Середовище виконання Amazon EMR для Apache Spark — це середовище виконання з оптимізованою продуктивністю для Apache Spark, яке на 100% сумісне з API із відкритим кодом Apache Spark. с Amazon EMR версії 6.9.0, середовище виконання EMR для Apache Spark підтримує еквівалентну версію Spark 3.3.0.
З Amazon EMR 6.9.0 тепер ви можете запускати свої програми Apache Spark 3.x швидше та з меншою ціною, не вимагаючи жодних змін у своїх програмах. У наших порівняльних тестах продуктивності, отриманих на основі тестів продуктивності TPC-DS у масштабі 3 ТБ, ми виявили, що середовище виконання EMR для Apache Spark 3.3.0 забезпечує в середньому в 3.5 рази підвищення продуктивності (за загальним часом виконання) порівняно з Apache Spark 3.3.0 з відкритим кодом. XNUMX.
У цьому дописі ми аналізуємо результати наших порівняльних тестів із застосуванням програми TPC-DS Apache Spark з відкритим кодом а потім на Amazon EMR 6.9, який постачається з оптимізованим середовищем виконання Spark, сумісним із Spark з відкритим кодом. Ми проводимо детальний аналіз витрат і, нарешті, надаємо покрокові інструкції для проведення порівняльного тесту.
Спостереження за результатами
Щоб оцінити покращення продуктивності, ми використали утиліту тестування продуктивності Spark з відкритим кодом, яка є похідною від набору інструментів тестування продуктивності TPC-DS. Ми провели тести на кластері EMR c5d.9xlarge із семи вузлами (шість основних вузлів і один основний вузол) із середовищем виконання EMR для Apache Spark і другому самокерованому кластері з семи вузлів на Обчислювальна хмара Amazon Elastic (Amazon EC2) з еквівалентною версією Spark з відкритим кодом. Ми провели обидва тести з даними Служба простого зберігання Amazon (Amazon S3).
Динамічний розподіл ресурсів (DRA) — це чудова функція, яку можна використовувати для різних робочих навантажень. Однак для порівняльного аналізу, де ми порівнюємо дві платформи виключно за продуктивністю, а обсяги тестових даних не змінюються (3 ТБ у нашому випадку), ми вважаємо, що найкраще уникати мінливості, щоб провести порівняння яблук з яблуками. У наших тестах як у Spark з відкритим кодом, так і в Amazon EMR ми вимкнули DRA під час роботи програми порівняльного аналізу.
У наведеній нижче таблиці показано загальний час виконання завдання для всіх запитів (у секундах) у наборі даних запитів розміром 3 ТБ між Amazon EMR версії 6.9.0 і Spark з відкритим кодом версії 3.3.0. Ми помітили, що загальний час виконання завдань на Amazon EMR на Amazon EC2 у наших тестах TPC-DS був у 3.5 рази швидшим, ніж у кластері Spark з відкритим кодом такої ж конфігурації.
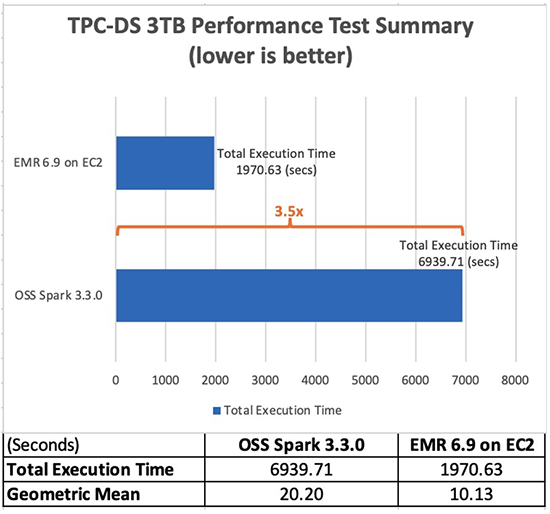
Прискорення кожного запиту в Amazon EMR 6.9 із середовищем виконання EMR для Apache Spark і без нього показано на наступній діаграмі. На горизонтальній осі показано кожен запит у контрольному тесті 3 ТБ. Вертикальна вісь показує прискорення кожного запиту завдяки часу виконання EMR. Помітне підвищення продуктивності більш ніж у 10 разів швидше для запитів TPC-DS 24b, 72, 95 і 96.

