AWS Glue Studio це графічний інтерфейс, який дозволяє легко створювати, запускати та контролювати завдання вилучення, трансформації та завантаження (ETL) у Клей AWS. Це дозволяє візуально створювати робочі процеси перетворення даних за допомогою вузлів, які представляють різні етапи обробки даних, які пізніше автоматично перетворюються на код для запуску.
AWS Glue Studio нещодавно випущений Ще 10 візуальних трансформацій, які дозволяють створювати складніші завдання візуально без навичок програмування. У цій публікації ми обговорюємо потенційні випадки використання, які відображають загальні потреби ETL.
Нові перетворення, які будуть продемонстровані в цьому дописі: об’єднання, розділення рядка, масив до стовпців, додавання поточної позначки часу, зведення рядків до стовпців, скасування зведення стовпців до рядків, пошук, рознесення масиву або зіставлення в стовпці, похідний стовпець і обробка автобалансу .
Огляд рішення
У цьому випадку ми маємо декілька файлів JSON з операціями з опціонами на акції. Ми хочемо зробити деякі перетворення перед збереженням даних, щоб полегшити їх аналіз, а також хочемо створити окремий підсумок набору даних.
У цьому наборі даних кожен рядок представляє торгівлю опціонними контрактами. Опціони – це фінансові інструменти, які надають право, але не зобов’язання, купувати чи продавати акції за фіксованою ціною (так звана страйкова ціна) до визначеного терміну придатності.
Вхідні дані
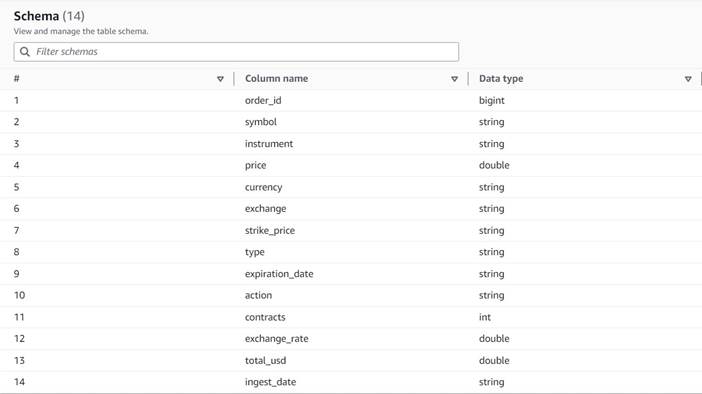
Дані відповідають такій схемі:
- order_id – Унікальний ідентифікатор
- символ – Код, який зазвичай складається з кількох літер для ідентифікації корпорації, яка випускає базові акції
- інструмент – Назва, яка ідентифікує конкретний варіант, який купується або продається
- валюта – Код валюти ISO, у якій виражено ціну
- price – Сума, сплачена за придбання кожного опціонного контракту (на більшості бірж один контракт дозволяє купити або продати 100 акцій)
- обмін – Код біржового центру або місця, де торгувався опціон
- проданий – Список кількості контрактів, які були виділені для виконання замовлення на продаж, коли це торгівля на продаж
- куплений – Список кількості контрактів, які були виділені для виконання замовлення на купівлю, коли це купівля
Нижче наведено зразок синтетичних даних, створених для цієї публікації:
Вимоги ETL
Ці дані мають низку унікальних характеристик, які часто зустрічаються в старих системах, які ускладнюють використання даних.
Нижче наведено вимоги ETL:
- Назва приладу містить цінну інформацію, яку люди повинні зрозуміти; ми хочемо нормалізувати його в окремі стовпці для легшого аналізу.
- Атрибути
boughtтаsoldє взаємовиключними; ми можемо об’єднати їх в одну колонку з номерами контрактів і створити іншу колонку, у якій буде вказано, чи були контракти куплені чи продані в цьому порядку. - Ми хочемо зберегти інформацію про розподіл окремих контрактів, але як окремі рядки замість того, щоб змушувати користувачів мати справу з масивом чисел. Ми могли б скласти цифри, але втратили б інформацію про те, як було виконано замовлення (вказує на ліквідність ринку). Замість цього ми вирішили денормалізувати таблицю, щоб кожен рядок містив одну кількість контрактів, розбиваючи замовлення з кількома номерами на окремі рядки. У стисненому стовпчастому форматі додатковий розмір набору даних цього повторення часто невеликий, коли застосовано стиснення, тому прийнятно зробити набір даних легшим для запиту.
- Ми хочемо створити зведену таблицю обсягу для кожного типу опціону (колл і пут) для кожної акції. Це вказує на ринкові настрої для кожної акції та ринку в цілому (жадібність проти страху).
- Щоб увімкнути загальні торговельні підсумки, ми хочемо надати для кожної операції загальну суму та стандартизувати валюту в доларах США, використовуючи приблизне посилання на конвертацію.
