بالآخر، ان لسانی عجائبات کی حقیقی صلاحیت کو کھولنے کی کلید ہیں۔ یہ مضمون مختلف قسم کے توجہ کے طریقہ کار اور ان کے افعال پر روشنی ڈالتا ہے۔
1. خود توجہ: ٹرانسفارمر کا رہنما ستارہ
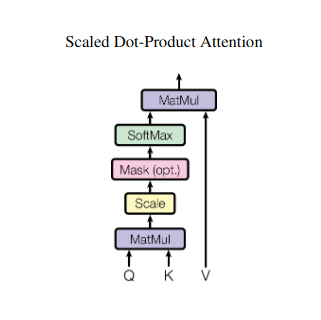
ایک سے زیادہ کتابوں کو جگانے کا تصور کریں اور خلاصہ لکھتے وقت ہر ایک میں مخصوص اقتباسات کا حوالہ دینے کی ضرورت ہے۔ خود توجہ یا اسکیلڈ ڈاٹ پروڈکٹ کی توجہ ایک ذہین معاون کی طرح کام کرتی ہے، ماڈلز کو ترتیب وار اعداد و شمار جیسے جملے یا ٹائم سیریز کے ساتھ ایسا کرنے میں مدد کرتی ہے۔ یہ ترتیب میں ہر عنصر کو ہر دوسرے عنصر میں شرکت کرنے کی اجازت دیتا ہے، مؤثر طریقے سے طویل فاصلے پر انحصار اور پیچیدہ تعلقات کو پکڑتا ہے۔
یہاں اس کے بنیادی تکنیکی پہلوؤں پر گہری نظر ہے:
ویکٹر کی نمائندگی
ہر عنصر (لفظ، ڈیٹا پوائنٹ) اپنے معلوماتی مواد کو انکوڈنگ کرتے ہوئے، ایک اعلیٰ جہتی ویکٹر میں تبدیل ہوتا ہے۔ یہ ویکٹر اسپیس عناصر کے درمیان تعامل کی بنیاد کے طور پر کام کرتا ہے۔
QKV تبدیلی
تین کلیدی میٹرکس کی وضاحت کی گئی ہے:
- سوال (س): "سوال" کی نمائندگی کرتا ہے ہر عنصر دوسروں کے سامنے لاحق ہوتا ہے۔ Q موجودہ عنصر کی معلومات کی ضروریات کو پکڑتا ہے اور ترتیب کے اندر متعلقہ معلومات کے لیے اس کی تلاش کی رہنمائی کرتا ہے۔
- کلید (K): ہر عنصر کی معلومات کی "کلید" رکھتا ہے۔ K ہر عنصر کے مواد کے جوہر کو انکوڈ کرتا ہے، دوسرے عناصر کو ان کی اپنی ضروریات کی بنیاد پر ممکنہ مطابقت کی شناخت کرنے کے قابل بناتا ہے۔
- قدر (V): اصل مواد کو ذخیرہ کرتا ہے جو ہر عنصر اشتراک کرنا چاہتا ہے۔ V تفصیلی معلومات پر مشتمل ہے جس تک دوسرے عناصر اپنے توجہ کے اسکور کی بنیاد پر رسائی اور فائدہ اٹھا سکتے ہیں۔
توجہ اسکور کا حساب کتاب
ہر عنصر کے جوڑے کے درمیان مطابقت کو ان کے متعلقہ Q اور K ویکٹر کے درمیان ڈاٹ پروڈکٹ کے ذریعے ماپا جاتا ہے۔ اعلی اسکور عناصر کے درمیان مضبوط ممکنہ مطابقت کی نشاندہی کرتے ہیں۔
