З появою генеративного штучного інтелекту сучасні базові моделі (FM), такі як великі мовні моделі (LLM) Claude 2 і Llama 2, можуть виконувати низку генеративних завдань, таких як відповіді на запитання, резюмування та створення вмісту на текстових даних. Однак дані реального світу існують у різних модальностях, таких як текст, зображення, відео та аудіо. Візьмемо, наприклад, колоду слайдів PowerPoint. Він може містити інформацію у вигляді тексту або вбудовану в графіки, таблиці та зображення.
У цьому дописі ми представляємо рішення, яке використовує мультимодальні FM, такі як Amazon Titan Multimodal Embeddings модель і LLaVA 1.5 і сервіси AWS в тому числі Amazon Bedrock та Amazon SageMaker для виконання подібних генеративних завдань на мультимодальних даних.
Огляд рішення
Рішення забезпечує реалізацію відповідей на запитання з використанням інформації, що міститься в тексті та візуальних елементах слайдів. Дизайн базується на концепції Retrieval Augmented Generation (RAG). Традиційно RAG асоціюється з текстовими даними, які можуть оброблятися LLM. У цій публікації ми розширюємо RAG, щоб також включити зображення. Це надає потужну можливість пошуку для вилучення релевантного контексту вмісту з візуальних елементів, таких як таблиці та графіки, разом із текстом.
Існують різні способи розробки рішення RAG, яке містить зображення. Ми представили один підхід тут і розглянемо альтернативний підхід у другій публікації цієї серії з трьох частин.
Це рішення включає наступні компоненти:
- Модель Amazon Titan Multimodal Embeddings – Цей FM використовується для створення вставок для вмісту слайдів, які використовуються в цій публікації. Будучи мультимодальною моделлю, ця модель Titan може обробляти текст, зображення або комбінацію як вхідні дані та генерувати вбудовування. Модель Titan Multimodal Embeddings генерує вектори (вбудовування) 1,024 вимірів, доступ до яких здійснюється через Amazon Bedrock.
- Великий асистент мови та зору (LLaVA) – LLaVA — це мультимодальна модель з відкритим вихідним кодом для візуального та мовного розуміння, яка використовується для інтерпретації даних у слайдах, включаючи візуальні елементи, такі як графіки та таблиці. Ми використовуємо версію з 7 мільярдами параметрів LLaVA 1.5-7b в цьому розчині.
- Amazon SageMaker – Модель LLaVA розгортається на кінцевій точці SageMaker за допомогою служб хостингу SageMaker, і ми використовуємо отриману кінцеву точку для виконання висновків щодо моделі LLaVA. Ми також використовуємо блокноти SageMaker, щоб оркеструвати та демонструвати це рішення від кінця до кінця.
- Amazon OpenSearch Serverless – OpenSearch Serverless – це безсерверна конфігурація на вимогу для Служба Amazon OpenSearch. Ми використовуємо OpenSearch Serverless як векторну базу даних для зберігання вбудовувань, згенерованих моделлю Titan Multimodal Embeddings. Індекс, створений у колекції OpenSearch Serverless, служить векторним сховищем для нашого рішення RAG.
- Amazon OpenSearch Ingestion (OSI) – OSI – це повністю керований безсерверний збирач даних, який доставляє дані в домени OpenSearch Service і колекції OpenSearch Serverless. У цій публікації ми використовуємо конвеєр OSI для доставки даних у безсерверне векторне сховище OpenSearch.
Архітектура рішення
Дизайн рішення складається з двох частин: прийом і взаємодія з користувачем. Під час прийому ми обробляємо вхідну колоду слайдів, перетворюючи кожен слайд на зображення, генеруючи вбудовування для цих зображень, а потім заповнюючи сховище векторних даних. Ці кроки виконуються перед етапами взаємодії з користувачем.
На етапі взаємодії з користувачем запитання від користувача перетворюється на вбудовування, і в векторній базі даних виконується пошук подібності, щоб знайти слайд, який потенційно може містити відповіді на запитання користувача. Потім ми надаємо цей слайд (у формі файлу зображення) моделі LLaVA та запитання користувача як підказку для створення відповіді на запит. Весь код для цієї публікації доступний у GitHub репо.
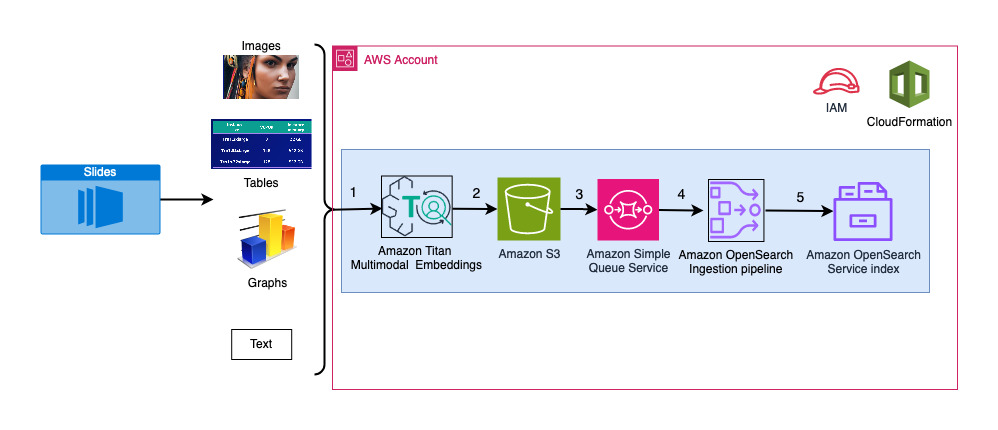
На наступній діаграмі показано архітектуру прийому даних.
