
Зображення створено за допомогою DALL-E3
Штучний інтелект став повною революцією у світі технологій.
Його здатність імітувати людський інтелект і виконувати завдання, які раніше вважалися виключно людською сферою, досі дивує більшість із нас.
Однак, незалежно від того, наскільки вдалими були ці пізні кроки ШІ, завжди є місце для вдосконалення.
І саме тут спрацьовує оперативне проектування!
Введіть це поле, яке може значно підвищити продуктивність моделей ШІ.
Давайте відкриємо це все разом!
Швидка інженерія – це сфера штучного інтелекту, яка швидко розвивається і зосереджена на підвищенні ефективності та результативності мовних моделей. Уся справа в створенні ідеальних підказок, які скеровуватимуть моделі ШІ для отримання бажаних результатів.
Подумайте про це як про те, як навчитися давати комусь кращі інструкції, щоб переконатися, що вони розуміють і правильно виконують завдання.
Чому оперативне проектування має значення
- Підвищена продуктивність: Використовуючи високоякісні підказки, моделі штучного інтелекту можуть генерувати точніші та релевантніші відповіді. Це означає менше часу, витраченого на виправлення, і більше часу на використання можливостей ШІ.
- Ефективність витрат: Навчання моделей ШІ потребує ресурсів. Швидка розробка може зменшити потребу в перенавчанні шляхом оптимізації продуктивності моделі за допомогою кращих підказок.
- Універсальність: Добре розроблена підказка може зробити моделі штучного інтелекту більш універсальними, дозволяючи їм вирішувати ширший спектр завдань і викликів.
Перш ніж зануритися в найдосконаліші методи, давайте згадаємо два найкорисніших (і базових) методу швидкої інженерії.
Послідовне мислення з «Давайте думати крок за кроком»
Сьогодні добре відомо, що точність моделей LLM значно підвищується при додаванні послідовності слів «Давай думати крок за кроком».
Чому… можете запитати ви?
Ну, це тому, що ми змушуємо модель розбивати будь-яке завдання на кілька кроків, таким чином гарантуючи, що модель має достатньо часу для обробки кожного з них.
Наприклад, я міг би оскаржити GPT3.5 за допомогою такого підказки:
Якщо Іван має 5 груш, потім з’їсть 2, купить ще 5 і віддасть 3 своєму другові, скільки у нього груш?
Модель відразу дасть мені відповідь. Однак, якщо я додаю останнє «Давайте подумаємо крок за кроком», я змушую модель генерувати процес мислення з кількома кроками.
Кілька підказок
У той час як підказка Zero-shot стосується прохання моделі виконати завдання без надання будь-якого контексту чи попередніх знань, техніка підказки кількох підказок передбачає, що ми представляємо LLM кілька прикладів наших бажаних результатів разом із деяким конкретним запитанням.
Наприклад, якщо ми хочемо придумати модель, яка визначає будь-який термін за допомогою поетичного тону, це може бути досить важко пояснити. правильно?
Однак ми можемо використати наступні кілька підказок, щоб направити модель у потрібному напрямку.
Ваше завдання — відповісти в узгодженому стилі відповідно до наступного стилю.
: Навчи мене стійкості.
: Стійкість подібна до дерева, яке гнеться від вітру, але ніколи не ламається.
Це здатність відновлюватися після труднощів і продовжувати рухатися вперед.
: Ваші дані тут.
Якщо ви ще не пробували, ви можете кинути виклик GPT.
Однак, оскільки я майже впевнений, що більшість із вас уже знає ці основні прийоми, я спробую запропонувати вам деякі просунуті прийоми.
1. Ланцюг думок (CoT).
Введений в Google у 2022 році, цей метод передбачає вказівку моделі пройти кілька етапів міркування перед тим, як дати остаточну відповідь.
Звучить знайомо, правда? Якщо так, то ви абсолютно праві.
Це схоже на об’єднання послідовного мислення та короткочасних підказок.
Як?
