Зображення на jcomp on Freepik
Часовий ряд – це унікальний набір даних у галузі даних. Дані записуються з певною періодичністю (наприклад, щодня, щотижня, щомісяця тощо), і кожне спостереження пов’язане з іншим. Дані часових рядів є цінними, коли ви хочете проаналізувати, що відбувається з вашими даними з часом, і створити майбутні прогнози.
Прогнозування часових рядів — це метод створення майбутніх прогнозів на основі даних історичних часових рядів. Існує багато статистичних методів прогнозування часових рядів, наприклад АРІМА or Експоненційне згладжування.
Прогнозування часових рядів часто зустрічається в бізнесі, тому спеціалісту з обробки даних корисно знати, як розробити модель часових рядів. У цій статті ми дізнаємося, як прогнозувати часові ряди за допомогою двох популярних пакетів прогнозування Python; statsmodels і Prophet. Давайте вникнемо в це.
Команда статистики Пакет Python — це пакет із відкритим вихідним кодом, який пропонує різні статистичні моделі, зокрема модель прогнозування часових рядів. Давайте спробуємо пакет із прикладом набору даних. У цій статті буде використано Часовий ряд цифрової валюти дані з Kaggle (CC0: громадське надбання).
Давайте очистимо дані та подивимося на набір даних, який у нас є.
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
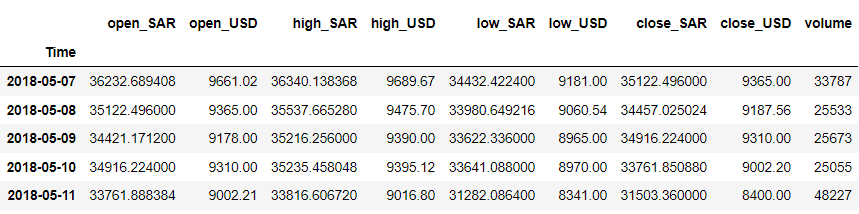
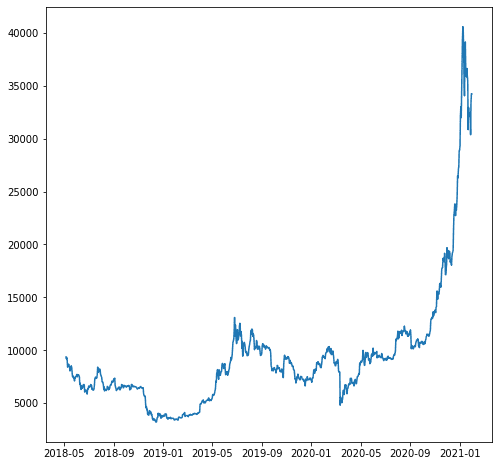
Для нашого прикладу, скажімо, ми хочемо спрогнозувати змінну 'close_USD'. Давайте подивимося, як змінюються дані з часом.
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
Давайте побудуємо модель прогнозу на основі наших даних вище. Перед моделюванням давайте розділимо дані на тренувальні та тестові дані.
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
Ми не розбиваємо дані випадковим чином, оскільки це дані часових рядів, і нам потрібно зберегти порядок. Замість цього ми намагаємося мати попередні дані про поїзди, а тестові дані – з останніх даних.
Давайте використаємо statsmodels для створення моделі прогнозу. The statsmodel надає багато API моделі часових рядів, але ми б використали модель ARIMA як приклад.
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
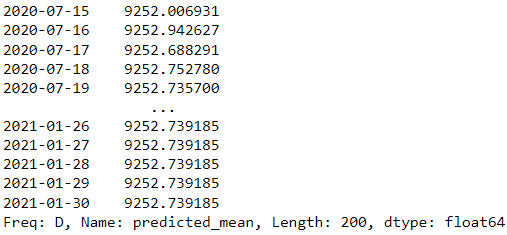
У наведеному вище прикладі ми використовуємо модель ARIMA зі statsmodels як модель прогнозування та намагаємося передбачити наступні 200 днів.