اسکیلڈ توجہ کا وزن
متعلقہ اہمیت کو یقینی بنانے کے لیے، یہ مطابقت کے اسکورز کو سافٹ میکس فنکشن کا استعمال کرتے ہوئے معمول بنایا جاتا ہے۔ اس کے نتیجے میں توجہ کا وزن، 0 سے 1 تک، موجودہ عنصر کے سیاق و سباق کے لیے ہر عنصر کی وزنی اہمیت کی نمائندگی کرتا ہے۔
وزنی سیاق و سباق جمع
توجہ کا وزن V میٹرکس پر لاگو کیا جاتا ہے، بنیادی طور پر موجودہ عنصر سے اس کی مطابقت کی بنیاد پر ہر عنصر سے اہم معلومات کو نمایاں کرتا ہے۔ یہ وزنی رقم موجودہ عنصر کے لیے ایک سیاق و سباق کی نمائندگی کرتی ہے، جس میں ترتیب میں دیگر تمام عناصر سے حاصل کردہ بصیرت کو شامل کیا جاتا ہے۔
عنصر کی بہتر نمائندگی
اس کی افزودہ نمائندگی کے ساتھ، عنصر اب اس کے اپنے مواد کے ساتھ ساتھ ترتیب میں موجود دیگر عناصر کے ساتھ اس کے تعلقات کی گہری سمجھ رکھتا ہے۔ یہ تبدیل شدہ نمائندگی ماڈل کے اندر بعد کی پروسیسنگ کی بنیاد بناتی ہے۔
یہ کثیر مرحلہ عمل خود توجہ کو قابل بناتا ہے:
- طویل فاصلے پر انحصار کیپچر: دور دراز عناصر کے درمیان تعلقات آسانی سے ظاہر ہو جاتے ہیں، چاہے متعدد مداخلتی عناصر سے الگ ہو جائیں۔
- ماڈل پیچیدہ تعاملات: ترتیب کے اندر ٹھیک ٹھیک انحصار اور ارتباط کو روشنی میں لایا جاتا ہے، جس سے ڈیٹا کے ڈھانچے اور حرکیات کی بہتر تفہیم ہوتی ہے۔
- ہر عنصر کو سیاق و سباق بنائیں: ماڈل ہر ایک عنصر کا تنہائی میں نہیں بلکہ تسلسل کے وسیع فریم ورک کے اندر تجزیہ کرتا ہے، جس سے زیادہ درست اور باریک بینی یا پیشین گوئیاں ہوتی ہیں۔
خود توجہ نے انقلاب برپا کردیا ہے کہ ماڈل کس طرح ترتیب وار ڈیٹا پر کارروائی کرتے ہیں، مختلف شعبوں جیسے مشینی ترجمہ، قدرتی زبان کی تخلیق، ٹائم سیریز کی پیشن گوئی، اور اس سے آگے کے نئے امکانات کو کھولتے ہیں۔ اس کی ترتیب کے اندر چھپے ہوئے رشتوں کی نقاب کشائی کرنے کی صلاحیت بصیرت کو بے نقاب کرنے اور کاموں کی ایک وسیع رینج میں اعلیٰ کارکردگی کے حصول کے لیے ایک طاقتور ٹول فراہم کرتی ہے۔
2. ملٹی ہیڈ توجہ: مختلف عینکوں کے ذریعے دیکھنا
