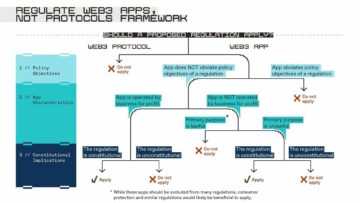
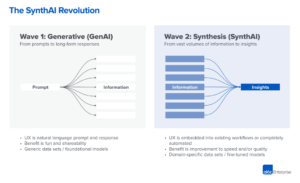
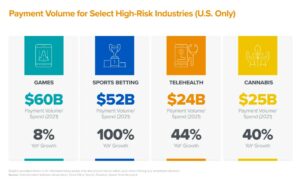
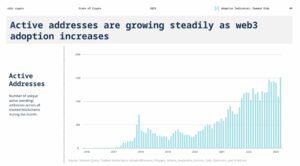
Ми починаємо спостерігати, як у генеративному штучному інтелекті (ШІ) з’являються дуже ранні стадії технологічного стеку. Сотні нових стартапів поспішають на ринок, щоб розробити базові моделі, створити додатки на базі ШІ та створити інфраструктуру/інструменти.
Багато гарячих технологічних тенденцій отримують надмірну рекламу задовго до того, як ринок наздожене. Але генеративний бум штучного інтелекту супроводжувався реальними досягненнями на реальних ринках і реальною тягою від реальних компаній. Такі моделі, як Stable Diffusion і ChatGPT, встановлюють історичні рекорди щодо зростання кількості користувачів, а кілька програм досягли 100 мільйонів доларів річного доходу менш ніж через рік після запуску. Пліч-о-пліч порівняння показує моделі ШІ перевершуючи людей в деяких завданнях на кілька порядків.
Таким чином, є достатньо ранніх даних, щоб стверджувати, що відбувається масштабна трансформація. Те, що ми не знаємо і що зараз стало критичним питанням, це: Де на цьому ринку накопичуватиметься вартість?
Протягом останнього року ми зустрічалися з десятками засновників та операторів стартапів у великих компаніях, які безпосередньо мають справу з генеративним ШІ. Ми це спостерігали постачальники інфраструктури наразі є найбільшими переможцями на цьому ринку, захоплюючи більшість доларів, що протікають через стек. Прикладні компанії дуже швидко зростають прибутки, але часто мають проблеми з утриманням, диференціацією продукту та валовою прибутковістю. І більшість моделі постачальників, хоч і відповідають за саме існування цього ринку, ще не досягли великих комерційних масштабів.
Іншими словами, компанії, які створюють найбільшу цінність, тобто тренують генеративні моделі штучного інтелекту та застосовують їх у нових програмах, не охопили більшу частину цього. Передбачити, що буде далі, набагато складніше. Але ми вважаємо, що головне зрозуміти, які частини стека є справді диференційованими та захищеними. Це матиме великий вплив на структуру ринку (тобто горизонтальний розвиток компанії проти вертикального) та чинники довгострокової цінності (наприклад, маржа та утримання). Поки що нам було важко знайти структурну обороноздатність де-небудь у стеку, поза традиційними ровами для посадових осіб.
Ми надзвичайно налаштовані на генеративний штучний інтелект і віримо, що він матиме величезний вплив на індустрію програмного забезпечення та за її межами. Мета цієї публікації — окреслити динаміку ринку та почати відповідати на ширші запитання про генеративні бізнес-моделі ШІ.
Технологічний стек високого рівня: інфраструктура, моделі та програми
Щоб зрозуміти, як формується генеративний ринок ШІ, нам спочатку потрібно визначити, як стек виглядає сьогодні. Ось наш попередній погляд.

