In 2021 та 2020, ми розповідали вам про нові функції в Амазонська червона зміна які полегшують, пришвидшують і рентабельніше аналізують усі ваші дані та знаходять багату й потужну статистику. У 2022 році ми раді повідомити, що команда Amazon Redshift наполегливо працювала. Ми відійшли від вимог клієнтів і оголосили про низку нових функцій, щоб зробити аналіз усіх ваших даних легшим, швидшим і економічнішим. Ця публікація охоплює деякі з цих нових функцій.
Стратегія AWS щодо даних і аналітики полягає в тому, щоб надати вам сучасна архітектура даних що допоможе вам звільнитися від накопичених даних; мати спеціальні дані, аналітику, машинне навчання (ML) і служби штучного інтелекту, щоб використовувати правильний інструмент для правильної роботи; і мати відкриті, керовані, безпечні та повністю керовані служби, щоб зробити аналітику доступною для всіх. У сучасній архітектурі даних AWS Amazon Redshift як хмарне сховище даних залишається ключовим компонентом, що дає змогу запускати складну аналітику SQL у масштабі та продуктивності на терабайтах до петабайтів структурованих і неструктурованих даних, а також робити інформацію широко доступною через популярну бізнес-аналітику ( BI) та інструменти аналітики. Ми продовжуємо працювати у зворотному напрямку від вимог клієнтів і в 2022 році запустили понад 40 функцій в Amazon Redshift, щоб допомогти клієнтам у найпопулярніших випадках використання сховищ даних, зокрема:
- Аналітика самообслуговування
- Легке введення даних
- Обмін даними та співпраця
- Наука про дані та машинне навчання
- Безпечна та надійна аналітика
- Найкраща аналітика ефективності ціни
Давайте зануримося глибше та обговоримо нові функції Amazon Redshift у цих сферах.
Аналітика самообслуговування
Клієнти продовжують розповідати нам, що дані та аналітика стають повсюдними, і аналітика потрібна кожному в їхній організації. Ми оголосили Amazon Redshift без сервера (у попередній версії) у 2021 році, щоб полегшити запуск і масштабування аналітики за лічені секунди без необхідності створення інфраструктури сховища даних і керування нею. У липні 2022 року ми оголосили про загальна доступність Redshift Serverless, і відтоді тисячі клієнтів, у тому числі Peloton, Broadridge Financials і NextGen Healthcare, використовували його для швидкого та легкого аналізу своїх даних. Amazon Redshift Serverless автоматично надає та інтелектуально масштабує ємність сховища даних, щоб забезпечити високу продуктивність усієї вашої аналітики, і ви платите лише за обчислення, які використовуються протягом тривалості робочих навантажень, на основі розрахунку за секунду. Починаючи з GA, ми додали такі функції, як тегування ресурсу, спрощений моніторинг і доступність у додаткових регіонах AWS для подальшого спрощення виставлення рахунків і розширення охоплення в інших регіонах по всьому світу.