خود توجہ ایک جامع نظریہ فراہم کرتی ہے، لیکن بعض اوقات ڈیٹا کے مخصوص پہلوؤں پر توجہ مرکوز کرنا بہت ضروری ہوتا ہے۔ اسی جگہ پر ملٹی ہیڈ توجہ آتی ہے۔ ایک سے زیادہ معاونوں کا تصور کریں، جن میں سے ہر ایک مختلف لینس سے لیس ہے:
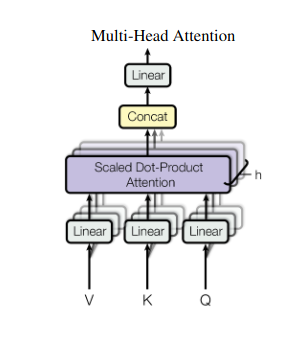
- متعدد "سر" بنائے جاتے ہیں، ہر ایک اپنے Q، K، اور V میٹرکس کے ذریعے ان پٹ ترتیب میں شرکت کرتا ہے۔
- ہر سر ڈیٹا کے مختلف پہلوؤں پر توجہ مرکوز کرنا سیکھتا ہے، جیسے طویل فاصلے تک انحصار، نحوی تعلقات، یا مقامی لفظی تعامل۔
- اس کے بعد ہر سر سے حاصل ہونے والے نتائج کو جوڑ دیا جاتا ہے اور ان پٹ کی کثیر جہتی نوعیت کو حاصل کرتے ہوئے، حتمی نمائندگی کے لیے پیش کیا جاتا ہے۔
یہ ماڈل کو بیک وقت مختلف نقطہ نظر پر غور کرنے کی اجازت دیتا ہے، جس کے نتیجے میں اعداد و شمار کے بارے میں مزید معلومات حاصل ہوتی ہیں۔
3. کراس توجہ: تسلسل کے درمیان پل بنانا
معلومات کے مختلف ٹکڑوں کے درمیان رابطوں کو سمجھنے کی صلاحیت NLP کے بہت سے کاموں کے لیے اہم ہے۔ کتاب کا جائزہ لکھنے کا تصور کریں - آپ صرف لفظ کے لیے متن کا خلاصہ نہیں کریں گے، بلکہ تمام ابواب میں بصیرت اور ربط پیدا کریں گے۔ داخل کریں۔ کراس توجہ، ایک طاقتور طریقہ کار جو ترتیبوں کے درمیان پل بناتا ہے، دو الگ الگ ذرائع سے معلومات کو فائدہ اٹھانے کے لیے ماڈلز کو بااختیار بناتا ہے۔
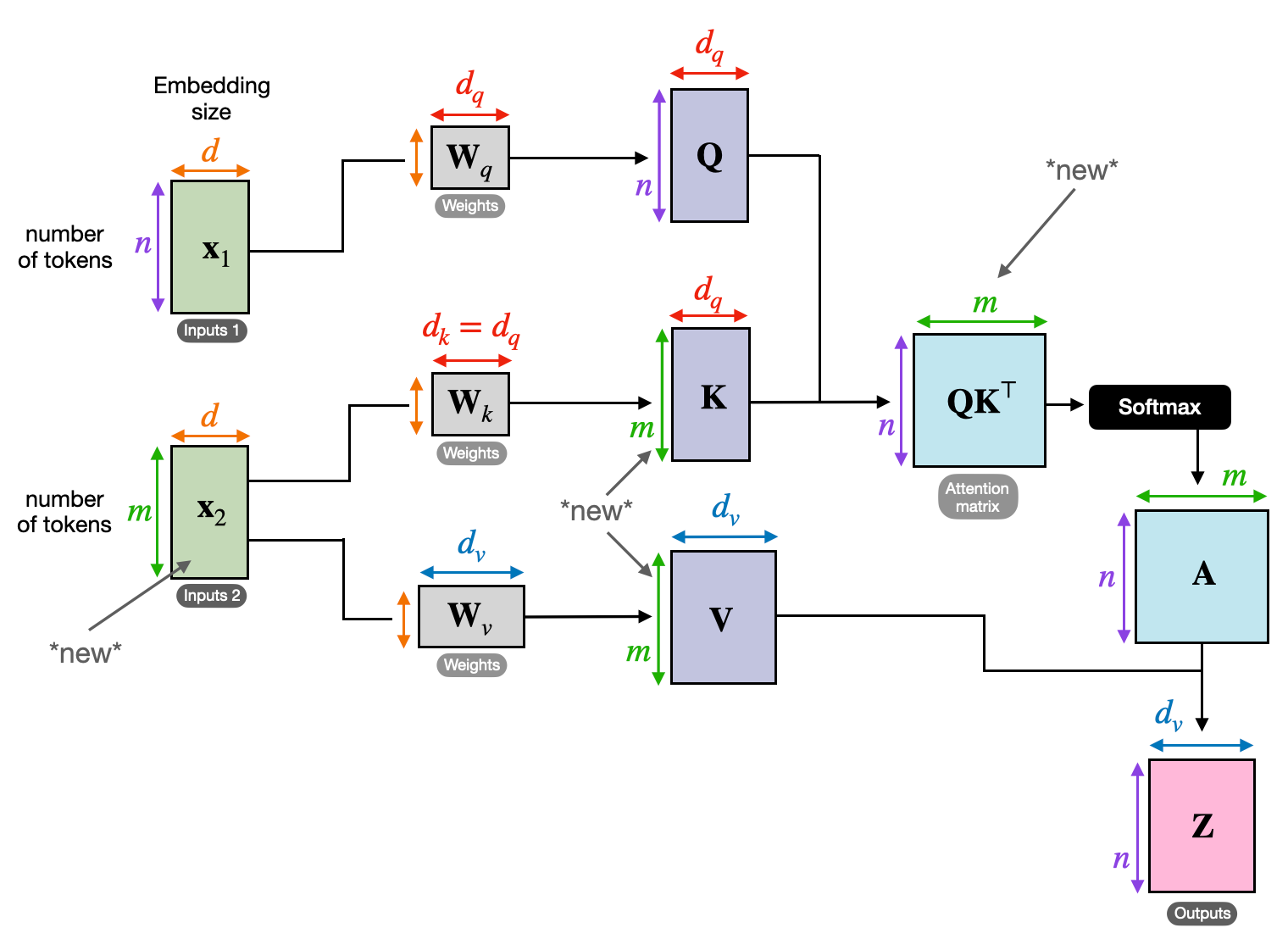
- انکوڈر-ڈیکوڈر آرکیٹیکچرز جیسے ٹرانسفارمرز میں، مرموزکار ان پٹ ترتیب (کتاب) پر کارروائی کرتا ہے اور چھپی ہوئی نمائندگی پیدا کرتا ہے۔
- ۔ کوٹواچک آؤٹ پٹ تسلسل (جائزہ) تیار کرتے ہوئے ہر قدم پر انکوڈر کی پوشیدہ نمائندگی میں شرکت کے لیے کراس اٹینشن کا استعمال کرتا ہے۔
- ڈیکوڈر کا Q میٹرکس انکوڈر کے K اور V میٹرکس کے ساتھ تعامل کرتا ہے، جس سے اسے جائزے کا ہر جملہ لکھتے ہوئے کتاب کے متعلقہ حصوں پر توجہ مرکوز کرنے کی اجازت ملتی ہے۔