Стек можна розділити на три шари:
- додатків які інтегрують генеративні моделі штучного інтелекту в продукт, орієнтований на користувача, або запускаючи власні конвеєри моделей («наскрізні програми»), або покладаючись на API третьої сторони
- моделі які забезпечують продукти штучного інтелекту, доступні як власний API або як контрольні точки з відкритим вихідним кодом (які, у свою чергу, вимагають рішення для хостингу)
- Інфраструктура постачальники (тобто хмарні платформи та виробники апаратного забезпечення), які запускають навчання та робочі навантаження для висновків для генеративних моделей ШІ
Важливо зауважити: це не карта ринку, а структура для аналізу ринку. У кожній категорії ми навели кілька прикладів відомих постачальників. Ми не робили жодних спроб бути вичерпними або перераховувати всі дивовижні генеративні програми ШІ, які були випущені. Ми також не будемо глибоко заглиблюватися в інструменти MLops або LLMops, які ще не є високостандартизованими та розглядатимуться в наступній публікації.
Перша хвиля генеративних додатків зі штучним інтелектом починає досягати масштабів, але їм важко утримуватися та диференціюватись

У попередніх технологічних циклах загальноприйнятою думкою було те, що для створення великої незалежної компанії ви повинні володіти кінцевим клієнтом — незалежно від того, чи це означало окремих споживачів, чи покупців B2B. Спокусливо вірити, що найбільші компанії з генеративного штучного інтелекту також будуть додатками для кінцевих користувачів. Поки що не зрозуміло, що це так.
Звісно, зростання генеративних додатків штучного інтелекту було приголомшливим завдяки чистій новизні та безлічі варіантів використання. Фактично, ми знаємо про принаймні три категорії продуктів, які вже перевищили 100 мільйонів доларів річного доходу: створення зображень, копірайтинг і написання коду.
Однак одного лише зростання недостатньо, щоб побудувати стійкі компанії програмного забезпечення. Важливо те, що зростання має бути прибутковим — у тому сенсі, що користувачі та клієнти після реєстрації отримують прибуток (високий валовий прибуток) і залишаються надовго (високе утримання). За відсутності сильної технічної диференціації програми B2B і B2C створюють довгострокову цінність для клієнтів через мережеві ефекти, збереження даних або створення дедалі складніших робочих процесів.
У генеративному ШІ ці припущення не обов’язково відповідають дійсності. У компаній, які займаються додатками, з якими ми спілкувалися, існує широкий діапазон валової прибутковості — у деяких випадках сягає 90%, але частіше — 50-60%, що здебільшого залежить від вартості моделювання. Зростання на початку послідовності було вражаючим, але незрозуміло, чи будуть поточні стратегії залучення клієнтів масштабованими — ми вже бачимо, що ефективність платного залучення та утримання починають падати. Багато додатків також є відносно недиференційованими, оскільки вони покладаються на схожі базові моделі ШІ та не виявили очевидних мережевих ефектів або даних/робочих процесів, які конкурентам важко повторити.
Отже, ще не очевидно, що продаж додатків для кінцевих користувачів є єдиним або навіть найкращим шляхом до побудови стійкого генеративного бізнесу ШІ. Націнки повинні покращитися, оскільки конкуренція та ефективність мовних моделей зростають (докладніше про це нижче). Утримання має зрости, коли туристи зі штучним інтелектом залишать ринок. І є вагомий аргумент, що вертикально інтегровані програми мають перевагу в диференціації. Але ще багато чого потрібно довести.
Забігаючи наперед, деякі з важливих питань, з якими стикаються компанії, що розробляють генеративні додатки ШІ, включають:
- Вертикальна інтеграція («модель + додаток»). Використання моделей штучного інтелекту як послуги дозволяє розробникам додатків швидко виконувати ітерацію з невеликою командою та міняти постачальників моделей у міру розвитку технологій. З іншого боку, деякі розробники стверджують, що продукт is модель, і що навчання з нуля є єдиним способом створити надійність, тобто шляхом постійного перенавчання на власних даних про продукт. Але це відбувається за рахунок значно вищих вимог до капіталу та менш спритної команди продукту.
- Функції побудови проти додатків. Продукти генеративного штучного інтелекту мають різні форми: настільні програми, мобільні програми, плагіни Figma/Photoshop, розширення Chrome і навіть боти Discord. Легко інтегрувати продукти штучного інтелекту туди, де вже працюють користувачі, оскільки інтерфейс користувача зазвичай є лише текстовим полем. Які з них стануть самостійними компаніями, а які будуть поглинені провідними компаніями, такими як Microsoft або Google, які вже впроваджують ШІ у свої продуктові лінії?