Чи хороший результат моделі? Спробуємо дати їм оцінку. Оцінка моделі часових рядів зазвичай використовує візуалізаційний графік для порівняння фактичних і прогнозованих показників із такими показниками регресії, як середня абсолютна похибка (MAE), середньоквадратична похибка (RMSE) і MAPE (середня абсолютна відсоткова похибка).
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
Оцінка вище виглядає добре, але давайте подивимося, як це, коли ми візуалізуємо їх.
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
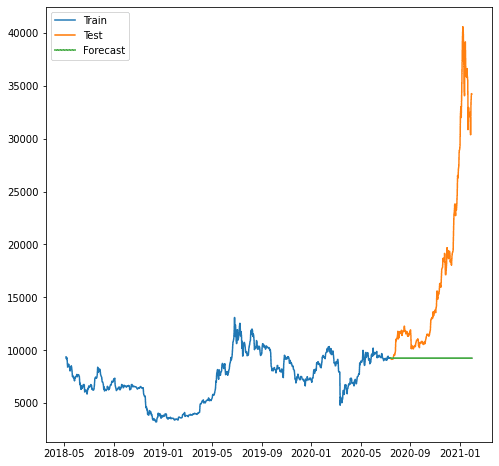
Як ми бачимо, прогноз був гіршим, оскільки наша модель не може передбачити тенденцію до зростання. Модель ARIMA, яку ми використовуємо, виглядає занадто простою для прогнозування.
Можливо, буде краще, якщо ми спробуємо використати іншу модель поза statsmodels. Давайте спробуємо відомий пакет prophet від Facebook.
Пророк це пакет моделей для прогнозування часових рядів, який найкраще працює на даних із сезонним впливом. Prophet також вважався надійною моделлю прогнозування, оскільки він міг обробляти відсутні дані та викиди.
Давайте спробуємо пакет Prophet. Спочатку нам потрібно встановити пакет.
pip install prophet
Після цього ми повинні підготувати наш набір даних для навчання моделі прогнозування. У Prophet є конкретна вимога: стовпець часу має бути названо «ds», а значення — «y».
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
Коли наші дані готові, давайте спробуємо створити прогнозний прогноз на основі даних.
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
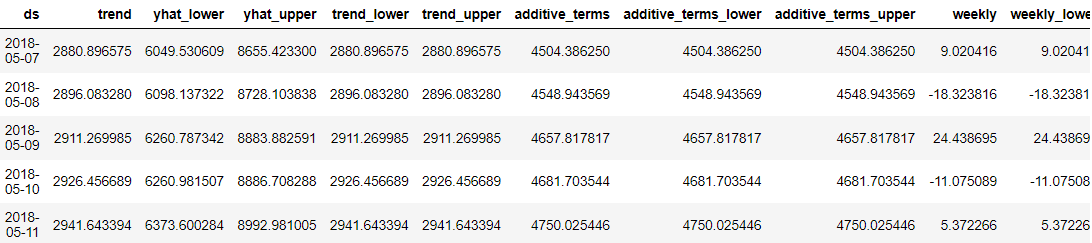
Що чудово в Prophet, так це те, що кожна точка прогнозних даних була детально описана для розуміння користувачів. Однак важко зрозуміти результат лише за даними. Отже, ми могли б спробувати візуалізувати їх за допомогою Prophet.
model.plot(predictions)
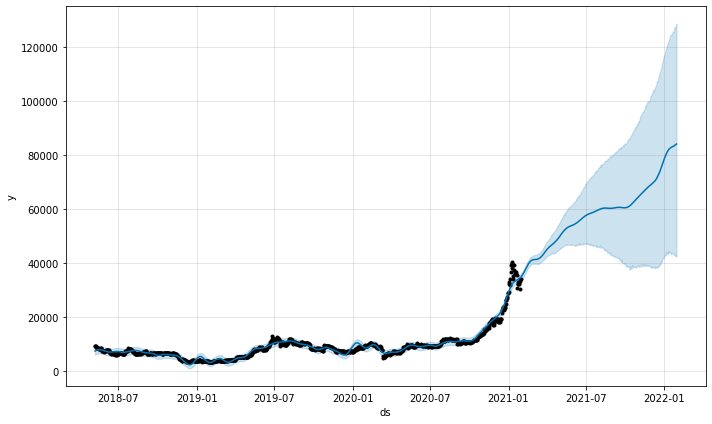
Функція графіка прогнозів з моделі дасть нам зрозуміти, наскільки впевненими були прогнози. З наведеного вище графіка ми бачимо, що прогноз має висхідну тенденцію, але зі збільшенням невизначеності, чим довшими є прогнози.