У 2021 році ми запустили Amazon Redshift Query Editor V2, який є безкоштовним веб-інструментом для аналітиків даних, дослідників даних і розробників для дослідження, аналізу та спільної роботи над даними в сховищах даних і озерах даних Amazon Redshift. У 2022 році Query Editor V2 отримав додаткові вдосконалення, як-от підтримка ноутбука для покращеної співпраці для створення, організації та анотування запитів; доступ користувача через облікові дані постачальника ідентифікаційної інформації (IdP). для єдиного входу; і можливість виконувати кілька запитів одночасно для підвищення продуктивності розробника.
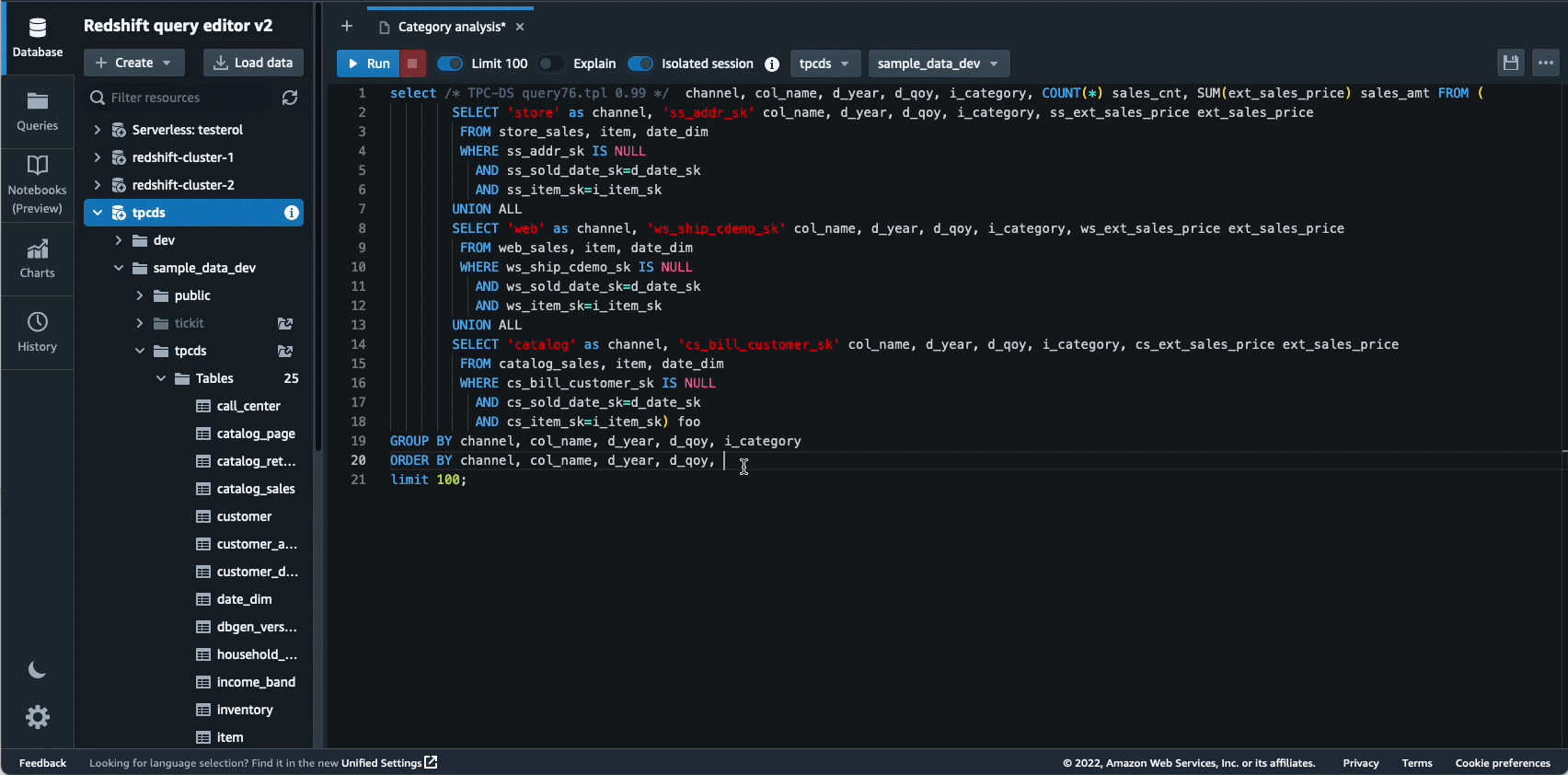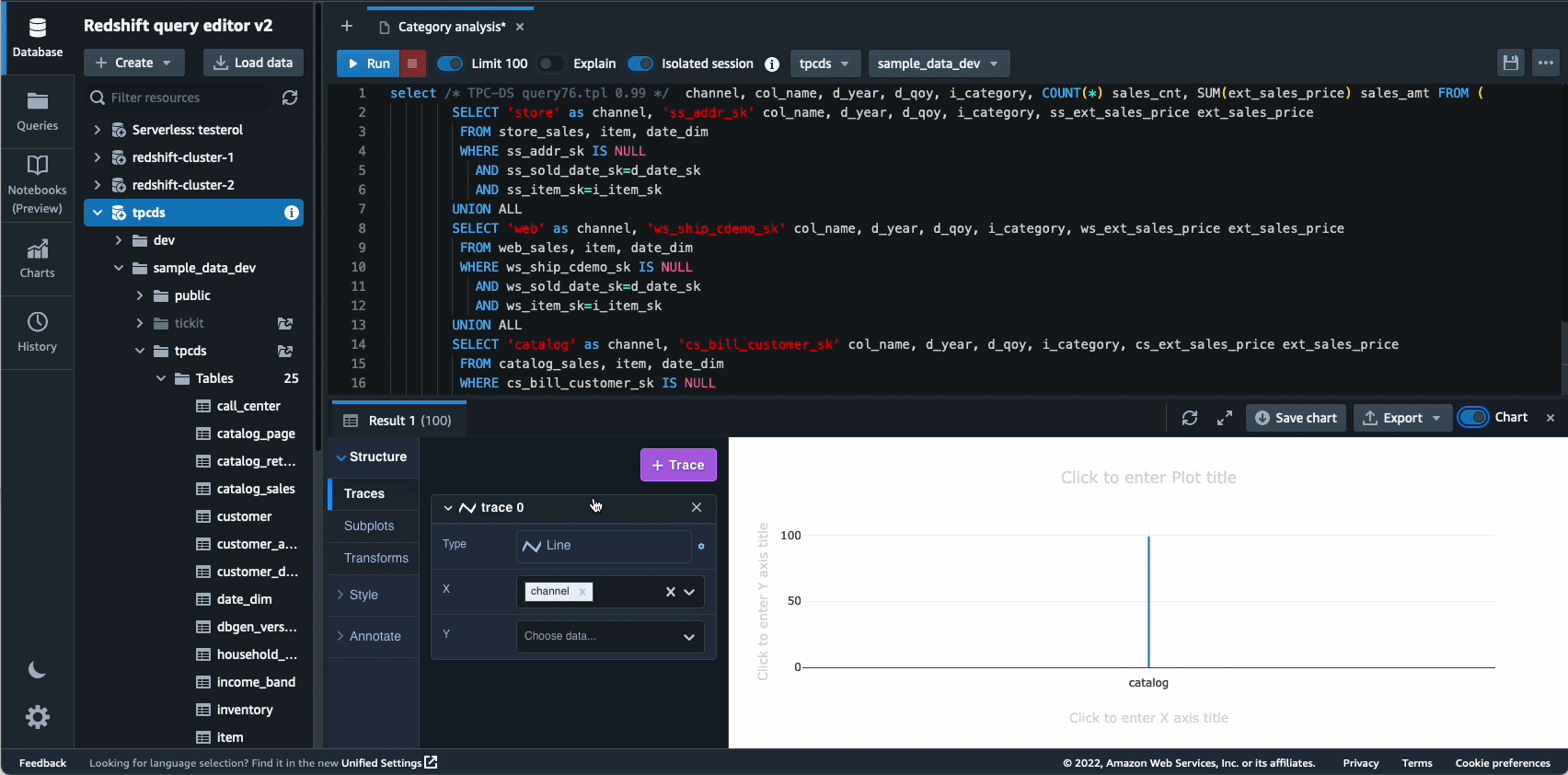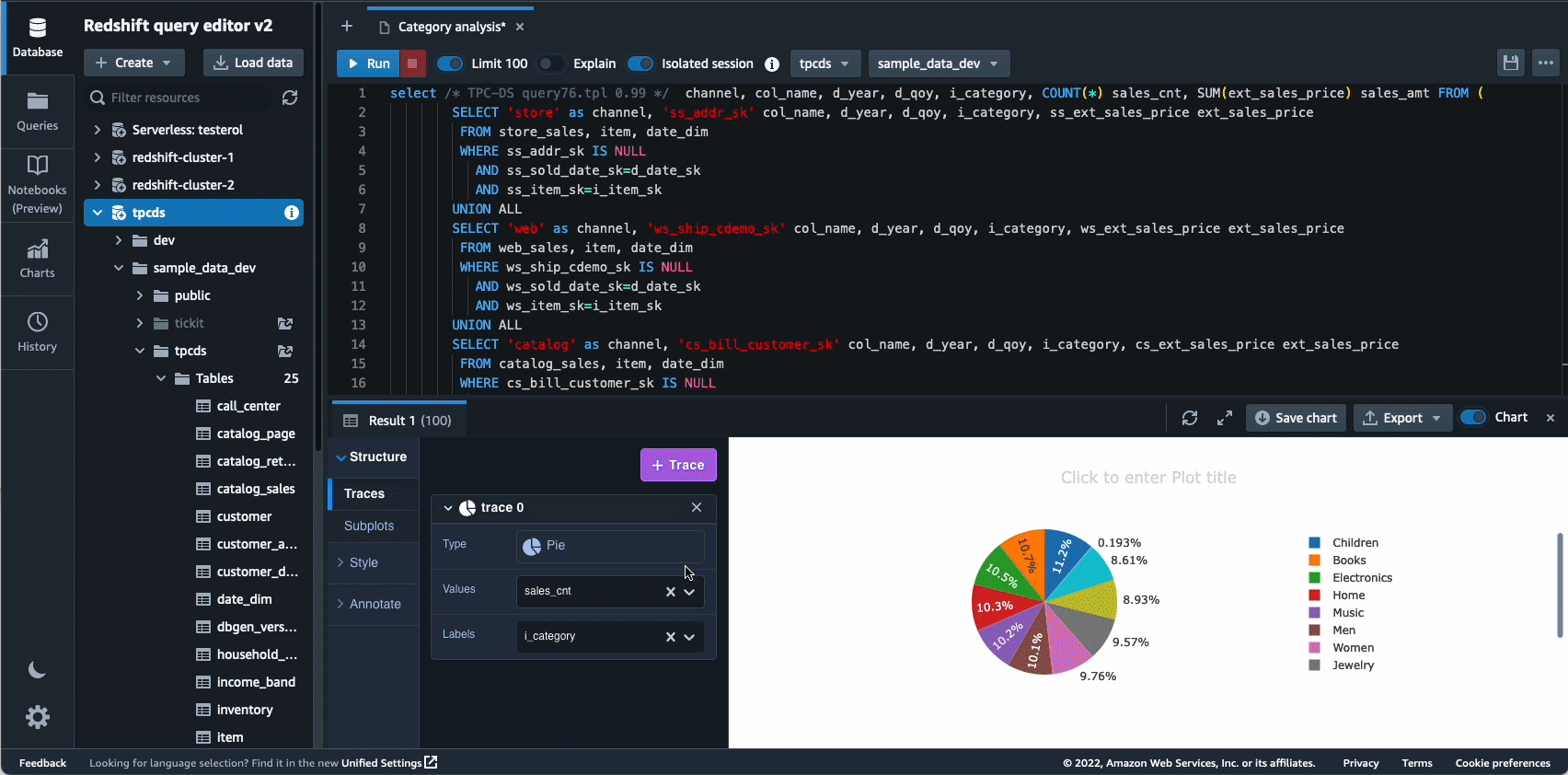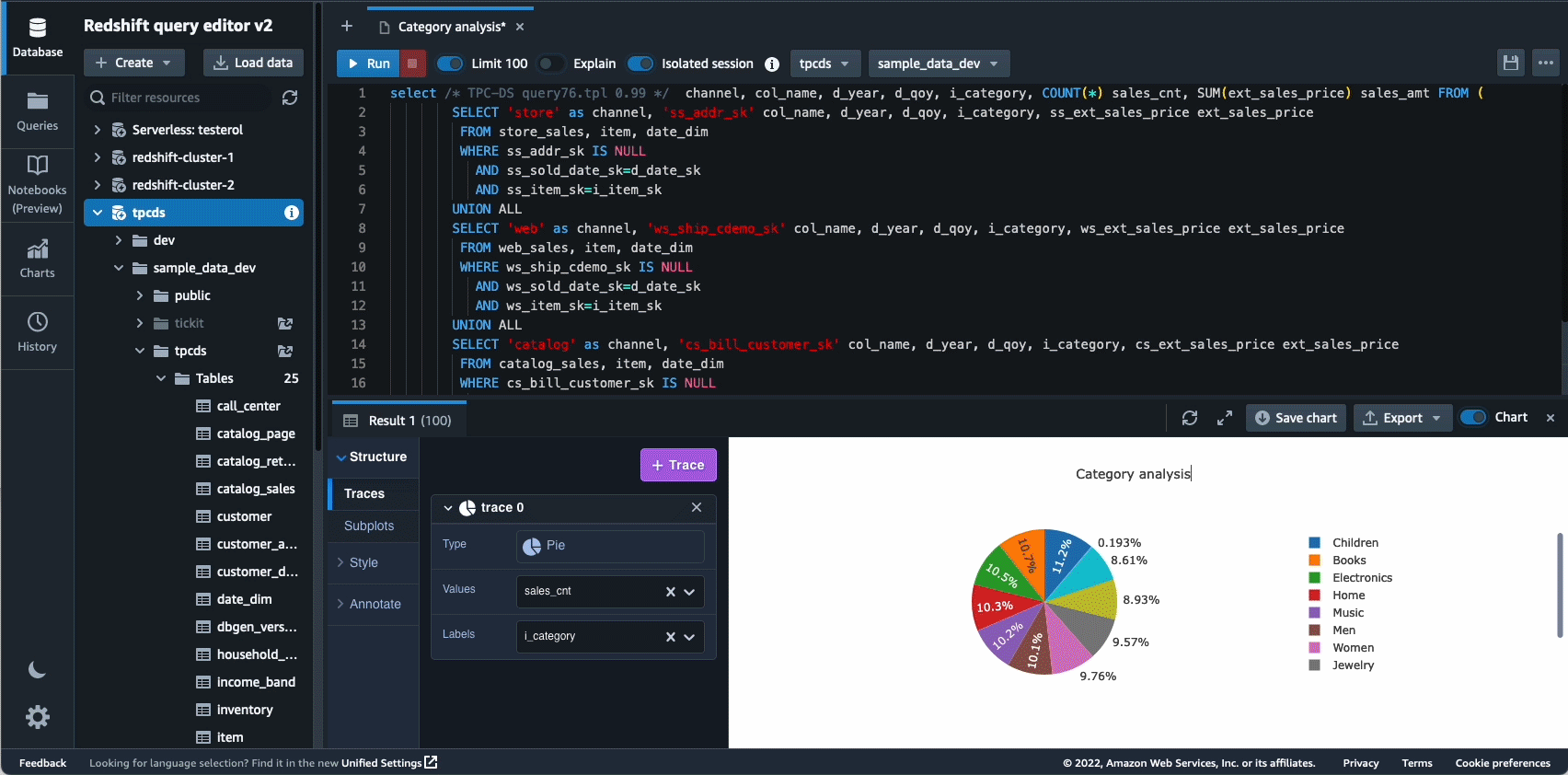
Autonomics — це ще одна сфера, де ми активно працюємо над використанням оптимізації на основі ML і наданням клієнтам сховища даних, що самонавчається та самооптимізується. У 2022 році ми оголосили про загальну доступність Автоматизовані матеріалізовані перегляди (AutoMVs), щоб покращити продуктивність запитів (зменшити загальний час виконання) без