- Управління циклом реклами. Поки що незрозуміло, чи відтік притаманний поточній серії генеративних продуктів ШІ, чи це артефакт раннього ринку. Або якщо сплеск інтересу до генеративного штучного інтелекту впаде, коли спаде ажіотаж. Ці запитання мають важливі наслідки для компаній, що займаються додатками, зокрема, коли натиснути на педаль газу під час збору коштів; наскільки агресивно інвестувати в залучення клієнтів; які сегменти користувачів віддати пріоритет; і коли оголошувати продукт придатним для ринку.
Постачальники моделей винайшли генеративний ШІ, але не досягли великого комерційного масштабу

Те, що ми зараз називаємо генеративним штучним інтелектом, не існувало б без блискучої дослідницької та інженерної роботи в таких місцях, як Google, OpenAI і Stability. Завдяки новітній архітектурі моделей і героїчним зусиллям щодо масштабування конвеєрів навчання ми всі отримуємо вигоду від приголомшливих можливостей поточних великих мовних моделей (LLM) і моделей генерації зображень.
Проте доходи, пов’язані з цими компаніями, все ще відносно невеликі порівняно з використанням і шумом. У створенні зображень Stable Diffusion спостерігає вибухове зростання спільноти, що підтримується екосистемою інтерфейсів користувача, розміщених пропозицій і методів тонкого налаштування. Але стабільність надає свої основні контрольно-пропускні пункти безкоштовно як основний принцип їхнього бізнесу. У моделях природної мови OpenAI домінує з GPT-3/3.5 і ChatGPT. але щодо Наразі існує кілька вбивчих програм, побудованих на OpenAI, і ціни вже зросли впав один раз.
Це може бути лише тимчасовим явищем. Стабільність – це нова компанія, яка ще не зосереджена на монетизації. OpenAI має потенціал стати масштабним бізнесом, заробляючи значну частину всіх доходів категорії NLP у міру створення більшої кількості вбивчих програм — особливо якщо їх інтеграція в портфоліо продуктів Microsoft йде гладко. Враховуючи величезне використання цих моделей, великі доходи можуть не відставати.

Але існують і протидіючі сили. Моделі, випущені з відкритим вихідним кодом, можуть розміщуватися будь-ким, у тому числі сторонніми компаніями, які не несуть витрат, пов’язаних із широкомасштабним навчанням моделей (до десятків або сотень мільйонів доларів). І незрозуміло, чи можуть будь-які моделі із закритим вихідним кодом зберігати свою перевагу нескінченно довго. Наприклад, ми починаємо спостерігати, як LLM, створені такими компаніями, як Anthropic, Cohere та Character.ai, наближаються до рівнів продуктивності OpenAI, навчаються на подібних наборах даних (тобто в Інтернеті) і мають подібну модельну архітектуру. Про це свідчить приклад стабільної дифузії if моделі з відкритим кодом досягають достатнього рівня продуктивності та підтримки спільноти, тоді пропрієтарним альтернативам може бути важко конкурувати.
Можливо, найяскравіший висновок для модельних провайдерів наразі полягає в тому, що комерціалізація, ймовірно, пов’язана з хостингом. Попит на власні API (наприклад, від OpenAI) швидко зростає. Сервіси хостингу для моделей з відкритим вихідним кодом (наприклад, Hugging Face і Replicate) стають корисними центрами для легкого обміну та інтеграції моделей — і навіть мають деякі непрямі мережеві ефекти між виробниками моделей і споживачами. Існує також сильна гіпотеза про те, що можна монетизувати через тонке налаштування та угоди про хостинг із корпоративними клієнтами.
Крім цього, існує ряд серйозних питань, з якими стикаються постачальники моделей:
- Комодитизація. Існує загальна думка, що моделі штучного інтелекту з часом будуть наближатися у продуктивності. Розмовляючи з розробниками додатків, зрозуміло, що цього ще не сталося, оскільки є сильні лідери як у текстових, так і в графічних моделях. Їхні переваги базуються не на унікальних архітектурах моделей, а на високих вимогах до капіталу, власних даних про взаємодію з продуктами та дефіциті талантів ШІ. Чи стане це довгостроковою перевагою?