Аналіз витрат
Покращення продуктивності середовища виконання EMR для Apache Spark безпосередньо призводить до зниження витрат. Нам вдалося заощадити 67% витрат на використання еталонної програми на Amazon EMR порівняно з витратами, понесеними на запуск тієї самої програми на Spark з відкритим кодом на Amazon EC2 із тим самим розміром кластера завдяки скороченню годин роботи Amazon EMR і Amazon Використання EC2. Ціни Amazon EMR стосуються додатків EMR, які працюють у кластерах EMR з примірниками EC2. Ціна Amazon EMR додається до основних цін на обчислення та зберігання, таких як ціна інстансу EC2 і Магазин еластичних блоків Amazon (Amazon EBS) вартість (якщо підключаються томи EBS). Загалом орієнтовна вартість у східному регіоні США (Північна Вірджинія) становить 27.01 дол. США за запуск для Spark з відкритим кодом на Amazon EC2 і 8.82 дол. США за запуск для Amazon EMR.
| Еталонна робота | Час виконання (година) | Орієнтовна вартість | Загальний екземпляр EC2 | Всього vCPU | Загальна пам'ять (ГіБ) | Кореневий пристрій (Amazon EBS) |
|
Spark з відкритим кодом на Amazon EC2 (1 основний і 6 основних вузлів) |
2.23 | $27.01 | 7 | 252 | 504 | 20 ГБ gp2 |
|
Amazon EMR на Amazon EC2 (1 основний і 6 основних вузлів) |
0.63 | $8.82 | 7 | 252 | 504 | 20 ГБ gp2 |
Розбивка витрат
Нижче наведено розбивку вартості роботи Spark з відкритим кодом на Amazon EC2 ($27.01):
- Загальна вартість Amazon EC2 – (7 * 1.728 дол. США * 2.23) = (кількість випадків * c5d.9xвелика погодинна ставка * час виконання завдання в годинах) = 26.97 дол.
- Вартість Amazon EBS – (0.1/730 $ * 20 * 7 * 2.23) = (EBS Amazon за ГБ-годинну ставку * розмір кореневого EBS * кількість екземплярів * час виконання завдання в годину) = 0.042 $
Нижче наведено розподіл витрат на роботу Amazon EMR на Amazon EC2 ($8.82):
- Загальна вартість Amazon EMR – (7 * 0.27 дол. США * 0.63) = ((кількість основних вузлів + кількість основних вузлів)* c5d.9xlarge Amazon EMR ціна * тривалість роботи в годину) = 1.19 дол. США
- Загальна вартість Amazon EC2 – (7 * $1.728 * 0.63) = ((кількість основних вузлів + кількість основних вузлів)* c5d.9xlarge ціна екземпляра * час виконання завдання в годину) = $7.62
- Вартість Amazon EBS – (0.1 дол. США/730 * 20 ГіБ * 7 * 0.63) = (EBS Amazon за ГБ-годинну ставку * розмір EBS * кількість екземплярів * час виконання завдання в годину) = 0.012 дол. США
Налаштуйте порівняльний аналіз OSS Spark
У наступних розділах ми надаємо короткий опис кроків, пов’язаних із налаштуванням порівняльного аналізу. Докладні інструкції з прикладами див GitHub репо.
Для порівняльного аналізу OSS Spark ми використовуємо інструмент із відкритим кодом Флінтрок щоб запустити наш Amazon EC2 Apache Spark кластер. Flintrock забезпечує швидкий спосіб запуску кластера Apache Spark на Amazon EC2 за допомогою командного рядка.
Передумови
Виконайте такі необхідні кроки:
- Мати Python 3.7.x або вище.
- Мати Pip3 22.2.2 або вище.
- Додайте каталог bin Python до шляху вашого середовища. Двійковий файл Flintrock буде встановлено на цьому шляху.
- прогін
aws configureщоб налаштувати свій Інтерфейс командного рядка AWS (AWS CLI), щоб вказувати на обліковий запис порівняльного аналізу. Відноситься до Швидке налаштування за допомогою aws configure для інструкцій. - Є пара ключів з обмеженими правами доступу до файлів для доступу до основного вузла OSS Spark.
- За потреби створіть нове відро S3 у своєму тестовому обліковому записі.