- Ми хочемо додати дату, коли відбулися ці перетворення. Це може бути корисно, наприклад, щоб мати довідку про те, коли було здійснено конвертацію валюти.
Виходячи з цих вимог, робота дасть два результати:
- Файл CSV із підсумком кількості контрактів для кожного символу та типу
- Таблиця каталогу для збереження історії замовлень після виконання вказаних перетворень
Передумови
Вам знадобиться власне відро S3, щоб слідувати цьому випадку використання. Щоб створити нове відро, див Створення відра.
Створення синтетичних даних
Щоб слідувати цій публікації (або експериментувати з такими даними самостійно), ви можете створити цей набір даних синтетично. Наведений нижче сценарій Python можна запустити в середовищі Python із встановленим Boto3 і доступом до нього Служба простого зберігання Amazon (Amazon S3).
Щоб згенерувати дані, виконайте такі кроки:
- У AWS Glue Studio створіть нове завдання з опцією Редактор сценаріїв оболонки Python.
- Дайте роботу назву та на Деталі роботи виберіть a відповідна роль і назва сценарію Python.
- У Деталі роботи розділ, розшир Розширені властивості і прокрутіть вниз до Параметри роботи.
- Введіть параметр з назвою
--bucketі призначте як значення назву сегмента, який ви хочете використовувати для зберігання зразків даних. - Введіть такий сценарій у редактор оболонки AWS Glue:
- Запустіть завдання та зачекайте, доки на вкладці «Запуски» воно не відобразиться як успішне завершення (це має зайняти кілька секунд).
Кожен запуск генеруватиме файл JSON із 1,000 рядків у вказаному сегменті та префіксі transformsblog/inputdata/. Ви можете запустити завдання кілька разів, якщо хочете протестувати з більшою кількістю вхідних файлів.
Кожен рядок у синтетичних даних є рядком даних, що представляє об’єкт JSON, як показано нижче:
Створіть візуальне завдання AWS Glue
Щоб створити візуальне завдання AWS Glue, виконайте такі дії:
- Перейдіть до AWS Glue Studio та створіть завдання за допомогою цієї опції Візуал із чистим полотном.
- Редагувати
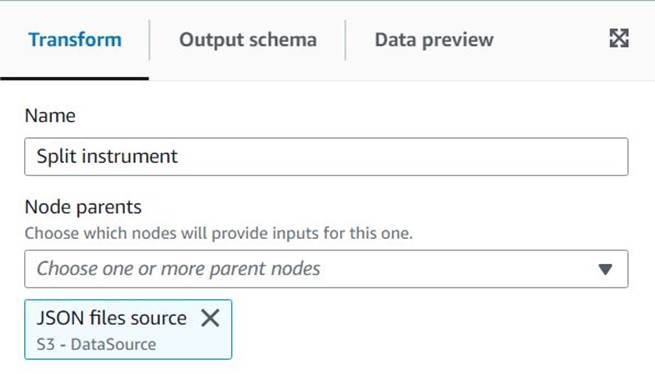
Untitled jobдати йому назву та призначити роль, яка підходить для AWS Glue на Деталі роботи Вкладка. - Додайте джерело даних S3 (ви можете назвати його
JSON files source) і введіть URL-адресу S3, під якою зберігаються файли (наприклад,s3://<your bucket name>/transformsblog/inputdata/), а потім виберіть JSON як формат даних. - Select Виведіть схему тому він встановлює вихідну схему на основі даних.
З цього вихідного вузла ви будете продовжувати зв’язувати перетворення. Додаючи кожне перетворення, переконайтеся, що вибраний вузол є останнім доданим, щоб він був призначений як батьківський, якщо інше не зазначено в інструкціях.
Якщо ви не вибрали належного батьківського елемента, ви завжди можете змінити його, вибравши його та вибравши іншого батьківського елемента на панелі конфігурації.
Для кожного доданого вузла ви дасте йому конкретну назву (тобто призначення вузла відображається на графіку) і конфігурацію на Перетворення Вкладка.
Кожного разу, коли перетворення змінює схему (наприклад, додає новий стовпець), схему виводу потрібно оновлювати, щоб вона була видимою для перетворень, що знаходяться нижче за течією. Ви можете редагувати вихідну схему вручну, але практичніше та безпечніше робити це за допомогою попереднього перегляду даних.
Крім того, таким чином ви можете переконатися, що перетворення працює належним чином. Для цього відкрийте Попередній перегляд даних вкладку з вибраним перетворенням і розпочніть сеанс попереднього перегляду. Переконавшись, що перетворені дані виглядають належним чином, перейдіть до Схема виведення та виберіть Використовуйте схему попереднього перегляду даних для автоматичного оновлення схеми.
Коли ви додаєте нові види перетворень, попередній перегляд може відображати повідомлення про відсутню залежність. Коли це станеться, виберіть Завершити сесію і почати новий, тому попередній перегляд підбирає новий тип вузла.