- Випускний ризик. Покладатися на модельних постачальників — це чудовий спосіб для компаній, що займаються додатками, розпочати роботу та навіть розширити свій бізнес. Але для них є стимул створювати та/або розміщувати власні моделі, коли вони досягнуть масштабу. Крім того, багато постачальників моделі мають дуже нерівний розподіл клієнтів, де кілька додатків представляють більшу частину доходу. Що станеться, якщо/коли ці клієнти перейдуть на власну розробку ШІ?
- Чи важливі гроші? Перспективи генеративного штучного інтелекту настільки великі — і також потенційно настільки шкідливі — що багато постачальників моделей організувалися як суспільно корисні корпорації (B corps), випустили обмежені частки прибутку або іншим чином включили суспільне благо у свою місію. Це зовсім не завадило їхнім зусиллям зі збору коштів. Але існує доцільна дискусія щодо того, чи більшість постачальників моделей насправді хотіти щоб отримати цінність, і якщо вони повинні.
Постачальники інфраструктури торкаються всього й отримують плоди

Майже все в генеративному штучному інтелекті в якийсь момент проходить через хмарний графічний процесор (або TPU). Чи для постачальників моделей/дослідницьких лабораторій, які виконують навчальні навантаження, для хостингових компаній, що виконують висновок/точне налаштування, чи для компаній, що використовують додатки, які поєднують те й інше — ФЛОПИ є джерелом життя генеративного ШІ. Вперше за дуже довгий час прогрес у найпроривніших обчислювальних технологіях пов’язаний із масовими обчисленнями.
Як наслідок, багато грошей на ринку генеративного штучного інтелекту зрештою надходять до інфраструктурних компаній. Щоб поставити трохи дуже Приблизні цифри навколо цього: за нашими оцінками, у середньому компанії, що займаються додатками, витрачають приблизно 20-40% доходу на висновки та тонке налаштування для кожного клієнта. Зазвичай це виплачується або безпосередньо хмарним постачальникам для екземплярів обчислень, або стороннім постачальникам моделей, які, у свою чергу, витрачають приблизно половину свого доходу на хмарну інфраструктуру. Отже, розумно припустити, що 10-20% від Загальна виручка у генеративному штучному інтелекті сьогодні користуються хмарні провайдери.
Крім того, стартапи, які навчають власних моделей, залучили мільярди доларів венчурного капіталу, більша частина якого (до 80-90% на ранніх стадіях) зазвичай також витрачається на постачальників хмарних технологій. Багато державних технологічних компаній витрачають сотні мільйонів на рік на навчання моделей або з зовнішніми хмарними постачальниками, або безпосередньо з виробниками апаратного забезпечення.
Це те, що ми б назвали, з технічної точки зору, «багато грошей» — особливо для ринку, що тільки зароджується. Велика частина витрачається на Великий 3 хмари: Amazon Web Services (AWS), Google Cloud Platform (GCP) і Microsoft Azure. Ці хмарні постачальники разом витратити більше ніж Мільярд доларів США на рік в капітальних витратах, щоб забезпечити найповніші, надійні та економічно конкурентоспроможні платформи. У генеративному штучному інтелекті, зокрема, вони також виграють від обмежень пропозиції, оскільки вони мають пільговий доступ до дефіцитного обладнання (наприклад, графічних процесорів Nvidia A100 і H100).
Цікаво, однак, що ми починаємо спостерігати появу надійної конкуренції. Такі конкуренти, як Oracle, досягли успіху завдяки значним капіталовкладенням і стимулюванням продажів. Кілька стартапів, як-от Coreweave і Lambda Labs, швидко виросли завдяки рішенням, націленим саме на великих розробників моделей. Вони конкурують за ціною, доступністю та персоналізованою підтримкою. Вони також надають більш детальні абстракції ресурсів (тобто контейнери), тоді як великі хмари пропонують лише екземпляри віртуальних машин через обмеження віртуалізації GPU.

