Нещодавно створена система штучного інтелекту (AI), заснована на глибокому підкріпленому навчанні (DRL), може реагувати на зловмисників у змодельованому середовищі та блокувати 95% кібератак до їх ескалації.
Так стверджують дослідники з Тихоокеанської північно-західної національної лабораторії Міністерства енергетики, які створили абстрактну симуляцію цифрового конфлікту між зловмисниками та захисниками в мережі та навчили чотири різні нейронні мережі DRL, щоб максимізувати винагороду на основі запобігання компромісам і мінімізації збоїв у мережі.
Імітовані нападники використовували серію тактик, заснованих на MITER ATT&CK за допомогою класифікації фреймворку для переходу від фази початкового доступу та розвідки до інших фаз атаки, поки вони не досягнуть своєї мети: фази впливу та ексфільтрації.
Успішне навчання системи штучного інтелекту в спрощеному середовищі атак демонструє, що захисна відповідь на атаки в режимі реального часу може бути оброблена моделлю штучного інтелекту, каже Самрат Чаттерджі, науковець з даних, який представив роботу команди на щорічній зустрічі Асоціації для Удосконалення штучного інтелекту у Вашингтоні, округ Колумбія, 14 лютого.
«Ви не хочете переходити до більш складних архітектур, якщо ви навіть не можете продемонструвати перспективність цих методів», — каже він. «Ми хотіли спершу продемонструвати, що ми дійсно можемо успішно навчити DRL і продемонструвати хороші результати тестування, перш ніж рухатися вперед».
Застосування методів машинного навчання та штучного інтелекту в різних сферах кібербезпеки стало гарячою тенденцією за останнє десятиліття, починаючи з ранньої інтеграції машинного навчання в шлюзи безпеки електронної пошти. на початку 2010 до останніх спроб використовувати ChatGPT для аналізу коду або провести судово-медичний аналіз. тепер, більшість продуктів безпеки мають — або стверджують, що мають — кілька функцій, які працюють на основі алгоритмів машинного навчання, навчених на великих наборах даних.
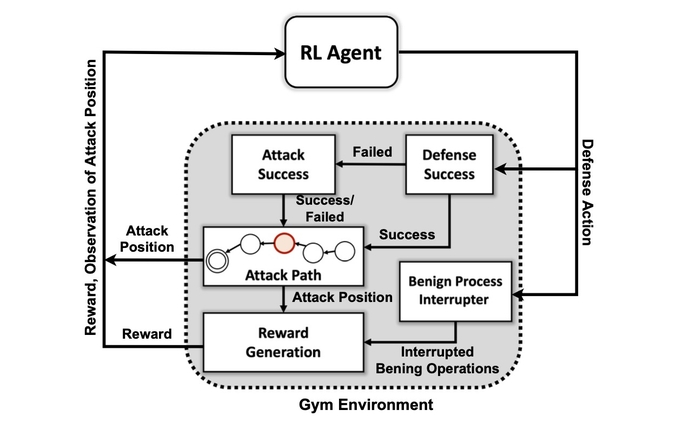
Проте створення системи штучного інтелекту, здатної до проактивного захисту, залишається радше бажанням, ніж практичним. Незважаючи на те, що для дослідників залишається ряд перешкод, дослідження PNNL показує, що захисник зі штучним інтелектом може бути можливим у майбутньому.
«Оцінка кількох алгоритмів DRL, навчених у різних змагальних налаштуваннях, є важливим кроком до практичних автономних рішень для кіберзахисту», — дослідницька група PNNL. зазначено в їхньому документі. «Наші експерименти свідчать про те, що безмодельні алгоритми DRL можуть бути ефективно навчені в багатоетапних профілях атаки з різними рівнями навичок і наполегливості, що забезпечує сприятливі результати захисту в спірних умовах».
Як система використовує MITER ATT&CK
Першою метою дослідницької групи було створити спеціальне середовище моделювання на основі набору інструментів з відкритим кодом, відомого як Відкрити AI Gym. Використовуючи це середовище, дослідники створили сутності зловмисників з різними рівнями навичок і наполегливості з можливістю використання підмножини з 7 тактик і 15 прийомів із структури MITER ATT&CK.
Цілі агентів зловмисників полягають у тому, щоб пройти через сім етапів ланцюга атаки, від початкового доступу до виконання, від наполегливості до командування та контролю та від збору до впливу.
Для нападника адаптація тактики до стану навколишнього середовища та поточних дій захисника може бути складною, каже Чаттерджі з PNNL.
«Противник повинен пройти свій шлях від початкового стану розвідки до певного стану ексфільтрації або удару», — каже він. «Ми не намагаємося створити якусь модель, щоб зупинити супротивника до того, як він потрапить у середовище — ми припускаємо, що система вже скомпрометована».
Дослідники використовували чотири підходи до нейронних мереж, засновані на навчанні з підкріпленням. Навчання з підкріпленням (RL) – це підхід до машинного навчання, який емулює систему винагороди людського мозку. Нейронна мережа навчається, підсилюючи або послаблюючи певні параметри для окремих нейронів, щоб винагороджувати кращі рішення, що вимірюється балом, який вказує на те, наскільки добре працює система.
Навчання з підкріпленням по суті дозволяє комп’ютеру створювати хороший, але не ідеальний підхід до проблеми, що розглядається, каже Махантеш Халаппанавар, дослідник PNNL і автор статті.