یہ طریقہ کار مشینی ترجمہ، خلاصہ، اور سوال کے جوابات جیسے کاموں کے لیے انمول ہے، جہاں ان پٹ اور آؤٹ پٹ کی ترتیب کے درمیان تعلقات کو سمجھنا ضروری ہے۔
4. سببی توجہ: وقت کے بہاؤ کو محفوظ رکھنا
آگے جھانکے بغیر کسی جملے میں اگلے لفظ کی پیشین گوئی کا تصور کریں۔ توجہ دینے کے روایتی طریقہ کار ان کاموں کے ساتھ جدوجہد کرتے ہیں جن کے لیے معلومات کے عارضی ترتیب کو محفوظ رکھنے کی ضرورت ہوتی ہے، جیسے کہ متن کی تیاری اور وقت کی سیریز کی پیشن گوئی۔ وہ ترتیب میں آسانی سے "آگے جھانکتے ہیں"، جس کی وجہ سے غلط پیشین گوئیاں ہوتی ہیں۔ اس بات کو یقینی بناتے ہوئے کہ پیشین گوئیاں مکمل طور پر پہلے سے پروسیس شدہ معلومات پر منحصر ہوں، وجہ سے توجہ اس حد کو دور کرتی ہے۔
یہ کام کرنے کا طریقہ یہاں ہے
- ماسکنگ میکانزم: ایک مخصوص ماسک توجہ کے وزن پر لاگو کیا جاتا ہے، جو ترتیب میں مستقبل کے عناصر تک ماڈل کی رسائی کو مؤثر طریقے سے روکتا ہے۔ مثال کے طور پر، جب "عورت جو…" میں دوسرے لفظ کی پیشین گوئی کرتے ہیں، تو ماڈل صرف "the" پر غور کر سکتا ہے نہ کہ "who" یا اس کے بعد کے الفاظ پر۔
- خود بخود پروسیسنگ: معلومات لکیری طور پر بہتی ہیں، ہر عنصر کی نمائندگی صرف اس کے سامنے آنے والے عناصر سے ہوتی ہے۔ ماڈل ترتیب وار لفظ پر عمل کرتا ہے، اس مقام تک قائم کردہ سیاق و سباق کی بنیاد پر پیشین گوئیاں پیدا کرتا ہے۔
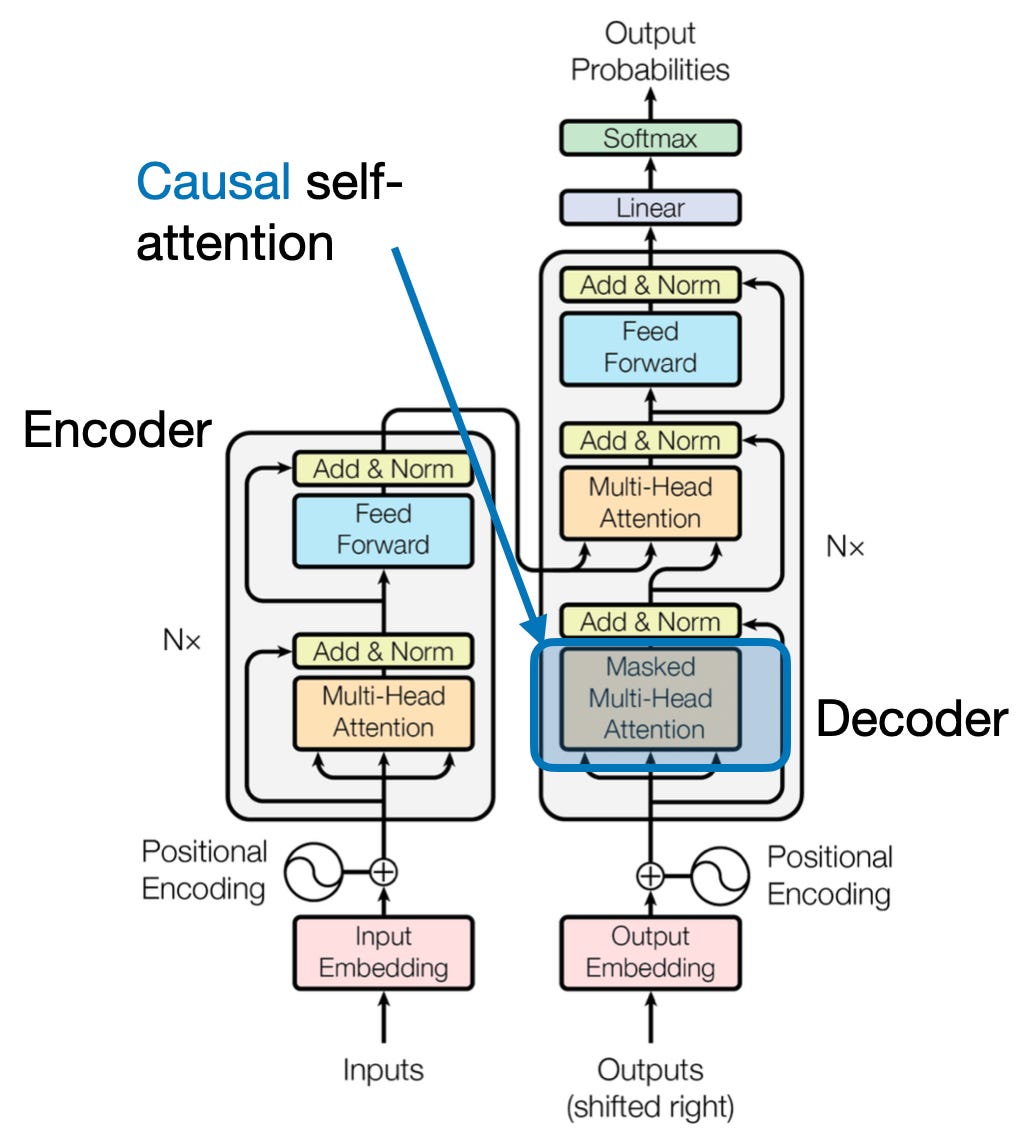
ٹیکسٹ جنریشن اور ٹائم سیریز کی پیشن گوئی جیسے کاموں کے لیے کارآمد توجہ بہت ضروری ہے، جہاں درست پیشین گوئیوں کے لیے ڈیٹا کی عارضی ترتیب کو برقرار رکھنا بہت ضروری ہے۔
5. عالمی بمقابلہ مقامی توجہ: توازن کو مارنا
توجہ دینے کے طریقہ کار کو ایک اہم تجارت کا سامنا کرنا پڑتا ہے: موثر حساب کو برقرار رکھنے کے مقابلے میں طویل فاصلے تک انحصار کو حاصل کرنا۔ یہ دو بنیادی طریقوں سے ظاہر ہوتا ہے: عالمی توجہ اور مقامی توجہ. کسی خاص باب پر توجہ مرکوز کرنے کے مقابلے میں پوری کتاب کو پڑھنے کا تصور کریں۔ عالمی توجہ ایک ساتھ پوری ترتیب پر کارروائی کرتی ہے، جبکہ مقامی توجہ ایک چھوٹی کھڑکی پر مرکوز ہوتی ہے:
- عالمی توجہ طویل فاصلے پر انحصار اور مجموعی سیاق و سباق کی گرفت کرتا ہے لیکن طویل ترتیب کے لیے کمپیوٹیشنل طور پر مہنگا ہو سکتا ہے۔
- مقامی توجہ زیادہ موثر ہے لیکن دور دراز کے تعلقات سے محروم رہ سکتا ہے۔
عالمی اور مقامی توجہ کے درمیان انتخاب کئی عوامل پر منحصر ہے:
- کام کی ضروریات: مشینی ترجمہ جیسے کاموں کے لیے دور دراز کے رشتوں کو حاصل کرنے، عالمی توجہ کی حمایت کی ضرورت ہوتی ہے، جب کہ جذبات کا تجزیہ مقامی توجہ کی طرف توجہ دے سکتا ہے۔
- تسلسل کی لمبائی: طویل ترتیب عالمی توجہ کو حسابی طور پر مہنگا بناتی ہے، مقامی یا ہائبرڈ طریقوں کی ضرورت ہوتی ہے۔
- ماڈل کی صلاحیت: وسائل کی رکاوٹوں کو مقامی توجہ کی ضرورت پڑ سکتی ہے حتیٰ کہ ایسے کاموں کے لیے جو عالمی تناظر کی ضرورت ہوتی ہے۔
زیادہ سے زیادہ توازن حاصل کرنے کے لیے، ماڈل استعمال کر سکتے ہیں:
- متحرک سوئچنگ: اہم عناصر کے لیے عالمی توجہ اور دوسروں کے لیے مقامی توجہ کا استعمال کریں، اہمیت اور فاصلے کی بنیاد پر موافقت کریں۔
- ہائبرڈ نقطہ نظر: دونوں میکانزم کو ایک ہی پرت کے اندر جوڑیں، ان کی متعلقہ طاقتوں کا فائدہ اٹھاتے ہوئے۔
بھی پڑھیں: گہری سیکھنے میں اعصابی نیٹ ورکس کی اقسام کا تجزیہ کرنا
نتیجہ
بالآخر، مثالی نقطہ نظر عالمی اور مقامی توجہ کے درمیان ایک سپیکٹرم پر مضمر ہے۔ ان تجارتی معاہدوں کو سمجھنا اور مناسب حکمت عملی اپنانا ماڈلز کو مختلف پیمانوں پر متعلقہ معلومات کا مؤثر طریقے سے فائدہ اٹھانے کی اجازت دیتا ہے، جس سے ترتیب کے بارے میں مزید بہتر اور درست سمجھ حاصل ہوتی ہے۔
حوالہ جات
- Raschka، S. (2023). "ایل ایل ایم میں خود دھیان، ملٹی ہیڈ اٹینشن، کراس اٹینشن، اور کازل اٹینشن کو سمجھنا اور کوڈ کرنا۔"
- واسوانی، اے، وغیرہ۔ (2017)۔ "توجہ صرف آپ کی ضرورت ہے۔"
- Radford، A.، et al. (2019)۔ "زبان کے ماڈل غیر زیر نگرانی ملٹی ٹاسک سیکھنے والے ہیں۔"