За лаштунками, керуючи переважною більшістю робочих навантажень штучного інтелекту, наразі стоїть, мабуть, найбільший переможець у генеративному штучному інтелекті: Nvidia. Компанія повідомив про 3.8 XNUMX доларів мільярд доходу GPU центру обробки даних у третьому кварталі 2023 фінансового року, включаючи значущу частину для генеративних випадків використання ШІ. І вони побудували міцні рови навколо цього бізнесу завдяки десятиліттям інвестицій в архітектуру GPU, надійну екосистему програмного забезпечення та глибоке використання в академічній спільноті. Один останній аналіз виявлено, що графічні процесори Nvidia цитуються в дослідницьких статтях у 90 разів частіше, ніж разом узяті найкращі стартапи чіпів ШІ.
Існують інші варіанти апаратного забезпечення, включаючи модулі обробки тензорів Google (TPU); Графічні процесори AMD Instinct; чіпи AWS Inferentia і Trainium; і прискорювачі ШІ від таких стартапів, як Cerebras, Sambanova та Graphcore. Intel, запізнившись у грі, також виходить на ринок зі своїми високоякісними чіпами Habana та графічним процесором Ponte Vecchio. Але поки що деякі з цих нових чіпів зайняли значну частку ринку. Двома винятками, на які варто звернути увагу, є Google, чиї TPU набули популярності в спільноті Stable Diffusion і в деяких великих угодах GCP, і TSMC, яка, як вважається, виробляє всі чіпів, перелічених тут, включаючи графічні процесори Nvidia (Intel використовує суміш власних фабрик і TSMC для виробництва своїх чіпів).
Іншими словами, інфраструктура — це прибутковий, міцний і, здавалося б, захистний шар у стеку. Основні питання, на які мають відповісти інфракомпанії, включають:
- Тримання робочих навантажень без стану. Графічні процесори Nvidia однакові, де б ви їх не орендували. Більшість робочих навантажень штучного інтелекту не мають стану, у тому сенсі, що висновок моделі не потребує прикріплених баз даних або сховища (крім самих ваг моделі). Це означає, що робочі навантаження штучного інтелекту можуть бути більш переносимими в хмарах, ніж навантаження традиційних програм. Як у цьому контексті хмарні провайдери можуть створити липкість і завадити клієнтам переходити до найдешевшого варіанту?
- Пережити кінець дефіциту мікросхем. Ціноутворення для хмарних постачальників і для самої Nvidia підтримувалося дефіцитними поставками найбажаніших графічних процесорів. Один постачальник сказав нам, що ціна на A100 фактично є збільшений з моменту запуску, що дуже незвично для комп’ютерного обладнання. Як це вплине на хмарних провайдерів, коли це обмеження поставок буде врешті-решт усунено шляхом збільшення виробництва та/або впровадження нових апаратних платформ?
- Чи може хмара претендента пробитися? Ми твердо віримо в це вертикальні хмари забере частку ринку у великої трійки за допомогою більш спеціалізованих пропозицій. Наразі в області штучного інтелекту претенденти досягли значної тяги завдяки помірній технічній диференціації та підтримці Nvidia, для якої діючі постачальники хмарних технологій є як найбільшими клієнтами, так і новими конкурентами. Довгострокове питання полягає в тому, чи буде цього достатньо, щоб подолати масштабні переваги великої трійки?
Отже... де накопичуватиметься вартість?
Звичайно, ми ще не знаємо. Але виходячи з перших даних, які ми маємо для генеративного ШІ в поєднанні з наш досвід роботи з попередніми компаніями AI/ML, наша інтуїція така.
Сьогодні в генеративному штучному інтелекті немає жодних системних рівів. Як наближення першого порядку, програми не мають сильної диференціації продуктів, оскільки вони використовують подібні моделі; моделі стикаються з нечіткою довгостроковою диференціацією, оскільки вони навчаються на подібних наборах даних зі схожою архітектурою; хмарним провайдерам бракує глибокої технічної диференціації, оскільки вони використовують однакові графічні процесори; і навіть апаратні компанії виробляють свої мікросхеми на тих самих фабриках.