«Без використання навчання з підкріпленням ми могли б це зробити, але це була б справді велика проблема, у якої не вистачило б часу, щоб фактично придумати якийсь хороший механізм», — каже він. «Наше дослідження… дає нам цей механізм, за допомогою якого глибоке навчання з підкріпленням певною мірою імітує саму людську поведінку, і воно може дуже ефективно досліджувати цей величезний простір».
Не готовий до прайм-тайму
Експерименти виявили, що спеціальний метод навчання з підкріпленням, відомий як Deep Q Network, створив надійне рішення проблеми захисту, спіймати 97% нападників у наборі даних тестування. Але дослідження – це лише початок. Фахівці з безпеки не повинні найближчим часом шукати компаньйона зі штучним інтелектом, щоб допомогти їм у реагуванні на інциденти та криміналістиці.
Серед багатьох проблем, які ще належить вирішити, — навчання з підкріпленням і глибокі нейронні мережі для пояснення факторів, які вплинули на їхні рішення, область дослідження називається пояснюваним навчанням з підкріпленням (XRL).
Крім того, за словами Чаттерджі з PNNL, стійкість алгоритмів штучного інтелекту та пошук ефективних способів навчання нейронних мереж є проблемами, які потрібно вирішити.
«Створення продукту — це не було головною мотивацією для цього дослідження», — каже він. «Це було більше про наукові експерименти та алгоритмічні відкриття».
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- здатність
- МЕНЮ
- РЕЗЮМЕ
- доступ
- За
- дії
- насправді
- доповнення
- просування
- змагальність
- агенти
- AI
- Можливість
- алгоритмічний
- алгоритми
- ВСІ
- дозволяє
- вже
- аналіз
- аналізувати
- та
- щорічний
- додаток
- підхід
- підходи
- ПЛОЩА
- штучний
- штучний інтелект
- Штучний інтелект (AI)
- Асоціація
- атака
- нападки
- автор
- автономний
- заснований
- ставати
- перед тим
- Краще
- між
- Великий
- Блокувати
- Brain
- побудований
- званий
- не може
- здатний
- певний
- ланцюг
- ChatGPT
- стверджувати
- класифікація
- збір
- Приходити
- комплекс
- Компрометація
- комп'ютер
- Проводити
- конфлікт
- триває
- контроль
- може
- створювати
- створений
- створення
- Поточний
- виготовлений на замовлення
- кібер-
- кібератаки
- Кібербезпека
- дані
- вчений даних
- набір даних
- набори даних
- dc
- десятиліття
- рішення
- рішення
- глибокий
- глибокі нейронні мережі
- Захисники
- оборони
- оборонний
- демонструвати
- демонструє
- відділ
- Департамент енергетики
- різний
- цифровий
- відкриття
- Зрив
- Різне
- DOE
- Рано
- фактично
- ефективний
- продуктивно
- зусилля
- безпека електронної пошти
- енергія
- досить
- юридичні особи
- Навколишнє середовище
- по суті
- Ефір (ETH)
- оцінки
- Навіть
- виконання
- ексфільтрація
- Пояснювати
- дослідити
- фактори
- риси
- кілька
- Поля
- виявлення
- Перший
- потік
- Криміналістика
- судово-медичної експертизи
- Вперед
- знайдений
- Рамки
- від
- майбутнє
- отримати
- отримання
- дає
- мета
- Цілі
- добре
- рука
- допомога
- ГАРЯЧА
- Як
- HTTPS
- людина
- Перешкоди
- Impact
- важливо
- in
- інцидент
- реагування на інциденти
- вказуючи
- індивідуальний
- під впливом
- початковий
- інтеграція
- Інтелект
- IT
- сам
- Дитина
- відомий
- лабораторія
- великий
- вивчення
- рівні
- подивитися
- машина
- навчання за допомогою машини
- головний
- багато
- макс-ширина
- Максимізувати
- механізм
- засідання
- метод
- мінімізація
- модель
- більше
- мотивація
- рухатися
- переміщення
- множинний
- National
- Переміщення
- Необхідність
- мережу
- мереж
- Нейронний
- нейронної мережі
- нейронні мережі
- Нейрони
- відкрити
- з відкритим вихідним кодом
- Інше
- Тихий океан
- Папір
- параметри
- Минуле
- ідеальний
- виступає
- наполегливість
- фаза
- plato
- Інформація про дані Платона
- PlatoData
- це можливо
- Харчування
- Практичний
- представлений
- попередження
- Prime
- Проактивний
- Проблема
- проблеми
- Продукти
- професіонали
- Профілі
- обіцянку
- RE
- досяг
- Реагувати
- вступає в реакцію
- готовий
- реальний
- реального часу
- останній
- навчання
- залишатися
- дослідження
- дослідник
- Дослідники
- відповідь
- Винагороджувати
- Нагороди
- стійкість
- говорить
- вчений
- безпеку
- Серія
- комплект
- налаштування
- сім
- Повинен
- Показувати
- Шоу
- спрощений
- моделювання
- майстерність
- рішення
- Рішення
- деякі
- Скоро
- Source
- Простір
- конкретний
- старт
- стан
- Крок
- заходи
- Як і раніше
- Стоп
- зміцнення
- сильний
- успішний
- Успішно
- система
- тактика
- команда
- методи
- Тестування
- Команда
- Майбутнє
- Держава
- їх
- через
- час
- до
- Інструментарій
- до
- поїзд
- навчений
- Навчання
- Trend
- при
- us
- використання
- різноманітність
- величезний
- хотів
- Вашингтон
- способи
- в той час як
- ВООЗ
- волі
- в
- без
- Work
- б
- поступаючись
- зефірнет