Отримайте інформацію про інструмент
Давайте почнемо з інформації про назву інструмента, щоб нормалізувати її в стовпці, до яких легше отримати доступ у результуючій вихідній таблиці.
- Додавати Розділити рядок вузол і назвіть його
Split instrument, який токенізуватиме стовпець інструменту за допомогою регулярного виразу пробілу:s+(у цьому випадку підійде один пробіл, але цей спосіб більш гнучкий і візуально зрозуміліший). - Ми хочемо зберегти оригінальну інформацію про інструмент, тому введіть нову назву стовпця для розділеного масиву:
instrument_arr.
- Додайте Масив до стовпців вузол і назвіть його
Instrument columnsщоб перетворити щойно створений стовпець масиву в нові поля, за виняткомsymbol, для якого вже є колонка. - Виберіть стовпець
instrument_arr, пропустіть перший маркер і скажіть йому витягнути вихідні стовпціmonth, day, year, strike_price, typeза допомогою індексів2, 3, 4, 5, 6(пробіли після ком призначені для зручності читання, вони не впливають на конфігурацію).
Витягнутий рік виражається лише двома цифрами; давайте поставимо проміжок, щоб припустити, що це в цьому столітті, якщо вони просто використовують дві цифри.
- Додавати Похідний стовпець вузол і назвіть його
Four digits year. -
Що натомість? Створіть віртуальну версію себе у
yearяк похідний стовпець, щоб він замінив його, і введіть такий вираз SQL:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Для зручності ми будуємо expiration_date поле, яке користувач може мати як посилання на останню дату, коли опцію можна використати.
- Додавати Об’єднати стовпці вузол і назвіть його
Build expiration date. - Назвіть новий стовпець
expiration_date, виділіть стовпціyear,monthтаday(у такому порядку) і дефіс як пробіл.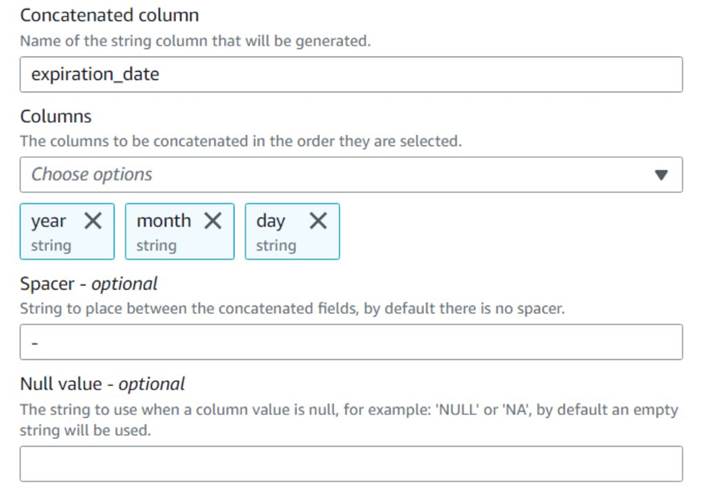
Поки що діаграма має виглядати як наведений нижче приклад.
![]()
Попередній перегляд даних нових стовпців має виглядати так, як наведений нижче знімок екрана.
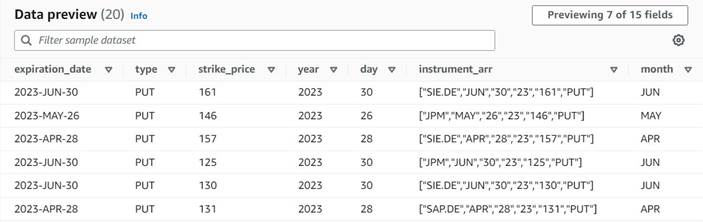
Унормувати кількість договорів
Кожен із рядків у даних вказує кількість контрактів кожного опціону, які були куплені чи продані, і партії, за якими були виконані замовлення. Не втрачаючи інформації про окремі партії, ми хочемо мати кожну суму в окремому рядку з єдиним значенням суми, тоді як решта інформації буде відтворено в кожному створеному рядку.
Спочатку давайте об’єднаємо суми в один стовпець.
- Додайте Скасувати зведення стовпців у рядки вузол і назвіть його
Unpivot actions. - Виберіть колонки
boughtтаsoldщоб скасувати зведення та зберегти імена та значення в названих стовпцяхactionтаcontracts, відповідно.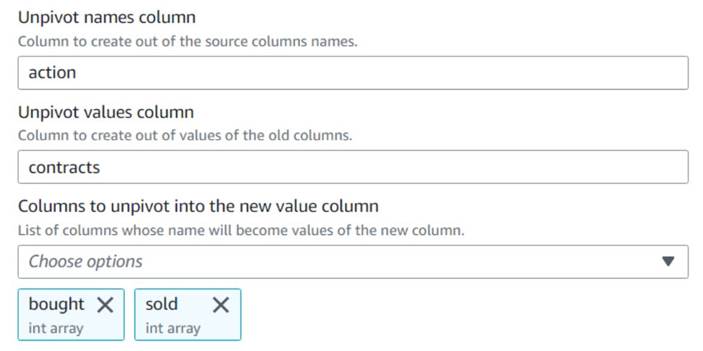
Зверніть увагу на попередній перегляд нового стовпцяcontractsвсе ще залишається масивом чисел після цього перетворення.