Існують, звичайно, стандартні рови: масштабні рови («Я маю або можу зібрати більше грошей, ніж ви!»), рови ланцюга постачання («У мене є графічні процесори, а у вас немає!»), екосистемні рови (« Усі вже користуються моїм програмним забезпеченням!»), алгоритмічних рівів («Ми розумніші за вас!»), рівів розподілу («У мене вже є команда продажів і більше клієнтів, ніж у вас!») і рівів каналів даних («Я я сканував більше Інтернету, ніж ти!»). Але жоден із цих ровів не може бути довговічним. І ще занадто рано говорити, чи сильні, прямі мережеві ефекти закріплюються на будь-якому рівні стеку.
Виходячи з наявних даних, просто неясно, чи буде довгострокова динаміка генеративного штучного інтелекту, коли переможець отримує все.
Це дивно. Але для нас це гарна новина. Потенційний розмір цього ринку важко зрозуміти — десь посередині все програмне забезпечення та всі людські починання — тому ми очікуємо багато-багато гравців і здорову конкуренцію на всіх рівнях стека. Ми також очікуємо, що як горизонтальні, так і вертикальні компанії досягнуть успіху, при цьому найкращий підхід буде продиктований кінцевими ринками та кінцевими користувачами. Наприклад, якщо основною відмінністю кінцевого продукту є сам штучний інтелект, вірогідно, що вертикалізація (тобто тісне зв’язування програми, орієнтованої на користувача, із домашньою моделлю) переможе. У той час як, якщо штучний інтелект є частиною більшого набору функцій з довгим хвостом, то більш імовірно, що станеться горизонтальність. Звичайно, ми також повинні побачити будівництво більш традиційних ровів з часом — і ми навіть можемо побачити нові типи ровів.
У будь-якому випадку, ми впевнені в одному: генеративний ШІ змінює гру. Ми всі вивчаємо правила в режимі реального часу, є величезна кількість цінностей, які буде розблоковано, і в результаті технологічний ландшафт виглядатиме набагато, набагато інакше. І ми тут для цього!
Усі зображення в цій публікації створено за допомогою Midjourney.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://a16z.com/2023/01/19/who-owns-the-generative-ai-platform/
- $ 100 мільйонів
- $3
- 1
- a
- A100
- МЕНЮ
- академічний
- прискорювачі
- доступ
- досягнутий
- придбання
- через
- насправді
- Прийняття
- аванси
- Перевага
- Переваги
- після
- угоди
- попереду
- AI
- Платформа AI
- випадки використання ai
- AI / ML
- алгоритмічний
- ВСІ
- дозволяє
- тільки
- вже
- альтернативи
- дивовижний
- Amazon
- Amazon Web Services
- Веб-служби Amazon (AWS)
- AMD
- кількість
- аналізувати
- та
- щорічно
- відповідь
- будь
- Інтерфейси
- додаток
- з'являтися
- додаток
- застосування
- Застосування
- підхід
- додатка
- архітектура
- сперечатися
- аргумент
- навколо
- штучний
- штучний інтелект
- Штучний інтелект (AI)
- асоційований
- наявність
- доступний
- середній
- AWS
- AWS Inferentia
- Лазурний
- B2B
- B2C
- заснований
- ведмідь
- оскільки
- ставати
- перед тим
- за
- віра
- Вірити
- вважається,
- віруючі
- нижче
- користь
- КРАЩЕ
- між
- За
- Великий
- найбільший
- Мільярд
- мільярди
- бум
- боти
- пов'язаний
- Box
- Перерва
- блискучий
- ширше
- будувати
- Створюємо
- побудований
- Бичачий
- бізнес
- підприємства
- покупців
- call
- можливості
- капітал
- захоплення
- захопивши
- випадок
- випадків
- категорії
- Категорія
- Центр
- певний
- претендент
- Зміни
- характер
- ChatGPT