متعلقہ
میں ڈیٹا پریمی ہوں اور مجھے ڈیٹا میں چھپے ہوئے نمونوں کو نکالنا اور سمجھنا پسند ہے۔ میں مشین لرننگ اور ڈیٹا سائنس کے شعبے میں سیکھنا اور ترقی کرنا چاہتا ہوں۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- کی صلاحیت
- تک رسائی حاصل
- درستگی
- درست
- حاصل
- حصول
- کے پار
- کام کرتا ہے
- اصل
- پتے
- اپنانے
- آگے
- AL
- تمام
- اجازت دے رہا ہے
- کی اجازت دیتا ہے
- am
- محیط
- مقدار
- an
- تجزیہ
- تجزیہ کرتا ہے
- تجزیہ
- اور
- جواب
- علاوہ
- واضح
- اطلاقی
- نقطہ نظر
- نقطہ نظر
- کیا
- علاقوں
- مضمون
- AS
- پہلوؤں
- اسسٹنٹ
- اسسٹنٹ
- At
- توقع
- میں شرکت
- توجہ
- کے بارے میں شعور
- متوازن
- کی بنیاد پر
- بنیاد
- BE
- بیم
- بن
- اس سے پہلے
- کے درمیان
- سے پرے
- مسدود کرنے میں
- کتاب
- کتب
- دونوں
- پل
- پلوں
- روشن
- وسیع
- لایا
- عمارت
- بناتا ہے
- تعمیر
- لیکن
- by
- آیا
- کر سکتے ہیں
- قبضہ
- قبضہ
- گرفتاری
- مقدمات
- تبدیل
- باب
- ابواب
- انتخاب
- قریب
- کوڈنگ
- جمع
- آتا ہے
- کمپنیاں
- مطابقت
- پیچیدہ
- حساب
- کمپیوٹیشنل
- رابطہ قائم کریں
- مربوط
- کنکشن
- غور کریں
- پر غور
- رکاوٹوں
- پر مشتمل ہے
- مواد
- سیاق و سباق
- جاری
- کور
- باہمی تعلقات
- بنائی
- پیدا
- تخلیق
- اہم
- اہم
- موجودہ
- اعداد و شمار
- ڈیٹا سائنس
- فیصلہ کرنا
- گہری
- گہرے
- کی وضاحت
- delves
- انحصار
- انحصار
- انحصار
- انحصار
- انحصار کرتا ہے
- تفصیلی
- مکالمے کے
- DID
- مختلف
- براہ راست
- فاصلے
- دور
- مختلف
- متنوع
- do
- دستاویز
- ڈاٹ
- دوگنا
- درجنوں
- ڈرامائی طور پر
- اپنی طرف متوجہ
- دو
- حرکیات
- ای اینڈ ٹی
- ہر ایک
- مؤثر طریقے
- کارکردگی
- ہنر
- مؤثر طریقے سے
- عنصر
- عناصر
- بااختیار بنانے
- کے قابل بناتا ہے
- کو فعال کرنا
- انکوڈنگ
- افزودہ
- کو یقینی بنانے کے
- کو یقینی بنانے ہے
- درج
- پوری
- پوری
- لیس
- خاص طور پر
- جوہر
- ضروری
- بنیادی طور پر