зусиль користувача шляхом автоматичного створення та підтримки матеріалізованих представлень. AutoMV у поєднанні з автоматичним оновленням, поступовим оновленням і автоматичним переписуванням запитів для матеріалізованих представлень зробили матеріалізовані представлення необхідними для обслуговування, автоматично забезпечуючи швидшу роботу. Крім того, автоматична оптимізація таблиці (ATO) можливість оптимізації схеми та автоматичне керування навантаженням (автоматичний WLM) для оптимізації робочого навантаження отримали подальші вдосконалення для кращої продуктивності запитів.
Легке введення даних
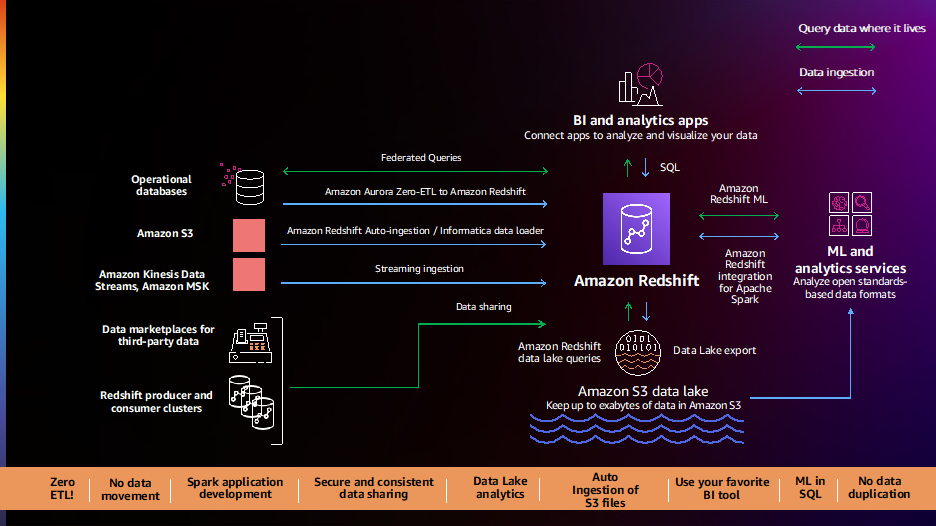
Клієнти повідомляють нам, що їхні дані розподіляються між кількома джерелами даних, такими як транзакційні бази даних, сховища даних, озера даних і системи великих даних. Їм потрібна гнучкість, щоб інтегрувати ці дані з конвеєрами даних без коду/низьким кодом, з нульовим ETL або аналізувати ці дані на місці, не переміщуючи їх. Клієнти повідомляють нам, що їхні поточні канали даних є складними, ручними, жорсткими та повільними, що призводить до неповних, суперечливих і застарілих переглядів даних, що обмежує розуміння. Клієнти просили нас про кращий шлях вперед, і ми раді оголосити про низку нових можливостей для спрощення та автоматизації конвеєрів даних.