- найдешевший
- чіп
- Чіпси
- Chrome
- цитується
- ясно
- ближче
- хмара
- інфраструктура хмари
- Хмарна платформа
- код
- колективно
- поєднання
- комбінований
- Приходити
- комерційний
- комерціалізація
- загальний
- співтовариство
- Компанії
- компанія
- порівняний
- конкурувати
- конкурс
- конкурентів
- комплекс
- всеосяжний
- обчислення
- обчислення
- обмеження
- Споживачі
- Контейнери
- контекст
- безперестанку
- звичайний
- сходяться
- Копірайтинг
- Core
- корпорації
- Коштувати
- витрати
- курс
- створювати
- створений
- створення
- достовірний
- критичний
- Поточний
- клієнт
- Клієнти
- циклів
- дані
- Центр обробки даних
- базами даних
- набори даних
- угода
- Пропозиції
- десятиліття
- глибокий
- Попит
- робочий стіл
- розвивати
- розробників
- розробка
- деви
- різний
- різні форми
- диференційований
- радіомовлення
- прямий
- безпосередньо
- розбрат
- відкритий
- обговорення
- руйнівний
- розподіл
- Розподілу
- розділений
- справи
- доларів
- домінує
- Не знаю
- безліч
- управляти
- керований
- драйвери
- водіння
- динамічний
- динаміка
- кожен
- Раніше
- Рано
- нарахування
- легко
- екосистема
- край
- ефекти
- ефективність
- зусилля
- або
- з'являються
- Машинобудування
- досить
- забезпечувати
- підприємство
- корпоративні клієнти
- особливо
- оцінити
- Навіть
- врешті-решт
- все
- приклад
- Приклади
- очікувати
- досвід
- Розширення
- зовнішній
- Особа
- облицювання
- Падати
- особливість
- риси
- кілька
- знайти
- виявлення
- Перший
- перший раз
- Фіскальний
- відповідати
- Flip
- Тече
- Потоки
- увагу
- після
- Війська
- форми
- знайдений
- фонд
- засновники
- Рамки
- Безкоштовна
- від
- Фандрайзинг
- майбутнє
- прибуток
- гра
- ГАЗ
- в цілому
- породжувати
- покоління
- генеративний
- Генеративний ШІ
- отримати
- даний
- дає
- мета
- йде
- буде
- добре
- Google Cloud
- Google Cloud Platform
- GPU
- Графічні процесори
- схопити
- великий
- валовий
- Рости
- Зростання
- вирощений
- Зростання
- Половина
- траплятися
- сталося
- відбувається
- Жорсткий
- апаратні засоби
- шкідливий
- здоровий
- тут
- Високий
- вище
- дуже
- історичний
- хіт
- тримати
- проведення
- Горизонтальний
- господар
- відбувся
- хостинг
- ГАРЯЧА
- Як
- HTTPS
- величезний
- людина
- Сотні
- сотні мільйонів
- обман
- зображення
- генерація зображень
- зображень
- Impact
- наслідки
- важливо
- удосконалювати
- in
- В інших
- Стимул
- стимули
- включати
- У тому числі
- Зареєстрований
- включення
- Augmenter
- збільшений
- Збільшує
- все більше і більше
- неймовірно
- Складно
- незалежний
- індивідуальний
- промисловість
- Інфраструктура
- притаманне
- інтегрувати
- інтегрований
- інтеграція
- Intel
- Інтелект
- взаємодія
- інтерес
- Інтерфейси
- інтернет
- інтуїція
- Винайдений
- Invest
- інвестиції
- Випущений
- IT
- сам
- ключ
- Знати
- Labs
- відсутність
- ландшафт
- мова
- великий
- масштабний
- в значній мірі
- більше
- останній
- Минулого року
- Пізно
- запуск
- шар
- шарів
- Лідери
- вивчення
- Залишати
- рівень
- рівні
- Ймовірно
- рамки
- ліній
- список
- Перераховані
- Довго
- багато часу
- довгостроковий
- подивитися
- ВИГЛЯДИ
- серія
- низький
- прибутковий
- made
- підтримувати
- основний
- Більшість
- зробити
- Виробники
- багато
- карта
- поля
- ринок
- карта ринку
- Структура ринку
- ринки
- масивний
- масово
- макс-ширина
- значущим