Етапи робочого процесу такі:
- Слайди перетворюються на файли зображень (по одному на слайд) у форматі JPG і передаються в модель Titan Multimodal Embeddings для створення вставок. У цій публікації ми використовуємо колоду слайдів під назвою Навчання та розгортання Stable Diffusion за допомогою AWS Trainium & AWS Inferentia із саміту AWS у Торонто, червень 2023 р., щоб продемонструвати рішення. Зразкова колода містить 31 слайд, тож ми генеруємо 31 набір векторних вставок, кожен із яких має 1,024 виміри. Ми додаємо додаткові поля метаданих до цих згенерованих векторних вставок і створюємо файл JSON. Ці додаткові поля метаданих можна використовувати для виконання розширених пошукових запитів за допомогою потужних пошукових можливостей OpenSearch.
- Згенеровані вставки об’єднуються в один файл JSON, який завантажується в Служба простого зберігання Amazon (Amazon S3).
- через Повідомлення про події Amazon S3, подія поміщається в Служба простої черги Amazon (Amazon SQS) черга.
- Ця подія в черзі SQS діє як тригер для запуску конвеєра OSI, який, у свою чергу, завантажує дані (файл JSON) як документи в індекс OpenSearch Serverless. Зверніть увагу, що індекс OpenSearch Serverless налаштовано як приймач для цього конвеєра та створюється як частина колекції OpenSearch Serverless.
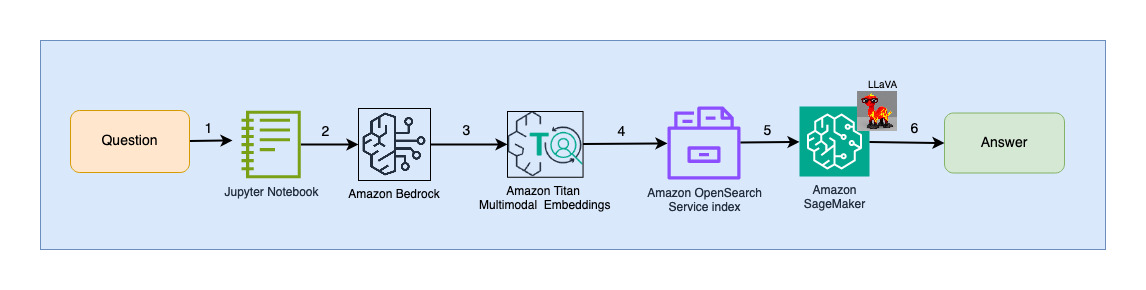
Наступна діаграма ілюструє архітектуру взаємодії з користувачем.
Етапи робочого процесу такі:
- Користувач надсилає запитання, пов’язане з переданою колодою слайдів.
- Введені користувачем дані перетворюються на вбудовування за допомогою моделі Titan Multimodal Embeddings, доступ до якої здійснюється через Amazon Bedrock. Векторний пошук OpenSearch виконується за допомогою цих вставок. Ми виконуємо пошук k-найближчого сусіда (k=1), щоб отримати найбільш релевантне вбудовування, яке відповідає запиту користувача. Налаштування k=1 отримує найбільш релевантний слайд для запитання користувача.
- Метадані відповіді OpenSearch Serverless містять шлях до зображення, що відповідає найбільш релевантному слайду.
- Підказка створюється шляхом поєднання запитання користувача та шляху до зображення та надається до LLaVA, розміщеного на SageMaker. Модель LLaVA здатна зрозуміти запитання користувача та відповісти на нього, досліджуючи дані на зображенні.
- Результат цього висновку повертається користувачеві.
Ці кроки детально обговорюються в наступних розділах. Див результати розділ для скріншотів і подробиць про результат.
Передумови
Щоб реалізувати рішення, наведене в цій публікації, ви повинні мати Обліковий запис AWS знайомство з FM, Amazon Bedrock, SageMaker і OpenSearch Service.
Це рішення використовує модель Titan Multimodal Embeddings. Переконайтеся, що цю модель увімкнено для використання в Amazon Bedrock. Виберіть на консолі Amazon Bedrock Доступ до моделі на панелі навігації. Якщо Titan Multimodal Embeddings увімкнено, статус доступу буде таким Доступ дозволено.