- Додайте Розбийте масив або карту на рядки рядок з назвою
Explode contracts. - Виберіть
contractsі введітьcontractsяк новий стовпець, щоб замінити його (нам не потрібно зберігати вихідний масив).
Попередній перегляд тепер показує, що кожен рядок має один contracts суму, а решта полів однакові.
Це також означає, що order_id більше не є унікальним ключем. Для власних випадків використання вам потрібно вирішити, як моделювати дані та чи хочете ви денормалізувати чи ні.
На наступному знімку екрана показано, як виглядають нові стовпці після перетворень.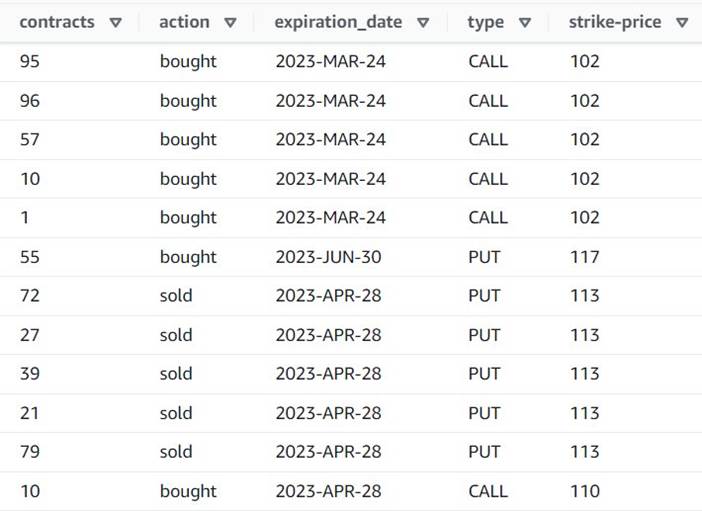
Створіть зведену таблицю
Тепер ви створюєте зведену таблицю з кількістю торгованих контрактів для кожного типу та кожного символу акцій.
Для ілюстрації припустімо, що оброблені файли належать до одного дня, тож цей підсумок дає бізнес-користувачам інформацію про інтерес і настрої ринку в цей день.
- Додавати Виберіть Поля вузол і виберіть наступні стовпці, щоб зберегти для підсумку:
symbol,typeтаcontracts.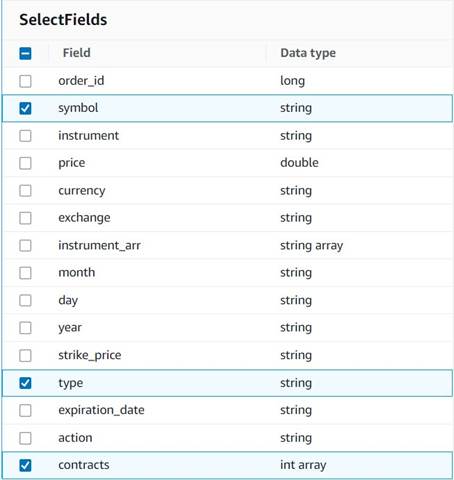
- Додавати Звести рядки в стовпці вузол і назвіть його
Pivot summary. - Агрегат на в
contractsстовпець за допомогоюsumі виберіть конвертуватиtypeколонка.
Зазвичай ви зберігаєте його в зовнішній базі даних або файлі для довідки; у цьому прикладі ми зберігаємо його як файл CSV на Amazon S3.
- Додайте Обробка автобалансу вузол і назвіть його
Single output file. - Хоча цей тип перетворення зазвичай використовується для оптимізації паралелізму, тут ми використовуємо його, щоб скоротити вихід до одного файлу. Тому вводьте
1у конфігурації кількості розділів.
- Додайте ціль S3 і назвіть її
CSV Contract summary. - Виберіть CSV як формат даних і введіть шлях S3, де посадовій ролі дозволено зберігати файли.
Остання частина роботи тепер має виглядати як наведений нижче приклад.![]()
- Збережіть і запустіть завдання. Використовувати Runs щоб перевірити успішне завершення.
За цим шляхом ви знайдете файл CSV, незважаючи на відсутність такого розширення. Ймовірно, вам знадобиться додати розширення після завантаження, щоб відкрити його.