По суті, підказки CoT спрямовують LLM на послідовну обробку інформації. Це означає, що ми показуємо, як розв’язати першу проблему за допомогою багатоетапного обґрунтування, а потім надсилаємо моделі наше реальне завдання, очікуючи, що вона емулюватиме порівнянний ланцюжок думок, відповідаючи на фактичний запит, який ми хочемо вирішити.
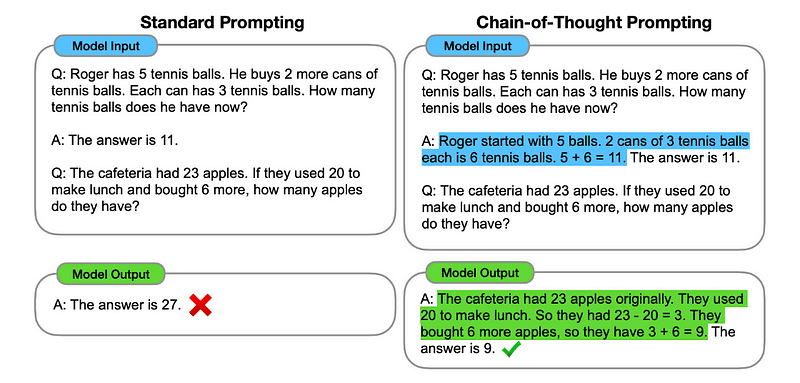
Зображення взято з папір.
Отже, слідуючи найпершому прикладу, ми могли б надати підказку з першою проблемою та послідовне пояснення того, як її вирішити. Тоді ми можемо надіслати свій внесок і побачити, як відбувається магія!
Якщо Іван має 5 груш, потім з’їсть 2, купить ще 5 і віддасть 3 своєму другові, скільки у нього груш? Давайте міркувати крок за кроком.
Давайте крок за кроком. Іван починає з 5 груш. Він з’їв 2 груші, тому у нього залишилося 5–2 = 3 груші. Потім він купує ще 5 груш. Отже, тепер у нього 3 + 5 = 8 груш. Нарешті він віддає 3 груші своєму другові. Отже, у нього залишилося 8–3 = 5 груш. Отже, після всіх цих кроків у Джона залишилося 5 груш.
Ваш внесок тут.
Однак більшість із вас, мабуть, думає… Чи потрібно мені думати про послідовний спосіб вирішення будь-якої проблеми кожного разу, коли я хочу щось запитати в ChatGPT?
Ну… ти не перший! І це веде нас до…
2. Автоматичний ланцюг думок (Auto-CoT)
У 2022, Zhang і колеги представили метод, щоб уникнути цього ручного процесу. Є дві основні причини уникати ручних завдань:
- Це може бути нудно.
- Це може призвести до поганих результатів – наприклад, коли наш розумовий процес неправильний.
Вони запропонували використовувати LLM у поєднанні з підказкою «Давайте подумаємо крок за кроком», щоб послідовно створювати ланцюжки міркувань для кожної демонстрації.
Це означає запитати ChatGPT, як послідовно вирішити будь-яку проблему, а потім використовувати цей самий приклад, щоб навчити його вирішувати будь-яку іншу проблему.
3. Самоузгодженість
Самоузгодженість є ще однією цікавою технікою спонукання, яка спрямована на покращення ланцюга спонукань думки для більш складних проблем міркування.
Отже... в чому головна відмінність?
Основна ідея Self-Consistency полягає в усвідомленні того, що ми можемо навчити модель на неправильному прикладі. Тільки уявіть, що я вирішую попередню задачу за допомогою неправильного розумового процесу:
Якщо Іван має 5 груш, потім з’їсть 2, купить ще 5 і віддасть 3 своєму другові, скільки у нього груш? Давайте міркувати крок за кроком.
Почніть з 5 груш. Джон їсть 2 груші. Потім він дає 3 груші своєму другові. Ці дії можна комбінувати: 2 (з’їдено) + 3 (віддано) = 5 груш загалом уражено. Тепер відніміть загальну кількість постраждалих груш від початкових 5 груш: 5 (початкові) – 5 (уражені) = 0 груш залишилося.