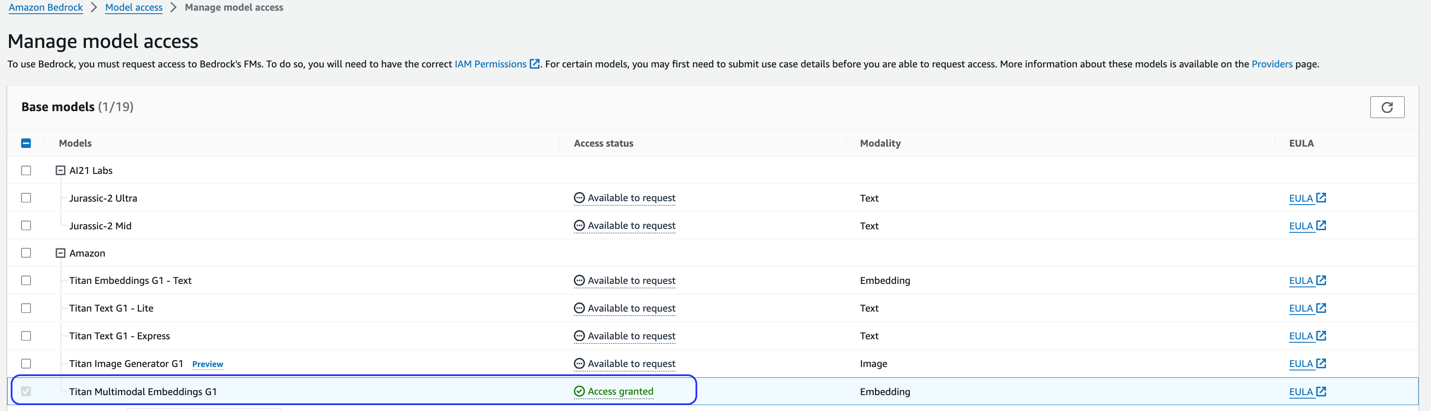
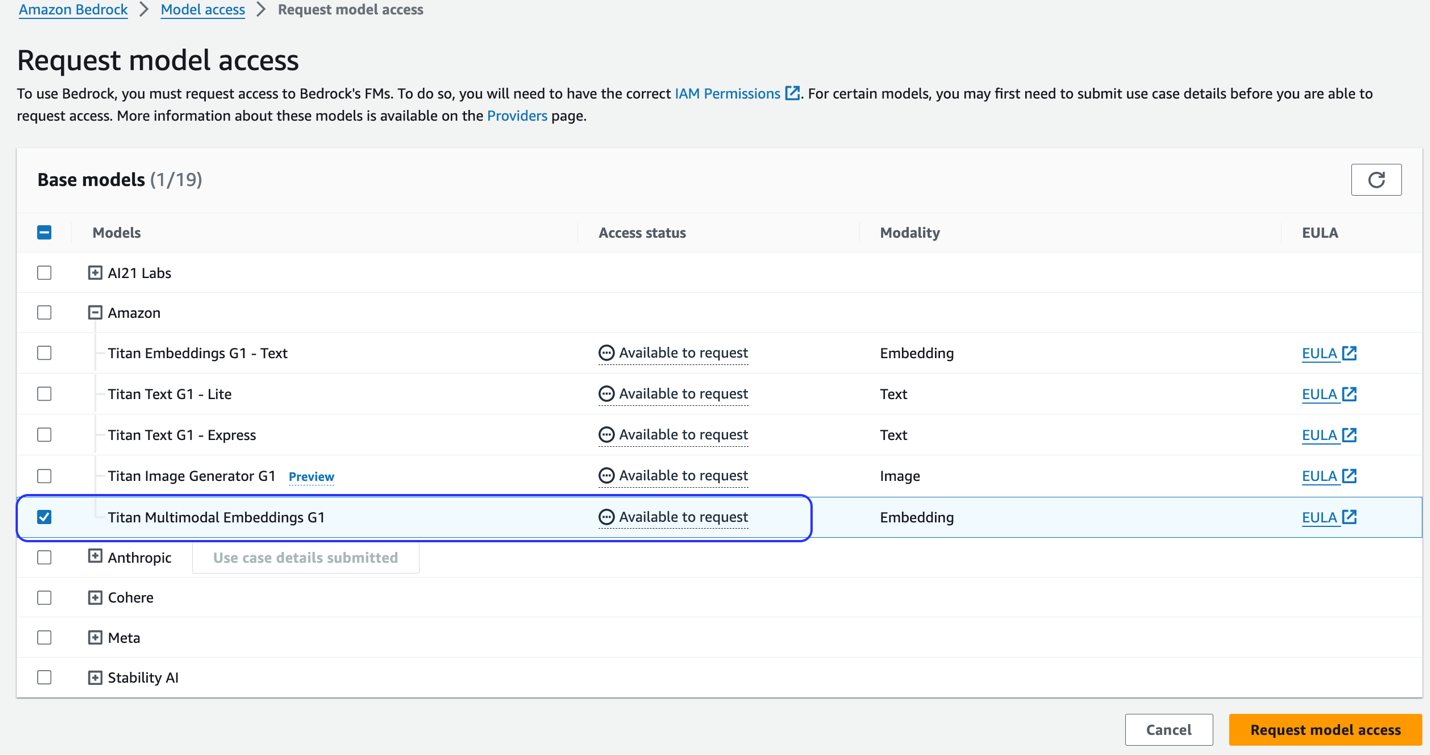
Якщо модель недоступна, увімкніть доступ до моделі, вибравши Керування доступом до моделі, вибір Titan Multimodal Embeddings G1, і вибір Запит на доступ до моделі. Модель готова до використання відразу.