В інструменті, який може зчитувати CSV, резюме має виглядати приблизно так, як наведено нижче.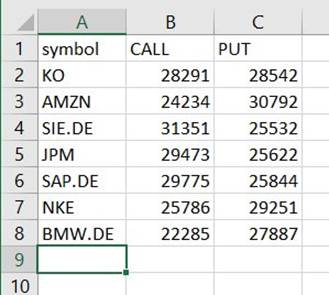
Очистіть тимчасові стовпці
Готуючись до збереження замовлень у історичній таблиці для майбутнього аналізу, давайте очистимо деякі тимчасові стовпці, створені під час цього.
- Додавати Опустіть поля вузол з
Explode contractsвузол, вибраний як його батьківський (ми розгалужуємо конвеєр даних, щоб створити окремий вихід). - Виберіть поля, які потрібно видалити:
instrument_arr,month,dayтаyear.
Решту ми хочемо зберегти, щоб вони були збережені в історичній таблиці, яку ми створимо пізніше.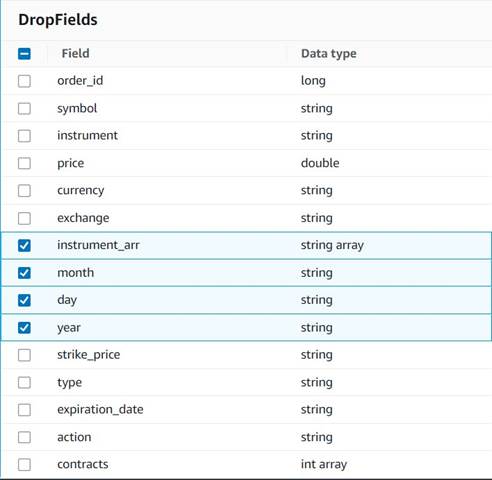
Стандартизація валюти
Ці синтетичні дані містять вигадані операції з двома валютами, але в реальній системі ви можете отримати валюти з ринків у всьому світі. Корисно стандартизувати валюти, що обробляються, у єдину базову валюту, щоб їх можна було легко порівнювати та агрегувати для звітності та аналізу.
Ми використовуємо Амазонка Афіна щоб імітувати таблицю з приблизними конвертаціями валют, яка періодично оновлюється (тут ми припускаємо, що ми обробляємо замовлення досить своєчасно, щоб конвертація була розумним представником для порівняння).
- Відкрийте консоль Athena в тому ж регіоні, де ви використовуєте AWS Glue.
- Виконайте наведений нижче запит, щоб створити таблицю, встановивши розташування S3, де ваші ролі Athena та AWS Glue можуть читати та писати. Крім того, ви можете зберегти таблицю в іншій базі даних
default(якщо ви це зробите, оновіть кваліфіковане ім’я таблиці відповідно до наданих прикладів). - Введіть кілька зразків перетворень у таблицю:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Тепер ви зможете переглянути таблицю за таким запитом:
SELECT * FROM default.exchange_rates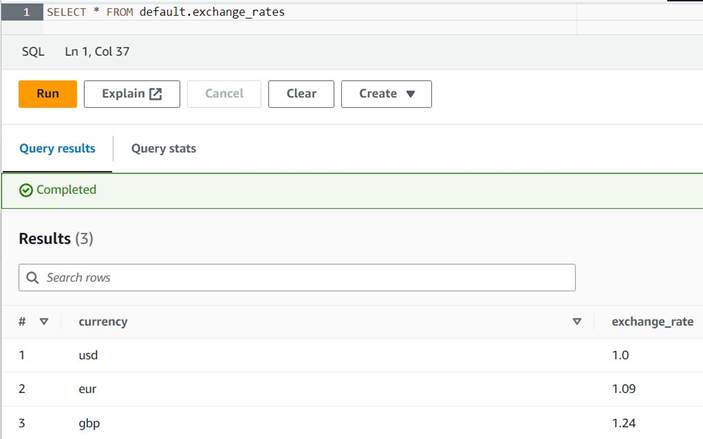
- Повернувшись до візуального завдання AWS Glue, додайте a Пошук вузол (як дочірній елемент
Drop Fields) і назвіть йогоExchange rate. - Введіть якісну назву таблиці, яку ви щойно створили, використовуючи
currencyяк ключ і виберітьexchange_rateполе для використання.