Тоді будь-яке інше завдання, яке я надсилаю моделі, буде неправильним.
Ось чому Self-Consistency включає вибірку з різних шляхів міркування, кожен з яких містить ланцюжок думок, а потім дозволяє LLM вибрати найкращий і найбільш послідовний шлях для вирішення проблеми.
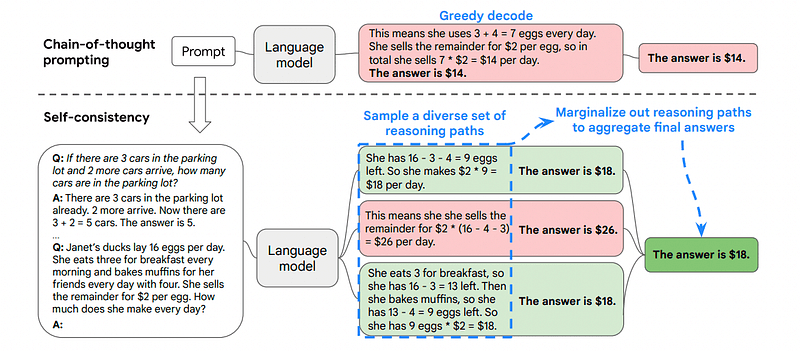
Зображення взято з папір
У цьому випадку, а також після першого прикладу, ми можемо показати моделі різні шляхи вирішення проблеми.
Якщо Іван має 5 груш, потім з’їсть 2, купить ще 5 і віддасть 3 своєму другові, скільки у нього груш?
Почніть з 5 груш. Джон з’їв 2 груші, залишивши 5–2 = 3 груші. Він купує ще 5 груш, що дає загальну суму 3 + 5 = 8 груш. Нарешті він віддає 3 груші своєму другові, отже, у нього залишилося 8–3 = 5 груш.
Якщо Іван має 5 груш, потім з’їсть 2, купить ще 5 і віддасть 3 своєму другові, скільки у нього груш?
Почніть з 5 груш. Потім він купує ще 5 груш. Зараз Джон з’їдає 2 груші. Ці дії можна комбінувати: 2 (з’їдено) + 5 (куплено) = 7 груш разом. Відніміть грушу, яку з’їв Джон, із загальної кількості груш 7 (загальна кількість) – 2 (з’їдено) = залишилося 5 груш.
Ваш внесок тут.
І ось остання техніка.
4. Загальні підказки знань
Поширеною практикою оперативного проектування є доповнення запиту додатковими знаннями перед надсиланням остаточного виклику API до GPT-3 або GPT-4.
За оцінками Jiacheng Liu and Co, ми завжди можемо додати деякі знання до будь-якого запиту, щоб LLM краще знав про це питання.
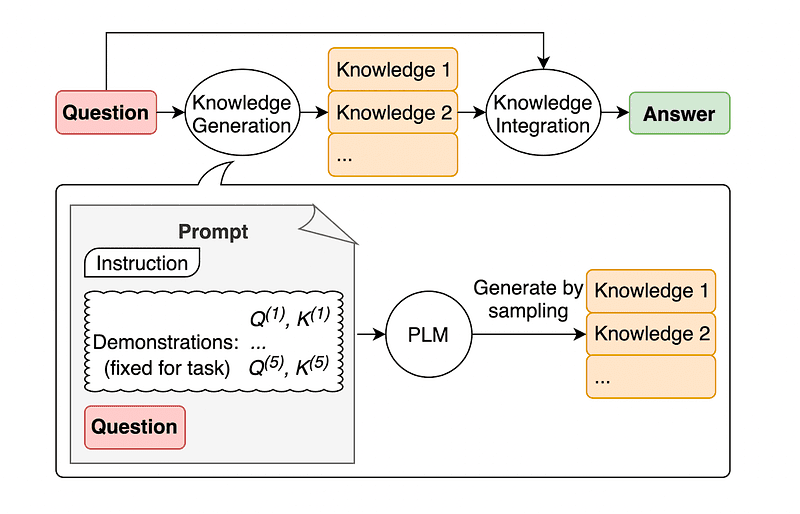
Зображення взято з папір.