Використовуйте шаблон AWS CloudFormation, щоб створити стек рішень
Використовуйте один із наведених нижче способів AWS CloudFormation шаблони (залежно від вашого регіону) для запуску ресурсів рішення.
| Регіон AWS | посилання |
|---|---|
us-east-1 |
|
us-west-2 |
Після успішного створення стека перейдіть до стека Виходи на консолі AWS CloudFormation і запишіть значення для MultimodalCollectionEndpoint, який ми використовуємо на наступних кроках.
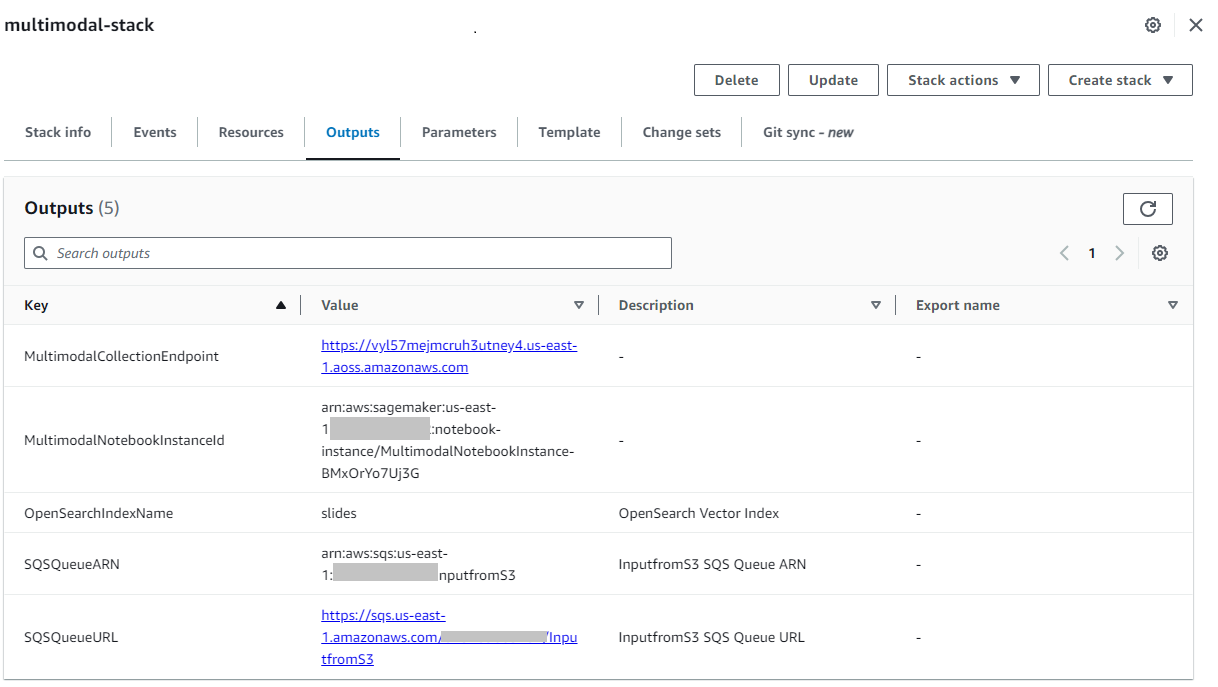
Шаблон CloudFormation створює такі ресурси:
- Ролі IAM - Наступне Управління ідентифікацією та доступом AWS (IAM) створюються ролі. Оновіть ці ролі, щоб застосувати дозволи з найменшими привілеями.
SMExecutionRoleз повним доступом Amazon S3, SageMaker, OpenSearch Service і Bedrock.OSPipelineExecutionRoleз доступом до певних дій Amazon SQS і OSI.
- Блокнот SageMaker – Весь код для цієї публікації запускається через цей блокнот.
- Безсерверна колекція OpenSearch – Це векторна база даних для зберігання та отримання вбудованих елементів.
- Конвеєр OSI – Це конвеєр для введення даних у OpenSearch Serverless.
- Ковш S3 – Усі дані для цієї публікації зберігаються в цьому відрі.
- Черга SQS – Події для запуску конвеєра OSI поміщаються в цю чергу.
Шаблон CloudFormation налаштовує конвеєр OSI з обробкою Amazon S3 і Amazon SQS як джерелом і індексом OpenSearch Serverless як приймачем. Будь-які об’єкти, створені у вказаному сегменті S3 і префіксі (multimodal/osi-embeddings-json) ініціюватиме сповіщення SQS, які використовуються конвеєром OSI для введення даних у OpenSearch Serverless.
Шаблон CloudFormation також створює мережу, шифрування та доступ до даних політики, необхідні для колекції OpenSearch Serverless. Оновіть ці політики, щоб застосувати дозволи з найменшими привілеями.
Зауважте, що назва шаблону CloudFormation вказується в блокнотах SageMaker. Якщо ім’я шаблону за замовчуванням змінено, переконайтеся, що ви оновили його в globals.py
Перевірте розчин
Після виконання необхідних кроків і успішного створення стека CloudFormation ви готові протестувати рішення:
- На консолі SageMaker виберіть Ноутбуки у навігаційній панелі.