- Скопіюйте вихідні дані TPC-DS як вхідні дані в сегмент S3.
- Створіть тестову програму, дотримуючись кроків, наведених у Кроки для створення додатка Spark-Benchmark-Assembly. Крім того, ви можете завантажити попередньо зібрану версію spark-benchmark-assembly-3.3.0.jar якщо вам потрібна програма на основі Spark 3.3.0.
Розгорніть кластер Spark і запустіть завдання тестування
Виконайте такі дії:
- Встановіть інструмент Flintrock через pip, як показано на Кроки для налаштування OSS Spark Benchmarking.
- Виконайте команду flintrock configure, яка відкриє файл конфігурації за замовчуванням.
- Змініть за замовчуванням
config.yamlфайл відповідно до ваших потреб. Або скопіюйте та вставте файл config.yaml вміст у файл конфігурації за замовчуванням. Потім збережіть файл там, де він був. - Нарешті, запустіть 7-вузловий кластер Spark на Amazon EC2 через Flintrock.
Це має створити кластер Spark з одним основним вузлом і шістьма робочими вузлами. Якщо ви бачите будь-які повідомлення про помилки, ще раз перевірте значення файлу конфігурації, особливо версії Spark і Hadoop, а також атрибути джерела завантаження та AMI.
Кластер OSS Spark не постачається з менеджером ресурсів YARN. Щоб увімкнути його, нам потрібно налаштувати кластер.
- Завантажити yarn-site.xml та enable-yarn.sh файли зі сховища GitHub.
- Замінити з IP-адресою основного вузла у вашому кластері Flintrock.
Ви можете отримати IP-адресу з консолі Amazon EC2.
- Завантажте файли на всі вузли кластера Spark.
- Запустіть сценарій enable-yarn.
- Увімкніть підтримку Snappy у Hadoop (еталонне завдання читає стислі дані Snappy).
- Завантажте JAR-файл утиліти тестування spark-benchmark-assembly-3.3.0.jar на вашу локальну машину.
- Скопіюйте цей файл у кластер.
- Увійдіть до основного вузла та запустіть YARN.
- Надішліть завдання тестування на кластері Spark з відкритим кодом, як показано в Надішліть контрольне завдання.
Підведіть підсумки
Завантажте файл результатів тесту з вихідного сегмента S3 s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Замінити $YOUR_S3_BUCKET з іменем сегмента S3.) Ви можете використовувати консоль Amazon S3 і перейти до вихідного розташування S3 або використовувати AWS CLI.
Програма тестування Spark створює папку з міткою часу та записує файл підсумку всередині префікса summary.csv. Ваша позначка часу та ім’я файлу відрізнятимуться від наведених у попередньому прикладі.
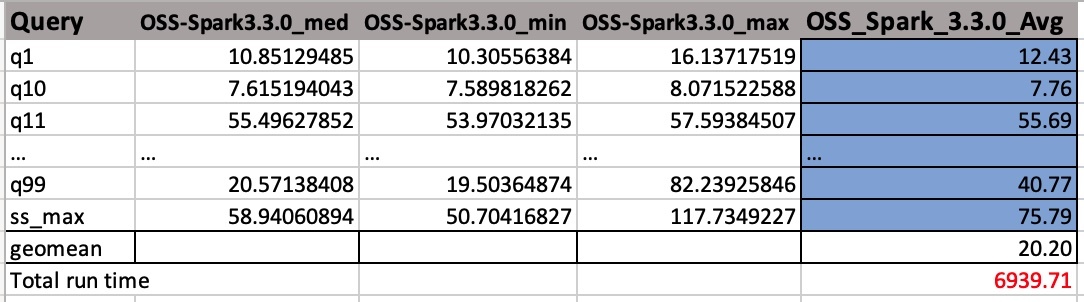
Вихідні файли CSV мають чотири стовпці без імен заголовків. Вони є:
- Назва запиту
- Середній час
- Мінімальний час
- Максимальний час
На наступному знімку екрана показано зразок результату. Ми вручну додали назви стовпців. Те, як ми обчислюємо геосереднє та загальний час виконання завдання, базується на середніх арифметичних. Спочатку ми беремо середнє середнє, мінімальне та максимальне значення за допомогою формули AVERAGE(B2:D2). Потім ми беремо середнє геометричне стовпця Avg за формулою GEOMEAN(E2:E105).