Так, наприклад, коли запитуємо ChatGPT, чи частина гольфу намагається отримати більшу кількість очок, ніж інші, це підтвердить нас. Але головна мета гольфу зовсім протилежна. Ось чому ми можемо додати деякі попередні знання, кажучи: «Перемагає гравець з меншим результатом».

Отже.. що смішного, якщо ми повідомляємо моделі точну відповідь?
У цьому випадку ця техніка використовується для покращення способу взаємодії LLM з нами.
Тож замість того, щоб витягувати додатковий контекст із зовнішньої бази даних, автори статті рекомендують, щоб LLM виробляв власні знання. Ці самостійно створені знання потім інтегруються в підказку, щоб підкріпити здоровий глузд і дати кращі результати.
Отже, ось як LLM можна покращити, не збільшуючи набір навчальних даних!
Оперативна інженерія стала ключовою технікою для розширення можливостей LLM. Ітеруючи та вдосконалюючи підказки, ми можемо більш безпосередньо спілкуватися з моделями AI і таким чином отримувати точніші та контекстуально відповідні результати, заощаджуючи час і ресурси.
Для технічних ентузіастів, науковців з обробки даних і творців контенту розуміння та оволодіння оперативним проектуванням може бути цінним надбанням у використанні всього потенціалу ШІ.
Поєднуючи ретельно розроблені підказки введення з цими більш просунутими техніками, володіння набором навичок розробки підказок, безсумнівно, дасть вам перевагу в найближчі роки.
Хосеп Феррер – інженер-аналітик із Барселони. Він закінчив інженер-фізику та зараз працює в галузі Data Science, що стосується людської мобільності. Він неповний робочий день створює контент, який зосереджується на науці даних і технологіях. Ви можете зв'язатися з ним на LinkedIn, Twitter or Medium.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- : має
- :є
- : ні
- :де
- $UP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- здатність
- МЕНЮ
- точність
- точний
- дії
- фактичний
- додавати
- додати
- Додатковий
- просунутий
- після
- знову
- AI
- Моделі AI
- Цілі
- вирівняні
- так
- ВСІ
- Дозволити
- по
- вже
- завжди
- am
- кількість
- an
- аналітика
- та
- Інший
- відповідь
- будь-який
- API
- прикладної
- ЕСТЬ
- AS
- запитати
- запитувач
- активи
- authors
- автоматичний
- уникнути
- знати
- геть
- назад
- поганий
- Барселона
- основний
- BE
- оскільки
- було
- перед тим
- буття
- КРАЩЕ
- Краще
- підсилювач
- підвищення
- Нудно
- обидва
- куплений
- Відскакувати
- Перерва
- ламається
- Приносить
- ширше
- але
- Купує
- by
- call
- CAN
- можливості
- обережно
- випадок
- ланцюг
- ланцюга
- виклик
- проблеми
- ChatGPT
- Вибирати
- колеги
- комбінований
- об'єднання
- Приходити
- приходить
- майбутній
- загальний
- спілкуватися
- порівнянний
- повний
- комплекс
- вважається
- послідовний
- контакт
- зміст
- творці контенту
- контекст
- Виправлення
- правильно
- може
- створений
- творець
- Творці
- В даний час
- дані
- наука про дані
- Database
- Визначає
- надання
- призначений
- бажаний
- різниця
- різний
- прямий
- напрям
- відкрити
- дайвінг
- do
- робить
- домен
- домени
- вниз
- кожен
- край
- ефективність
- ефективність
- з'явився
- інженер