- Виберіть
MultimodalNotebookInstanceекземпляр блокнота та виберіть Відкрийте JupyterLab.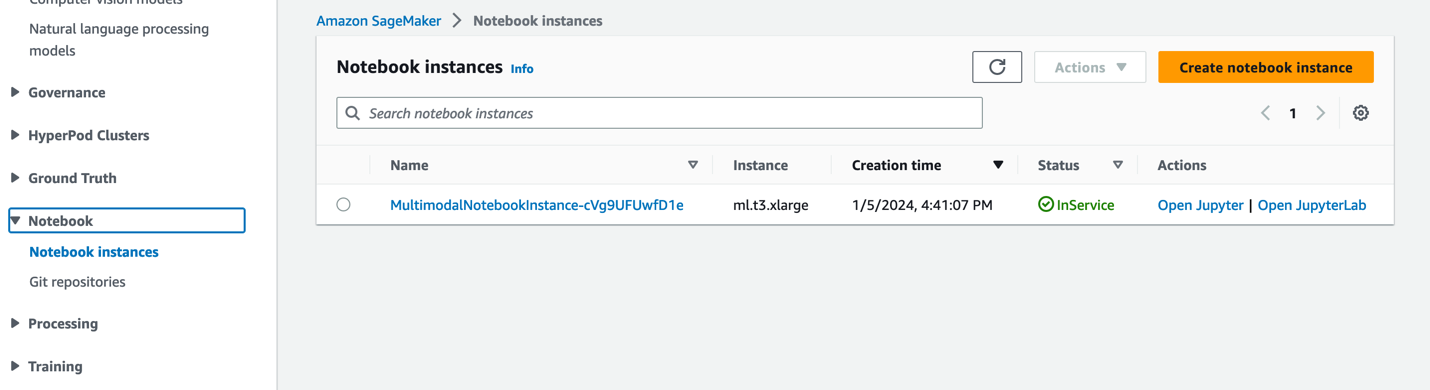
- In Браузер файлів, перейдіть до папки блокнотів, щоб переглянути блокноти та допоміжні файли.
Зошити пронумеровані в тій послідовності, в якій вони виконуються. Інструкції та коментарі в кожному блокноті описують дії, які виконує цей блокнот. Ми запускаємо ці зошити один за одним.
- Вибирати 0_deploy_llava.ipynb щоб відкрити його в JupyterLab.
- на прогін меню, виберіть Запустіть усі клітинки щоб запустити код у цьому блокноті.
Цей ноутбук розгортає модель LLaVA-v1.5-7B на кінцевій точці SageMaker. У цьому блокноті ми завантажуємо модель LLaVA-v1.5-7B з HuggingFace Hub, замінюємо сценарій inference.py на llava_inference.pyі створіть файл model.tar.gz для цієї моделі. Файл model.tar.gz завантажується в Amazon S3 і використовується для розгортання моделі на кінцевій точці SageMaker. The llava_inference.py Сценарій має додатковий код, який дозволяє читати файл зображення з Amazon S3 і запускати на ньому висновки.
- Вибирати 1_data_prep.ipynb щоб відкрити його в JupyterLab.
- на прогін меню, виберіть Запустіть усі клітинки щоб запустити код у цьому блокноті.
Цей блокнот завантажує слайд-палуба, перетворює кожен слайд у формат файлу JPG і завантажує їх у відро S3, яке використовується для цієї публікації.
- Вибирати 2_data_ingestion.ipynb щоб відкрити його в JupyterLab.
- на прогін меню, виберіть Запустіть усі клітинки щоб запустити код у цьому блокноті.
У цьому блокноті ми робимо наступне:
- Ми створюємо індекс у колекції OpenSearch Serverless. Цей індекс зберігає дані про вбудовування слайдів. Перегляньте наступний код:
- Ми використовуємо модель Titan Multimodal Embeddings для перетворення зображень JPG, створених у попередньому блокноті, у векторні вбудовані зображення. Ці вбудовування та додаткові метадані (наприклад, шлях S3 до файлу зображення) зберігаються у файлі JSON і завантажуються в Amazon S3. Зауважте, що створюється єдиний файл JSON, який містить документи для всіх слайдів (зображень), перетворених на вбудовування. У наступному фрагменті коду показано, як зображення (у формі рядка, закодованого Base64) перетворюється на вбудовування:
- Ця дія запускає конвеєр OpenSearch Ingestion, який обробляє файл і завантажує його в індекс OpenSearch Serverless. Нижче наведено приклад створеного файлу JSON. (У прикладі коду показано вектор із чотирма вимірами. Модель Titan Multimodal Embeddings створює 1,024 виміри.)
- Вибирати 3_rag_inference.ipynb щоб відкрити його в JupyterLab.
- на прогін меню, виберіть Запустіть усі клітинки щоб запустити код у цьому блокноті.