Інтеграція Amazon Aurora zero-ETL з Amazon Redshift (попередній перегляд) дає змогу запускати аналітику майже в реальному часі та ML на петабайтах транзакційних даних. Він пропонує рішення без коду для створення транзакційних даних із кількох Амазонська Аврора бази даних, доступні в сховищах даних Amazon Redshift, за лічені секунди після запису в Aurora, усуваючи необхідність створювати та підтримувати складні конвеєри даних. За допомогою цієї функції клієнти Aurora також можуть отримати доступ до таких можливостей Amazon Redshift, як складна аналітика SQL, вбудований ML, обмін даними та об’єднаний доступ до кількох сховищ даних і озер даних. Ця функція тепер доступна в попередній версії для Amazon Aurora MySQL-сумісне видання версії 3 (з сумісністю з MySQL 8.0), і ви можете запросити доступ до попереднього перегляду.
Amazon Redshift тепер підтримує автокопіювання з Amazon S3 (попередній перегляд), щоб спростити завантаження даних Служба простого зберігання Amazon (Amazon S3) в Amazon Redshift. Тепер ви можете налаштувати безперервні правила прийому файлів (завдання копіювання), щоб відстежувати ваші шляхи Amazon S3 і автоматично завантажувати нові файли без необхідності використання додаткових інструментів або спеціальних рішень. Завдання копіювання можна відстежувати за допомогою системних таблиць, і вони автоматично відстежують раніше завантажені файли та виключають їх із процесу прийому, щоб запобігти дублюванню даних. Ця функція тепер доступна в попередньому перегляді; ви можете спробувати цю функцію, створивши новий кластер за допомогою доріжки попереднього перегляду.
Клієнти продовжують говорити нам, що їм потрібна миттєва аналітика в реальному часі, і ми раді повідомити, загальна доступність підтримки прийому потокових даних в Amazon Redshift для Потоки даних Amazon Kinesis та Amazon керував потоковим передаванням для Apache Kafka (Amazon MSK). Ця функція усуває необхідність ініціювати потокові дані в Amazon S3 перед надсиланням їх в Amazon Redshift, дозволяючи досягти низької затримки, яка вимірюється в секундах, одночасно надаючи сотні мегабайт потокових даних на секунду у ваші сховища даних. Ви можете використовувати SQL в Amazon Redshift для підключення та безпосереднього отримання даних із кількох потоків даних Kinesis або тем MSK, створювати автоматично оновлювані потокові матеріалізовані перегляди з перетвореннями поверх потоків безпосередньо для доступу до потокових даних, а також поєднувати дані в реальному часі з історичними дані для кращого розуміння. Наприклад, Adobe інтегрувала систему потокового передавання Amazon Redshift як частину своєї платформи Adobe Experience Platform для отримання й аналізу в режимі реального часу веб-потоків і даних про кліки програм і сеансів для різних програм, таких як CRM і програми підтримки клієнтів.
Клієнти сказали нам, що їм потрібна проста готова інтеграція між інструментами Amazon Redshift, BI та ETL (вилучення, перетворення та завантаження), а також бізнес-додатками, такими як Salesforce і Marketo. Ми раді повідомити про загальну доступність Завантажувач даних Informatica для Amazon Redshift, який дає змогу безкоштовно використовувати Informatica Data Loader для високошвидкісного та великого обсягу завантаження даних в Amazon Redshift. Ви можете просто вибрати опцію Informatica Data Loader на консолі Amazon Redshift. Увійшовши в Informatica Data Loader, ви можете підключитися до таких джерел, як Salesforce або Marketo, вибрати Amazon Redshift як ціль і почати завантажувати дані.
Обмін даними та співпраця
Клієнти продовжують повідомляти нам, що вони хочуть аналізувати всі свої дані першої та третьої сторони та надавати своїм клієнтам, партнерам і постачальникам повну інформацію на основі даних. У 2021 році ми запустили нові функції, як-от Обмін даними та Інтеграція AWS Data Exchange, щоб вам було легше аналізувати всі ваші дані та ділитися ними всередині та за межами вашої організації.
Чудовим прикладом клієнта, який використовує обмін даними, є Orion. Orion надає рішення в режимі реального часу як послугу (DaaS) для клієнтів у галузі фінансових послуг, таких як управління капіталом, управління активами та провайдери управління інвестиціями. Вони мають понад 2,500 джерел даних, які в основному є базами даних SQL Server, які знаходяться як на місці, так і в AWS. Дані передаються в Amazon Redshift за допомогою конекторів Kafka. У них є кластер-виробник, який отримує всі ці дані, а потім використовує обмін даними для обміну даними в режимі реального часу для співпраці. Це мультитенантна архітектура, яка обслуговує кілька клієнтів. Враховуючи чутливість їхніх даних, обмін даними — це спосіб забезпечити ізоляцію робочого навантаження між кластерами, а також безпечно надати ці дані кінцевим користувачам.
У 2022 році ми продовжили інвестувати в цю сферу, щоб покращити продуктивність, управління та продуктивність розробників за допомогою нових функцій, які полегшать, спростять і пришвидшать обмін даними та співпрацю над ними.
Оскільки клієнти створюють масштабні конфігурації спільного використання даних, вони попросили спрощене керування та безпеку спільних даних, і ми додаємо централізований контроль доступу за допомогою AWS Lake Formation для спільного доступу до даних Amazon Redshift, щоб увімкнути обмін живими даними в кількох сховищах даних Amazon Redshift. Завдяки цій функції Amazon Redshift тепер підтримує спрощене керування спільними ресурсами Amazon Redshift за допомогою Формування озера AWS як єдине скло для централізованого керування даними або дозволами на спільні ресурси. Ви можете переглядати, змінювати та перевіряти дозволи, включно з безпекою на рівні рядків і стовпців для таблиць і подання в спільному доступі до даних Amazon Redshift, використовуючи API Lake Formation і Консоль управління AWS, і дозволити іншим сховищам даних Amazon Redshift виявляти та використовувати спільні ресурси Amazon Redshift.