- قائم
- بھی
- ہر کوئی
- تیار
- بالکل
- مہنگی
- دھماکہ
- نکالنے
- چہرہ
- عوامل
- دور
- کی حمایت
- میدان
- قطعات
- فائنل
- بہاؤ
- بہنا
- توجہ مرکوز
- توجہ مرکوز
- توجہ مرکوز
- توجہ مرکوز
- کے لئے
- سب سے اوپر
- فارم
- فاؤنڈیشن
- چار
- فریم ورک
- سے
- تقریب
- افعال
- مستقبل
- کھیل ہی کھیل میں
- پیدا ہوتا ہے
- پیدا کرنے والے
- نسل
- گلوبل
- عالمی تناظر
- سمجھو
- بڑھائیں
- ہدایات
- رہنمائی کرنے والا
- ہینڈل
- ہے
- ہونے
- سر
- مدد
- پوشیدہ
- ہائی
- اعلی
- اجاگر کرنا۔
- کی ڈگری حاصل کی
- کلی
- کس طرح
- HTTPS
- انسانی
- ہائبرڈ
- i
- مثالی
- شناخت
- if
- تصور
- فوری طور پر
- اہمیت
- اہم
- in
- غلط
- شامل کرنا
- اشارہ کرتے ہیں
- انفرادی
- ناکافی
- معلومات
- موروثی طور پر
- ان پٹ
- بصیرت
- مثال کے طور پر
- انٹیلجنٹ
- ارادہ
- بات چیت
- بات چیت
- انٹرایکٹو
- مداخلت
- میں
- انمول
- تنہائی
- IT
- میں
- فوٹو
- صرف
- کلیدی
- کلیدی علاقے
- زبان
- آخری
- پرت
- معروف
- جانیں
- سیکھیں اور بڑھیں
- سیکھنے والے
- سیکھنے
- قیادت
- لینس
- لینس
- لیوریج
- لیورنگنگ
- لائبریری
- جھوٹ ہے
- روشنی
- کی طرح
- حد کے
- حدود
- مقامی
- لانگ
- اب
- دیکھو
- محبت
- مشین
- مشین لرننگ
- مشین ترجمہ
- برقرار رکھنے
- بنا
- بنانا
- آدمی
- بہت سے
- ماسک
- میٹرکس
- زیادہ سے زیادہ چوڑائی
- مطلب
- معنی
- ماپا
- میکانزم
- نظام
- یاد داشت
- شاید
- یاد آتی ہے
- لاپتہ
- ماڈل
- ماڈل
- زیادہ
- زیادہ موثر
- کثیر جہتی
- ایک سے زیادہ
- قدرتی
- قدرتی زبان
- قدرتی زبان کی نسل
- قدرتی زبان عملیات
- قدرتی زبان کی تفہیم
- فطرت، قدرت
- ضرورت ہے
- ضرورت ہے
- ضروریات
- پڑوسیوں
- نیٹ ورک
- عصبی
- نیند نیٹ ورک
- نئی
- اگلے
- رات
- ویزا
- لفظیں
- اب
- باریک
- of
- اکثر
- on
- ایک بار
- صرف
- زیادہ سے زیادہ
- or
- حکم
- دیگر
- دیگر
- ہمارے
- باہر
- پیداوار
- نتائج
- مجموعی طور پر
- مجموعی جائزہ
- خود
- صفحہ
- جوڑی
- کاغذ.