У цьому блокноті реалізовано рішення RAG: ми перетворюємо запитання користувача на вбудовування, знаходимо подібне зображення (слайд) у векторній базі даних і надаємо отримане зображення в LLaVA для створення відповіді на запитання користувача. Ми використовуємо наступний шаблон запиту:
Наступний фрагмент коду забезпечує робочий процес RAG:
результати
Нижче наведено добірку деяких запитань користувачів і відповідей, створених нашою реалізацією. The Питання стовпець фіксує запитання користувача, і Відповідь стовпець — це текстова відповідь, згенерована LLaVA. зображення є k-найближчим (k=1) збігом слайдів, який повертає безсерверний векторний пошук OpenSearch. Цей слайд інтерпретується LLaVA, щоб надати відповідь.
Мультимодальні результати RAG
| Питання | Відповідь | зображення |
|---|---|---|
| Як Inf2 порівнює продуктивність із порівнянними примірниками EC2? Мені потрібні цифри. | Згідно зі слайдами, екземпляри Inf2 від AWS Inferentia2 пропонують до 4 разів вищу пропускну здатність і в 10 разів нижчу затримку порівняно з аналогічними екземплярами EC2. |  |
| Відповідно до маховика AI/ML, що надають послуги AWS AI/ML? | Сервіси AWS AI/ML забезпечують кращі можливості $/perfer, нові можливості та інвестиції в інновації. | 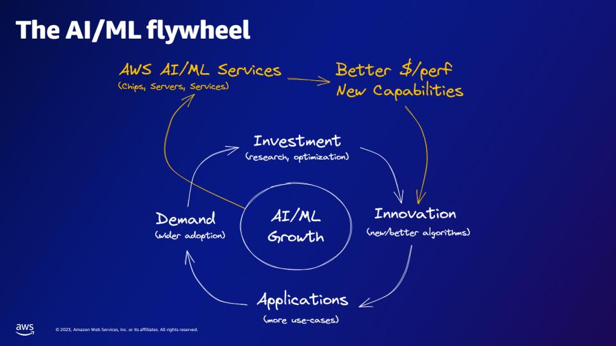 |
| Скільки більше параметрів у GPT-2 порівняно з GPT-3? Яка чисельна різниця між розміром параметра GPT-2 і GPT-3? | Згідно зі слайдом, GPT-3 має 175 мільярдів параметрів, тоді як GPT-2 має 1.5 мільярда параметрів. Чисельна різниця між розміром параметра GPT-2 і GPT-3 становить 173.5 мільярда. | 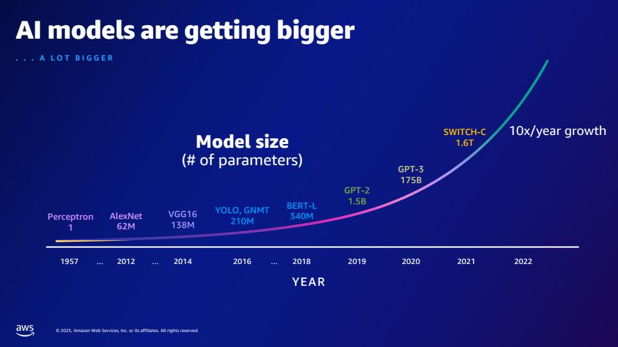 |
| Що таке кварки у фізиці елементарних частинок? | Я не знайшов відповіді на це питання в слайдах. |  |
Не соромтеся поширити це рішення на свої слайд-деки. Просто оновіть змінну SLIDE_DECK у globals.py, вказавши URL-адресу вашої колоди слайдів, і виконайте дії, описані в попередньому розділі.
Чайові
Ви можете використовувати інформаційні панелі OpenSearch, щоб взаємодіяти з OpenSearch API, щоб виконувати швидкі тести вашого індексу та отриманих даних. На наступному знімку екрана показано приклад GET інформаційної панелі OpenSearch.
Прибирати
Щоб уникнути майбутніх витрат, видаліть створені вами ресурси. Ви можете зробити це, видаливши стек за допомогою консолі CloudFormation.

Крім того, видаліть кінцеву точку висновку SageMaker, створену для висновку LLaVA. Ви можете зробити це, розкоментувавши крок очищення 3_rag_inference.ipynb і запустивши клітинку, або видаливши кінцеву точку через консоль SageMaker: виберіть Висновок та Кінцеві точки на панелі навігації, потім виберіть кінцеву точку та видаліть її.
Висновок
Підприємства постійно створюють новий вміст, а слайди — це звичайний механізм, який використовується для обміну та поширення інформації всередині організації та за її межами з клієнтами або на конференціях. З часом багата інформація може залишатися прихованою в нетекстових формах, як-от графіки та таблиці в цих слайдах. Ви можете використовувати це рішення та потужність мультимодальних FM, таких як модель Titan Multimodal Embeddings і LLaVA, щоб відкривати нову інформацію або розкривати нові перспективи вмісту в слайдах.
Ми радимо вам дізнатися більше, досліджуючи Amazon SageMaker JumpStart, Моделі Amazon Titan, Amazon Bedrock і OpenSearch Service, а також створити рішення за допомогою прикладу впровадження, наведеного в цій публікації.
Зверніть увагу на дві додаткові публікації в рамках цієї серії. Частина 2 охоплює інший підхід, яким ви можете скористатися, щоб спілкуватися зі своєю колодою слайдів. Цей підхід генерує та зберігає висновки LLaVA та використовує ці збережені висновки для відповідей на запити користувачів. Частина 3 порівнює два підходи.