Наука про дані та машинне навчання
Клієнти продовжують говорити нам, що вони хочуть, щоб їхні дані та системи аналітики допомагали їм відповідати на широкий спектр питань, від того, що відбувається в їхньому бізнесі (описова аналітика), до того, чому це відбувається (діагностична аналітика) і що станеться в майбутньому (прогностична аналітика). Amazon Redshift надає такі функції, як комплексна аналітика SQL, аналітика озера даних тощо Amazon Redshift ML для клієнтів, щоб аналізувати свої дані та відкривати для себе потужну інформацію. Червоне зміщення ML інтегрує Amazon Redshift з Amazon SageMaker, повністю керована служба ML, що дозволяє створювати, навчати та розгортати моделі ML за допомогою знайомих команд SQL.
Клієнти також просили нас покращити інтеграцію між Amazon Redshift і Apache Spark, тому ми раді оголосити Інтеграція Amazon Redshift для Apache Spark щоб зробити сховища даних легко доступними для додатків на основі Spark. Тепер розробники, які використовують аналітику AWS і сервіси машинного навчання, наприклад Amazon EMR, Клей AWS, а SageMaker може без особливих зусиль створювати програми Apache Spark, які читають і записують у свої сховища даних Amazon Redshift. Amazon EMR і AWS Glue містять конектор Redshift-Spark, щоб ви могли легко підключитися до свого сховища даних із програм на основі Spark. Ви можете використовувати кілька можливостей висунення для таких операцій, як сортування, агрегування, обмеження, об’єднання та скалярні функції, щоб лише релевантні дані переміщувалися зі сховища даних Amazon Redshift у споживаючу програму Spark. Ви також можете зробити свої програми більш безпечними, використовуючи Управління ідентифікацією та доступом AWS (IAM) облікові дані для підключення до Amazon Redshift.
Безпечна та надійна аналітика
Клієнти продовжують говорити нам, що їхні сховища даних є критично важливими системами, які потребують високої доступності, надійності та безпеки. У 2022 році ми запустили низку нових функцій у цій сфері.
Amazon Redshift тепер підтримує Розгортання в кількох зонах доступності (у попередній версії) для кластерів на основі екземплярів RA3, що дозволяє запускати ваше сховище даних у кількох зонах доступності AWS одночасно та безперервно працювати в непередбачених сценаріях збоїв у зоні доступності. Підтримка Multi-AZ вже доступна для Redshift Serverless. Розгортання Amazon Redshift Multi-AZ дозволяє відновлювати роботу в разі збою зони доступності без втручання користувача. Доступ до сховища даних Amazon Redshift Multi-AZ доступний як до єдиного сховища даних з однією кінцевою точкою, і це допомагає вам максимізувати продуктивність шляхом автоматичного розподілу робочого навантаження між кількома зонами доступності. Для підтримки безперервності роботи під час непередбачених збоїв не потрібно змінювати програми.
У 2022 році ми запустили такі функції, як контроль доступу на основі ролей, безпека на рівні рядків і маскування даних (у попередній версії), щоб вам було простіше керувати доступом і вирішувати, хто має доступ до яких даних, зокрема маскування особистої інформації (ІПІ). ), як номери кредитних карток.
Ви можете використовувати контроль доступу на основі ролей (RBAC) для керування доступом кінцевого користувача до даних на широкому або детальному рівні на основі робочої ролі та дозволів кінцевого користувача. За допомогою RBAC ви можете створити роль за допомогою SQL, надати їй набір детальних дозволів, а потім призначити цю роль кінцевим користувачам. Ролям можна надати дозволи на рівні об’єкта, рівня стовпця та системи. Крім того, RBAC представляє готові системні ролі для адміністраторів баз даних, операторів, адміністраторів безпеки або налаштовані ролі.
Безпека на рівні рядків (RLS) спрощує проектування та реалізацію детального доступу до рядків у таблицях. За допомогою RLS ви можете обмежити доступ до підмножини рядків у таблиці на основі робочої ролі користувачів або дозволів за допомогою SQL.
Підтримка Amazon Redshift для динамічне маскування даних (DDM), який тепер доступний у попередній версії, дозволяє спростити захист ідентифікаційної інформації, наприклад номерів соціального страхування, номерів кредитних карток і номерів телефонів у вашому сховищі даних Amazon Redshift. За допомогою динамічного маскування даних ви контролюєте доступ до своїх даних за допомогою простих політик маскування на основі SQL, які визначають, як Amazon Redshift повертає конфіденційні дані користувачеві під час запиту. Ви можете створити політики маскування, щоб визначити узгоджені масковані значення даних із збереженням формату та незворотні. Ви можете застосувати політику маскування до певного стовпця або списку стовпців у таблиці. Крім того, у вас є можливість вибрати спосіб відображення замаскованих даних. Наприклад, ви можете повністю приховати дані, замінити часткові дійсні значення символами підстановки або визначити власний спосіб маскування даних за допомогою виразів SQL, Python або AWS Lambda призначені для користувача функції. Крім того, ви можете застосувати політику умовного маскування на основі інших стовпців, яка вибірково захищає дані стовпців у таблиці на основі значень в одному або кількох різних стовпцях.
Ми також анонсували вдосконалення для реєстрація аудиту, рідна інтеграція с Microsoft Azure Active Directoryта підтримка ролі IAM за замовчуванням у додаткових регіонах для подальшого спрощення керування безпекою.