Оскільки поле має однакову назву як у даних, так і в таблиці пошуку, ми можемо просто ввести назвуcurrencyі не потрібно визначати відображення.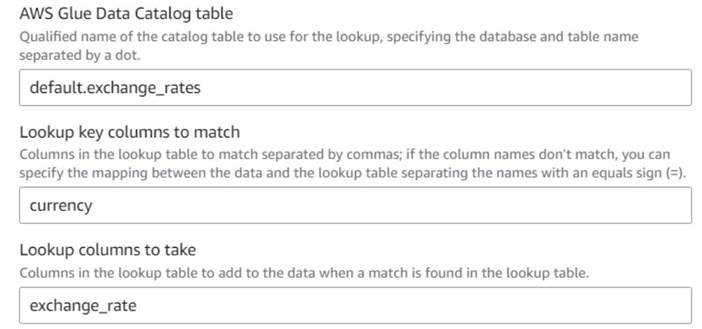
На момент написання цієї статті перетворення підстановки не підтримується в попередньому перегляді даних, і воно показуватиме помилку про те, що таблиця не існує. Це лише для попереднього перегляду даних і не перешкоджає правильній роботі завдання. Кілька кроків публікації, що залишилися, не потребують оновлення схеми. Якщо вам потрібно запустити попередній перегляд даних на інших вузлах, ви можете тимчасово видалити вузол пошуку, а потім повернути його назад. - Додавати Похідний стовпець вузол і назвіть його
Total in usd. - Назвіть похідний стовпець
total_usdі використовуйте такий вираз SQL:round(contracts * price * exchange_rate, 2)
- Додавати Додайте позначку поточного часу вузол і назвіть стовпець
ingest_date. - Використовуйте формат
%Y-%m-%dдля вашої позначки часу (для демонстрації ми використовуємо лише дату; ви можете зробити її більш точною, якщо хочете).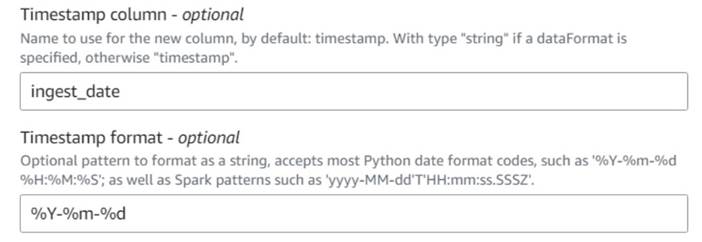
Збережіть таблицю історичних замовлень
Щоб зберегти таблицю історичних замовлень, виконайте такі дії:
- Додайте цільовий вузол S3 і назвіть його
Orders table. - Налаштуйте формат Parquet із швидким стисненням і надайте цільовий шлях S3, у якому зберігатимуться результати (окремо від підсумку).
- Select Створіть таблицю в каталозі даних і під час наступних запусків оновіть схему та додайте нові розділи.
- Введіть цільову базу даних і назву для нової таблиці, наприклад:
option_orders.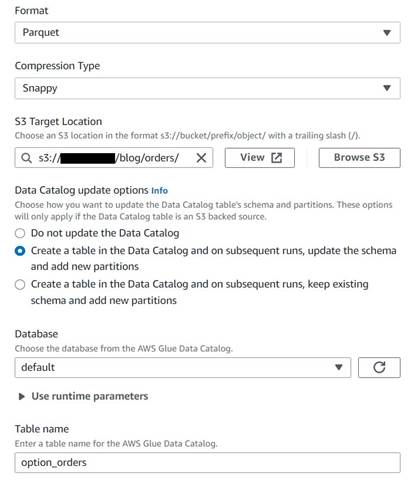
Остання частина діаграми тепер має виглядати так, як показано нижче, з двома гілками для двох окремих виходів.![]()
Після успішного виконання завдання ви можете використовувати такий інструмент, як Athena, щоб переглянути дані, створені завданням, зробивши запит до нової таблиці. Ви можете знайти таблицю в списку Афіни і вибрати Таблиця попереднього перегляду або просто запустіть запит SELECT (оновлюючи ім’я таблиці до імені та каталогу, які ви використовували):
SELECT * FROM default.option_orders limit 10
Вміст вашої таблиці має виглядати так, як на знімку екрана нижче.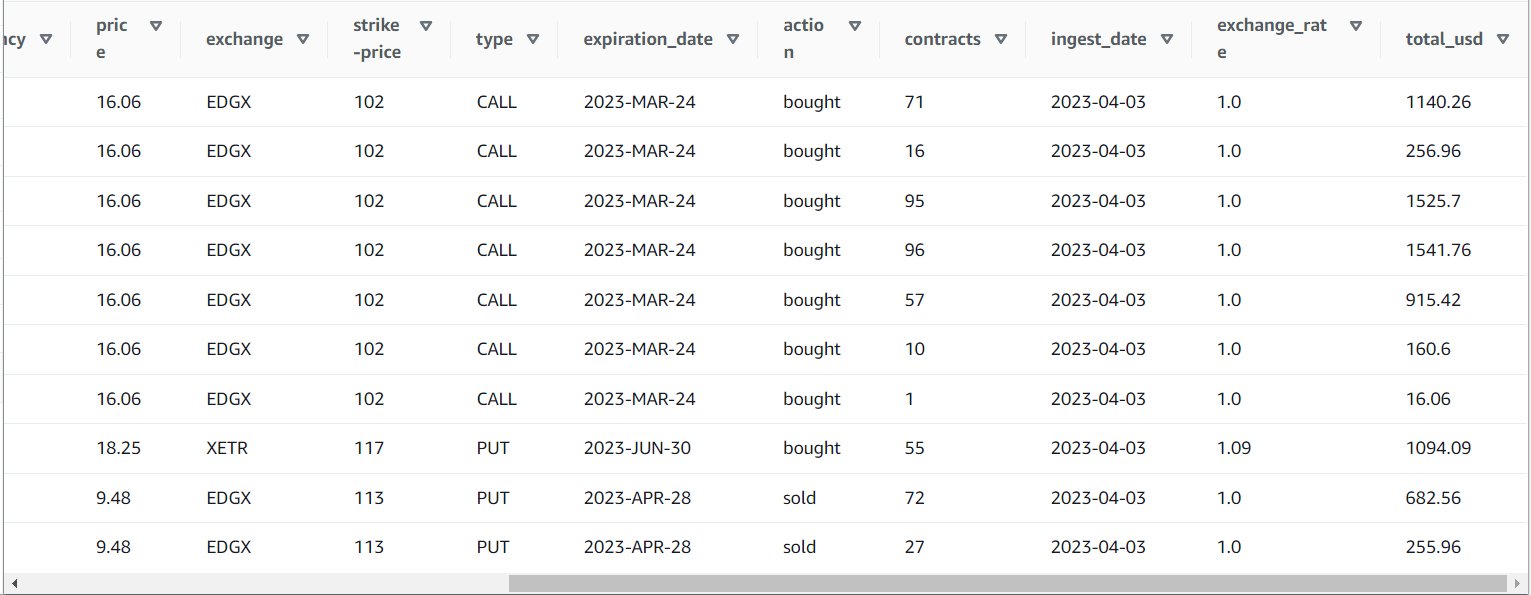
Прибирати
Якщо ви не хочете зберігати цей приклад, видаліть дві створені вами роботи, дві таблиці в Athena та шляхи S3, де зберігалися вхідні та вихідні файли.
Висновок
У цьому дописі ми показали, як нові трансформації в AWS Glue Studio можуть допомогти вам виконати розширені трансформації з мінімальною конфігурацією. Це означає, що ви можете реалізувати більше випадків використання ETL без необхідності писати та підтримувати будь-який код. Нові трансформації вже доступні в AWS Glue Studio, тому ви можете використовувати нові трансформації вже сьогодні у своїх візуальних роботах.
Про автора
![]() Гонсало Еррерос є старшим архітектором великих даних у команді AWS Glue.
Гонсало Еррерос є старшим архітектором великих даних у команді AWS Glue.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- Карбування майбутнього з Адріенн Ешлі. Доступ тут.