Про авторів
 Аміт Арора є архітектором-спеціалістом зі штучного інтелекту та машинного навчання Amazon Web Services, який допомагає корпоративним клієнтам використовувати хмарні сервіси машинного навчання для швидкого масштабування своїх інновацій. Він також є допоміжним лектором у програмі MS Data Science and Analytics в Джорджтаунському університеті у Вашингтоні, округ Колумбія.
Аміт Арора є архітектором-спеціалістом зі штучного інтелекту та машинного навчання Amazon Web Services, який допомагає корпоративним клієнтам використовувати хмарні сервіси машинного навчання для швидкого масштабування своїх інновацій. Він також є допоміжним лектором у програмі MS Data Science and Analytics в Джорджтаунському університеті у Вашингтоні, округ Колумбія.
 Манджу Прасад є старшим архітектором рішень у відділі стратегічних облікових записів Amazon Web Services. Вона зосереджена на наданні технічного керівництва в різних сферах, включаючи штучний інтелект/ML для клієнтів M&E. До приходу в AWS вона розробляла та створювала рішення для компаній у секторі фінансових послуг, а також для стартапів.
Манджу Прасад є старшим архітектором рішень у відділі стратегічних облікових записів Amazon Web Services. Вона зосереджена на наданні технічного керівництва в різних сферах, включаючи штучний інтелект/ML для клієнтів M&E. До приходу в AWS вона розробляла та створювала рішення для компаній у секторі фінансових послуг, а також для стартапів.
 Арчана Інапуді є старшим архітектором рішень в AWS, який підтримує стратегічних клієнтів. Вона має понад десятирічний досвід, допомагаючи клієнтам проектувати та створювати рішення для аналітики даних і баз даних. Вона захоплена використанням технологій для забезпечення цінності для клієнтів і досягнення бізнес-результатів.
Арчана Інапуді є старшим архітектором рішень в AWS, який підтримує стратегічних клієнтів. Вона має понад десятирічний досвід, допомагаючи клієнтам проектувати та створювати рішення для аналітики даних і баз даних. Вона захоплена використанням технологій для забезпечення цінності для клієнтів і досягнення бізнес-результатів.
 Антара Раїса є архітектором рішень штучного інтелекту та машинного навчання в Amazon Web Services, який підтримує стратегічних клієнтів із Далласа, штат Техас. Вона також має попередній досвід роботи з великими корпоративними партнерами в AWS, де вона працювала архітектором успішних рішень для цифрових клієнтів.
Антара Раїса є архітектором рішень штучного інтелекту та машинного навчання в Amazon Web Services, який підтримує стратегічних клієнтів із Далласа, штат Техас. Вона також має попередній досвід роботи з великими корпоративними партнерами в AWS, де вона працювала архітектором успішних рішень для цифрових клієнтів.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- Здатний
- МЕНЮ
- доступ
- доступний
- Рахунки
- Achieve
- дію
- дії
- акти
- додавати
- Додатковий
- доповнення
- прихід
- проти
- AI
- AI / ML
- ВСІ
- дозволяти
- по
- Також
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- аналітика
- та
- Інший
- відповідь
- відповідь
- Відповіді
- будь-який
- API
- Застосовувати
- підхід
- підходи
- архітектура
- ЕСТЬ
- AS
- запитати
- Помічник
- асоційований
- At
- аудіо
- збільшено
- Auth
- доступний
- уникнути
- AWS
- AWS CloudFormation
- заснований
- BE
- було
- Краще
- між
- Мільярд
- тіло
- будувати
- Створюємо
- побудований
- бізнес
- by
- CAN
- можливості
- можливості
- захвати
- осередок
- змінилися
- вантажі
- Вибирати
- Вибираючи
- клієнт
- код
- збір
- Колекції
- колектор
- Колонка
- поєднання
- об'єднання
- коментарі
- загальний
- Компанії
- порівнянний
- порівняти
- порівняний
- повний
- Зроблено
- Компоненти
- концепція
- конференції
- конфігурація
- налаштувати
- складається
- Консоль
- містити
- містяться
- містить
- зміст
- контент-створення
- конвертувати
- перероблений
- перетворення
- Відповідний
- може
- охоплює
- створювати
- створений
- створює
- створення
- створення
- Повноваження
- клієнт
- Клієнти
- Даллас
- приладова панель
- інформаційні панелі
- дані
- Analytics даних
- наука про дані
- Database
- десятиліття
- палуба
- дефолт
- доставляти
- постачає
- демонструвати
- Залежно
- розгортання
- розгорнути
- розгортання
- розгортає
- описувати
- дизайн
- призначений
- деталь
- докладно
- деталі
- схема
- DICT
- DID
- різниця
- різний
- радіомовлення
- цифровий
- Розмір
- розміри
- відкрити