Також можна перевірити компоненти прогнозу за допомогою наступної функції.
model.plot_components(predictions)
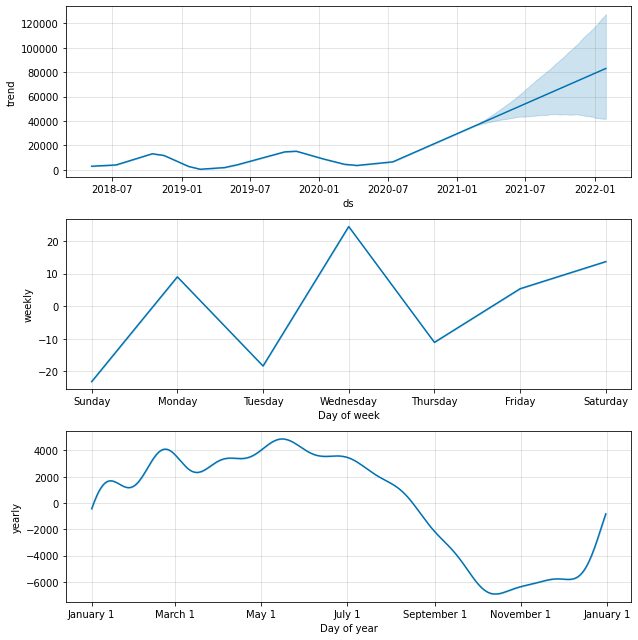
За замовчуванням ми отримаємо тенденцію даних із річною та тижневою сезонністю. Це хороший спосіб пояснити, що відбувається з нашими даними.
Чи можна було б оцінити і модель Пророка? Абсолютно. Prophet містить діагностичне вимірювання, яке ми можемо використовувати: перехресна перевірка часових рядів. Метод використовує частину історичних даних і кожного разу підганяє модель, використовуючи дані до точки відсічення. Потім Пророк порівняв передбачення з реальними. Давайте спробуємо скористатися кодом.
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
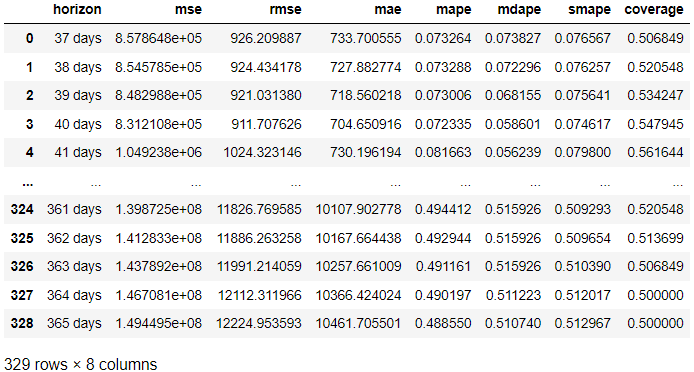
У результатах вище ми отримали результат оцінки з фактичного результату в порівнянні з прогнозом для кожного прогнозованого дня. Також можна візуалізувати результат за допомогою наступного коду.
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
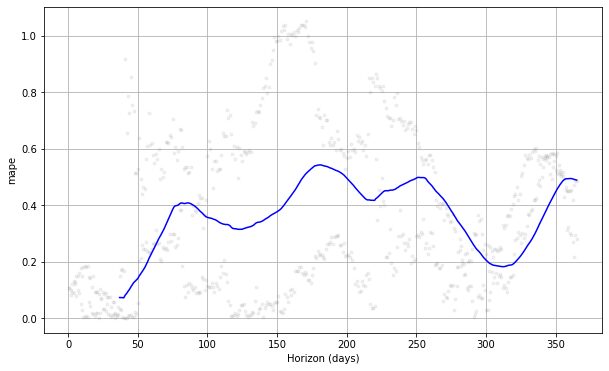
Якщо ми побачимо графік вище, ми побачимо, що похибка передбачення змінювалася за днями, і в деякі моменти вона могла досягати 50% похибки. Таким чином, ми можемо захотіти ще більше налаштувати модель, щоб виправити помилку. Ви можете перевірити документація для подальшого дослідження.