- засоби
- методика
- Microsoft
- Microsoft Azure
- Серед Подорожі
- мільйона
- мільйони
- Місія
- MLOps
- Mobile
- мобільні Програми-
- модель
- Моделі
- монетизація
- Монетизувати
- гроші
- більше
- найбільш
- множинний
- зародження
- Природний
- Природна мова
- обов'язково
- Необхідність
- мережу
- Нові
- нове обладнання
- новини
- наступний
- спритний
- nlp
- роман
- новинка
- номер
- номера
- Nvidia
- Очевидний
- пропонувати
- Пропозиції
- ONE
- відкрити
- з відкритим вихідним кодом
- OpenAI
- Оператори
- варіант
- Опції
- оракул
- замовлень
- Організований
- Інше
- інакше
- поза
- Подолати
- власний
- володіє
- оплачувану
- документи
- частина
- приватність
- частини
- проходить
- шлях
- продуктивність
- може бути
- Персоналізовані
- явище
- трубопровід
- місце
- місця
- платформа
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- гравці
- безліч
- plugins
- точка
- це можливо
- пошта
- потенціал
- потенційно
- влада
- прогнозування
- запобігати
- price
- ціни
- первинний
- попередній
- Пріоритетність
- обробка
- Виробники
- Product
- Production
- Продукти
- Прибуток
- прибутковий
- прибутку
- прогрес
- обіцянку
- власником
- Доведіть
- Постачальник
- провайдери
- громадськість
- put
- Квартал
- питання
- питань
- швидко
- підвищення
- піднятий
- діапазон
- швидко
- досягати
- досяг
- реальний
- реального часу
- розумний
- останній
- облік
- щодо
- випущений
- надійний
- Вилучено
- оренда
- представляє
- вимагати
- Вимога
- дослідження
- ресурс
- відповідальний
- результат
- утримання
- revenue
- надходження
- Risk
- міцний
- турів
- Правила
- прогін
- біг
- продажів
- Стимулювання продажів
- то ж
- масштабовані
- шкала
- Дефіцитний
- Дефіцит
- сцени
- бачачи
- сегменти
- Продаж
- сенс
- служити
- обслуговування
- Послуги
- комплект
- установка
- кілька
- Форма
- Поділитись
- акції
- Повинен
- Показувати
- підпис
- значний
- аналогічний
- з
- Розмір
- невеликий
- плавно
- So
- так далеко
- Софтвер
- рішення
- Рішення
- деякі
- десь
- Source
- спеціалізований
- конкретно
- витрачати
- відпрацьований
- Стабільність
- стабільний
- стек
- етапи
- стояти
- автономні
- standard
- старт
- почалася
- Починаючи
- введення в експлуатацію
- Стартапи
- палиця
- Як і раніше
- зберігання
- стратегії
- сильний
- структурний
- структура
- боротьба
- процвітати
- достатній
- Запропонує
- поставка
- підтримка
- Підтриманий
- сплеск
- сталого
- перемикач
- системний
- Приймати
- взяття
- талант
- говорити
- цільове
- завдання
- команда
- технології
- технічних компаній
- технічний
- Технологія
- тимчасовий
- terms
- Команда
- їх
- самі
- річ
- третій
- третя сторона
- три
- через
- Зв'язаний
- щільно
- час
- times
- до
- сьогодні
- занадто
- топ
- торкатися
- тяги
- традиційний
- навчений
- Навчання
- Перетворення
- величезний
- Тенденції
- правда
- tsmc
- ПЕРЕГЛЯД
- Типи
- типово
- ui
- Зрештою
- що лежить в основі
- розуміти
- створеного
- одиниць
- незвичайний
- us
- Використання
- використання
- користувач
- користувачі
- значення
- величезний
- постачальники
- підприємство
- венчурний капітал
- через
- вид
- годинник
- хвиля
- Web
- веб-сервіси
- добре відомі
- Що
- Чи
- який
- в той час як
- ВООЗ
- широкий
- Широкий діапазон
- Вікіпедія
- волі
- виграти
- Переможці
- мудрість
- без
- слова
- Work
- Робочі процеси
- лист
- рік
- зефірнет