Налаштуйте порівняльний аналіз Amazon EMR
Докладні інструкції див Кроки для налаштування EMR Benchmarking.
Передумови
Виконайте такі необхідні кроки:
- прогін
aws configureщоб налаштувати оболонку AWS CLI для вказівки на обліковий запис порівняльного аналізу. Відноситься до Швидке налаштування за допомогою aws configure для інструкцій. - Завантажте програму тестування на Amazon S3.
Розгорніть кластер EMR і запустіть завдання тестування
Виконайте такі дії:
- Запустіть Amazon EMR у своїй оболонці AWS CLI за допомогою командного рядка, як показано на Розгорніть EMR Cluster і запустіть тестове завдання.
- Налаштуйте Amazon EMR з одним основним (c5d.9xlarge) і шістьма основними (c5d.9xlarge) вузлами. Відноситься до створити кластер для детального опису опцій AWS CLI.
- Збережіть ідентифікатор кластера з відповіді. Це вам знадобиться на наступному кроці.
- Надішліть тестове завдання в Amazon EMR, використовуючи кроки додавання в AWS CLI.
Підведіть підсумки
Узагальніть результати з вихідного відра s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT так само, як ми це зробили для результатів OSS, і порівняйте.
Прибирати
Щоб уникнути майбутніх витрат, видаліть ресурси, які ви створили, дотримуючись інструкцій у Розділ очищення сховища GitHub.
- Зупиніть кластери EMR і OSS Spark. Ви також можете видалити їх, якщо не хочете зберігати вміст. Ви можете видалити ці ресурси, запустивши сценарій cleanup-benchmark-env.sh з терміналу у вашому середовищі тестування.
- Якщо ви використовували AWS Cloud9 як IDE для створення JAR-файлу тестової програми за допомогою Кроки для створення додатка Spark-Benchmark-Assembly, ви також можете видалити середовище.
Висновок
За допомогою Amazon EMR 3.5 ви можете запускати робочі навантаження Apache Spark у 6.9.0 рази (на основі загального часу виконання) швидше та з нижчою ціною, не вносячи жодних змін у свої програми.
Щоб бути в курсі подій, підпишіться на Big Data Blog RSS подача щоб дізнатися більше про середовище виконання EMR для Apache Spark, найкращі методи налаштування та поради щодо налаштування.
Про минулі тести порівняння див Виконуйте робочі навантаження Apache Spark 3.0 у 1.7 рази швидше за допомогою середовища виконання Amazon EMR для Apache Spark. Зауважте, що попередній результат порівняння продуктивності в 1.7 раза базувався на середньому геометричному. Виходячи з середнього геометричного, продуктивність в Amazon EMR 6.9 була вдвічі вищою.
Про авторів
 Секар Шрінівасан є старшим архітектором-спеціалістом із рішень у AWS, який спеціалізується на великих даних та аналітиці. Секар має понад 20-річний досвід роботи з даними. Він захоплений тим, щоб допомагати клієнтам створювати масштабовані рішення, модернізуючи їх архітектуру та генеруючи інформацію на основі їхніх даних. У вільний час він любить працювати над некомерційними проектами, особливо тими, які спрямовані на освіту дітей із неблагополучних дітей.
Секар Шрінівасан є старшим архітектором-спеціалістом із рішень у AWS, який спеціалізується на великих даних та аналітиці. Секар має понад 20-річний досвід роботи з даними. Він захоплений тим, щоб допомагати клієнтам створювати масштабовані рішення, модернізуючи їх архітектуру та генеруючи інформацію на основі їхніх даних. У вільний час він любить працювати над некомерційними проектами, особливо тими, які спрямовані на освіту дітей із неблагополучних дітей.
 Прабу Равічандран є старшим архітектором даних Amazon Web Services, який спеціалізується на аналітиці, архітектурі Data Lake та реалізації. Він допомагає клієнтам розробляти та створювати масштабовані та надійні рішення за допомогою сервісів AWS. У вільний час Прабу любить подорожувати та проводити час із родиною.