- обговорювалися
- дисплей
- do
- документація
- робить
- домени
- скачати
- завантажень
- під час
- e
- кожен
- елементи
- вбудований
- вбудовування
- включіть
- включений
- кодований
- заохочувати
- кінець
- Кінцева точка
- двигун
- забезпечувати
- підприємство
- корпоративні клієнти
- помилка
- Ефір (ETH)
- Event
- Події
- Вивчення
- приклад
- Крім
- виняток
- існує
- досвід
- Дослідження
- продовжити
- зовні
- витяг
- Знайомство
- Поля
- філе
- Файли
- фінансовий
- фінансові послуги
- знайти
- фокусується
- стежити
- після
- слідує
- для
- форма
- формат
- фонд
- чотири
- Безкоштовна
- від
- Повний
- повністю
- майбутнє
- породжувати
- генерується
- генерує
- покоління
- генеративний
- Генеративний ШІ
- Джорджтаун
- отримати
- GitHub
- буде
- графіки
- керівництво
- Мати
- he
- корисний
- допомогу
- тут
- прихований
- вище
- число переглядів
- господар
- відбувся
- хостинг
- хостів
- Як
- Однак
- HTML
- HTTP
- HTTPS
- Концентратор
- HuggingFace
- i
- IAM
- Особистість
- if
- ілюструє
- зображення
- зображень
- негайно
- здійснювати
- реалізація
- implements
- in
- включати
- includes
- У тому числі
- індекс
- індекси
- інформація
- інновація
- інновації
- вхід
- екземпляр
- випадки
- інструкції
- взаємодіяти
- взаємодія
- внутрішньо
- в
- інвестиції
- IT
- приєднання
- JPG
- json
- червень
- мова
- великий
- Затримка
- запуск
- УЧИТЬСЯ
- вивчення
- викладач
- як
- LINK
- Лама
- місцевий
- знизити
- машина
- навчання за допомогою машини
- зробити
- управляти
- вдалося
- багато
- матч
- узгодження
- механізм
- Меню
- метадані
- метод
- ML
- модальності
- модель
- Моделі
- більше
- найбільш
- MS
- множинний
- ім'я
- рідний
- Переміщення
- навігація
- Необхідність
- Нові
- ніхто
- увагу
- ноутбук
- ноутбуки
- Повідомлення
- зараз
- пронумерований
- номера
- об'єкти
- of
- пропонувати
- on
- On-Demand
- ONE
- тільки
- відкрити
- з відкритим вихідним кодом
- or
- організація
- OS
- наші
- з
- Результати
- вихід
- над
- pane
- параметр
- параметри
- частина
- частинка
- партнер
- партнери
- частини
- Пройшов
- пристрасний
- шлях
- для
- виконувати
- продуктивність
- виконується
- Дозволи
- перспективи
- фаза
- Фізика
- фотографії
- трубопровід
- plato
- Інформація про дані Платона
- PlatoData
- Політика
- пошта
- Пости
- потенційно
- влада
- потужний
- Прогноз
- представити
- представлений
- попередній
- попередній
- процес
- оброблена
- процеси
- обробка
- програма
- властивості
- забезпечувати
- за умови
- забезпечує
- забезпечення
- put
- кварки
- запити
- запит
- питання
- питань
- Швидко
- ганчіркою
- діапазон
- швидко
- читання
- готовий
- Реальний світ
- отримано
- посилання на
- регіон
- пов'язаний
- доречний
- залишатися
- замінювати
- запросити
- вимагається
- ресурси
- Реагувати
- відповідь
- відповіді
- результат
- в результаті
- результати
- пошук
- повертати
- Багаті
- ролі
- прогін
- біг
- мудрець
- Висновок SageMaker
- то ж
- say
- шкала
- наука
- скріншоти
- сценарій
- Пошук
- другий
- розділ
- розділам
- сектор
- побачити
- вибрати
- вибирає
- старший
- Послідовність
- Серія
- Без сервера
- служить
- обслуговування
- Послуги
- Сесія
- набори
- установка
- налаштування
- Поділитись
- вона
- Повинен
- показаний
- Шоу
- аналогічний
- простий
- просто
- один
- Розмір
- Ковзати
- Слайди
- уривок
- So
- рішення
- Рішення
- деякі
- Source
- спеціаліст
- конкретний
- зазначений
- стабільний
- стек
- введення в експлуатацію
- стан
- Статус
- Крок
- заходи
- зберігання
- зберігати
- зберігати
- магазинів
- Стратегічний
- рядок
- наступні
- успіх
- Успішно
- такі
- Саміт
- Підтримуючий
- Переконайтеся
- таблиця
- Приймати
- балаканина
- завдання
- технічний
- Технологія
- шаблон
- Шаблони
- тест
- Тести
- Техас
- текст
- текстуальний
- Що
- Команда
- інформація
- їх
- потім
- Ці
- це
- ті
- пропускна здатність
- час
- велетень
- під назвою
- до
- сьогоднішній
- разом
- Торонто
- традиційно
- траверс
- викликати
- спрацьовування
- правда
- намагатися
- ПЕРЕГЛЯД
- два
- тип
- розкрити
- розуміти
- розуміння
- університет
- Оновити
- завантажено
- URL
- використання
- використовуваний
- користувач
- використовує
- використання
- значення
- змінна
- різноманітність
- версія
- через
- Відео
- вид
- бачення
- візуальний
- Вашингтон
- способи
- we
- Web
- веб-сервіси
- ДОБРЕ
- Що
- Що таке
- який
- в той час як
- волі
- з
- в
- працював
- робочий
- робочий
- ви
- вашу
- зефірнет