Прогнозування є одним із поширених випадків, які трапляються в бізнесі. Одним із простих способів розробки моделі прогнозування є використання пакетів statsforecast і Prophet Python. У цій статті ми дізнаємося, як створити модель прогнозу та оцінити її за допомогою statsforecast і Prophet.
Корнеліус Юдха Віджая є помічником менеджера з питань науки про дані та автора даних. Працюючи повний робочий день в Allianz Indonesia, він любить ділитися порадами щодо Python і даних у соціальних мережах і друкованих ЗМІ.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- :є
- $UP
- 1
- 11
- 7
- 8
- 9
- a
- МЕНЮ
- вище
- абсолют
- абсолютно
- Achieve
- придбаний
- Allianz
- аналізувати
- та
- Інший
- Інтерфейси
- ЕСТЬ
- стаття
- AS
- Помічник
- At
- заснований
- BE
- оскільки
- перед тим
- корисний
- КРАЩЕ
- Краще
- між
- будувати
- бізнес
- by
- обчислювати
- CAN
- випадків
- CC0
- перевірка
- код
- Колонка
- Колони
- загальний
- порівняти
- порівняний
- Компоненти
- впевнений
- вважається
- може
- охоплення
- створювати
- Валюта
- щодня
- дані
- наука про дані
- вчений даних
- Дата
- день
- Днів
- dc
- дефолт
- докладно
- розвивати
- домен
- Не знаю
- e
- кожен
- Раніше
- ефекти
- помилка
- і т.д.
- оцінювати
- оцінка
- Кожен
- приклад
- Пояснювати
- дослідження
- знаменитий
- поле
- кінець
- Перший
- відповідати
- виправляти
- після
- для
- Прогноз
- від
- функція
- далі
- майбутнє
- отримати
- GitHub
- добре
- графік
- великий
- обробляти
- відбувається
- Жорсткий
- Мати
- історичний
- горизонт
- Як
- How To
- Однак
- HTML
- HTTPS
- імпорт
- in
- includes
- У тому числі
- збільшений
- зростаючий
- індекс
- Індонезія
- початковий
- встановлювати
- замість
- IT
- JPG
- KDnuggets
- Знати
- останній
- УЧИТЬСЯ
- довше
- подивитися
- ВИГЛЯДИ
- зробити
- менеджер
- багато
- matplotlib
- Медіа
- метод
- методика
- Метрика
- може бути
- відсутній
- модель
- моделювання
- Моделі
- щомісячно
- Названий
- Необхідність
- потреби
- наступний
- нумпі
- отримувати
- of
- пропонує
- on
- ONE
- з відкритим вихідним кодом
- порядок
- Інше
- поза
- пакет
- пакети
- панди
- параметри
- частина
- Викрійки
- відсоток
- виконувати
- plato
- Інформація про дані Платона
- PlatoData
- точка
- точок
- популярний
- це можливо
- передбачати
- прогноз
- Прогнози
- Готувати
- забезпечувати
- забезпечує
- громадськість
- Python
- готовий
- записаний
- регресія
- пов'язаний
- вимога
- результат
- результати
- міцний
- корінь
- наука
- вчений
- Здається,
- Серія
- комплект
- Поділитись
- простий
- So
- соціальна
- соціальні медіа
- деякі
- конкретний
- розкол
- площа
- статистичний
- такі
- Приймати
- тест
- Що
- Команда
- Їх
- час
- Часовий ряд
- Поради
- до
- занадто
- поїзд
- Навчання
- Trend
- Невизначеність
- розуміти
- створеного
- БЕЗ ІМЕНИ
- вгору
- us
- використання
- користувачі
- зазвичай
- Цінний
- значення
- різний
- через
- візуалізації
- шлях..
- тижні
- ДОБРЕ
- Що
- в той час як
- Вікіпедія
- волі
- з
- в
- робочий
- працює
- б
- письменник
- лист
- вашу
- зефірнет