Прабу Равічандран є старшим архітектором даних Amazon Web Services, який спеціалізується на аналітиці, архітектурі Data Lake та реалізації. Він допомагає клієнтам розробляти та створювати масштабовані та надійні рішення за допомогою сервісів AWS. У вільний час Прабу любить подорожувати та проводити час із родиною.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 роки
- 7
- 9
- a
- Здатний
- МЕНЮ
- вище
- доступ
- рахунки
- доданий
- адреса
- рада
- ВСІ
- розподіл
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- аналіз
- аналітика
- аналізувати
- та
- Apache
- Apache Spark
- API
- додаток
- застосування
- архітектура
- Атрибути
- середній
- AVG
- AWS
- Вісь
- заснований
- Вірити
- еталонний тест
- КРАЩЕ
- передового досвіду
- між
- Великий
- Великий даних
- Блокувати
- Пробій
- будувати
- Створюємо
- випадок
- зміна
- Зміни
- вантажі
- Графік
- кластер
- Колонка
- Колони
- Приходити
- порівняти
- порівняння
- сумісний
- обчислення
- конфігурація
- Консоль
- зміст
- Core
- Коштувати
- економія на витратах
- витрати
- створювати
- створений
- створює
- Клієнти
- дані
- Озеро даних
- Дата
- дефолт
- Отриманий
- description
- докладно
- пристрій
- DID
- різний
- безпосередньо
- інвалід
- Ні
- Не знаю
- скачати
- кожен
- Схід
- відливи
- Освіта
- включіть
- Навколишнє середовище
- Еквівалент
- помилка
- особливо
- оцінка
- Ефір (ETH)
- оцінювати
- приклад
- Приклади
- Здійснювати
- досвід
- сім'я
- швидше
- особливість
- філе
- Файли
- в кінці кінців
- Перший
- увагу
- зосереджений
- після
- формула
- знайдений
- Безкоштовна
- від
- майбутнє
- прибуток
- породжує
- GitHub
- великий
- Hadoop
- допомогу
- допомагає
- Горизонтальний
- ГОДИННИК
- Однак
- HTML
- HTTPS
- реалізація
- поліпшення
- поліпшення
- in
- вхід
- розуміння
- екземпляр
- інструкції
- залучений
- IP
- IP-адреса
- IT
- робота
- тримати
- озеро
- запуск
- УЧИТЬСЯ
- Лінія
- місцевий
- розташування
- машина
- Робить
- менеджер
- манера
- вручну
- Макс
- засоби
- пам'ять
- повідомлення
- більше
- ім'я
- Імена
- Переміщення
- Необхідність
- необхідний
- потреби
- Нові
- наступний
- вузол
- вузли
- некомерційний
- Помітний
- номер
- ONE
- з відкритим вихідним кодом
- оптимізований
- Опції
- порядок
- Нам
- план
- загальний
- пристрасний
- Минуле
- шлях
- продуктивність
- Дозволи
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- точка
- попсовий
- пошта
- практики
- price
- ціни
- ціни без прихованих комісій
- первинний
- приватний
- проектів
- забезпечувати
- за умови
- забезпечує
- суто
- Python
- Швидко
- ставка
- реалізувати
- Знижений
- регіон
- звільнити
- замінювати
- ресурс
- ресурси
- відповідь
- Обмежувальний
- результат
- результати
- міцний
- корінь
- прогін
- біг
- то ж
- зберегти
- Економія
- масштабовані
- шкала
- другий
- seconds
- розділ
- розділам
- старший
- Послуги
- установка
- установка
- Склад
- Повинен
- показаний
- Шоу
- простий
- SIX
- Розмір
- Рішення
- Source
- Іскритися
- спеціаліст
- Витрати
- старт
- Крок
- заходи
- зберігання
- підписуватися
- такі
- РЕЗЮМЕ
- підтримка
- Опори
- таблиця
- Приймати
- термінал
- тест
- Тести
- Команда
- їх
- через
- час
- times
- відмітка часу
- до
- інструмент
- Інструментарій
- Усього:
- переводити
- Подорож
- що лежить в основі
- малопривілейовані
- us
- Використання
- використання
- утиліта
- Цінності
- версія
- через
- Віргінія
- Обсяги
- Web
- веб-сервіси
- який
- в той час як
- волі
- без
- Work
- робочий
- робочий
- X
- XML
- ямл
- років
- вашу
- зефірнет