- متوازی
- حصے
- حصئوں
- گزشتہ
- پیٹرن
- انجام دینے کے
- کارکردگی
- نقطہ نظر
- ٹکڑے ٹکڑے
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیلیں
- پوائنٹ
- متصور ہوتا ہے
- ہے
- امکانات
- قوی
- ممکنہ
- ممکنہ طور پر
- طاقت
- طاقتور
- پیش گوئی
- پیشن گوئی
- محفوظ کر رہا ہے
- کی روک تھام
- پہلے
- بنیادی طور پر
- پرائمری
- عمل
- عملدرآمد
- عمل
- پروسیسنگ
- پاور پروسیسنگ
- مصنوعات
- متوقع
- چلانے
- فراہم کرتا ہے
- سوال
- رینج
- لے کر
- بلکہ
- پڑھیں
- آسانی سے
- پڑھنا
- اصل وقت
- حوالہ
- بے شک
- تعلقات
- رشتہ دار
- مطابقت
- متعلقہ
- قابل ذکر
- نمائندگی
- نمائندگی
- کی نمائندگی کرتا ہے
- کی ضرورت
- حل
- وسائل
- وسائل
- متعلقہ
- نتائج کی نمائش
- کا جائزہ لینے کے
- انقلابی
- انقلاب آگیا
- امیر
- کردار
- s
- اسی
- سرکشم
- دیکھا
- ترازو
- سکیننگ
- سائنس
- سکور
- اسکور
- تلاش کریں
- دوسری
- دیکھ کر
- سزا
- جذبات
- تسلسل
- سیریز
- کام کرتا ہے
- کئی
- سیکنڈ اور
- چمک
- شوٹنگ
- مختصر
- نمائش
- بیک وقت
- سست
- چھوٹے
- مکمل طور پر
- حل
- کبھی کبھی
- ذرائع
- خلا
- مخصوص
- خاص طور پر
- سپیکٹرم
- رفتار
- کے لئے نشان راہ
- کھڑے
- سٹار
- مرحلہ
- پردہ
- حکمت عملیوں
- طاقت
- مضبوط
- ساخت
- جدوجہد
- جدوجہد
- موضوع
- بعد میں
- اس طرح
- موزوں
- رقم
- مختصر
- خلاصہ
- اعلی
- ارد گرد
- سسٹمز
- ٹیکل
- لینے
- ٹیپسٹری
- کاموں
- ٹیکنیکل
- اصطلاح
- متن
- متن کی نسل
- کہ
- ۔
- دنیا
- ان
- ان
- تو
- یہ
- وہ
- اس
- تین
- کے ذریعے
- وقت
- وقت کا سلسلہ
- کرنے کے لئے
- کے آلے
- روایتی
- ٹریننگ
- تبدیلی
- تبدیل
- ٹرانسفارمر
- ٹرانسفارمرز
- تبدیل
- ترجمہ
- سچ
- دو
- اقسام
- آخر میں
- سمجھ
- افہام و تفہیم
- بلاشبہ
- غیر مقفل
- بے نقاب
- بے نقاب
- استعمال کی شرائط
- استعمال
- کا استعمال کرتے ہوئے
- مختلف
- وسیع
- بنام
- لنک
- کا دورہ کیا
- اہم
- vs
- چاہتے ہیں
- چاہتا ہے
- تھا
- اچھا ہے
- کیا
- جب
- جبکہ
- ڈبلیو
- پوری
- وسیع
- وسیع رینج
- گے
- ونڈو
- ساتھ
- کے اندر
- بغیر
- عورت
- لفظ
- الفاظ
- کام
- دنیا
- تحریری طور پر
- کل
- آپ
- زیفیرنیٹ
- چڑیا گھر