- Купуйте та продавайте акції компаній, які вийшли на IPO, за допомогою PREIPO®. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- : має
- :є
- : ні
- :де
- $UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Здатний
- МЕНЮ
- прийнятний
- доступ
- відповідно
- додавати
- доданий
- додати
- просунутий
- після
- ВСІ
- виділено
- асигнувань
- дозволяти
- дозволяє
- по
- вже
- Також
- завжди
- Amazon
- кількість
- суми
- an
- аналіз
- аналізувати
- та
- Інший
- будь-який
- прикладної
- приблизний
- квітня
- ЕСТЬ
- аргумент
- масив
- AS
- призначений
- At
- Атрибути
- автоматично
- доступний
- AWS
- Клей AWS
- назад
- заснований
- BE
- перед тим
- буття
- Великий
- Великий даних
- порожній
- BMW
- обидва
- куплений
- гілки
- будувати
- бізнес
- але
- купити
- by
- call
- CAN
- випадок
- випадків
- каталог
- Центр
- Століття
- Зміни
- характеристика
- перевірка
- дитина
- Вибирати
- Вибираючи
- ясніше
- код
- Кодування
- Колонка
- Колони
- загальний
- порівняний
- порівняння
- повний
- Зроблено
- конфігурація
- Консоль
- Консолідувати
- містить
- зміст
- контракт
- контрактів
- зручність
- Перетворення
- конверсій
- конвертувати
- перероблений
- КОРПОРАЦІЯ
- може
- створювати
- створений
- створення
- валюти
- Валюта
- Поточний
- DAG
- дані
- Database
- Дата
- Дати
- дата, час
- день
- угода
- справу
- вирішувати
- дефолт
- певний
- продемонстрований
- Залежність
- Отриманий
- Незважаючи на
- деталі
- різний
- цифр
- обговорювати
- do
- Ні
- справи
- доларів
- Не знаю
- подвійний
- вниз
- Падіння
- впав
- кожен
- легше
- легко
- легко
- редактор
- включіть
- досить
- Що натомість? Створіть віртуальну версію себе у
- Навколишнє середовище
- помилка
- Ефір (ETH)
- EURO
- приклад
- Приклади
- Крім
- обмін
- Біржі
- Ексклюзивний курс
- існувати
- Розширювати
- очікуваний
- експеримент
- витікання
- виражений
- розширення
- зовнішній
- додатково
- витяг
- далеко
- страх
- кілька
- вигаданий
- поле
- Поля
- філе
- Файли
- заповнювати
- заповнений
- фінансовий
- фінансові інструменти
- знайти
- Перший
- фіксованою
- гнучкий
- стежити
- після
- слідує
- для
- формат
- знайдений
- від
- майбутнє
- GBP
- Загальне
- в цілому
- породжувати
- генерується
- отримати
- Давати
- дає
- Go
- графік
- Жадібність
- Обробка
- відбувається
- Мати
- має
- допомога
- тут
- історичний
- історія
- Як
- How To
- HTML
- HTTP
- HTTPS
- Людей
- i
- ідентифікує
- ідентифікувати
- if
- Impact
- здійснювати
- імпорт
- in
- покажчики
- зазначений
- вказує
- вказуючи
- індикація
- індивідуальний
- інформація
- вхід
- екземпляр
- замість
- інструкції
- інструмент
- інструменти
- інтерес
- інтерфейс
- в
- ISO
- IT
- ЙОГО
- робота
- Джобс
- JPG
- json
- просто
- тримати
- ключ
- Дитина
- останній
- пізніше
- як
- МЕЖА
- Лінія
- ліквідності
- список
- загрузка
- розташування
- довше
- подивитися
- виглядає як
- ВИГЛЯДИ
- пошук
- втрачати
- програш
- made
- підтримувати
- зробити
- РОБОТИ
- вручну
- карта
- відображення
- ринок
- ринкові настрої
- ринки
- Може..