Найкраща аналітика ефективності ціни
Клієнти продовжують говорити нам, що їм потрібні швидкі та економічно ефективні сховища даних, які забезпечують високу продуктивність у будь-якому масштабі та зберігають низькі витрати. З першого дня Запуск Amazon Redshift у 2012 році, ми застосували підхід, що керується даними, і використали телеметрію флоту, щоб створити службу хмарного сховища даних, яка дає вам найкращу цінову ефективність у будь-якому масштабі. З роками ми розвивалися Архітектура Amazon Redshift і запустив такі функції, як Кероване сховище Redshift (RMS) для розділення сховища та обчислень, Спектр червоного зсуву Amazon для запитів озера даних, автоматична оптимізація таблиці для оптимізації фізичної схеми, автоматичне керування навантаженням щоб визначити пріоритетність робочих навантажень і розподілити потрібний обчислювальний ресурс і пам’ять, зміна розміру кластера для вертикального масштабування обчислень і зберігання, а також паралельне масштабування для динамічного масштабування обчислень. Наші показники ефективності продовжує демонструвати лідерство Amazon Redshift у цінових показниках.
У 2022 році ми додали нові функції, наприклад загальну доступність масштабування паралельності для операцій запису наприклад COPY, INSERT, UPDATE і DELETE для підтримки практично необмеженої кількості одночасних користувачів і запитів. Ми також запровадили покращення продуктивності для обробки даних на основі рядків за допомогою векторизованого сканування легких, ефективних ЦП стовпців рядків, закодованих словником, що дозволяє механізму бази даних працювати безпосередньо над стисненими даними.
Ми також додали підтримку таких операторів SQL, як ВЕЛИКИЙ (єдиний оператор для вставок або оновлень); CONNECY_BY (для ієрархічних запитів); ГРУПУВАННЯ НАБОРІВ, РОЛЛУП і КУБ (для багатовимірної звітності); і збільшили розмір типу даних SUPER до 16 МБ, щоб полегшити вам перехід із застарілих сховищ даних на Amazon Redshift.
Висновок
Наші клієнти продовжують говорити нам, що дані та аналітика залишаються для них головним пріоритетом, а потреба рентабельно отримувати більшу цінність для бізнесу з їхніх даних у ці часи є гострішою, ніж будь-коли в минулому. Amazon Redshift як ваше хмарне сховище даних дає змогу виконувати комплексну аналітику SQL із масштабуванням і продуктивністю на терабайтах і петабайтах структурованих і неструктурованих даних і робити інформацію широко доступною за допомогою популярних інструментів BI та аналітики.
Незважаючи на те, що ми запустили понад 40 функцій у 2022 році, і темп інновацій продовжує прискорюватися, це залишається днем 1, і ми з нетерпінням чекаємо від вас, як ці функції допоможуть вам розблокувати більше цінності для ваших організацій. Ми запрошуємо вас спробувати ці нові функції та зв’язатися з нами через вашу команду облікових записів AWS, якщо у вас є додаткові коментарі.
Про автора
 Манан Гоель є лідером продукту Go-To-Market для аналітичних служб AWS, включаючи Amazon Redshift в AWS. Він має понад 25 років досвіду та добре розбирається в базах даних, сховищах даних, бізнес-аналітиці та аналітиці. Манан має ступінь магістра ділового адміністрування в Університеті Дьюка та ступінь бакалавра електроніки та комунікацій.
Манан Гоель є лідером продукту Go-To-Market для аналітичних служб AWS, включаючи Amazon Redshift в AWS. Він має понад 25 років досвіду та добре розбирається в базах даних, сховищах даних, бізнес-аналітиці та аналітиці. Манан має ступінь магістра ділового адміністрування в Університеті Дьюка та ступінь бакалавра електроніки та комунікацій.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- здатність
- МЕНЮ
- прискорювати
- доступ
- Доступ до даних
- доступний
- доступною
- рахунки
- Achieve
- через
- активний
- активно
- доданий
- доповнення
- Додатковий
- Додатково
- саман
- ВСІ
- дозволяє
- вже
- Amazon
- Amazon EMR
- аналітики
- аналітика
- аналізувати
- Аналізуючи
- та
- Оголосити
- оголошений
- Інший
- відповідь
- Apache
- Apache Spark
- Інтерфейси
- додаток
- застосування
- Застосовувати
- підхід
- архітектура
- ПЛОЩА
- області
- штучний
- штучний інтелект
- активи
- управління активами
- аудит
- Аврора
- автор
- автоматичний
- автоматизувати
- автоматичний
- автоматично
- наявність
- доступний
- AWS
- Клей AWS
- Лазурний
- заснований
- основа
- становлення
- перед тим
- буття
- КРАЩЕ
- Краще
- між
- Великий
- Великий даних
- біллінг
- Перерва
- широкий
- Бродрідж
- будувати
- Створюємо
- вбудований
- бізнес
- Бізнес-додатки
- забезпечення безперервності бізнесу
- бізнес-аналітика
- можливості
- потужність
- карта
- випадок
- випадків
- Зміни
- символи
- Вибирати
- Вибираючи
- клієнтів
- хмара
- кластер
- співпрацювати
- співробітництво
- збір
- Колонка
- Колони
- об'єднувати
- комбінований
- коментарі
- зв'язку
- сумісність
- повністю
- комплекс
- компонент
- обчислення
- одночасно
- З'єднуватися
- послідовний
- Консоль
- спожитий
- продовжувати
- триває
- триває
- безперервний
- контроль
- рентабельним