- Машинобудування
- підвищувати
- підвищення
- досить
- забезпечувати
- ентузіастів
- точно
- приклад
- Приклади
- виконувати
- очікував
- Пояснювати
- пояснення
- знайомий
- кілька
- поле
- остаточний
- в кінці кінців
- Перший
- увагу
- фокусується
- після
- для
- примус
- Вперед
- друг
- від
- Повний
- смішний
- Загальне
- породжувати
- отримати
- Давати
- даний
- дає
- Go
- мета
- гольф
- добре
- керівництво
- Жорсткий
- Запрягання
- Мати
- має
- he
- тут
- високоякісний
- вище
- його
- його
- Як
- How To
- Однак
- HTTPS
- людина
- людський інтелект
- i
- ідея
- if
- картина
- удосконалювати
- поліпшений
- поліпшення
- поліпшення
- in
- зростаючий
- інформація
- початковий
- вхід
- екземпляр
- інструкції
- інтегрований
- Інтелект
- взаємодіє
- цікавий
- в
- введені
- включає в себе
- IT
- ЙОГО
- Джон
- джон
- просто
- KDnuggets
- тримати
- удар
- Kicks
- Знати
- знання
- знає
- мова
- останній
- Пізно
- Веде за собою
- Стрибок
- вивчення
- догляд
- залишити
- менше
- дозволяти
- здавати
- використання
- як
- знизити
- магія
- головний
- зробити
- Робить
- манера
- керівництво
- багато
- Освоєння
- Матерія
- me
- засоби
- психічний
- злиття
- метод
- може бути
- мобільність
- модель
- Моделі
- більше
- найбільш
- переміщення
- множинний
- повинен
- Необхідність
- ніколи
- немає
- зараз
- отримувати
- of
- on
- один раз
- протилежний
- оптимізуючий
- or
- Інше
- інші
- наші
- з
- вихід
- виходи
- поза
- власний
- Папір
- частина
- шлях
- ідеальний
- виконувати
- продуктивність
- Фізика
- основний
- plato
- Інформація про дані Платона
- PlatoData
- гравець
- точка
- потенціал
- практика
- точно
- представити
- досить
- попередній
- Проблема
- проблеми
- процес
- виробляти
- продуктивність
- забезпечувати
- забезпечення
- тягне
- питання
- досить
- діапазон
- швидше
- реальний
- Причини
- рекомендувати
- зменшити
- відноситься
- доречний
- запросити
- пружність
- ресурсомісткий
- ресурси
- відповідаючи
- відповідь
- відповіді
- результати
- перепідготовка
- Революція
- право
- Кімната
- s
- то ж
- економія
- наука
- Наука і технології
- Вчені
- рахунок
- побачити
- послати
- відправка
- Послідовність
- комплект
- кілька
- Показувати
- істотно
- майстерність
- So
- виключно
- ВИРІШИТИ
- Розв’язування
- деякі
- Хтось
- що в сім'ї щось
- конкретний
- відпрацьований
- етапи
- старт
- починається
- управляти
- Крок
- заходи
- Як і раніше
- стиль
- Переконайтеся
- снасті
- прийняті
- Завдання
- завдання
- технології
- техніка
- методи
- Технологія
- говорять
- термін
- ніж
- Що
- Команда
- Їх
- потім
- Там.
- отже
- Ці
- вони
- думати
- Мислення
- це
- думка
- через
- Таким чином
- час
- до
- TONE
- Усього:
- ТОТАЛЬНО
- поїзд
- Навчання
- дерево
- намагався
- намагатися
- намагається
- два
- кінцевий
- при
- пройти
- розуміти
- розуміння
- безсумнівно
- us
- використання
- використовуваний
- використання
- ПЕРЕВІР
- Цінний
- різний
- різнобічний
- дуже
- хотіти
- шлях..
- способи
- we
- добре відомі
- були
- коли
- який
- чому
- волі
- вітер
- з
- в
- без
- слово
- робочий
- світ
- Неправильно
- років
- ще
- вихід
- ви
- вашу
- зефірнет