- засоби
- Злиття
- повідомлення
- може бути
- мінімальний
- відсутній
- модель
- монітор
- більше
- найбільш
- множинний
- взаємно
- ім'я
- Названий
- Імена
- Необхідність
- потреби
- Нові
- немає
- вузол
- вузли
- нормально
- зараз
- номер
- номера
- об'єкт
- of
- часто
- on
- ONE
- тільки
- відкрити
- операція
- операції
- Оптимізувати
- варіант
- Опції
- or
- порядок
- замовлень
- оригінал
- Інше
- інакше
- вихід
- над
- загальний
- перевизначення
- власний
- оплачувану
- pane
- параметр
- частина
- шлях
- Вибори
- трубопровід
- Стрижень
- місце
- plato
- Інформація про дані Платона
- PlatoData
- пошта
- потенціал
- Практичний
- необхідність
- запобігати
- попередній перегляд
- price
- ймовірно
- процес
- обробка
- виробляти
- Вироблений
- забезпечувати
- за умови
- забезпечує
- покупка
- мета
- цілей
- put
- Python
- кваліфікований
- підвищення
- випадковий
- Читати
- реальний
- розумний
- зменшити
- відображати
- регіон
- решті
- видаляти
- тиражувати
- Звітність
- представляти
- представник
- представляє
- представляє
- вимагати
- Вимога
- Вимагається
- відповідно
- REST
- в результаті
- результати
- огляд
- Роль
- ролі
- ROW
- прогін
- біг
- безпечніше
- то ж
- живиця
- зберегти
- економія
- прокрутки
- seconds
- обраний
- вибирає
- продавати
- старший
- настрій
- окремий
- Сесія
- набори
- установка
- акції
- Склад
- Повинен
- Показувати
- Шоу
- аналогічний
- простий
- один
- Розмір
- навички
- невеликий
- So
- так далеко
- проданий
- деякі
- що в сім'ї щось
- Source
- Простір
- пробіли
- конкретний
- зазначений
- розкол
- Електронна таблиця
- SQL
- старт
- заходи
- Як і раніше
- акції
- зберігання
- зберігати
- зберігати
- рядок
- студія
- наступні
- Успішно
- підходящий
- РЕЗЮМЕ
- Підтриманий
- символ
- синтетичний
- синтетичні дані
- синтетично
- система
- Systems
- таблиця
- Приймати
- Мета
- команда
- сказати
- тимчасовий
- десять
- тест
- ніж
- Що
- Команда
- Графік
- інформація
- світ
- Їх
- потім
- отже
- Ці
- вони
- це
- ті
- час
- times
- відмітка часу
- до
- сьогодні
- знак
- токенізувати
- прийняли
- інструмент
- Усього:
- торгувати
- торгував
- Перетворення
- Перетворення
- перетворень
- перетворений
- два
- тип
- при
- що лежить в основі
- розуміти
- створеного
- до
- Оновити
- оновлений
- оновлення
- URL
- us
- Долари США
- USD
- використання
- використання випадку
- використовуваний
- користувач
- користувачі
- використання
- Цінний
- Цінна інформація
- значення
- Цінності
- Місце зустрічі
- перевірено
- перевірити
- вид
- видимий
- обсяг
- vs
- чекати
- хотіти
- було
- шлях..
- we
- були
- Що
- коли
- який
- в той час як
- волі
- з
- без
- Робочі процеси
- робочий
- світ
- б
- запис
- лист
- рік
- ви
- вашу
- зефірнет