- витрати
- охоплює
- створювати
- створення
- Повноваження
- кредит
- кредитна картка
- кредити
- CRM
- Поточний
- виготовлений на замовлення
- клієнт
- підтримка клієнтів
- Клієнти
- налаштувати
- дані
- Обмін даними
- Озеро даних
- обробка даних
- обмін даними
- сховище даних
- сховища даних
- керовані даними
- Database
- базами даних
- день
- глибше
- доставляти
- демонструвати
- розгортання
- розгортання
- дизайн
- Визначати
- Розробник
- розробників
- різний
- безпосередньо
- відкрити
- відкритий
- обговорювати
- розподілений
- розповсюдження
- Герцог
- герцогський університет
- під час
- динамічний
- легше
- легко
- редактор
- зусилля
- електроніка
- Усуває
- усуваючи
- включіть
- дозволяє
- дозволяє
- Кінцева точка
- двигун
- Машинобудування
- Ефір (ETH)
- все
- еволюціонували
- приклад
- обмін
- збуджений
- Розширювати
- досвід
- дослідити
- вирази
- витяг
- Провал
- знайомий
- ШВИДКО
- швидше
- особливість
- риси
- філе
- Файли
- фінансовий
- фінансові послуги
- фінансові
- знайти
- ФЛЕТ
- Гнучкість
- освіта
- Вперед
- Безкоштовна
- від
- повністю
- Функції
- далі
- майбутнє
- Загальне
- отримати
- GIF
- Давати
- даний
- дає
- дає
- скло
- Вихід на ринок
- управління
- надавати
- надається
- великий
- траплятися
- щасливий
- Жорсткий
- має
- охорона здоров'я
- слух
- допомога
- допомагає
- приховувати
- Високий
- історичний
- тримає
- Як
- How To
- HTML
- HTTPS
- Сотні
- IAM
- Особистість
- реалізація
- удосконалювати
- поліпшений
- поліпшення
- in
- У тому числі
- збільшений
- промисловість
- інформація
- Інфраструктура
- інновація
- Вставки
- розуміння
- інтегрувати
- інтегрований
- Інтеграція
- інтеграція
- Інтелект
- втручання
- введені
- Вводить
- Invest
- інвестиції
- запрошувати
- ізоляція
- IT
- робота
- Джобс
- приєднатися
- липень
- кафка
- тримати
- зберігання
- ключ
- Потоки даних Kinesis
- озеро
- масштабний
- Затримка
- запуск
- запущений
- лідер
- Керівництво
- вивчення
- Legacy
- рівень
- легкий
- МЕЖА
- список
- жити
- живі дані
- загрузка
- завантажувач
- погрузка
- подивитися
- низький
- машина
- навчання за допомогою машини
- made
- підтримувати
- обслуговування
- зробити
- Робить
- управляти
- вдалося
- управління
- керівництво
- Marketo
- маска
- Максимізувати
- пам'ять
- мігрувати
- ML
- Моделі
- сучасний
- змінювати
- контрольований
- моніторинг
- більше
- переміщення
- множинний
- MySQL
- рідний
- Необхідність
- необхідний
- потреби
- Нові
- Нові можливості
- номер
- номера
- Пропозиції
- ONE
- відкрити
- працювати
- операція
- операції
- оператор
- Оператори
- оптимізація
- варіант
- організація
- організації
- Інше
- Недоліки
- поза
- власний
- алюр
- пакет
- pane
- частина
- партнери
- Минуле
- Платити
- пелотон
- продуктивність
- Дозволи
- Особисто
- телефон
- фізичний
- пій
- місце
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- задоволений
- Політика
- політика
- популярний
- пошта
- потужний
- Прогностична аналітика
- запобігати
- попередній перегляд
- раніше
- price
- в першу чергу
- Пріоритетність
- пріоритет
- процес
- обробка
- виробник
- Product
- продуктивність
- захищає
- забезпечувати
- Постачальник
- провайдери
- забезпечує
- забезпечення
- Python
- питань
- швидко
- діапазон
- досягати
- Читати
- реальний
- реального часу
- дані в режимі реального часу
- отримує
- Відновлювати
- зменшити
- райони
- доречний
- надійність
- надійний
- залишається
- замінювати
- звітом
- Звітність
- Вимога
- обмежити
- в результаті
- Умови повернення
- огляд
- перезапису
- Багаті
- жорсткий
- Роль
- ролі
- згорнути
- Правила
- прогін
- біг
- мудрець
- Salesforce
- шкала
- ваги
- Масштабування
- сценарії
- наука
- Вчені
- другий
- seconds
- безпечний
- безпечно
- безпеку
- чутливий
- Чутливість
- Без сервера
- служить
- обслуговування
- Послуги
- Сесія
- комплект
- набори
- кілька
- Поділитись
- загальні
- поділ
- Показувати
- простий
- спрощений
- спростити
- просто
- одночасно
- з
- один
- Сидячий
- Розмір
- сповільнювати
- So
- соціальна
- рішення
- Рішення
- деякі
- Джерела
- Іскритися
- конкретний
- SQL
- Стажування
- зберігання
- магазинів
- Стратегія
- потоковий
- потоковий
- потоки
- структурований
- структуровані та неструктуровані дані
- такі
- Super
- постачальники
- підтримка
- Опори
- система
- Systems
- таблиця
- Мета
- команда
- Команда
- Майбутнє
- їх
- третя сторона
- тисячі
- через
- час
- times
- до
- інструмент
- інструменти
- топ
- теми
- Усього:
- торкатися
- трек
- поїзд
- транзакційний
- Перетворення
- перетворень
- повсюдний
- непередбачений
- університет
- необмежений
- відімкнути
- Оновити
- Updates
- us
- використання
- користувач
- користувачі
- використовує
- значення
- Цінності
- різний
- версія
- вид
- думки
- фактично
- Склад
- Складування
- Багатство
- управління активами
- Web
- Web-Based
- Що
- Що таке
- який
- в той час як
- ВООЗ
- широкий
- Широкий діапазон
- широко
- волі
- в
- без
- Work
- працював
- робочий
- світовий
- запис
- письмовий
- рік
- років
- вашу
- зефірнет
- зони